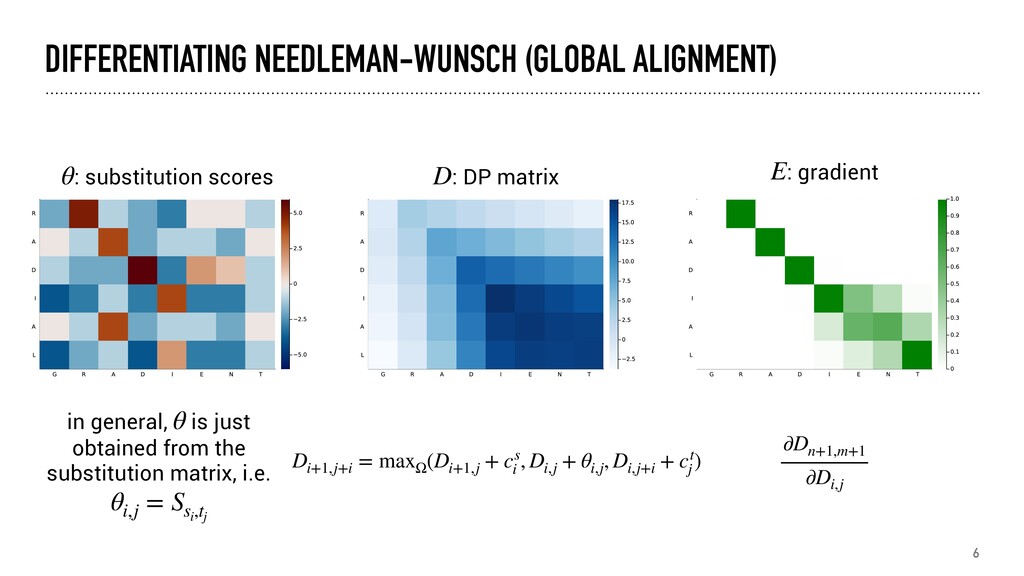
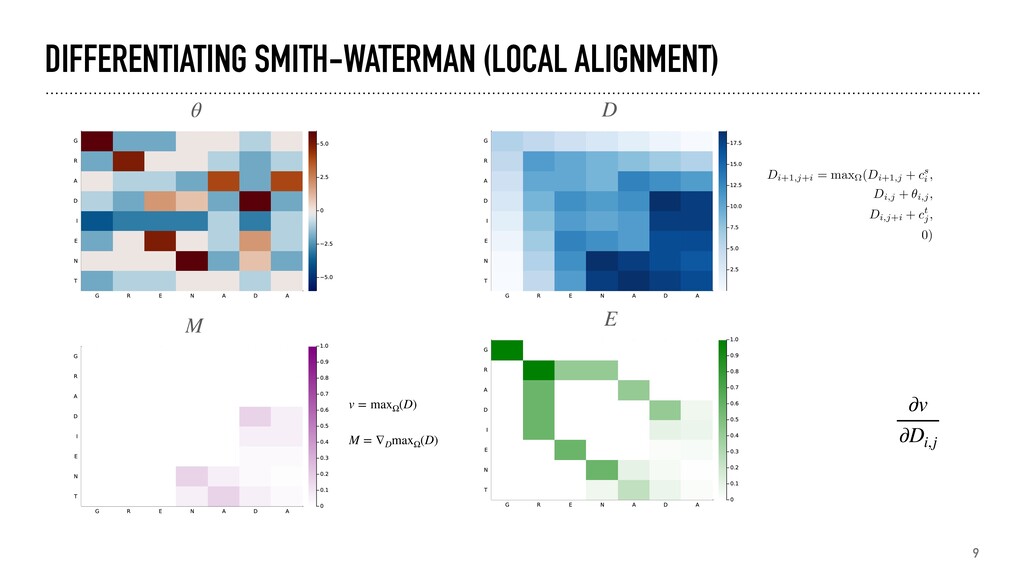
= size(θ) D = zeros(n+1, m+1) # initialize dynamic programming matrix D[2:n+1,1] .= -cumsum(cˢ) # cost of starting with gaps in s D[1,2:m+1] .= -cumsum(cᵗ) # cost of starting with gaps in t E = zeros(n+2, m+2) # matrix for the gradient E[n+2,m+2] = 1.0 Q = zeros(n+2, m+2, 3) # matrix for backtracking Q[n+2,m+2,2] = 1.0 # forward pass, performing dynamic programming for i in 1:n, j in 1:m v, q = max_argmaxᵧ((D[i+1,j] - cˢ[i], # gap in first sequence D[i,j] + θ[i,j], # extending the alignment D[i,j+1] - cᵗ[j])) # gap in second sequence D[i+1,j+1] = v # store smooth max Q[i+1,j+1,:] .= q # store directions end # backtracking through the directions to compute the gradient for i in n:-1:1, j in m:-1:1 E[i+1,j+1] = Q[i+1,j+2,1] * E[i+1,j+2] + Q[i+2,j+2,2] * E[i+2,j+2] + Q[i+2,j+1,3] * E[i+2,j+1] end return D[n+1,2:m+1], E[n+1,2:m+1] # value and gradient end initialize arrays for dynamic programming ( ), backtracking ( ) and the gradient ( ) D Q E compute optimal local choice and store soft maximum and its gradient backtrack to obtain the gradient
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}