Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
CVPR2026_VGGTとその仲間たち
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
小島瑞貴
May 30, 2026
Science
960
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
CVPR2026_VGGTとその仲間たち
小島瑞貴
May 30, 2026
More Decks by 小島瑞貴
See All by 小島瑞貴
【Zozo Research 技術共有会】三次元領域の現在と展望
mickey_0226
3
460
学術バーQってどんなところ??
mickey_0226
0
120
さわって動かす人工知能
mickey_0226
0
54
動画生成と三次元生成を融合して最強の生成モデルを作ろう
mickey_0226
0
49
Transformerの推論を線形時間にして皆を驚かせましょう
mickey_0226
0
47
Other Decks in Science
See All in Science
Build your own LLM, Live, with MicroGPT
ianozsvald
0
100
Physical AIを支えるWeights & Biases
olachinkei
1
410
データベース03: 関係データモデル
trycycle
PRO
1
590
Inside the Mind of an LLM
baggiponte
0
200
見上公一.pdf
genomethica
0
160
Kritische evaluatie van GenAI-output voor literatuuronderzoek
voginip
0
190
YouTubeにおける撤回論文の参照実態 / metascience-meetup2026
corgies
3
300
Distributional Regression
tackyas
0
550
機械学習 - 決定木からはじめる機械学習
trycycle
PRO
0
1.5k
Conwayの法則を"ちゃんと"使うために — 原典でConwayは何を言っていたのか
bonotake
9
5k
明治薬科大学講義_ビッグデータ解析を支えるデータベース技術とクラウドコンピューティング
ktatsuya
1
130
AkarengaLT vol.40
hashimoto_kei
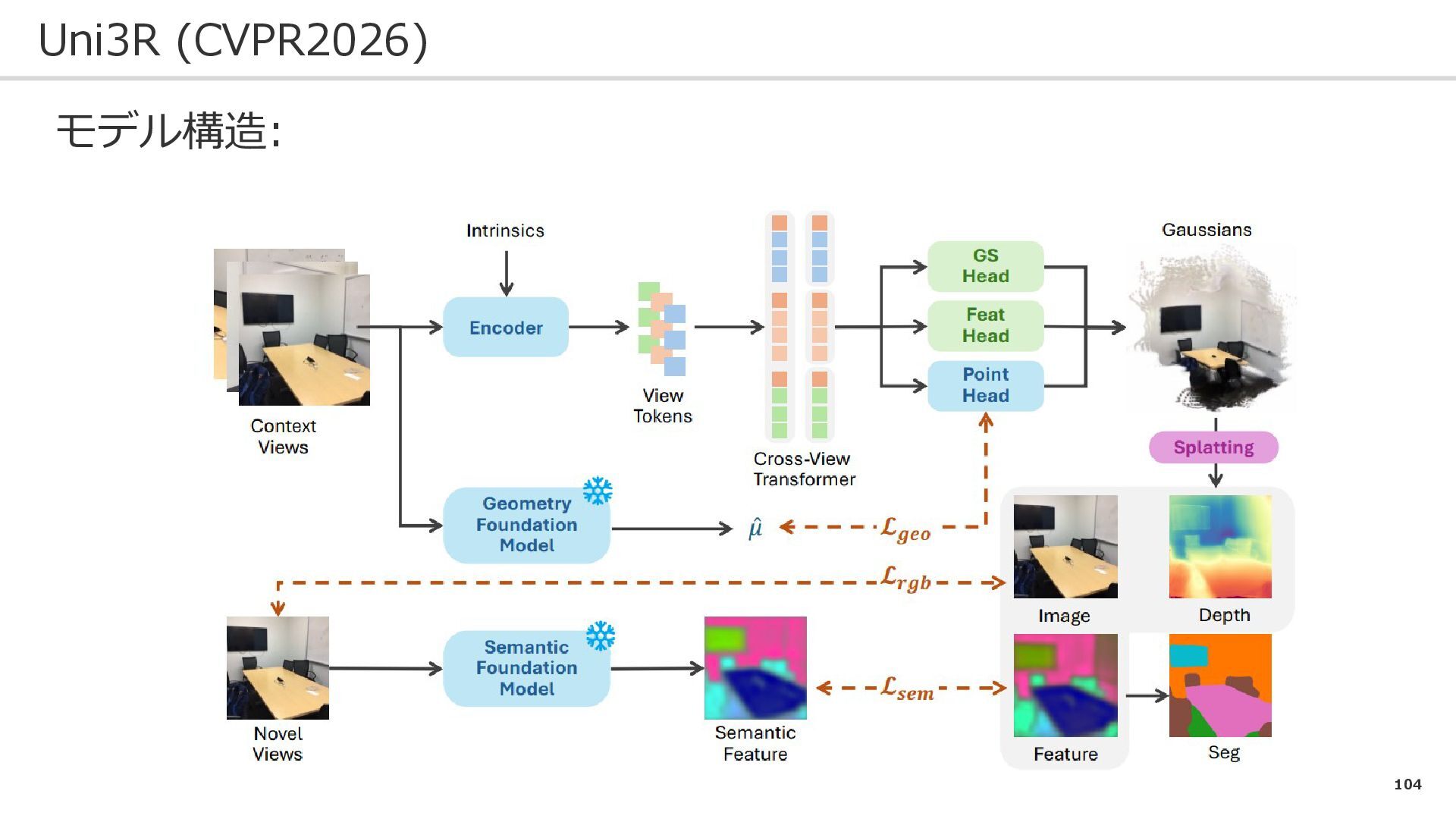
0
110
Featured
See All Featured
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
360
Performance Is Good for Brains [We Love Speed 2024]
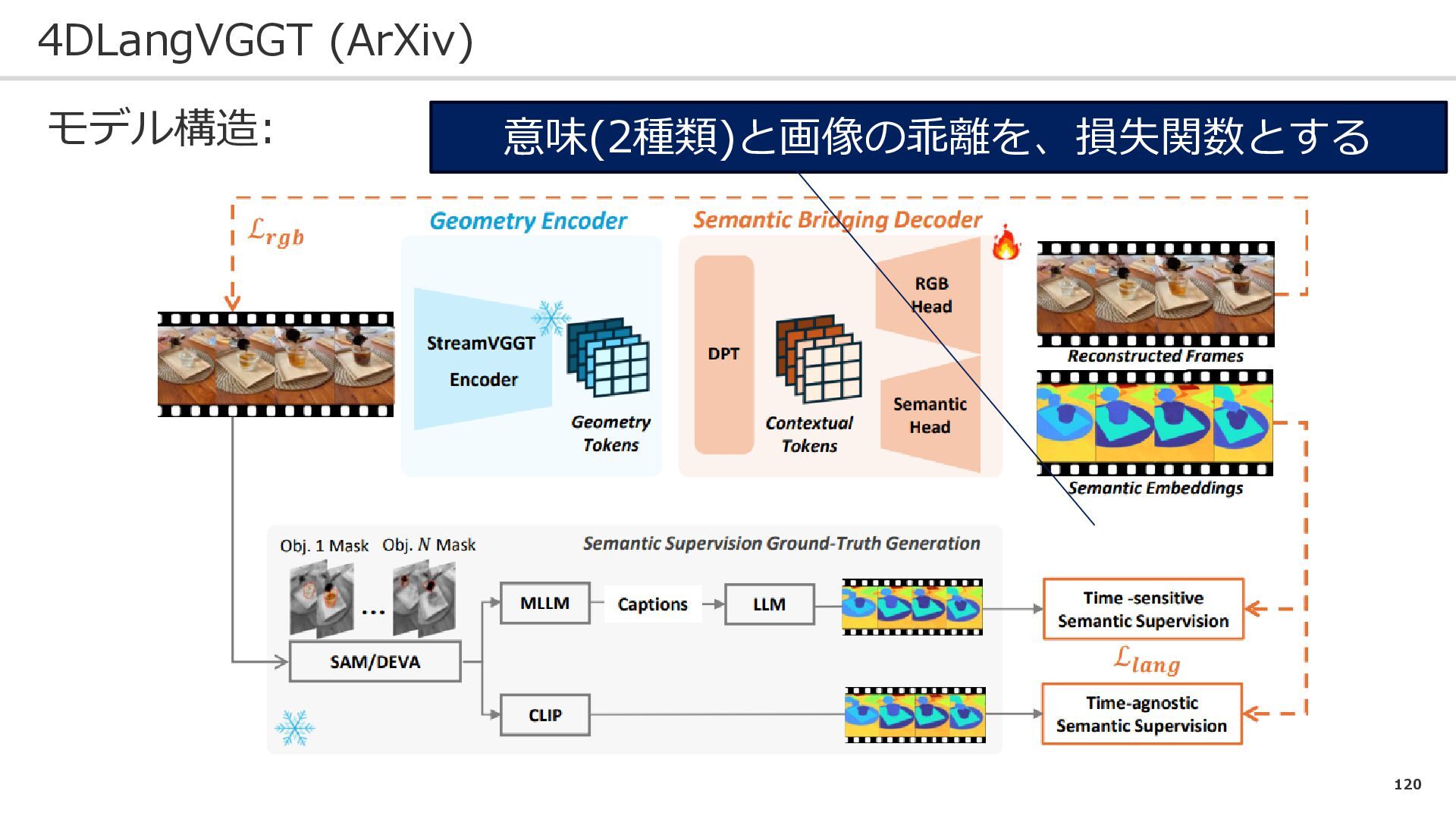
tammyeverts
12
1.7k
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.3k
Google's AI Overviews - The New Search
badams
0
1.1k
Tell your own story through comics
letsgokoyo
1
990
Done Done
chrislema
186
16k
GitHub's CSS Performance
jonrohan
1033
470k
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.5k
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
2
230
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
150
A Modern Web Designer's Workflow
chriscoyier
698
190k
Transcript
3次元領域の最新動向 佐藤研輪講: 東京科学大学 小島 瑞貴
2 VGGT (CVPR2025) 問題設定 : 3次元シーンでの汎用的なモデルを作りたい 課題: ➀ 各3Dタスク(デプス推定・カメラポーズ推定)が独立している ②
各シーンごとの最適化 (あらゆるシーンで汎用的に使えるモデルの不足) (例: NeRF, 3DGSなど)
3 VGGT (CVPR2025) なにができるようになったのか: 複数画像からの統一した三次元情報の推定 三次元情報の推定 … 点群・画素対応関係・カメラ姿勢・デプス 複数画像 点群
対応関係 デプス カメラ姿勢
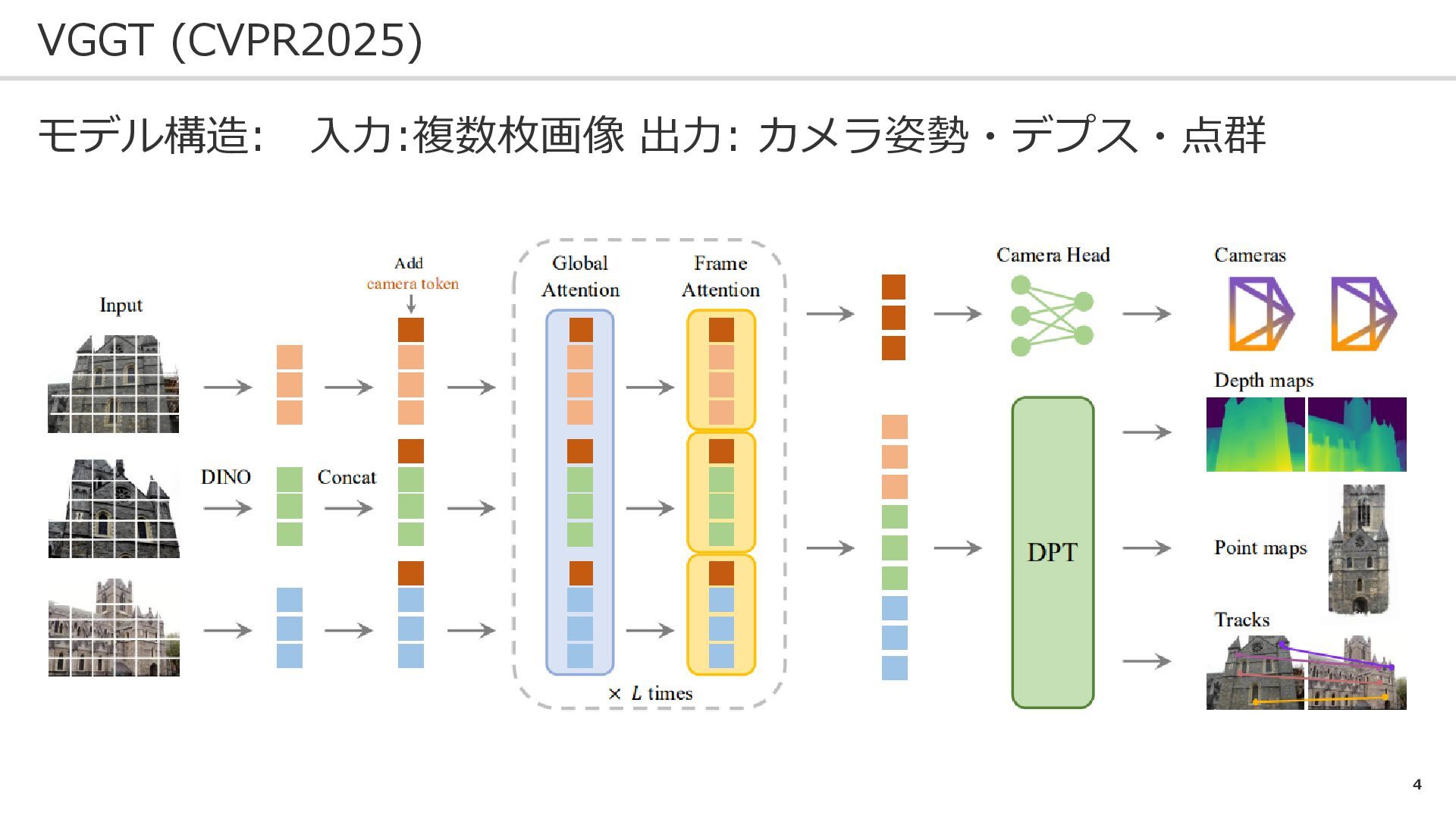
4 VGGT (CVPR2025) モデル構造: 入力:複数枚画像 出力: カメラ姿勢・デプス・点群
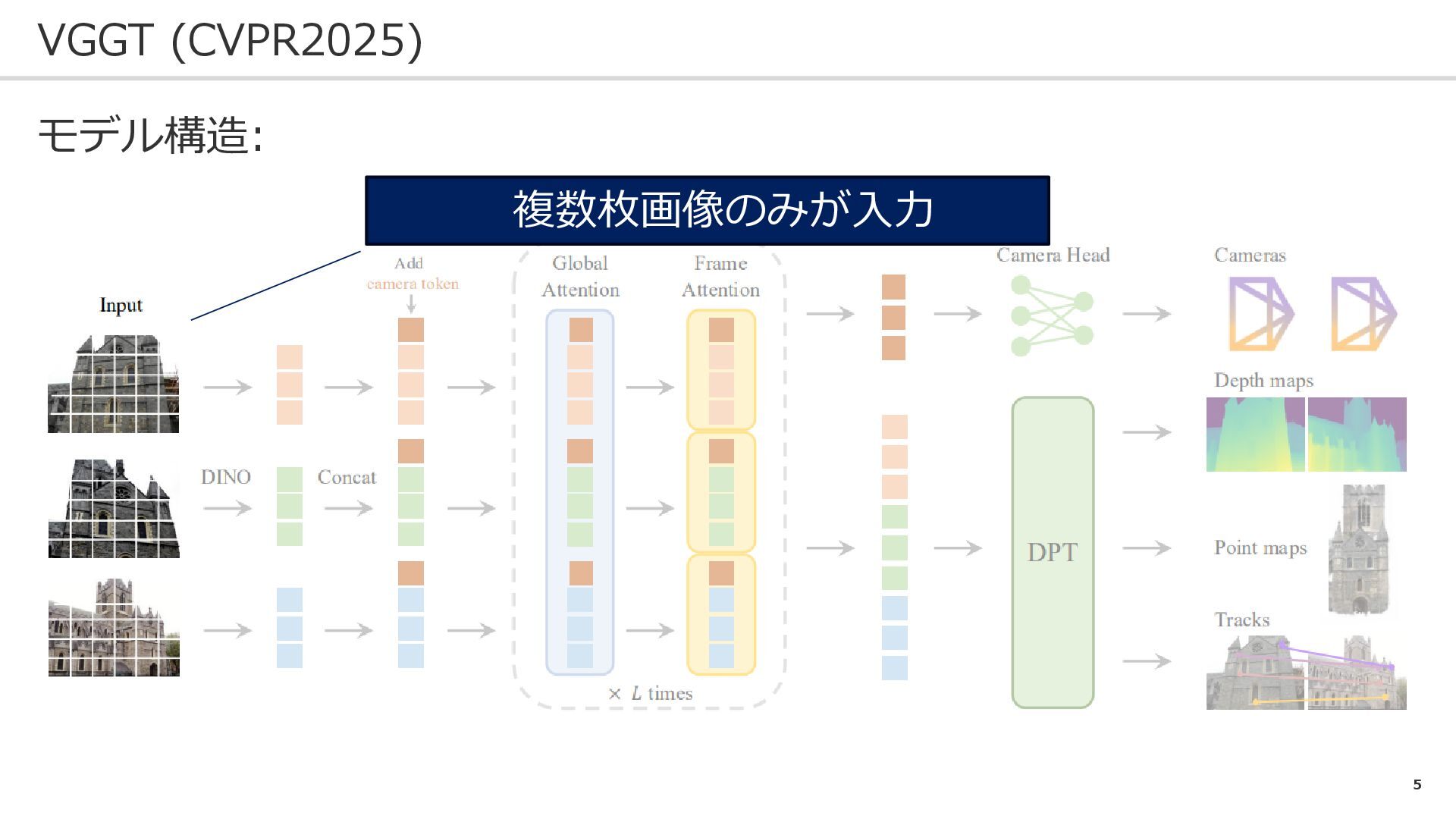
5 VGGT (CVPR2025) モデル構造: 複数枚画像のみが入力
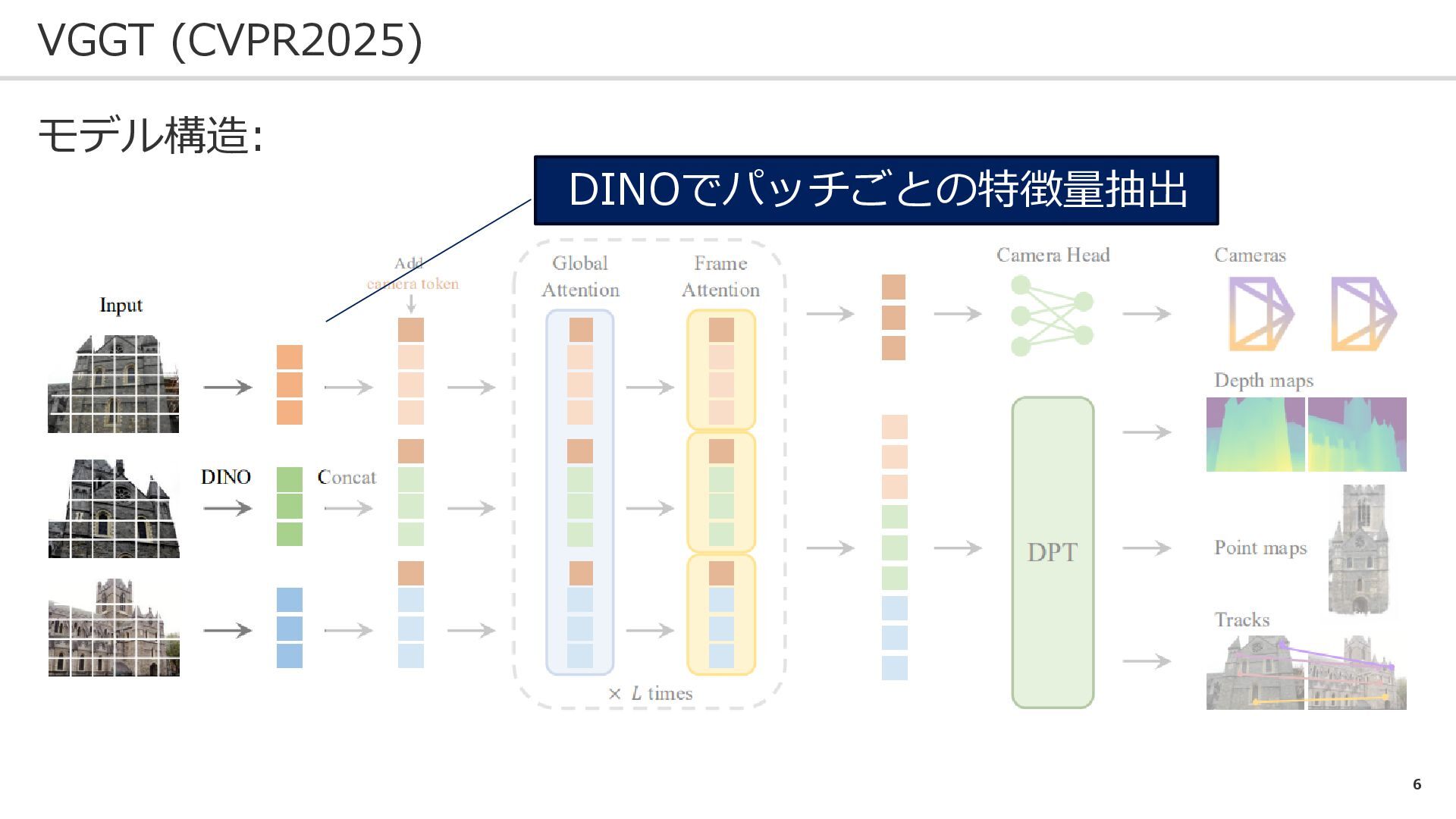
6 VGGT (CVPR2025) モデル構造: DINOでパッチごとの特徴量抽出
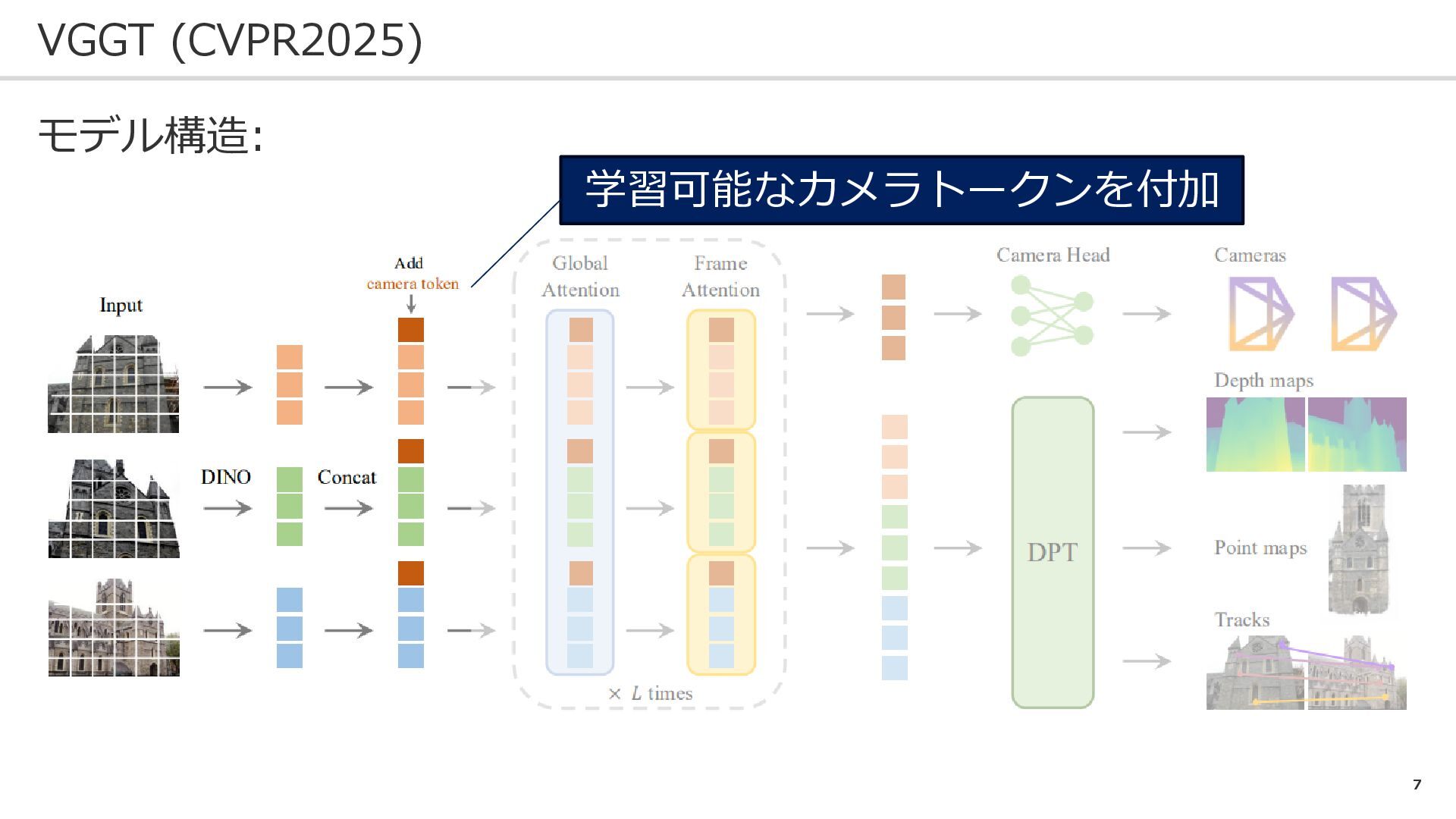
7 VGGT (CVPR2025) モデル構造: 学習可能なカメラトークンを付加
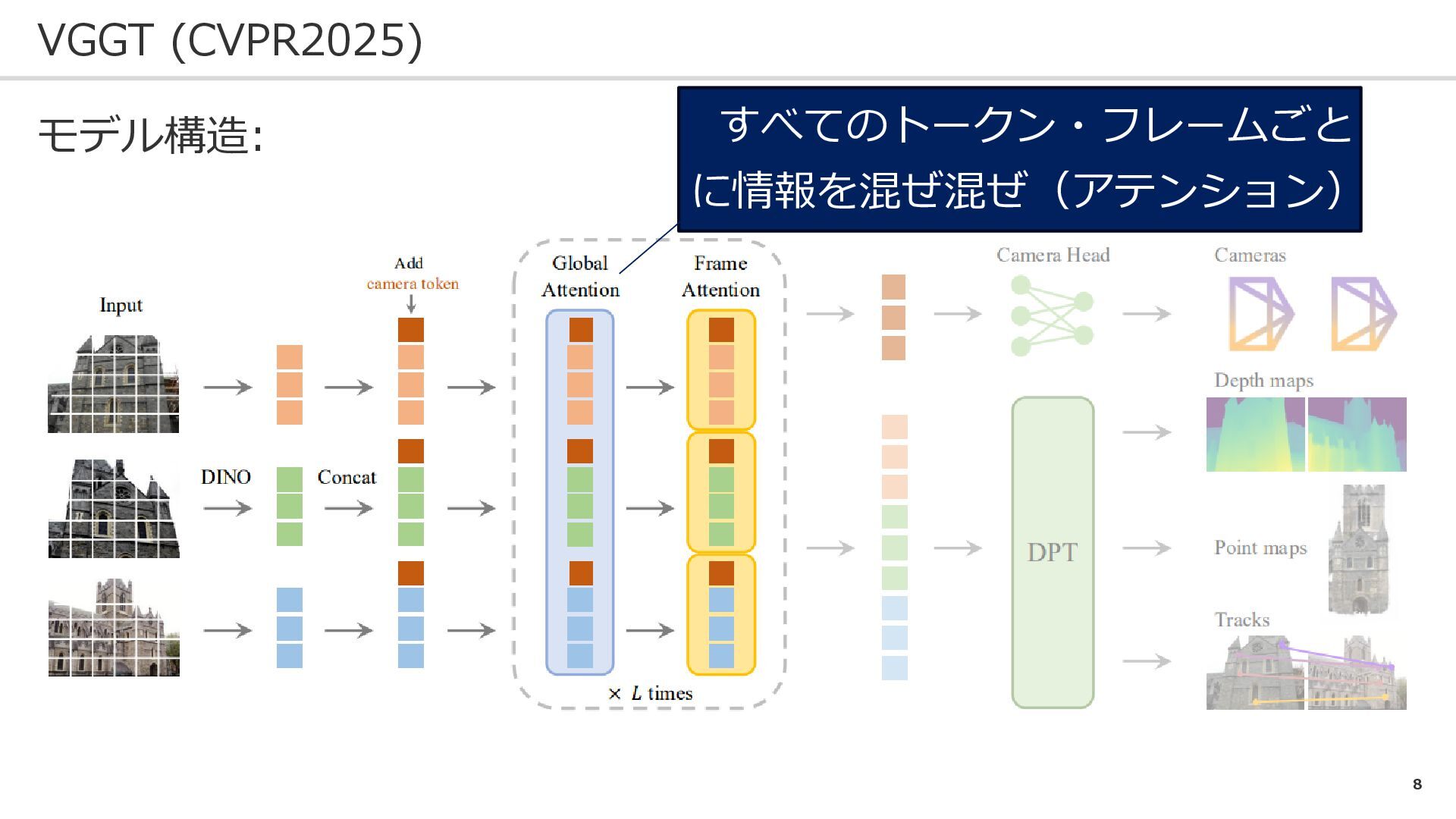
8 VGGT (CVPR2025) モデル構造: すべてのトークン・フレームごと に情報を混ぜ混ぜ(アテンション)
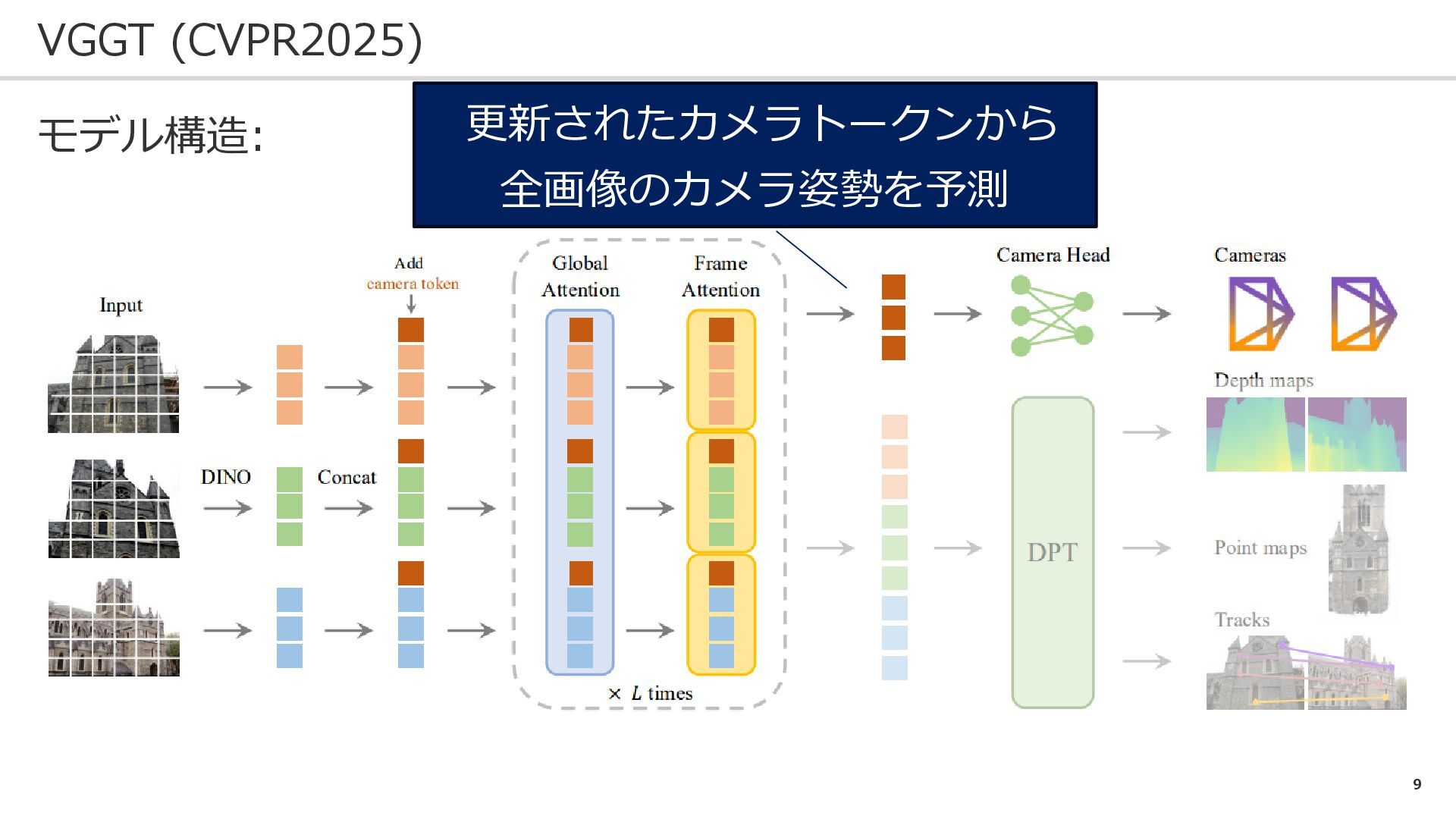
9 VGGT (CVPR2025) モデル構造: 更新されたカメラトークンから 全画像のカメラ姿勢を予測
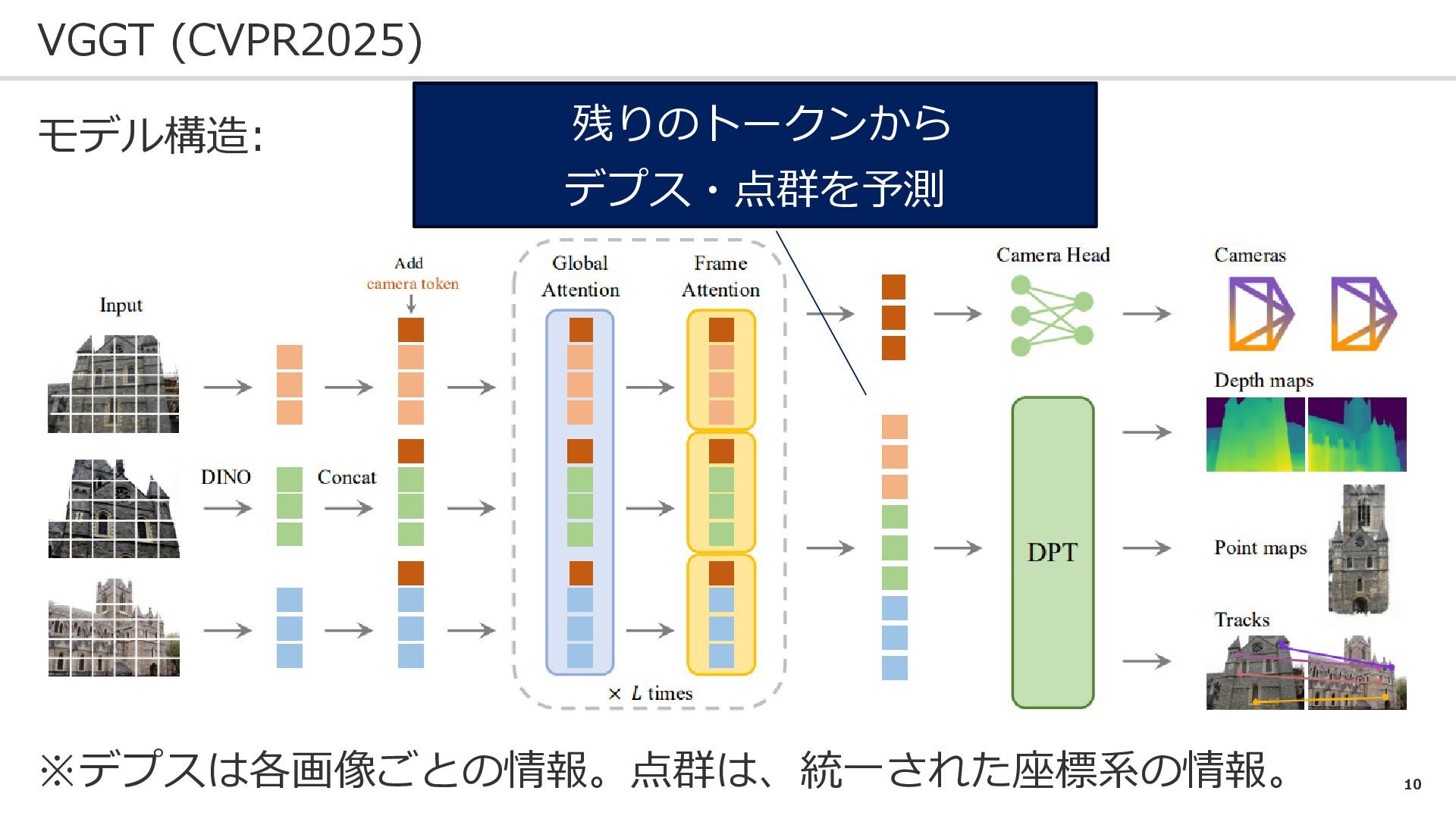
10 VGGT (CVPR2025) モデル構造: 残りのトークンから デプス・点群を予測 ※デプスは各画像ごとの情報。点群は、統一された座標系の情報。
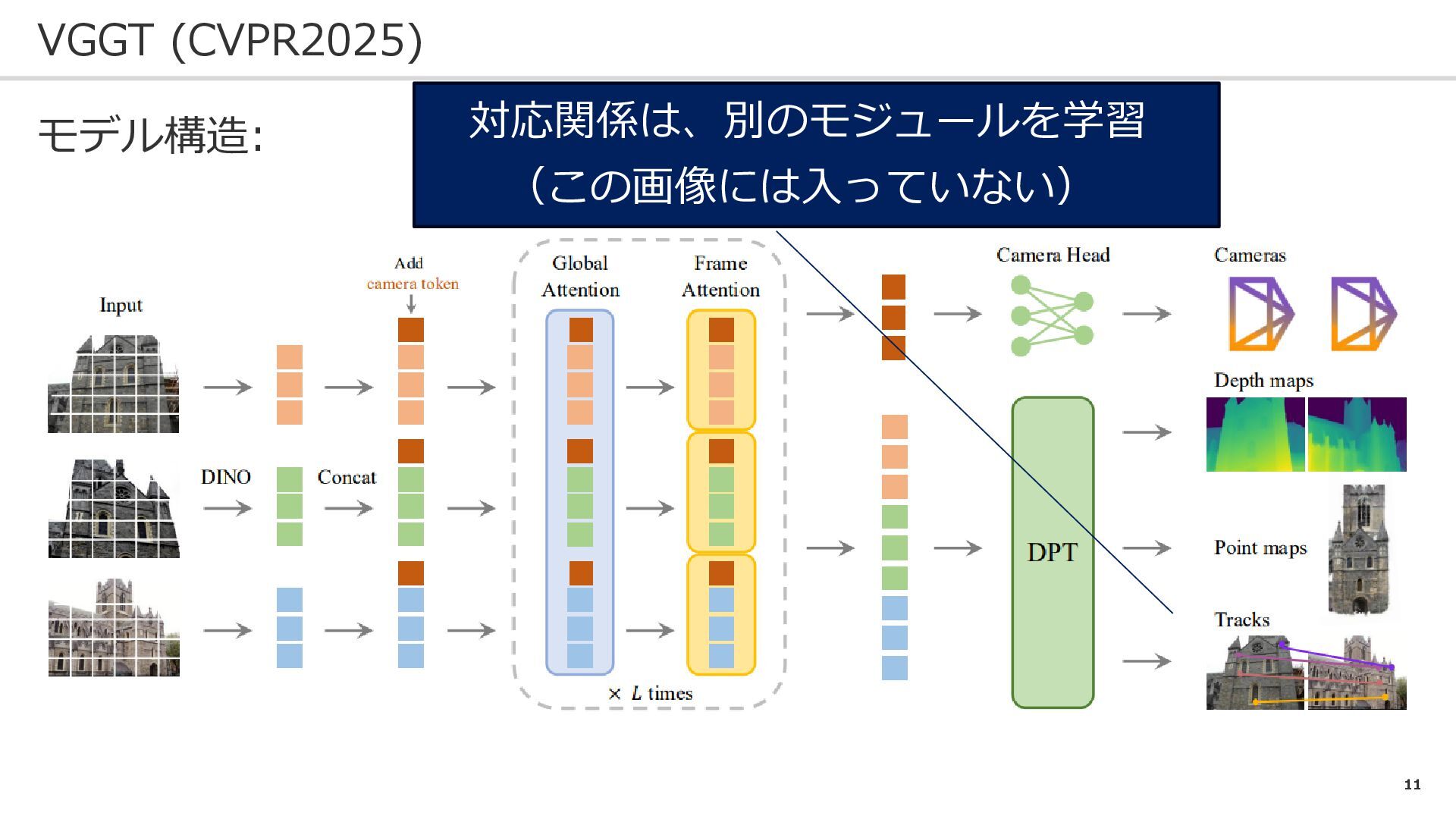
11 VGGT (CVPR2025) モデル構造: 対応関係は、別のモジュールを学習 (この画像には入っていない)
12 VGGT (CVPR2025) 損失関数: 一応、モデルの入出力を定式化しておく: 複数枚画像 カメラ姿勢 デプス 点群 対応関係用の
特徴量 (略) 出力するカメラ姿勢・デプス・点群・トラッキングに関して GTとの誤差を最小化するように学習という認識でOK
13 VGGT (CVPR2025) 定性結果:
14 VGGT (CVPR2025) 定性結果: この論文をきっかけに種々の研究が生まれる
15 VGG-T^3 (CVPR2026) 問題設定 : VGGTでの入力画像増加に伴う長い推論時間をなんとかしたい 課題: ➀ 入力画像枚数に対し、推論時間が2次関数的 ②
三次元復元の大規模化と相性が悪い
16 VGG-T^3 (CVPR2026) なにができるようになったのか : 推論時間が訓練画像枚数に対して線形に! 数千枚の画像から 三次元復元
17 VGG-T^3 (CVPR2026) なにができるようになったのか : 推論時間が訓練画像枚数に対して線形に! VGGTでは10分かかるが 50秒まで短縮
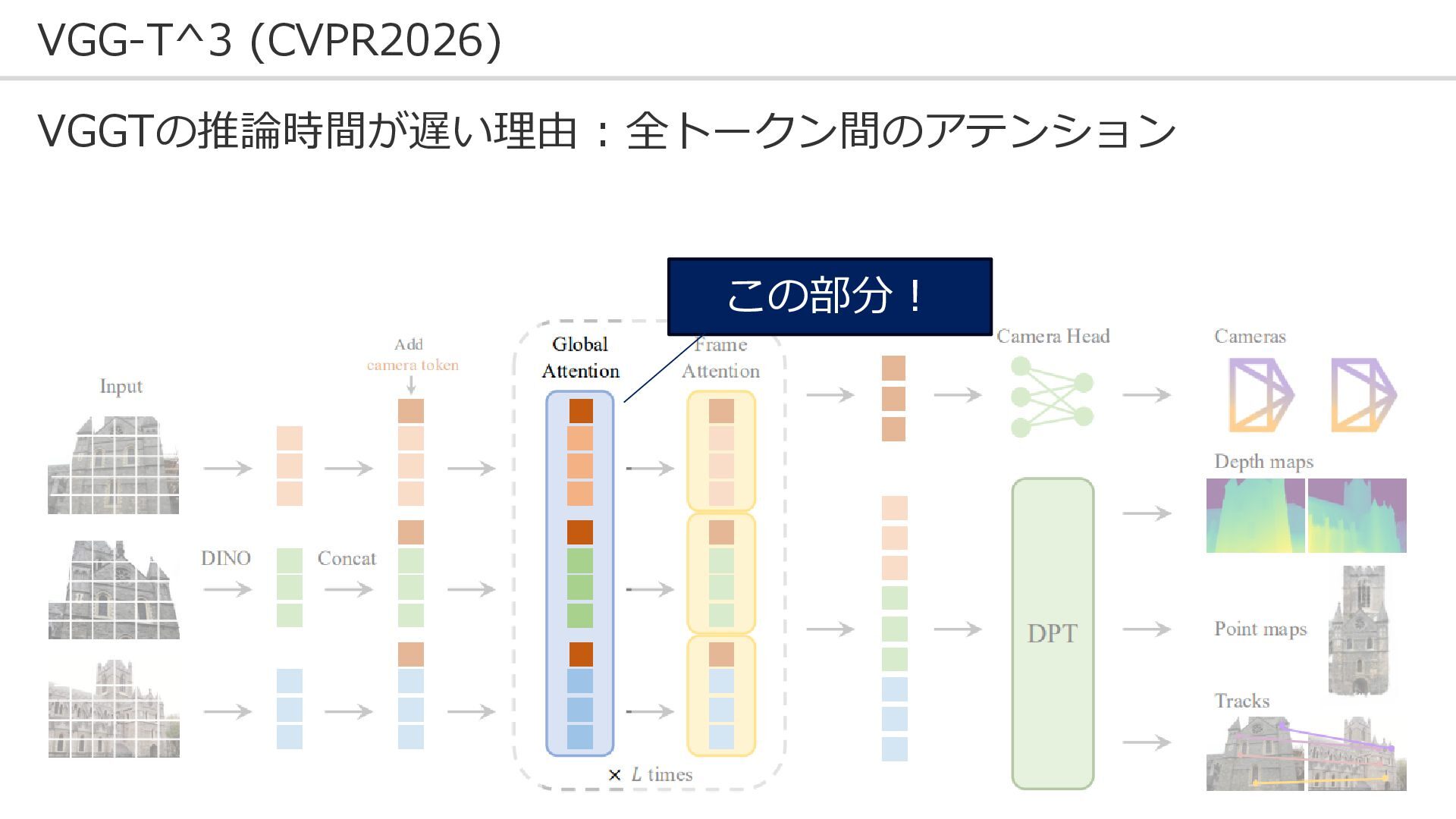
18 VGG-T^3 (CVPR2026) VGGTの推論時間が遅い理由 : 全トークン間のアテンション この部分!
19 VGG-T^3 (CVPR2026) 数式で捉えるとわかりやすい: ・トークンiの特徴量を出力する過程 トークンiのクエリに対して
20 VGG-T^3 (CVPR2026) 数式で捉えるとわかりやすい: ・トークンiの特徴量を出力する過程 複数のキーとの類似度を元に バリューを重みづけする
21 VGG-T^3 (CVPR2026) 数式で捉えるとわかりやすい: ・トークンiの特徴量を出力する過程 複数のキーとの類似度を元に バリューを重みづけする キーとバリューのペアを記録し(KV-cache)、参照するのが メモリ容量を食うし、時間がかかる。
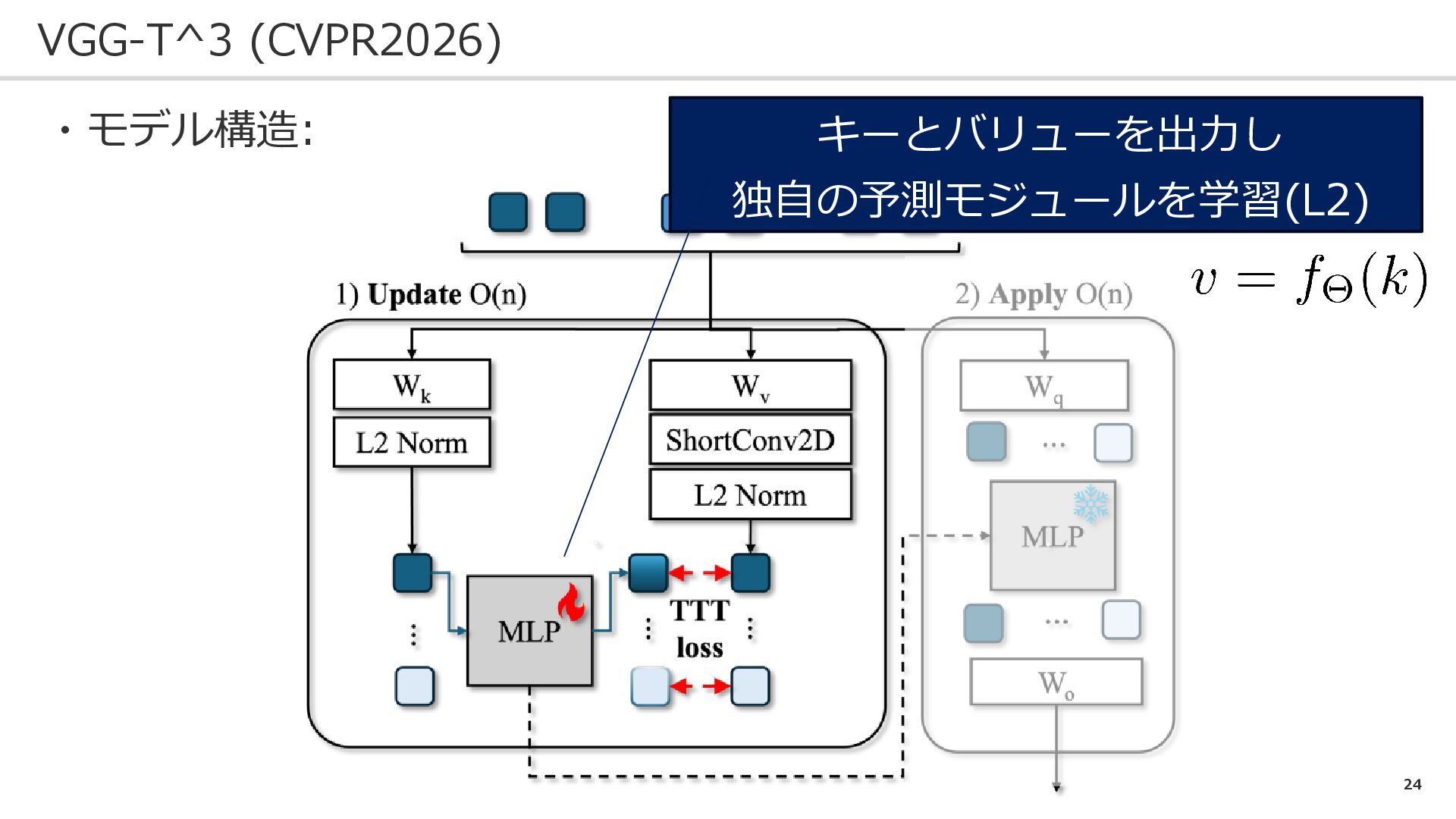
22 VGG-T^3 (CVPR2026) ・キーとバリューのペアを格納しておくのが問題点 ・文字を変えると見通しが良くなる。たとえば、 を格納するのが問題 それならニューラルネットワークで陰関数表現すればOK なので、キーとバリューについても陰関数表現
23 VGG-T^3 (CVPR2026) ・解釈: クエリとの類似度をキーで算出し、バリューを出す ニューラルネットが入力類似度に基づく出力をすると仮定して(※) ・今、獲得しているもの(詳細は後述): ※小島は少し怪しいと思っている 本論文の提案
24 VGG-T^3 (CVPR2026) ・モデル構造: キーとバリューを出力し 独自の予測モジュールを学習(L2)
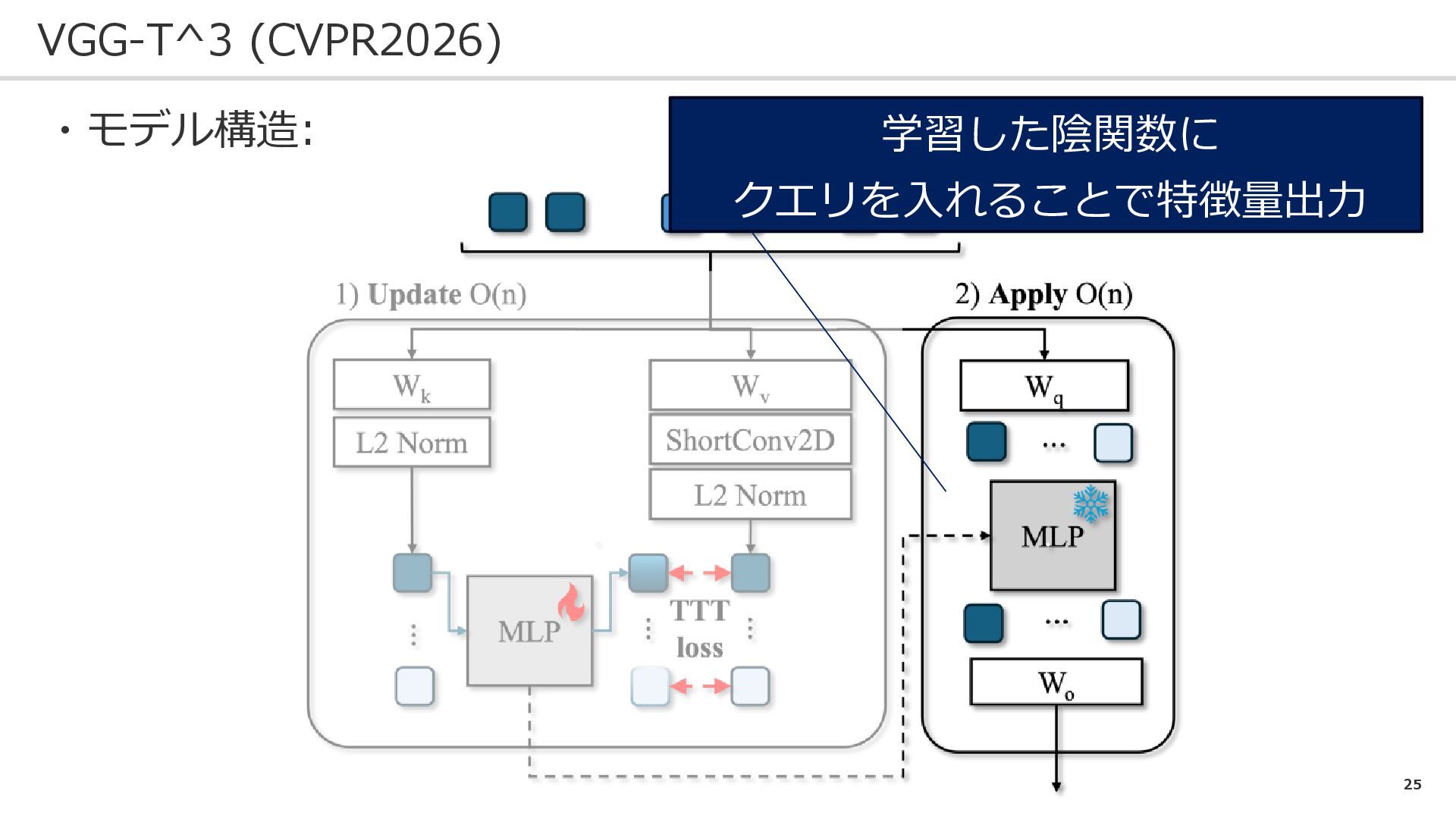
25 VGG-T^3 (CVPR2026) ・モデル構造: 学習した陰関数に クエリを入れることで特徴量出力
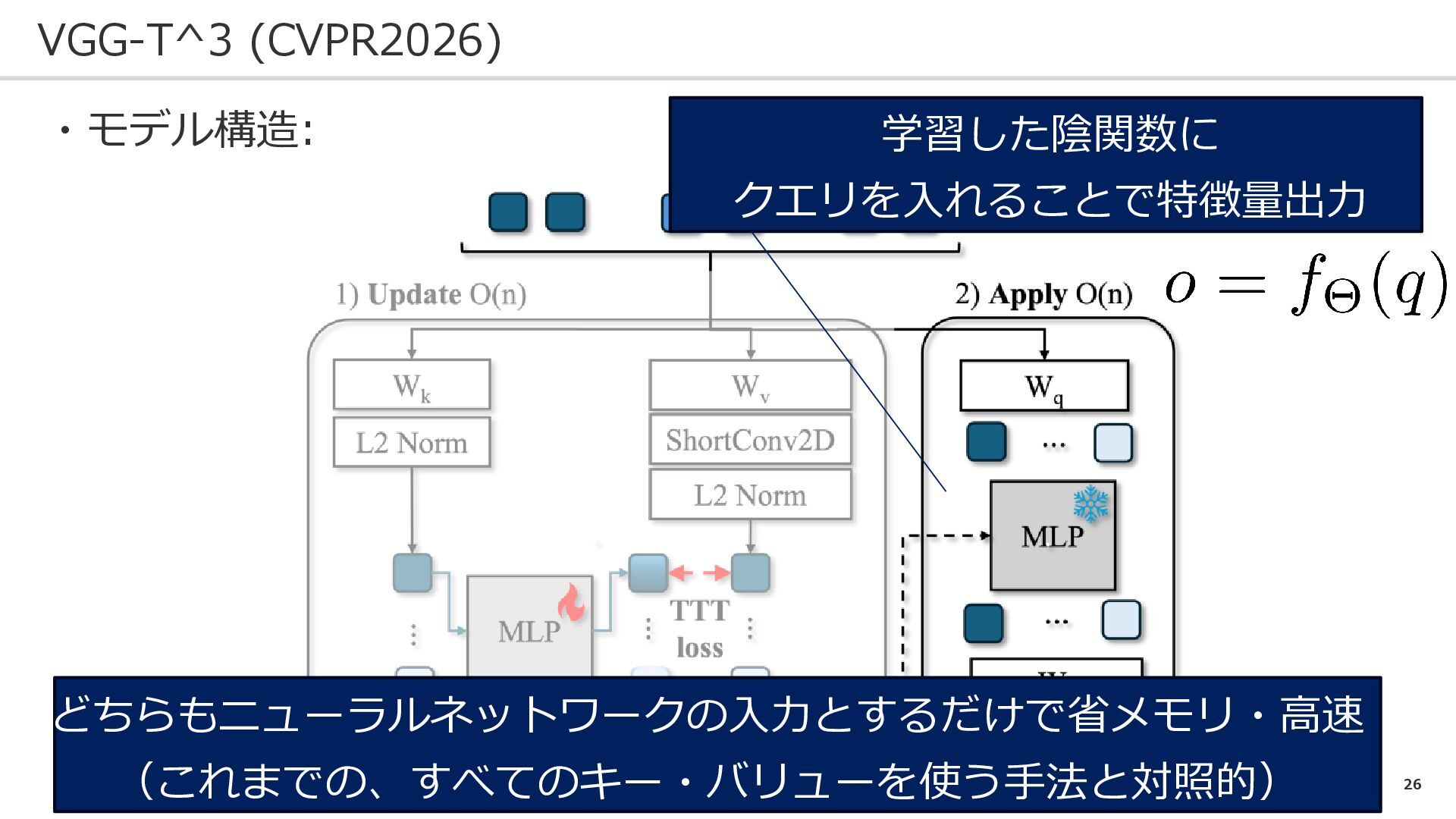
26 VGG-T^3 (CVPR2026) ・モデル構造: 学習した陰関数に クエリを入れることで特徴量出力 どちらもニューラルネットワークの入力とするだけで省メモリ・高速 (これまでの、すべてのキー・バリューを使う手法と対照的)
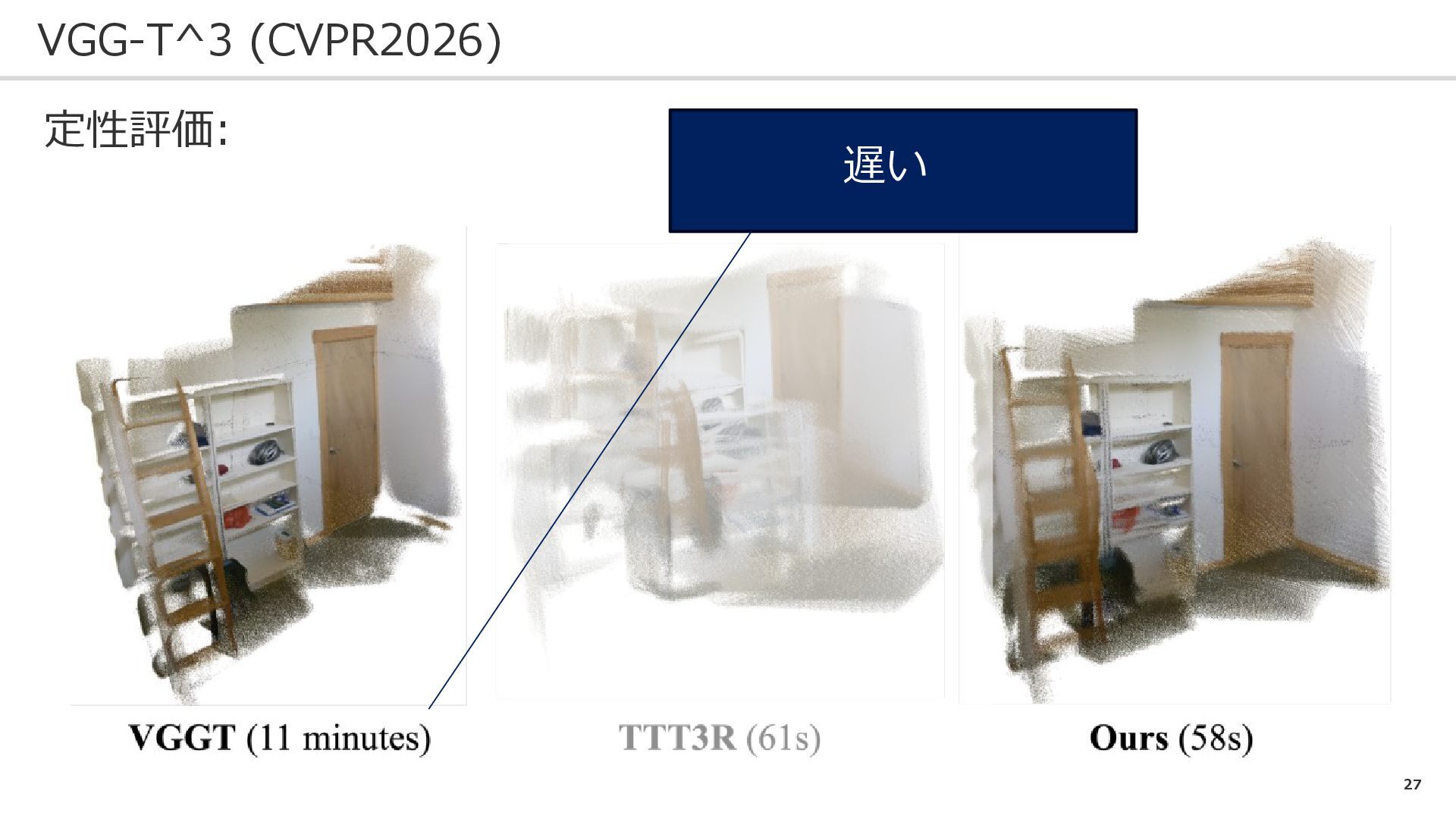
27 VGG-T^3 (CVPR2026) 定性評価: 遅い
28 VGG-T^3 (CVPR2026) 定性評価: 早いが低品質
29 Zipmap (CVPR2026) VGGT^3と同じ手法:➀キーとバリューの関係学習 ②クエリを入力
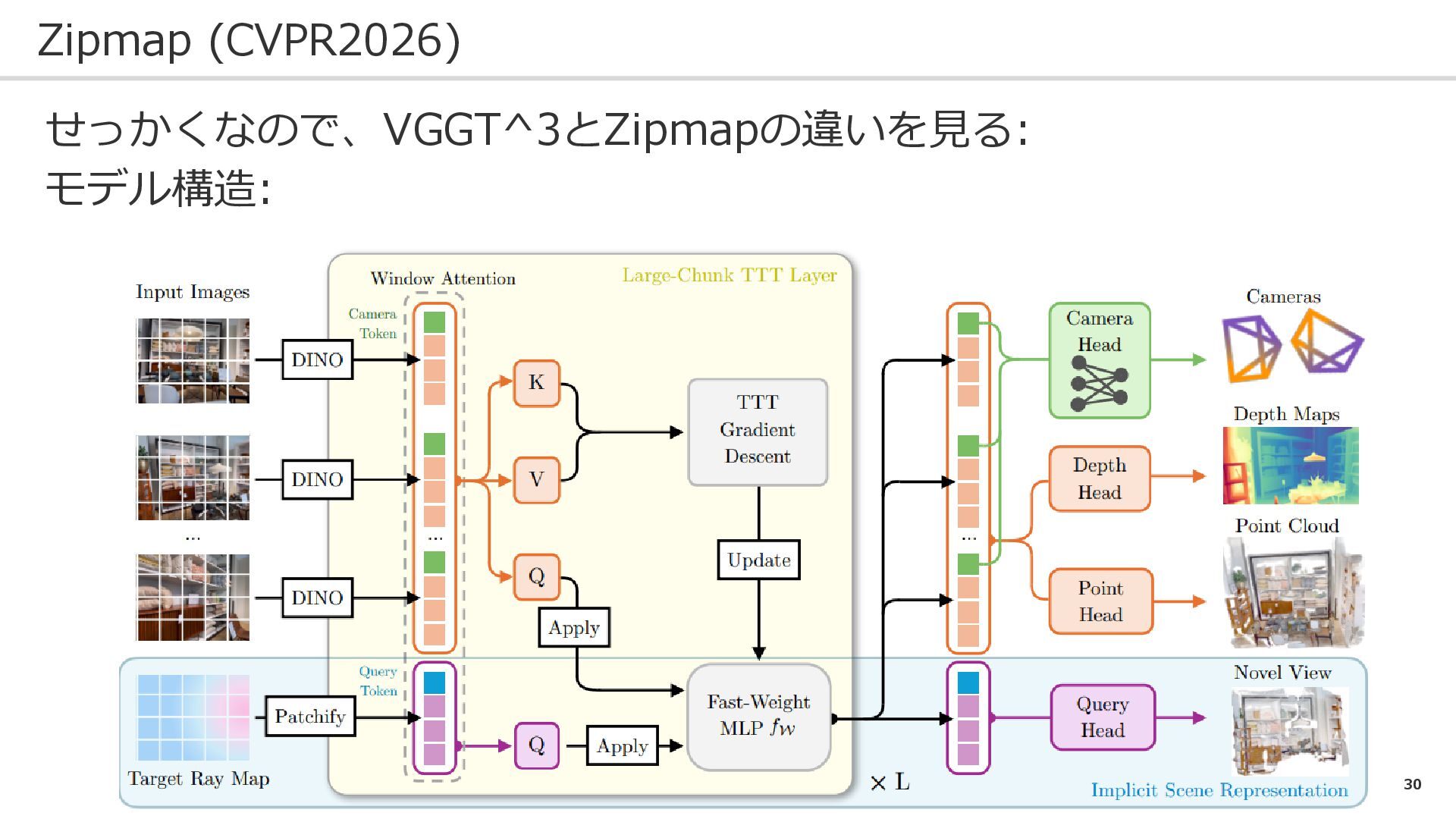
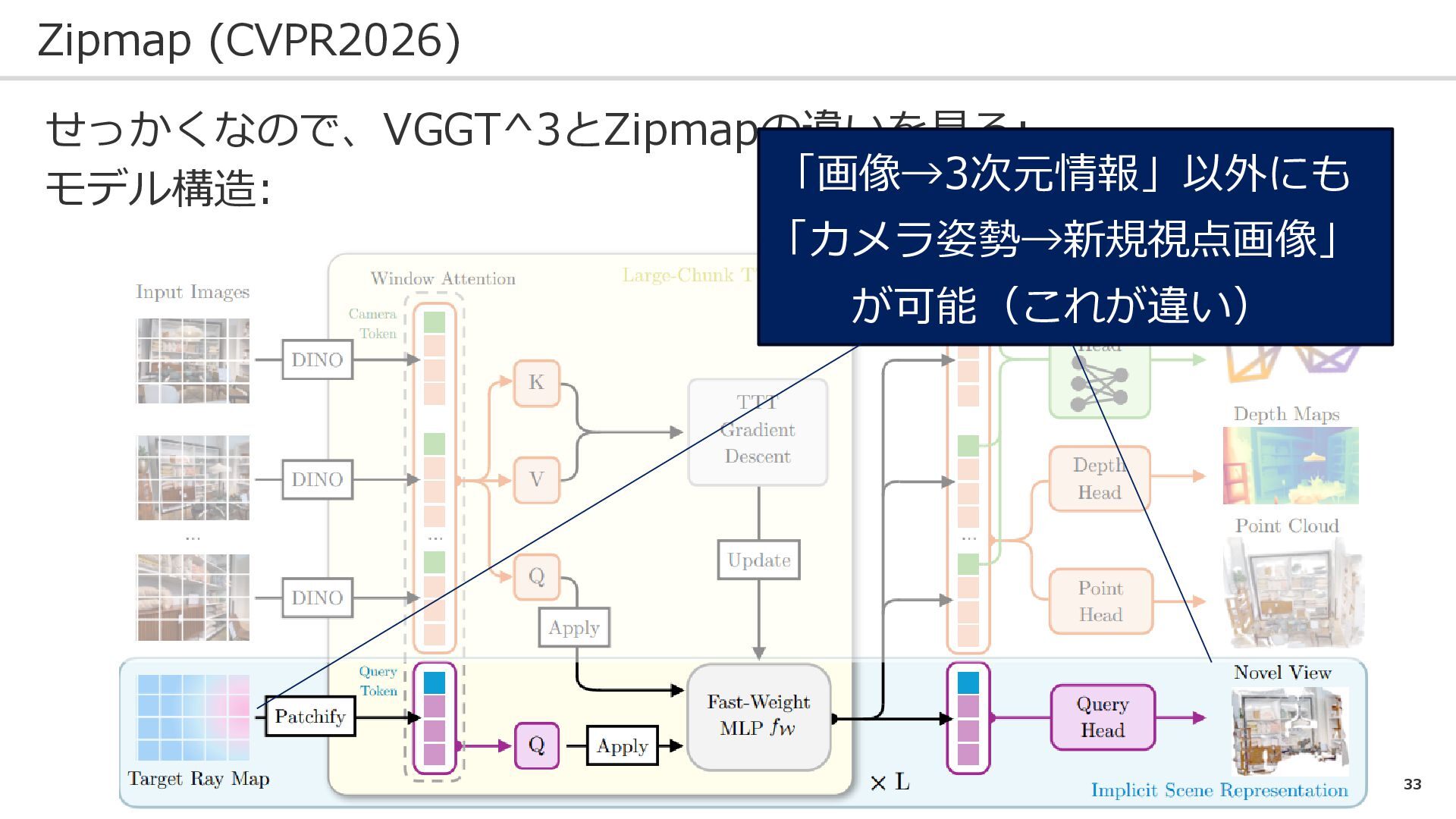
30 Zipmap (CVPR2026) せっかくなので、VGGT^3とZipmapの違いを見る: モデル構造:
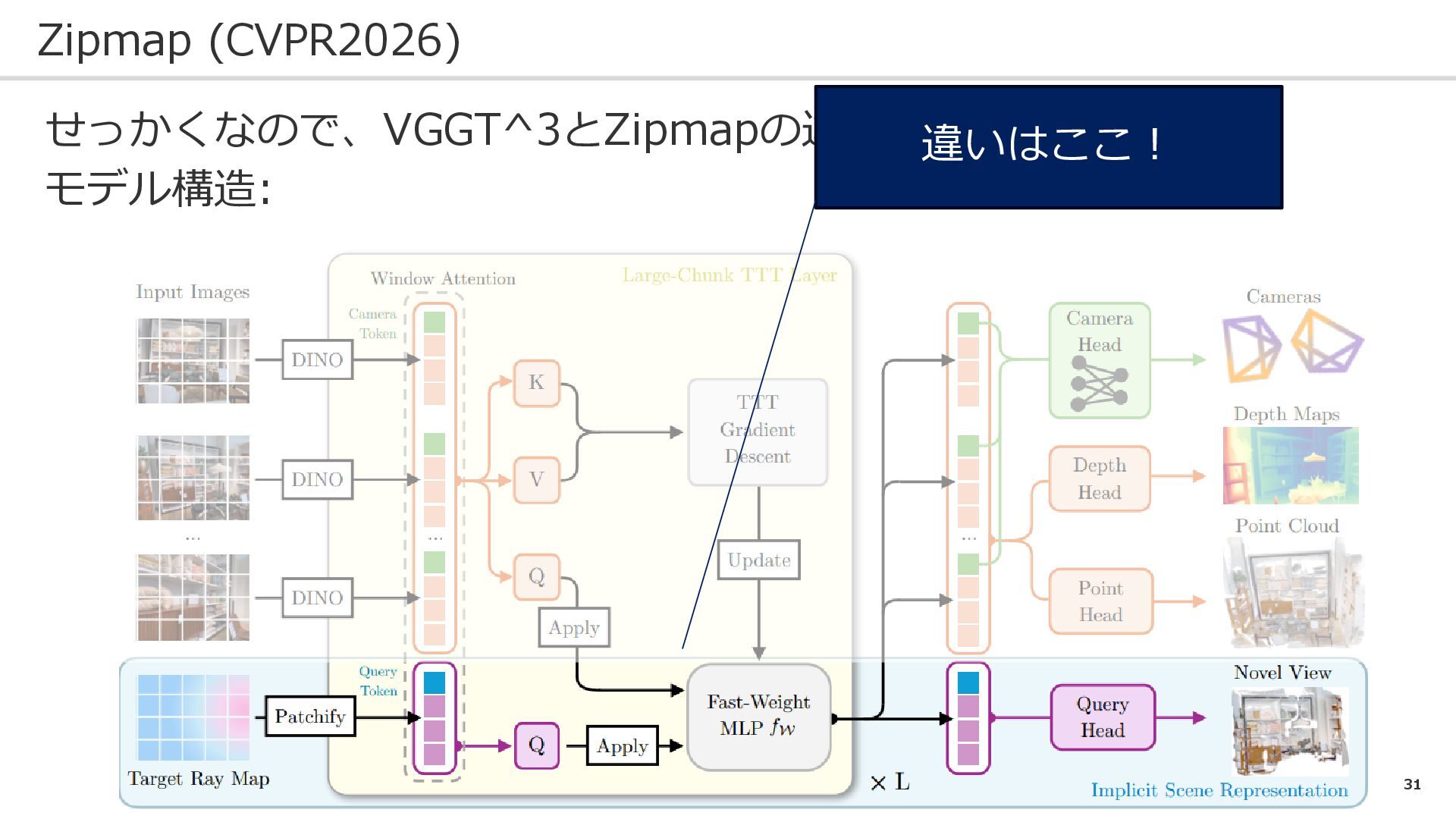
31 Zipmap (CVPR2026) せっかくなので、VGGT^3とZipmapの違いを見る: モデル構造: 違いはここ!
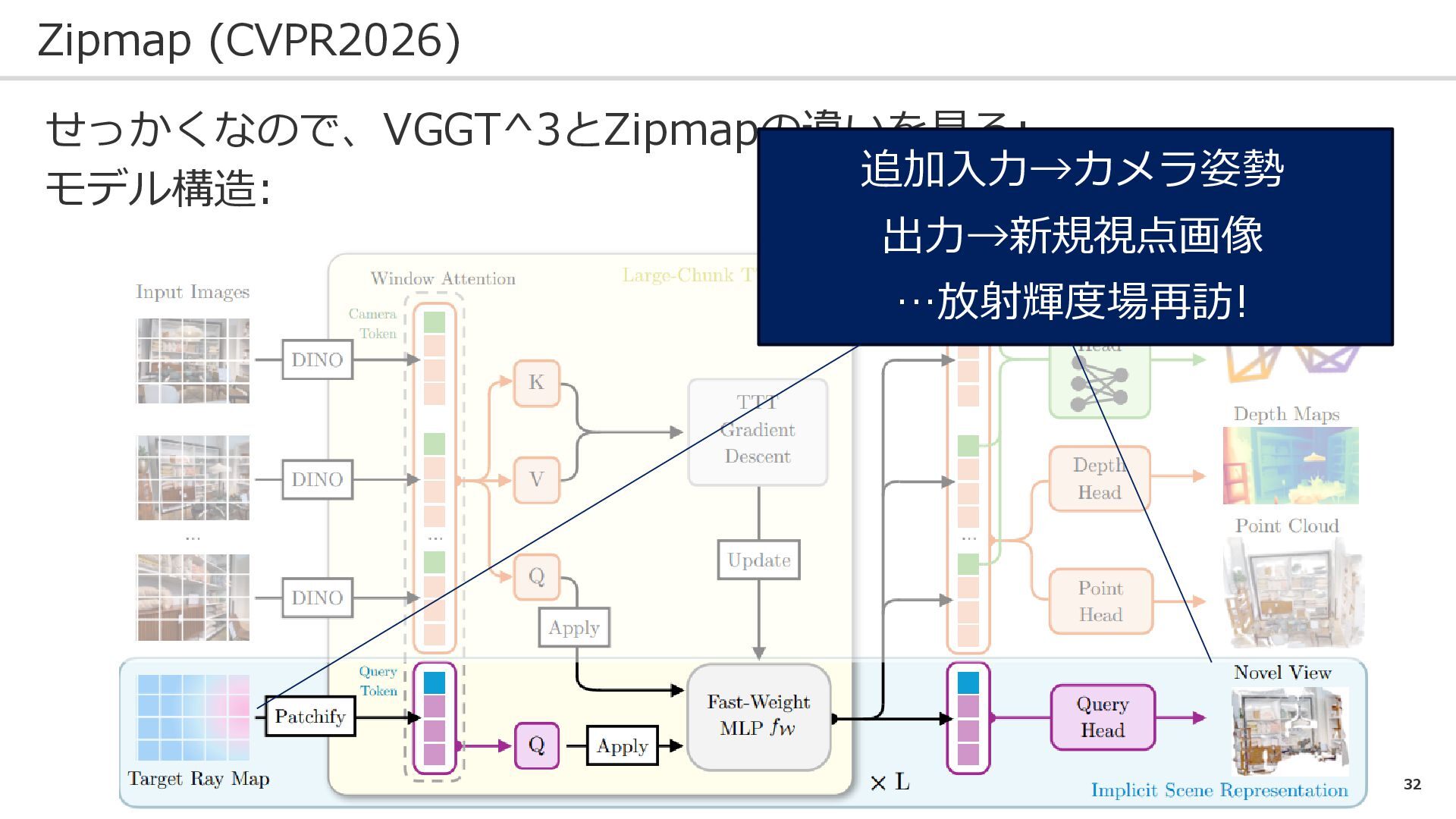
32 Zipmap (CVPR2026) せっかくなので、VGGT^3とZipmapの違いを見る: モデル構造: 追加入力→カメラ姿勢 出力→新規視点画像 …放射輝度場再訪!
33 Zipmap (CVPR2026) せっかくなので、VGGT^3とZipmapの違いを見る: モデル構造: 「画像→3次元情報」以外にも 「カメラ姿勢→新規視点画像」 が可能(これが違い)
34 Zipmap (CVPR2026) せっかくなので、VGGT^3とZipmapの違いを見る: 損失関数: VGGT・VGGT^3 (画像→三次元情報) Zipmap (カメラ視点→新規視点画像)
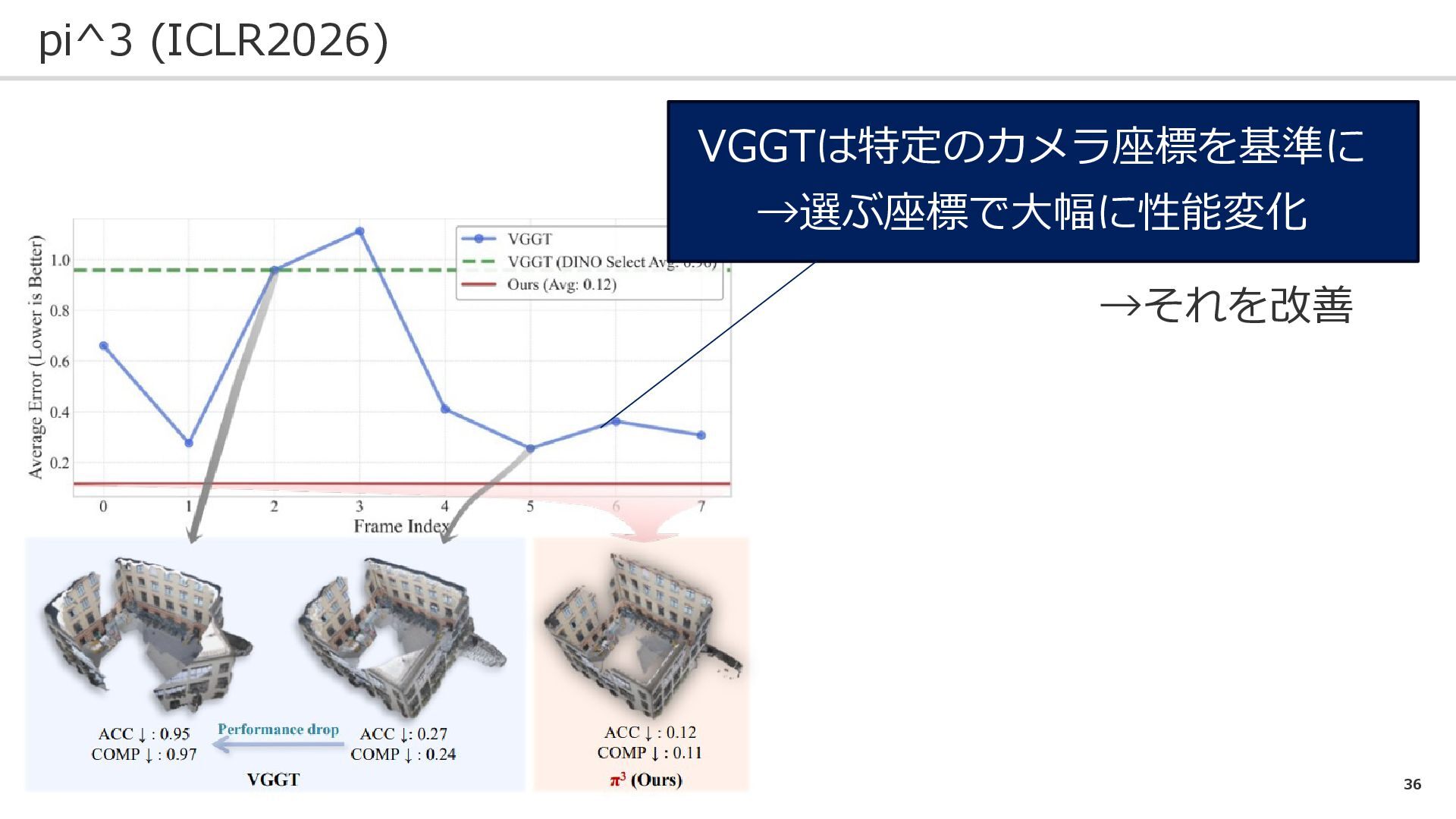
35 pi^3 (ICLR2026) 問題設定 : VGGTでの特定フレームに依存した復元をなんとかしたい
36 pi^3 (ICLR2026) →それを改善 VGGTは特定のカメラ座標を基準に →選ぶ座標で大幅に性能変化
37 pi^3 (ICLR2026) 入力画像に対し置換不変にすることで、性能向上に繋がる
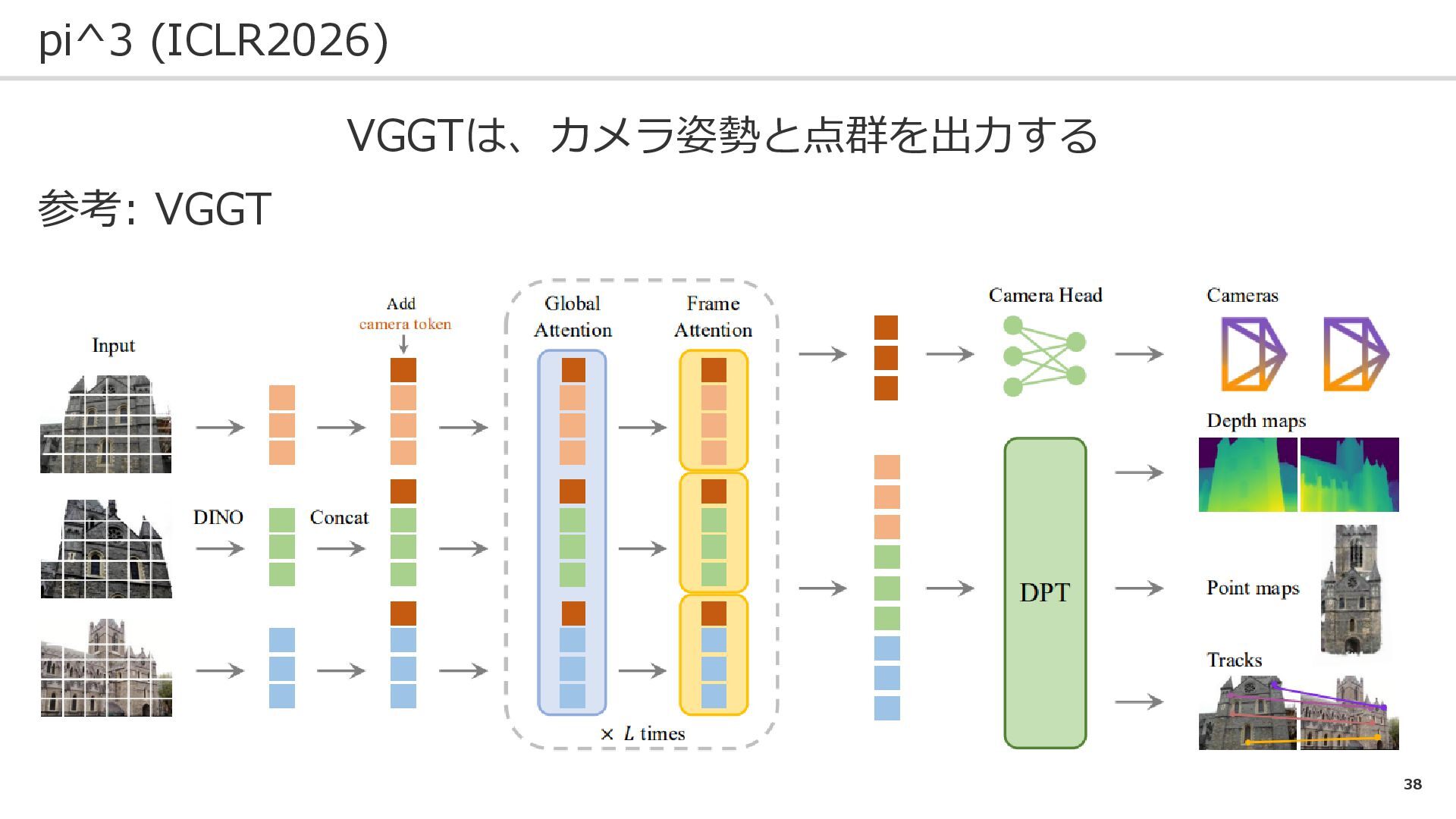
38 pi^3 (ICLR2026) VGGTは、カメラ姿勢と点群を出力する 参考: VGGT
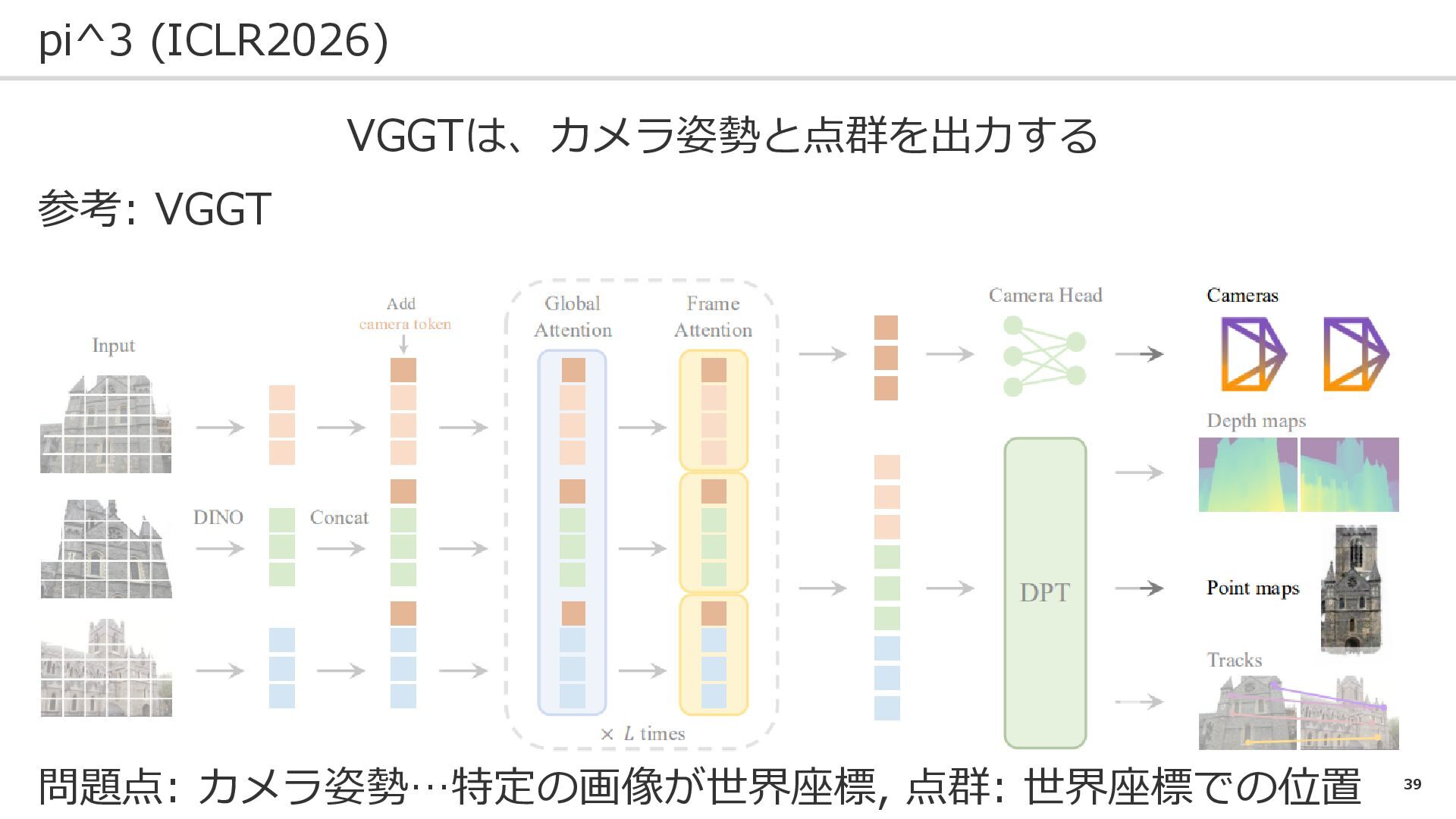
39 pi^3 (ICLR2026) VGGTは、カメラ姿勢と点群を出力する 参考: VGGT 問題点: カメラ姿勢…特定の画像が世界座標, 点群: 世界座標での位置
40 pi^3 (ICLR2026) 問題点: カメラ姿勢…特定の画像が世界座標, 点群: 世界座標での位置 VGGT Pi^3
41 pi^3 (ICLR2026) 問題点: カメラ姿勢…特定の画像が世界座標, 点群: 世界座標での位置 VGGT Pi^3 座標系が1つ固定されている
42 pi^3 (ICLR2026) 問題点: カメラ姿勢…特定の画像が世界座標, 点群: 世界座標での位置 VGGT Pi^3 すべてのカメラ姿勢が平等(置換不変)
43 pi^3 (ICLR2026) VGGTは、カメラ姿勢と点群を出力する カメラ姿勢側の修正点: カメラ姿勢間の相対関係で学習→ (出力はカメラ姿勢なので注意) 点群側の修正点: 各画像の座標で点群(デプス)を持つ ※共通したスケールは持つように
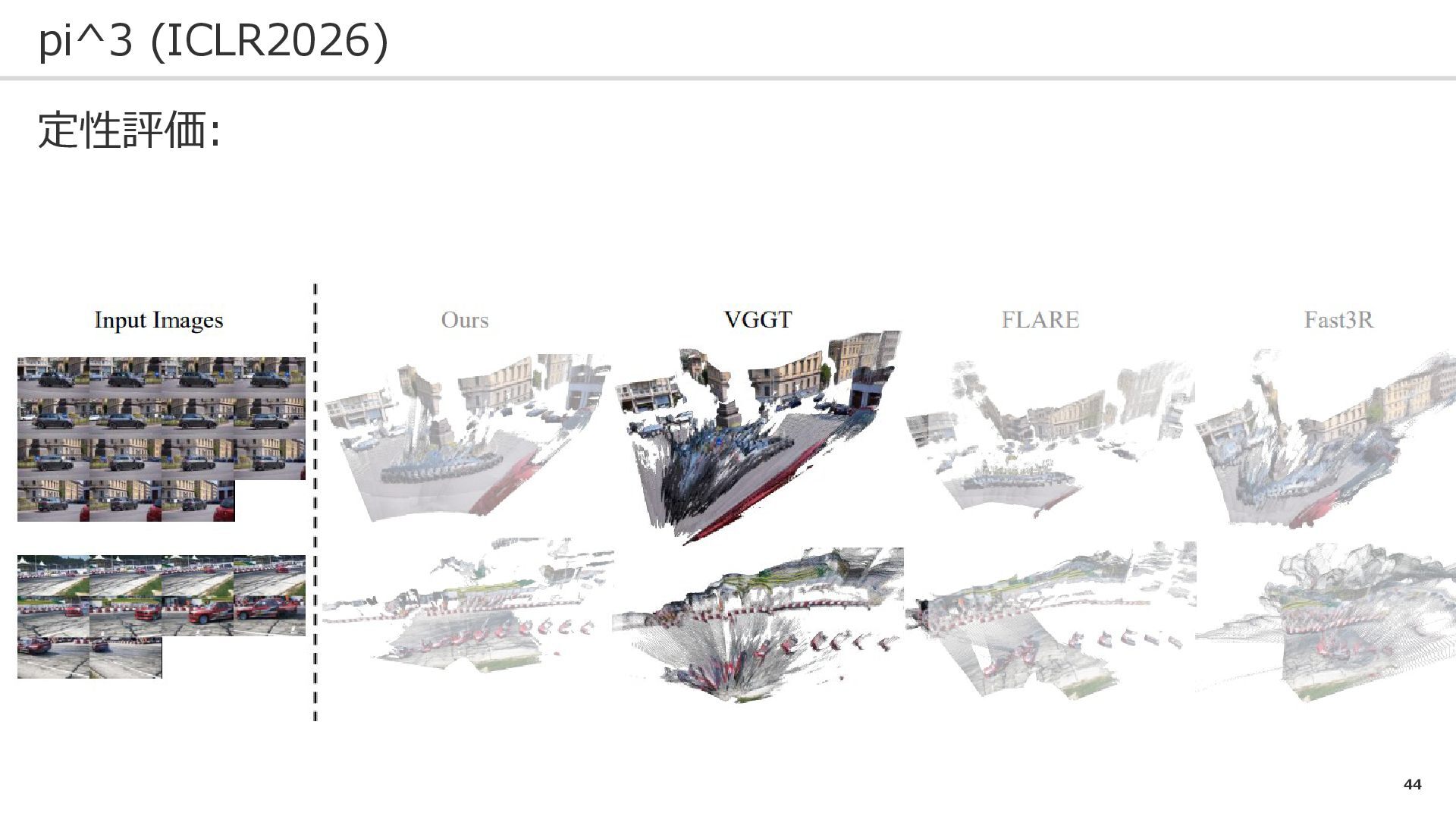
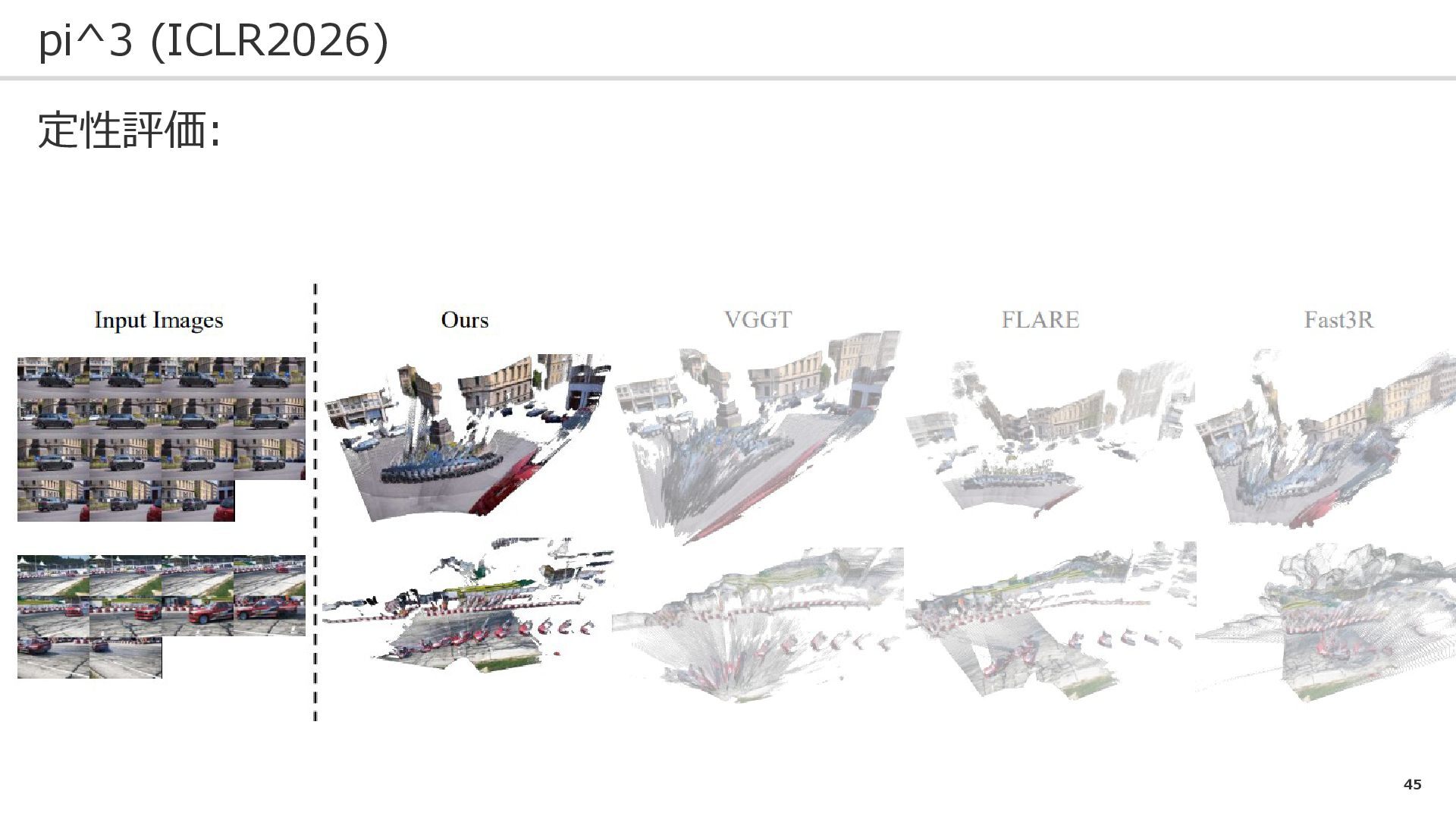
44 pi^3 (ICLR2026) 定性評価:
45 pi^3 (ICLR2026) 定性評価:
46 pi^3 (ICLR2026) 定性評価:
47 pi^3 (ICLR2026) 定性評価:
48 VGGT-Omega (CVPR2026) 問題設定 : VGGTをもっと大規模に学習し、スケールさせたい! 課題 : ➀ 出力付近の高解像度な出力がメモリ容量を食う
② すべてのパッチごとのアテンションが大変重い (それを解消するべく, TTTが導入された)
49 VGGT-Omega (CVPR2026) 問題設定 : VGGTをもっと大規模に学習し、スケールさせたい! 課題 : ➀ 出力付近の高解像度な出力がメモリ容量を食う
② すべてのパッチごとのアテンションが大変重い (それを解消するべく, TTTが導入された)
50 VGGT-Omega (CVPR2026)
51 VGGT-Omega (CVPR2026)
52 VGGT-Omega (CVPR2026)
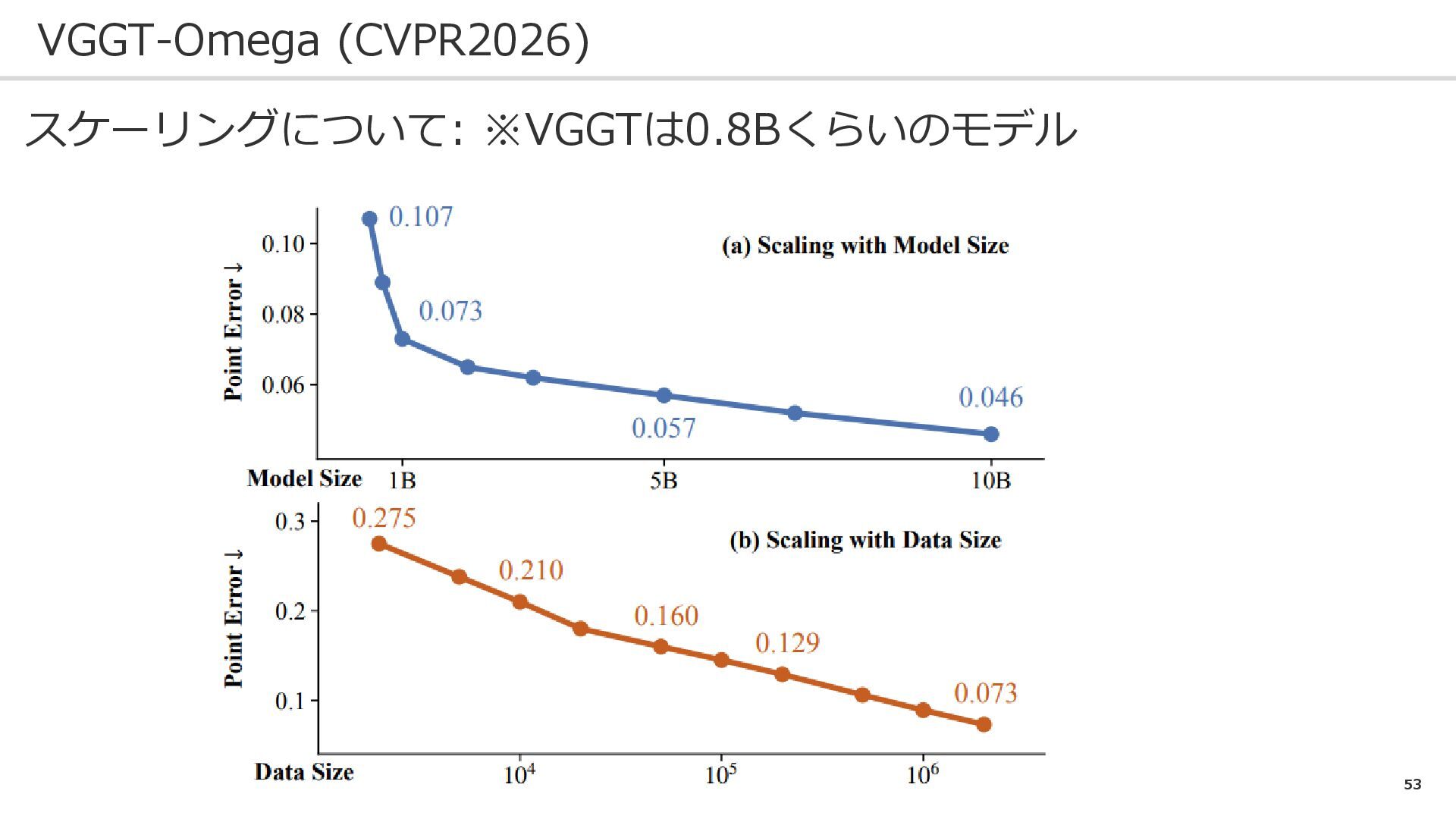
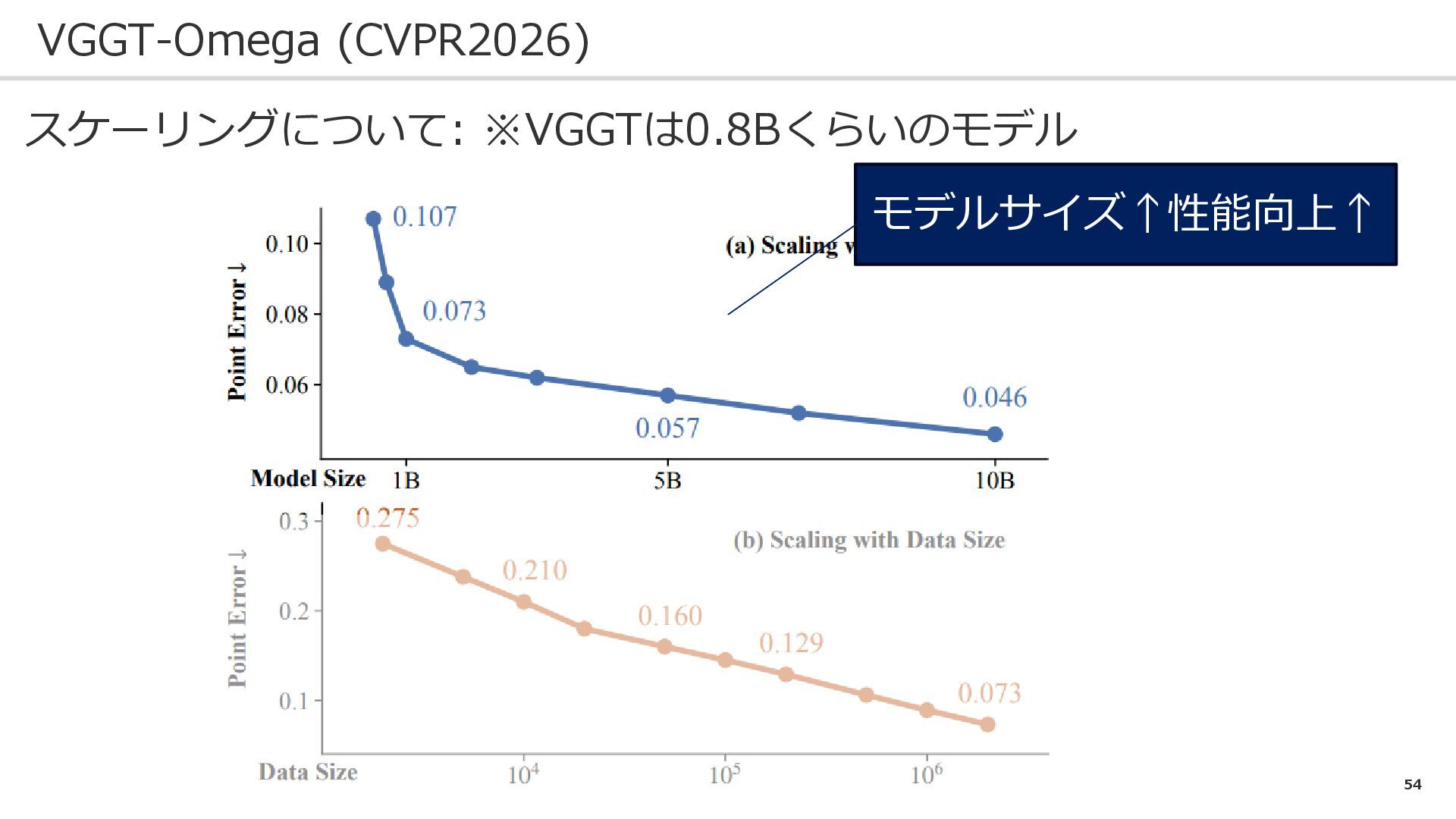
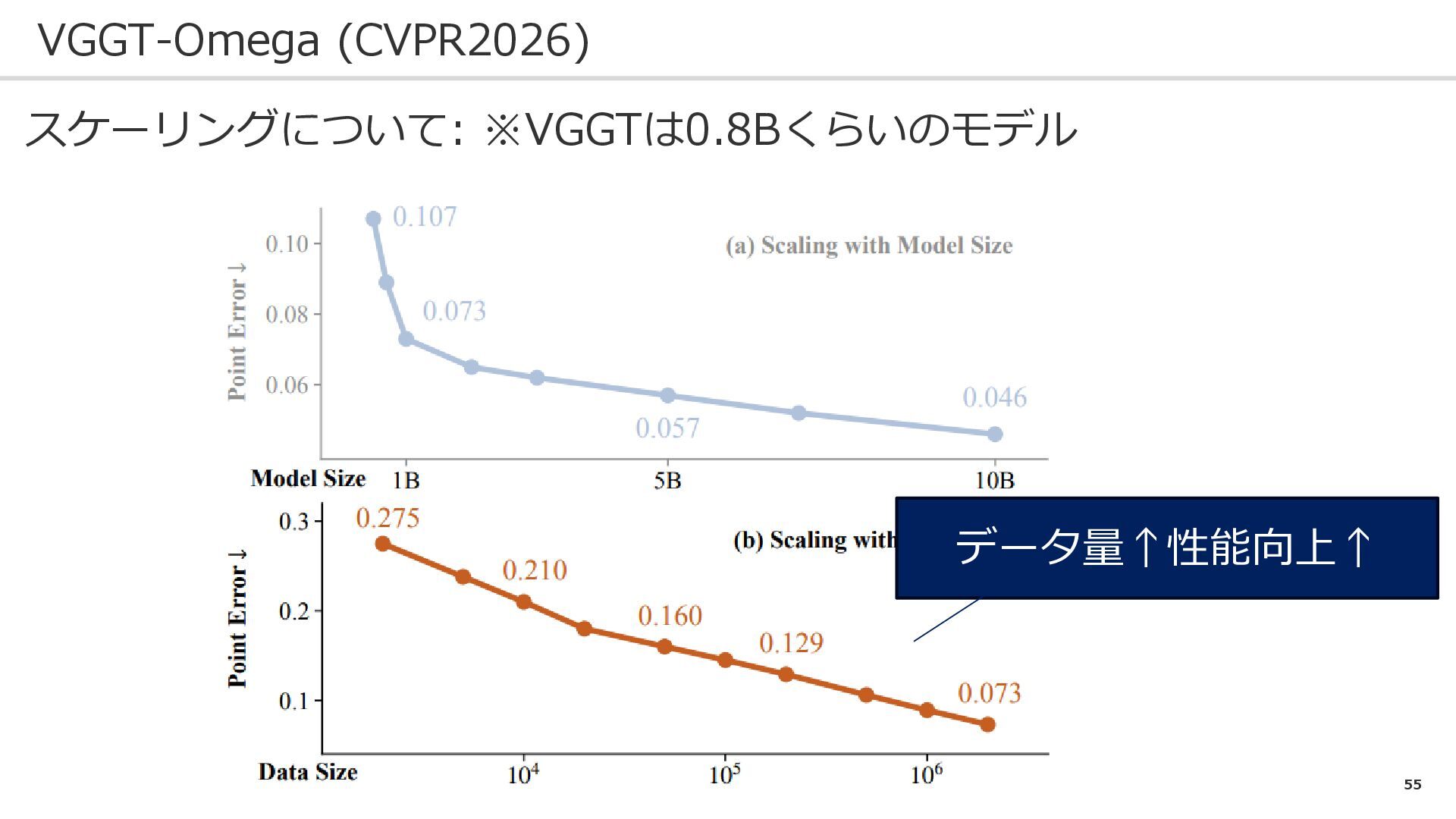
53 VGGT-Omega (CVPR2026) スケーリングについて: ※VGGTは0.8Bくらいのモデル
54 VGGT-Omega (CVPR2026) スケーリングについて: ※VGGTは0.8Bくらいのモデル モデルサイズ↑性能向上↑
55 VGGT-Omega (CVPR2026) スケーリングについて: ※VGGTは0.8Bくらいのモデル データ量↑性能向上↑
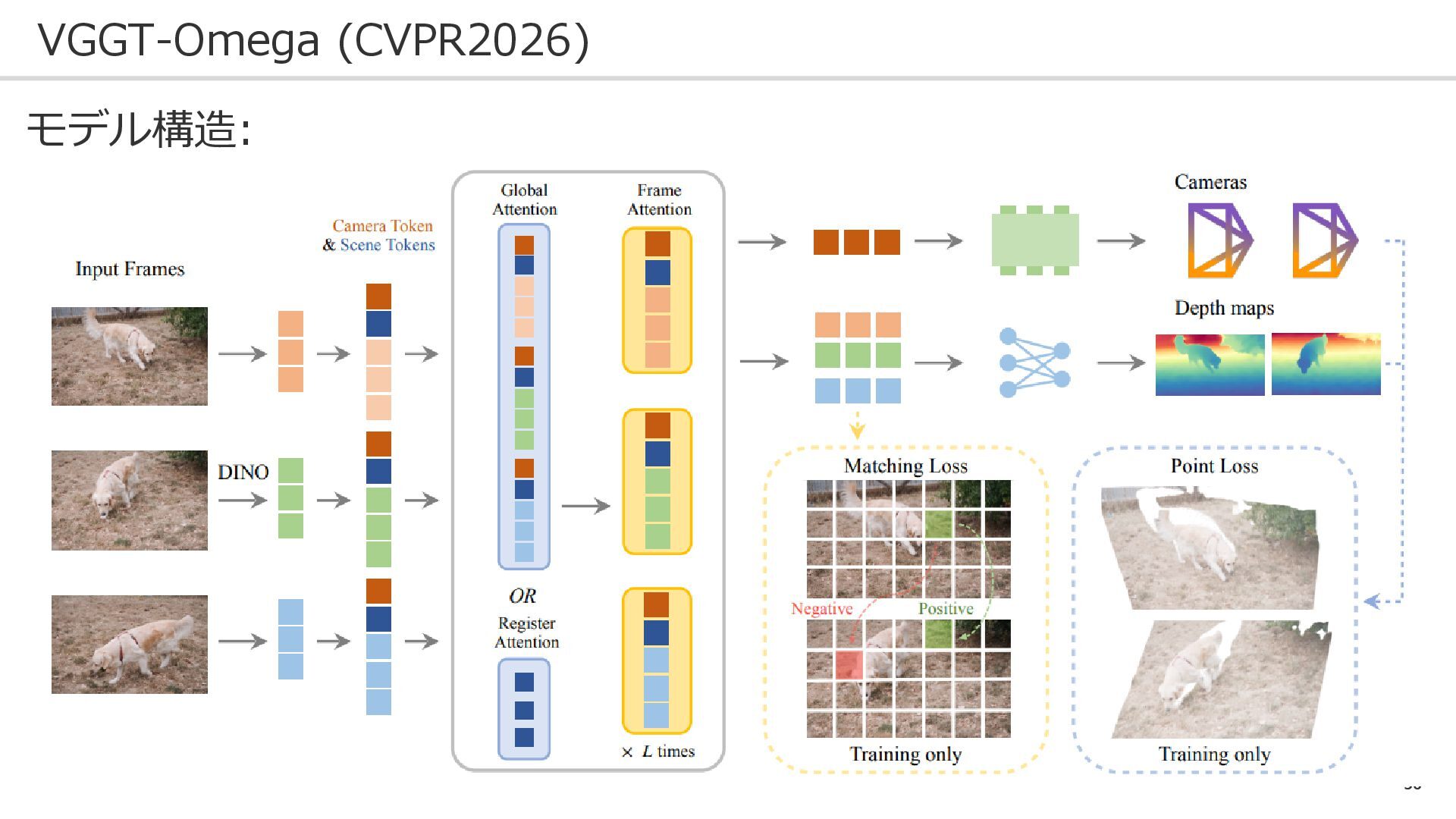
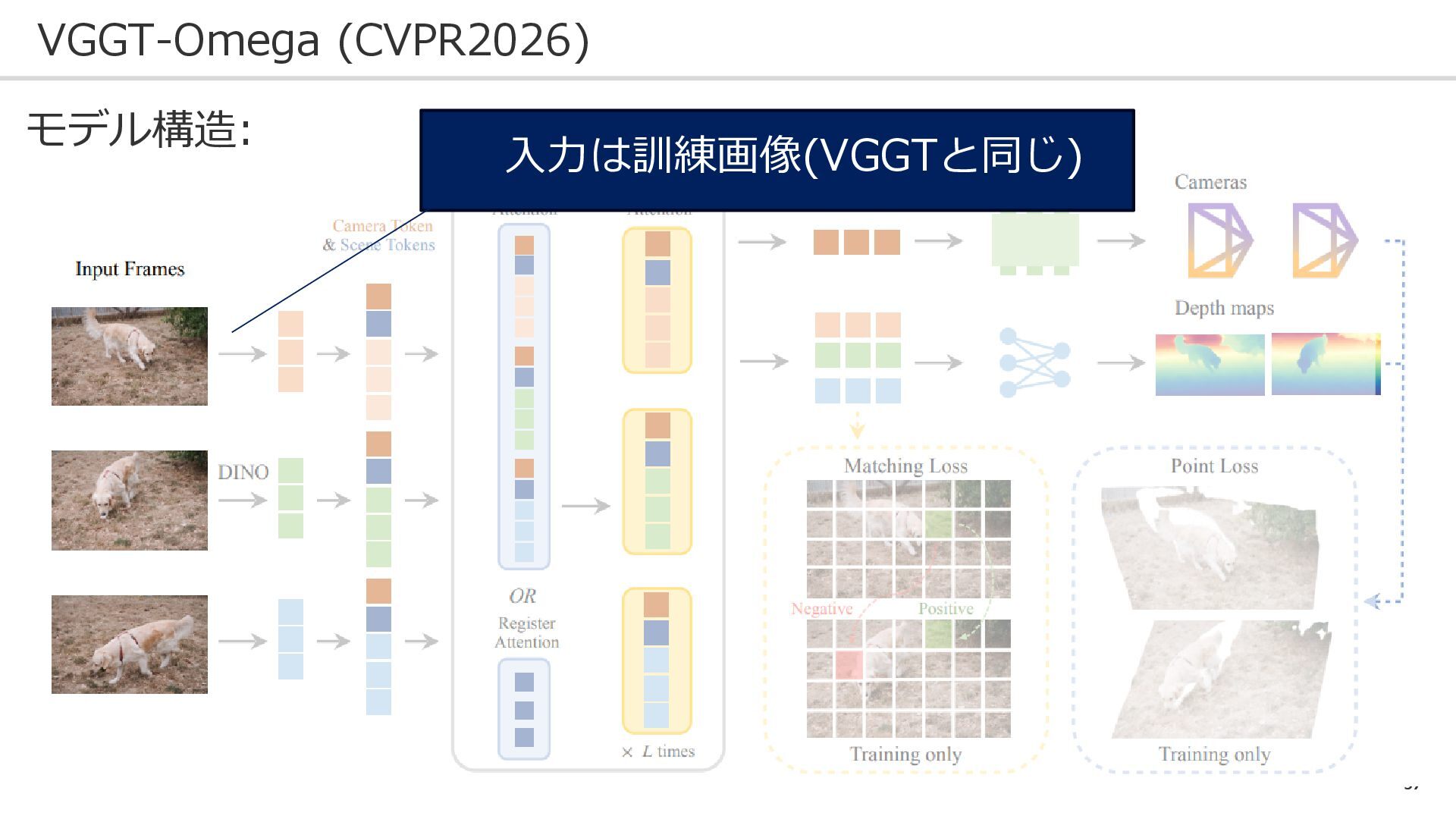
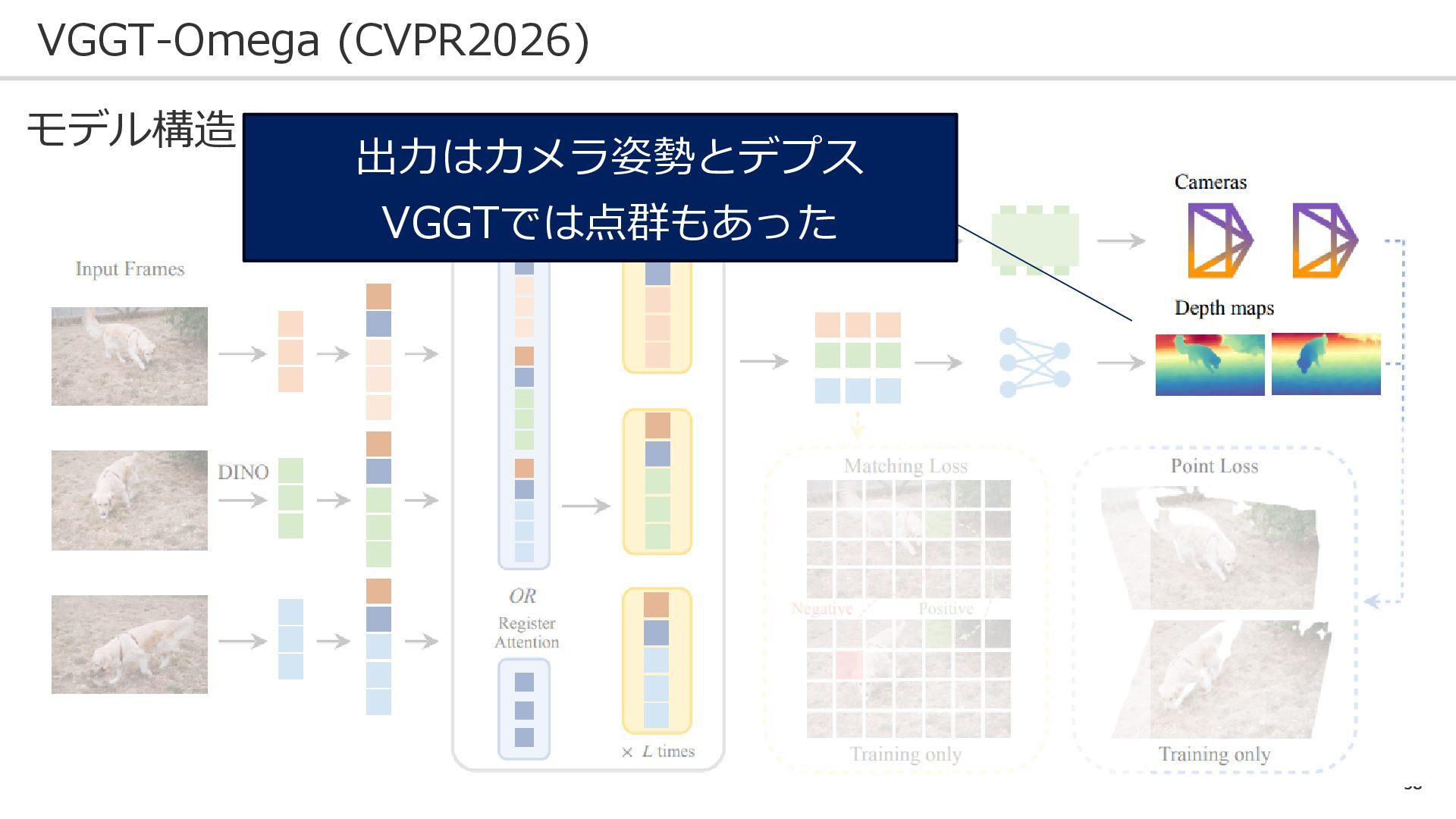
56 VGGT-Omega (CVPR2026) モデル構造:
57 VGGT-Omega (CVPR2026) モデル構造: 入力は訓練画像(VGGTと同じ)
58 VGGT-Omega (CVPR2026) モデル構造: 出力はカメラ姿勢とデプス VGGTでは点群もあった
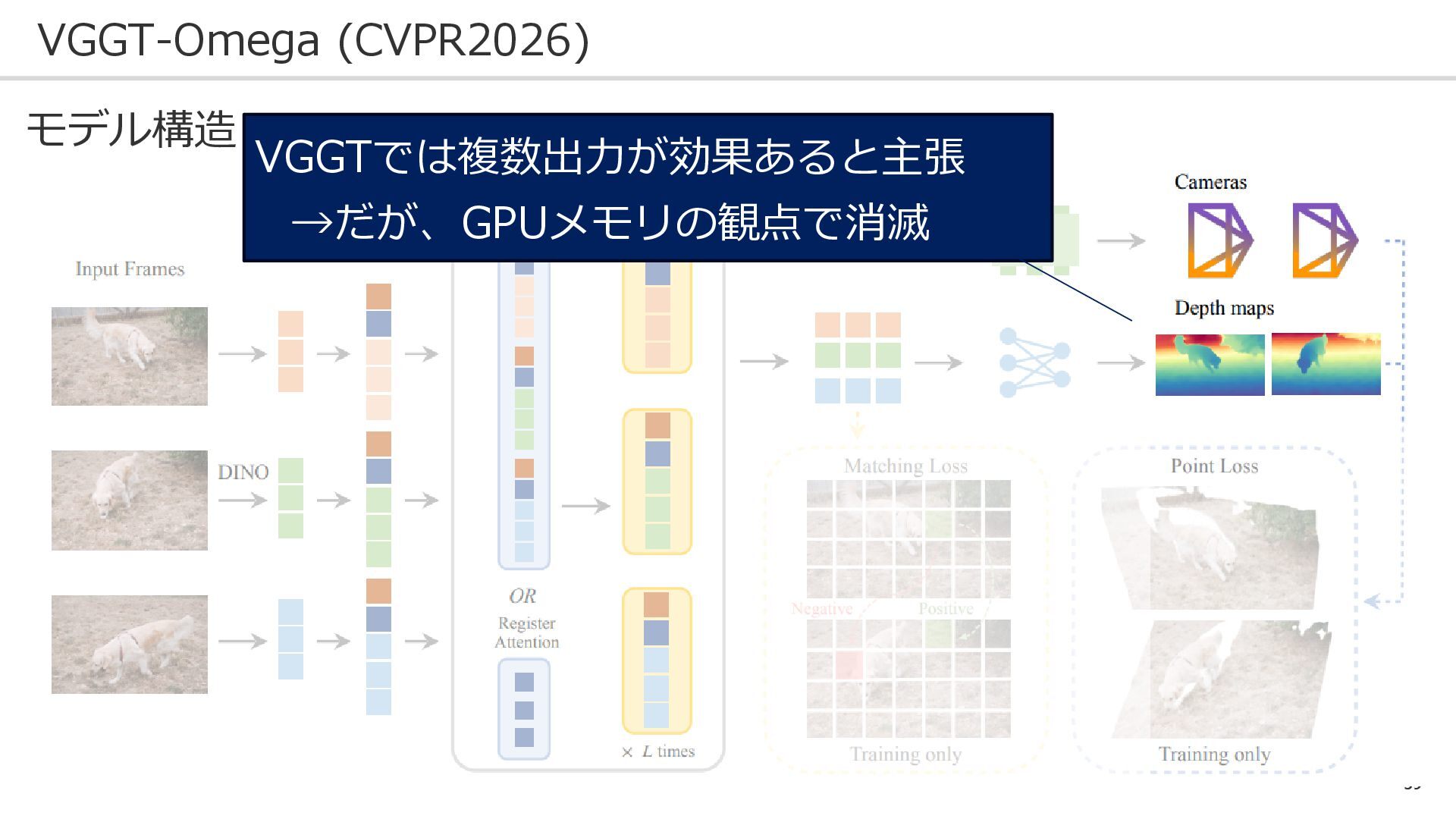
59 VGGT-Omega (CVPR2026) モデル構造: VGGTでは複数出力が効果あると主張 →だが、GPUメモリの観点で消滅
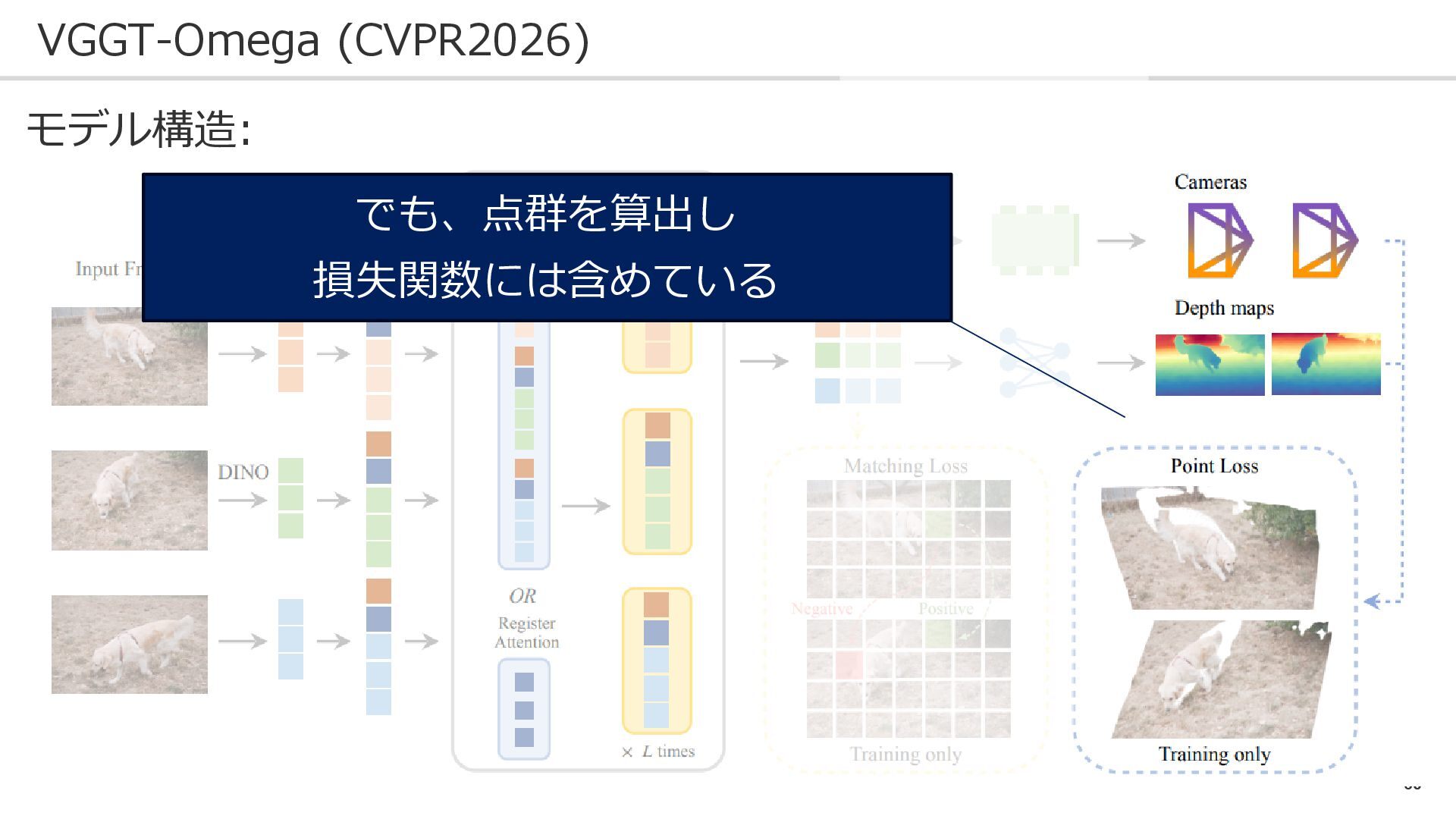
60 VGGT-Omega (CVPR2026) モデル構造: でも、点群を算出し 損失関数には含めている
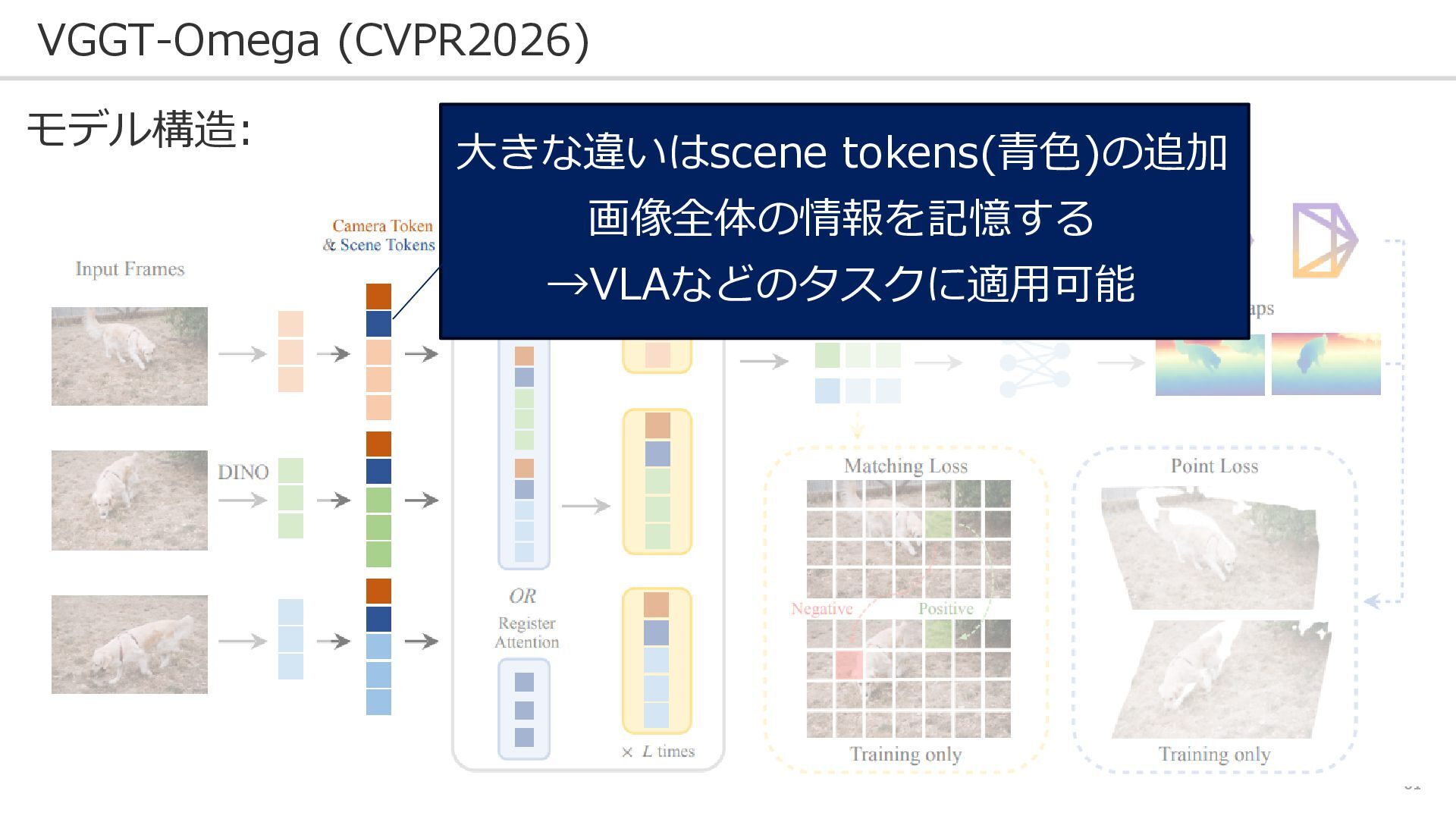
61 VGGT-Omega (CVPR2026) モデル構造: 大きな違いはscene tokens(青色)の追加 画像全体の情報を記憶する →VLAなどのタスクに適用可能
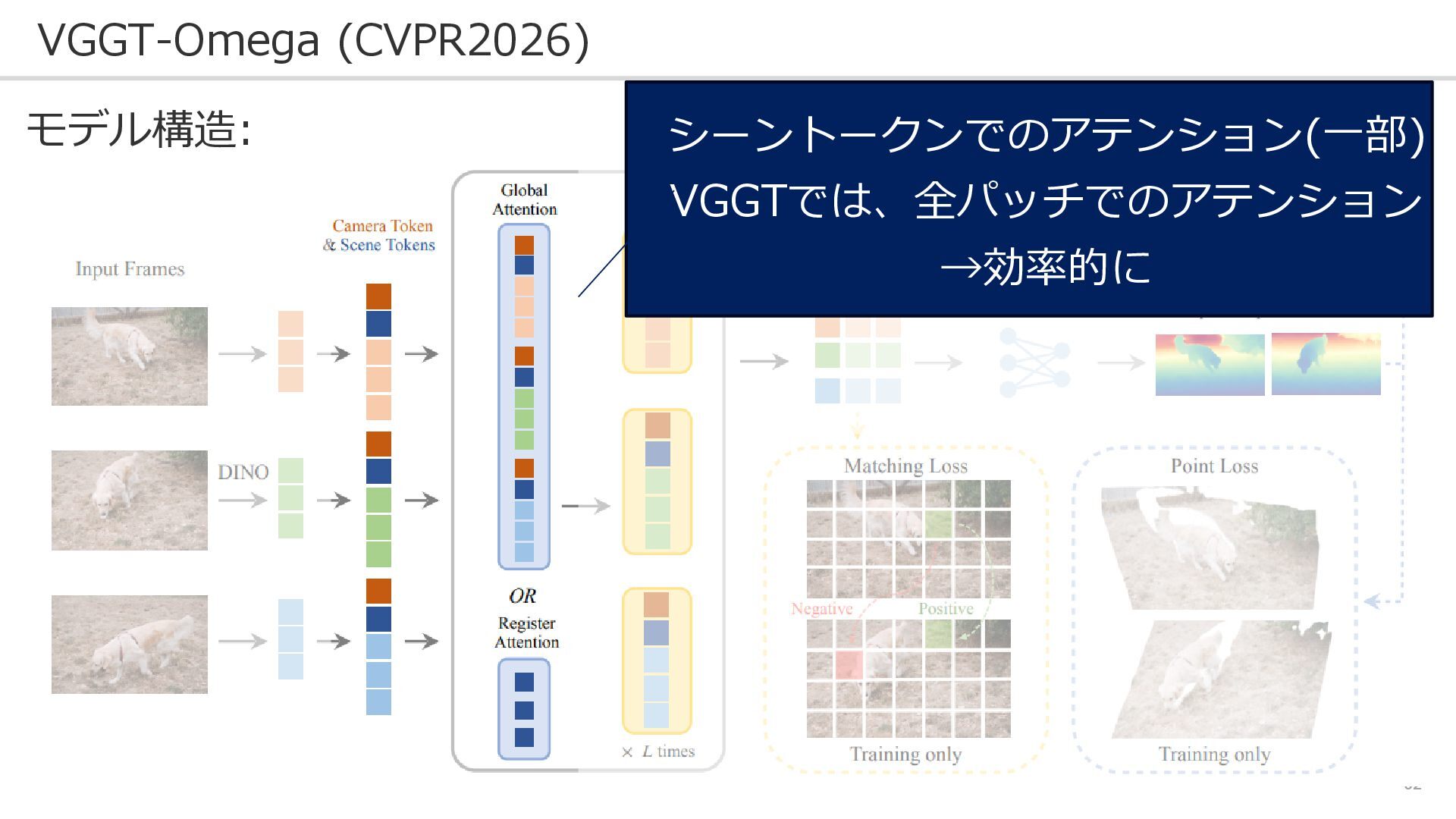
62 VGGT-Omega (CVPR2026) モデル構造: シーントークンでのアテンション(一部) VGGTでは、全パッチでのアテンション →効率的に
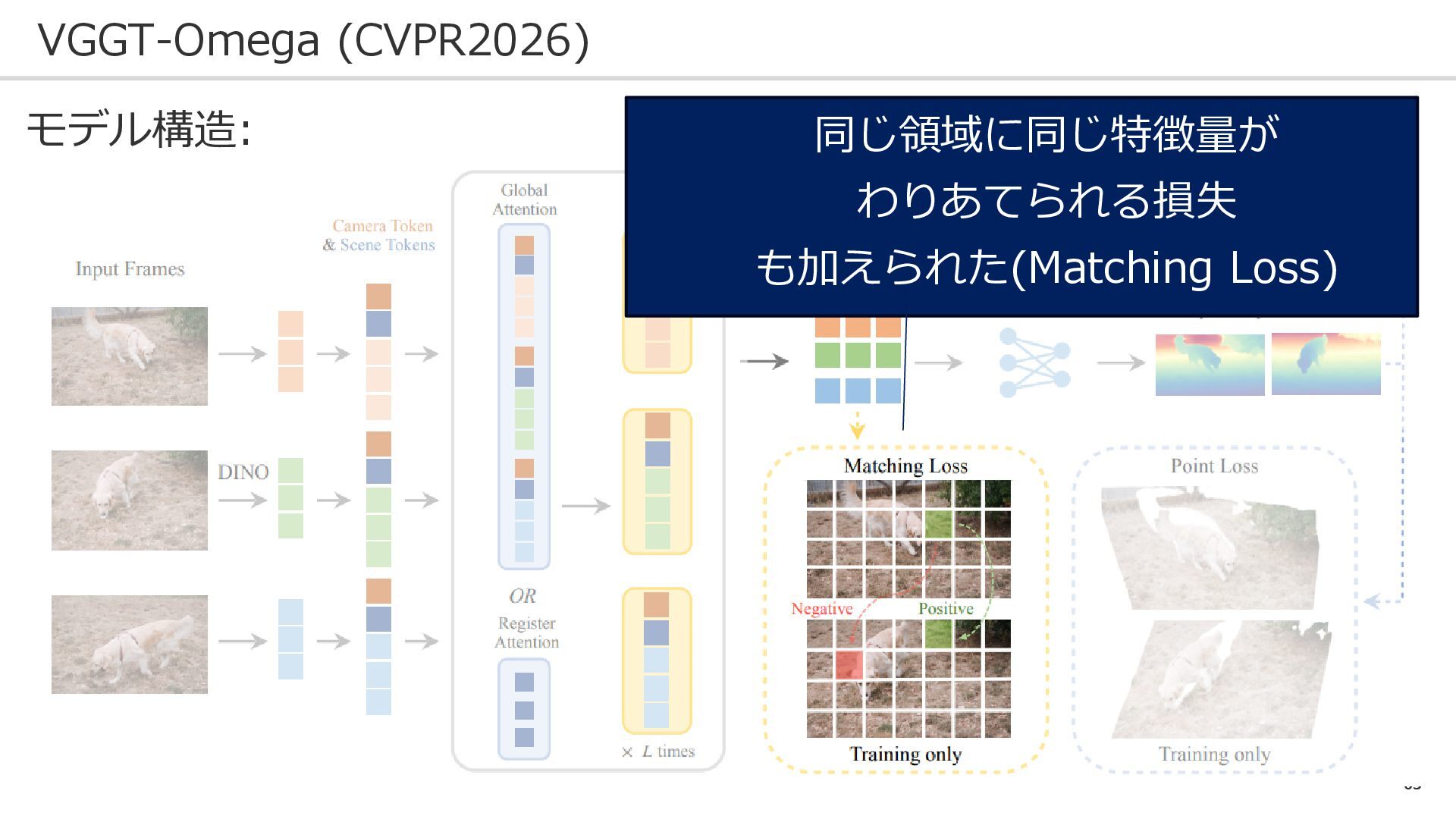
63 VGGT-Omega (CVPR2026) モデル構造: 同じ領域に同じ特徴量が わりあてられる損失 も加えられた(Matching Loss)
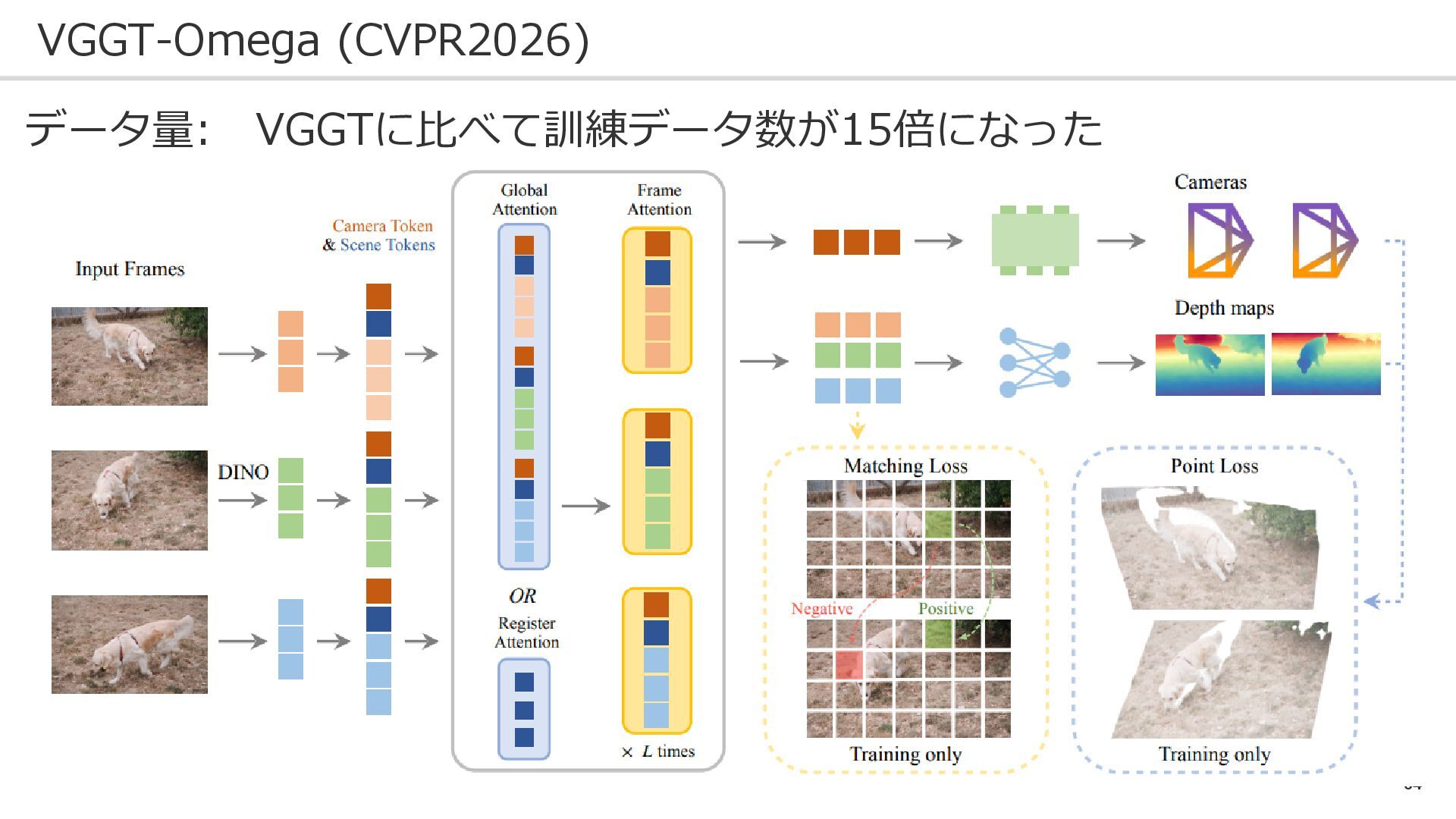
64 VGGT-Omega (CVPR2026) データ量: VGGTに比べて訓練データ数が15倍になった
65 LargerNVS (CVPR2026) 問題設定 : VGGTの能力を活用して新規視点画像生成したい! 課題: ➀ VGGTは重いので、VGGTそのものに新規視点画像生成の 機能を付けると実用に向かない
66 LargerNVS (CVPR2026) 工夫することで、リアルタイムでの新規視点画像生成が可能に!
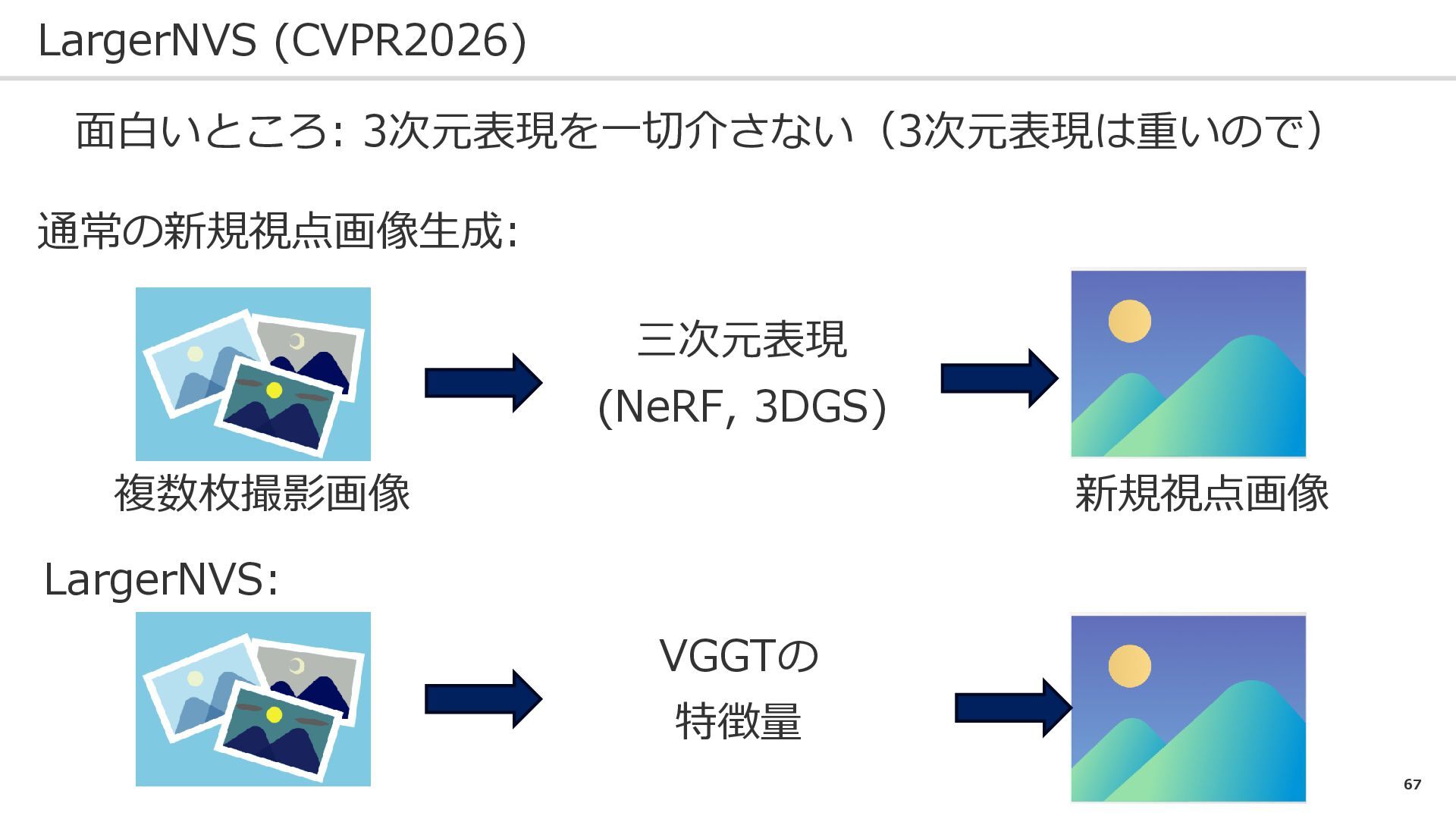
67 LargerNVS (CVPR2026) 面白いところ: 3次元表現を一切介さない(3次元表現は重いので) 通常の新規視点画像生成: LargerNVS: 複数枚撮影画像 新規視点画像 三次元表現
(NeRF, 3DGS) VGGTの 特徴量
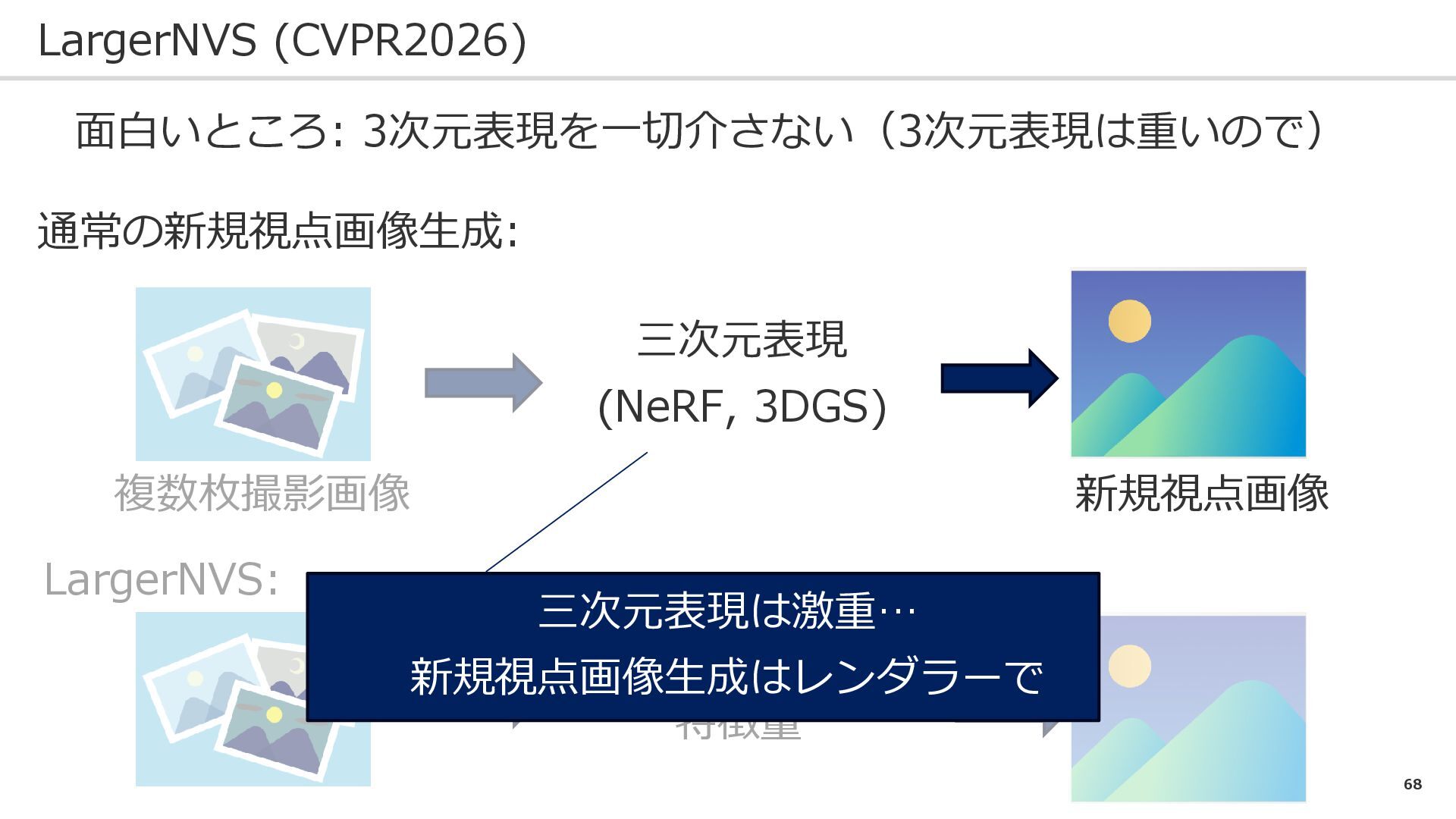
68 LargerNVS (CVPR2026) 面白いところ: 3次元表現を一切介さない(3次元表現は重いので) 通常の新規視点画像生成: LargerNVS: 複数枚撮影画像 新規視点画像 三次元表現
(NeRF, 3DGS) VGGTの 特徴量 三次元表現は激重… 新規視点画像生成はレンダラーで
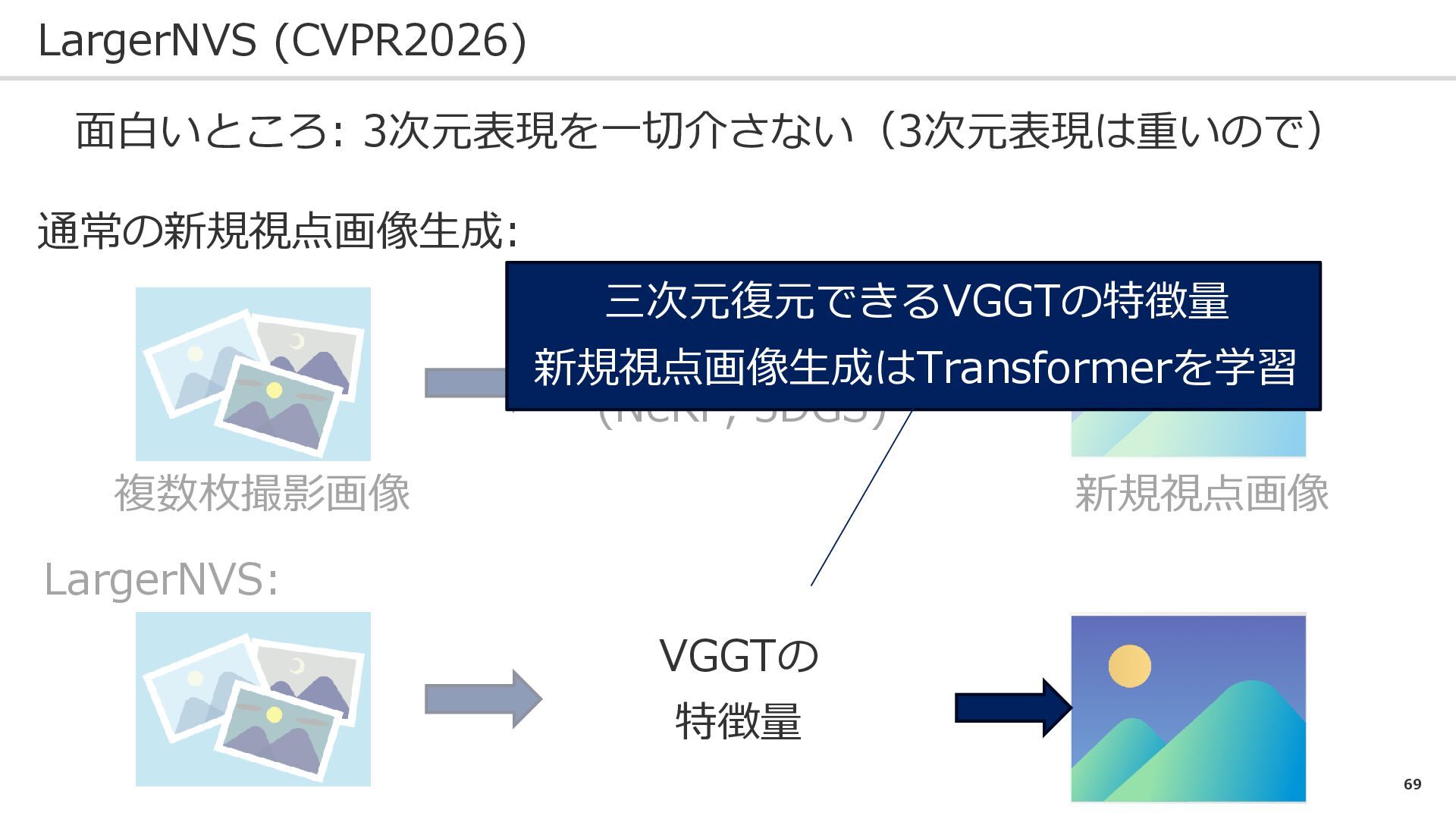
69 LargerNVS (CVPR2026) 面白いところ: 3次元表現を一切介さない(3次元表現は重いので) 通常の新規視点画像生成: LargerNVS: 複数枚撮影画像 新規視点画像 三次元表現
(NeRF, 3DGS) VGGTの 特徴量 三次元復元できるVGGTの特徴量 新規視点画像生成はTransformerを学習
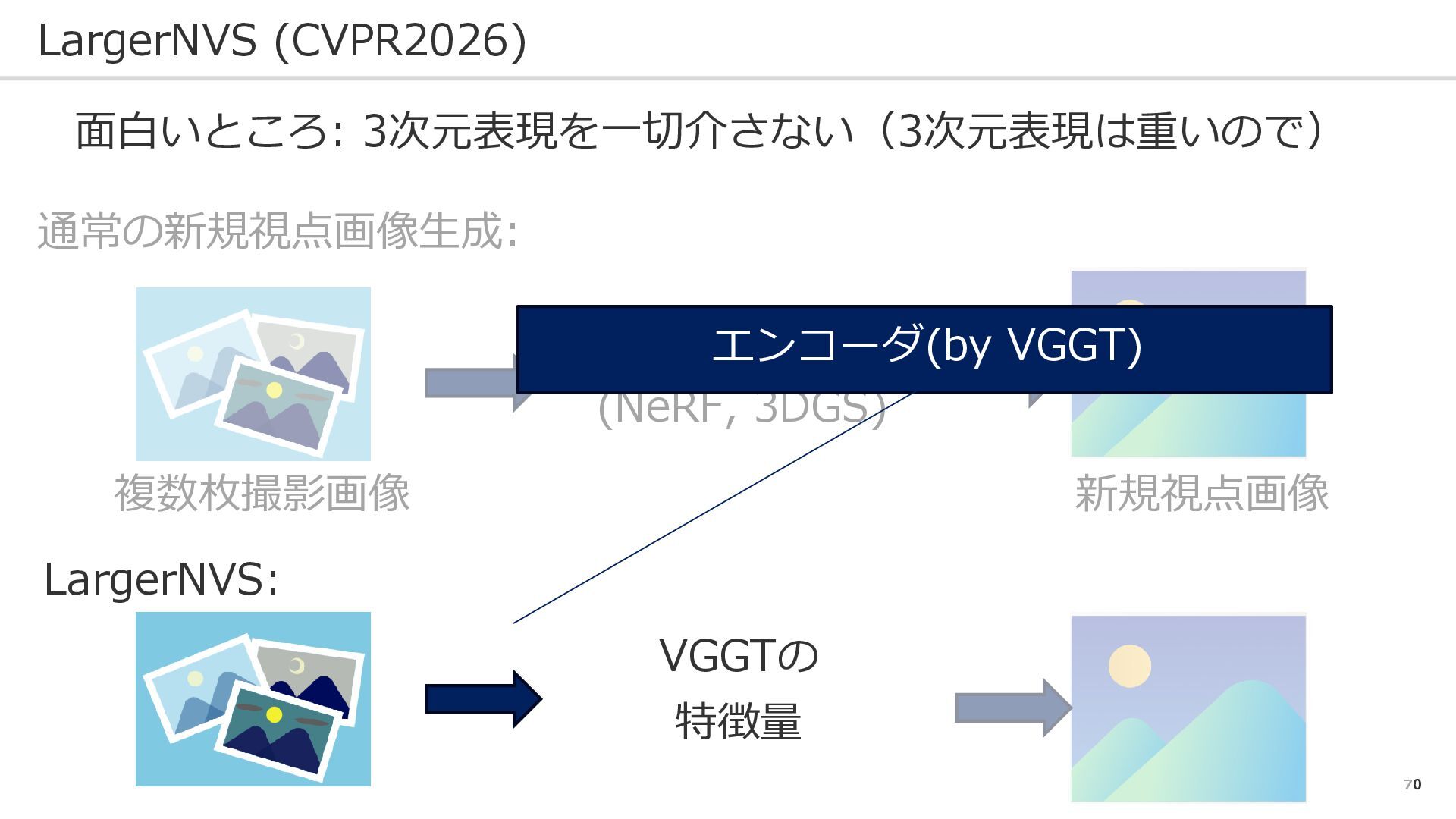
70 LargerNVS (CVPR2026) 面白いところ: 3次元表現を一切介さない(3次元表現は重いので) 通常の新規視点画像生成: LargerNVS: 複数枚撮影画像 新規視点画像 三次元表現
(NeRF, 3DGS) VGGTの 特徴量 エンコーダ(by VGGT)
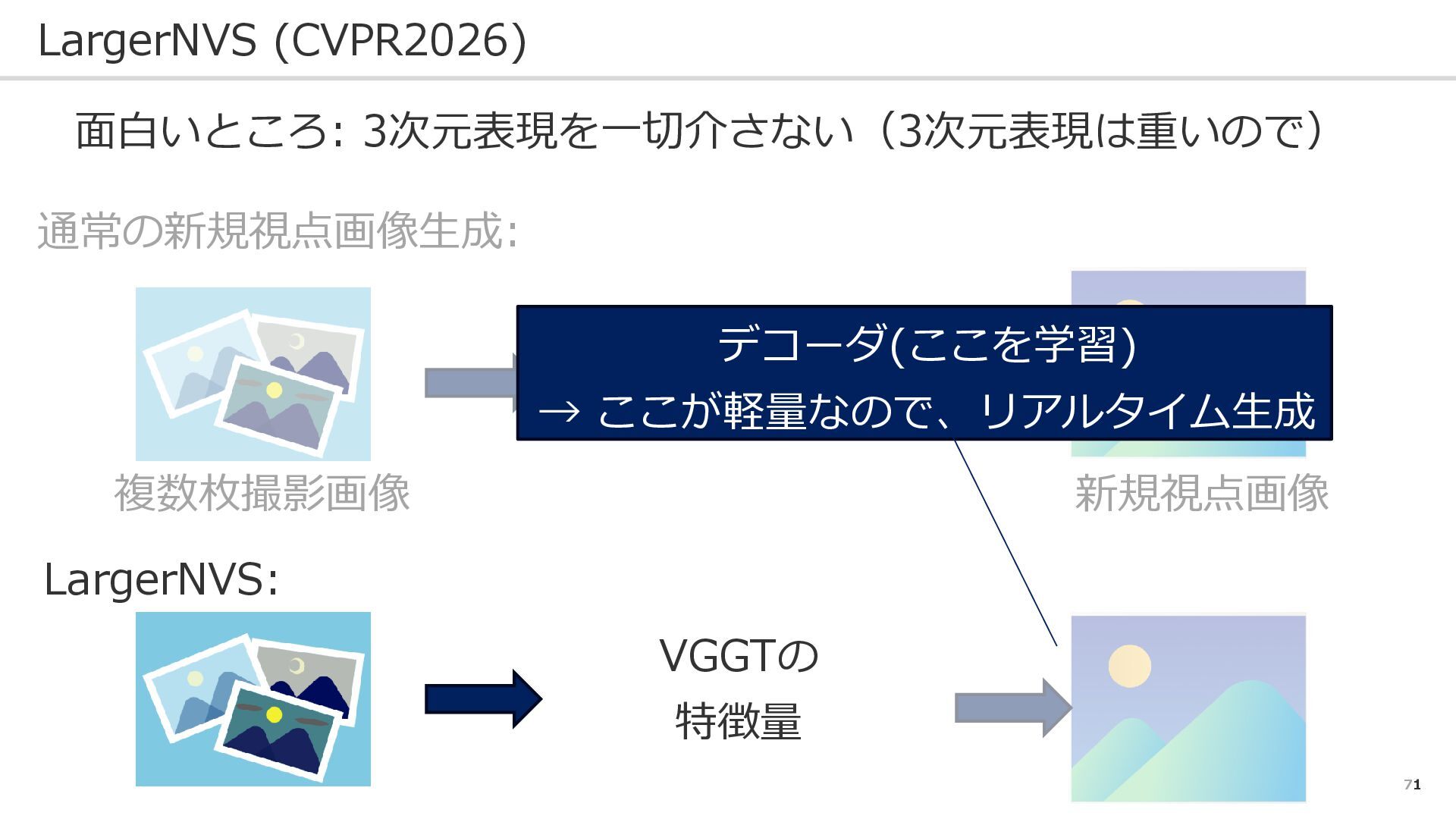
71 LargerNVS (CVPR2026) 面白いところ: 3次元表現を一切介さない(3次元表現は重いので) 通常の新規視点画像生成: LargerNVS: 複数枚撮影画像 新規視点画像 三次元表現
(NeRF, 3DGS) VGGTの 特徴量 デコーダ(ここを学習) → ここが軽量なので、リアルタイム生成
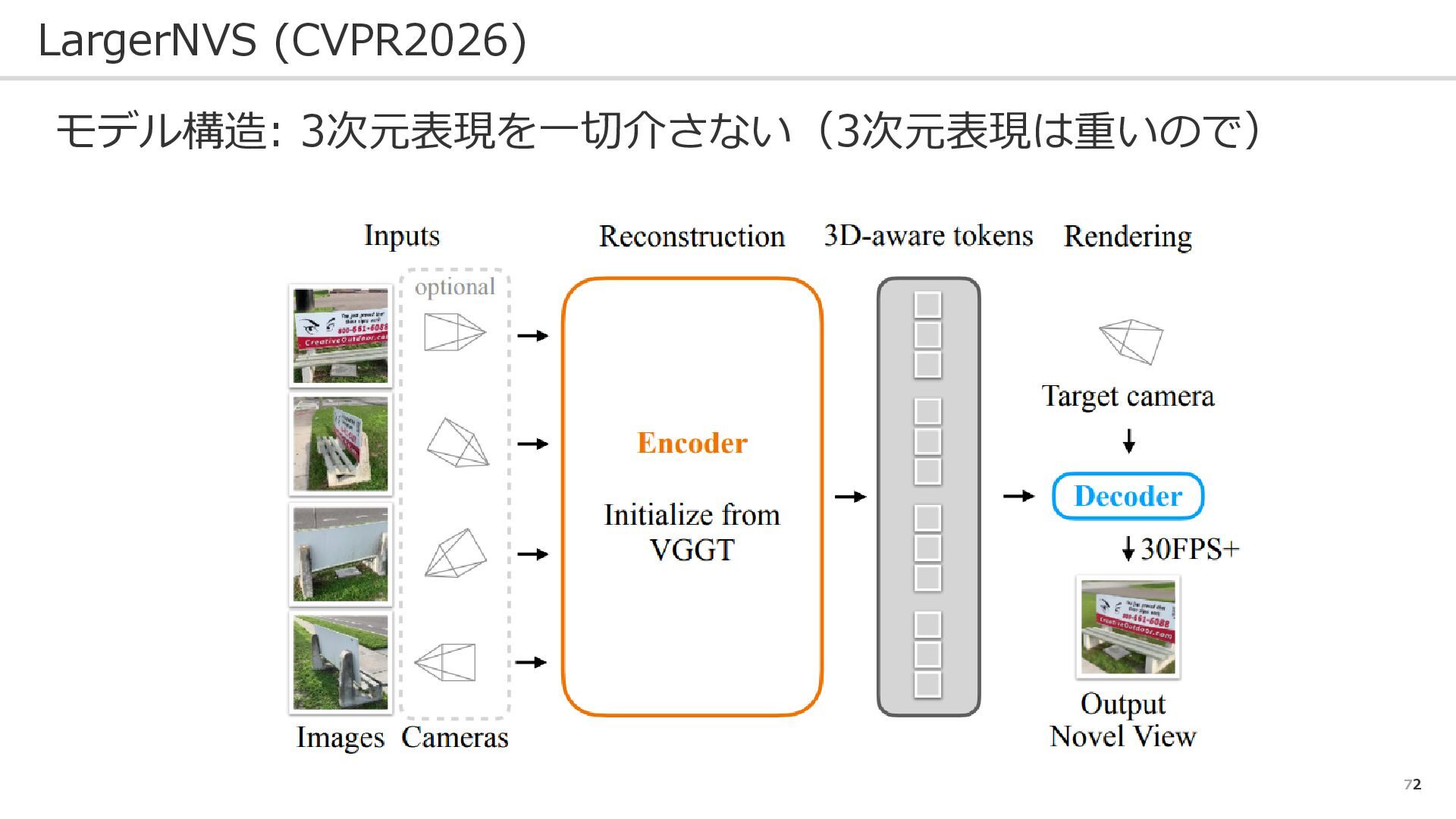
72 LargerNVS (CVPR2026) モデル構造: 3次元表現を一切介さない(3次元表現は重いので)
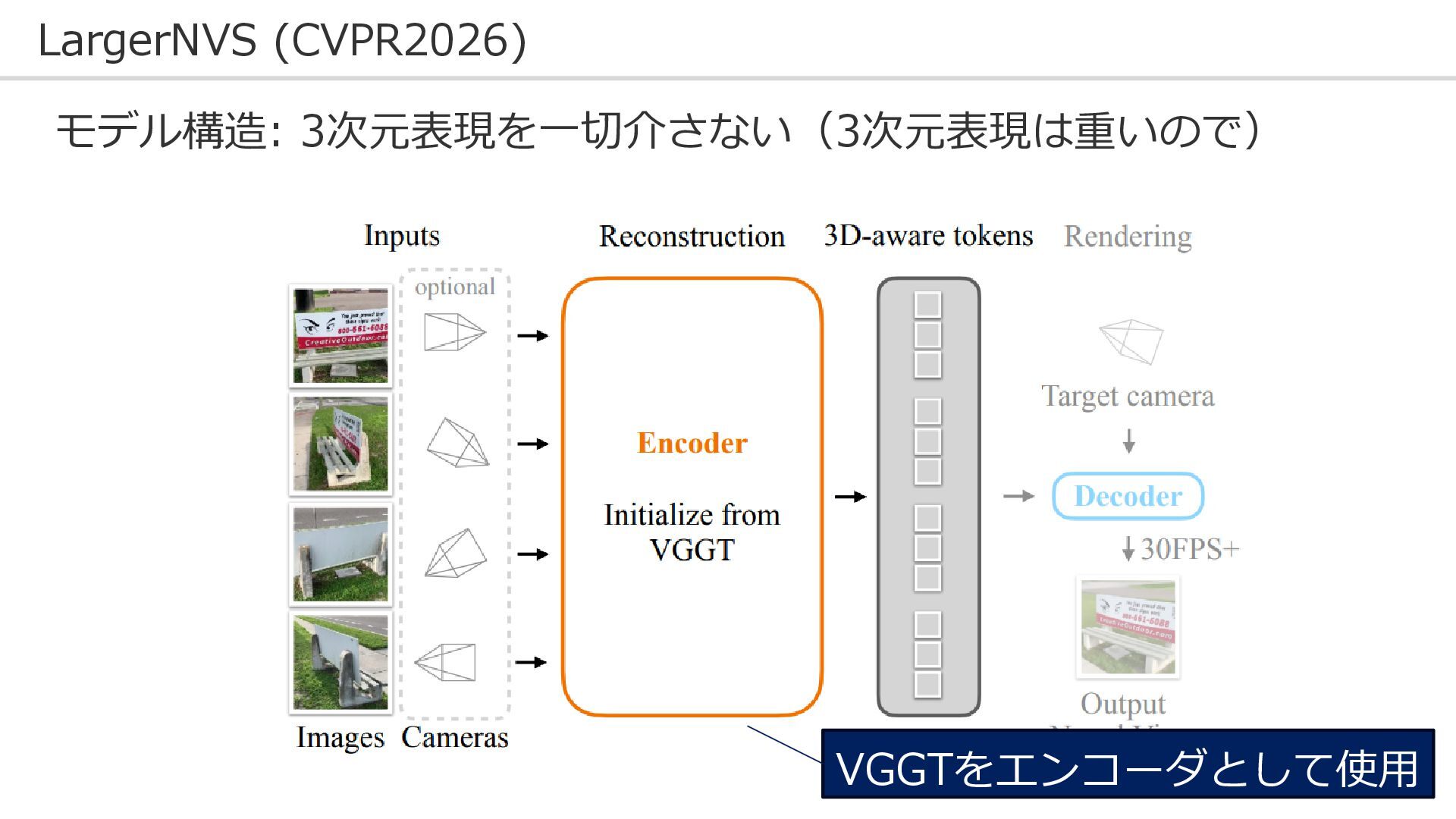
73 LargerNVS (CVPR2026) モデル構造: 3次元表現を一切介さない(3次元表現は重いので) VGGTをエンコーダとして使用
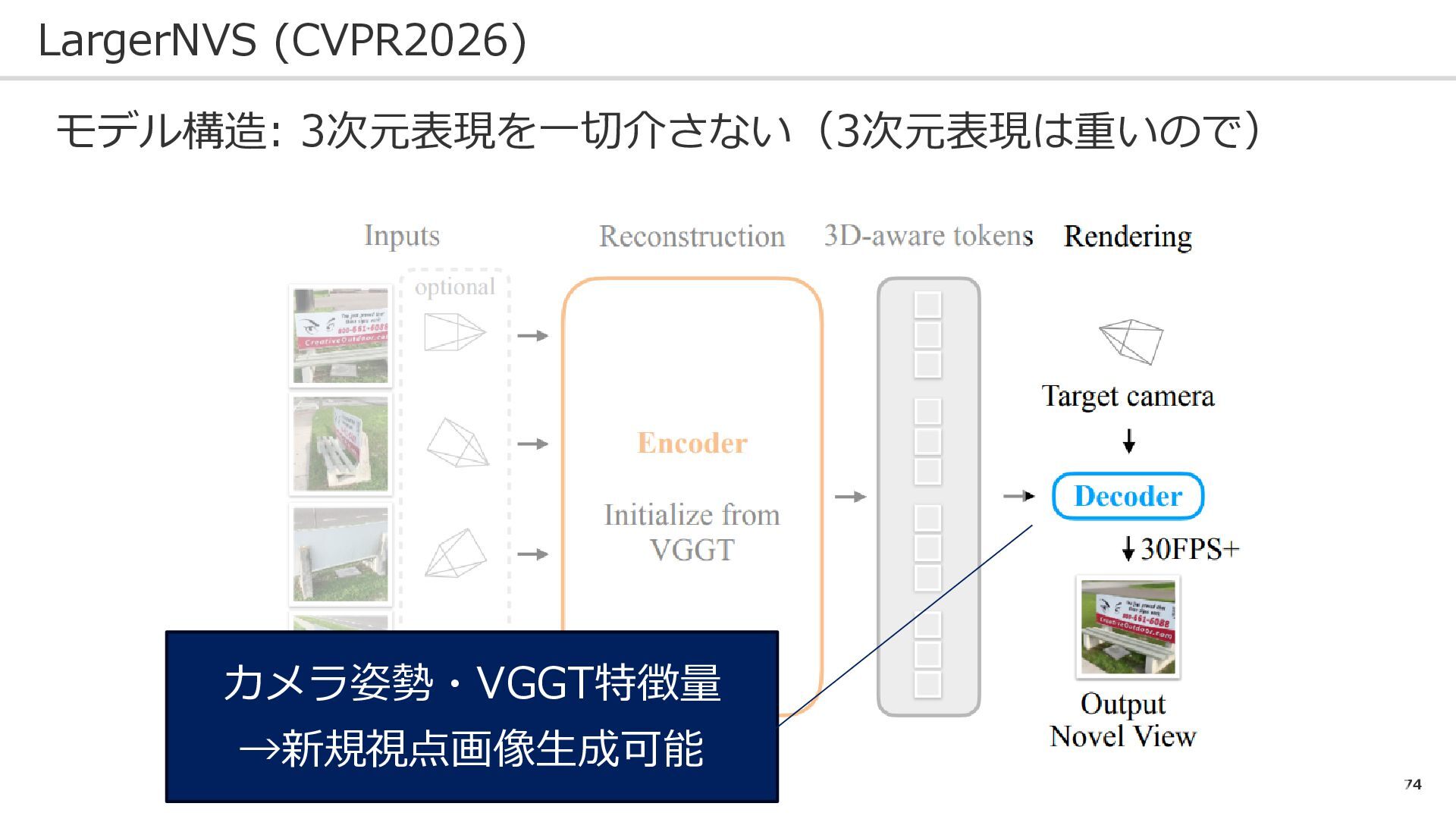
74 LargerNVS (CVPR2026) モデル構造: 3次元表現を一切介さない(3次元表現は重いので) カメラ姿勢・VGGT特徴量 →新規視点画像生成可能
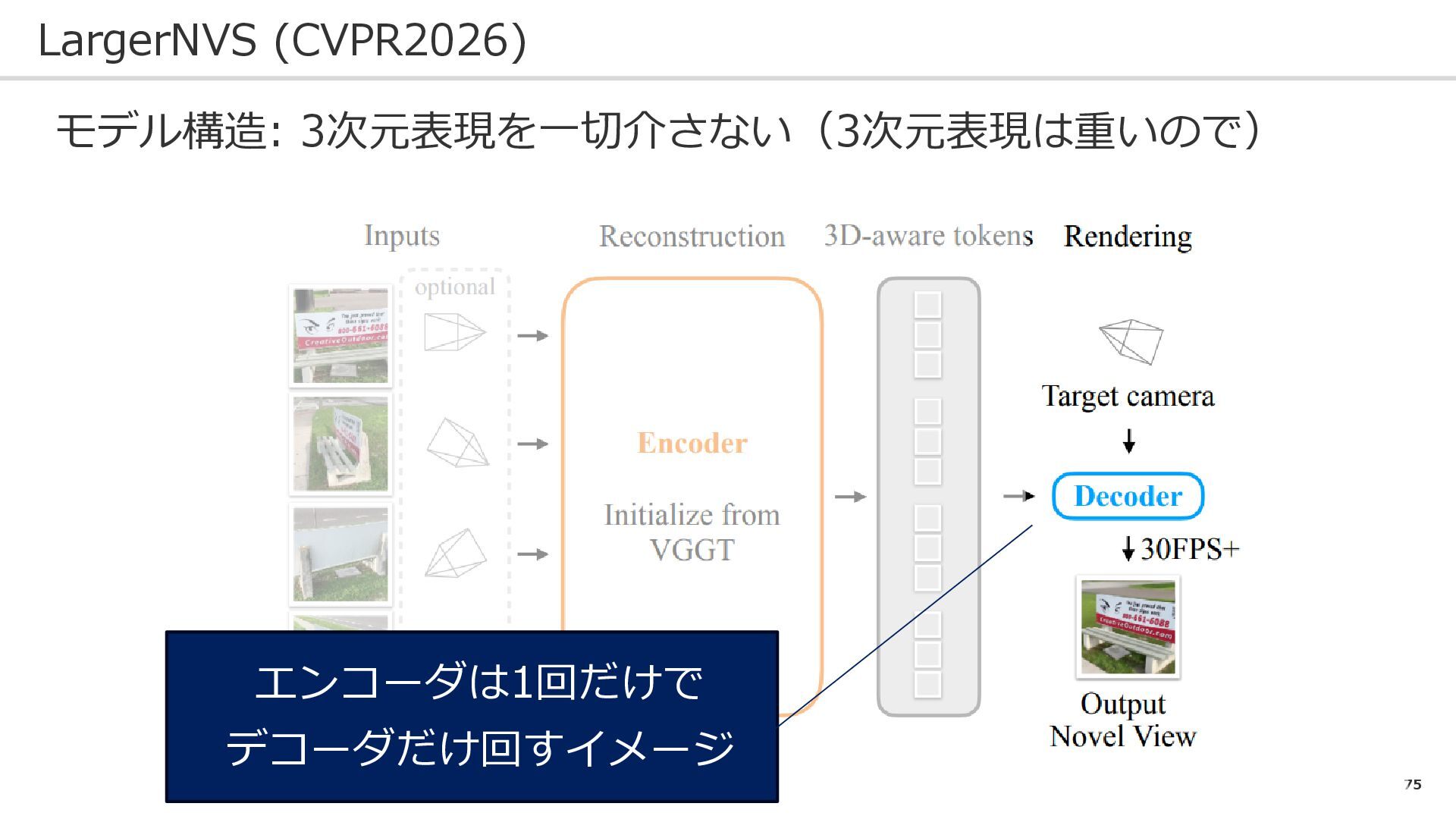
75 LargerNVS (CVPR2026) モデル構造: 3次元表現を一切介さない(3次元表現は重いので) エンコーダは1回だけで デコーダだけ回すイメージ
76 LargerNVS (CVPR2026) 応用例は幅広い:
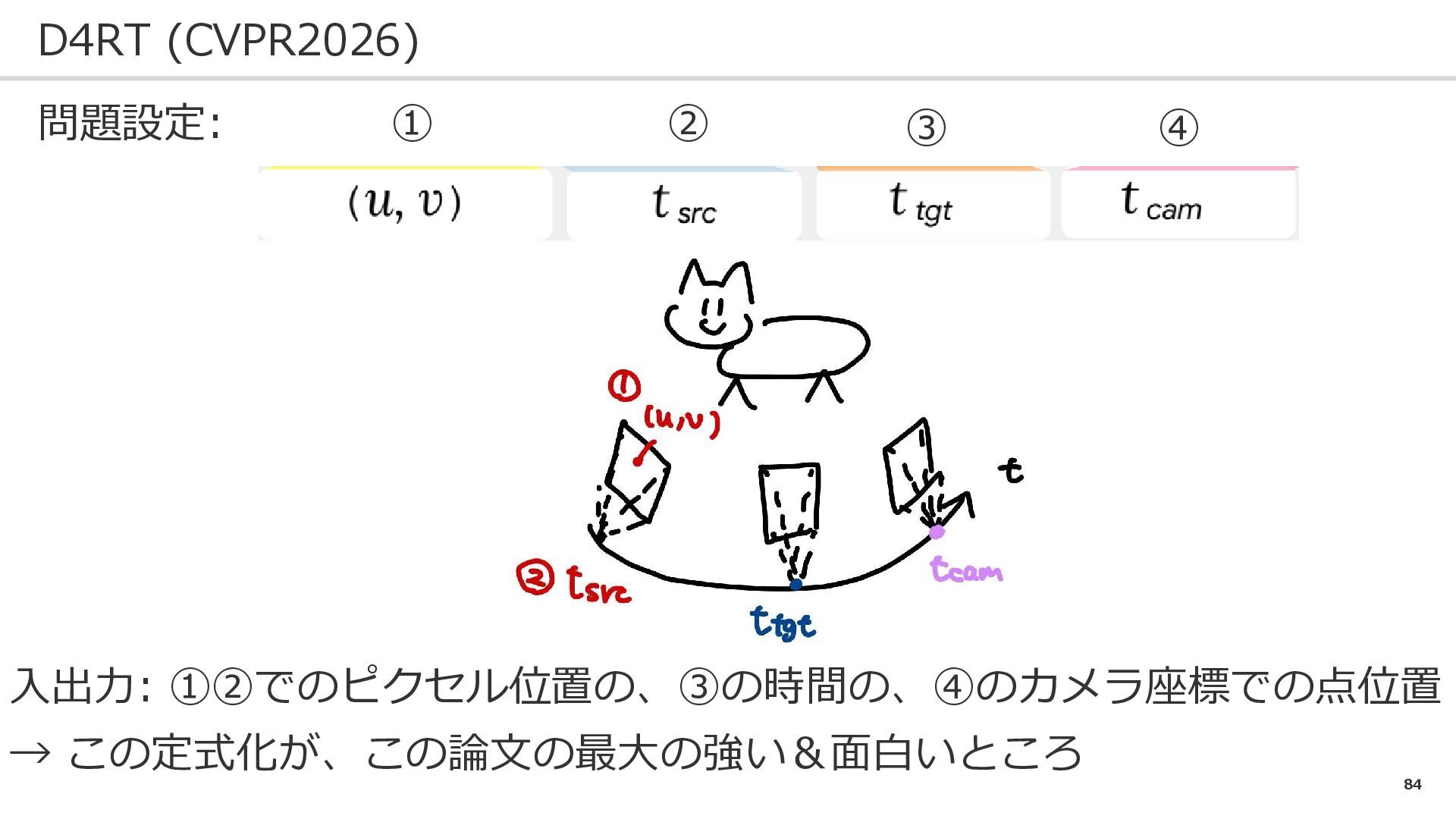
77 D4RT (CVPR2026) 問題設定: VGGTのタスクを4次元に応用したい! 課題: ➀3D・4Dタスクごとに別々のモジュールを使うのは変 ②シーンの大規模化を考えると、VGGTの全フレームのデプス・ 点群を出力するのは重すぎる
78 D4RT (CVPR2026) トラッキング・点群推定・デプス推定・カメラ姿勢推定を統一的枠組みに 最初ぱっとみてもわからない可能性が高いので、もう一度流します
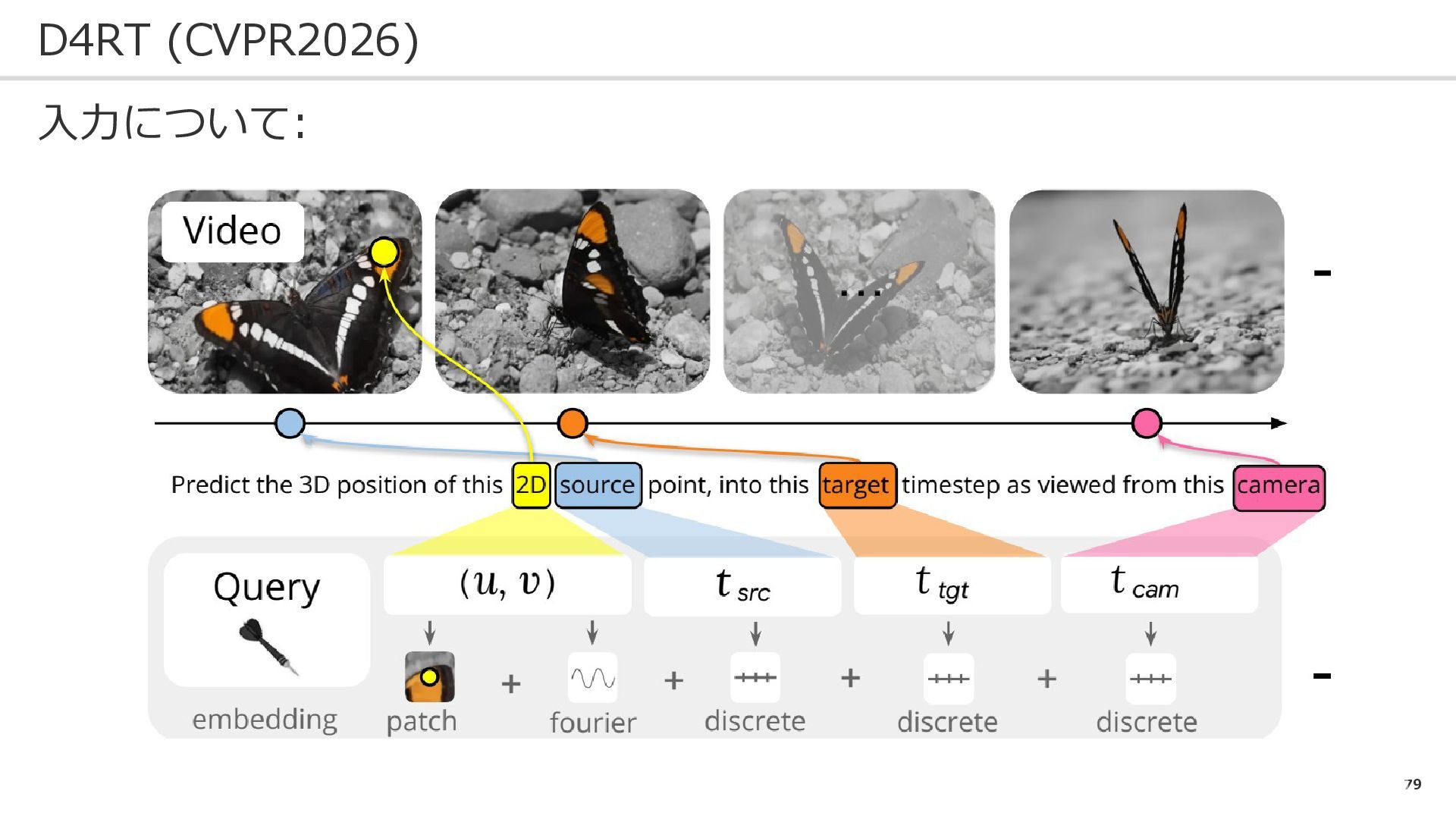
79 D4RT (CVPR2026) 入力について:
80 D4RT (CVPR2026) 入力について: 入力1: 動画
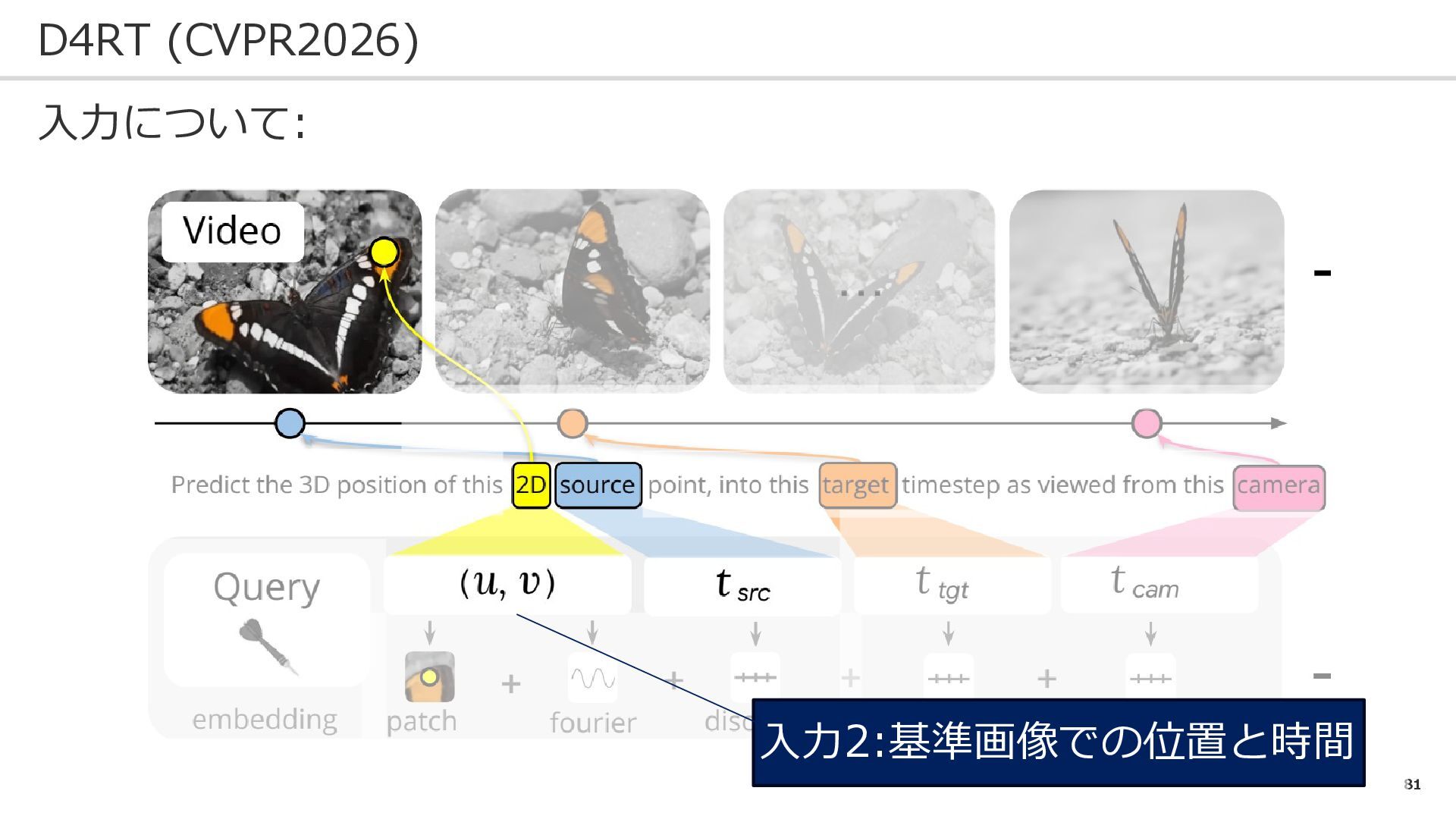
81 D4RT (CVPR2026) 入力について: 入力2:基準画像での位置と時間
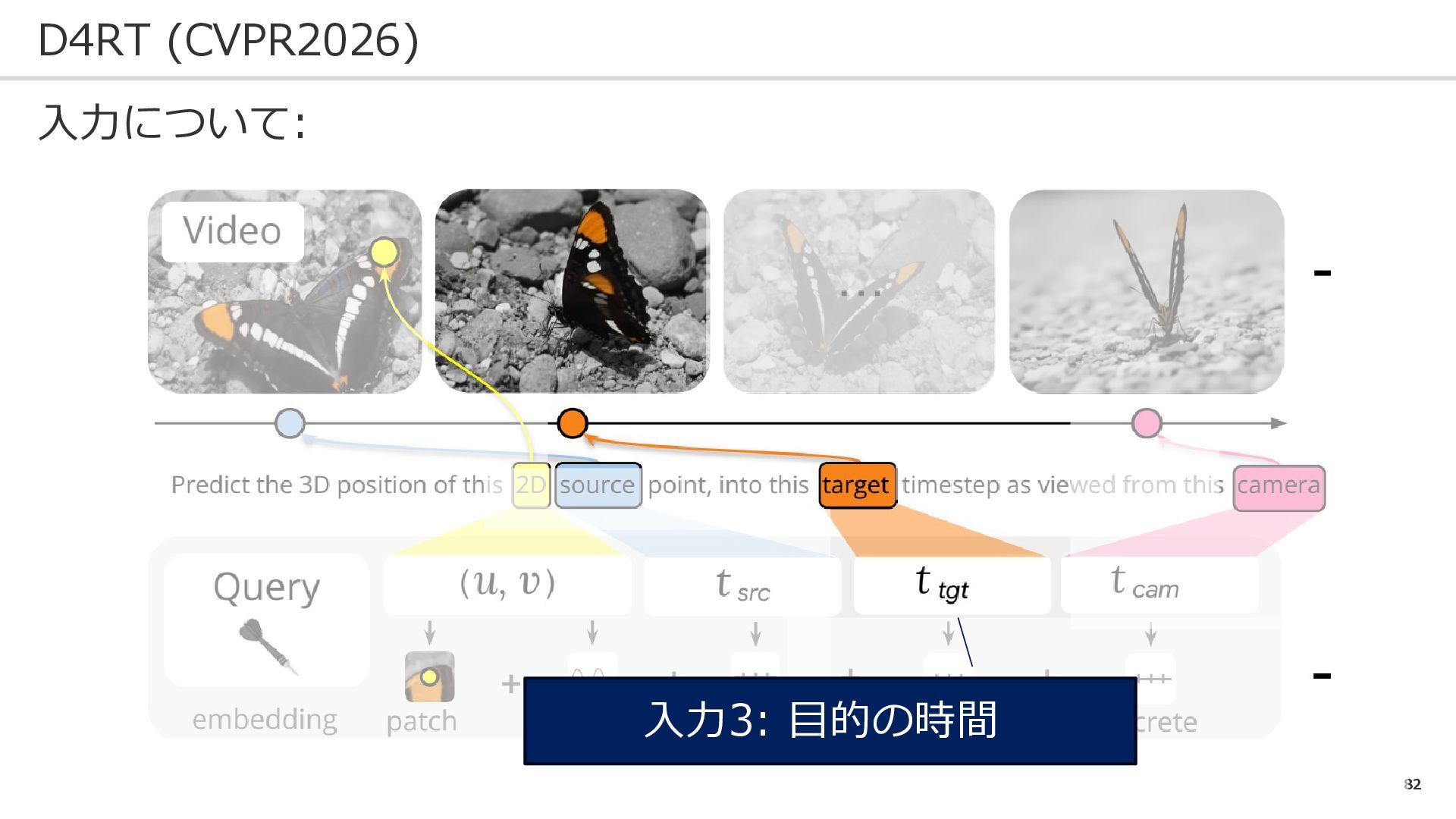
82 D4RT (CVPR2026) 入力について: 入力3: 目的の時間
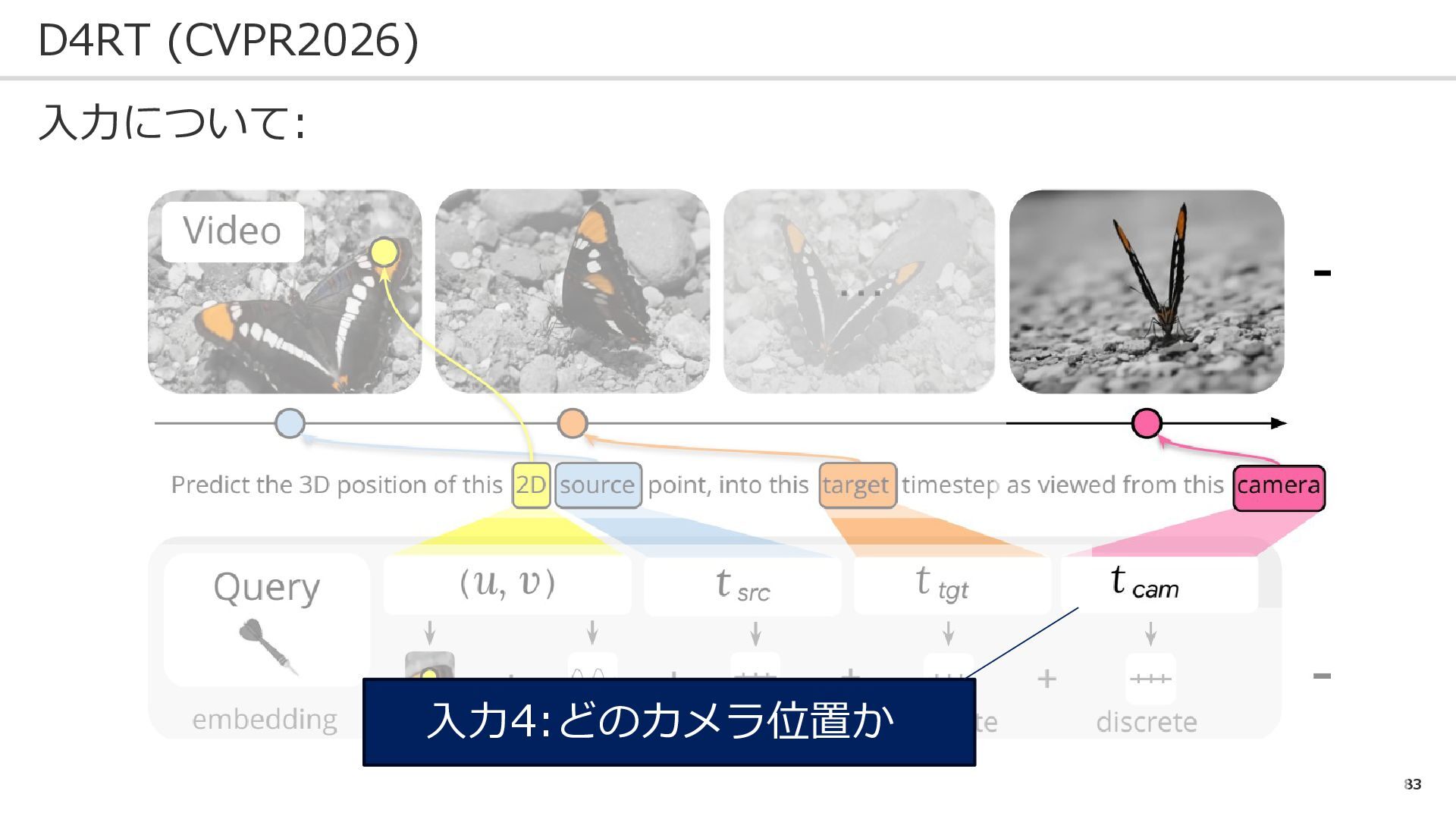
83 D4RT (CVPR2026) 入力について: 入力4:どのカメラ位置か
84 D4RT (CVPR2026) 問題設定: 入出力: ➀②でのピクセル位置の、③の時間の、④のカメラ座標での点位置 → この定式化が、この論文の最大の強い&面白いところ ➀ ②
③ ④
85 D4RT (CVPR2026) 具体例: 1つのピクセル 1-> T 1つの点のカメラに合わせた3D位置→ トラッキング
86 D4RT (CVPR2026) 具体例: 全ピクセル 1-> T 固定 全ての点について、固定カメラ座標で、時間を動かす →
点群復元
87 D4RT (CVPR2026) 具体例: 全ピクセル 1-> T 全画像の全ての点の、それぞれのカメラ座標での位置 → デプス推定
88 D4RT (CVPR2026) トラッキング・点群推定・デプス推定・カメラ姿勢推定を統一的枠組みに
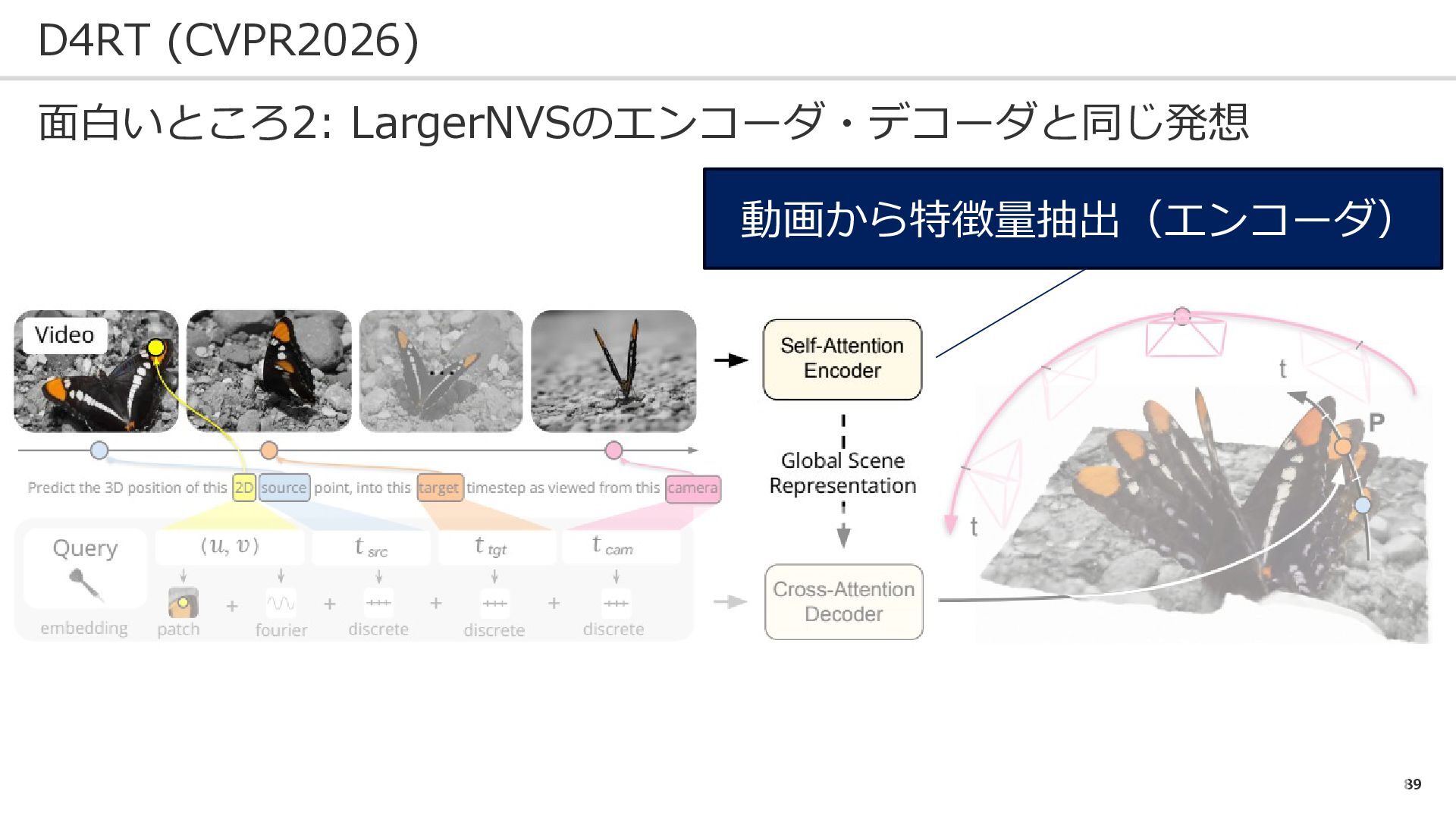
89 D4RT (CVPR2026) 面白いところ2: LargerNVSのエンコーダ・デコーダと同じ発想 動画から特徴量抽出(エンコーダ)
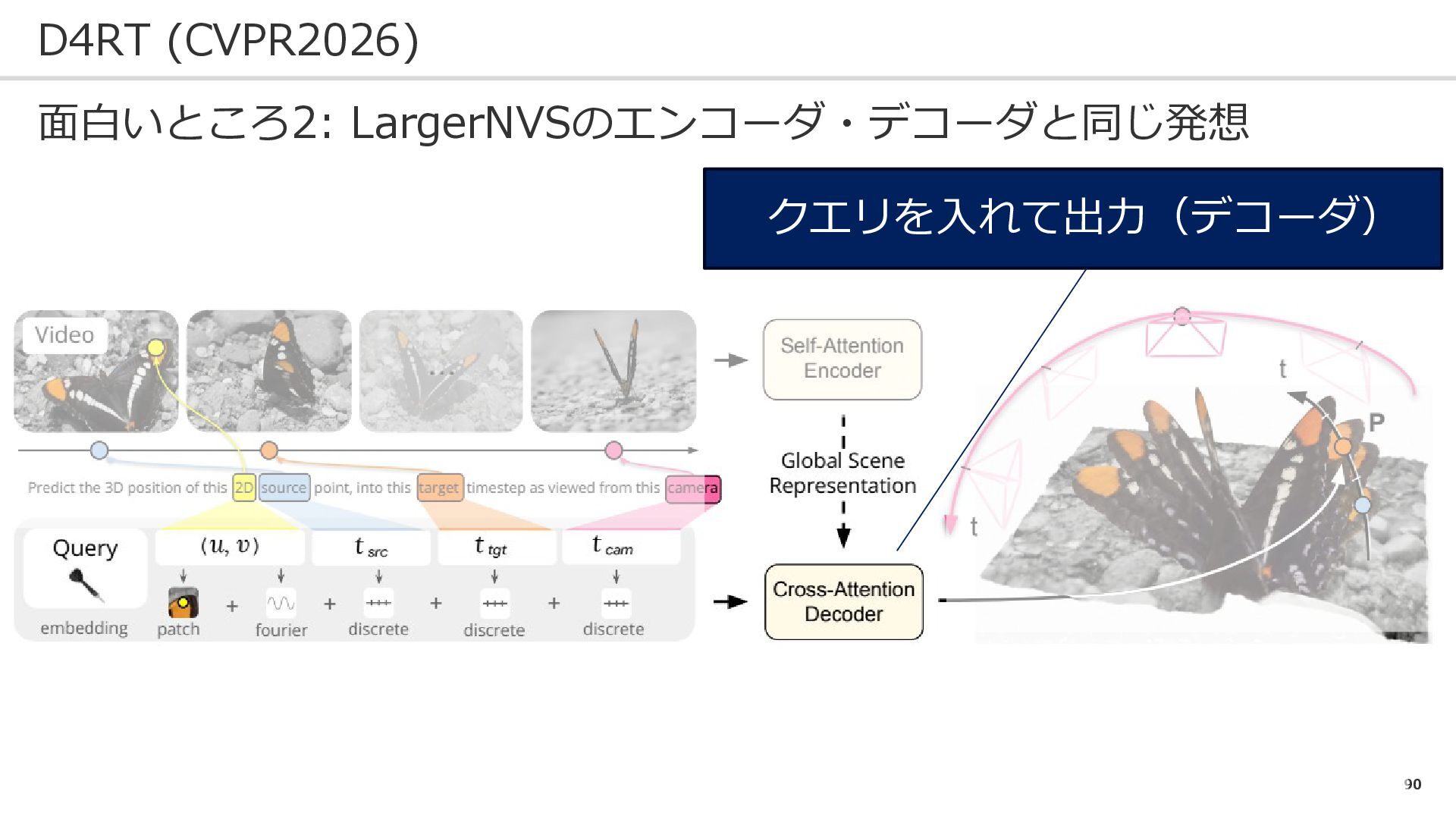
90 D4RT (CVPR2026) 面白いところ2: LargerNVSのエンコーダ・デコーダと同じ発想 クエリを入れて出力(デコーダ)
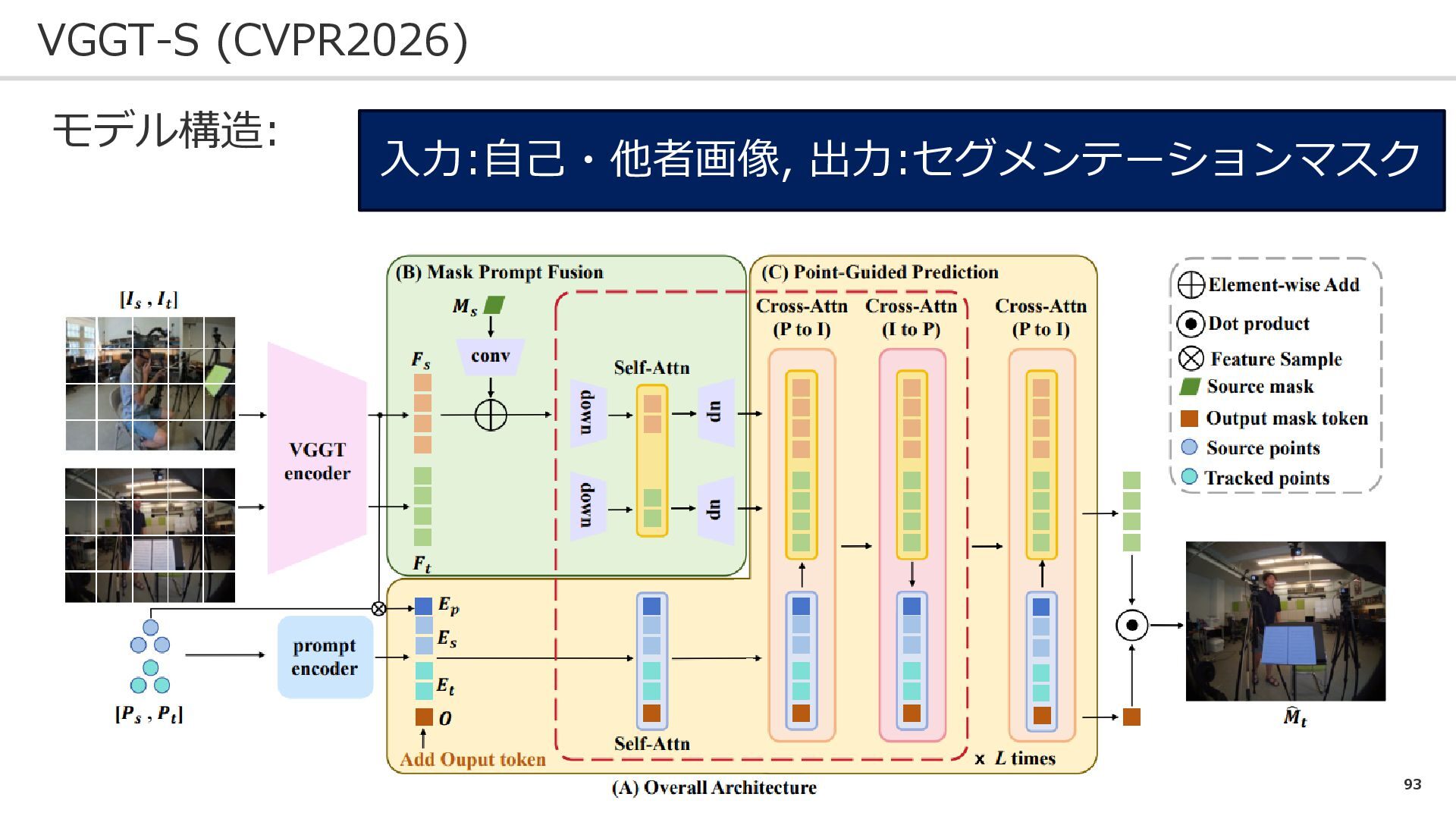
91 VGGT-S (CVPR2026) 問題設定: 自己・他者視点の同物体セグメンテーション 課題: ➀自己・他者視点の撮影画像は、遮蔽や視点位置の変化が大きく難しい
92 VGGT-S (CVPR2026) VGGTの三次元を反映した特徴量を、セグメンテーションにも活用!
93 VGGT-S (CVPR2026) モデル構造: 入力:自己・他者画像, 出力:セグメンテーションマスク
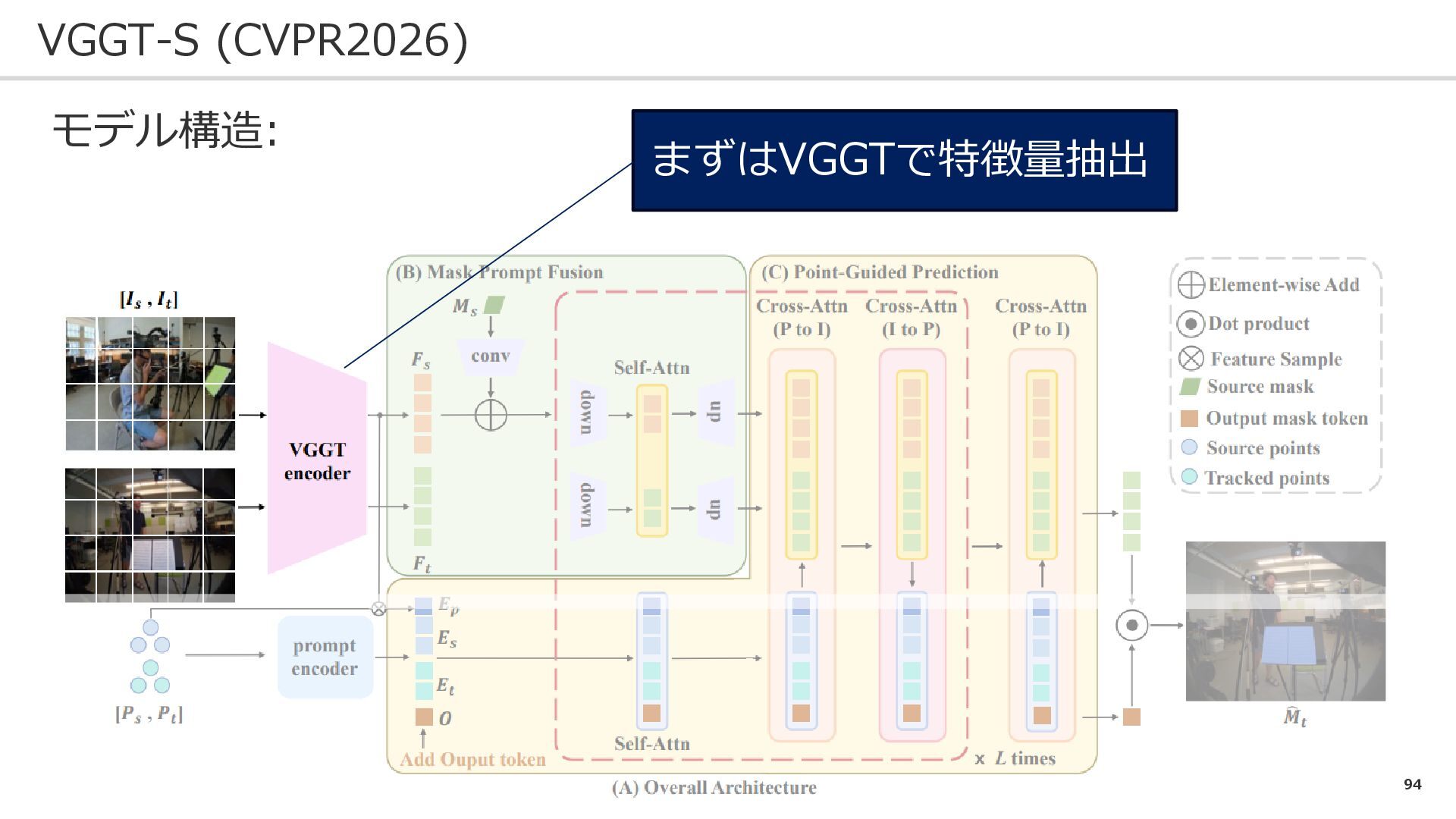
94 VGGT-S (CVPR2026) モデル構造: まずはVGGTで特徴量抽出
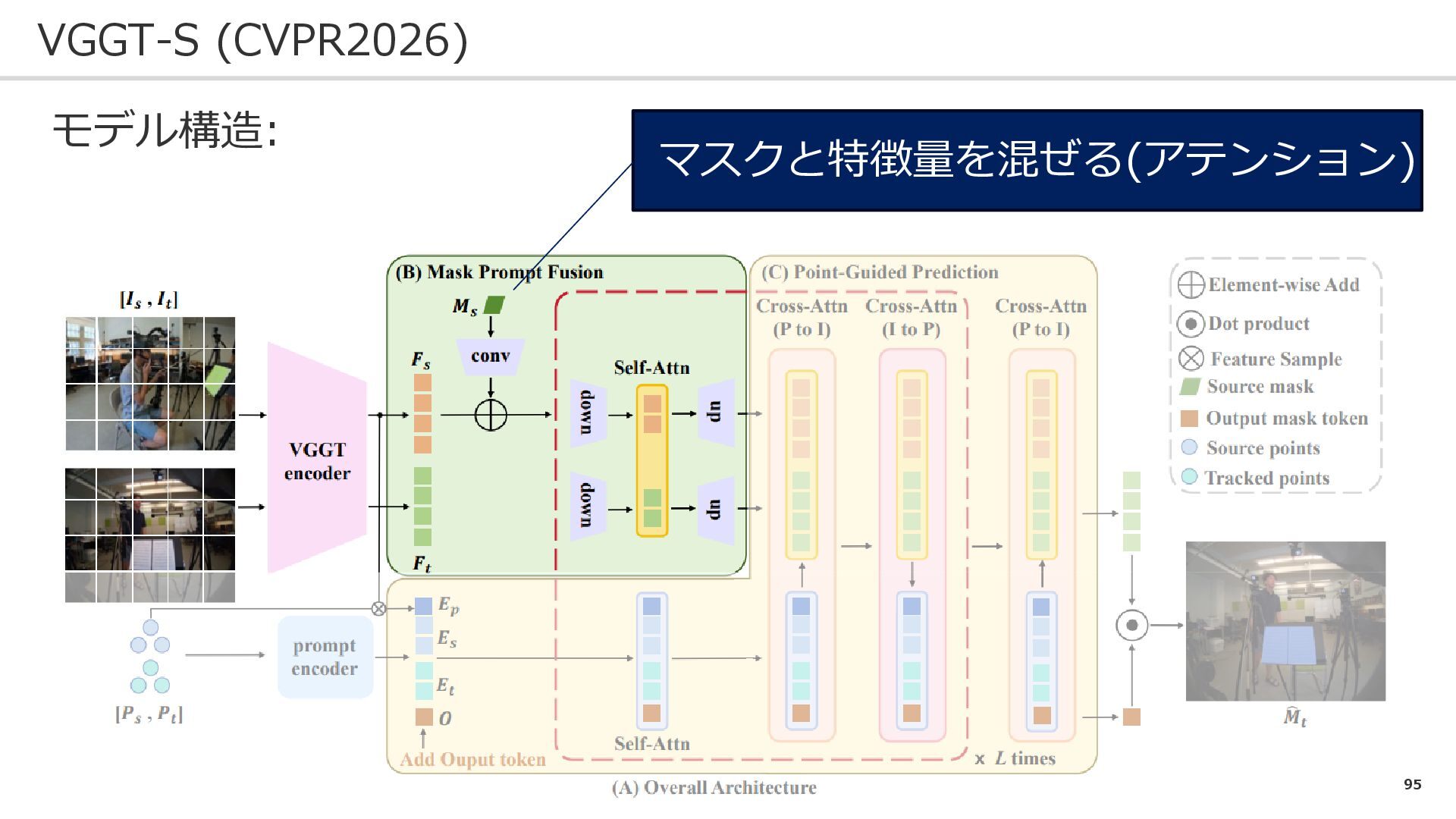
95 VGGT-S (CVPR2026) モデル構造: マスクと特徴量を混ぜる(アテンション)
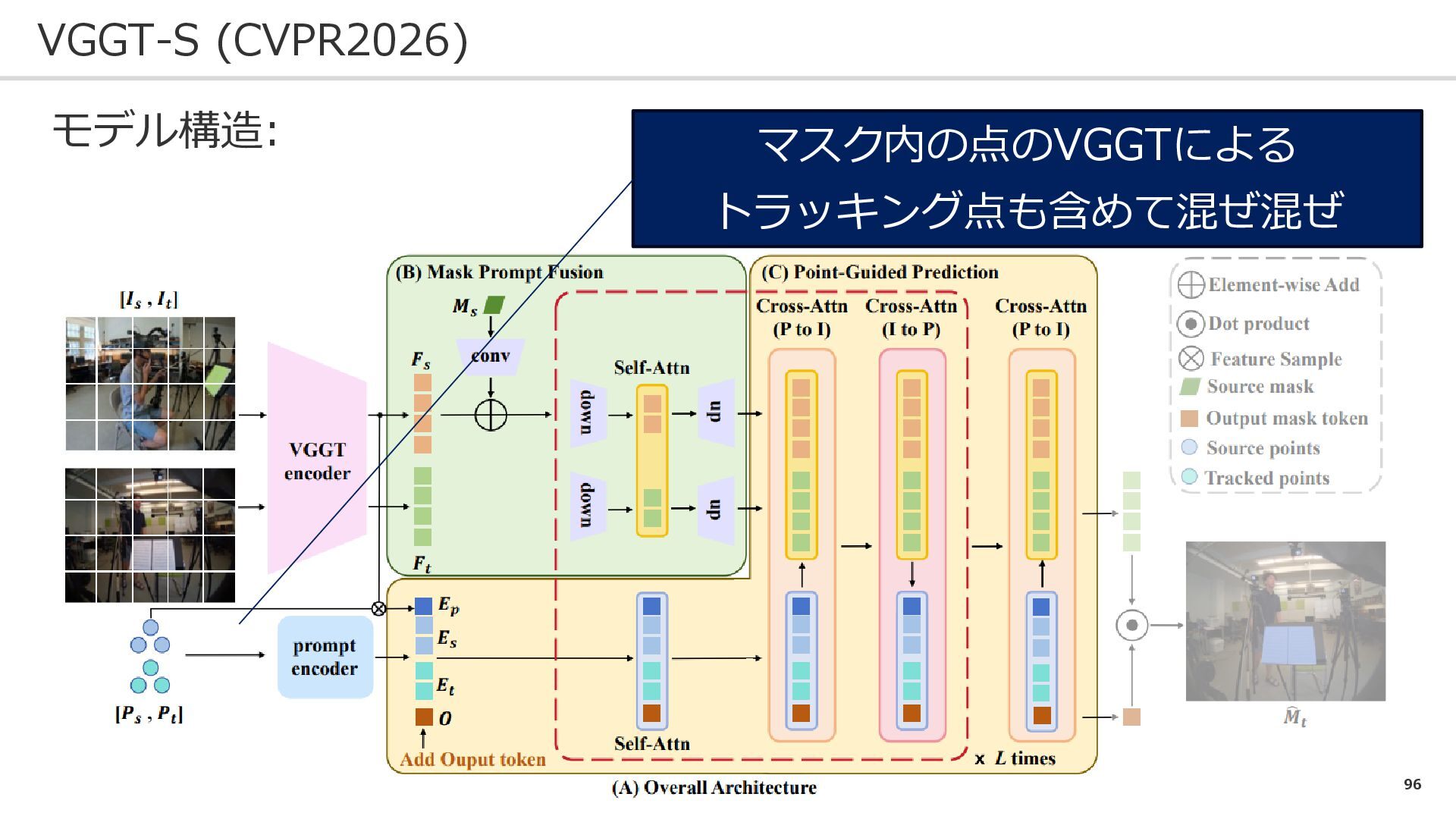
96 VGGT-S (CVPR2026) モデル構造: マスク内の点のVGGTによる トラッキング点も含めて混ぜ混ぜ
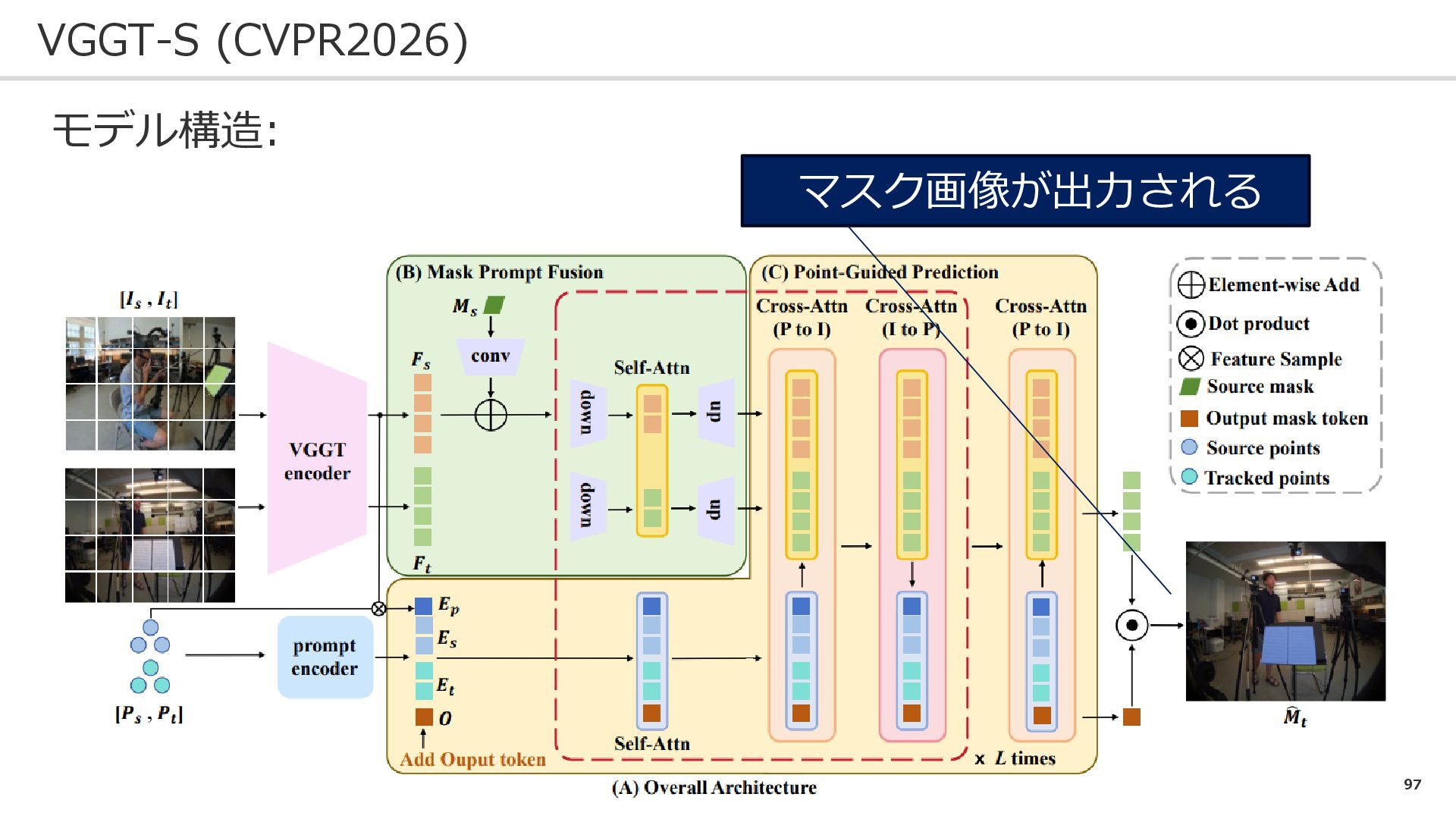
97 VGGT-S (CVPR2026) モデル構造: マスク画像が出力される
98 Omni-VGGT (CVPR2026) 問題設定: VGGTの入力を画像以外にも拡張できないか 課題: ➀VGGTの入力は、画像だけに限られる
99 Omni-VGGT (CVPR2026) VGGTの入力を、画像以外にもカメラ姿勢とデプスを入力できるように
100 Omni-VGGT (CVPR2026) カメラ姿勢とデプスも入力に! → 一緒に学習すると(それらがなくとも)SOTA
101 Omni-VGGT (CVPR2026) ただ、最初から入れてftすると学習が不安定なので 初期重みをすべて0にした畳み込みを入れる
102 Omni-VGGT (CVPR2026) 定性評価: 複数の入力に基づき学習すれば、画像入力だけでも性能向上
103 Uni3R (CVPR2026) 3DGSの各ガウシアンが意味合いを持つ フィードフォワード型モデルの構築 問題設定: 課題: ➀そのようなモデルは存在しないので作る必要性あり
104 Uni3R (CVPR2026) モデル構造:
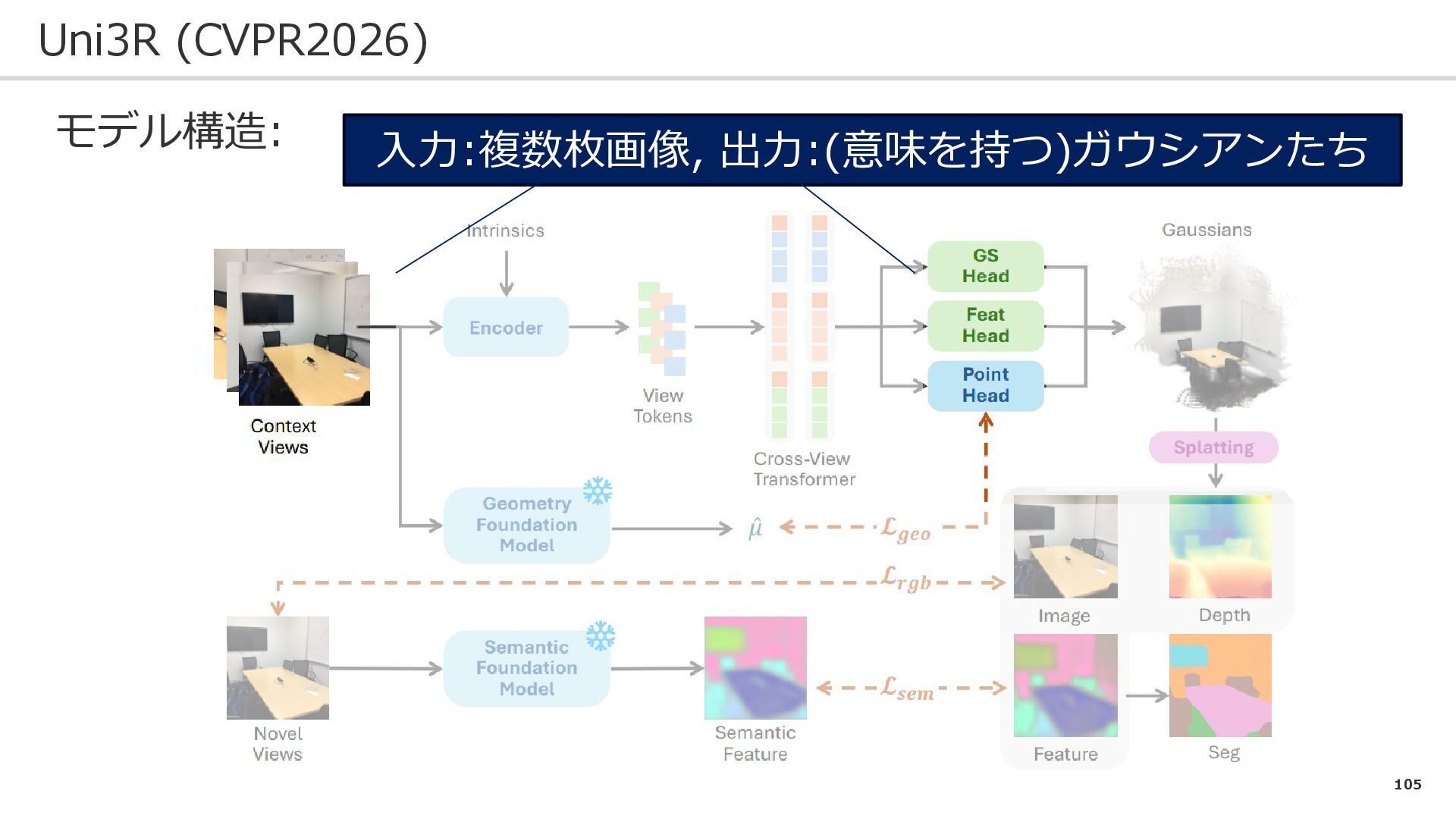
105 Uni3R (CVPR2026) モデル構造: 入力:複数枚画像, 出力:(意味を持つ)ガウシアンたち
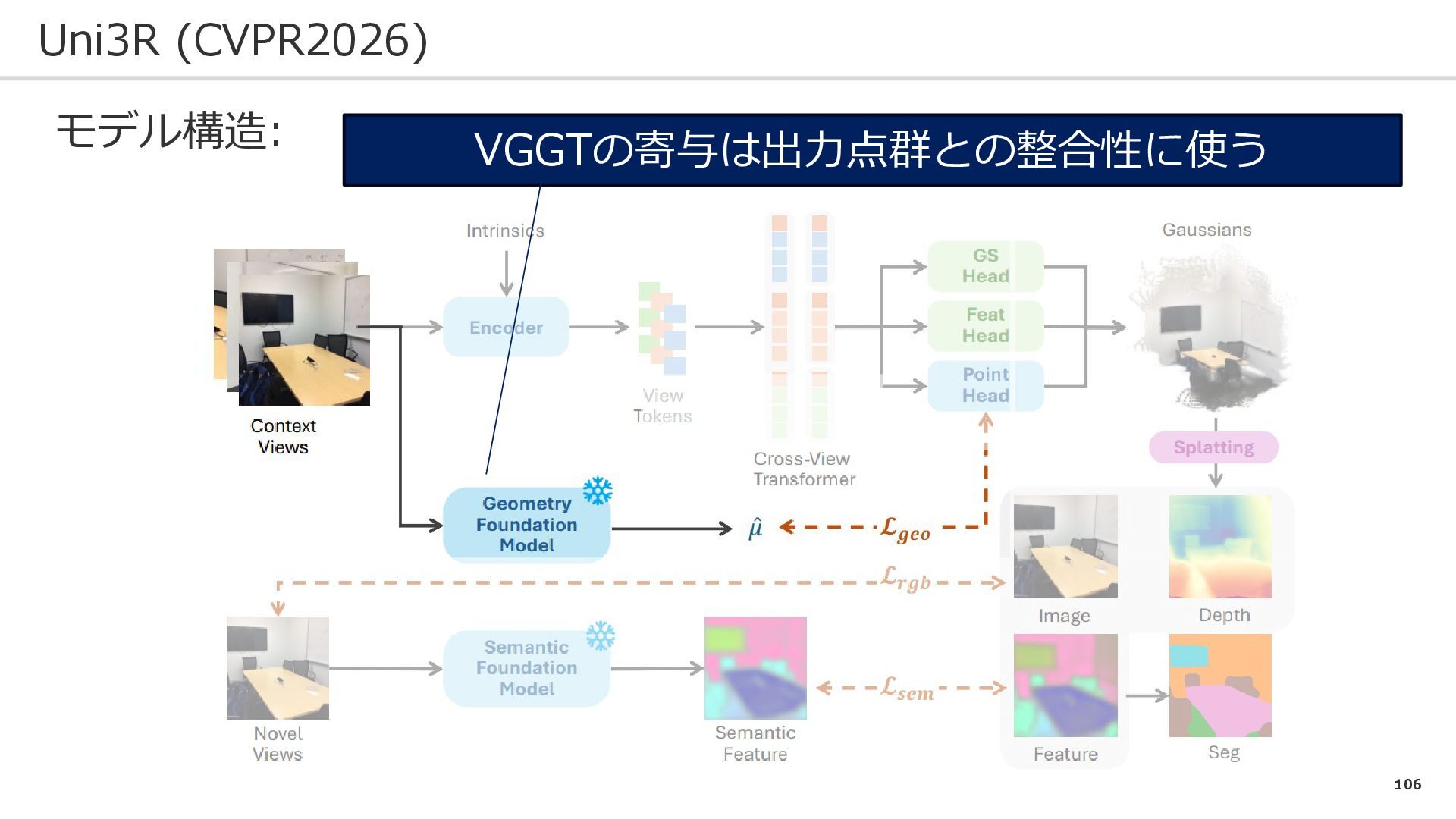
106 Uni3R (CVPR2026) モデル構造: VGGTの寄与は出力点群との整合性に使う
107 Uni3R (CVPR2026) 損失関数: 損失関数は(大きく分けて)3種類! ➀ガウシアンを投影した画像とGT画像の差異: ②ピクセルレベルの意味合いの損失 (L-Segによる意味合いがGT)↓ ③推定点群とVGGTによる点群の損失
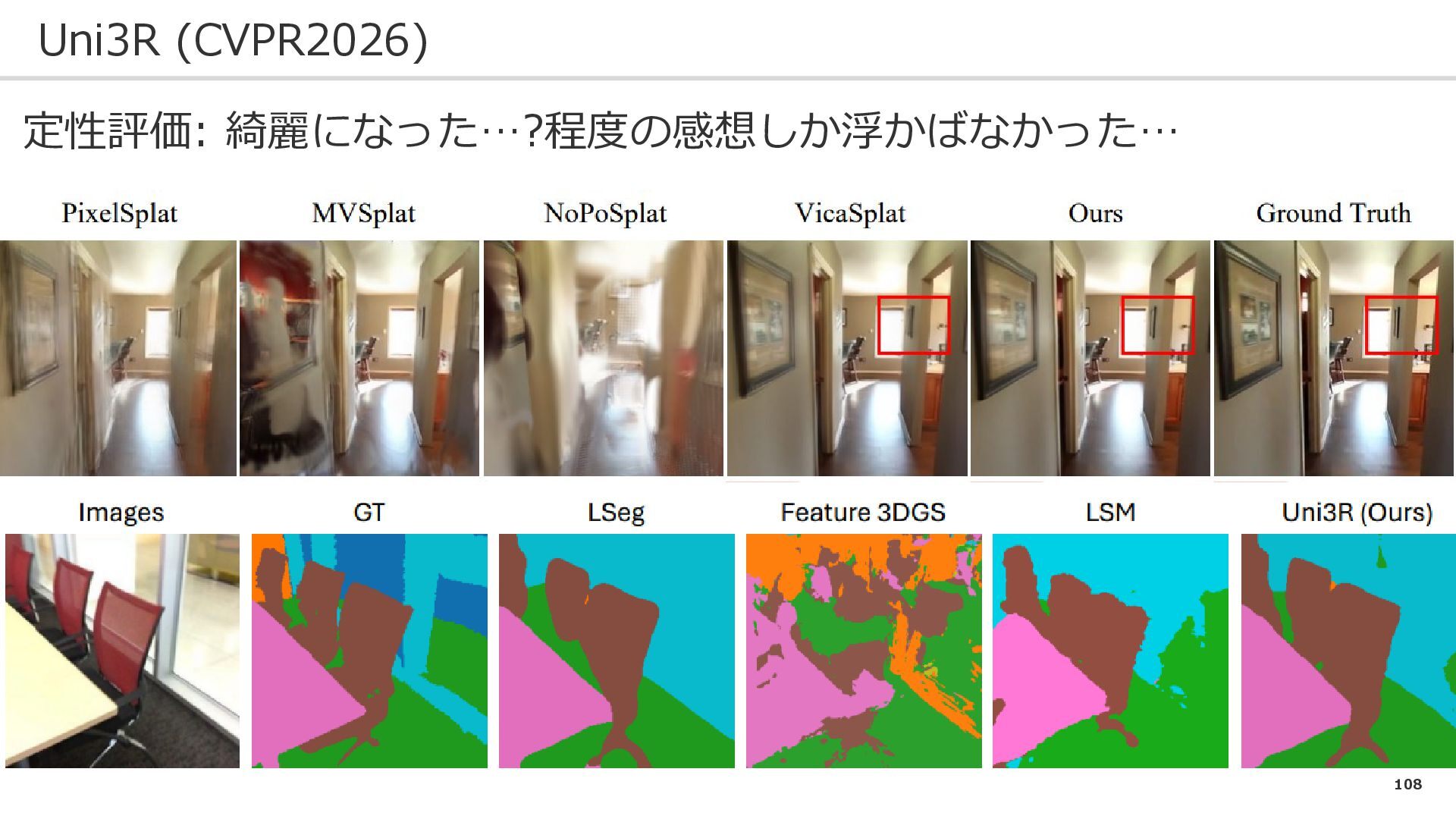
108 Uni3R (CVPR2026) 定性評価: 綺麗になった…?程度の感想しか浮かばなかった…
109 4DLangVGGT (ArXiv) 問題設定: 動画に言語特徴(時間変化考慮)を結びつける 課題: ➀NeRFや3GDSの上に実装されていることが多く シーンごとに最適化する必要がある
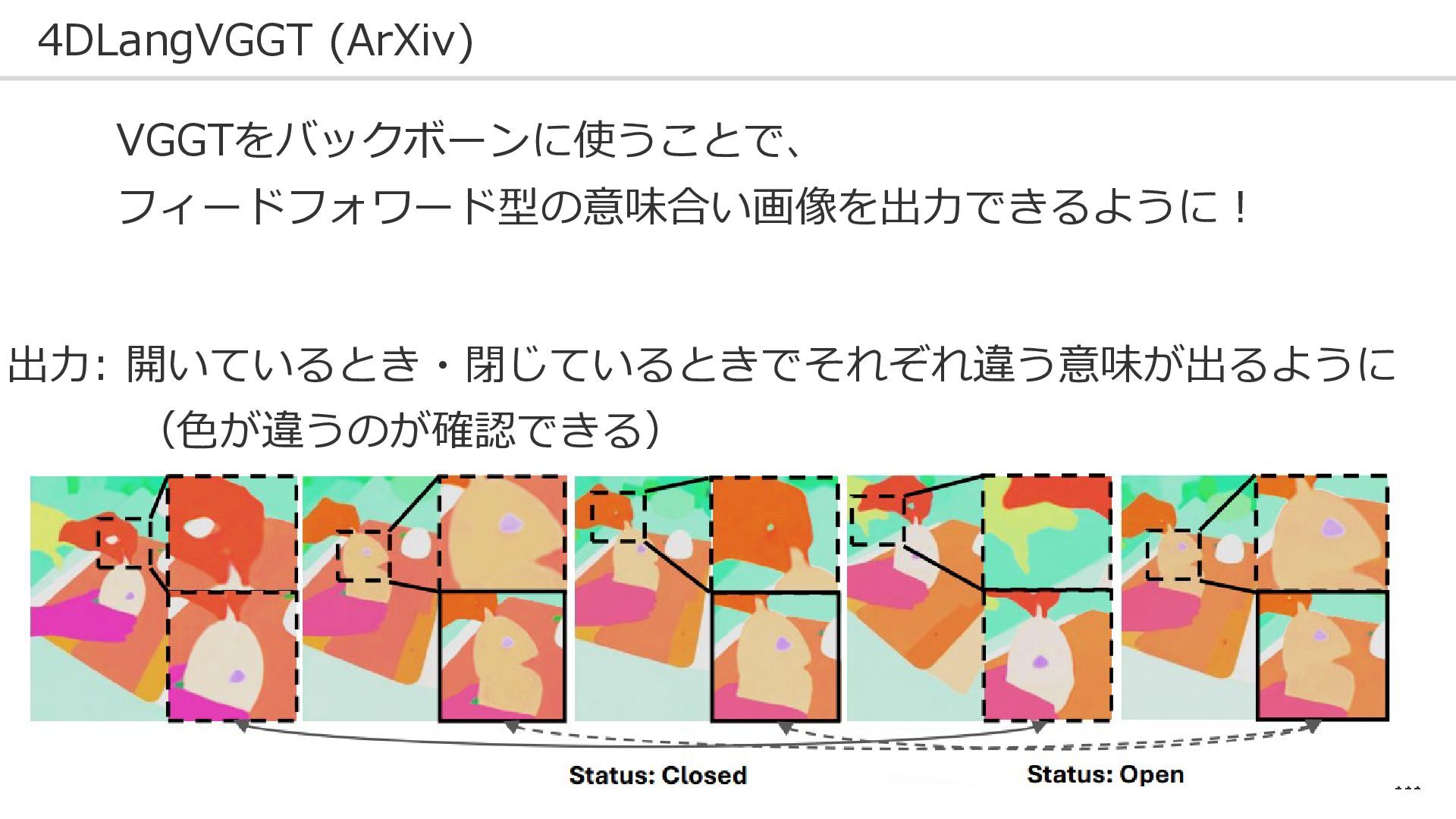
110 4DLangVGGT (ArXiv) VGGTをバックボーンに使うことで、 フィードフォワード型の意味合い画像を出力できるように! 入力: 蓋をぱかぱかしたときに、どのように画像意味が変化するか
111 4DLangVGGT (ArXiv) VGGTをバックボーンに使うことで、 フィードフォワード型の意味合い画像を出力できるように! 出力: 開いているとき・閉じているときでそれぞれ違う意味が出るように (色が違うのが確認できる)
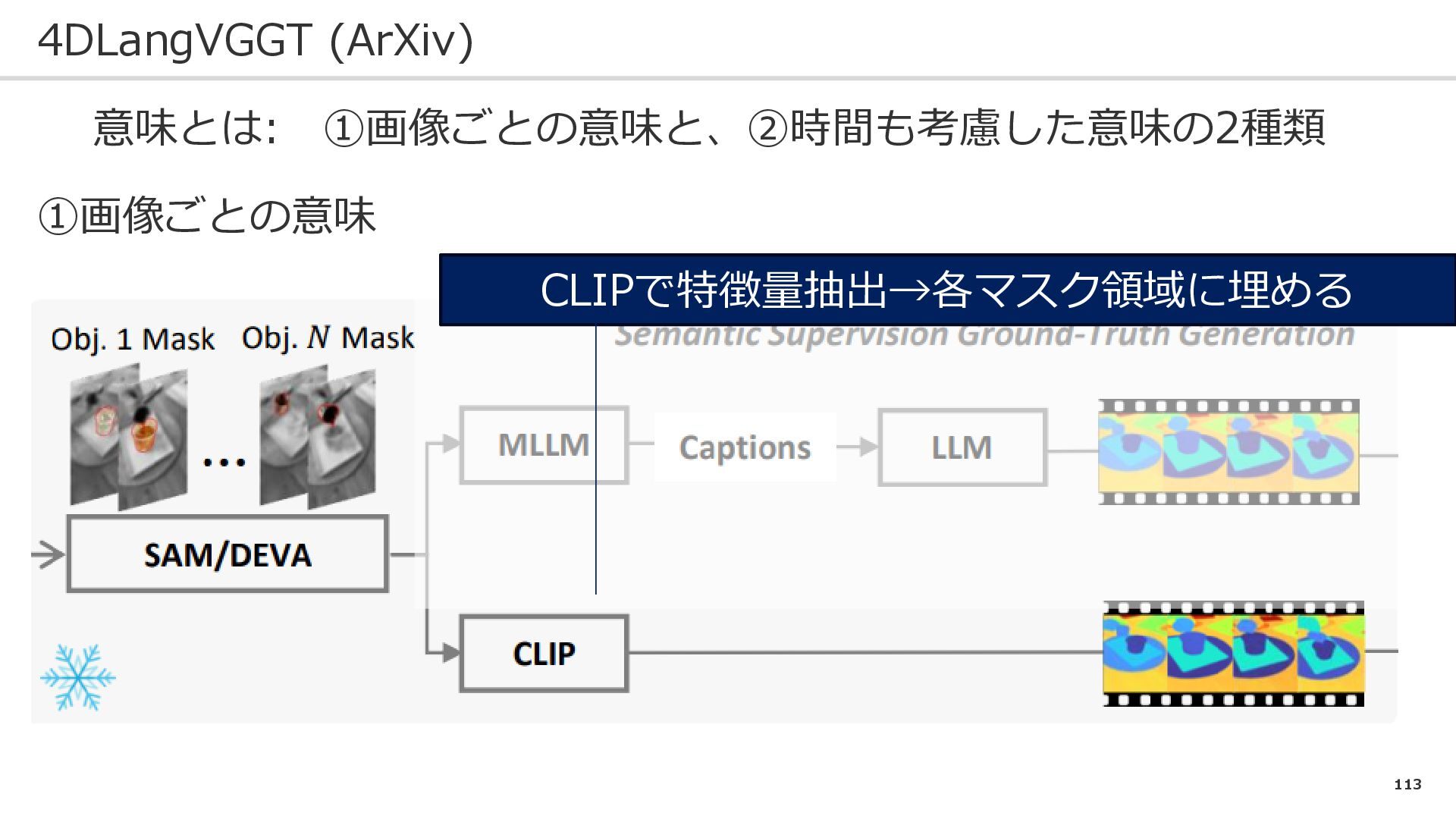
112 4DLangVGGT (ArXiv) 意味とは: ➀画像ごとの意味と、②時間も考慮した意味の2種類 ➀画像ごとの意味 各フレームごとにオブジェクトを抽出
113 4DLangVGGT (ArXiv) 意味とは: ➀画像ごとの意味と、②時間も考慮した意味の2種類 ➀画像ごとの意味 CLIPで特徴量抽出→各マスク領域に埋める
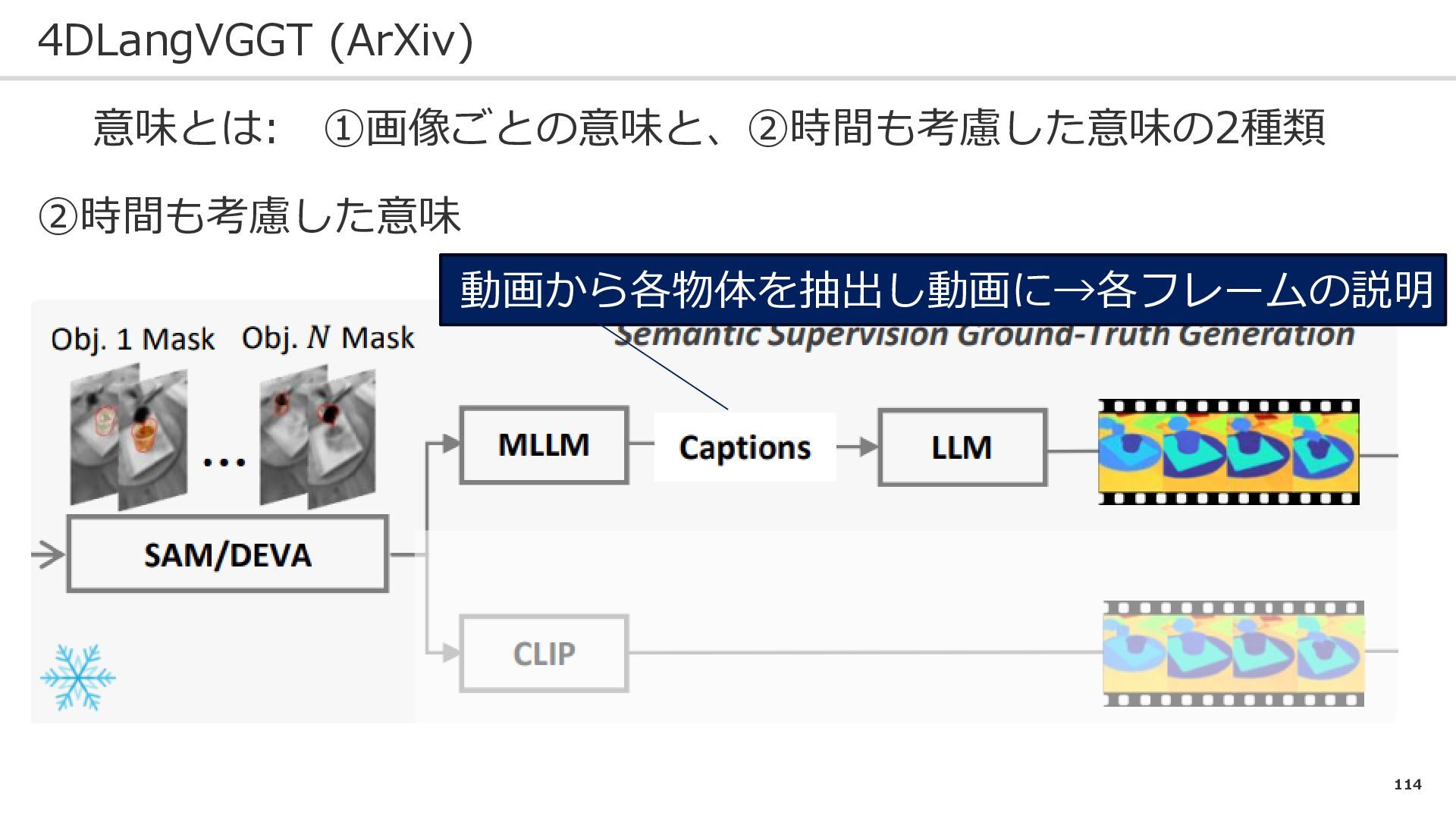
114 4DLangVGGT (ArXiv) 意味とは: ➀画像ごとの意味と、②時間も考慮した意味の2種類 ②時間も考慮した意味 動画から各物体を抽出し動画に→各フレームの説明
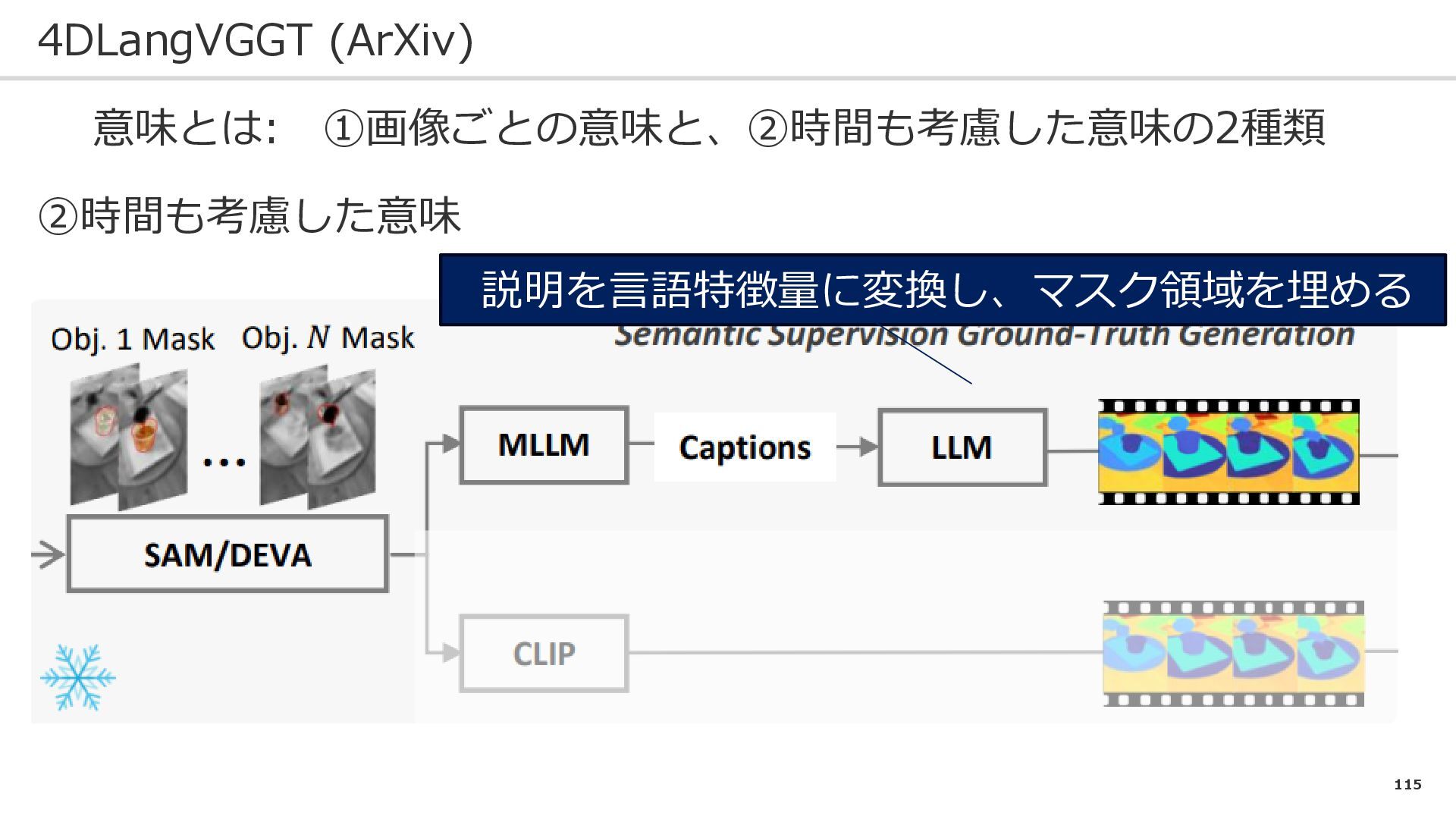
115 4DLangVGGT (ArXiv) 意味とは: ➀画像ごとの意味と、②時間も考慮した意味の2種類 ②時間も考慮した意味 説明を言語特徴量に変換し、マスク領域を埋める
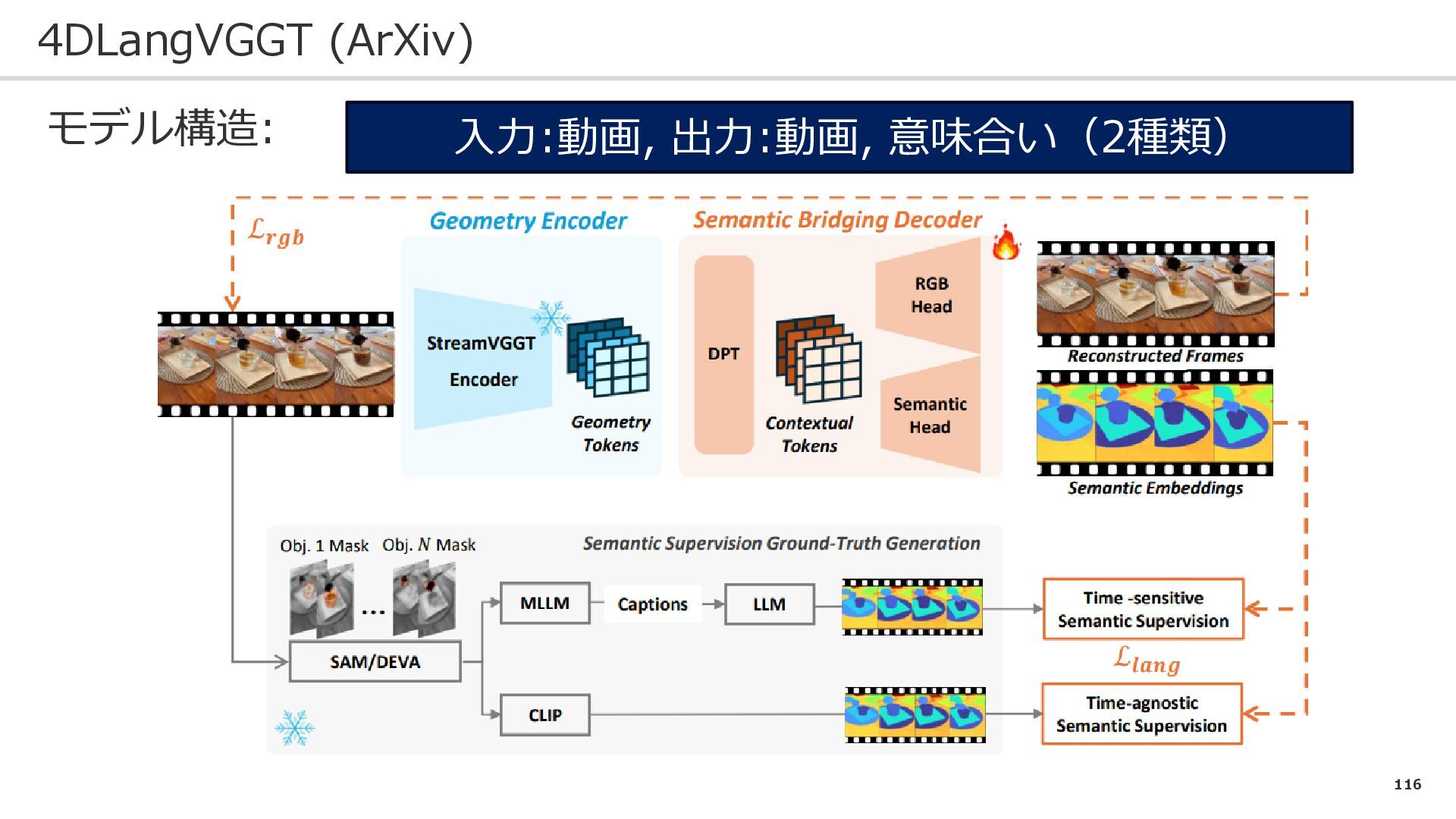
116 4DLangVGGT (ArXiv) モデル構造: 入力:動画, 出力:動画, 意味合い(2種類)
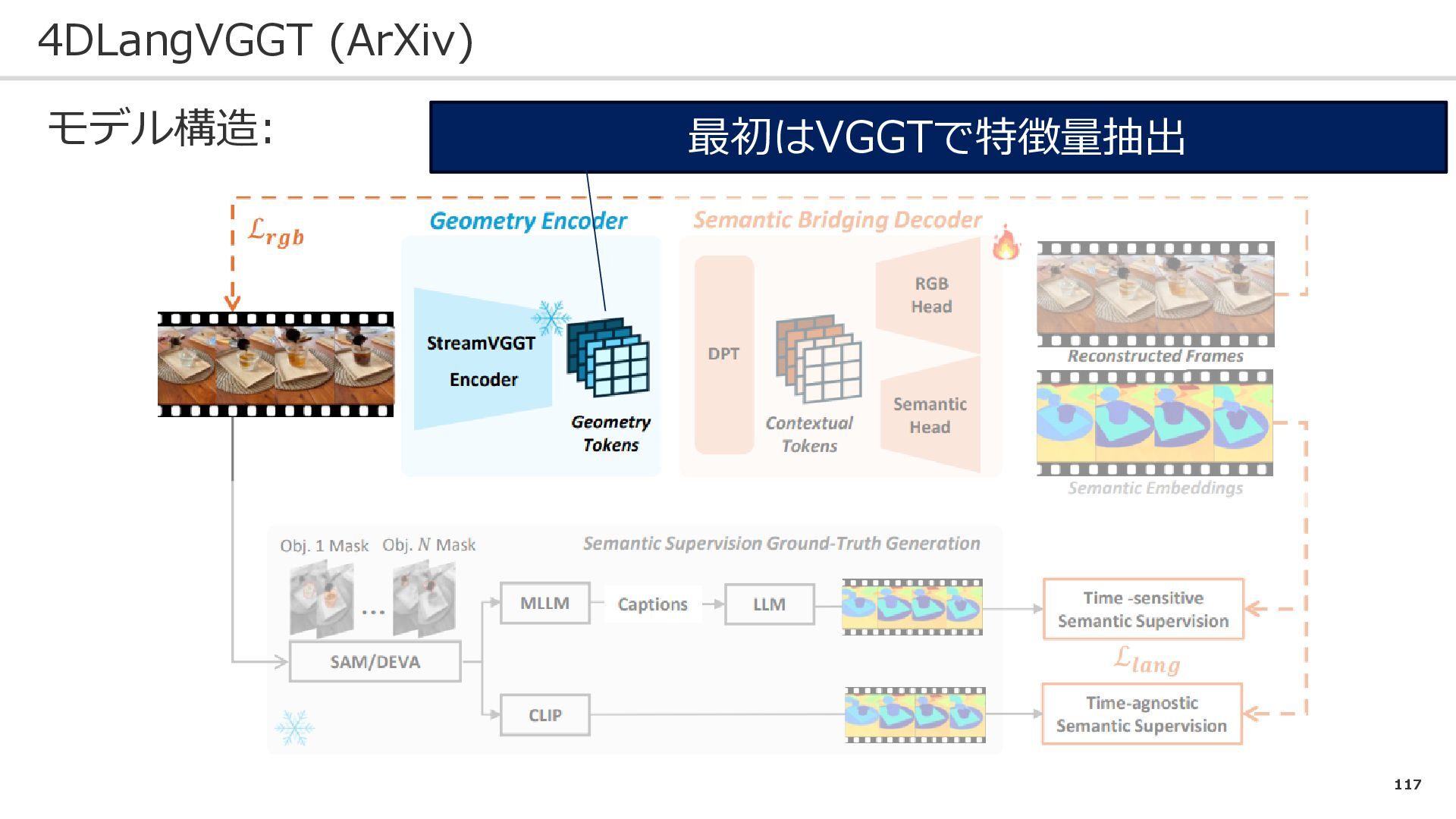
117 4DLangVGGT (ArXiv) モデル構造: 最初はVGGTで特徴量抽出
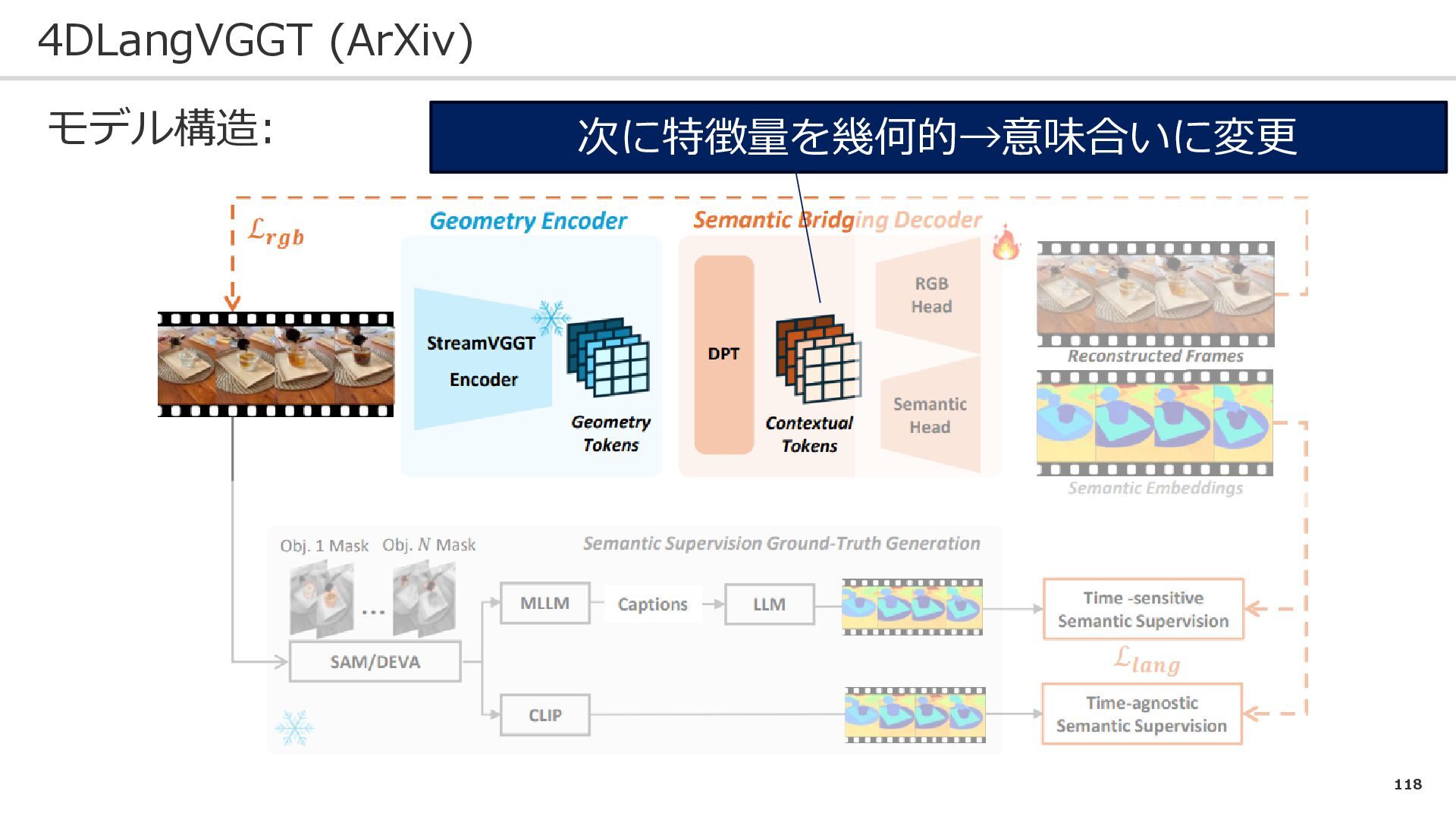
118 4DLangVGGT (ArXiv) モデル構造: 次に特徴量を幾何的→意味合いに変更
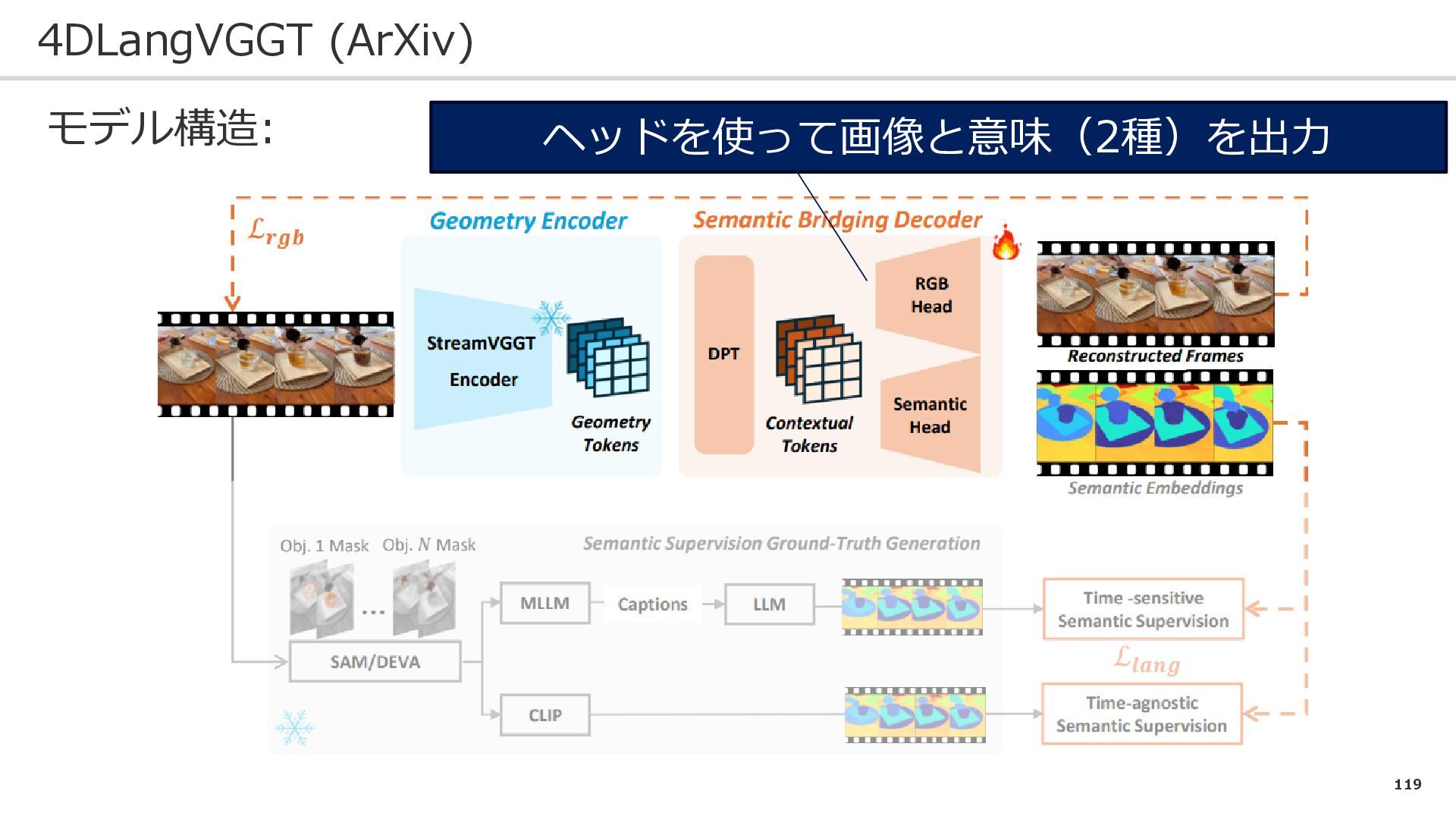
119 4DLangVGGT (ArXiv) モデル構造: ヘッドを使って画像と意味(2種)を出力
120 4DLangVGGT (ArXiv) モデル構造: 意味(2種類)と画像の乖離を、損失関数とする
121 4DLangVGGT (ArXiv) 評価: 4DLangSplatは、3DGSに意味を持たせたので激重だった(無理) → VGGTに基づくこの手法はとてもよいと思う
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}