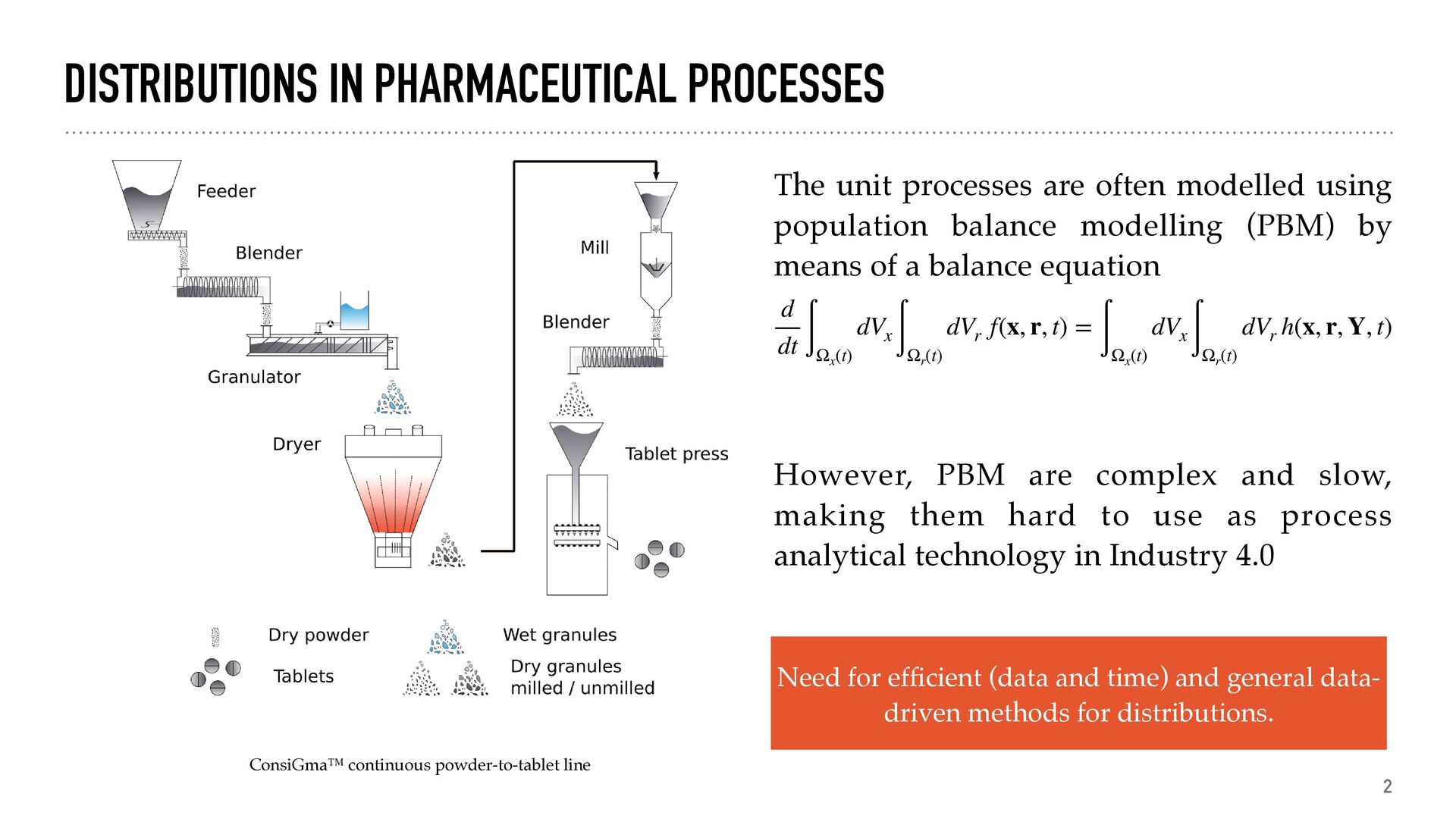
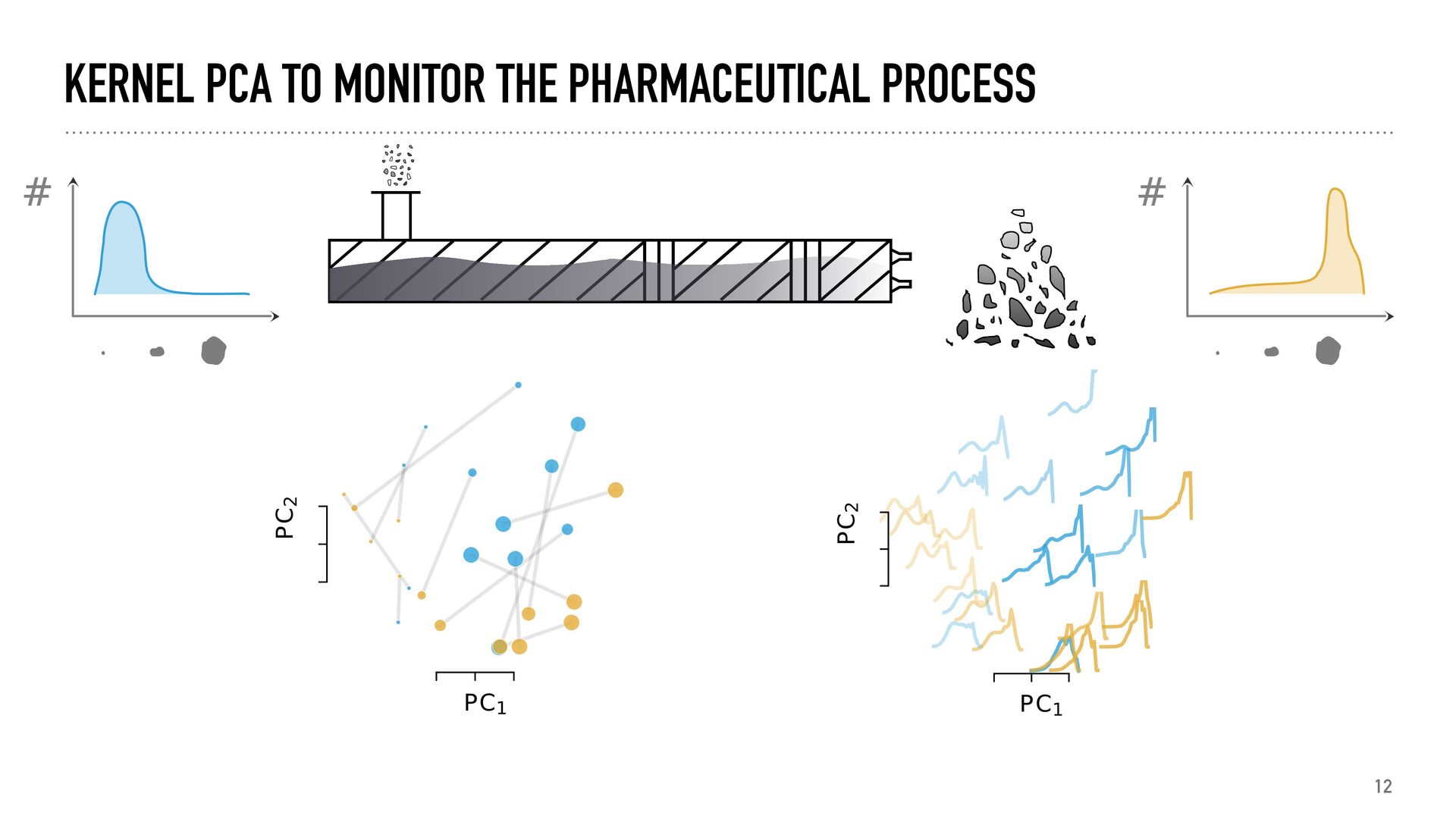
unit processes are often modelled using population balance modelling (PBM) by means of a balance equatio n d dt ∫ Ωx (t) dVx ∫ Ωr (t) dVr f(x, r, t) = ∫ Ωx (t) dVx ∫ Ωr (t) dVr h(x, r, Y, t) However, PBM are complex and slow, making them hard to use as process analytical technology in Industry 4.0 Need for ef fi cient (data and time) and general data- driven methods for distributions.
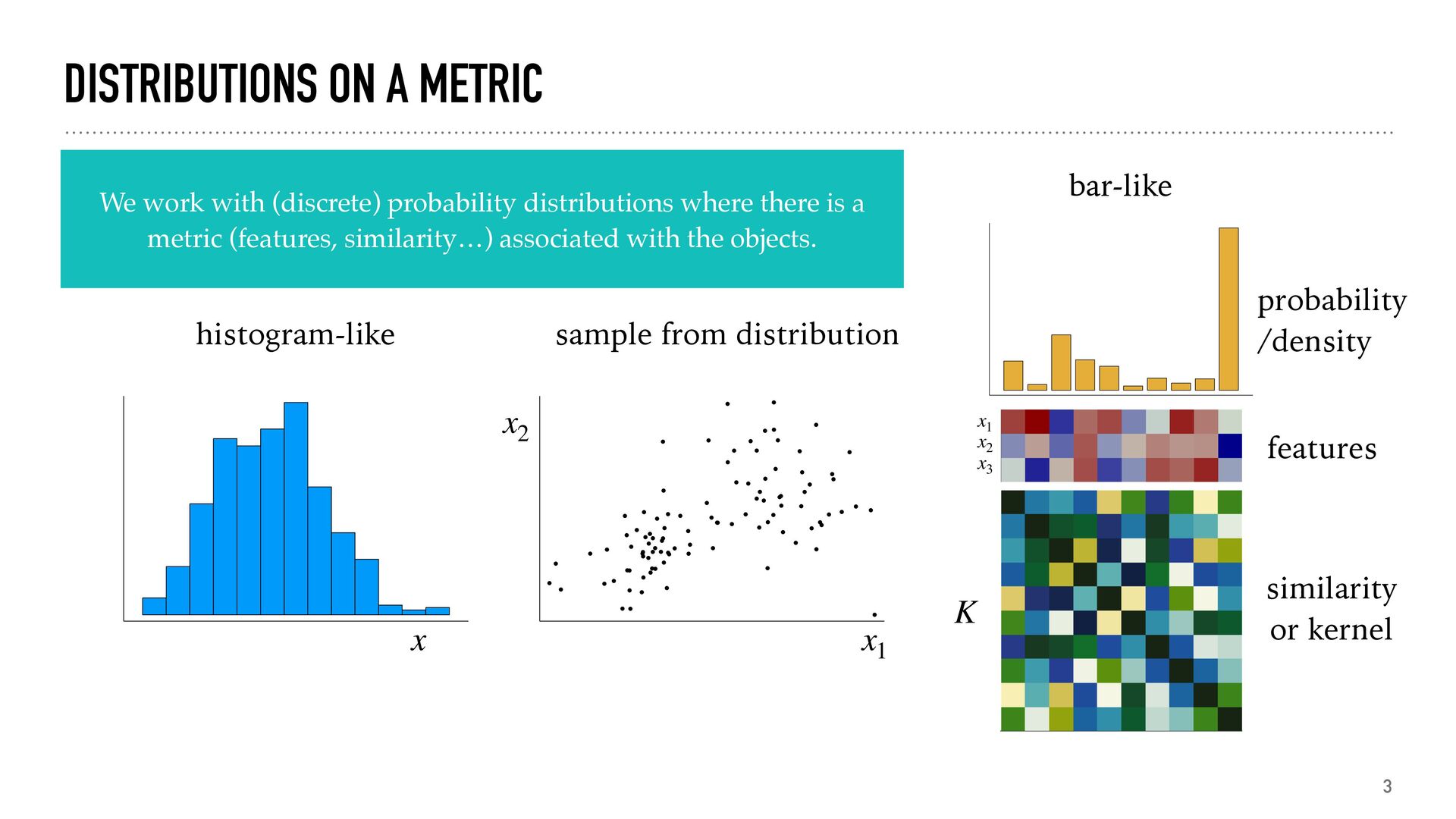
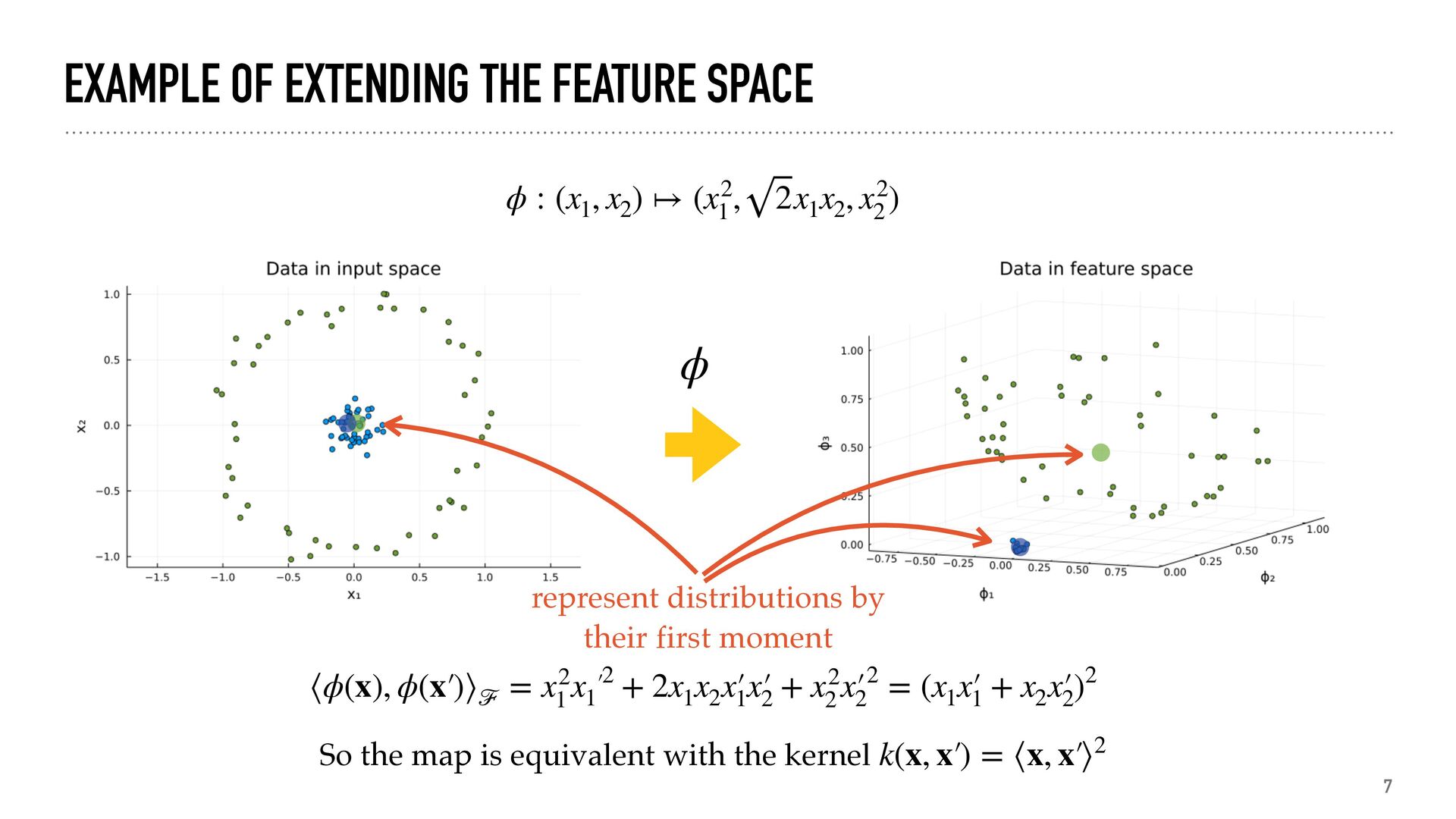
distributions where there is a metric (features, similarity…) associated with the objects. x histogram-like x1 x2 sample from distribution x1 x2 x3 bar-like K features similarity or kernel probability /density
how similar distributions are representation PC1 PC2 generate numerical descriptors of distributions predict X → → y predict distributions from properties or vice versa inference get the distribution from a description
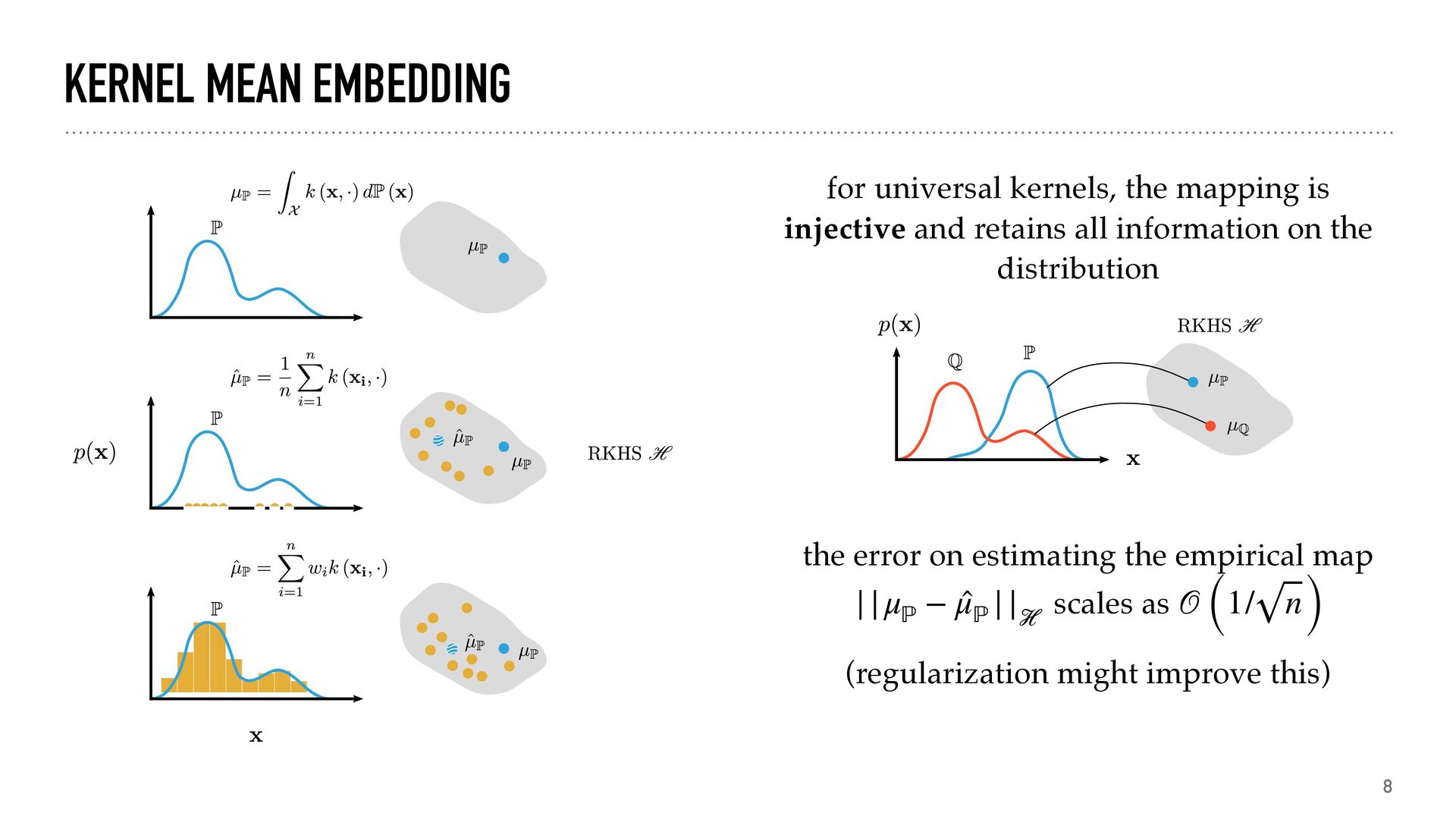
injective and retains all information on the distribution the error on estimating the empirical map scales as (regularization might improve this) ||μℙ − ̂ μℙ || ℋ 𝒪 (1/ n)
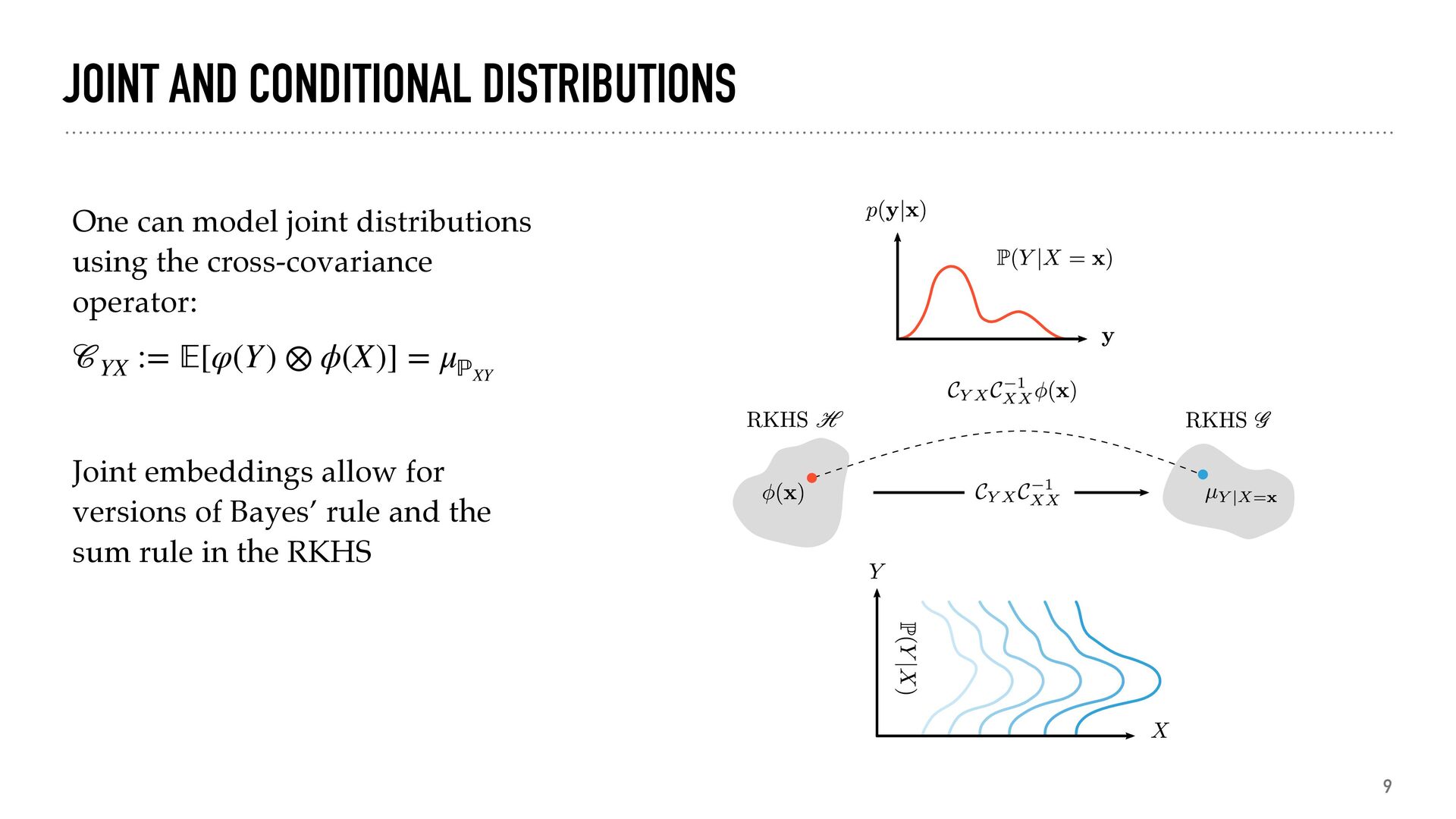
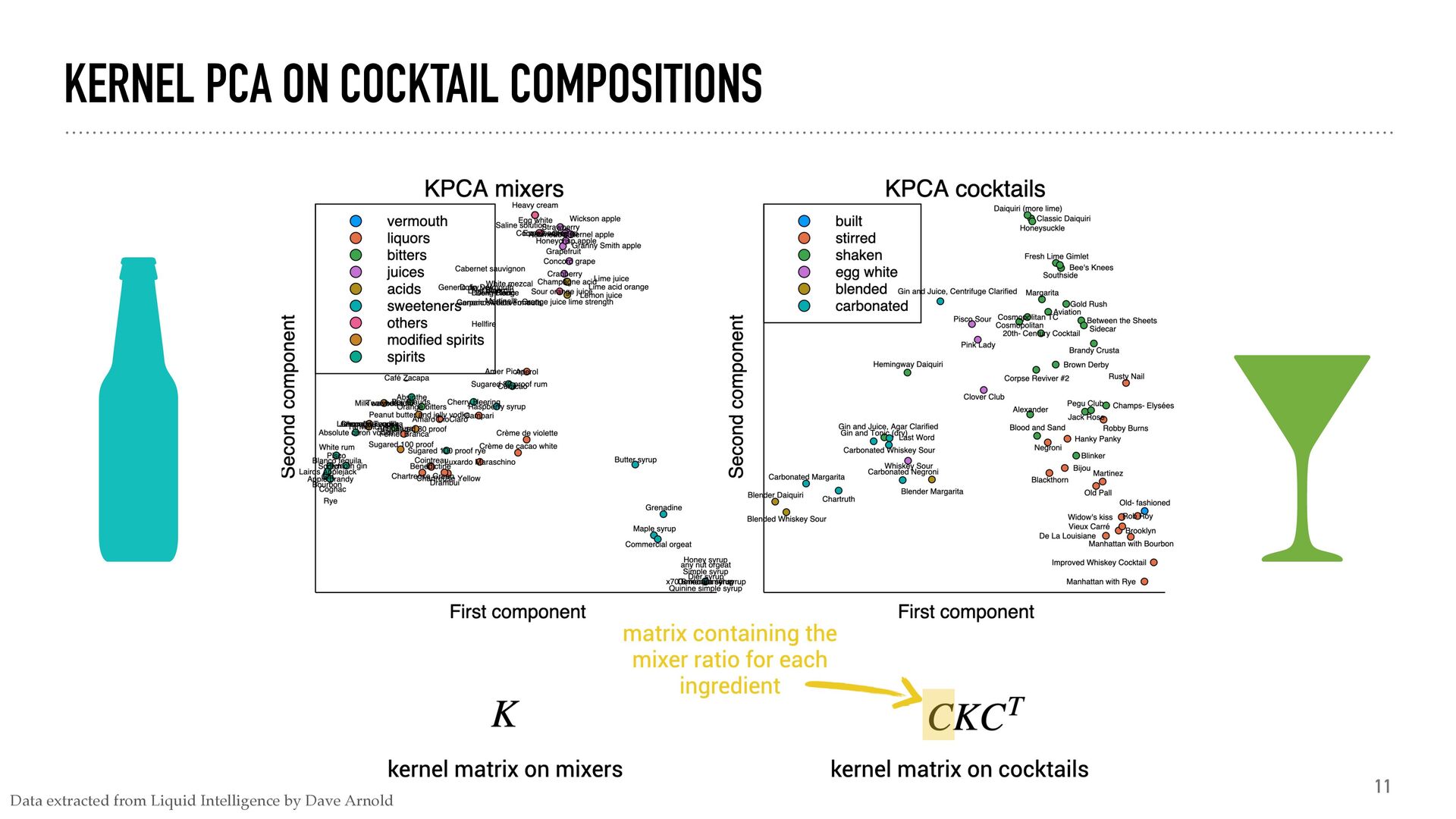
how similar distributions are representation PC1 PC2 generate numerical descriptors of distributions predict X → → y predict distributions from properties or vice versa inference get the distribution from a description maximum mean discrepancy (i.e. norm) ||μℙ − μℚ || ℋ kernel principal component analysi s (i.e. eigenvalues) svd(K) kernel ridge regressio n W = (K + λI)−1Φ fitting a parametrized distributio n min θ || ̂ μℙ − μℙθ ||2 ℋ +R(ℙθ )
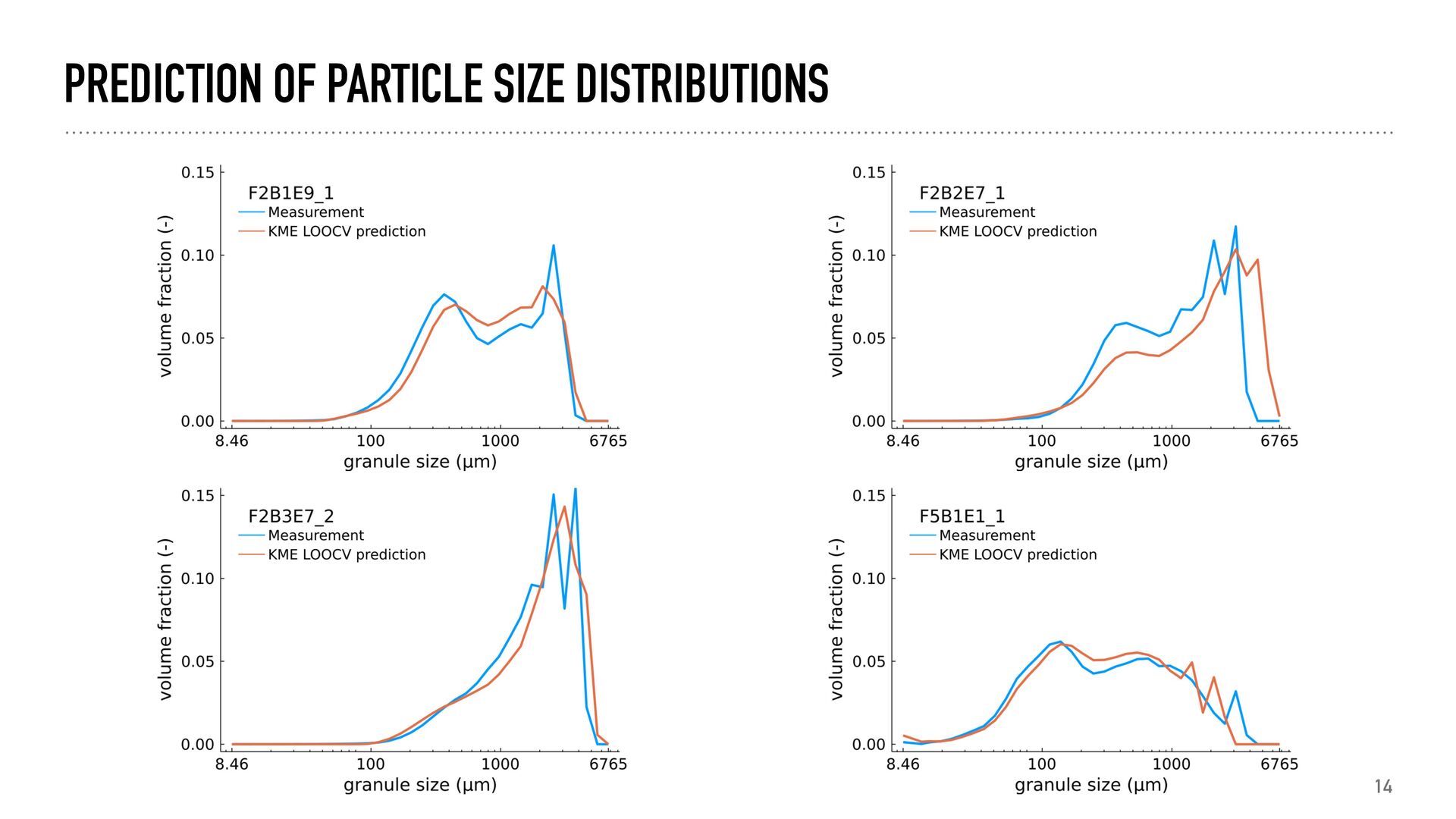
settings and powder composition . Dataset consists of 399 distributions with features . Goal: predict a histogram with 35 bins, logarithmically spaced between 8.46 and 6765.36 µm . We used a linear and RBF kernel for the process settings and blending ratios. These were combed by addition or element-wise multiplication . Evaluation was done using leave-one-out cross- validation with MSE, MMD and Kullback-Leibler as performance measures.
@michielstock [email protected] https://michielstock.github.io/ Daan Van Hauwermeire n UGent postdoc/co-founder elegen t https://www.ele.gent/ Jasper De Landsheer e former UGent master student Kernel mean embedding is a powerful and general method for manipulating and modeling distributions. It is both extremely simple to implement (35 loc) and blazingly fast (1 second to fi t and validate).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}