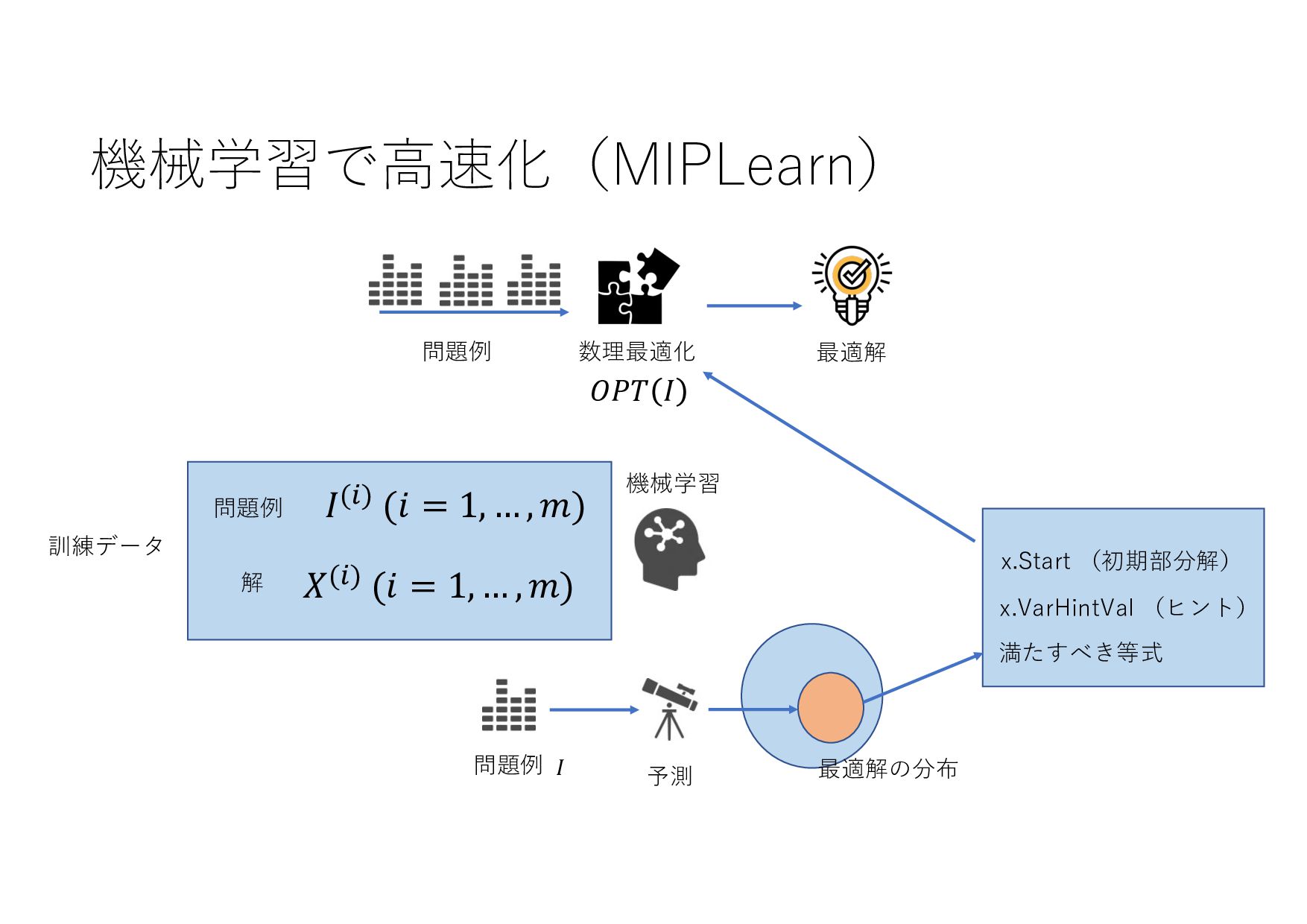
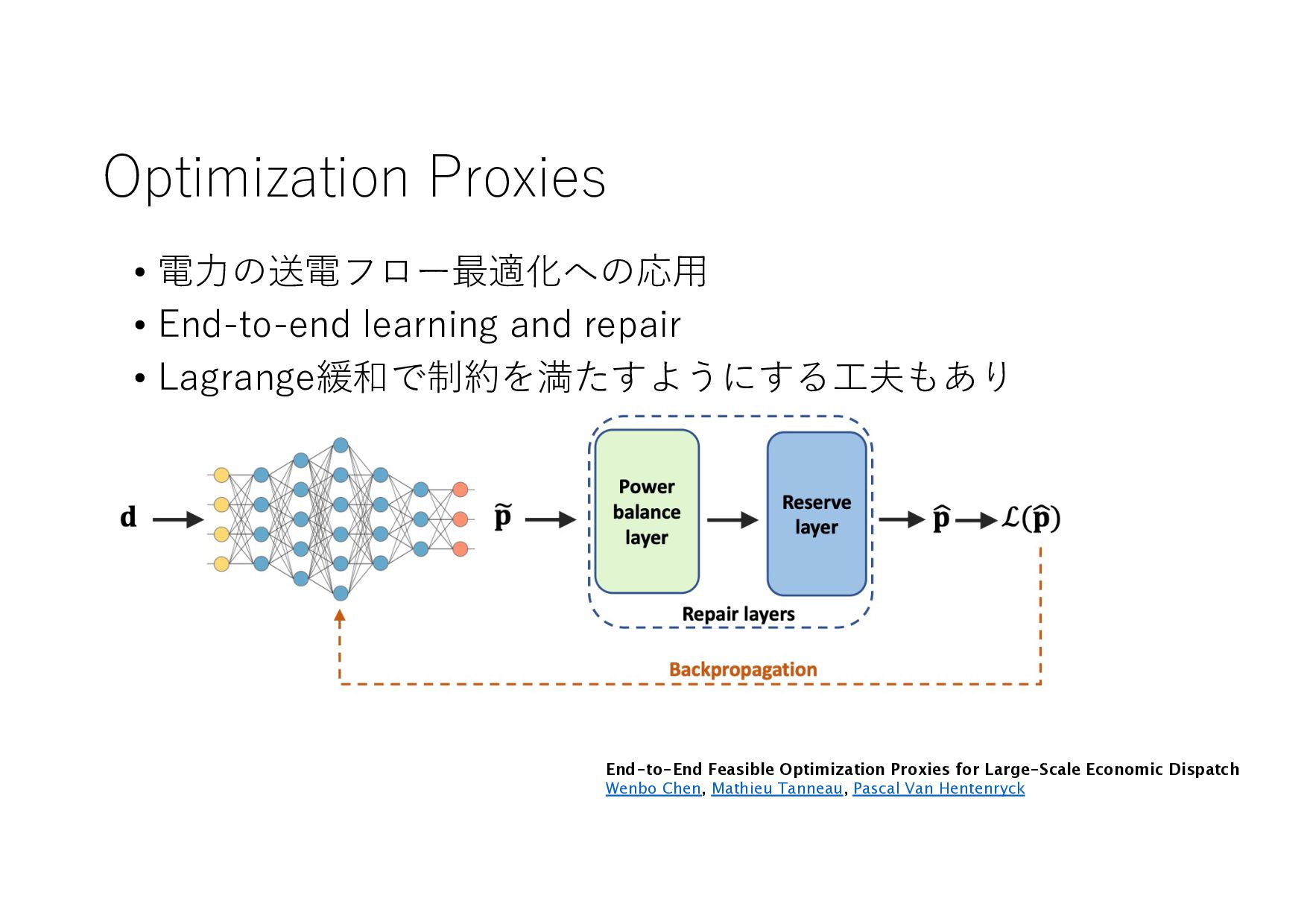
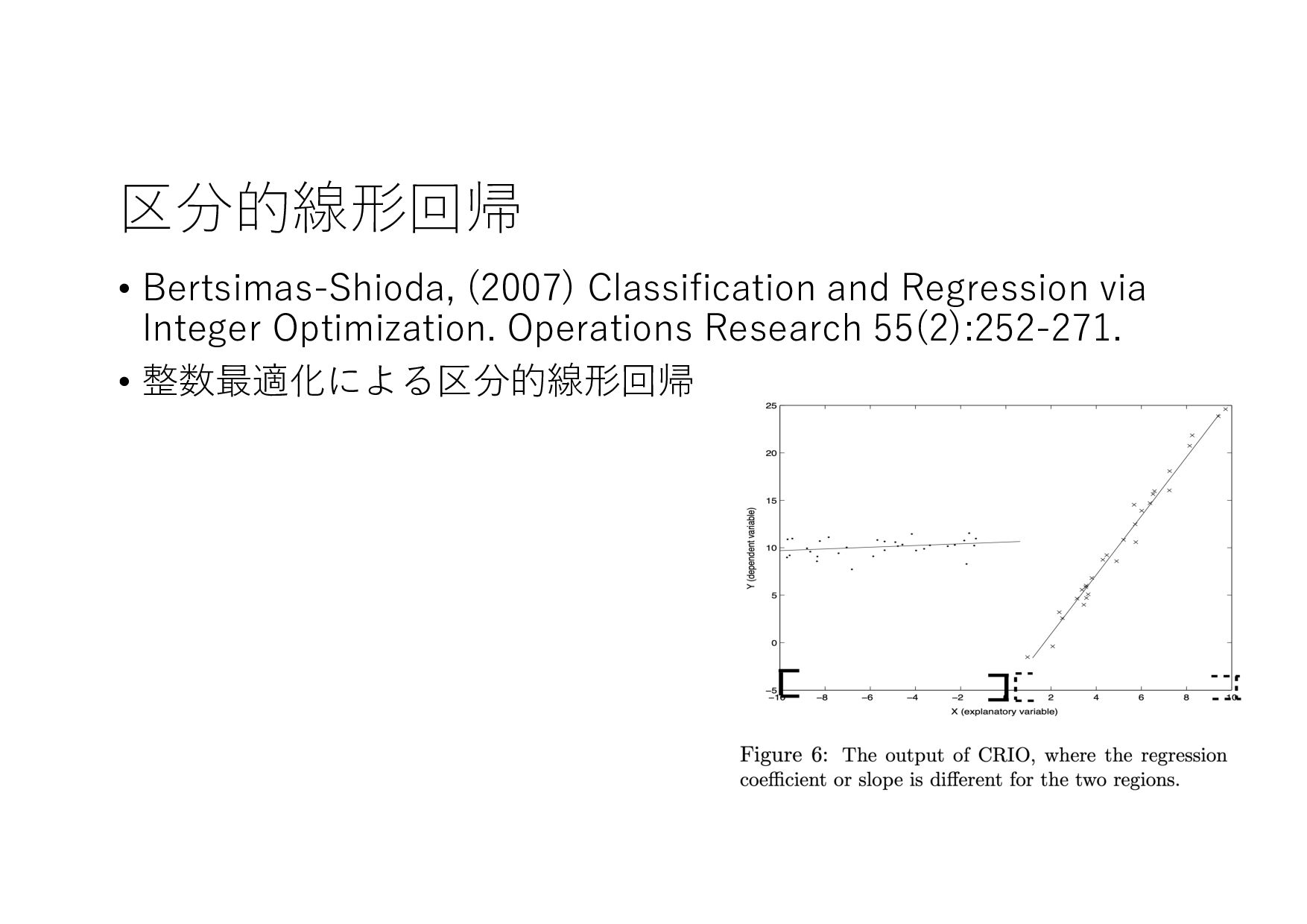
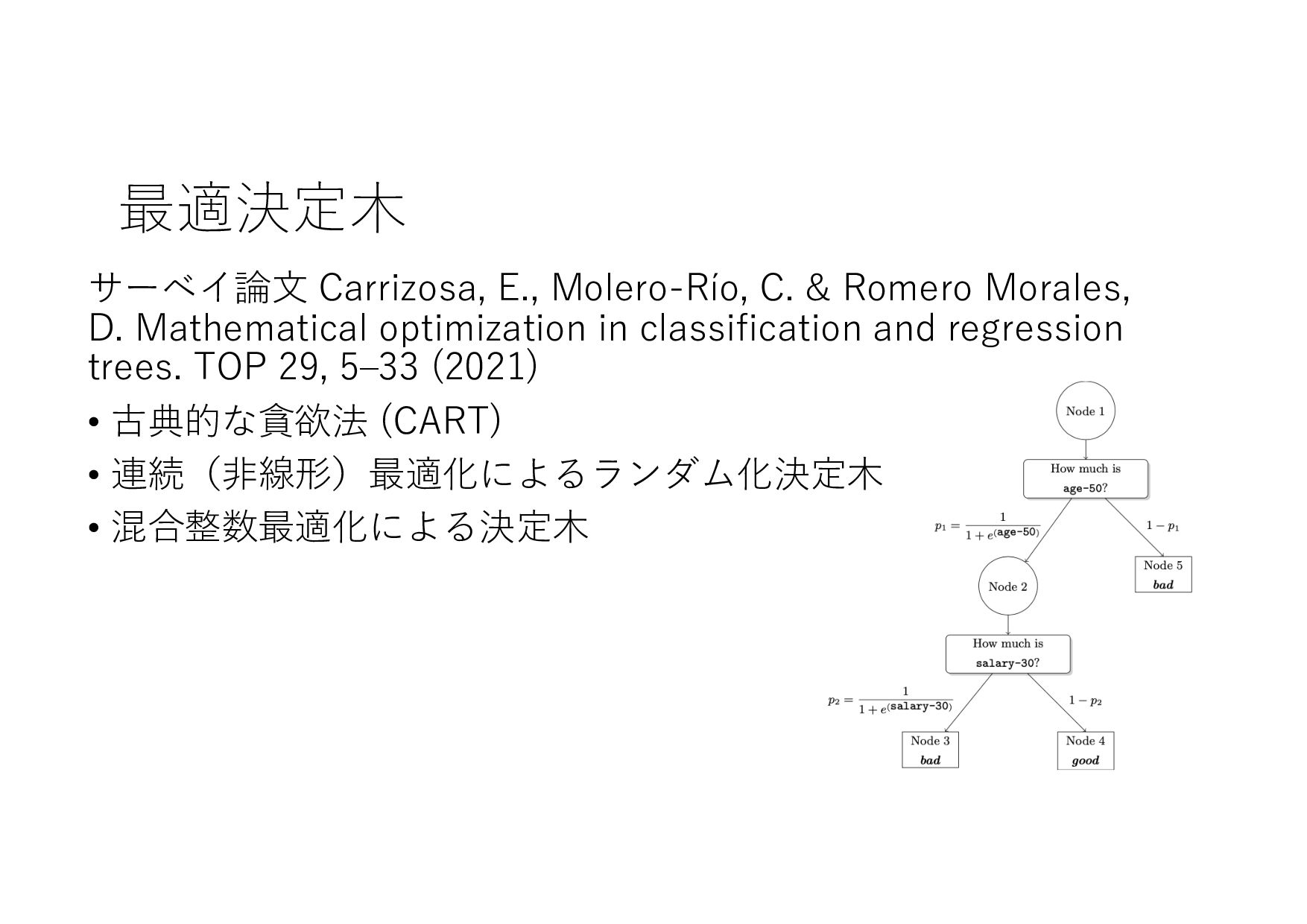
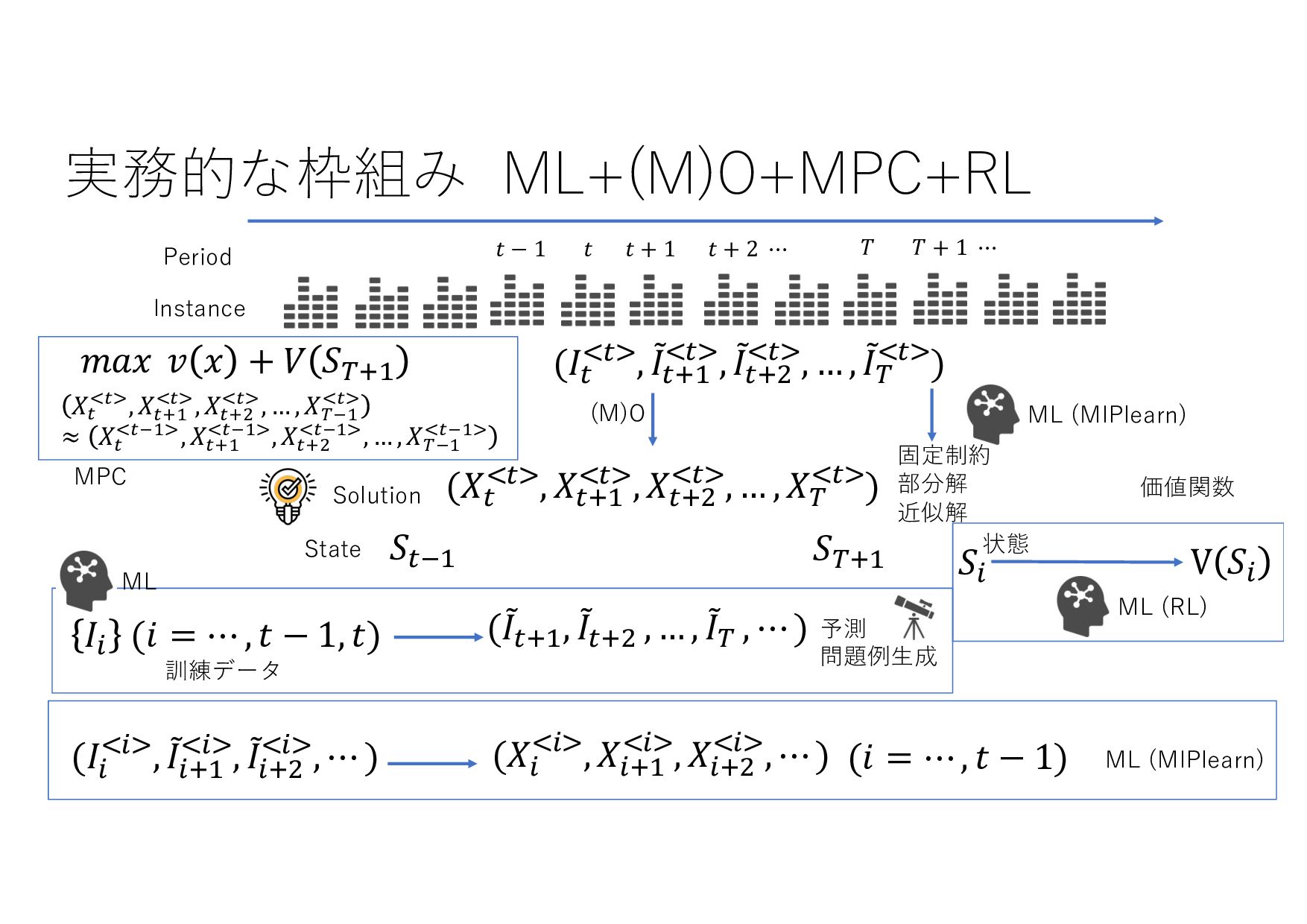
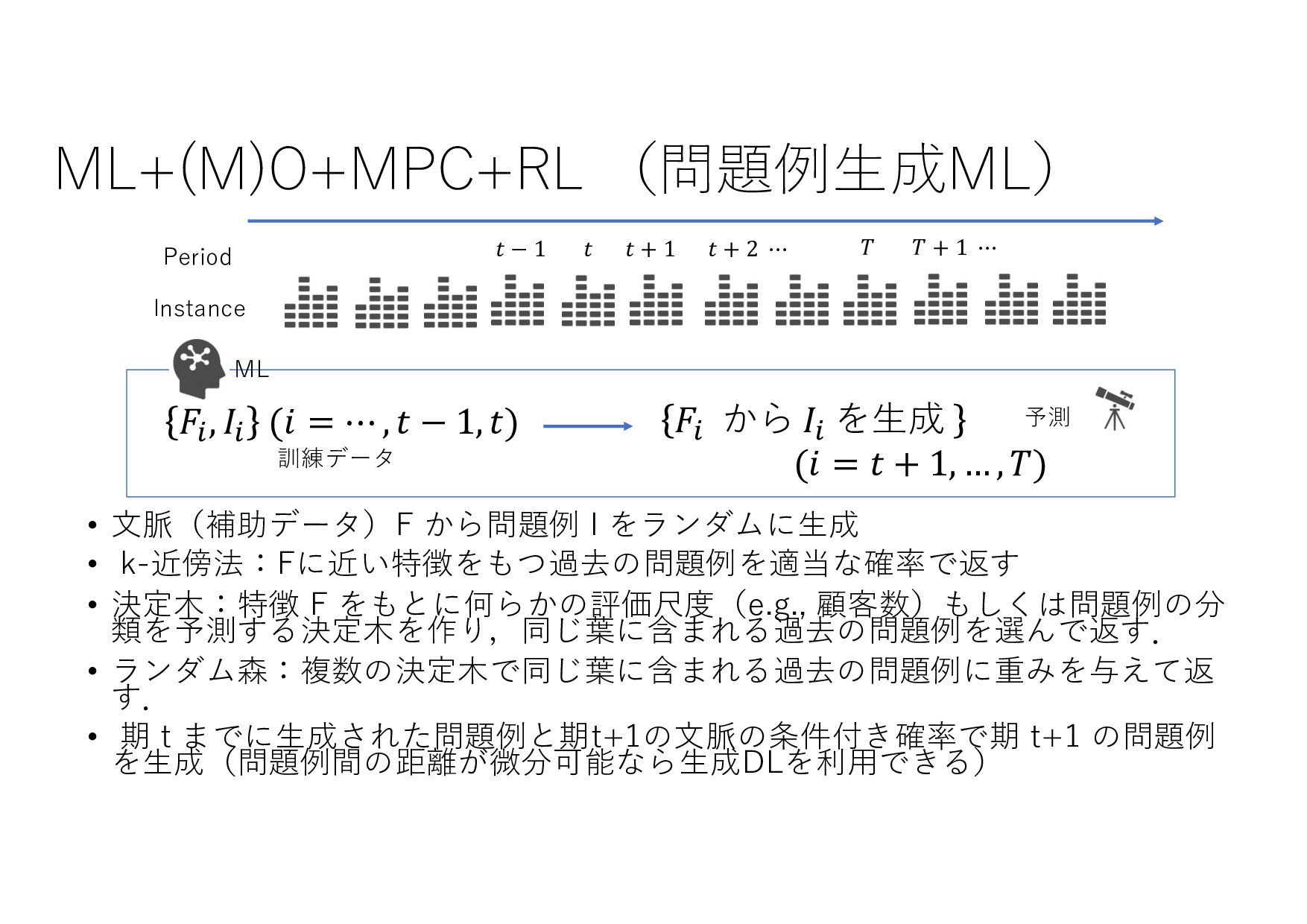
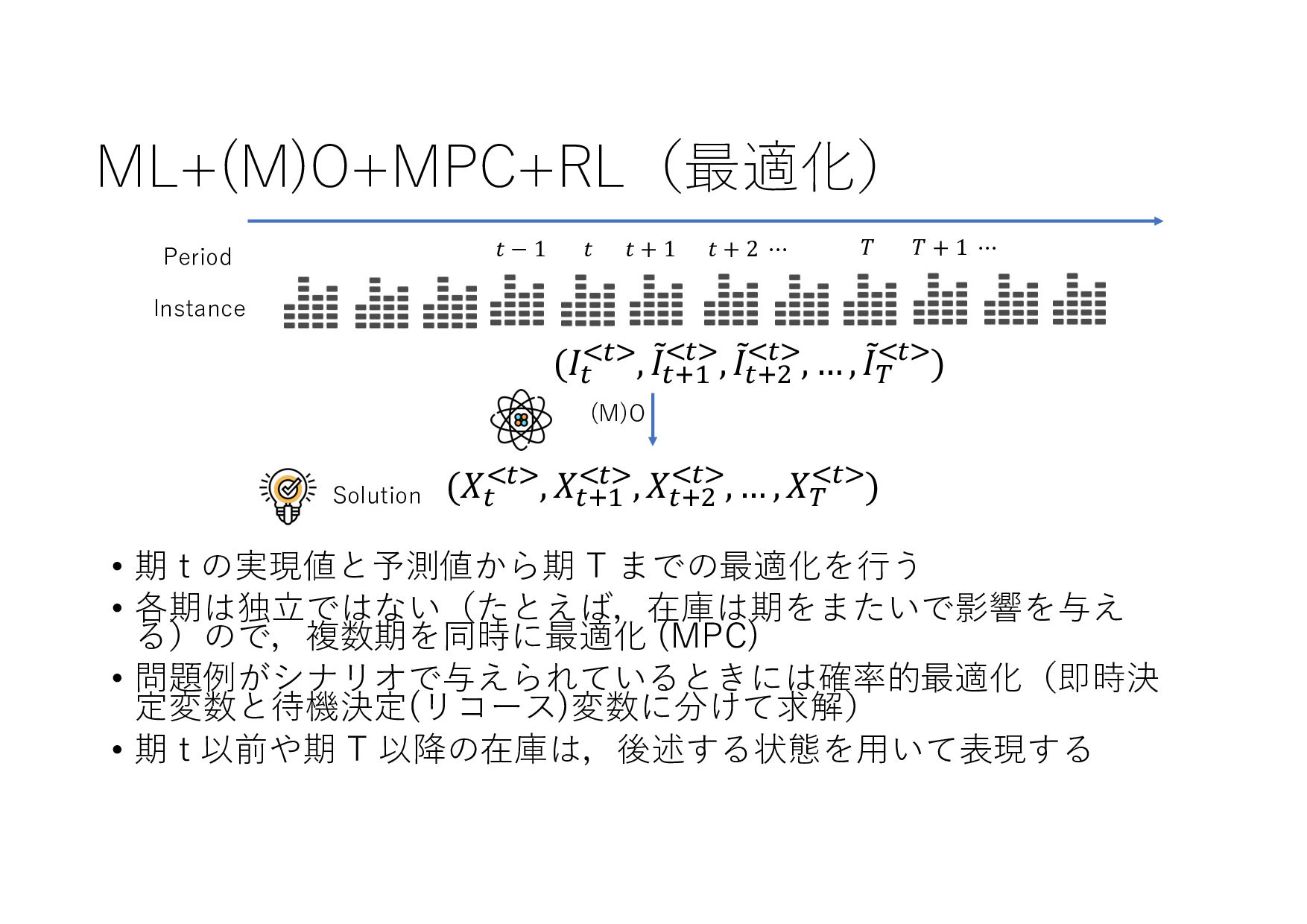
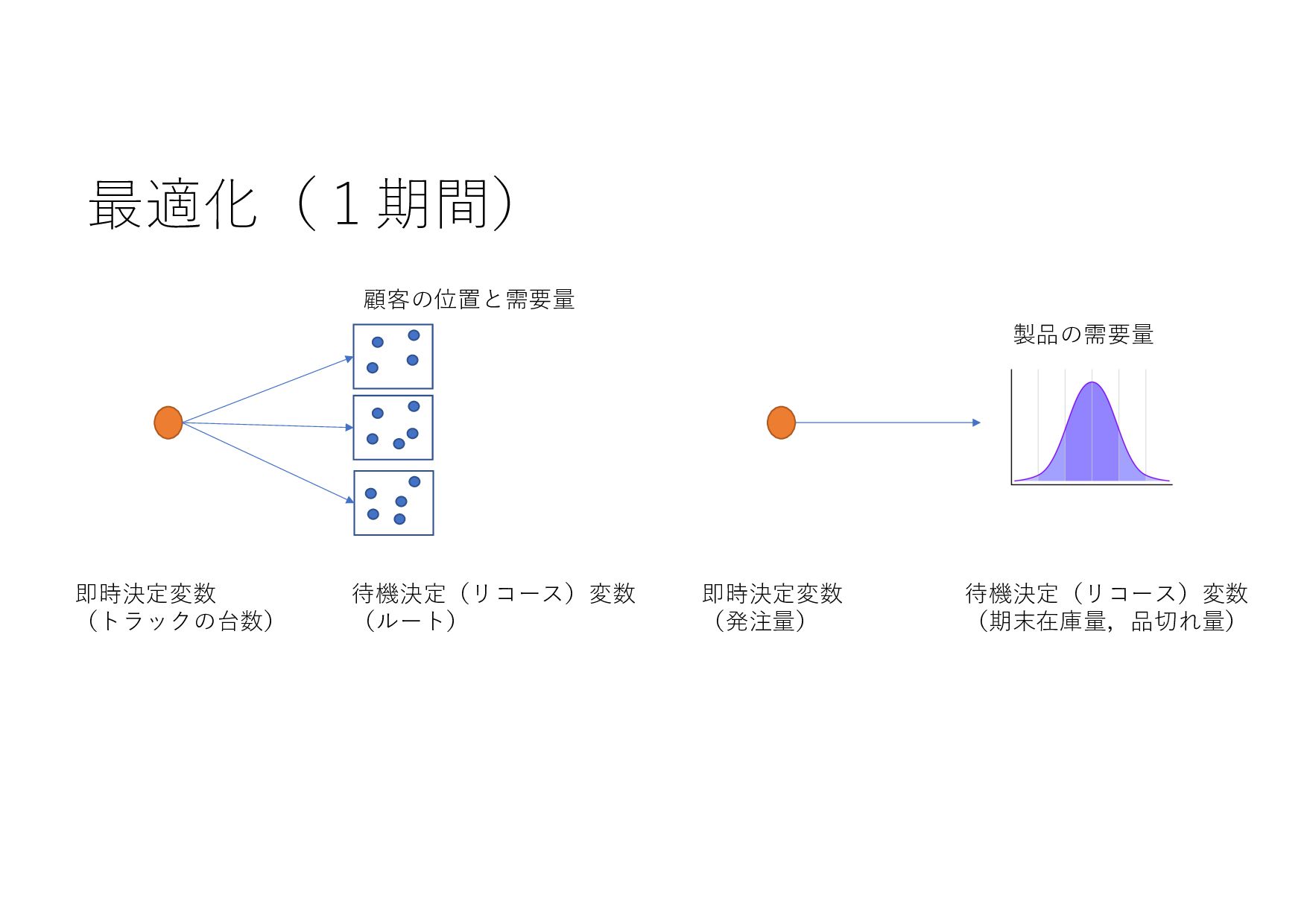
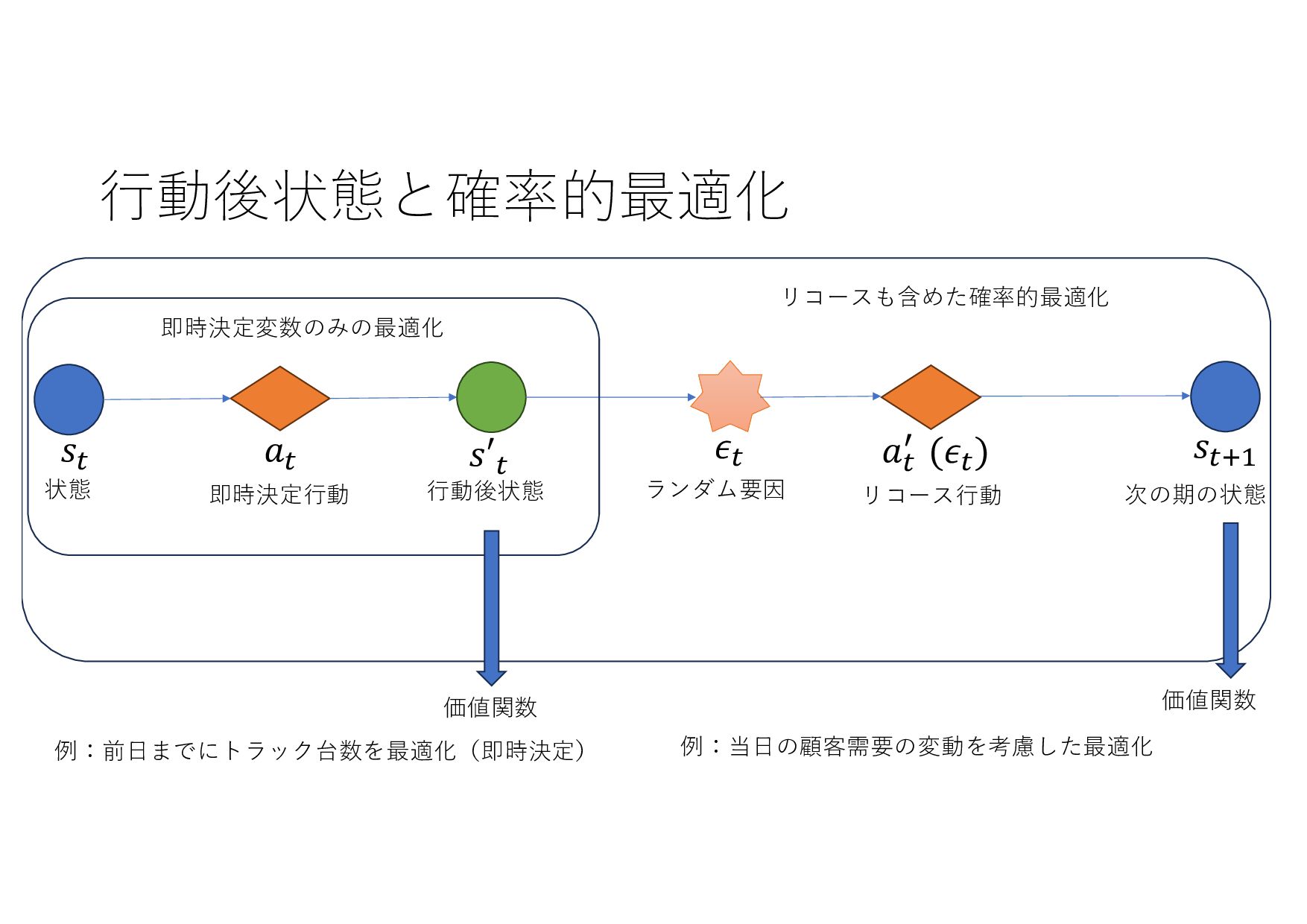
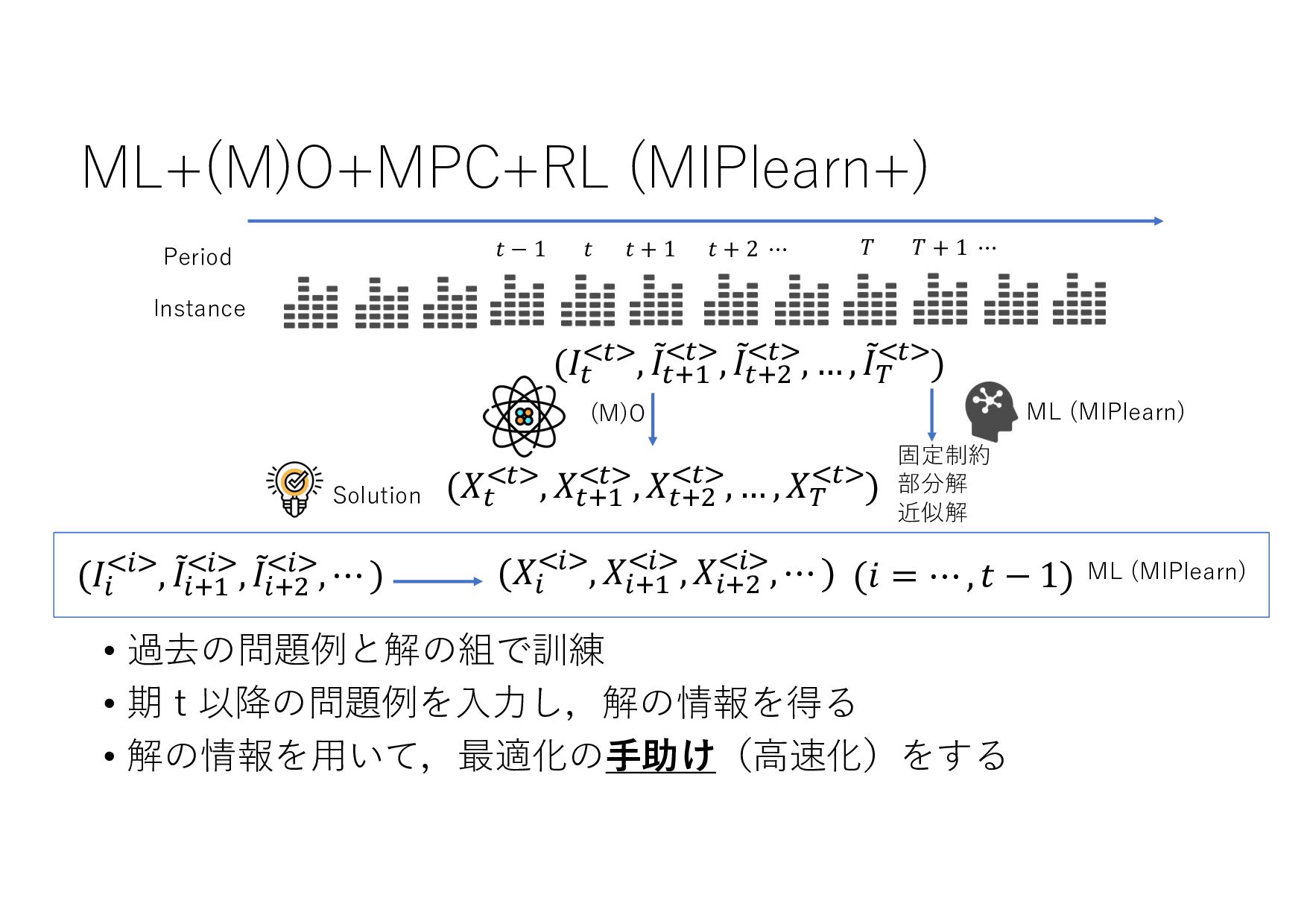
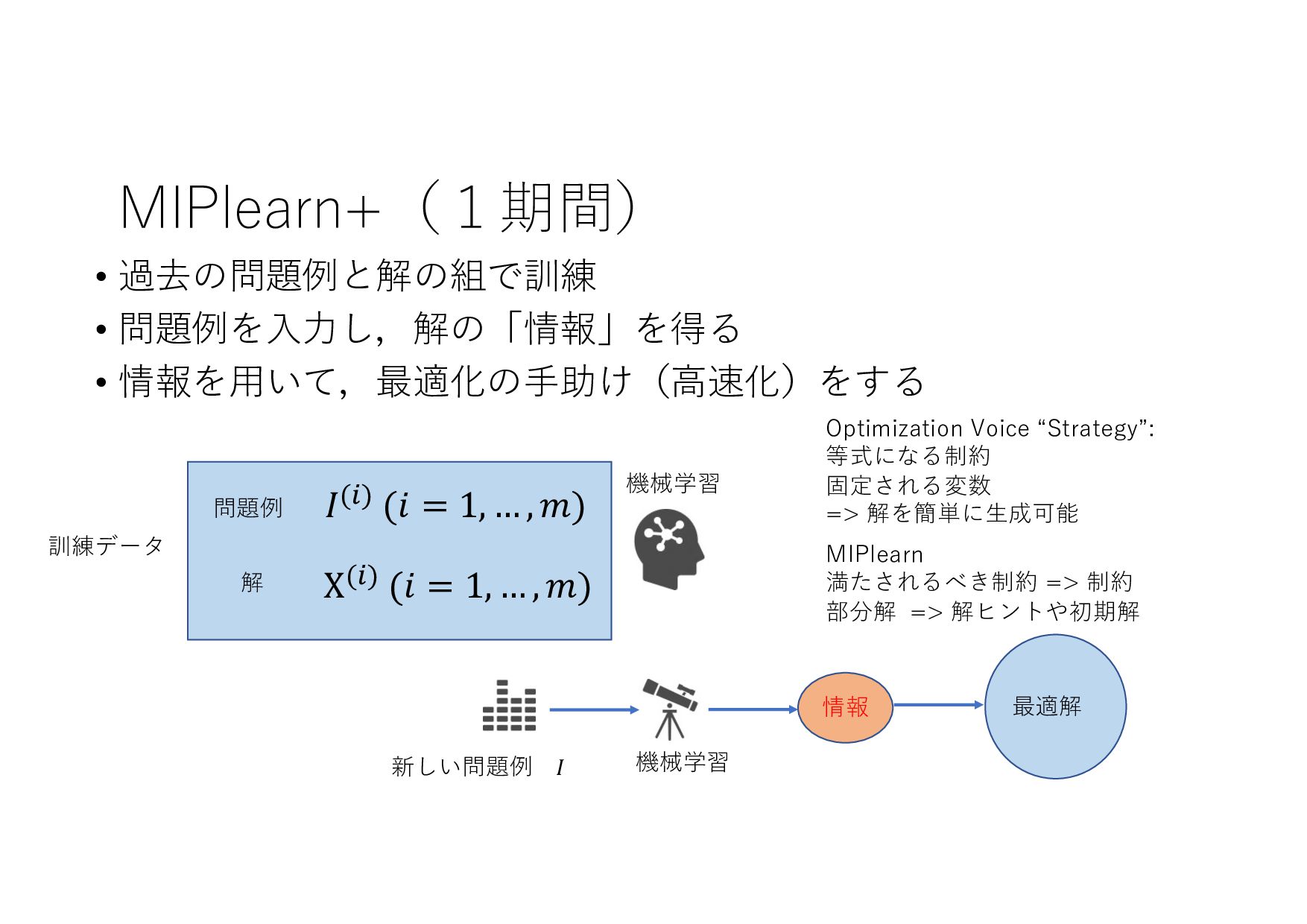
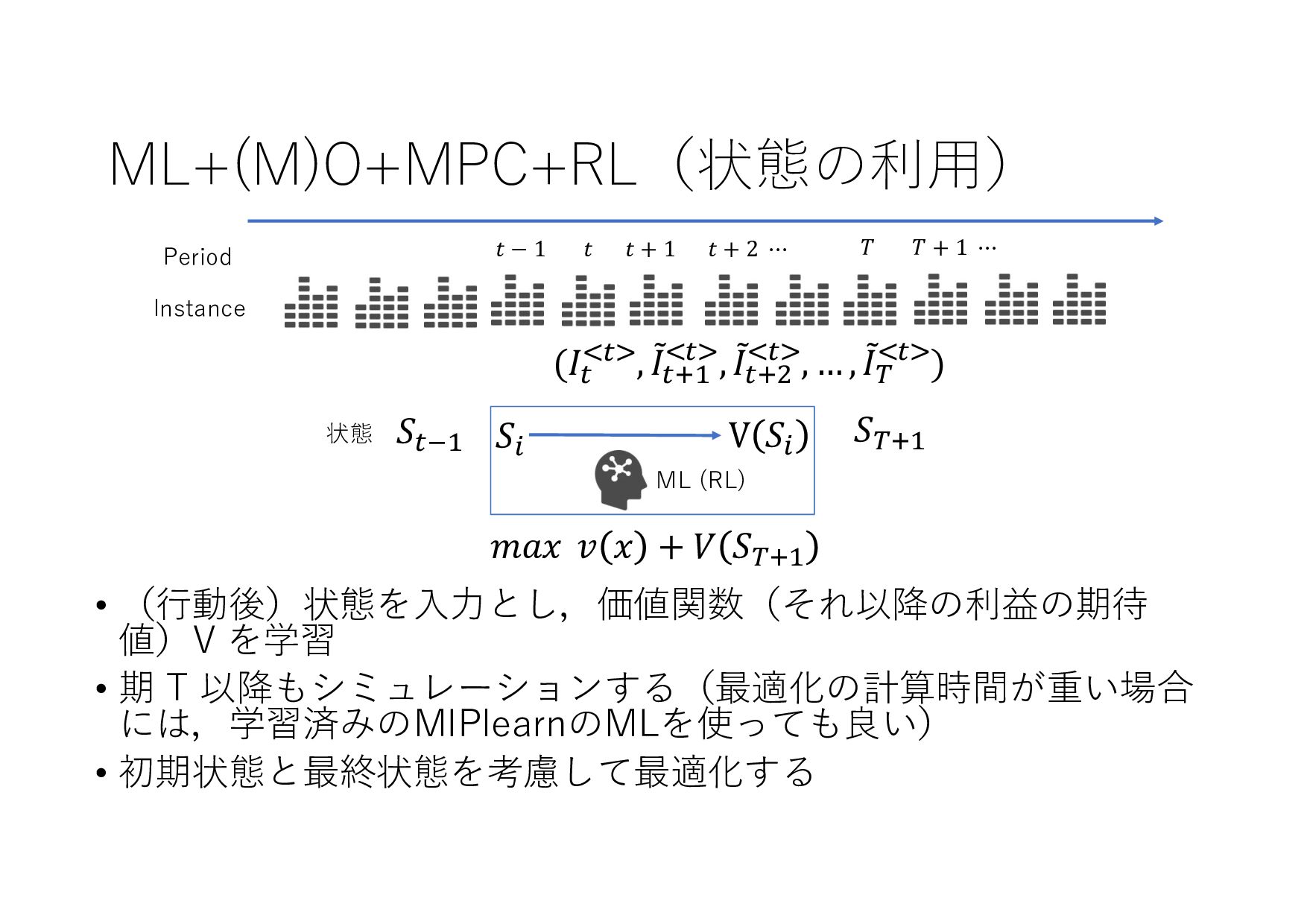
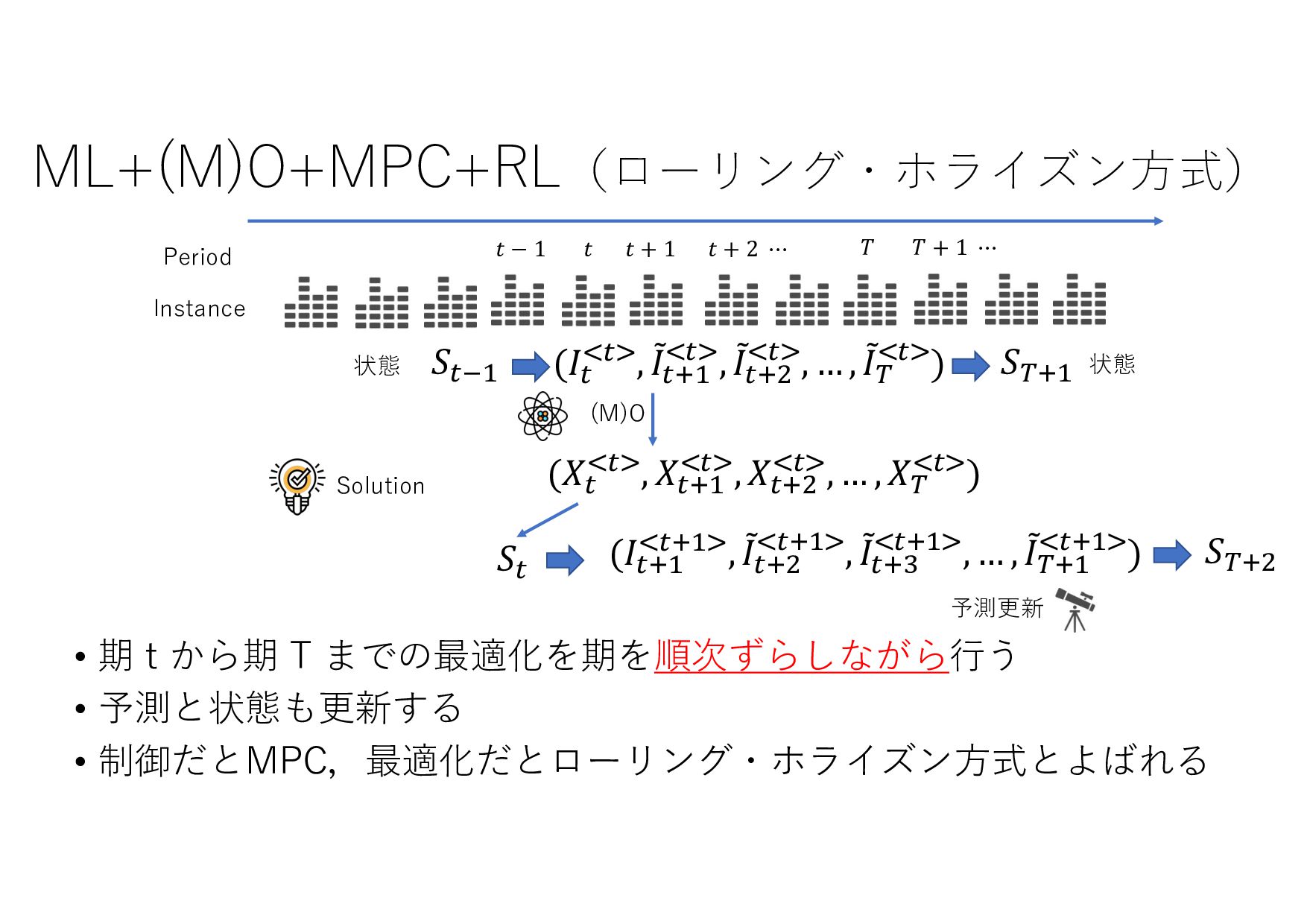
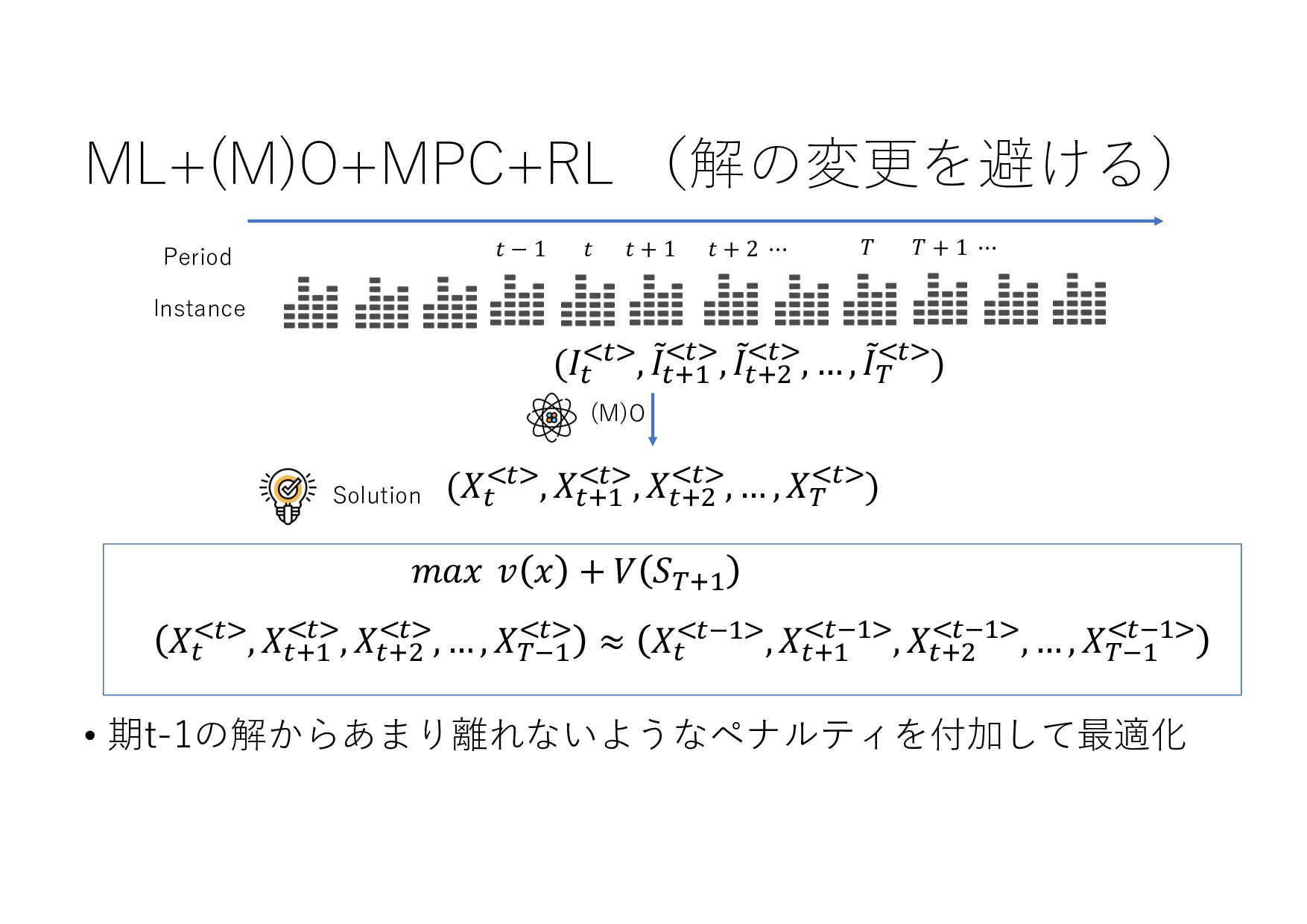
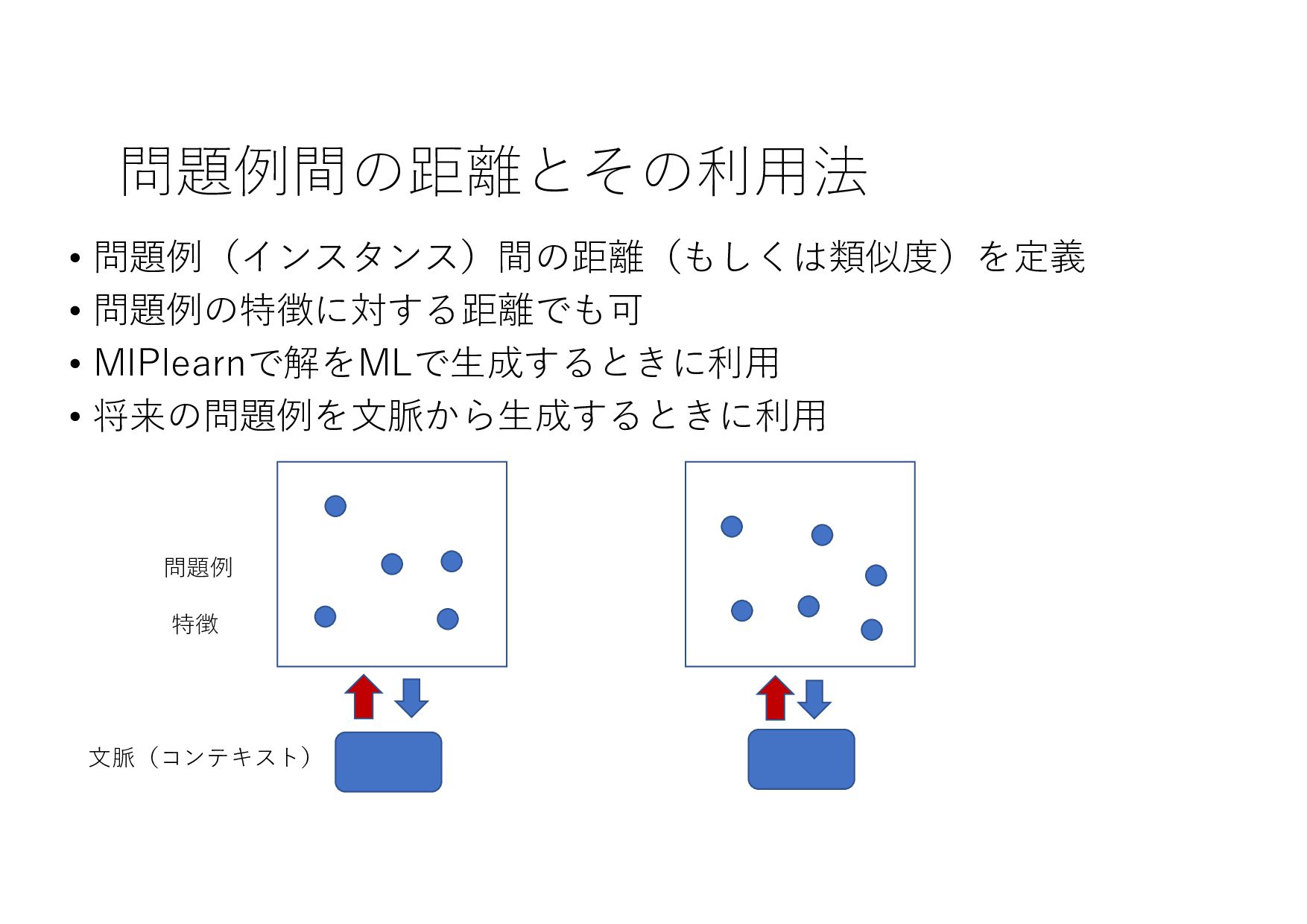
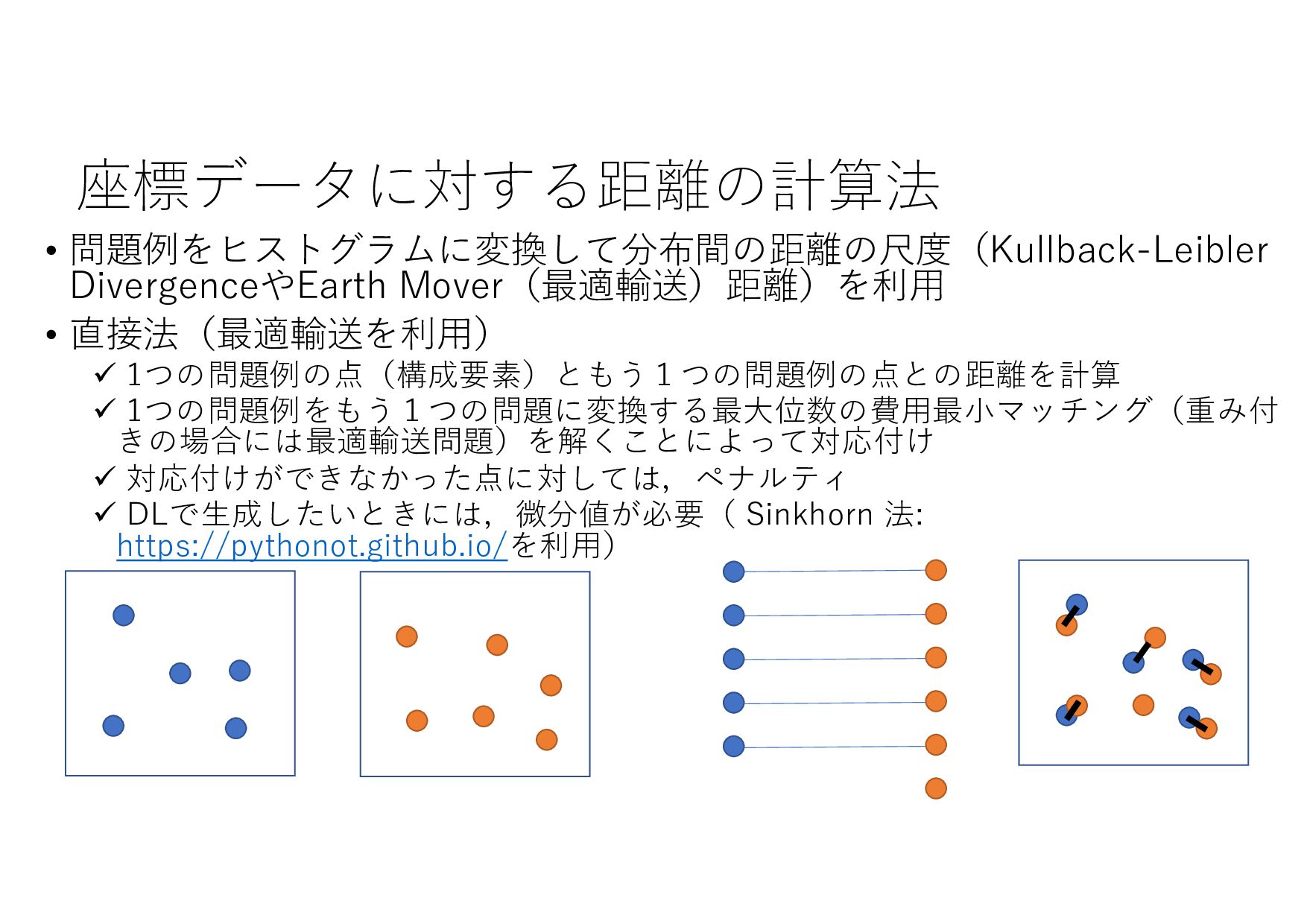
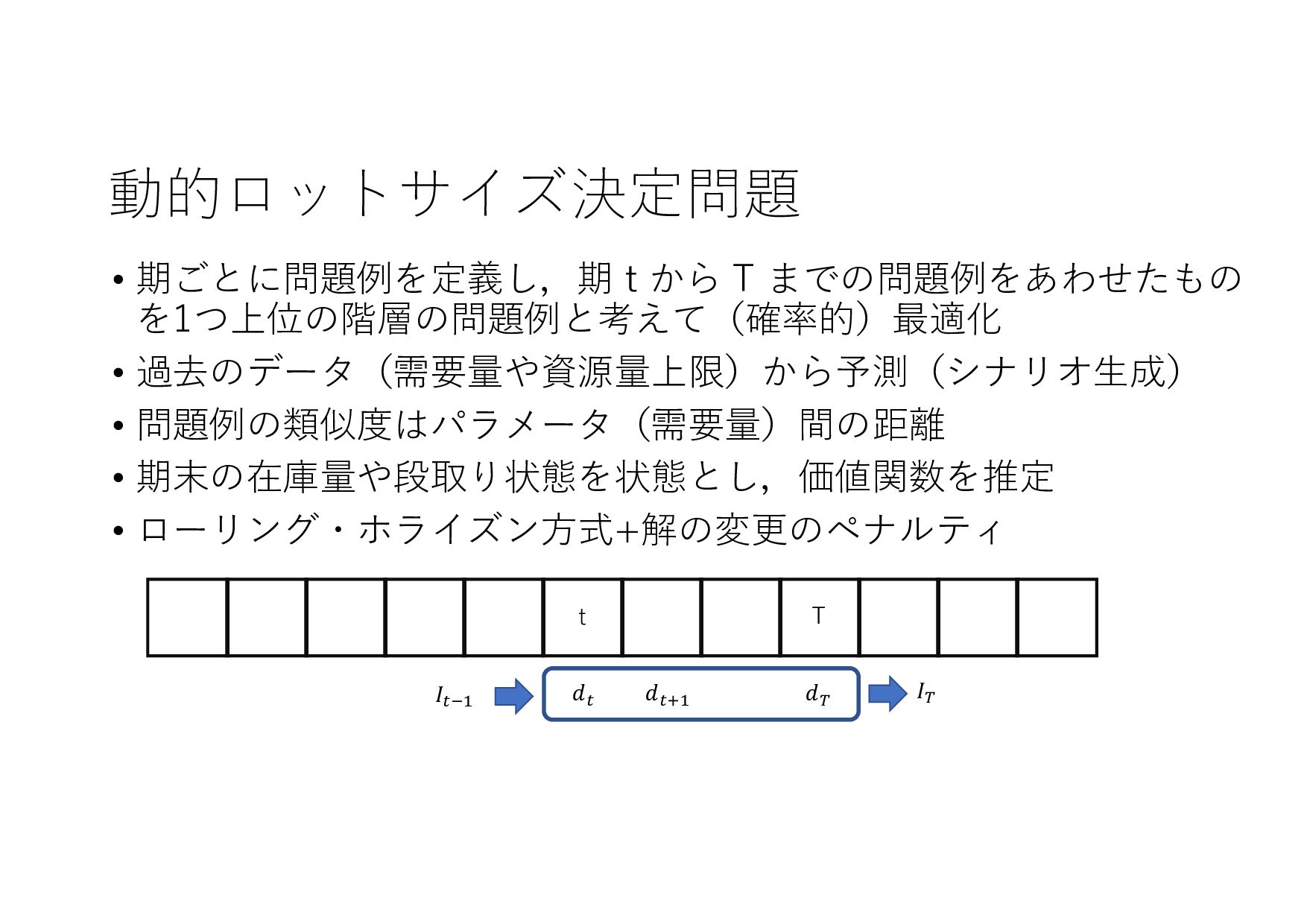
− 1 𝑡 𝑡 + 1 𝑡 + 2 ⋯ 𝑇 𝑇 + 1 ⋯ (𝐼+ .+/, 8 𝐼+,- .+/, 8 𝐼+,0 .+/, … , 8 𝐼& .+/) (𝑋+ .+/, 𝑋+,- .+/, 𝑋+,0 .+/, … , 𝑋& .+/) (8 𝐼+,-, 8 𝐼+,0 , … , 8 𝐼& , ⋯ ) ML ML (MIPlearn) ML (MIPlearn) State 𝐼) (𝑖 = ⋯ , 𝑡 − 1, 𝑡) (𝑋) .)/, 𝑋),- .)/, 𝑋),0 .)/, ⋯ ) (𝑖 = ⋯ , 𝑡 − 1) (𝐼) .)/, 8 𝐼),- .)/, 8 𝐼),0 .)/, ⋯ ) 固定制約 部分解 近似解 𝑆+1- 𝑆) ML (RL) V 𝑆) 𝑆&,- 𝑚𝑎𝑥 𝑣 𝑥 + 𝑉 𝑆&,- 𝑋! "!#, 𝑋!$% "!#, 𝑋!$& "!#, … , 𝑋'(% "!# ≈ 𝑋! "!(%#, 𝑋!$% "!(%#, 𝑋!$& "!(%#, … , 𝑋'(% "!(%# MPC 状態 価値関数
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
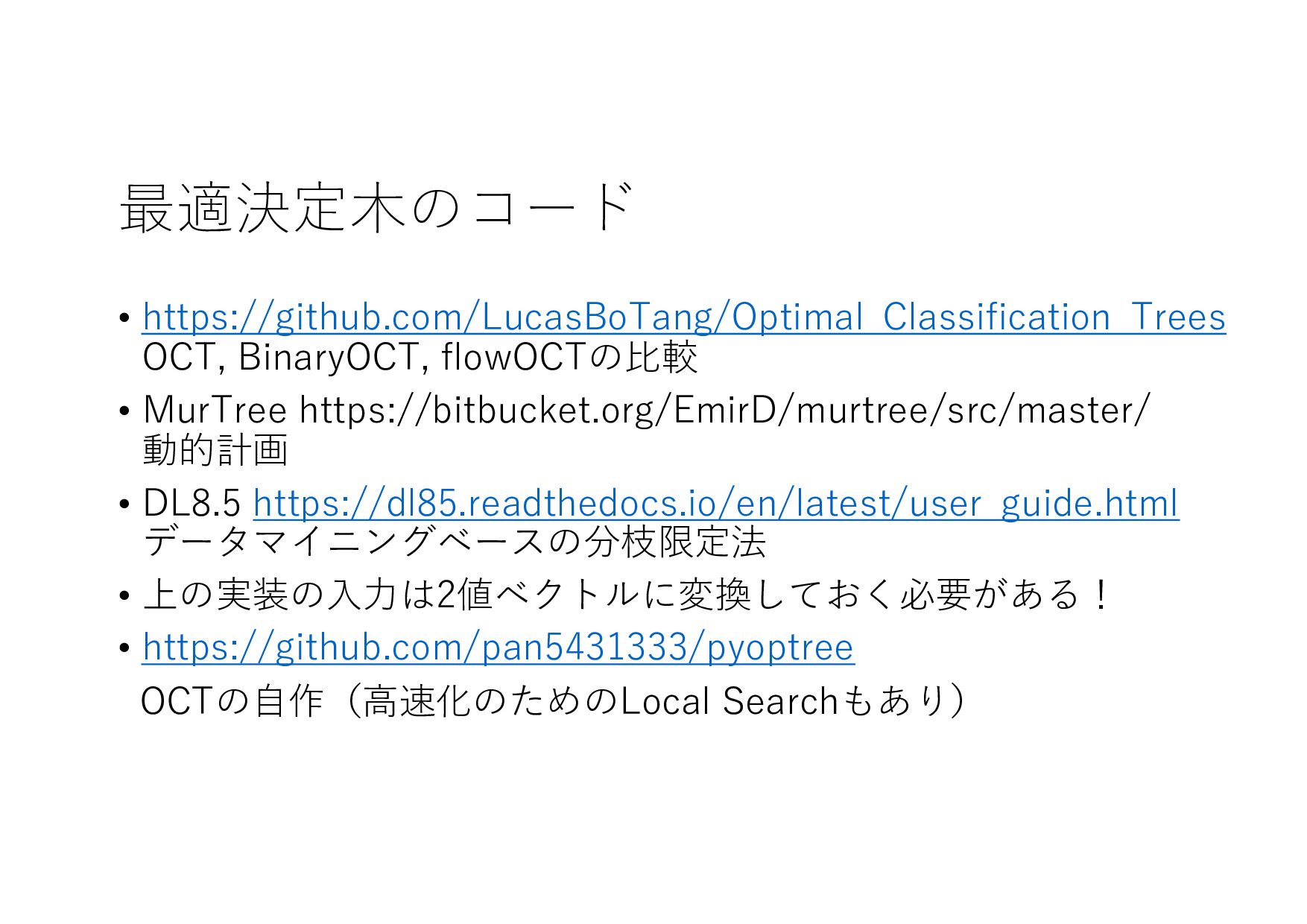{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
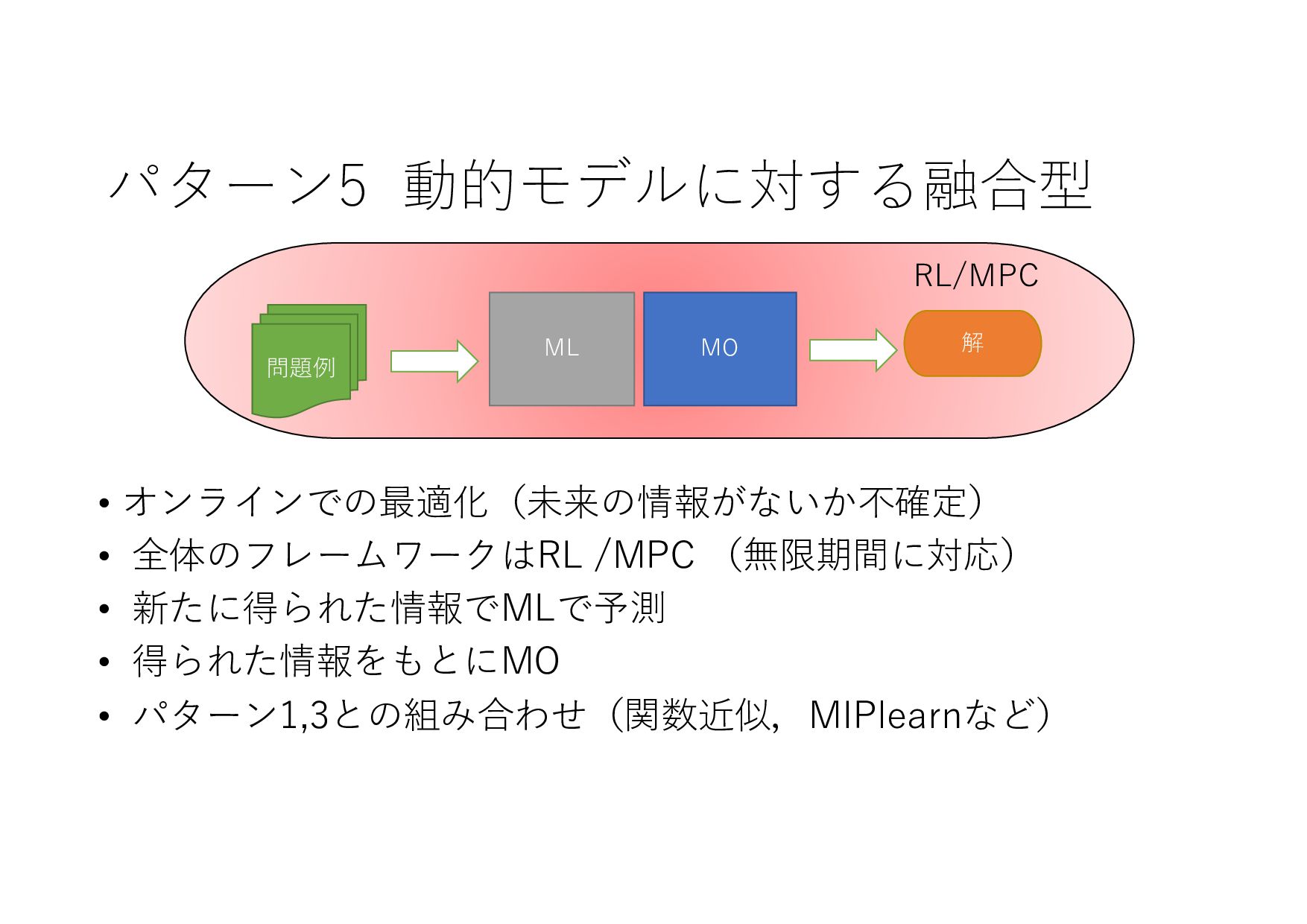{kind=link}
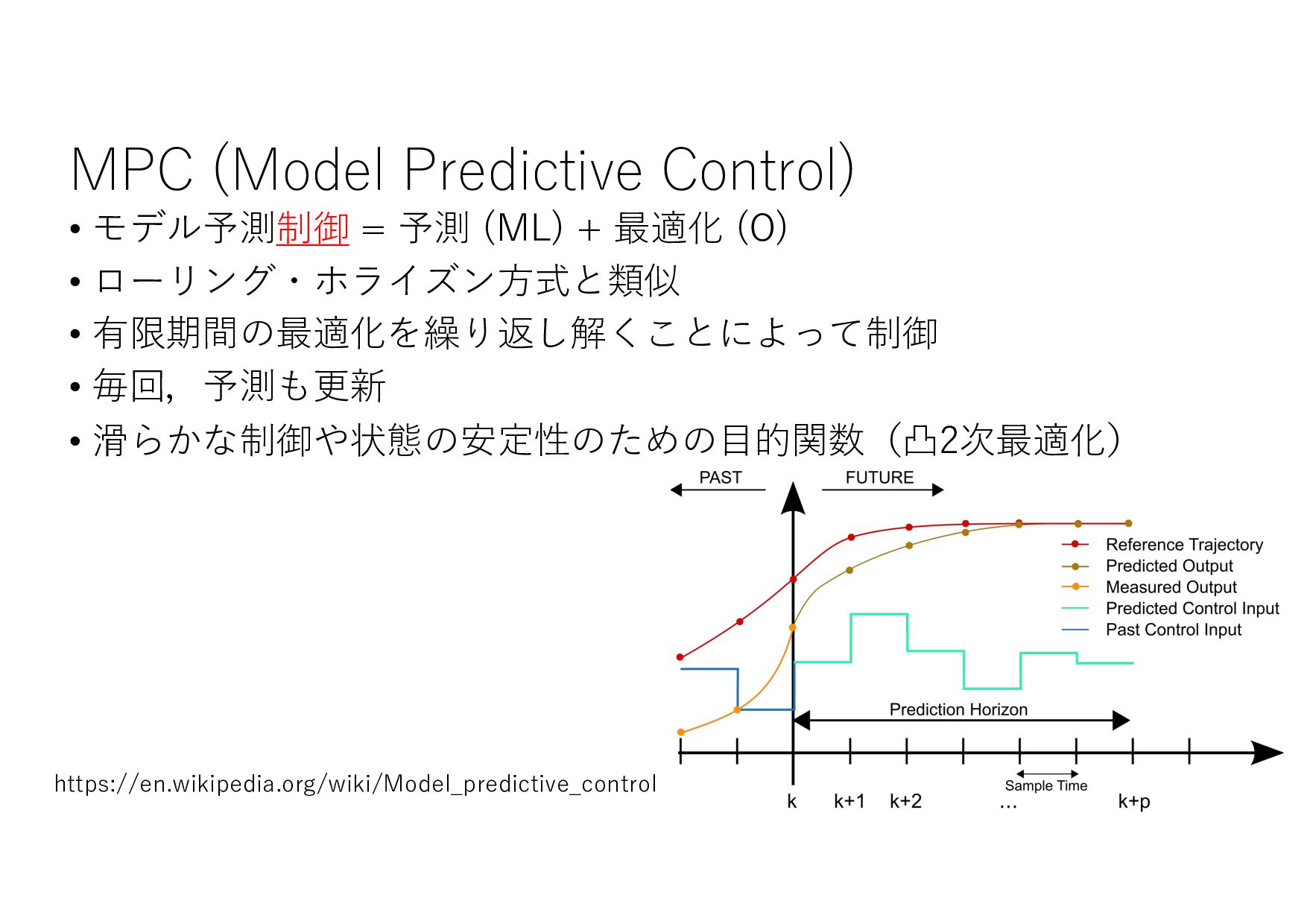{kind=link}
{kind=link}
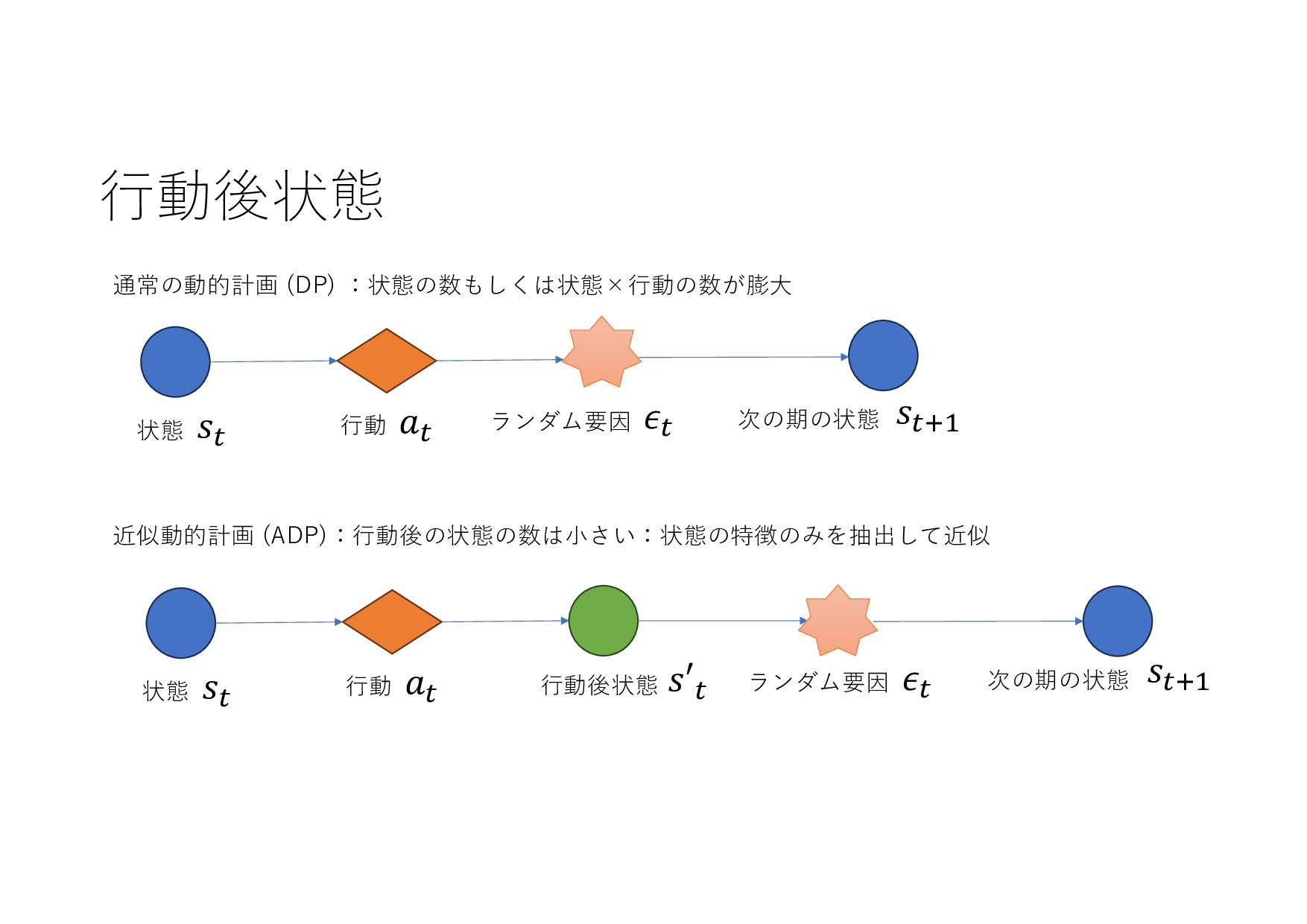{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
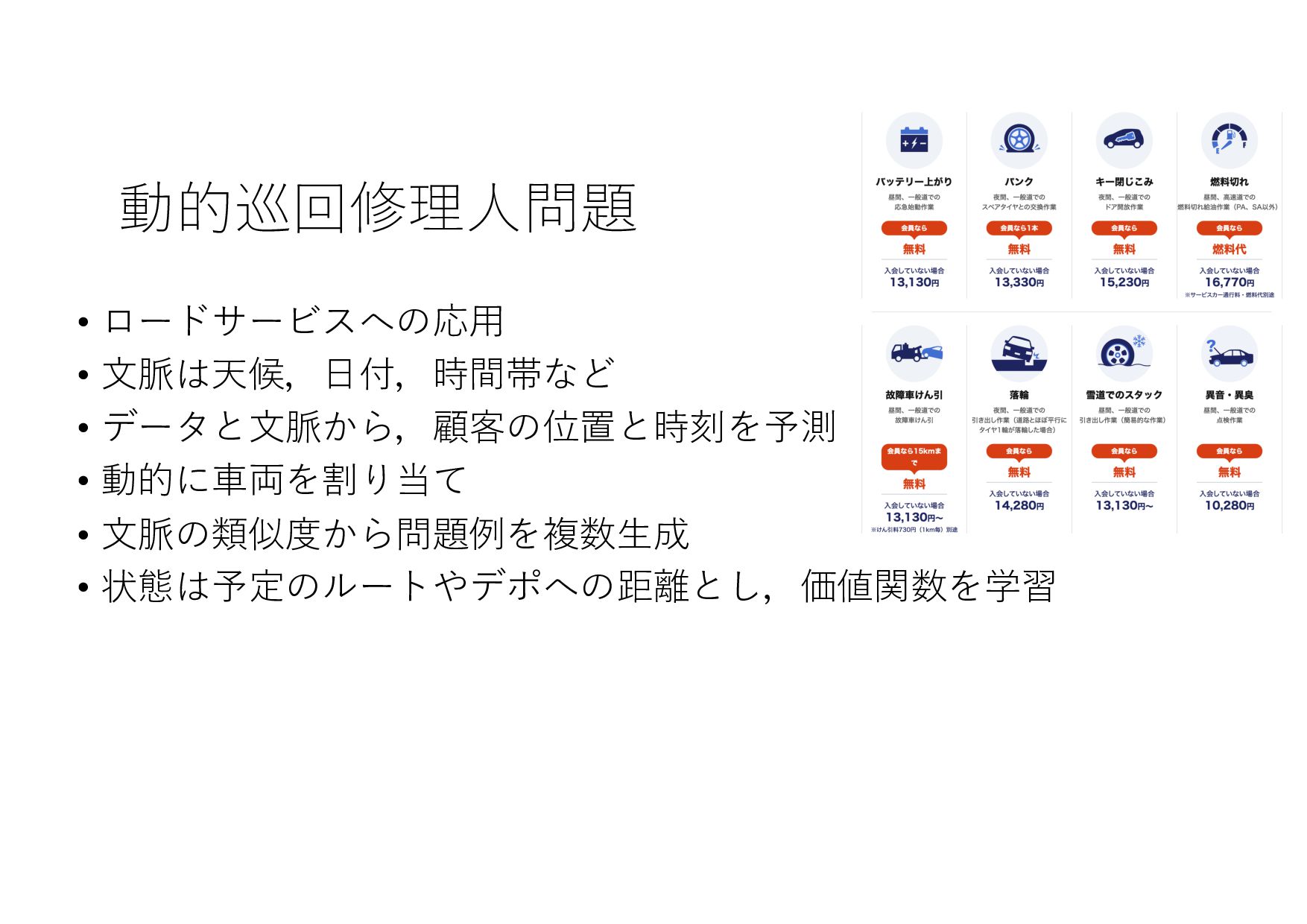{kind=link}
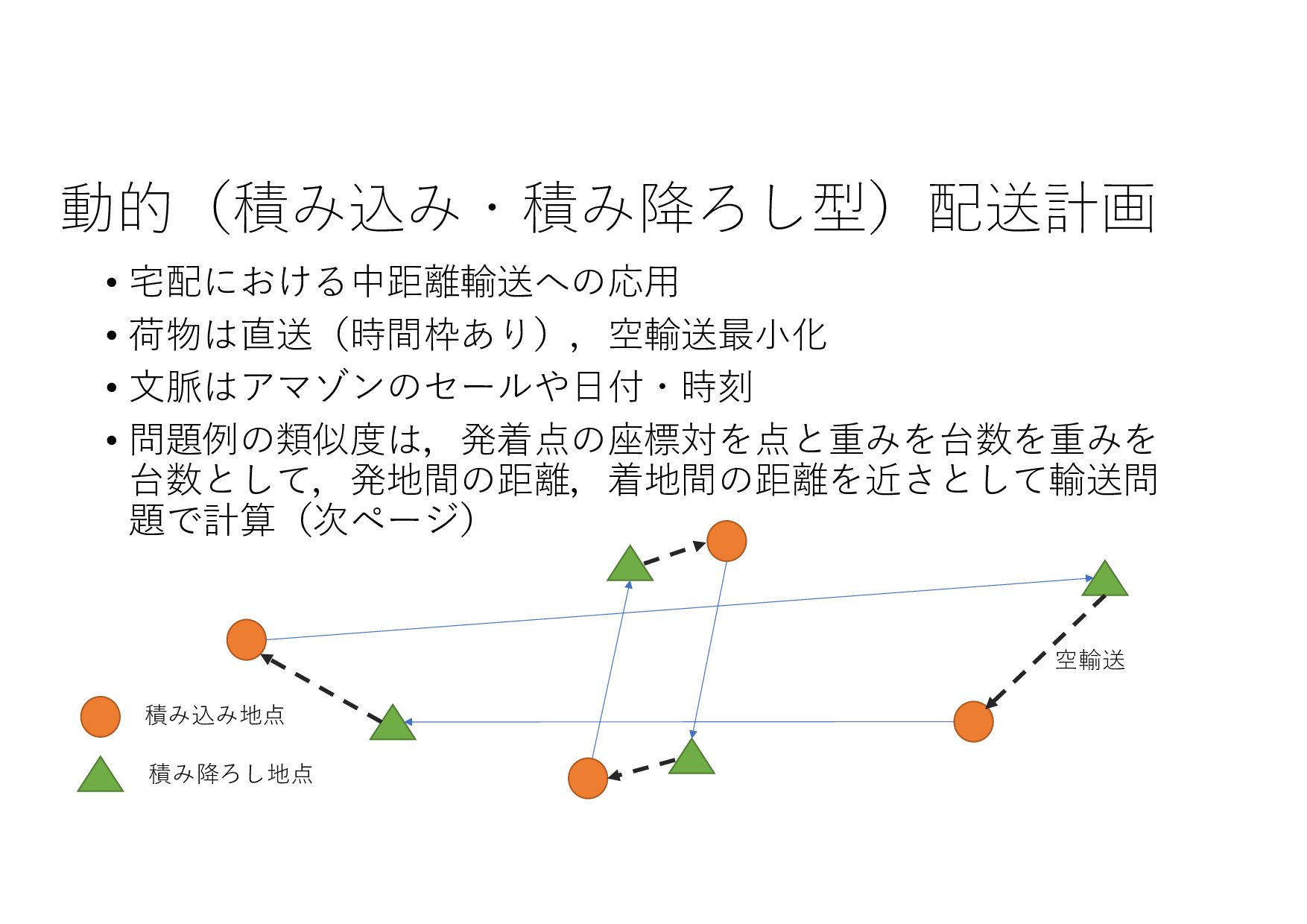{kind=link}
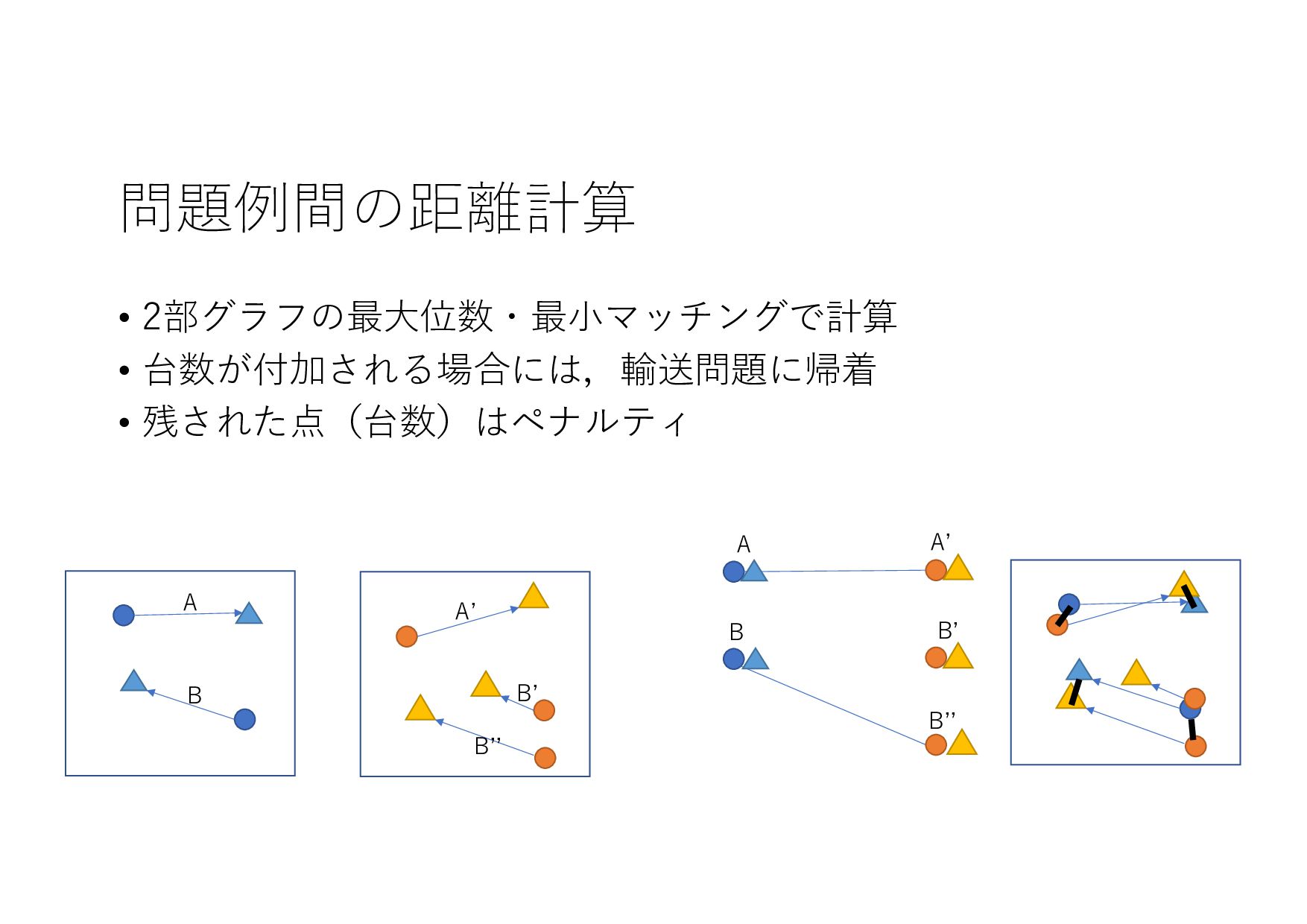{kind=link}
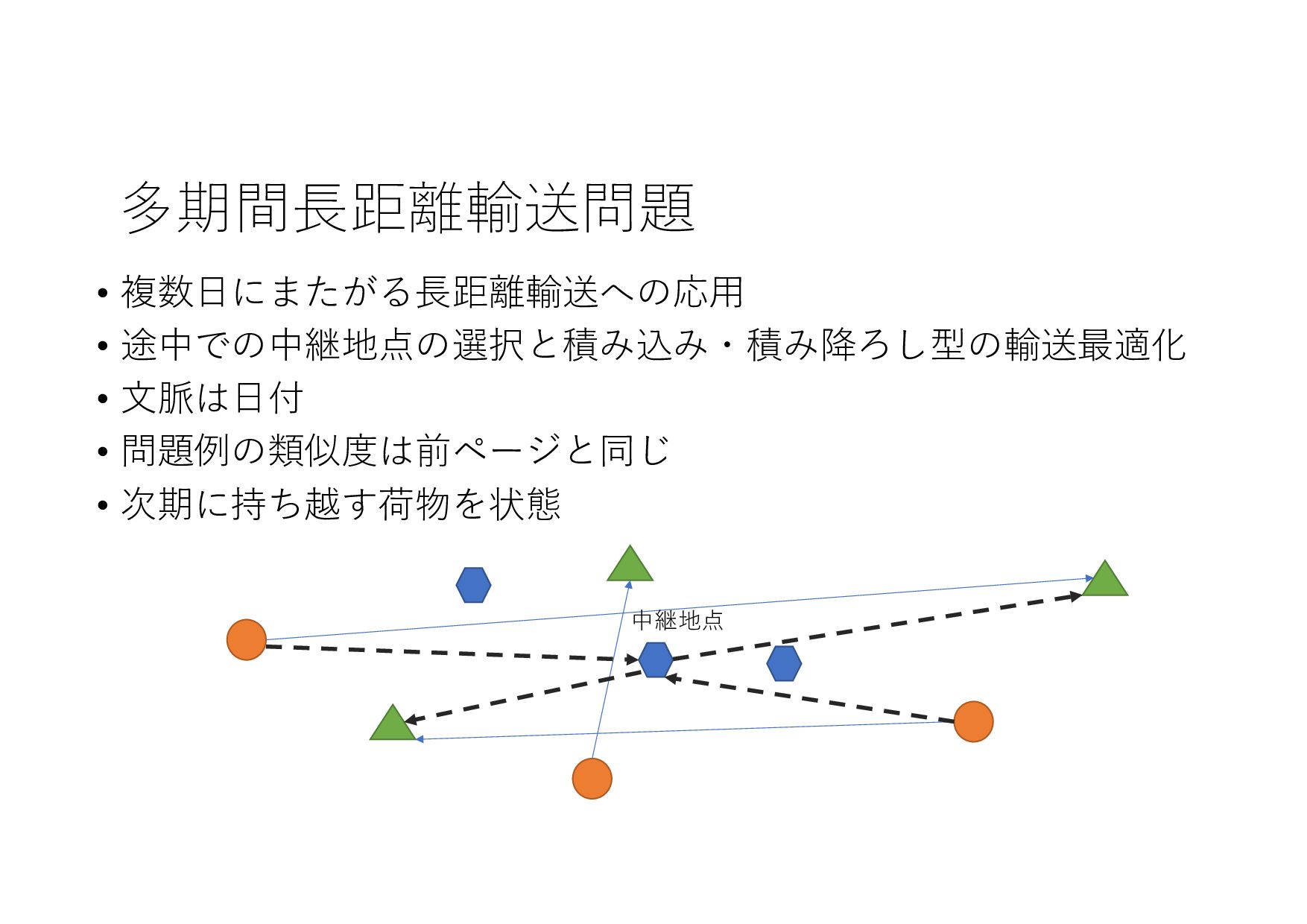{kind=link}
{kind=link}
{kind=link}
{kind=link}