Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Transformerの推論を線形時間にして皆を驚かせましょう
Search
小島瑞貴
May 30, 2026
47
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Transformerの推論を線形時間にして皆を驚かせましょう
小島瑞貴
May 30, 2026
More Decks by 小島瑞貴
See All by 小島瑞貴
【Zozo Research 技術共有会】三次元領域の現在と展望
mickey_0226
3
460
学術バーQってどんなところ??
mickey_0226
0
120
さわって動かす人工知能
mickey_0226
0
54
動画生成と三次元生成を融合して最強の生成モデルを作ろう
mickey_0226
0
49
CVPR2026_VGGTとその仲間たち
mickey_0226
0
960
Featured
See All Featured
Site-Speed That Sticks
csswizardry
13
1.2k
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.8k
個人開発の失敗を避けるイケてる考え方 / tips for indie hackers
panda_program
123
22k
What does AI have to do with Human Rights?
axbom
PRO
1
2.2k
sira's awesome portfolio website redesign presentation
elsirapls
0
300
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
Principles of Awesome APIs and How to Build Them.
keavy
128
18k
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.2k
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
Speed Design
sergeychernyshev
33
1.9k
BBQ
matthewcrist
89
10k
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
460
Transcript
Learning to (Learn at Test Time) 東京科学大学 小島 瑞貴 RNNs
with Expressive Hidden States
2 Paper Info ICML2026
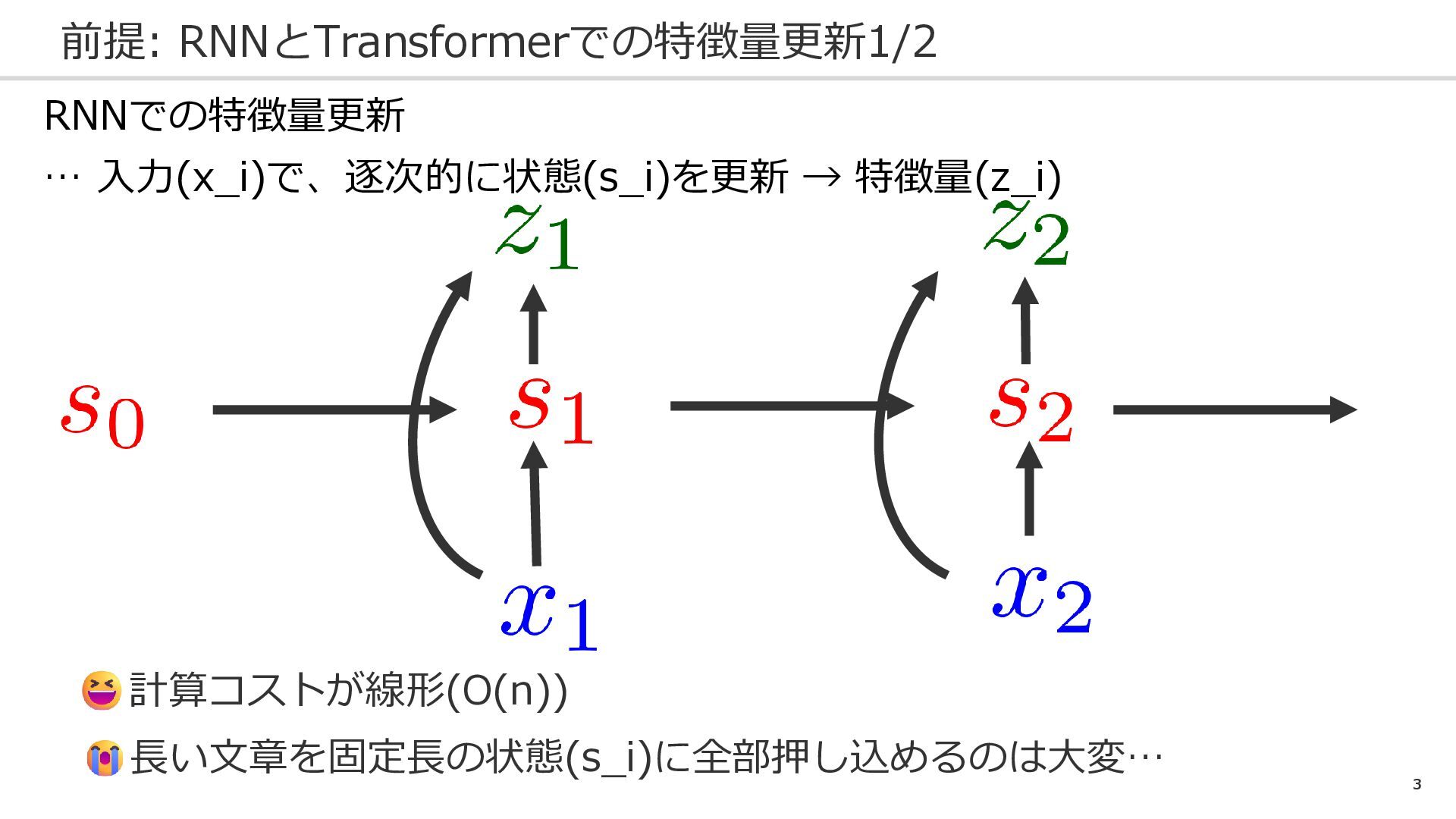
3 前提: RNNとTransformerでの特徴量更新1/2 RNNでの特徴量更新 … 入力(x_i)で、逐次的に状態(s_i)を更新 → 特徴量(z_i) 計算コストが線形(O(n)) 長い文章を固定長の状態(s_i)に全部押し込めるのは大変…
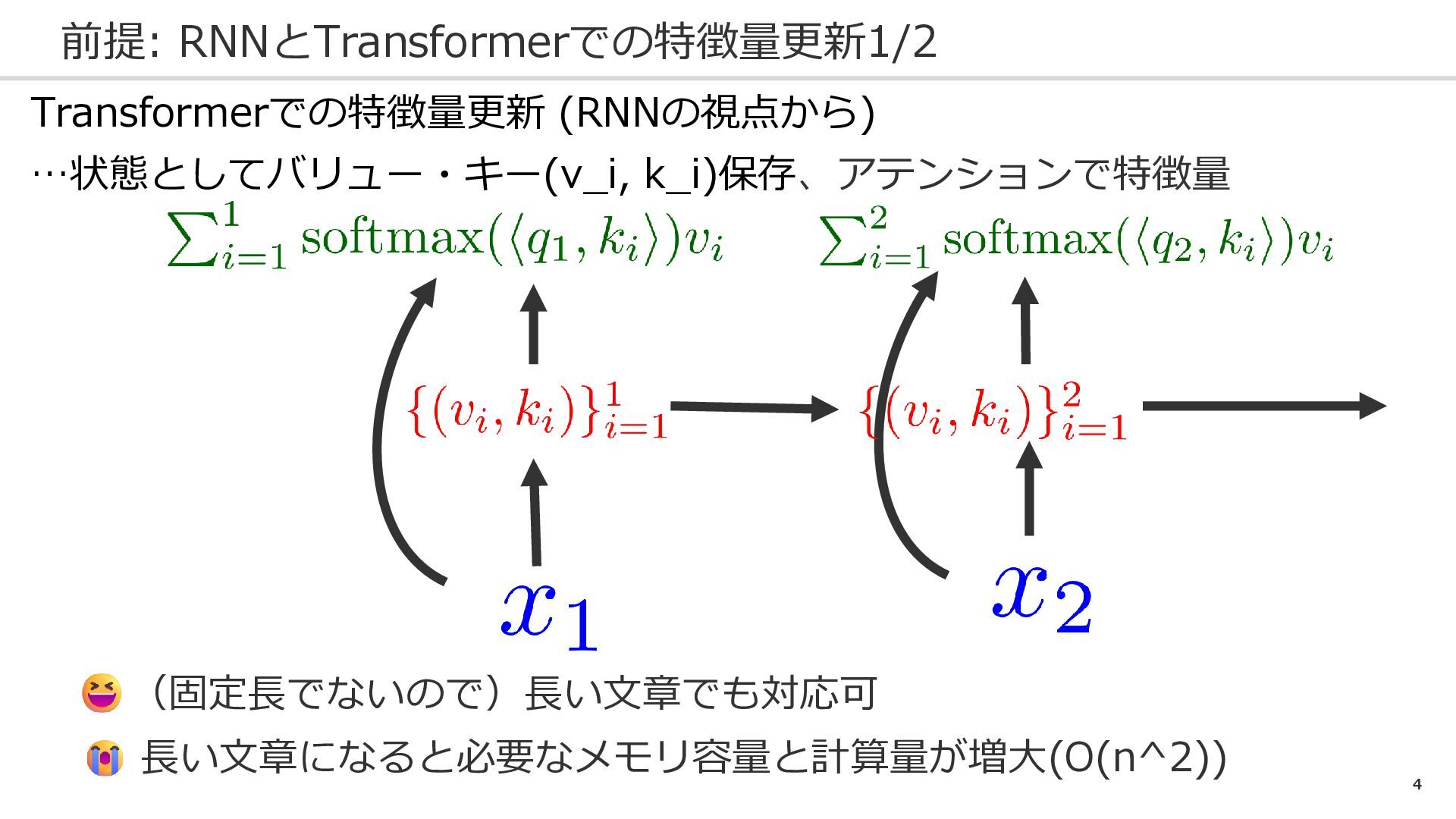
4 前提: RNNとTransformerでの特徴量更新1/2 Transformerでの特徴量更新 (RNNの視点から) …状態としてバリュー・キー(v_i, k_i)保存、アテンションで特徴量 (固定長でないので)長い文章でも対応可 長い文章になると必要なメモリ容量と計算量が増大(O(n^2))
5 問題設定・目標 RNNの性質のまま、表現能力を向上できない?? 目標は、早く推論できて、長い文章でも大丈夫で、 トークン数(や画像数)に対してO(n)なモデル!
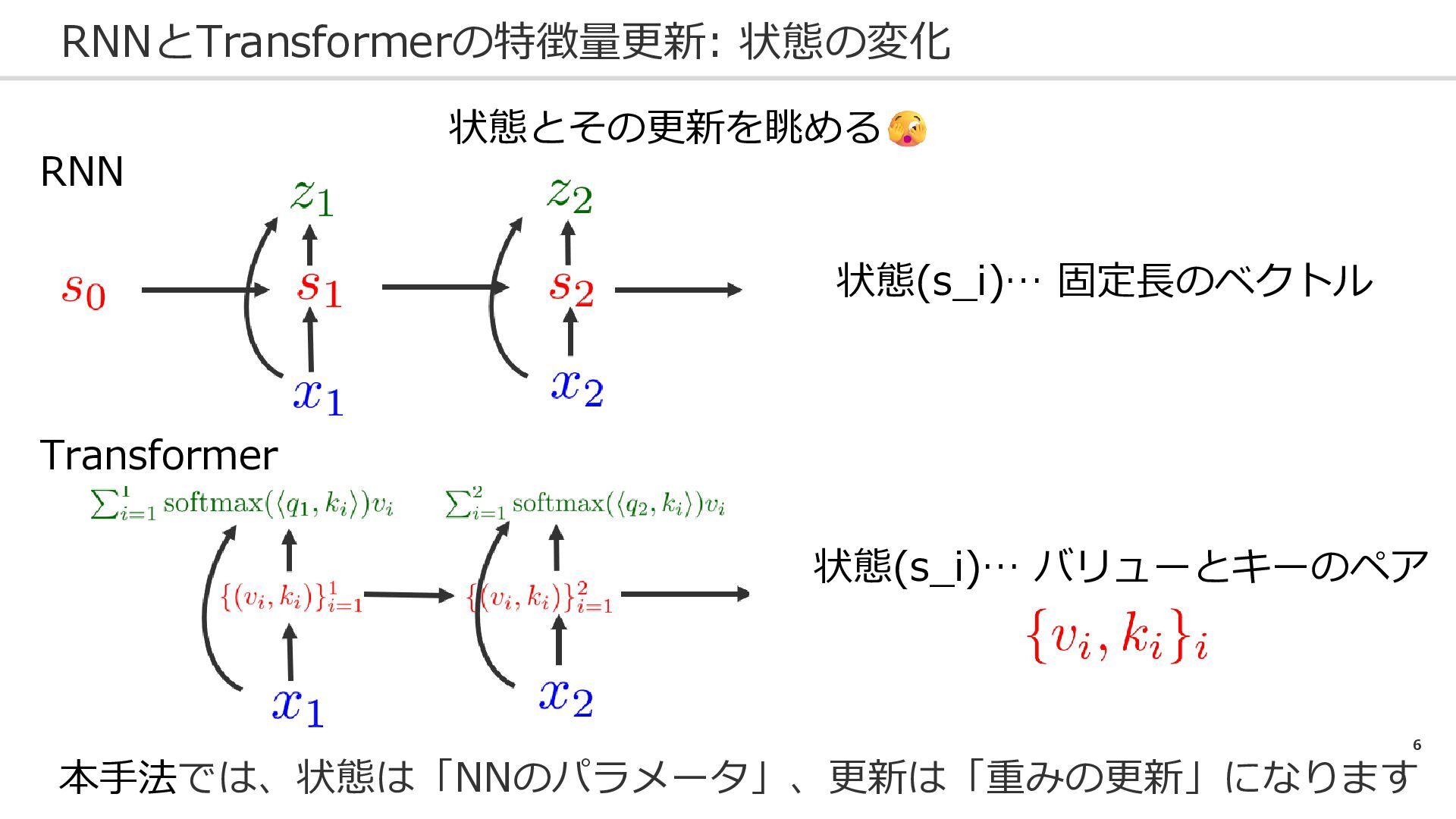
6 RNNとTransformerの特徴量更新: 状態の変化 RNN 状態とその更新を眺める 状態(s_i)… 固定長のベクトル Transformer 状態(s_i)… バリューとキーのペア
本手法では、状態は「NNのパラメータ」、更新は「重みの更新」になります
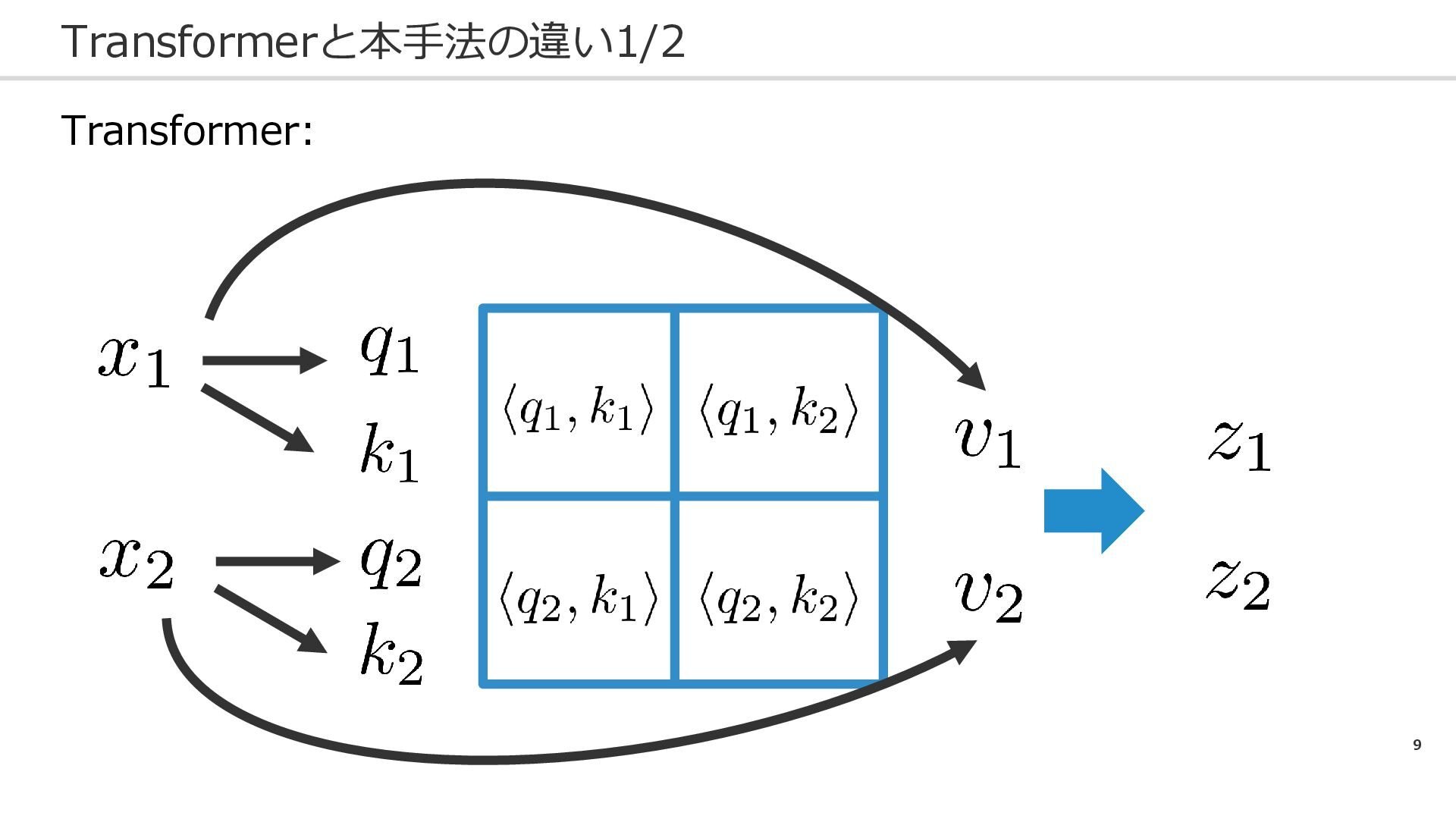
7 状態をNNで表現するのは妥当…? 1/2 目的は、Transformerの状態の圧縮 Transformer: ☛ 状態は今までのキーとバリューの保存 ☛ 特徴量はクエリqに対して、キーとの類似度によるバリューの重みづけ 本手法:
キーをバリューに結び付ける関数 を学習 ☛ 特徴量は、クエリqに対して、関数 の入力とする ☛ (入力である)キーとの類似度で、(重みづけ後の)特徴量が出てくる
8 状態をNNで表現するのは妥当…? 2/2 特別な関数: キーからバリューへの対応が「近さ」での重みつき和 (定義)2つのキー同士の「近さ」: バリューの推定:「近さ」での重みつき和 クエリqに対する出力: Attentionに一致 ☛
上記の関数を表現できれば、Transformerに一致する ☛ ただ、トークンごとに関数が動的に変化する必要あり
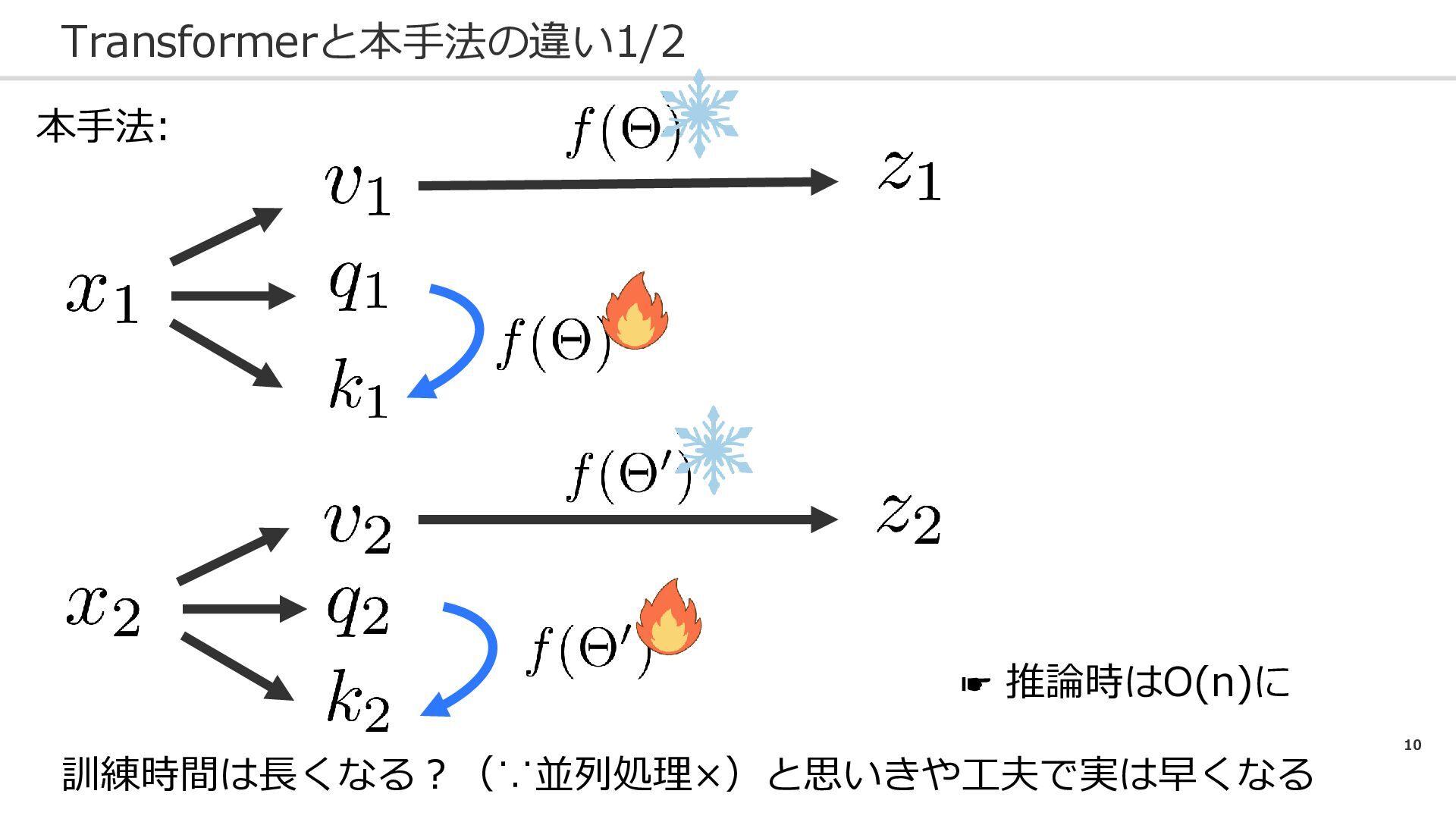
9 Transformerと本手法の違い1/2 Transformer:
10 Transformerと本手法の違い1/2 本手法: 訓練時間は長くなる?(∵並列処理×)と思いきや工夫で実は早くなる ☛ 推論時はO(n)に
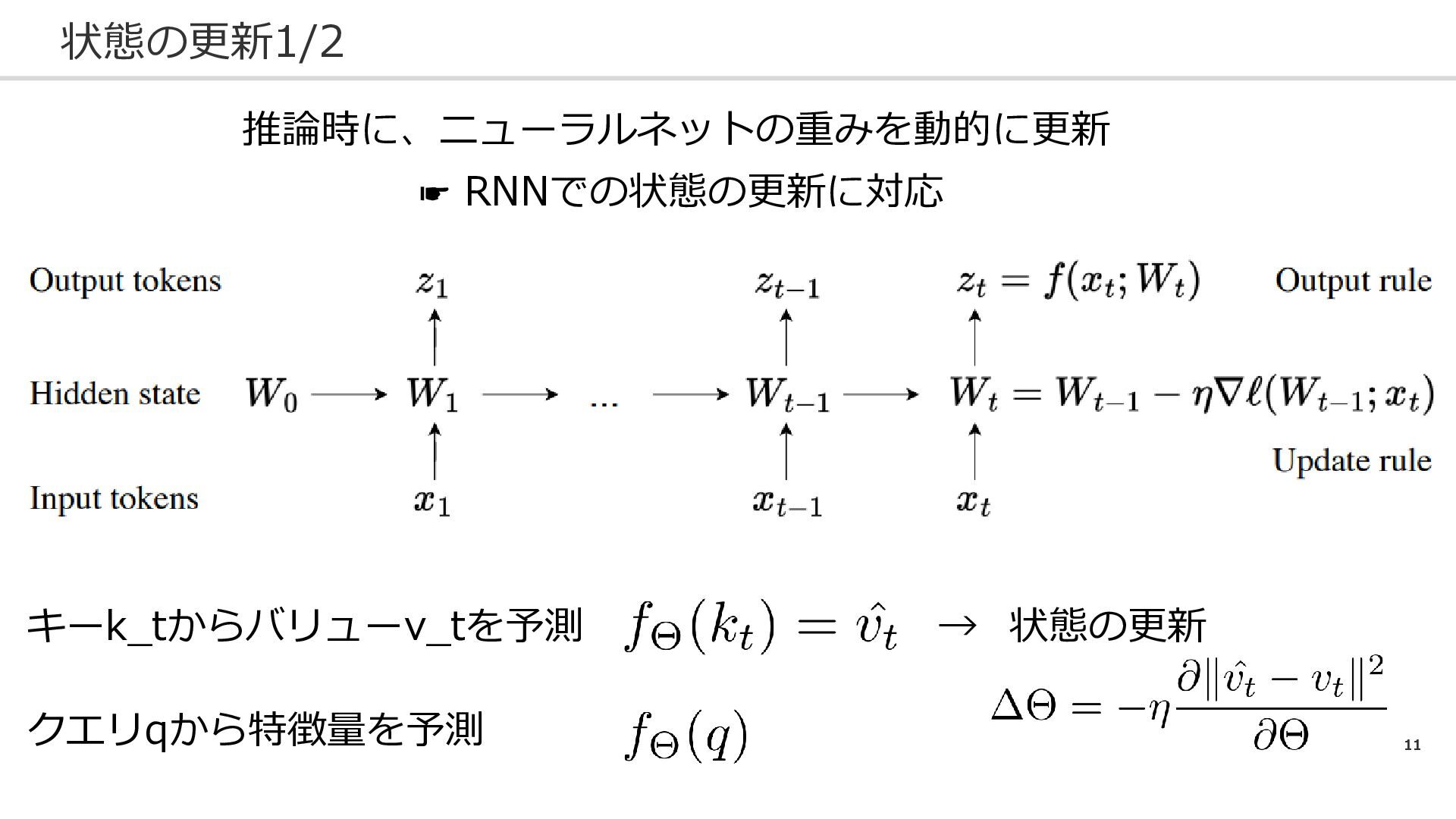
11 状態の更新1/2 推論時に、ニューラルネットの重みを動的に更新 ☛ RNNでの状態の更新に対応 キーk_tからバリューv_tを予測 → 状態の更新 クエリqから特徴量を予測
12 状態の更新2/2 特別な関数の場合: 線形写像 (パラメータはW_t) クエリqを入力: Linear Attentionに一致
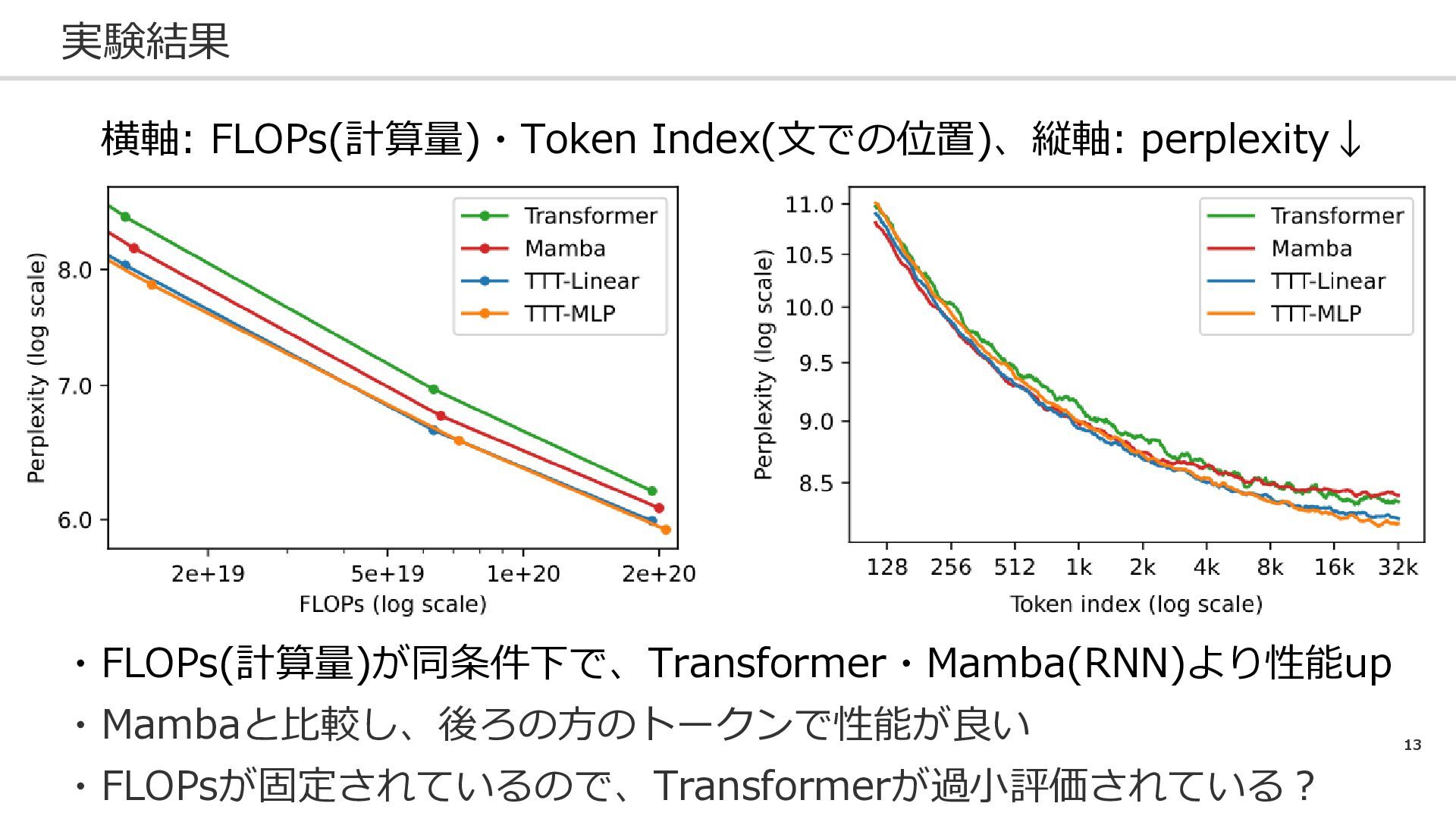
13 実験結果 ・FLOPs(計算量)が同条件下で、Transformer・Mamba(RNN)より性能up ・Mambaと比較し、後ろの方のトークンで性能が良い ・FLOPsが固定されているので、Transformerが過小評価されている? 横軸: FLOPs(計算量)・Token Index(文での位置)、縦軸: perplexity↓
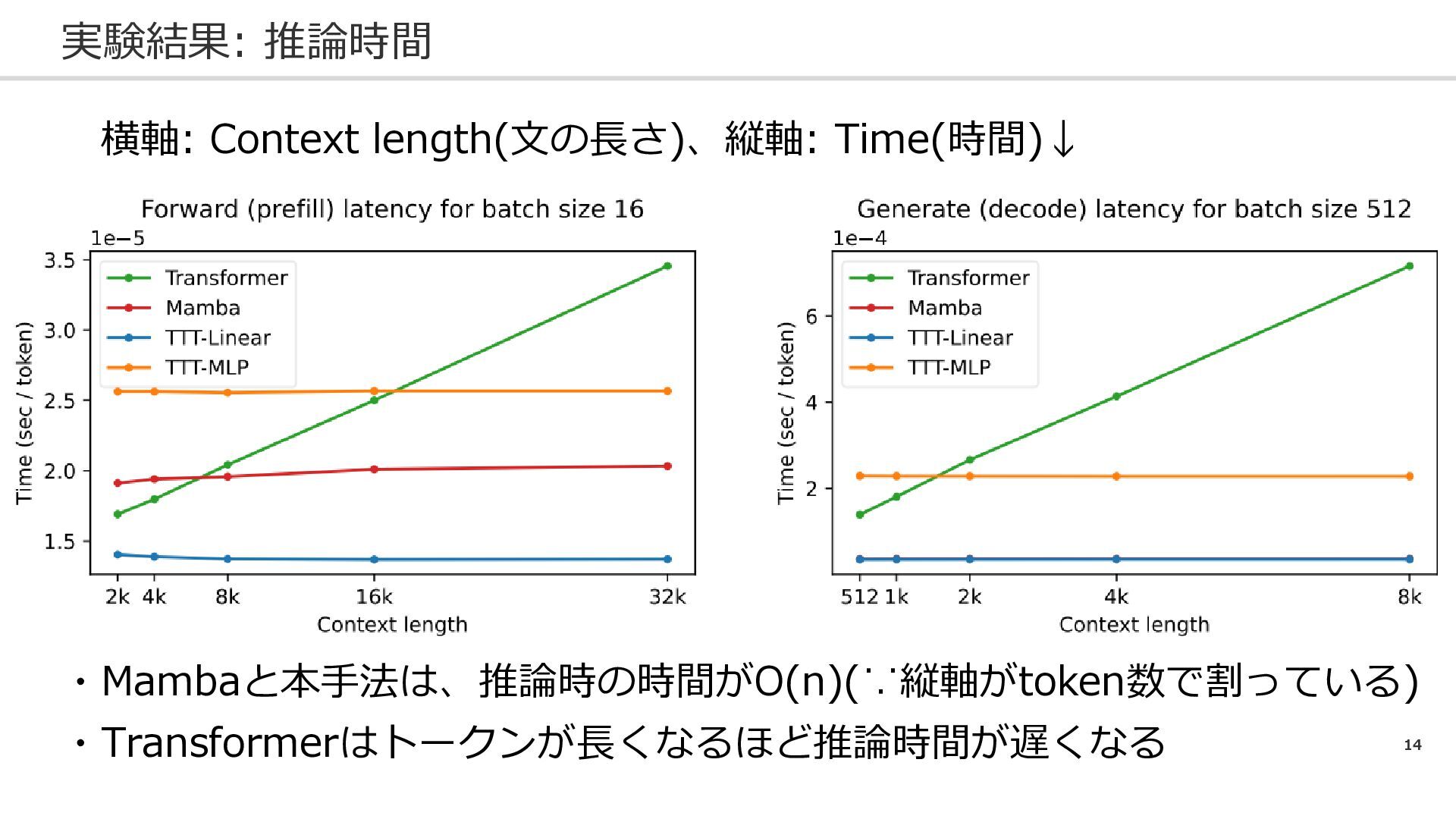
14 実験結果: 推論時間 ・Mambaと本手法は、推論時の時間がO(n)(∵縦軸がtoken数で割っている) ・Transformerはトークンが長くなるほど推論時間が遅くなる 横軸: Context length(文の長さ)、縦軸: Time(時間)↓
15 まとめ ・RNNは長い文章でも高速だが、固定ベクトルへの情報の詰め込みが大変 ・Transformerは、長い文章の情報を捉えられるが、推論時間・必要メモリ↑ ・本手法の目的は、O(n)で、RNNより表現力高く長い文章の情報を捉える ・キーとバリューの関係をNNで動的に捉える、クエリを入れて特徴量が出る ・この枠組みで、AttentionやLinear Attentionの枠組みを説明可能
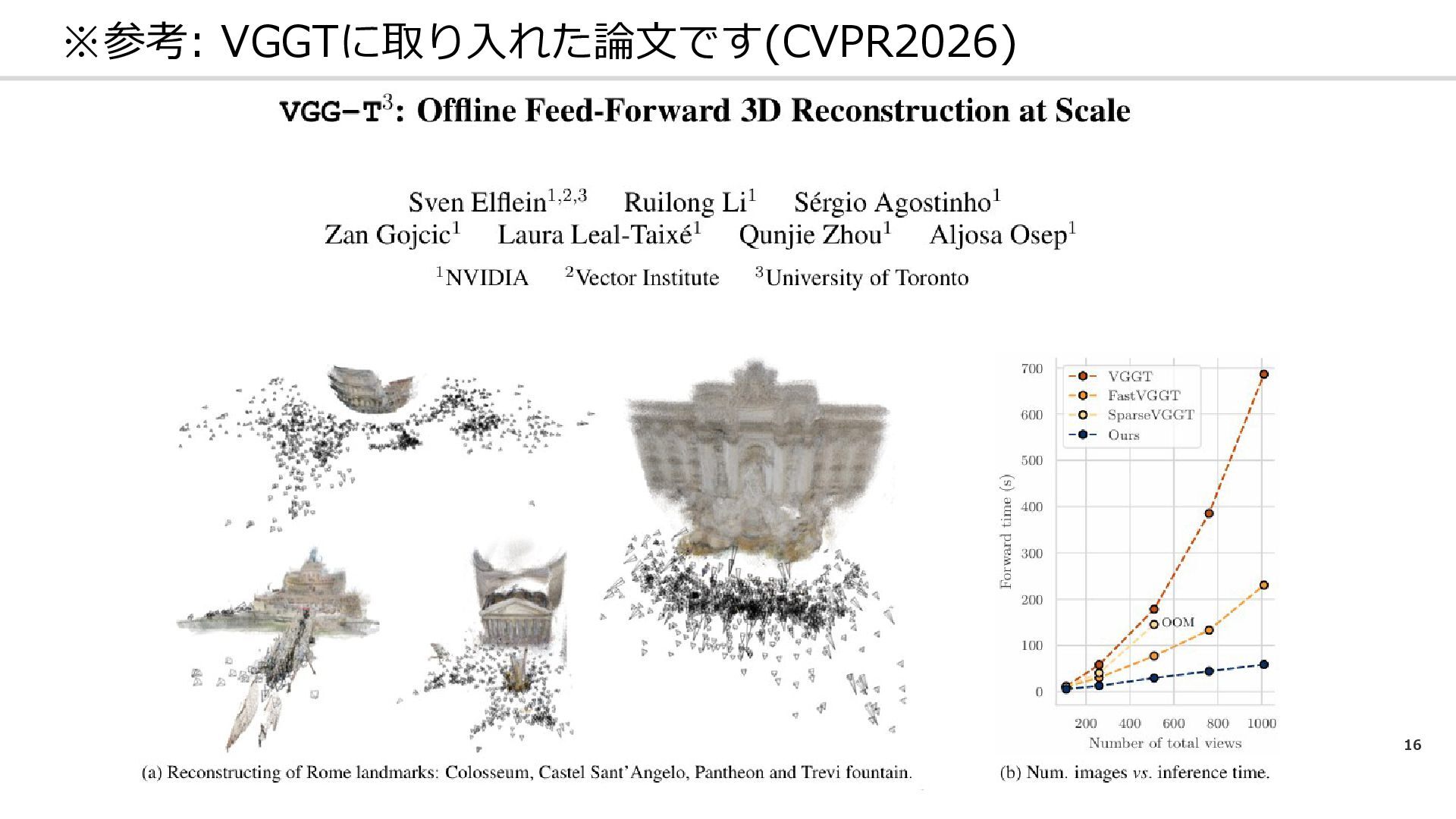
16 ※参考: VGGTに取り入れた論文です(CVPR2026)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}