Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
codt-2022-yappli
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
Masahito Mochizuki
June 27, 2022
Technology
1.3k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
codt-2022-yappli
Masahito Mochizuki
June 27, 2022
More Decks by Masahito Mochizuki
See All by Masahito Mochizuki
Product Security Summit 2024 Yappli
mmochi23
0
560
[SRE NEXT 2022]ヤプリのSREにおけるセキュリティ強化の取り組みを公開する
mmochi23
2
9.7k
Other Decks in Technology
See All in Technology
それでも、技術なブログを書く理由 #kichijojipm / Why I Still Write Tech Blogs Even Now
shinkufencer
0
870
AWS環境のセキュリティ不安を解消した企業事例 ~よくある課題と対策を一挙公開~
asanoharuki
0
180
全社でのソフトウェアサプライチェーン攻撃対策をやってみた with Takumi Guard
z63d
0
300
なぜ、あなたのエージェントは言うことを聞かないのか
segavvy
1
500
AIで楽になるはずが、なぜ疲れる?
kinopeee
0
100
発表と総括 / Presentations and Summary
ks91
PRO
0
210
kaonavi Tech Night#1
kaonavi
0
170
Claude Mythos、Fable...フロンティアAIの最新動向と企業のセキュリティ対策
flatt_security
0
150
AI時代のPlaywright活用(システムテストを自動化する ー 実行エンジンにPla ywrightを選んだ理由)
ynisqa1988
2
1k
CloudWatchから始めるAWS監視
butadora
0
170
AI研修(Day1)【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
860
ファミコンでPHPを動かす / PHP on the Famicom
tomzoh
2
650
Featured
See All Featured
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
380
Building Applications with DynamoDB
mza
96
7.1k
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
180
First, design no harm
axbom
PRO
2
1.2k
Large-scale JavaScript Application Architecture
addyosmani
515
110k
The Mindset for Success: Future Career Progression
greggifford
PRO
0
430
HDC tutorial
michielstock
2
750
Designing Powerful Visuals for Engaging Learning
tmiket
1
460
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
2
1.7k
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.4k
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
2
240
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
Transcript
ヤプリが乗り越えてきた監視運用の失敗と改善 顧客影響に気づけるアラート設計と 原因特定が素早くできるSREへ
1. イントロダクション 2. 事業拡大に寄り添う監視の見直し 3. 未来を見据えた監視サービス移行 4. まとめ アジェンダ
1 イントロダクション
2018/01にQAエンジニアとしてノーコードでアプリ開発を実現 するYappliを提供する株式会社ヤプリにジョイン QAの立ち上げやテスト自動化推進などを経てSREに転身 現在は基盤部およびSREグループの責任者として活動 基盤部 └ SREグループ:Yappliのサービス・インフラ └ ITグループ(情シス):社内IT全般・情報セキュリティ 自己紹介
望月 真仁 (Masahito Mochizuki) テックブログの編集長もやっております ヤプリの技術にご興味がある方は是非ご覧ください https://tech.yappli.io/
障害発生時の監視体制に不安がある、監視サービスを導入した ものの活用しきれていない、仕組みは構築したものの導入時から あまり改善していないという方が、一歩先に進めるようなヒントを 得ていただく 今日のゴール
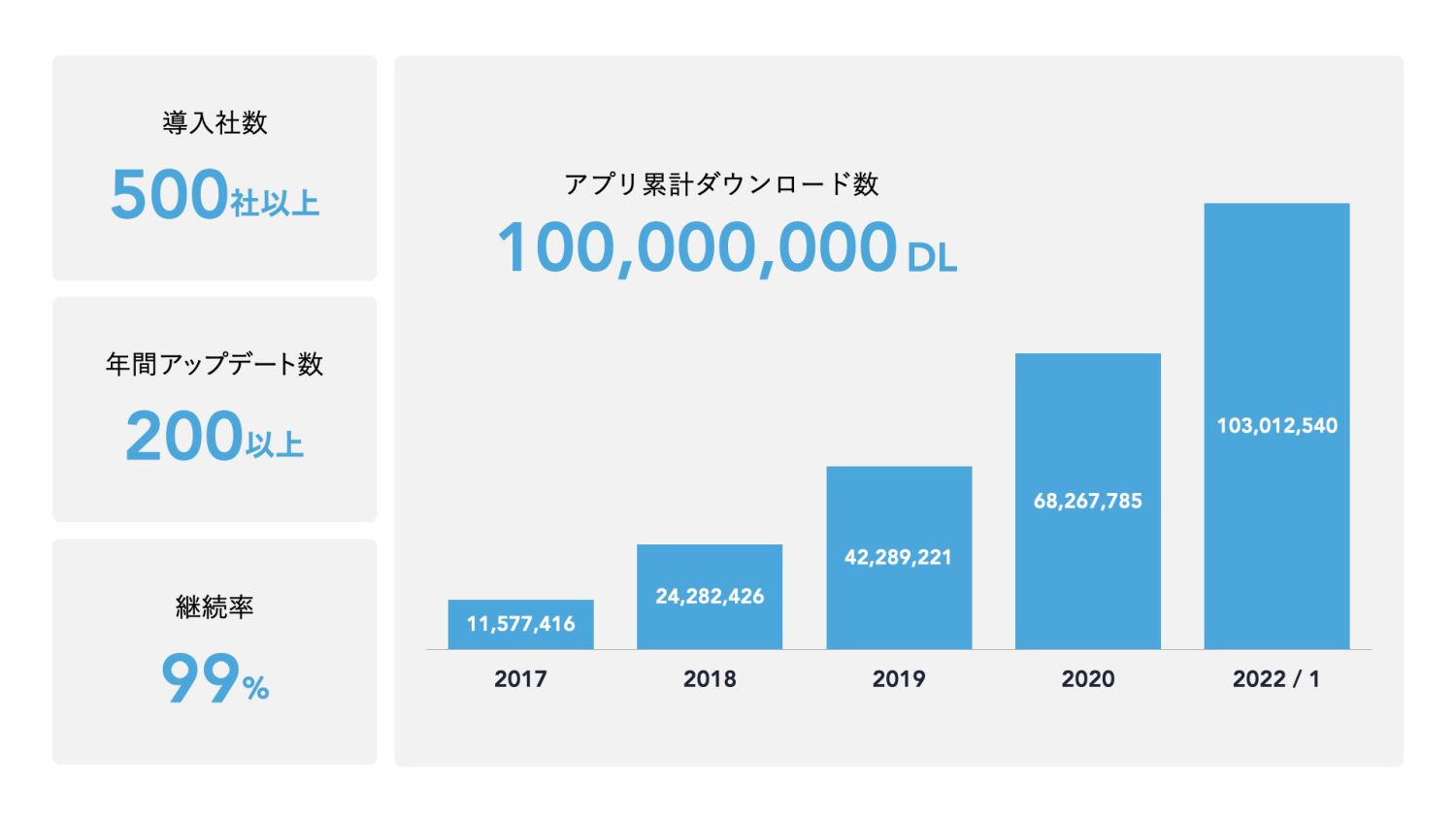
セッションの前提となるヤプリの紹介
None
None
None
2 事業拡大に寄り添う 監視の見直し
• 2019年にSREグループ発足 • 2020年頃にかけてベースとなる監視の考え方・仕組み • 最近まで大きな障害なくサービス運用を継続 • 我々のサービス安定しているじゃん! 背景 →実は見えないところで問題が進行していた・・・
• ある日アプリの特定機能が利用できない障害発生 ◦ サービス系統Aのサーバーのうち2台のプロセスで障害 残ったサーバーのみではアクセスのスパイクに耐えきれず利用不可 • 翌週にもアプリの特定機能が利用できない障害発生 ◦ サービス系統Bのサーバーがアクセスのスパイクに耐えきれず利用不可 障害発生
→アプリの重要な機能において、インフラを起因とした 障害を連続して発生させてしまった
振り返り・ポストモーテムで様々な監視の課題洗い出し • 障害の緊急性にふさわしいレベルで通知されなかった • 障害発生したサーバーからアラートが通知されなかった • 特定ロールのエンジニアしか対処できない障害があった • 障害の状況把握・原因調査に時間がかかる •
事前に予兆があったが気づけなかった なぜ? 検知・リードタイム 障害対応 プロアクティブ →改善・見直しを実施
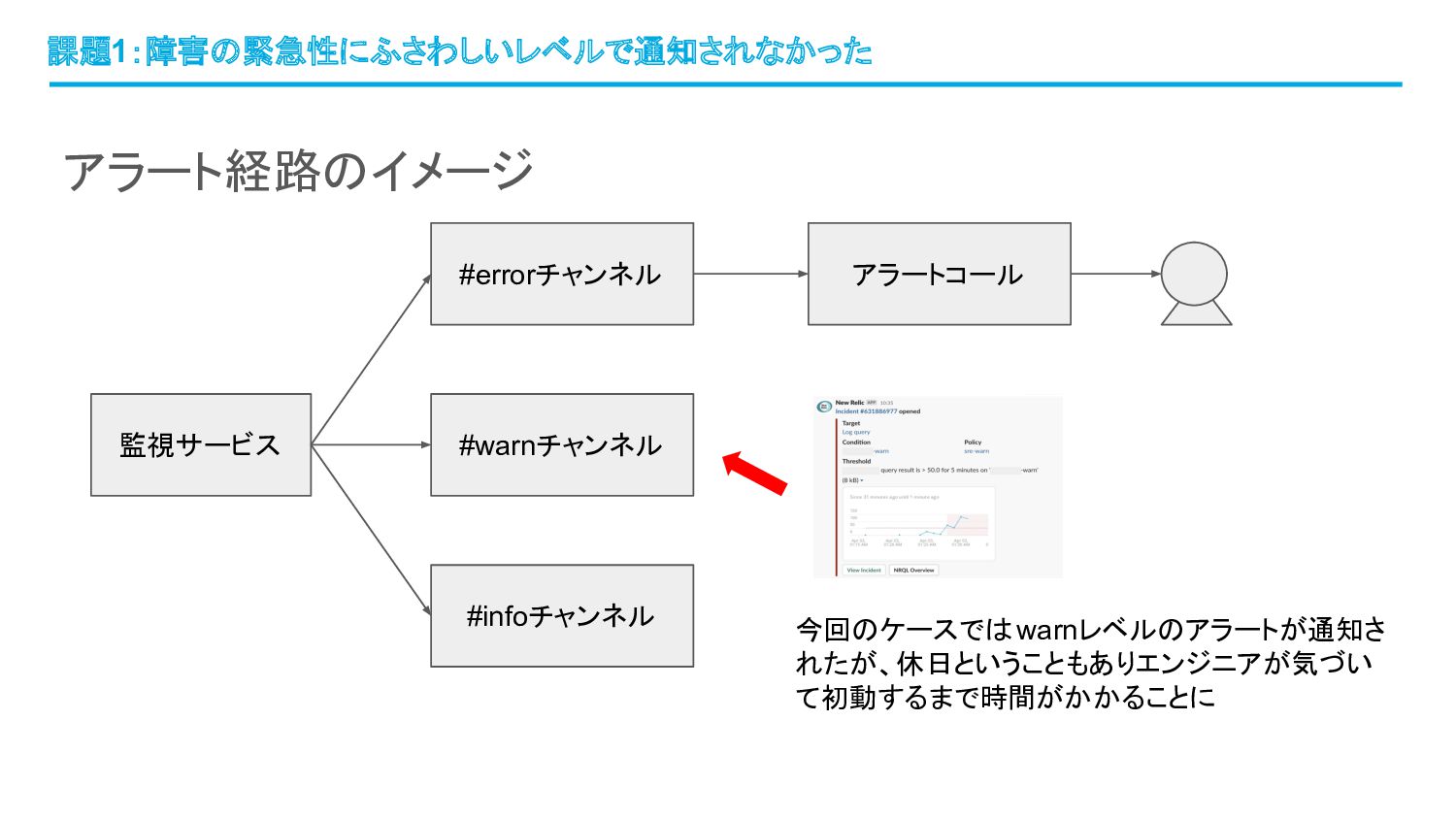
障害の緊急性にふさわしいレベルで通知さ れなかった
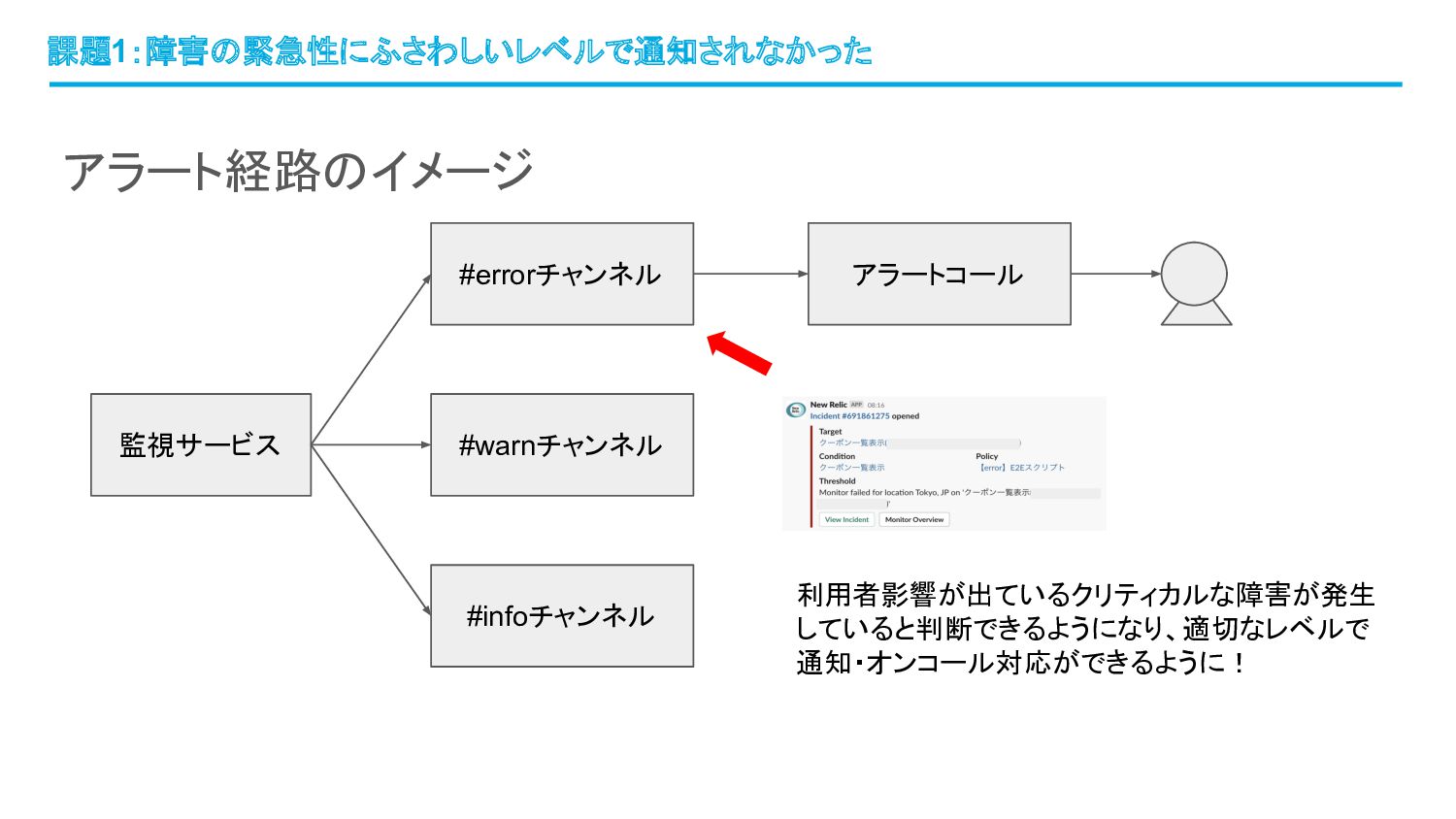
アラート経路のイメージ 課題1:障害の緊急性にふさわしいレベルで通知されなかった 監視サービス #errorチャンネル #warnチャンネル #infoチャンネル アラートコール 今回のケースではwarnレベルのアラートが通知さ れたが、休日ということもありエンジニアが気づい て初動するまで時間がかかることに
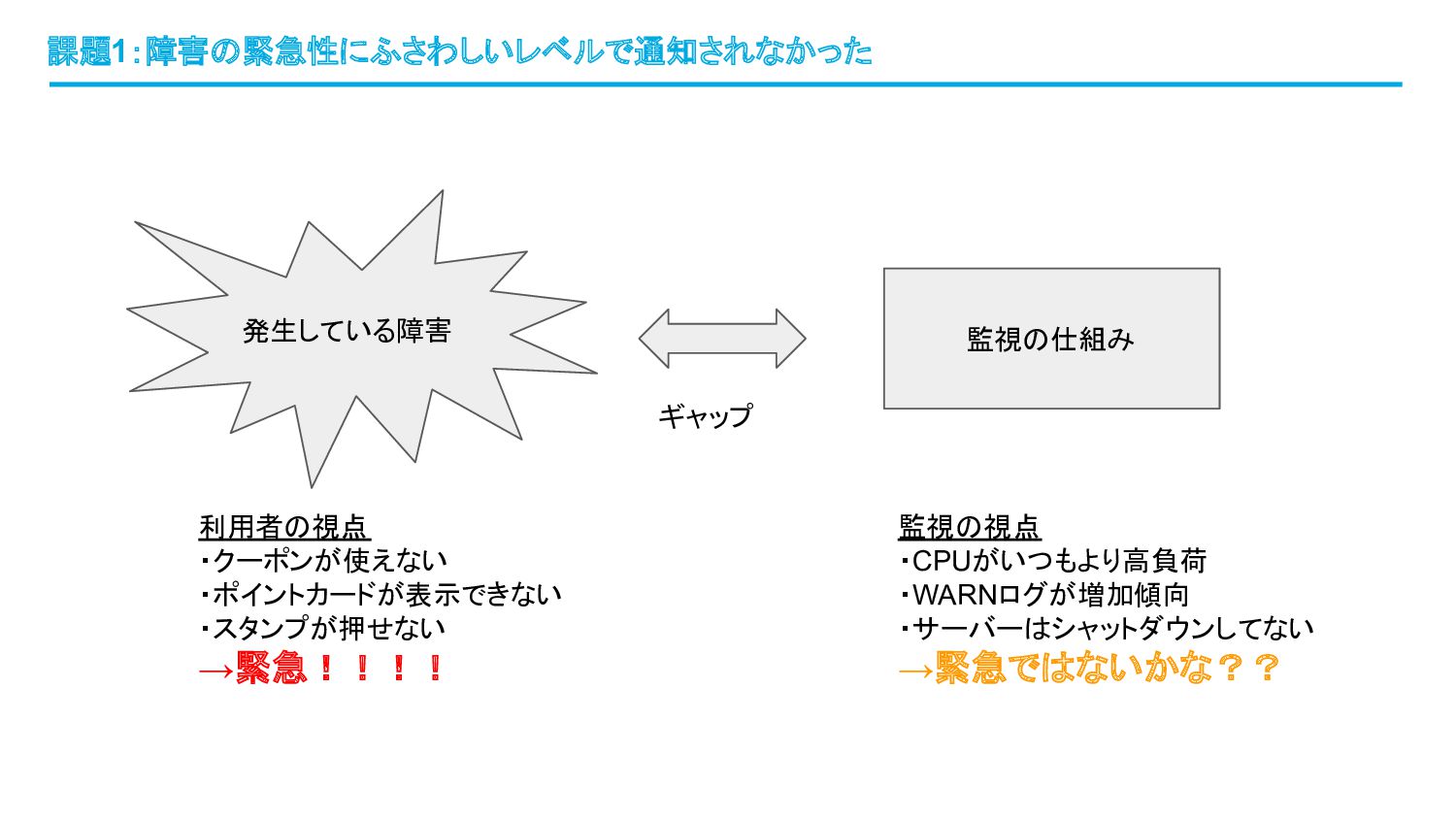
課題1:障害の緊急性にふさわしいレベルで通知されなかった 発生している障害 ギャップ 監視の仕組み 利用者の視点 ・クーポンが使えない ・ポイントカードが表示できない ・スタンプが押せない →緊急!!!! 監視の視点
・CPUがいつもより高負荷 ・WARNログが増加傾向 ・サーバーはシャットダウンしてない →緊急ではないかな??
利用者視点での外形監視をしたいが・・・ • ブラウザリプレイ形式の外形監視:❎ ◦ 自分アプリなんで ◦ Appium版の外形監視欲しいなー(チラッ) • Ping形式の外形監視:❎ ◦
障害を握りつぶしているケース ◦ 200だけどレスポンス内に「表示/利用できません」ケース ◦ 歴史的経緯でインフラ経路が様々(ALB→EC2→Aurora、CloudFront→S3、 NLB→Fargate→SQLite等) ◦ コア機能に絞ってもヘルスチェックをそれぞれ用意するのは大変 課題1:障害の緊急性にふさわしいレベルで通知されなかった
Scripted APIを利用したE2E監視 課題1:障害の緊急性にふさわしいレベルで通知されなかった 見つけた
var assert = require('assert'); var request = require('request'); var options
= { uri: 'https://apiserver/api/show/123456', form: { contents_id: 'xxx' }, headers: { "User-Agent": "I am Android.", }, json: true }; request.post(options, function(error, response, body){ assert.equal(response.statusCode, 200); if (body.indexOf("使えるクーポン :あなただけのクーポン ") > -1) { console.log("OK"); } else { console.log("リトライ"); request.post(options, function(error, retry_response, retry_body){ assert.equal(retry_response.statusCode, 200); assert(retry_body.indexOf("使えるクーポン :あなただけのクーポン ") > -1); }); } }); 課題1:障害の緊急性にふさわしいレベルで通知されなかった requestを自由に加工 assertで独自の条件判定 条件分岐など自由に制御 ユーザー操作をそのまま シナリオとして実装 ヤプリのために用意してく れた機能では・・・?
アラート経路のイメージ 課題1:障害の緊急性にふさわしいレベルで通知されなかった 監視サービス #errorチャンネル #warnチャンネル #infoチャンネル アラートコール 利用者影響が出ているクリティカルな障害が発生 していると判断できるようになり、適切なレベルで 通知・オンコール対応ができるように!
障害が発生したサーバーからアラートが通 知されなかった
課題2:障害が発生したサーバーからアラートが通知されなかった サービスA サービスB サービスC 障害 障害 サービスB/Cに接 続できない →アラート
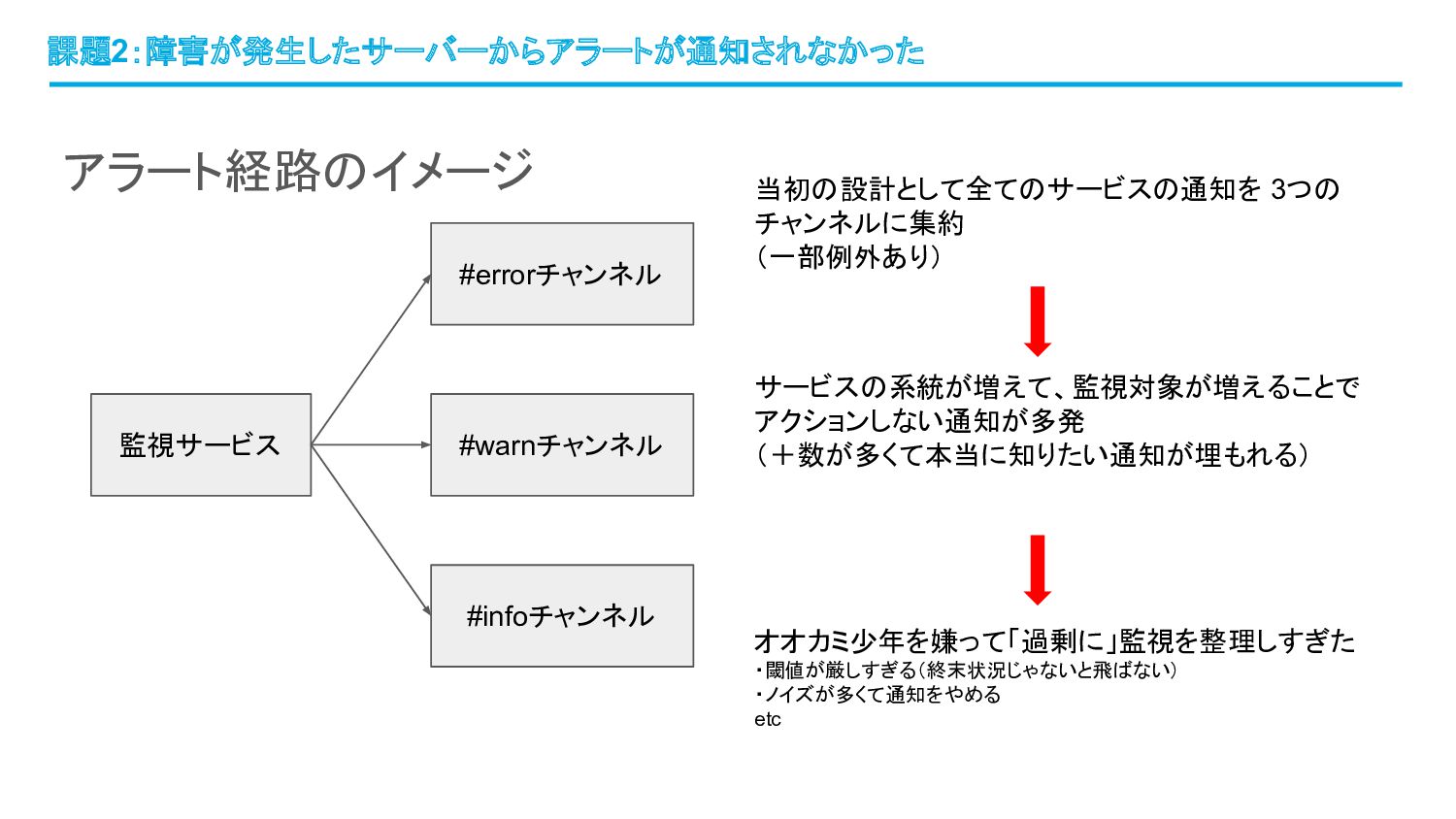
アラート経路のイメージ 課題2:障害が発生したサーバーからアラートが通知されなかった 当初の設計として全てのサービスの通知を 3つの チャンネルに集約 (一部例外あり) サービスの系統が増えて、監視対象が増えることで アクションしない通知が多発 (+数が多くて本当に知りたい通知が埋もれる) オオカミ少年を嫌って「過剰に」監視を整理しすぎた
・閾値が厳しすぎる(終末状況じゃないと飛ばない) ・ノイズが多くて通知をやめる etc 監視サービス #errorチャンネル #warnチャンネル #infoチャンネル
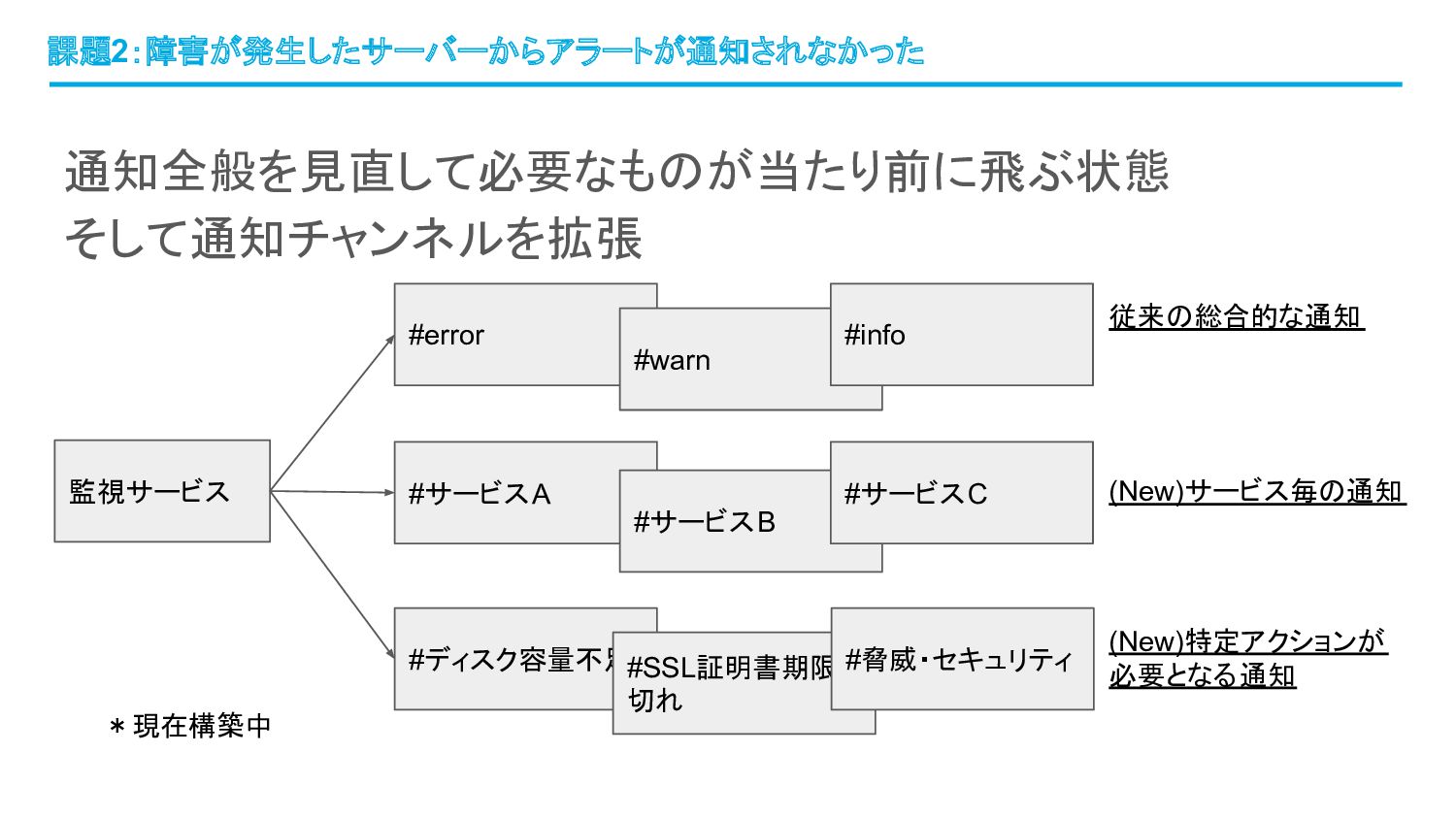
課題2:障害が発生したサーバーからアラートが通知されなかった 通知全般を見直して必要なものが当たり前に飛ぶ状態 そして通知チャンネルを拡張 監視サービス #error #サービスA #ディスク容量不足 #warn #info #サービスB
#サービスC #SSL証明書期限 切れ #脅威・セキュリティ 従来の総合的な通知 (New)サービス毎の通知 (New)特定アクションが 必要となる通知 *現在構築中
• 従来の総合的な通知 ◦ サービス全体の健全性を俯瞰する ◦ 障害レベルごとに状況を把握する ◦ #errorではオンコールに直結して迅速対応する • サービス毎の通知
◦ どの系統で障害・変化が起きているか把握する ◦ 即時のアクションが不要な通知も積極的に流して中長期的な変化を捉える ◦ 課題3の解決と連動(後述) • 特定アクションが必要となる通知 ◦ ディスク容量が一定割合を超えたサーバ、期限が近づいている SSL証明書、脅威・セキュリティ系 の通知など、後続アクションが明確に決まっているものを把握する ◦ Slackスタンプで実施状況を可視化する(将来的にはチケット化など) 課題2:障害が発生したサーバーからアラートが通知されなかった
特定ロールのエンジニアしか対処できない 障害があった
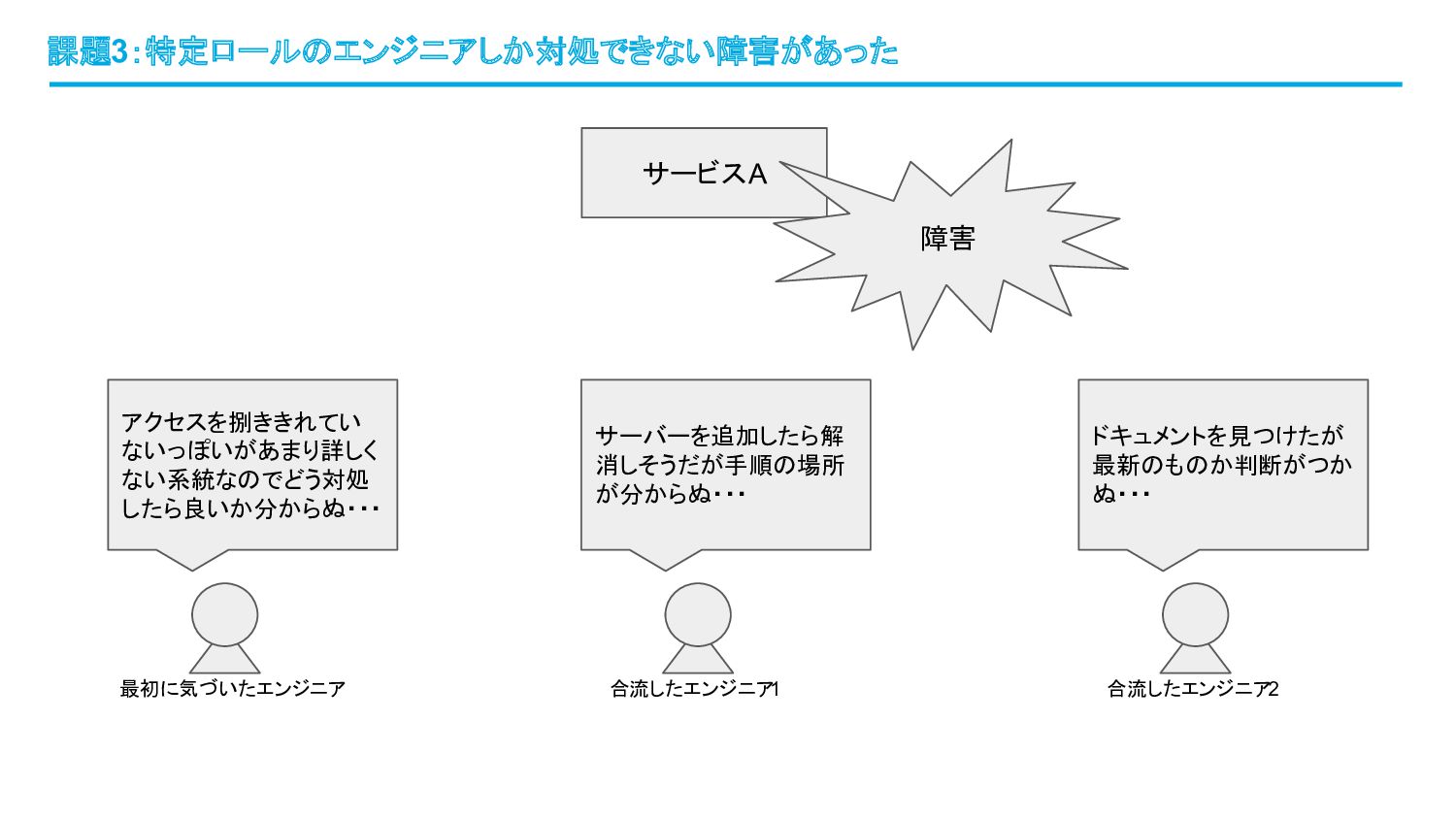
課題3:特定ロールのエンジニアしか対処できない障害があった サービスA 障害 最初に気づいたエンジニア アクセスを捌ききれてい ないっぽいがあまり詳しく ない系統なのでどう対処 したら良いか分からぬ・・・ 合流したエンジニア 1
サーバーを追加したら解 消しそうだが手順の場所 が分からぬ・・・ 合流したエンジニア 2 ドキュメントを見つけたが 最新のものか判断がつか ぬ・・・
課題3:特定ロールのエンジニアしか対処できない障害があった 課題2で新たに設置したサービス毎の通知チャンネルにドキュメン トをリンク #サービスAの通知 チャンネル ドキュメントの拡充・メンテナンスや、最 新であることを保証し続ける運用など は今後の課題 通知ごとにdescriptionやリンクを付与 することも検討したが、あまり細かく分
けずサービス単位で集約した方が現状 にマッチしそうだった 開発環境での障害訓練などを通じて、 通知やドキュメントの有効性を継続的 にチェックしていきたい 調査方法やサービスのスケーリング手順や連絡体制など
障害の状況把握・原因調査に 時間がかかる
• 大きく分類すると2種類の基盤がある ◦ PHP on EC2(旧系統) ◦ Go on Fargate(新系統)
• 徐々に新系統に寄せているが旧系統も現役 • 他にも色々なインフラがあって複雑に関連し合っている ◦ Lambdaをベースとした配信基盤 ◦ Aurora、SQLite、Elasticsearch、DynamoDB、Redisなど依存サービス ◦ embulkをベースとしたETL基盤 ◦ 外部APIと連携するケース • 旧系統はロギングが弱い 課題4:障害の状況把握・原因調査に時間がかかる
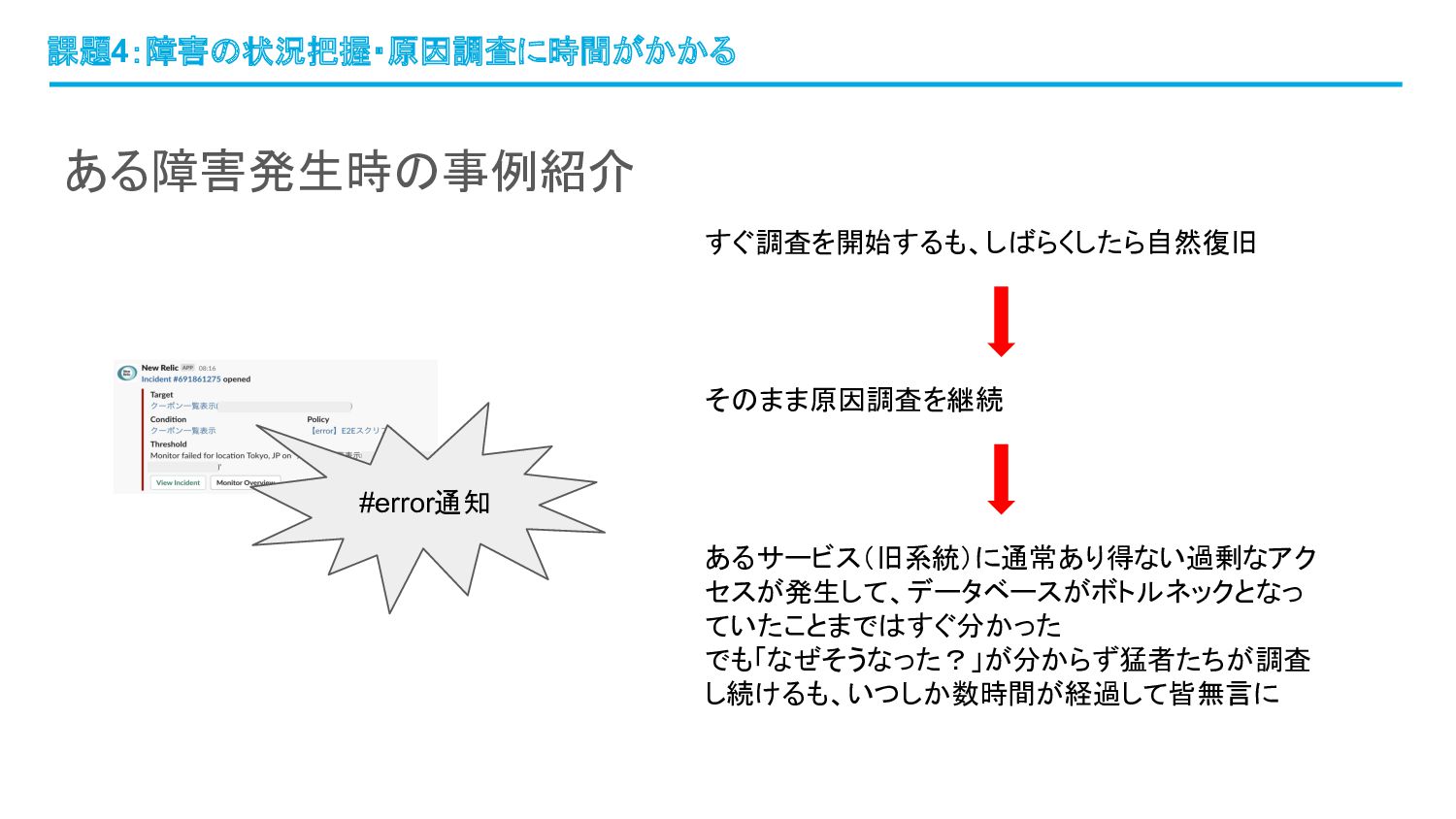
ある障害発生時の事例紹介 課題4:障害の状況把握・原因調査に時間がかかる #error通知 すぐ調査を開始するも、しばらくしたら自然復旧 そのまま原因調査を継続 あるサービス(旧系統)に通常あり得ない過剰なアク セスが発生して、データベースがボトルネックとなっ ていたことまではすぐ分かった でも「なぜそうなった?」が分からず猛者たちが調査 し続けるも、いつしか数時間が経過して皆無言に
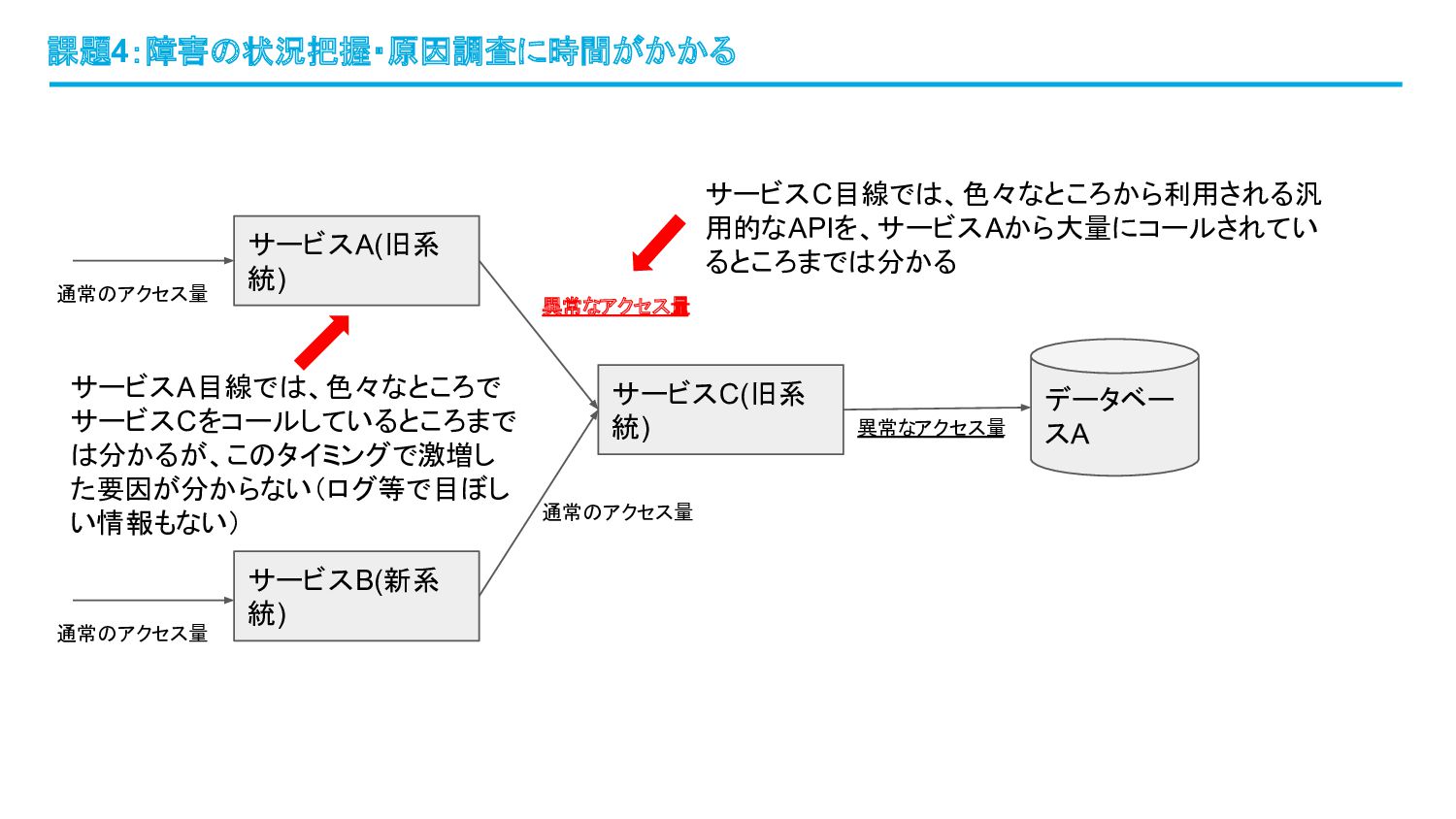
課題4:障害の状況把握・原因調査に時間がかかる サービスA(旧系 統) サービスC(旧系 統) サービスB(新系 統) データベー スA 通常のアクセス量
通常のアクセス量 通常のアクセス量 異常なアクセス量 異常なアクセス量 サービスC目線では、色々なところから利用される汎 用的なAPIを、サービスAから大量にコールされてい るところまでは分かる サービスA目線では、色々なところで サービスCをコールしているところまで は分かるが、このタイミングで激増し た要因が分からない(ログ等で目ぼし い情報もない)
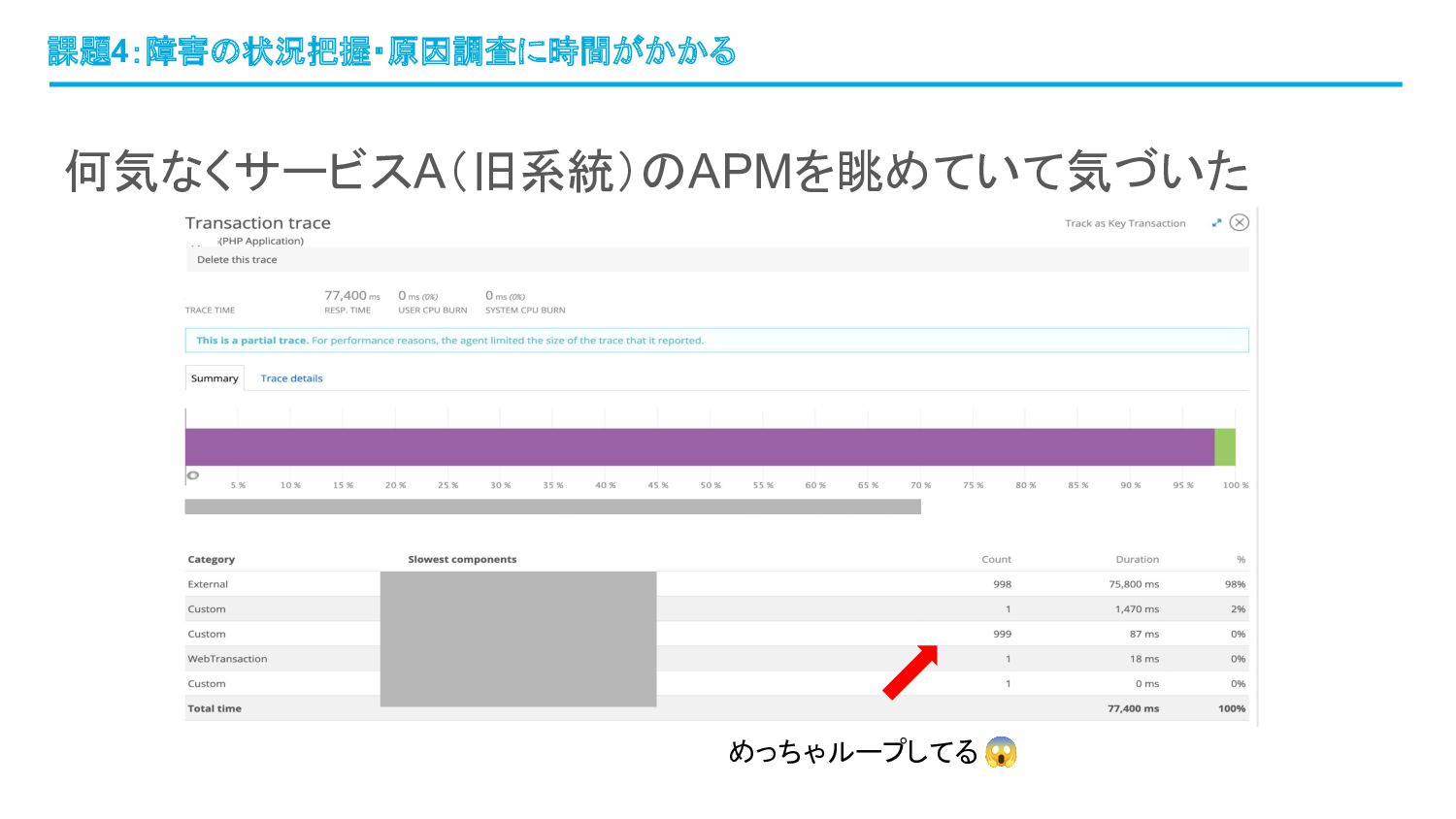
何気なくサービスA(旧系統)のAPMを眺めていて気づいた 課題4:障害の状況把握・原因調査に時間がかかる めっちゃループしてる 😱
結果、特定条件がいくつか重なった際に、大量のループが発生す る不具合があることが判明 ➔ 修正 ➔ ミッションコンプリート! ➔ ではなかった ➔ 実は別の根本原因があったことがその後すぐ判明
課題4:障害の状況把握・原因調査に時間がかかる
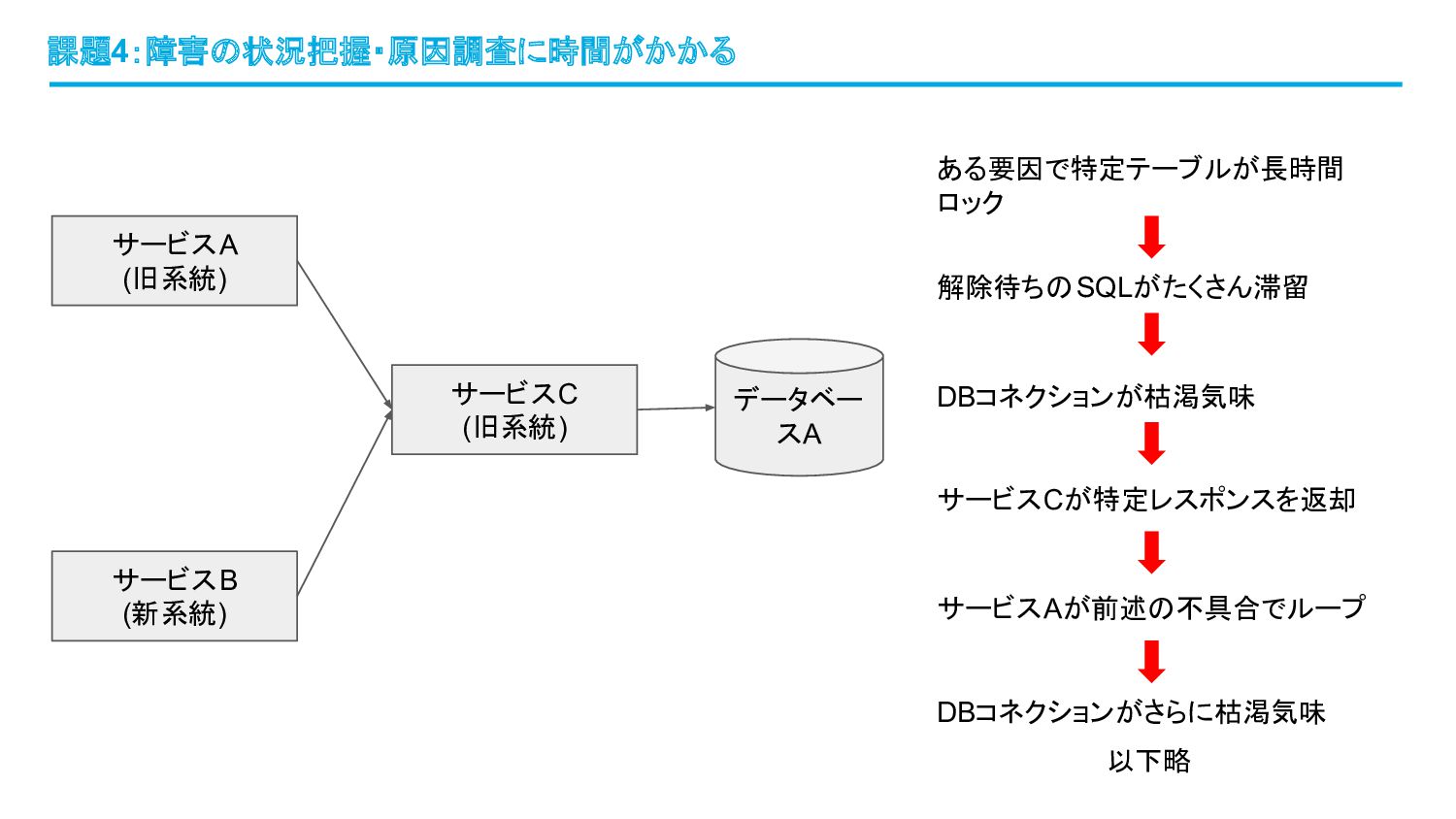
課題4:障害の状況把握・原因調査に時間がかかる サービスA (旧系統) サービスC (旧系統) サービスB (新系統) データベー スA ある要因で特定テーブルが長時間
ロック 解除待ちのSQLがたくさん滞留 サービスCが特定レスポンスを返却 DBコネクションが枯渇気味 サービスAが前述の不具合でループ DBコネクションがさらに枯渇気味 以下略
• DBでロック待ちが多いのは最初の時点で確認できていた • 一方で特定サービスのアクセス数が異常なことに目を奪われ て、そこに調査の意識を集中させすぎた • 古くからあるサービスでログなどの情報が乏しく、昔からいる 詳しいエンジニアでも原因特定が困難を極めた • APMがきっかけでアクセス数の問題がクリアになった
• 残ったDBの調査を進めることで根本原因が特定できた 課題4:障害の状況把握・原因調査に時間がかかる
• ブラックボックスが多くて障害対応が困難なプログラムがあっ たとしても、諦めないでとりあえずAPM入れてみよう! • 目立った異常な事象にとらわれすぎず、多角的な観点で障害 を俯瞰しよう(反省) 課題4:障害の状況把握・原因調査に時間がかかる
事前に予兆があったが気づけなかった
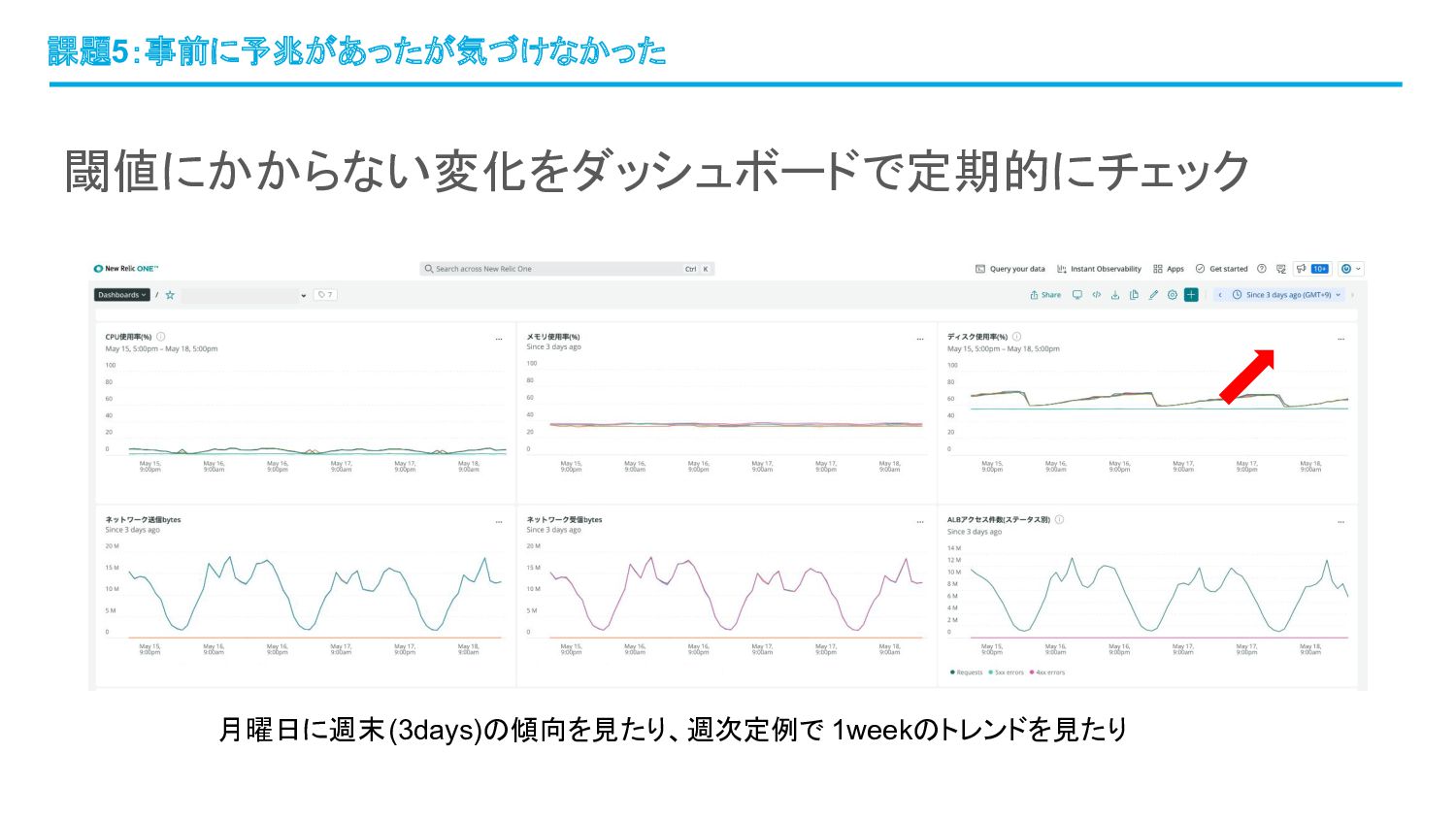
課題5:事前に予兆があったが気づけなかった 振り返りをしていて2件のサーバー障害には予兆があったことに 気づいた サービスA(最初の障害) サービスB(翌週の障害) ある日を境にCPU使用率が徐々に上昇し続ける (閾値内ではある) 一方で特定の2台のみ徐々にCPU使用率が減少 半年前と比較して全体的にCPU使用率のアベレージ が上昇
(閾値内ではある)
閾値にかからない変化をダッシュボードで定期的にチェック 課題5:事前に予兆があったが気づけなかった 月曜日に週末(3days)の傾向を見たり、週次定例で 1weekのトレンドを見たり
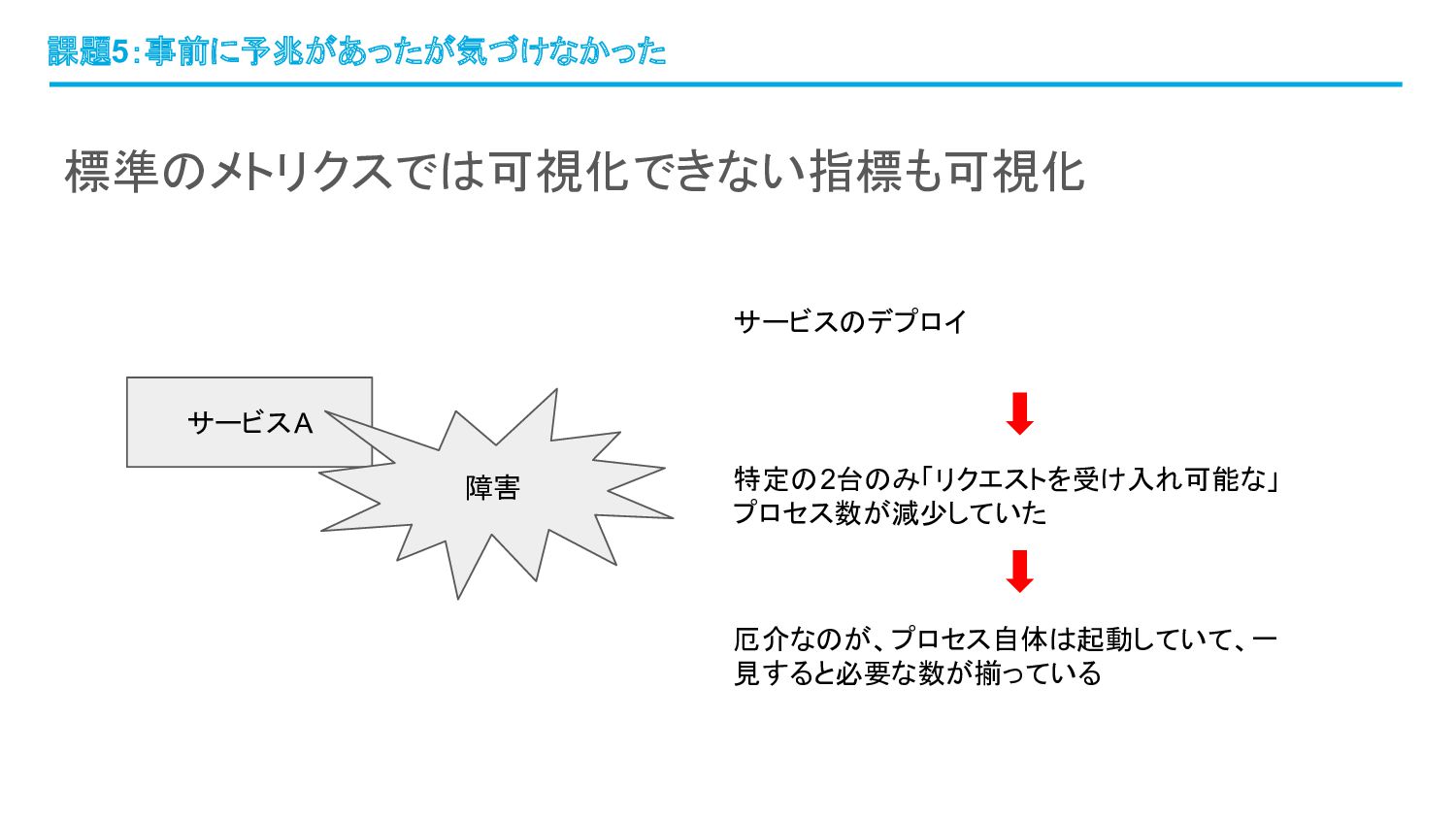
標準のメトリクスでは可視化できない指標も可視化 課題5:事前に予兆があったが気づけなかった サービスA 障害 サービスのデプロイ 厄介なのが、プロセス自体は起動していて、一 見すると必要な数が揃っている 特定の2台のみ「リクエストを受け入れ可能な」 プロセス数が減少していた
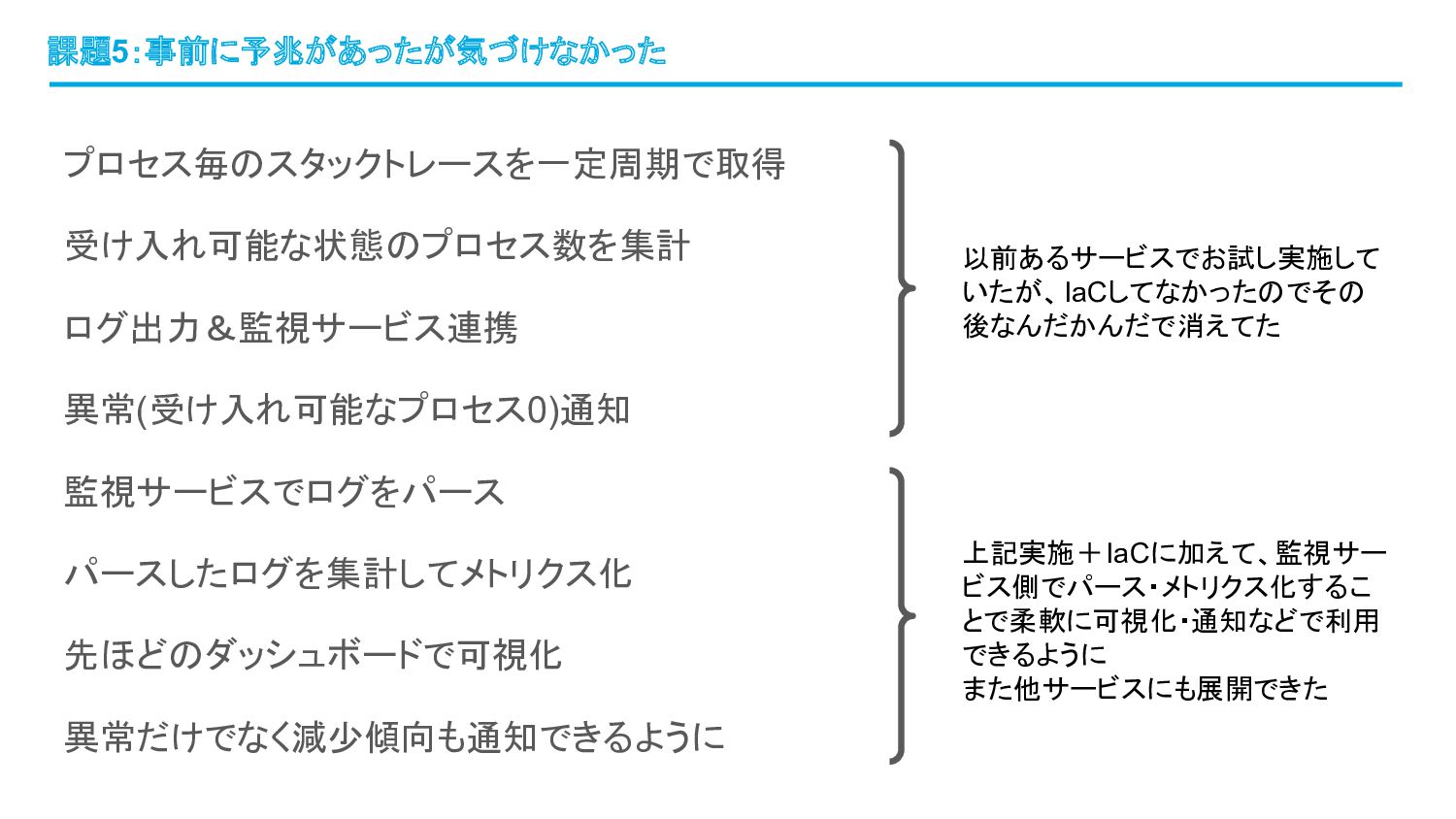
プロセス毎のスタックトレースを一定周期で取得 受け入れ可能な状態のプロセス数を集計 ログ出力&監視サービス連携 異常(受け入れ可能なプロセス0)通知 監視サービスでログをパース パースしたログを集計してメトリクス化 先ほどのダッシュボードで可視化 異常だけでなく減少傾向も通知できるように 課題5:事前に予兆があったが気づけなかった 以前あるサービスでお試し実施して
いたが、IaCしてなかったのでその 後なんだかんだで消えてた 上記実施+IaCに加えて、監視サー ビス側でパース・メトリクス化するこ とで柔軟に可視化・通知などで利用 できるように また他サービスにも展開できた
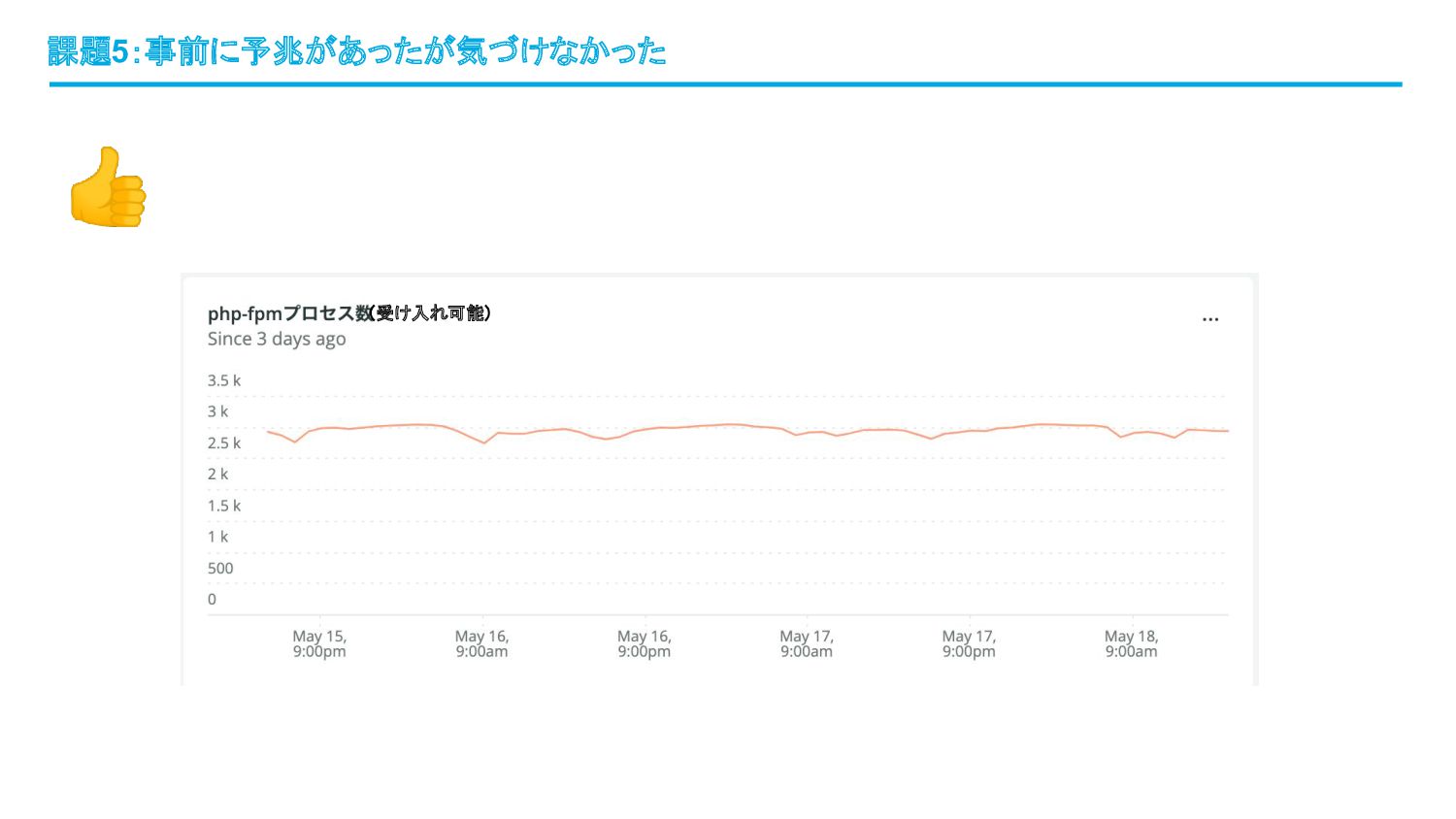
👍 課題5:事前に予兆があったが気づけなかった (受け入れ可能)
改善後 • 障害の緊急性にふさわしいレベルで通知されなかった • 障害発生したサーバーからアラートが通知されなかった • 特定ロールのエンジニアしか対処できない障害があった • 障害の状況把握・原因調査に時間がかかる •
事前に予兆があったが気づけなかった 👍ユーザーシナリオを模したScripted API監視で即時対応 👍サービス・アクション毎のチャンネルで適切な通知 👍サービス毎のSlackチャンネルに対応ドキュメント 👍とりあえずAPM、落ち着いて全体を俯瞰しよう 👍ダッシュボードやメトリクス化で変化に気づく
3 未来を見据えた 監視サービス移行
監視サービスの移行 • 監視の仕組み・体制を構築する際に、最も重要なファクターが 監視サービス • ヤプリでは2021年に監視サービスとしてNewRelicを採用し て、従来のサービスから移行した • 先ほど紹介した監視の改善前にNewRelicへ移行したが、移 行したからこそ実現できたソリューションがあった
• 移行の背景と効果について紹介
• 事業が順調に拡大しているなかで、サーバー・インフラも同じ ように拡大 • 結果、監視サービスのコストも拡大 • それはそう • 一方で監視をレベルアップしようとすると、事業やサーバー・イ ンフラの拡大ペースを超えてコストがかかってしまう
• 新たな取り組みがしづらい 当時の課題感
• 全ての系統にAPMを導入しサービス全体を俯瞰できる分散トレーシング基盤 • バックエンドだけではなく、フロントエンドやiOS/Androidのモバイル、セキュリティな ども監視 • 実際のデータを基準としたSLI/SLO管理 • ステージング環境に監視を入れて、定期的なQAプロセスに合わせて、監視サービ ス視点でも変化に気づける
• エンジニアの開発環境にも監視を入れて、自身が加えたプログラム変更に対して、 QA前のエラーレート変化やパフォーマンス観点での気づき提供 • 本番同等の監視を入れた検証環境で、サーバーが死んだ時やデータベースが詰 まった時など再現し、アラートから復旧までの訓練・行動確認をしたい 妄想していた未来
💸 別のアプローチがないか? 予算がいくらあっても足りない
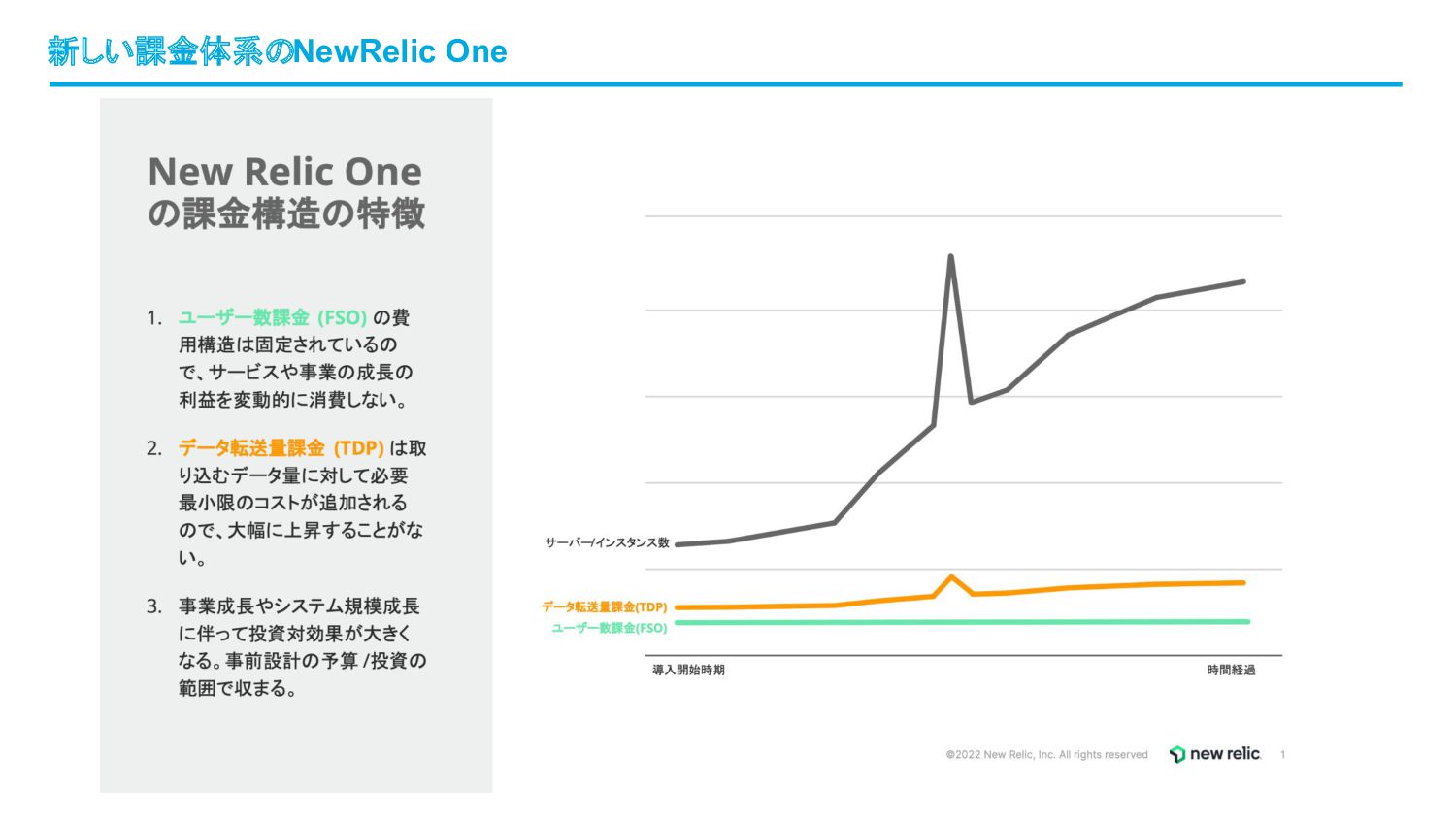
新しい課金体系のNewRelic One
• まだまだヤプリは変化が激しいフェーズ 実際に利用されたデータ量に応じて課金されるため無駄がない ◦ 年間契約したものの途中から不要になるケース ◦ 検証などでほんの一時だけ使いたいケース ◦ スパイク時に一時的にインフラを増強するケース ◦
余裕を見て多めにホストを用意しているケース • 一時的な利用超過に対する柔軟な対応 • 先の紹介の通り今後ヤプリでは重要性が高まるSynthetics(外形監視) ◦ 種類・頻度・ロケーションがコストに影響しない • NRQL(SQLライクなクエリ)で複雑な条件でも可視化・アラート • 迅速な日本語サポート、オンボーディングの手厚さ ◦ ユーザーグループの活発さ、活用事例も充実 Goodなポイント👍
妄想していた未来が現実にできる土台 監視の新たなチャレンジ 褒めるだけだとサクラっぽいので一応
• GoのAPMがもっと使いやすくなるとGood👍 ◦ 計測したい単位でTransaction/Segmentの挿入が必要 ◦ redigoのインテグレーションがなかった ◦ nrmysqlでクエリが自動記録されない *それぞれ有志のOSSやワークアラウンドが公開されていたりする •
Alertの条件がもっと分かりやすくなるとGood👍 ◦ ログをベースにしたAlertが条件を満たしても通知されなかった ◦ Fine-tune advanced signal settingsのStereaming methodをEvent timerに すべきだった(デフォルトがEvent flow) *日本語ブログで細かく説明されていたりする 改善してほしいポイント🙏
• 契約期間の関連などでかなり急なスケジュールになった • 旧サービスと新サービスどっち使ったら良いの? • 当然ながらサービス間の違いがあるので、New Relicではで きない(できるけど実装が大変な)こともある • 利用者への調整や教育などが不十分になってしまった
→適宜フォローしながら社内の活用推進を進めていきたい 個人的な反省
4 まとめ
• 監視は一度構築したら終わりではなく、事業拡大など周囲の 状況に合わせて継続的にアップデートしていく (表面化してないだけで陳腐化していることもある) • 同様な課題に取り組んでいる先人の知恵を活用しよう (本改善でも活用事例をヤプリ向けにアレンジしたり) • 監視サービスはそれぞれ一長一短、自社の状況やフェーズに 合わせて、柔軟に選択していきたい
(でも移行は大変だよ) • 素敵な監視ライフを! まとめ
SRE・セキュリティエンジニアさん絶賛募集中 https://www.wantedly.com/projects/311183 https://open.talentio.com/r/1/c/yappli/pages/48798 宣伝させてください🙏
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}