Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
10gatu
Search
miyanishi
October 21, 2014
350
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
10gatu
miyanishi
October 21, 2014
More Decks by miyanishi
See All by miyanishi
平成27年度最終ゼミ
miyanishi
0
91
文献紹介1月
miyanishi
0
200
文献紹介12月
miyanishi
0
260
文献紹介11月
miyanishi
0
260
文献紹介10月
miyanishi
0
200
文献紹介(2015/09)
miyanishi
0
230
文献紹介8月(PPDB)
miyanishi
0
340
文献紹介15年08月
miyanishi
0
240
15年7月文献紹介
miyanishi
0
270
Featured
See All Featured
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
250
The Illustrated Children's Guide to Kubernetes
chrisshort
51
52k
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.6k
How GitHub (no longer) Works
holman
316
150k
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3.4k
sira's awesome portfolio website redesign presentation
elsirapls
0
280
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
720
JavaScript: Past, Present, and Future - NDC Porto 2020
reverentgeek
52
6k
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
65
55k
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
360
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
160
Transcript
文献紹介ゼミ 長岡技術科学大学 山本研究室 M1 宮西 由貴 1
著者情報 • Title: Word-Sense Disambiguation Using Statistical Models of Roget’s
Categories Trained on Large Corpora • 著者: David Yarowsky • COLING-92 p454-460 2
概要 • 統計モデルを使った英語のWSDシステム – 訓練データ:大量の平文テキストを使用 – 入力:文 – 出力:Roget’s Thesaurusのカテゴリタグ
• 多義性のある12語に対して実験 – 平均92%の正解率 3
背景 • 語義曖昧性に統計を利用するボトルネック – 大量のタグ付きコーパスを使用 – 人手での処理→コスト高 • 上記問題の解決策 –
人手の加わったコーパスを使わないシステム – 多量の平文コーパスを使用 4
システムについて • “語義”の定義 – 明確な定義がない – 今回:Roget’s International Thesaurus のカテゴリ
• 使用するモデル – カテゴリの中で一番確率が高いものを選択 • 入出力 – 入力:文 – 出力:カテゴリ名 5
提案手法:3つの仮定 • 異なる概念集合は異なる文脈で使われる • 異なる語義は異なる概念集合に属する • 概念集合用の文脈識別器が存在する場合 →多義性解消のための文脈識別器と同等 Roget’sのカテゴリを概念集合とみなす 6
提案手法:3つの操作 • 各々のカテゴリ内の代表となるcontextを収集 • 重要語を同定&語に重要度の重み付け • 上記結果を用いたふさわしいカテゴリの推定 7
提案手法:3つの操作 • 各々のカテゴリ内の代表となるcontextを収集 • 重要語を同定&語に重要度の重み付け • 上記結果を用いたふさわしいカテゴリの推定 8
contextの収集 • 使用コーパス – Grolier’s Encyclopedia(1991の最新版) • 手法 – コーパス内からカテゴリ内の語を検索
– その周辺語100語の用語索引を引く • ノイズ除去 – 同じカテゴリにおいての多義性→許容 – その他→コーパス内の出現頻度の逆数を重みに 9
提案手法:3つの操作 • 各々のカテゴリ内の代表となるcontextを収集 • 重要語を同定&語に重要度の重み付け • 上記結果を用いたふさわしいカテゴリの推定 10
重要語の重み付け • 単純なイメージ – 重要語=そのカテゴリの文脈に頻繁に出る語! • 上記のイメージを式で表現 – 相互情報量:Pr (|)
Pr () RCat= Roget’sカテゴリ Pr :単語の出現頻度 Pr (|):単語とカテゴリの条件付き確率 • 相互情報量のlogを重みとして付与 11
提案手法:3つの操作 • 各々のカテゴリ内の代表となるcontextを収集 • 重要語を同定&語に重要度の重み付け • 上記結果を用いたふさわしいカテゴリの推定 12
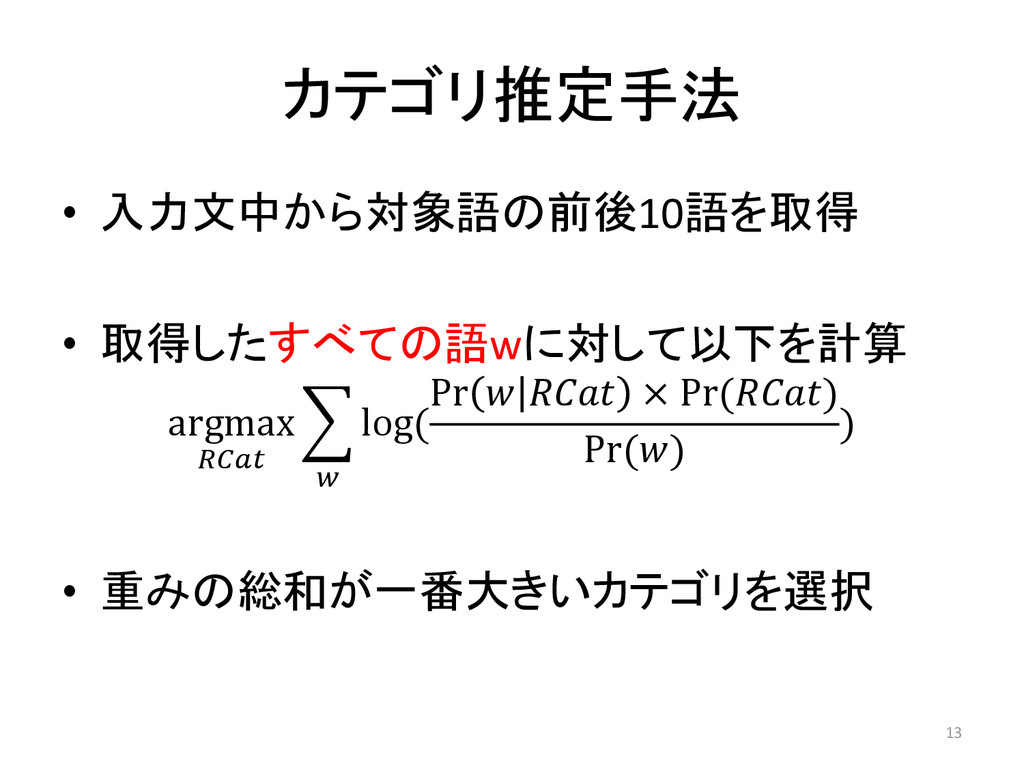
カテゴリ推定手法 • 入力文中から対象語の前後10語を取得 • 取得したすべての語wに対して以下を計算 argmax log ( Pr ×
Pr () Pr () ) • 重みの総和が一番大きいカテゴリを選択 13
実験について • 12個の多義語を選択 – star, mole, galley, cone, bass, bow,
taste, interest, issue, duty, sentence, slug 単語 語義 RCat 頻度 正解率 平均正解率 space object UNIVERSE 1422 96% celebrity ENTERTAINER 222 95% star-shaoed object INSIGNIA 56 82% star 96% 14
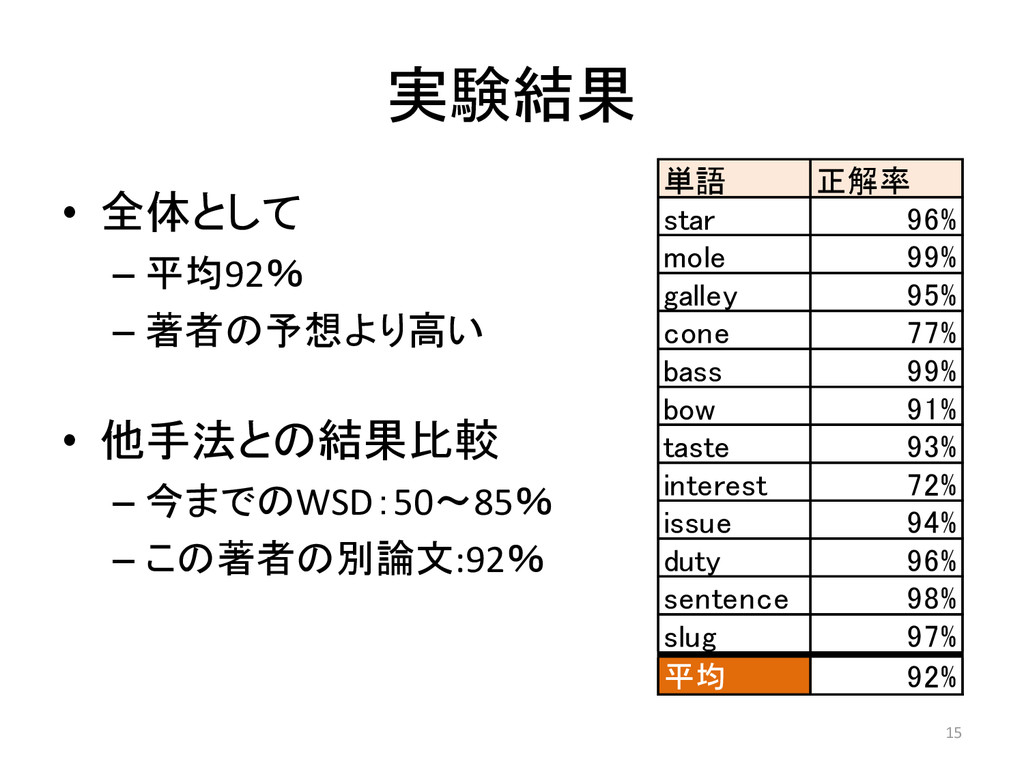
実験結果 • 全体として – 平均92% – 著者の予想より高い • 他手法との結果比較 –
今までのWSD:50~85% – この著者の別論文:92% 単語 正解率 star 96% mole 99% galley 95% cone 77% bass 99% bow 91% taste 93% interest 72% issue 94% duty 96% sentence 98% slug 97% 平均 92% 15
概要 • 統計モデルを使った英語のWSDシステム – 訓練データ:大量の平文テキストを使用 – 入力:文 – 出力:Roget’s Thesaurusのカテゴリタグ
• 多義性のある12語に対して実験 – 平均92%の正解率 – 他手法より有利な結果 16
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}