Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
動画生成と三次元生成を融合して最強の生成モデルを作ろう
Search
小島瑞貴
June 01, 2026
Science
49
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
動画生成と三次元生成を融合して最強の生成モデルを作ろう
小島瑞貴
June 01, 2026
More Decks by 小島瑞貴
See All by 小島瑞貴
【Zozo Research 技術共有会】三次元領域の現在と展望
mickey_0226
3
460
学術バーQってどんなところ??
mickey_0226
0
120
さわって動かす人工知能
mickey_0226
0
54
CVPR2026_VGGTとその仲間たち
mickey_0226
0
960
Transformerの推論を線形時間にして皆を驚かせましょう
mickey_0226
0
47
Other Decks in Science
See All in Science
20260410_SystemsThinking
takusamar
1
110
明治薬科大学講義_ビッグデータ解析を支えるデータベース技術とクラウドコンピューティング
ktatsuya
1
130
なぜエネルギーは保存する? 〜自由落下でわかる“対称性”とネーターの定理〜
syotasasaki593876
0
210
「念のためのログ保存」を組織全体でやめるためのポリシーと仕組み作り
i2tsuki
4
230
水耕栽培を始める前に知っておきたい植物の科学
grow_design_lab
0
270
Kritische evaluatie van GenAI-output voor literatuuronderzoek
voginip
0
190
AI bij literatuuronderzoek in de wetenschap
voginip
0
210
Build your own LLM, Live, with MicroGPT
ianozsvald
0
100
データベース10: 拡張実体関連モデル
trycycle
PRO
0
1.2k
AI(人工知能)の過去・現在・未来 ~AIは人類を越えるのか~
tagtag
PRO
0
120
20251212_LT忘年会_データサイエンス枠_新川.pdf
shinpsan
0
300
【論文紹介】Is CLIP ideal? No. Can we fix it?Yes! 第65回 コンピュータビジョン勉強会@関東
shun6211
5
2.5k
Featured
See All Featured
CoffeeScript is Beautiful & I Never Want to Write Plain JavaScript Again
sstephenson
162
16k
Building Experiences: Design Systems, User Experience, and Full Site Editing
marktimemedia
0
550
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
490
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
270
Site-Speed That Sticks
csswizardry
13
1.2k
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
SEO Brein meetup: CTRL+C is not how to scale international SEO
lindahogenes
1
2.8k
The Mindset for Success: Future Career Progression
greggifford
PRO
0
410
How to train your dragon (web standard)
notwaldorf
97
6.7k
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
180
Sam Torres - BigQuery for SEOs
techseoconnect
PRO
0
300
Mind Mapping
helmedeiros
PRO
1
280
Transcript
Vist3A 東京科学大学 小島 瑞貴 Text-to-3D by stitching a multi-view reconstruction
network to a video generator
2 問題設定: 文章からの3次元生成 難しさ: 3次元データとテキストのペアの正解データを大量に作るのは困難…
3 分野のトレンド❶: 文章からの映像生成 説明文章に沿った映像を生成できる 3次元的に一貫した映像の生成が難しい 例: オールが途中で消えたりする
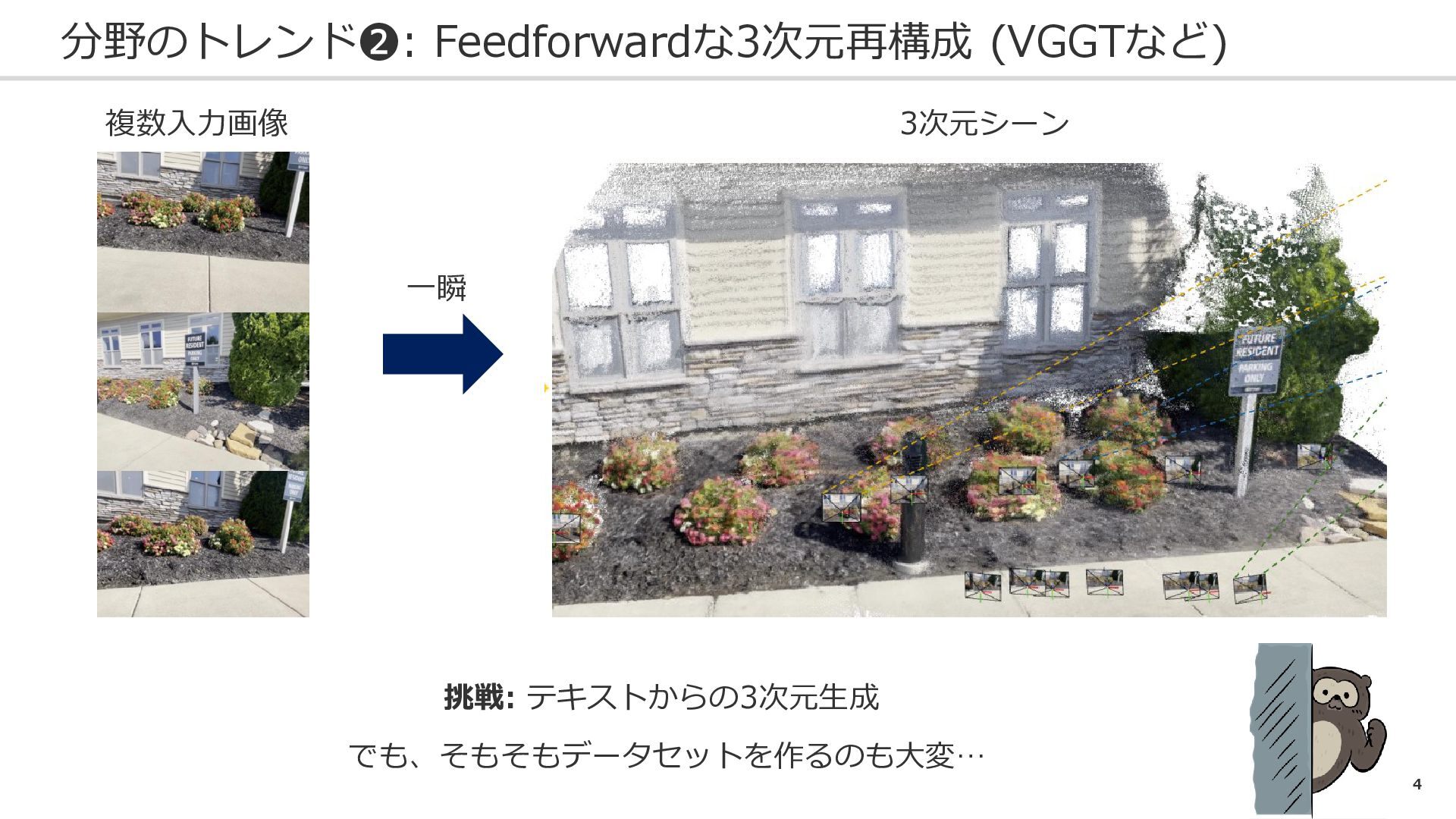
4 分野のトレンド❷: Feedforwardな3次元再構成 (VGGTなど) 複数入力画像 3次元シーン 一瞬 挑戦: テキストからの3次元生成 でも、そもそもデータセットを作るのも大変…
5 アプローチ (概要) 映像生成モデル VGGT テキスト 動画 画像たち 3次元 2つの手法を合わせて、最強のモデルを作ろう!!
でも、構造的に全然違くない…??? → 「創造的」な「3次元生成モデル」が構築
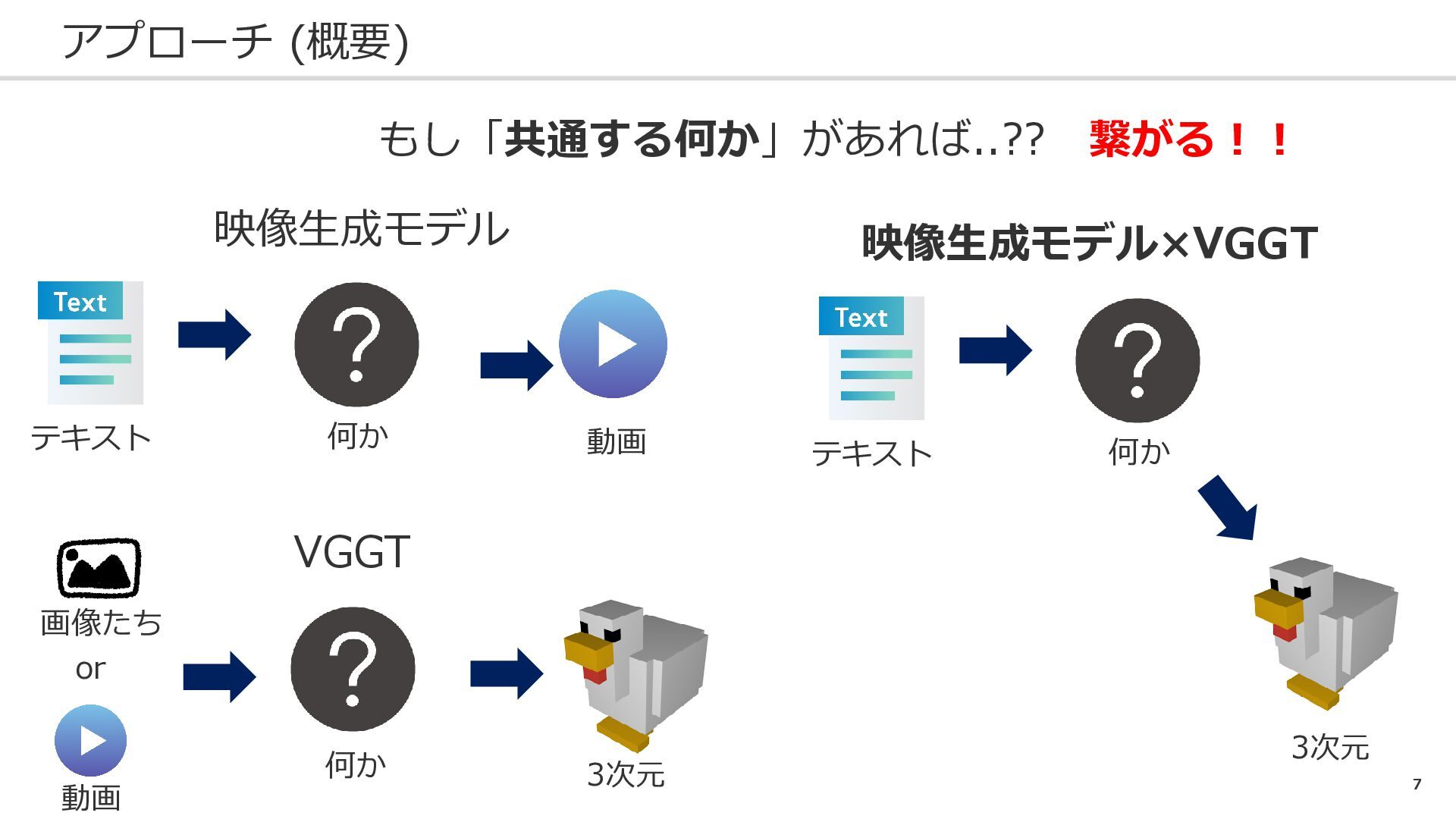
6 アプローチ (概要) 映像生成モデル VGGT テキスト 動画 3次元 もし「共通する何か」があれば..?? 何か
何か 画像たち or 動画
7 アプローチ (概要) 映像生成モデル VGGT テキスト 動画 画像たち 3次元 もし「共通する何か」があれば..??
繋がる!! 何か 何か テキスト 何か 3次元 映像生成モデル×VGGT or 動画
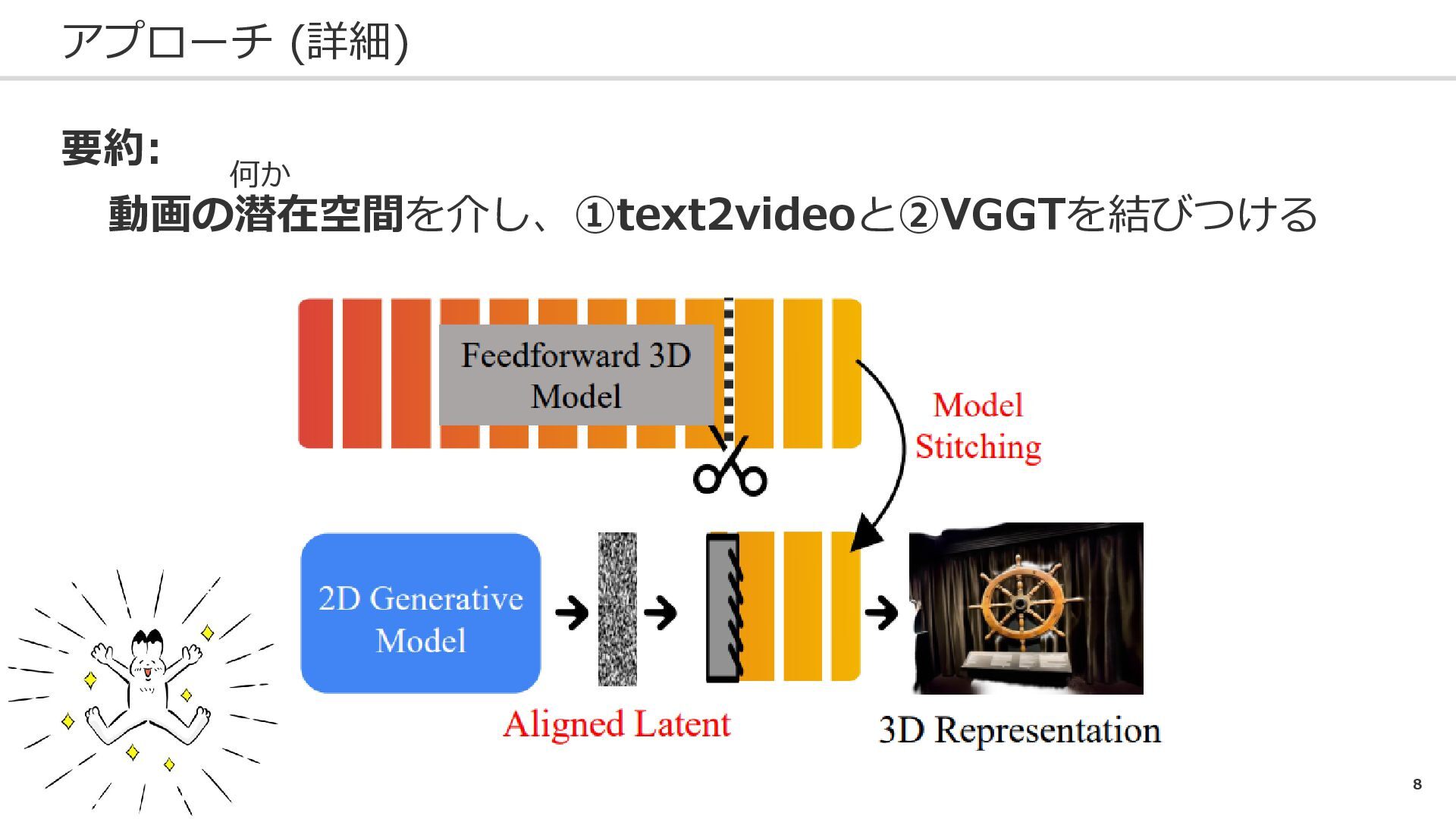
8 アプローチ (詳細) 要約: 動画の潜在空間を介し、①text2videoと②VGGTを結びつける 何か
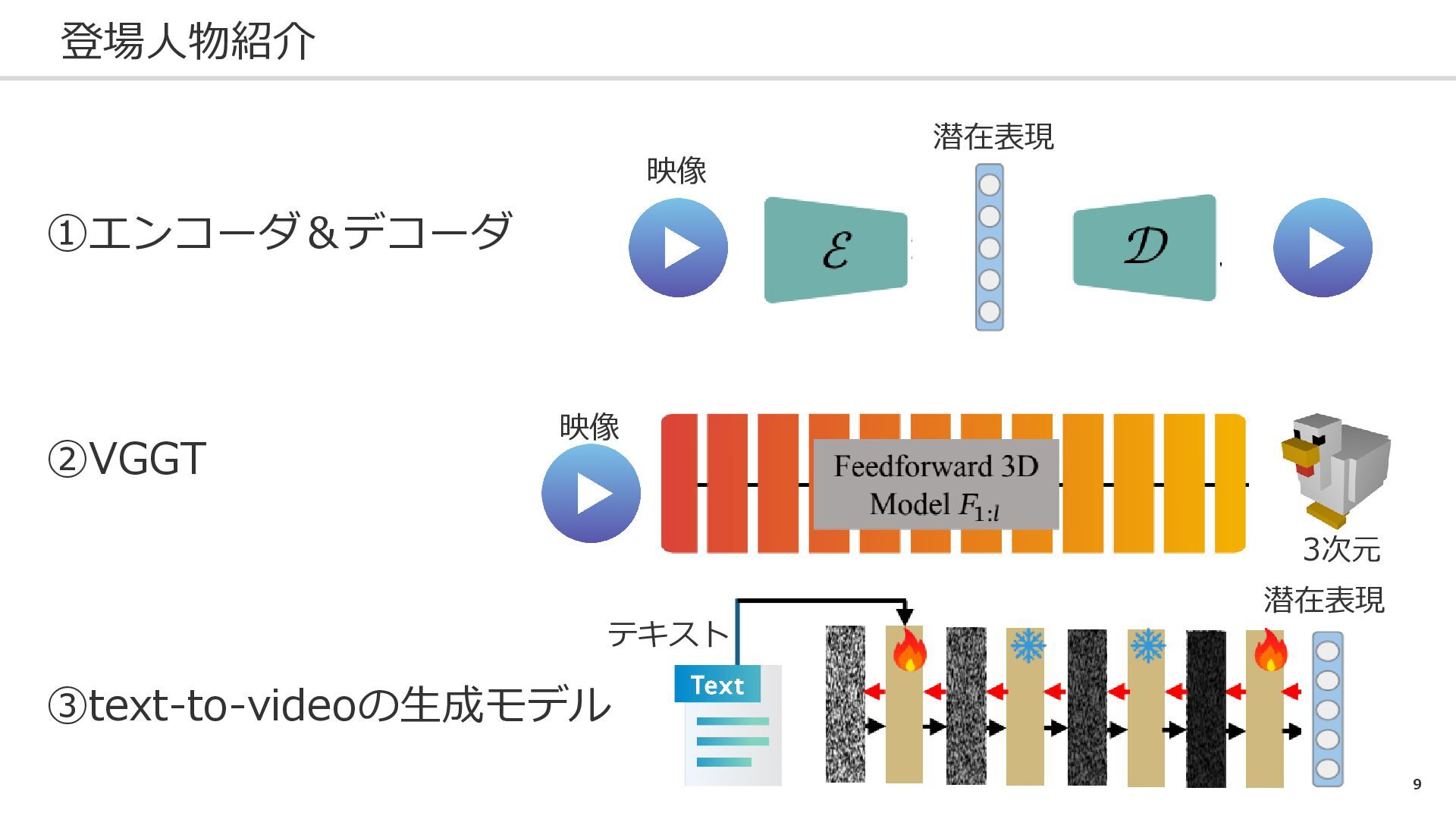
9 登場人物紹介 ①エンコーダ&デコーダ ②VGGT ③text-to-videoの生成モデル 潜在表現 映像 テキスト 潜在表現 映像
3次元
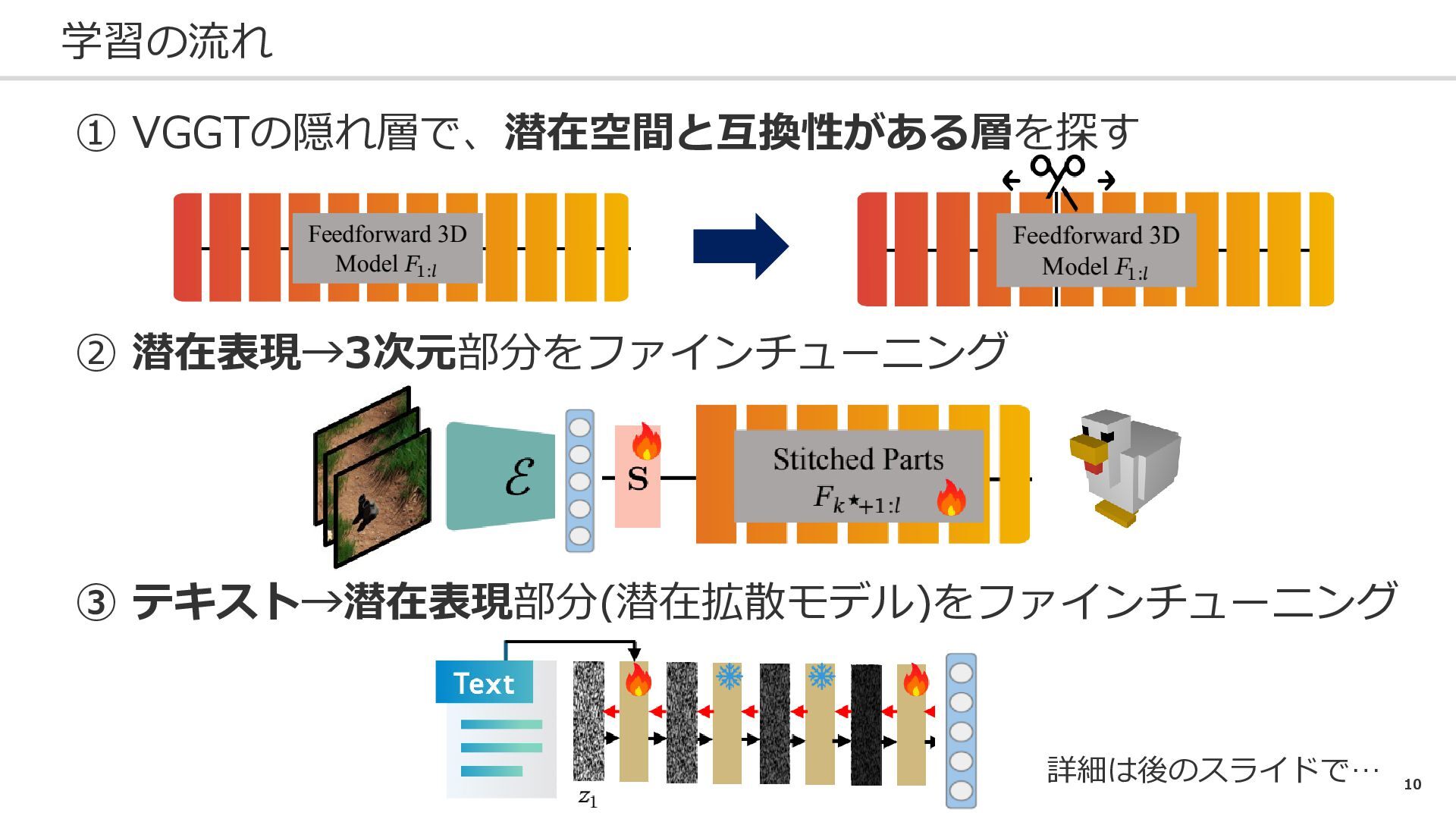
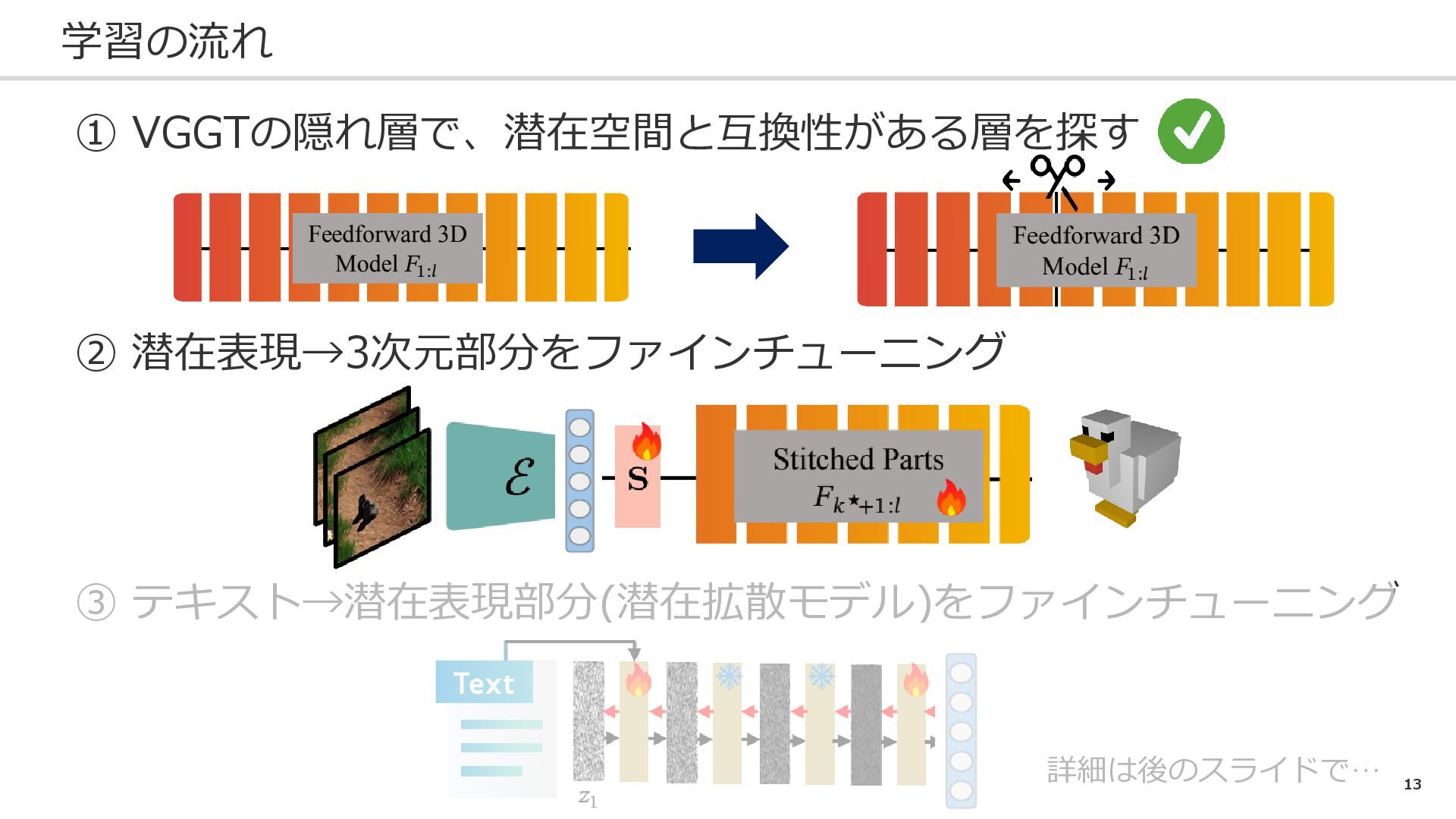
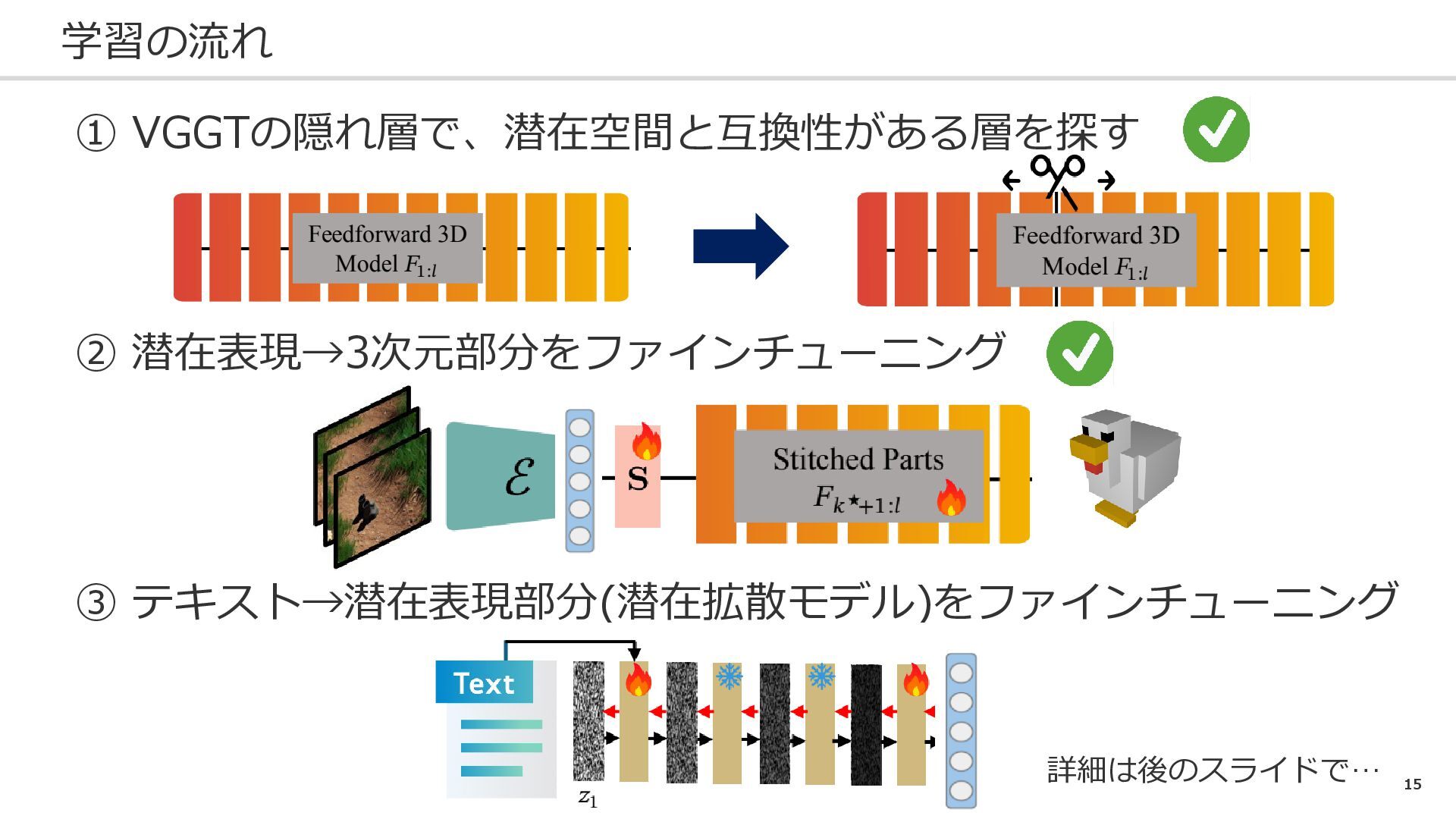
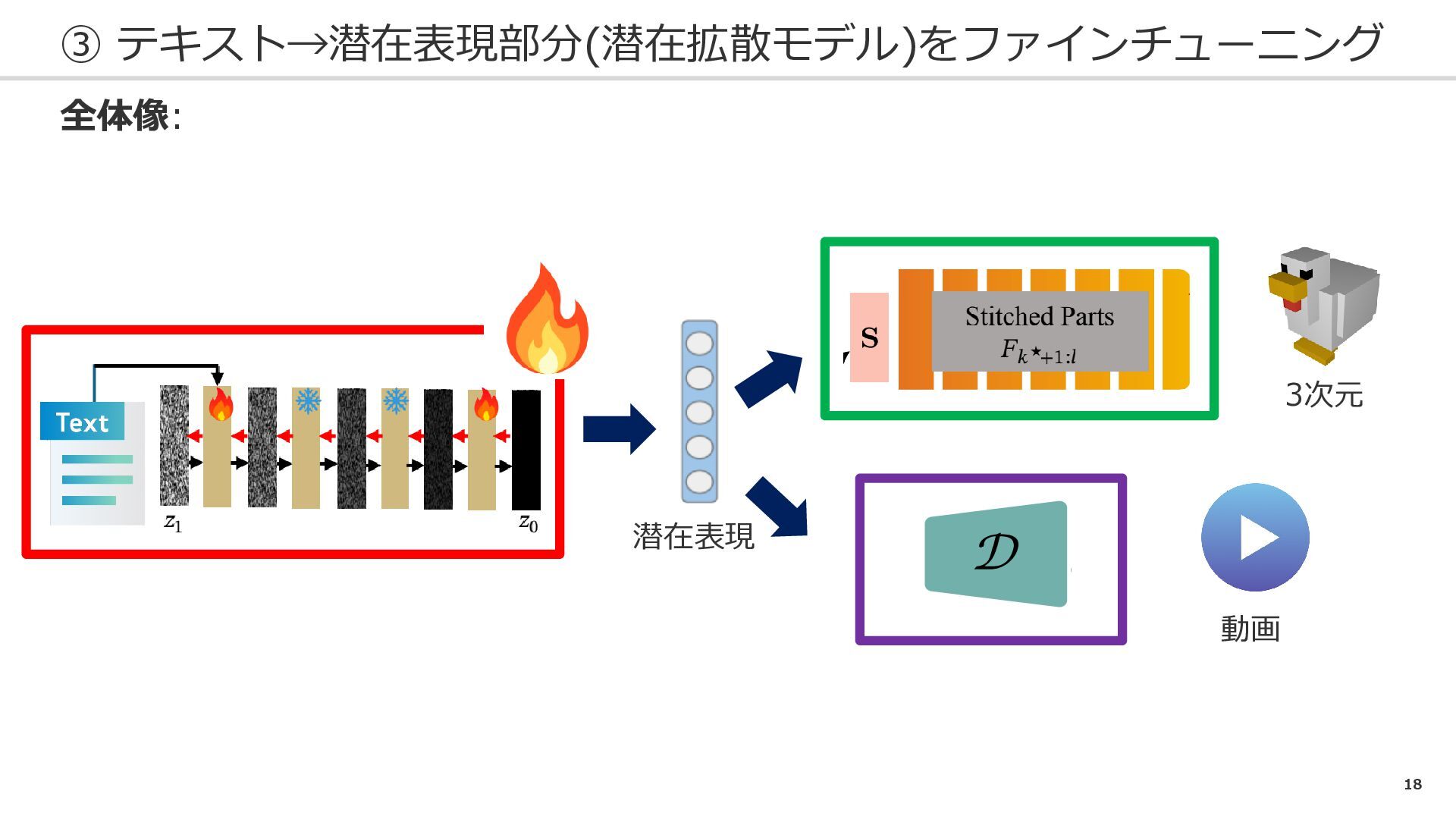
10 学習の流れ ① VGGTの隠れ層で、潜在空間と互換性がある層を探す ② 潜在表現→3次元部分をファインチューニング ③ テキスト→潜在表現部分(潜在拡散モデル)をファインチューニング 詳細は後のスライドで…
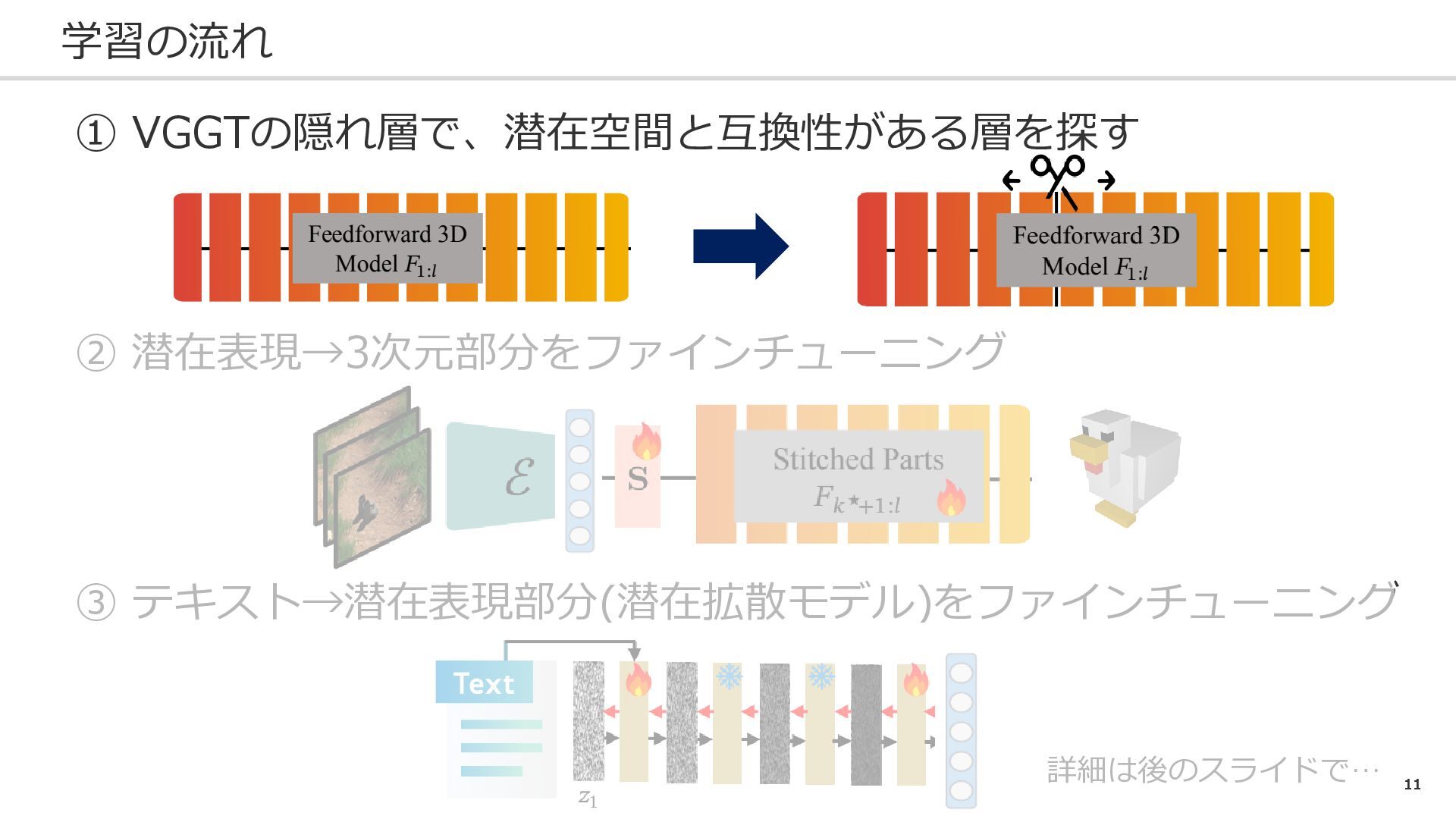
11 学習の流れ ① VGGTの隠れ層で、潜在空間と互換性がある層を探す ② 潜在表現→3次元部分をファインチューニング ③ テキスト→潜在表現部分(潜在拡散モデル)をファインチューニング 詳細は後のスライドで…
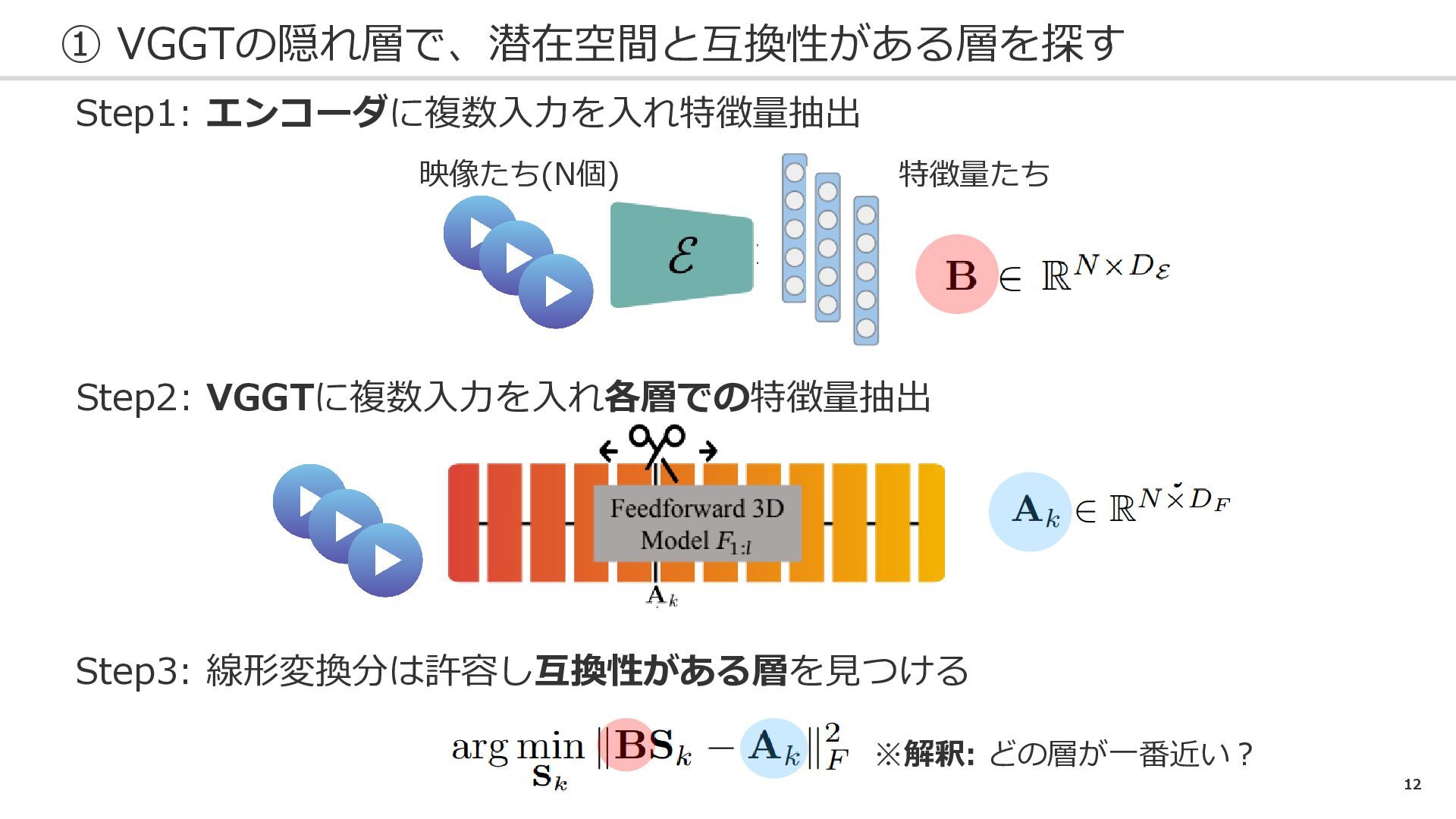
12 ① VGGTの隠れ層で、潜在空間と互換性がある層を探す Step1: エンコーダに複数入力を入れ特徴量抽出 映像たち(N個) 特徴量たち Step2: VGGTに複数入力を入れ各層での特徴量抽出 Step3:
線形変換分は許容し互換性がある層を見つける ※解釈: どの層が一番近い?
13 学習の流れ ① VGGTの隠れ層で、潜在空間と互換性がある層を探す ② 潜在表現→3次元部分をファインチューニング ③ テキスト→潜在表現部分(潜在拡散モデル)をファインチューニング 詳細は後のスライドで…
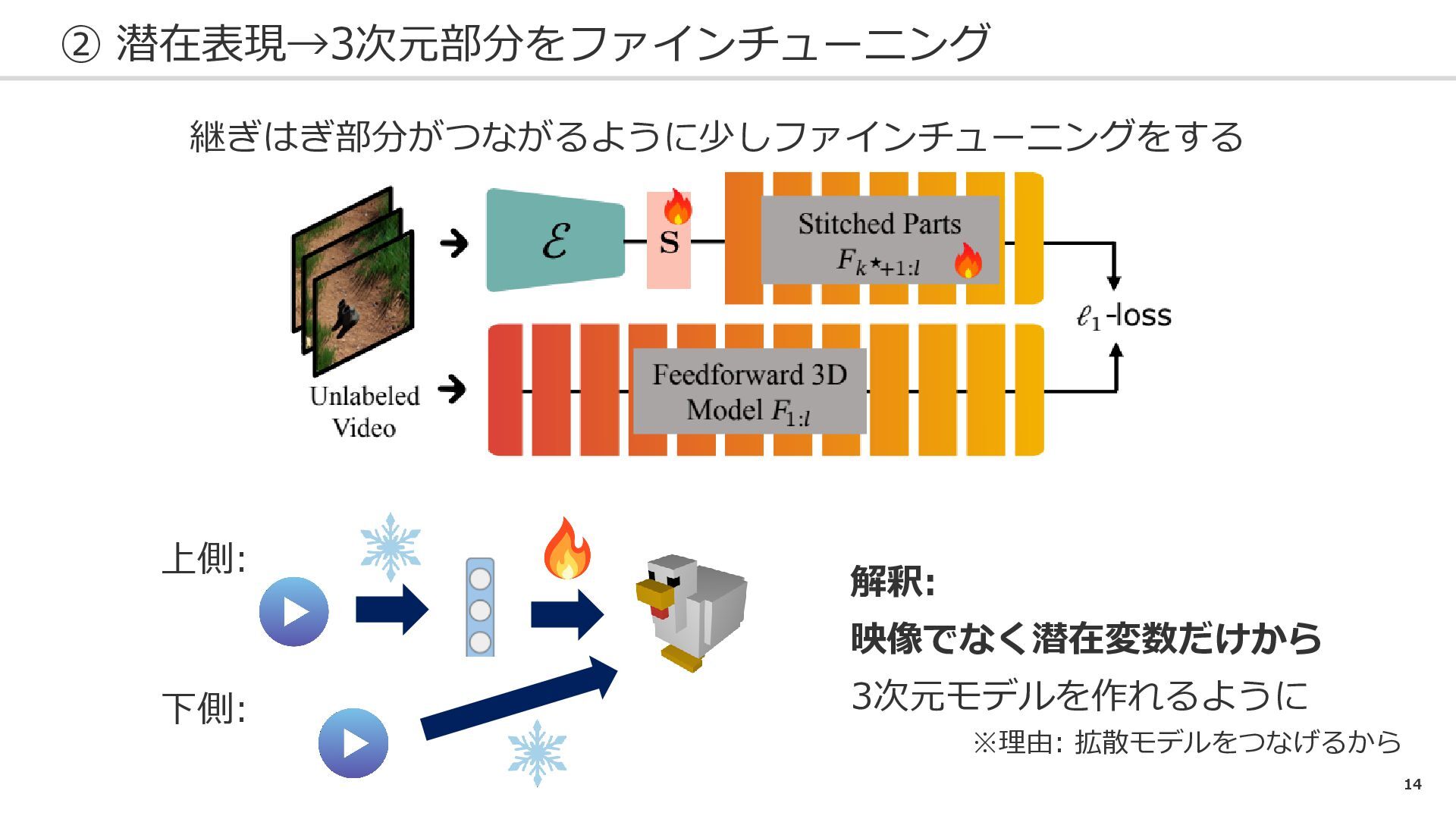
14 ② 潜在表現→3次元部分をファインチューニング 上側: 下側: 継ぎはぎ部分がつながるように少しファインチューニングをする 解釈: 映像でなく潜在変数だけから 3次元モデルを作れるように ※理由:
拡散モデルをつなげるから
15 学習の流れ ① VGGTの隠れ層で、潜在空間と互換性がある層を探す ② 潜在表現→3次元部分をファインチューニング ③ テキスト→潜在表現部分(潜在拡散モデル)をファインチューニング 詳細は後のスライドで…
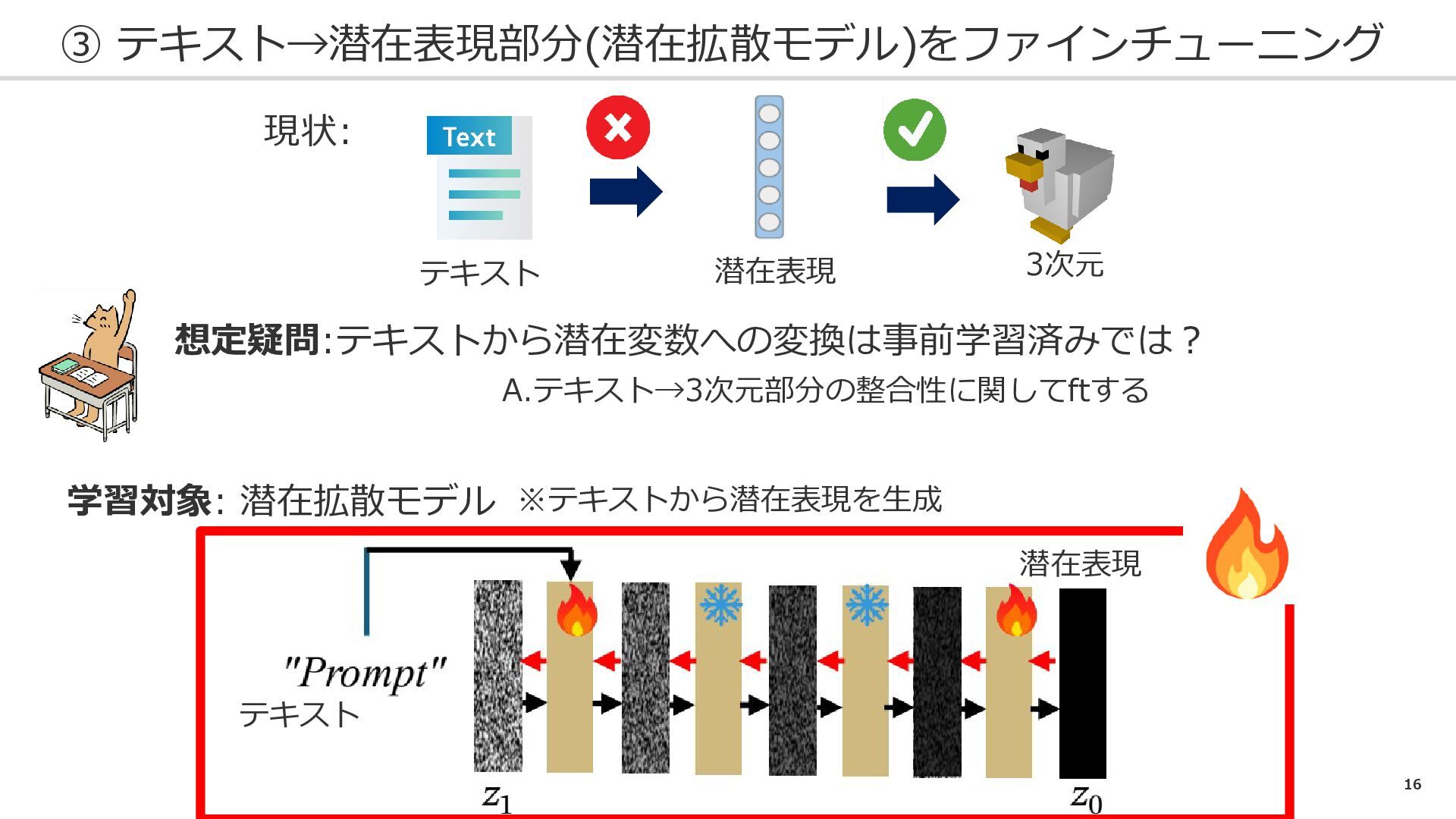
16 ③ テキスト→潜在表現部分(潜在拡散モデル)をファインチューニング 現状: テキスト 潜在表現 3次元 学習対象: 潜在拡散モデル ※テキストから潜在表現を生成
潜在表現 テキスト 想定疑問:テキストから潜在変数への変換は事前学習済みでは? A.テキスト→3次元部分の整合性に関してftする
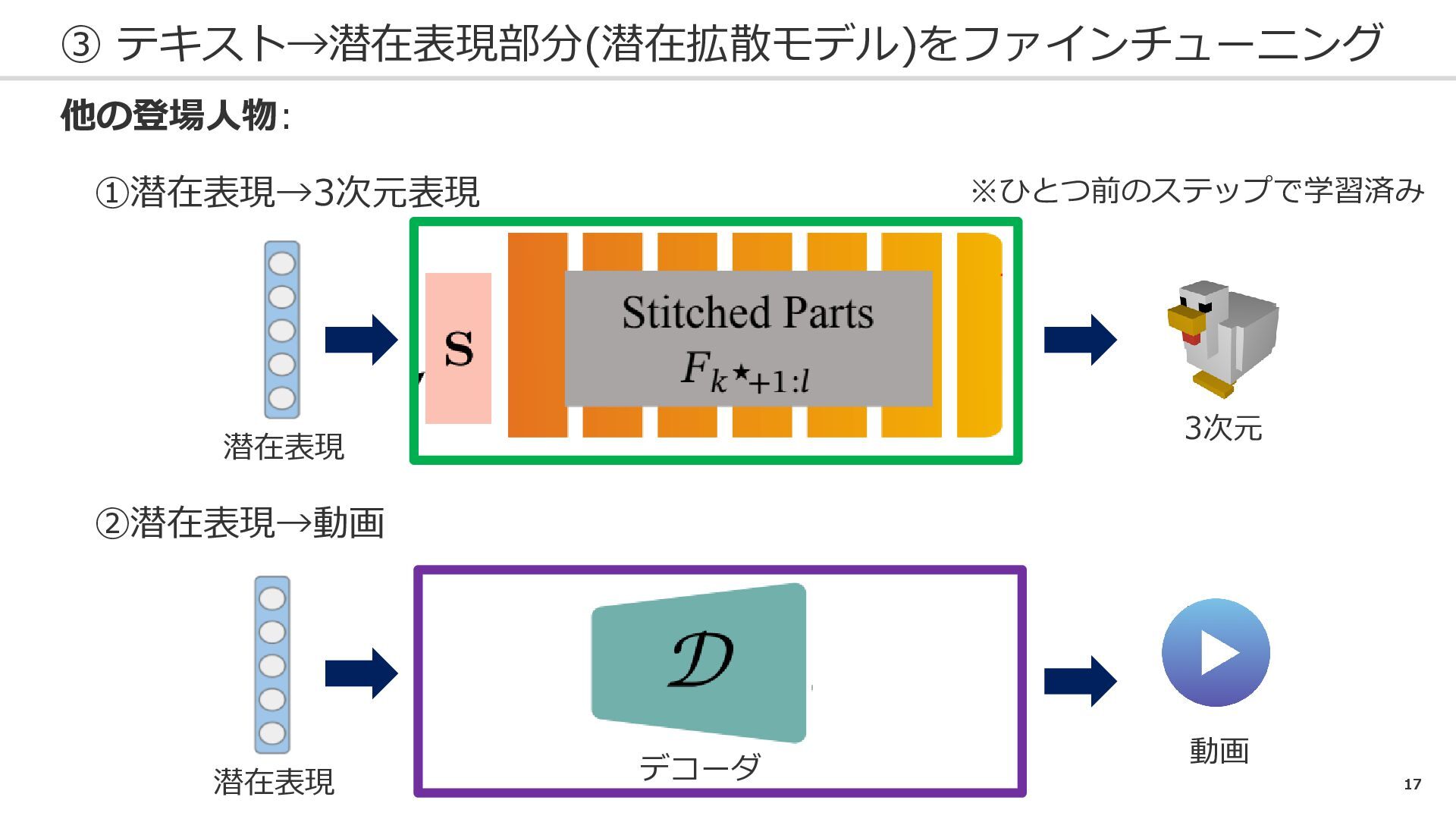
17 ③ テキスト→潜在表現部分(潜在拡散モデル)をファインチューニング 他の登場人物: ①潜在表現→3次元表現 潜在表現 3次元 ※ひとつ前のステップで学習済み ②潜在表現→動画 潜在表現
デコーダ 動画
18 ③ テキスト→潜在表現部分(潜在拡散モデル)をファインチューニング 全体像: 潜在表現 3次元 動画
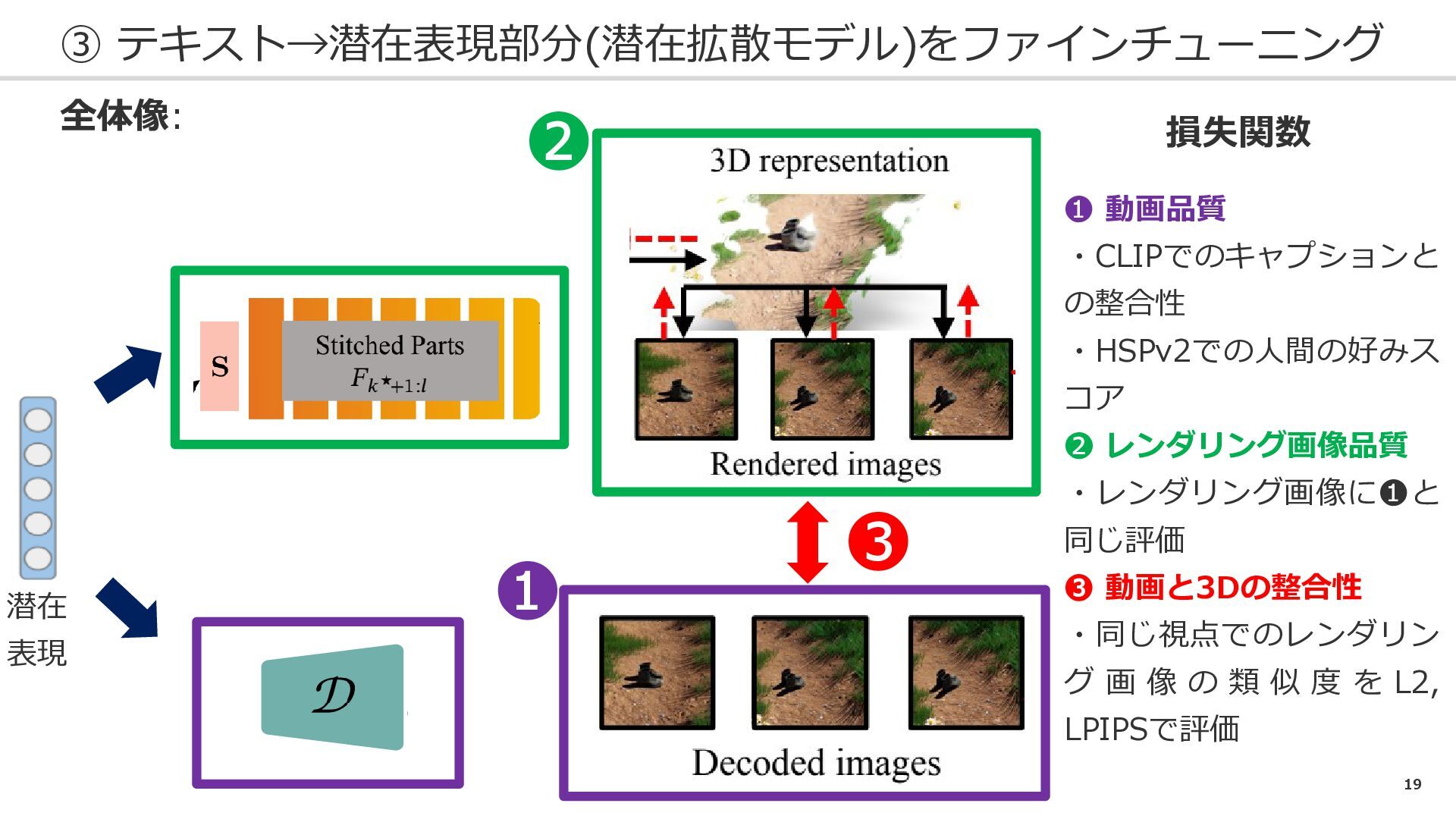
19 ③ テキスト→潜在表現部分(潜在拡散モデル)をファインチューニング 全体像: 損失関数 ❶ 動画品質 ・CLIPでのキャプションと の整合性 ・HSPv2での人間の好みス
コア ❷ レンダリング画像品質 ・レンダリング画像に❶と 同じ評価 ❸ 動画と3Dの整合性 ・同じ視点でのレンダリン グ 画 像 の 類 似 度 を L2, LPIPSで評価 ❶ ❷ ❸ 潜在 表現
20 先行研究との定性比較① Director3D Splatflow Prometheus3D VideoRFSplat Splatflow
21 先行研究との定性比較② Director3D Splatflow Prometheus3D VideoRFSplat Vist3A
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}