Talk for RubyConf Brazil introducing Pusher, some patterns for managing complexity in evented code, and some thoughts on distributed systems - specifically how we manage state and messaging at Pusher.
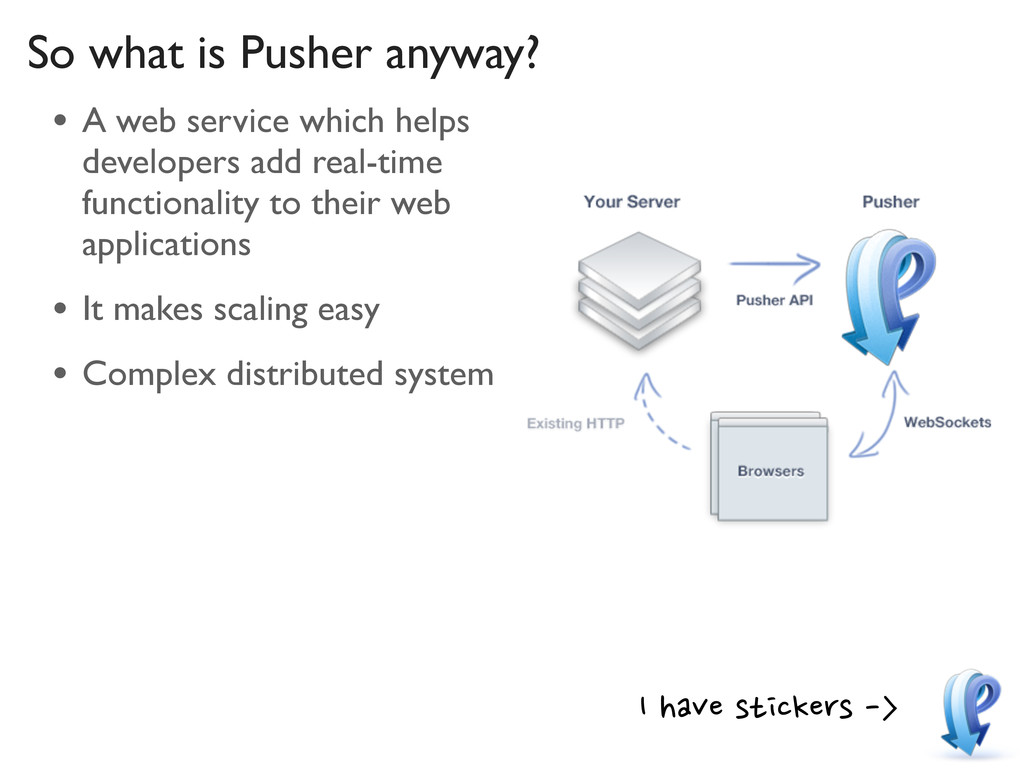
introduction to Pusher • The event loop • Why you’d use it • Managing complexity • The distributed system • Some general considerations • Some specific problems and how we solved them
job_params| http = EM::HttpRequest.new(job_params['url'].post({ :body => job_params["data"] }) http.callback do |response| df.success end http.errback do df.fail end end
Work doesn’t fit on a single machine any more • You need better availability • How can I make one? • Decouple the application so that each function is handled by a separate component • Scale components horizontally, and independantly • Make components tolerant to failure
provide all three of the following guarantees: - Consistency (all nodes see the same data at the same time) - Availability (a guarantee that every request receives a response about whether it was successful or failed) - Partition tolerance (the system continues to operate despite arbitrary message loss) http://en.wikipedia.org/wiki/CAP_theorem State: CAP theorem
How durable does it need to be? • How much data do you need to store? • Does it need to be highly available? • Does it need to be consistent / eventually consistent?
messaging? • A single all powerful box • Simple, but hard to scale • Custom messaging topologies • ZeroMQ - point to point, fanout, pubsub, load balanced • Lots of choices, therefore complex • This is the future, but we’re not quite there yet
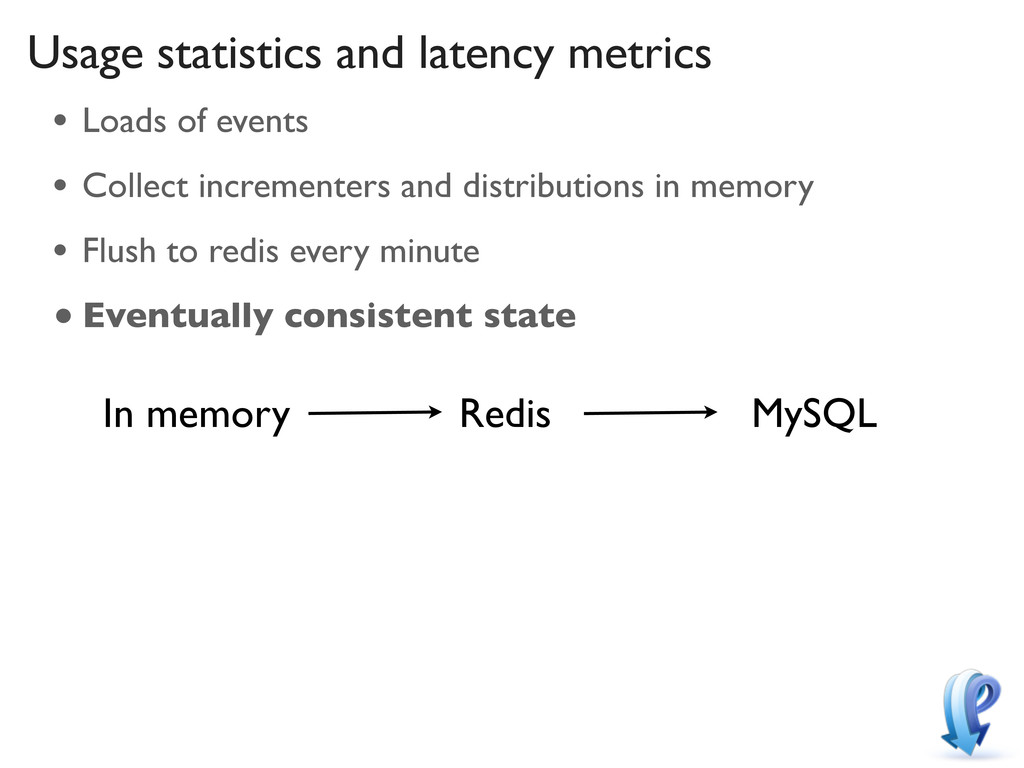
joins or leaves a channel • Needs to be consistent across processes • Use redis incrementers • Needs to survive process failure • Use a global hash, and a hash per process, with redis transactions • Consistent state
all connections • Unnecessary messaging, most of the time • Only publish data when it’s needed • Eventually consistent, distributed state, cached in memory
= RedisLiveSet.new("debug_open") set.add('42') # redis.sadd("debug_open", 42) # redis.publish("debug_open", ["sadd", "42"]) # On another process set.member?('42') # Checks the in memory set
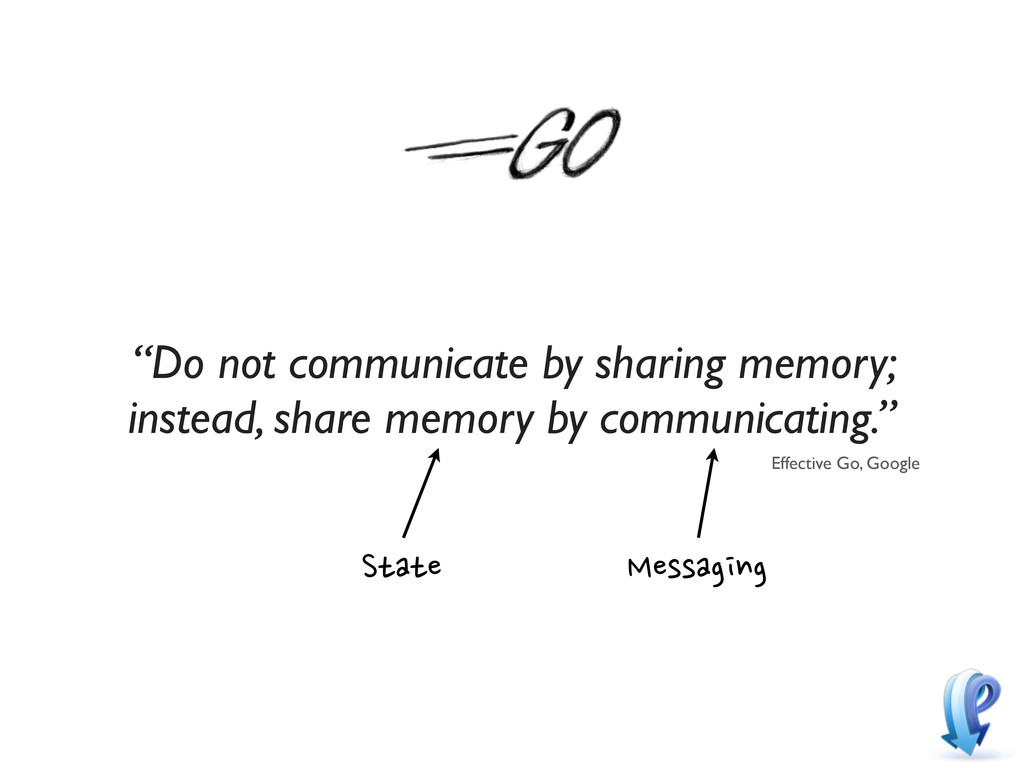
EventMachine is great, you don’t need to use node.js • Think about state & messaging • It’s all about compromises; there are no right answers • Find creative solutions to your problems
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks for listening Martyn Loughran [email protected] @mloughran Come](https://files.speakerdeck.com/presentations/4ebc1c2823f60d0051015ac8/slide_51.jpg){kind=link}