Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
2015年1月 文献紹介ゼミ
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
miyanishi
January 23, 2015
330
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
2015年1月 文献紹介ゼミ
miyanishi
January 23, 2015
More Decks by miyanishi
See All by miyanishi
平成27年度最終ゼミ
miyanishi
0
91
文献紹介1月
miyanishi
0
200
文献紹介12月
miyanishi
0
260
文献紹介11月
miyanishi
0
260
文献紹介10月
miyanishi
0
200
文献紹介(2015/09)
miyanishi
0
230
文献紹介8月(PPDB)
miyanishi
0
340
文献紹介15年08月
miyanishi
0
240
15年7月文献紹介
miyanishi
0
270
Featured
See All Featured
Thoughts on Productivity
jonyablonski
76
5.2k
How People are Using Generative and Agentic AI to Supercharge Their Products, Projects, Services and Value Streams Today
helenjbeal
1
210
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
840
The Invisible Side of Design
smashingmag
302
52k
Tell your own story through comics
letsgokoyo
1
950
Max Prin - Stacking Signals: How International SEO Comes Together (And Falls Apart)
techseoconnect
PRO
0
180
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
560
The innovator’s Mindset - Leading Through an Era of Exponential Change - McGill University 2025
jdejongh
PRO
1
200
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
190
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.7k
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
2
390
個人開発の失敗を避けるイケてる考え方 / tips for indie hackers
panda_program
122
22k
Transcript
文献紹介ゼミ 自然言語処理研究室 M1 宮西 由貴
文献情報 • タイトル – Naïve Bayes Word Sense Induction •
著者 – Du Kook Choe – Engene Charniak • 発表学会 – EMNLP2013(p1433-1437)
概要 • ナイーブベイズを利用した語義推定 – シンプルな手法の提案 • 名詞の語義推定にて特に良い結果 – F値であれば他の手法に全体的に勝利
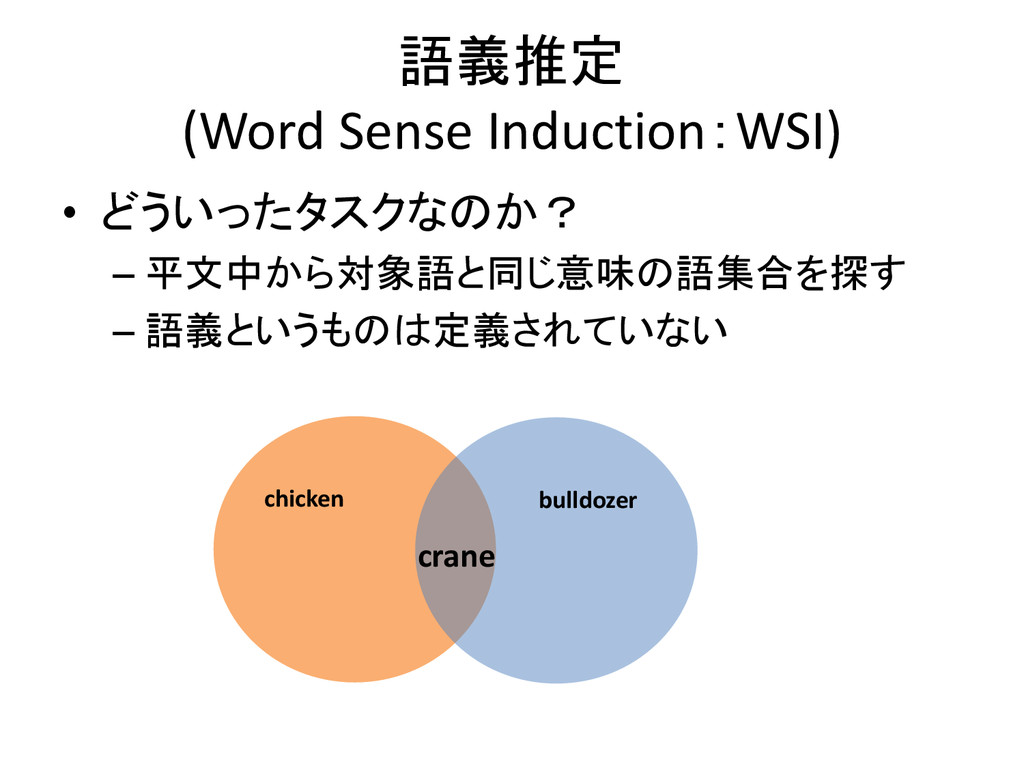
語義推定 (Word Sense Induction:WSI) • どういったタスクなのか? – 平文中から対象語と同じ意味の語集合を探す – 語義というものは定義されていない
crane chicken bulldozer
語義推定 (Word Sense Induction:WSI) • 語義曖昧性解消(WSD)より優れている? – WSIの方が新語や新語義に強い – ある特定の領域に使われる語にも強い
– WSDは使用するリソースのボトルネックがある – 現在の精度WSD>WSI
関連研究 • Yarowsky(1995) – 半教師ありブートストラップアルゴリズムを提唱 – 2つの仮定も提唱 • One-Sense-per-Collocation •
One-Sense-per-discource • 上記アルゴリズムでは不十分 – 新語に対応する際は人手での情報が必要
提案したモデルについて • Yarowskyの仮説に沿って・・・ – One-Sense-per-document – 複数の語が同じ文書に出現→同じコンセプト • 文書はひとつのトピックを持つ –
トピックを使って曖昧な語義を決定
ナイーブベイズを使ったモデル
モデルの拡張 • 語が遠い→単語の意味も遠い – 対象語と他の語の距離を考慮したシステム
実験 • データ – SemEval2010のWSIタスクのものを使用 • SemEval2010のWSIタスク – 資源としてNLPツール以外使用付加 •
POS-Tagger • Parser • Lemmatizer など – パラメータの調整などはトレーニング中のみ可
詳細な手法 • 文脈は50語とする – Bag-of-wordsを構築 • 文書中に複数回同じ語が出現した場合は・・・ – 語の遠さを測定 –
(例)shiningと一番近いのは2番目のchip
比較手法 • MFS – ベースライン – 一番頻度の高い語義を使用 • UoY –
クラスタリングアルゴリズム – グラフを用いたもの(単語と共起頻度)
比較手法 • Hermit – K-means法を改良したアルゴリズム – 階層的な集合のクラスタリングを行うもの • NMFlib –
マトリックスを用いたクラスタリングアルゴリズム – 他の手法より新しいもの(2011)
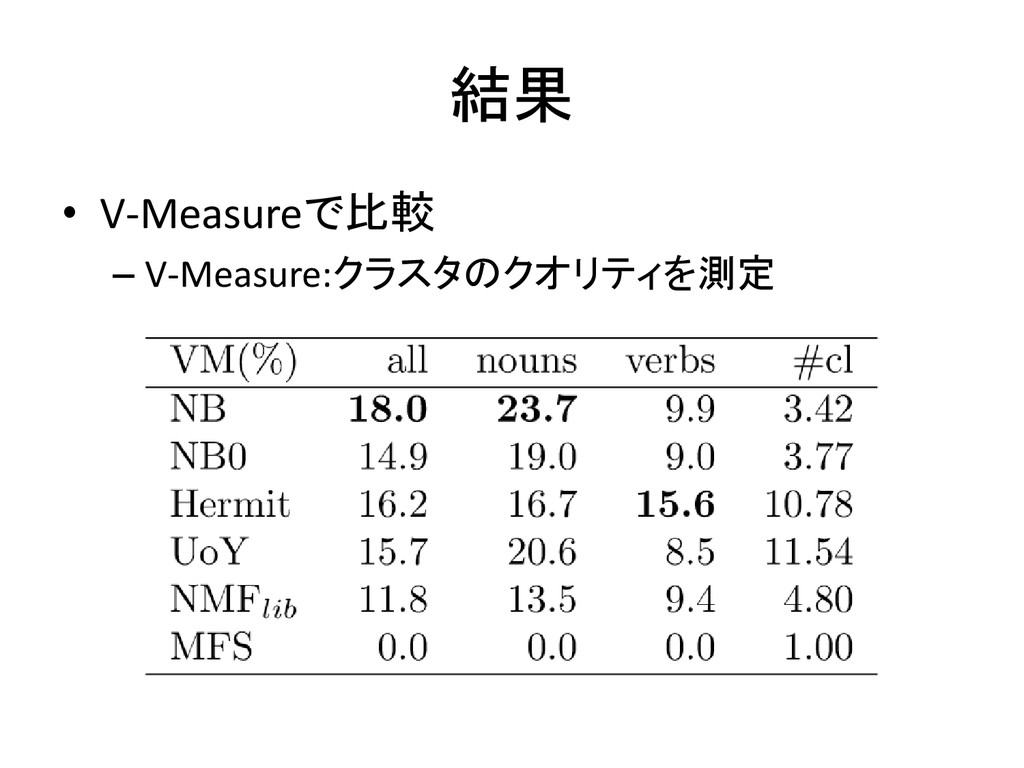
結果 • V-Measureで比較 – V-Measure:クラスタのクオリティを測定
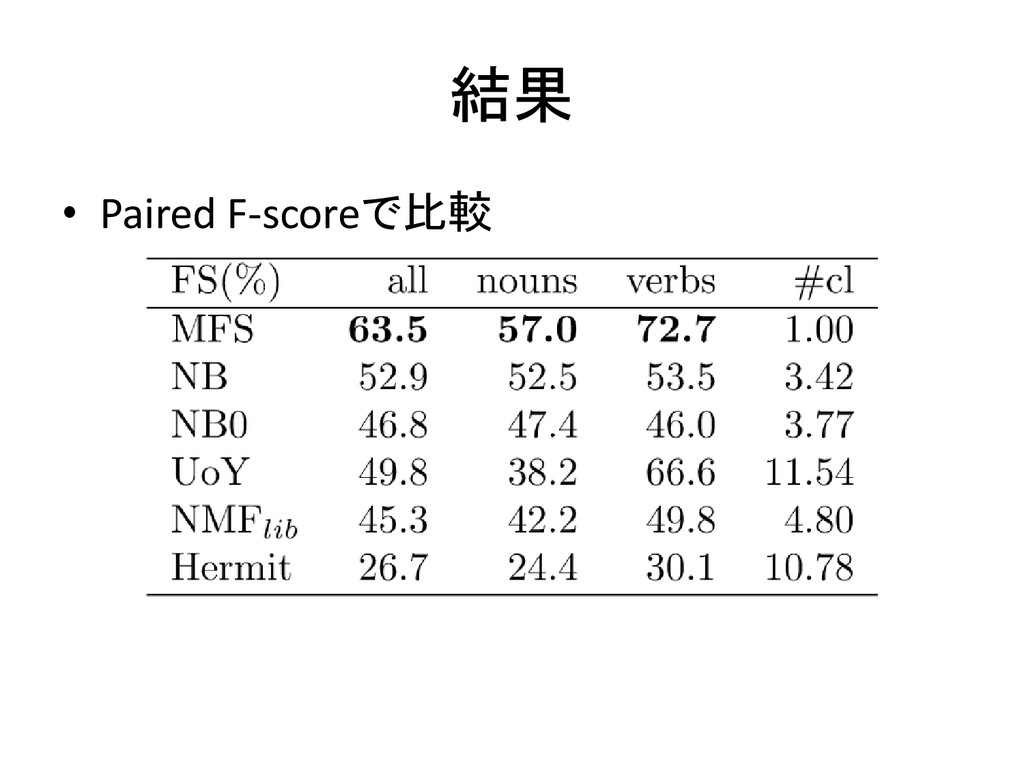
結果 • Paired F-scoreで比較
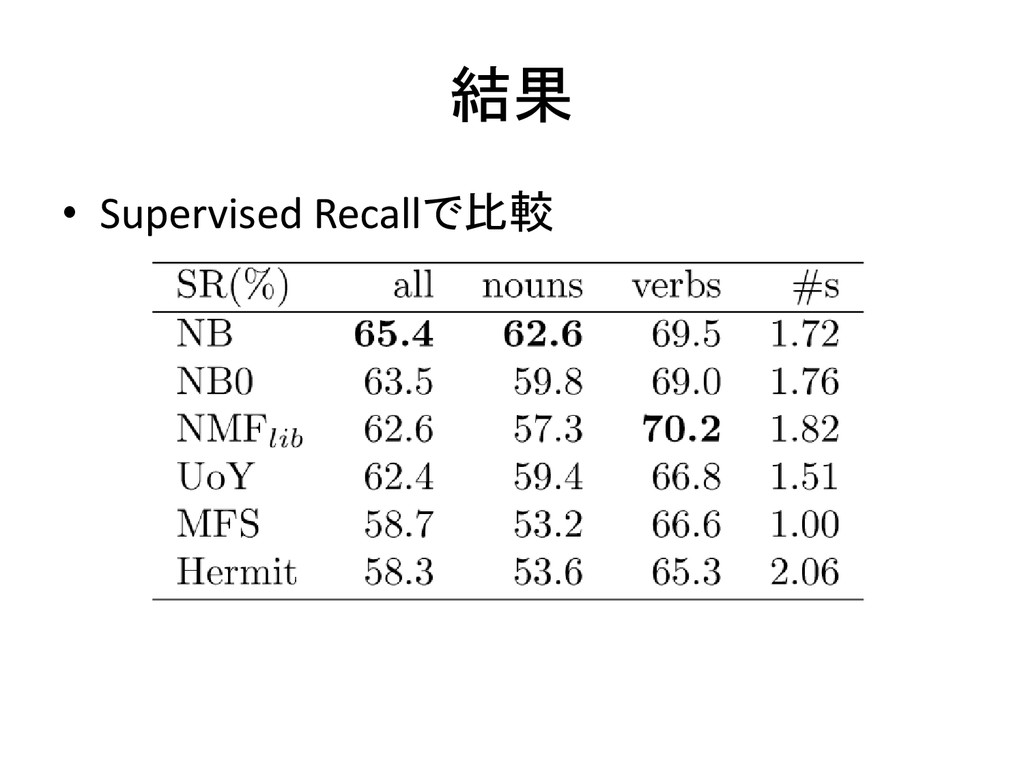
結果 • Supervised Recallで比較
まとめ • ナイーブベイズを利用した語義推定 – シンプルな手法の提案 • 名詞の語義推定にて特に良い結果 – F値であれば他の手法に全体的に勝利
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
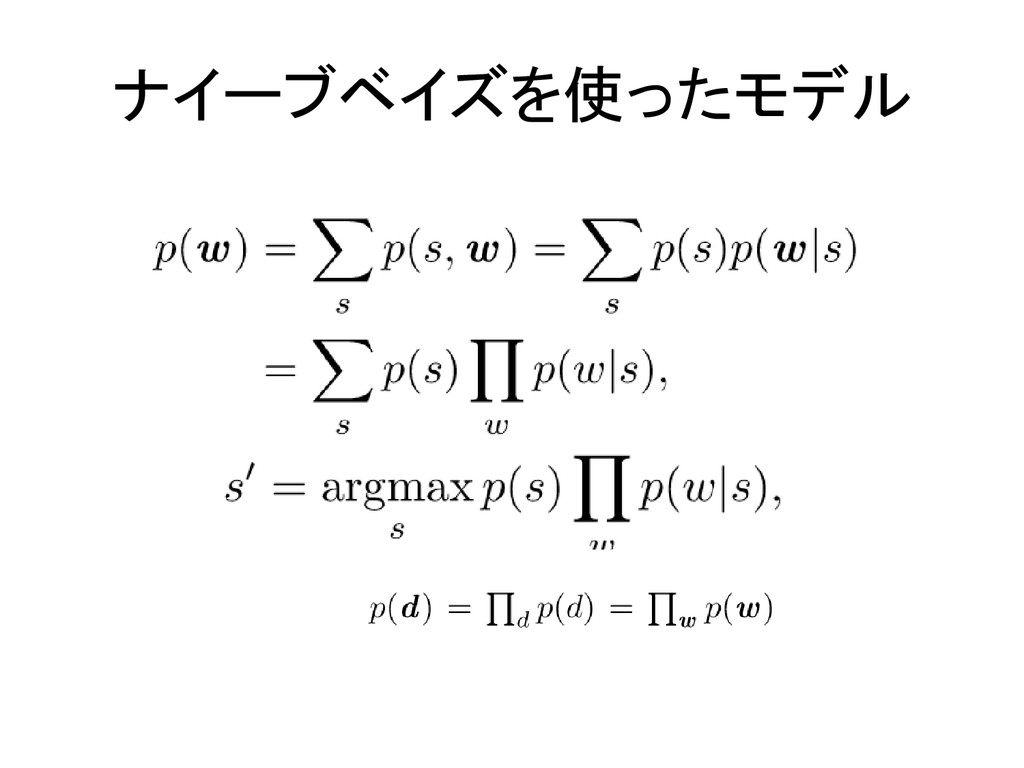{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}