カテゴリ特徴量の扱いに特化した勾配ブースティングツリー。 XGB XGBoost 高性能でスケーラブルな勾配ブースティングツリー。Kaggleで実 績。 RF Random Forest 複数の決定木を組み合わせたアンサンブル。堅牢で安定した性能。 XT Extra Trees RFに似るが、よりランダム性を高め高速化。 NN_TORCH PyTorch NN 表形式データ向けのディープラーニングモデル。複雑なパターンを 学習。 LR Linear Model 線形回帰/ロジスティック回帰。シンプルで解釈しやすい。 KNN K-Nearest Neighbors 近いデータ点に基づいて予測。シンプルで直感的。 AG_AUTOMM AutoMM 表、テキスト、画像など複数データタイプを統合するマルチモーダ ルモデル。 6
{kind=link}
{kind=link}
{kind=link}
{kind=link}
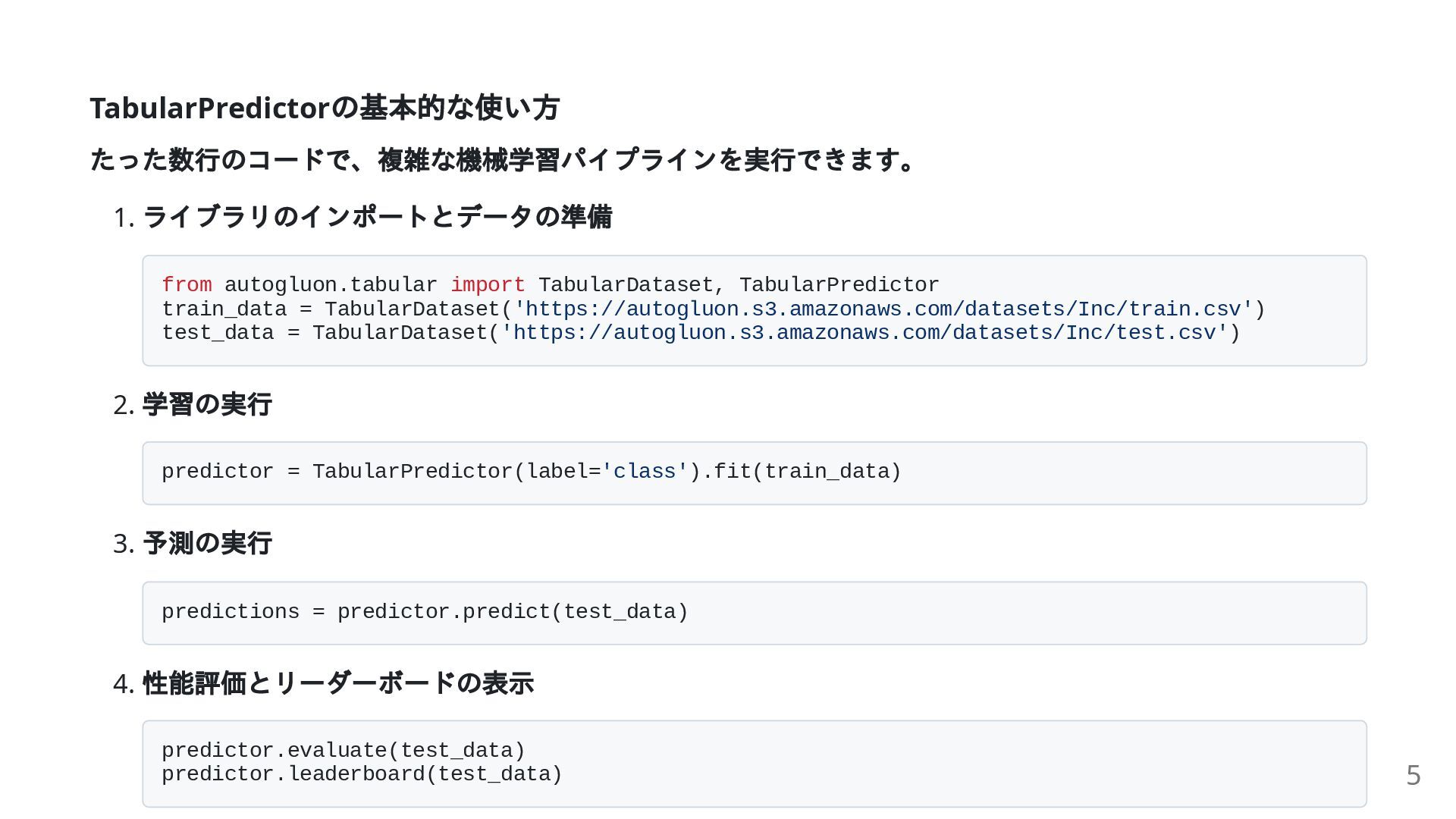{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}