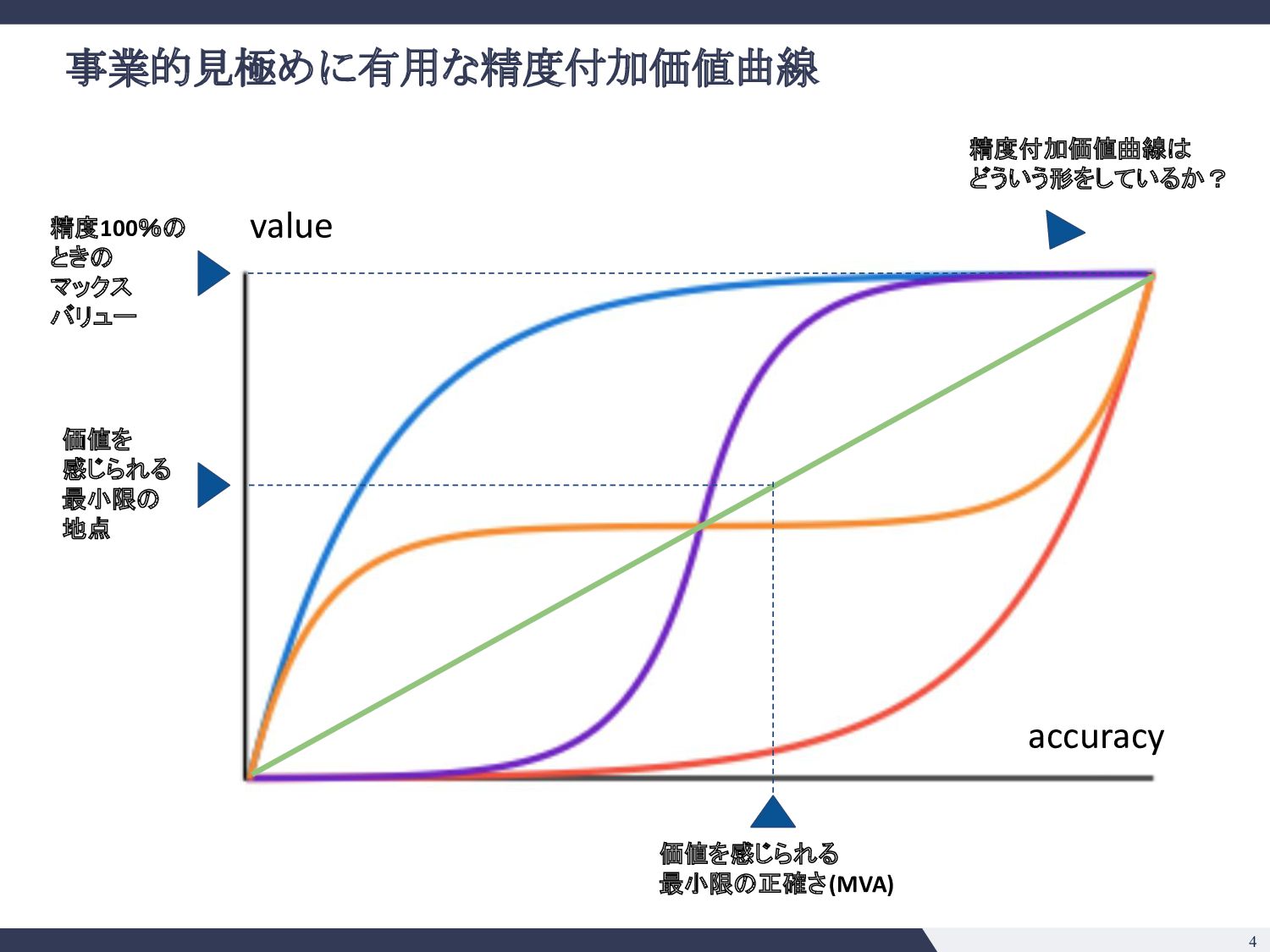
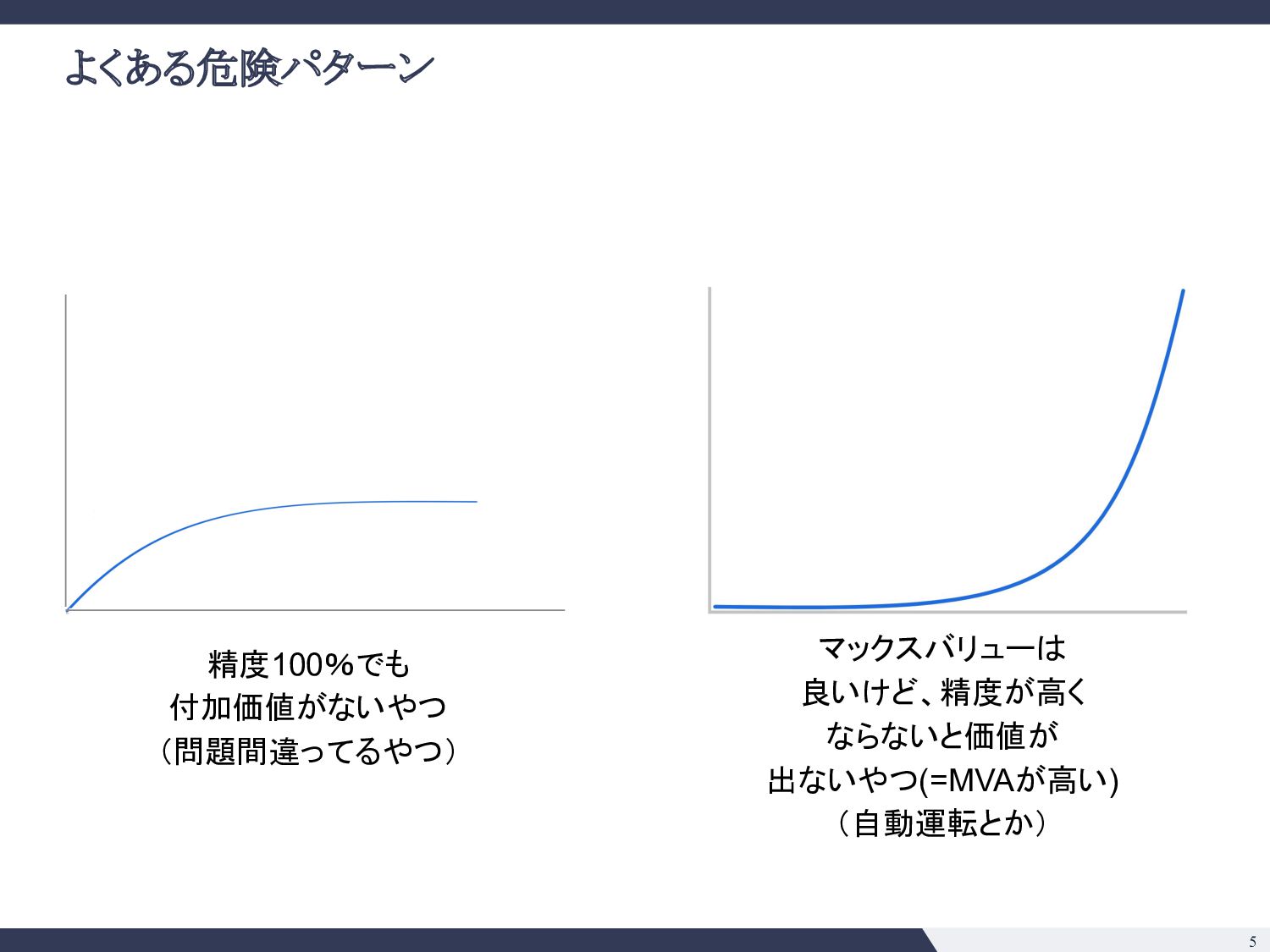
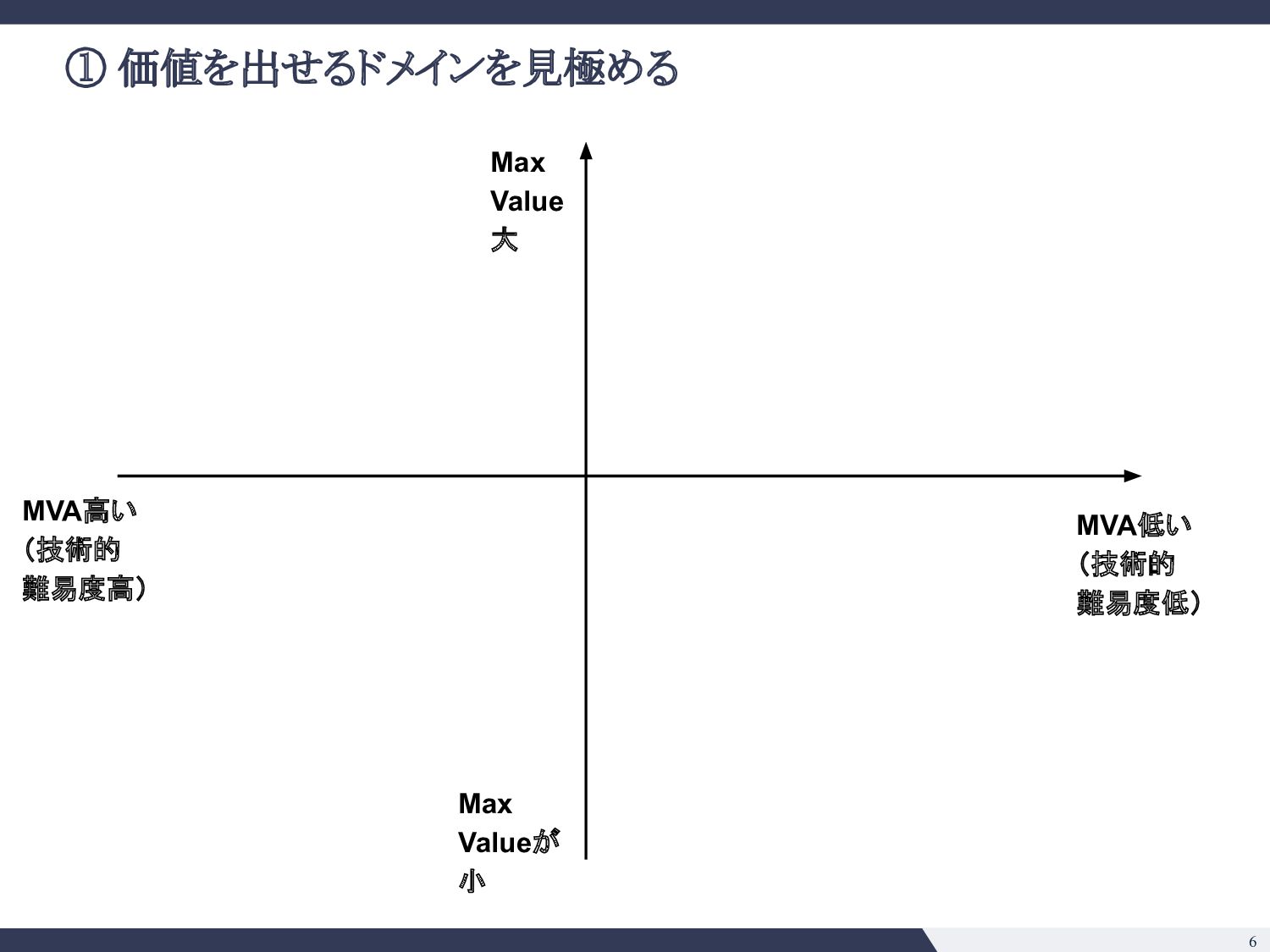
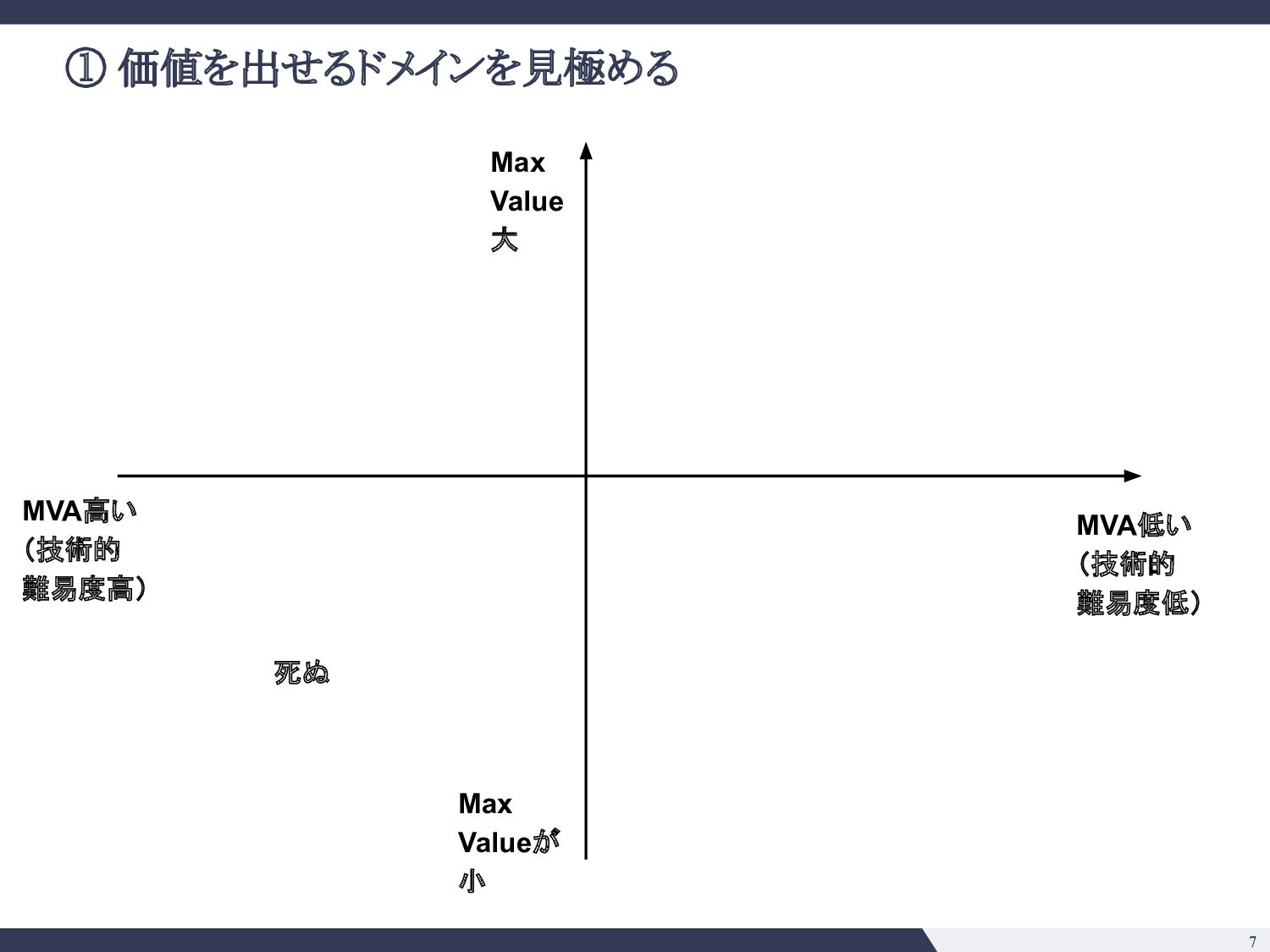
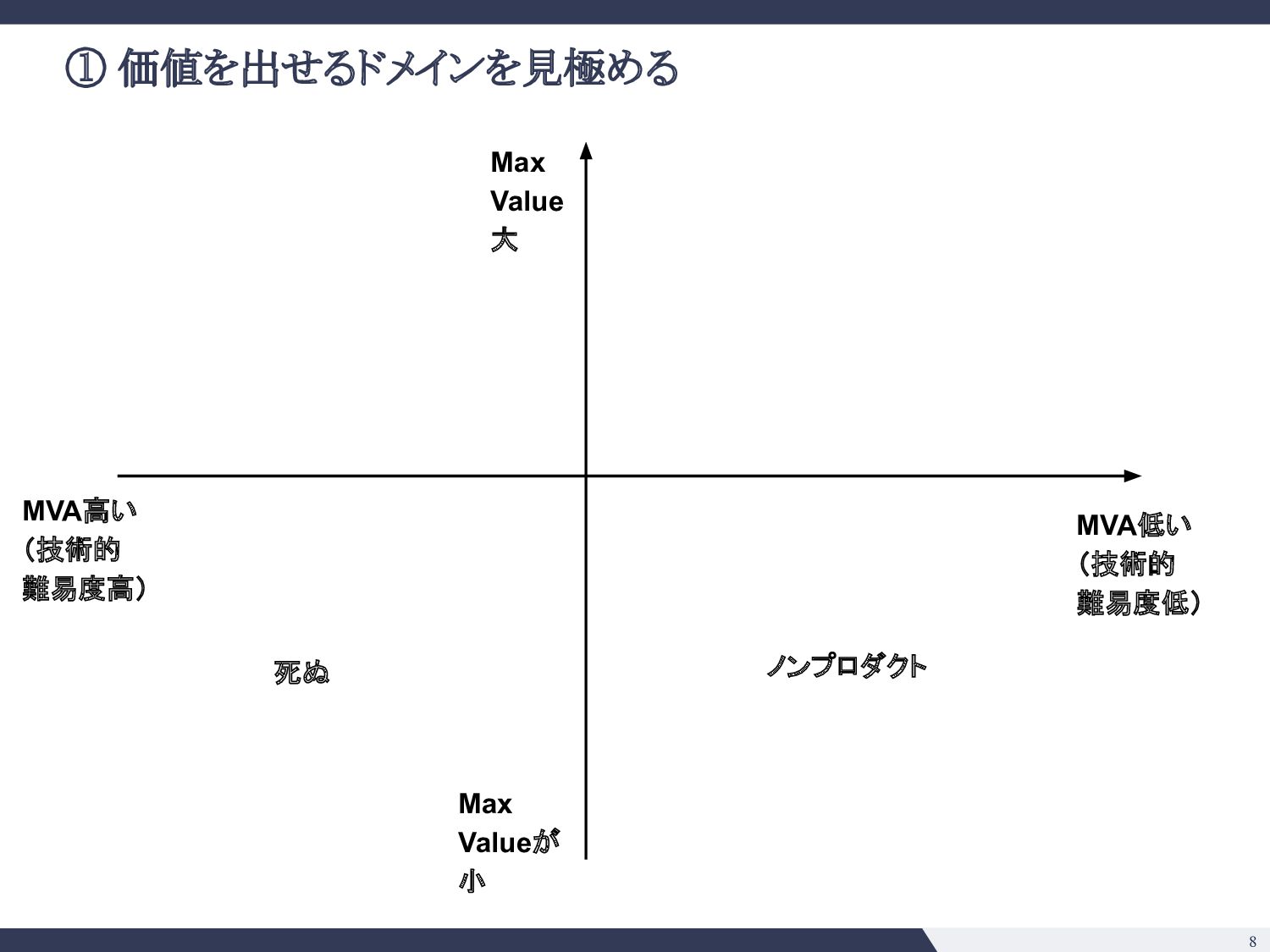
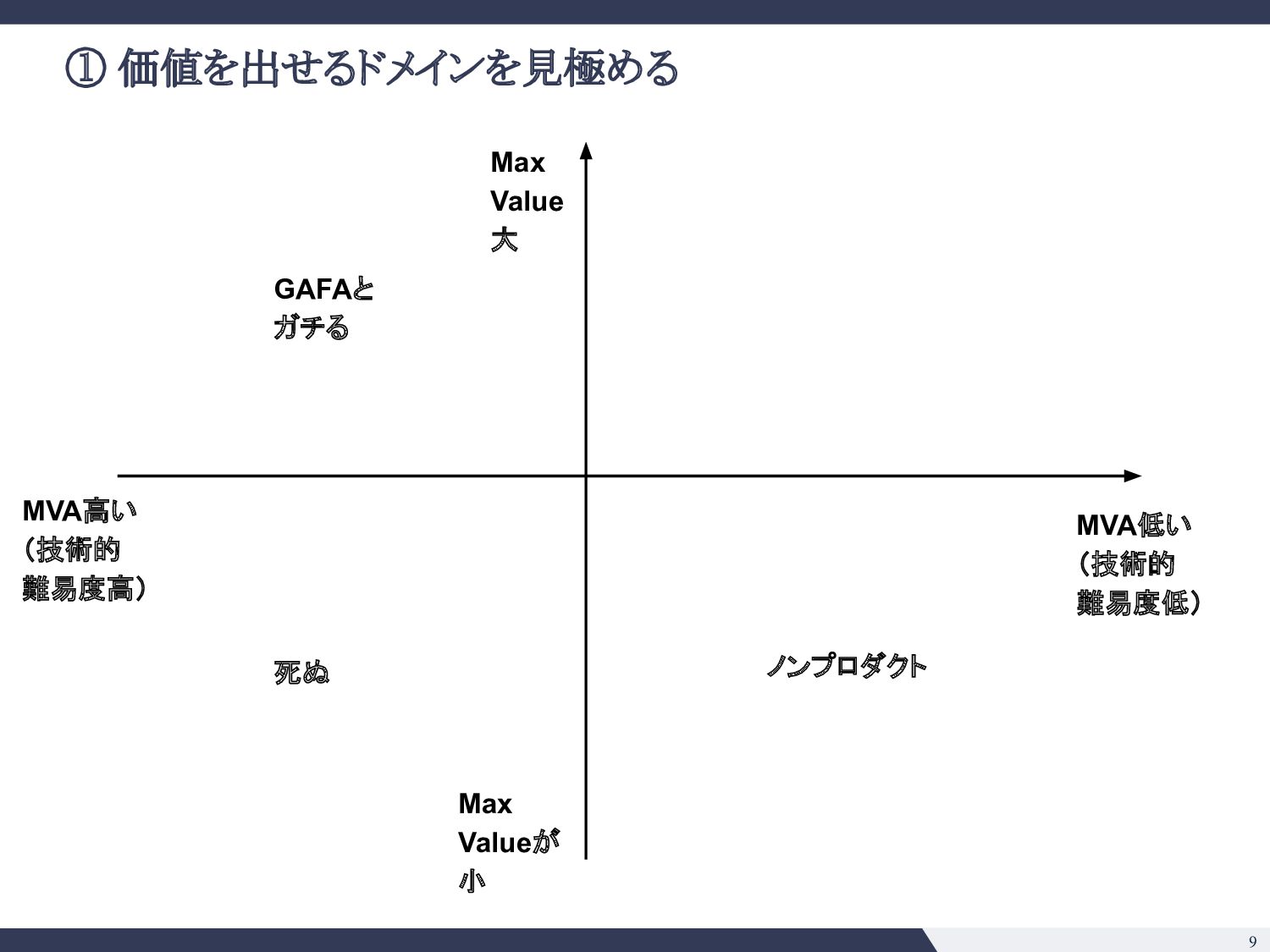
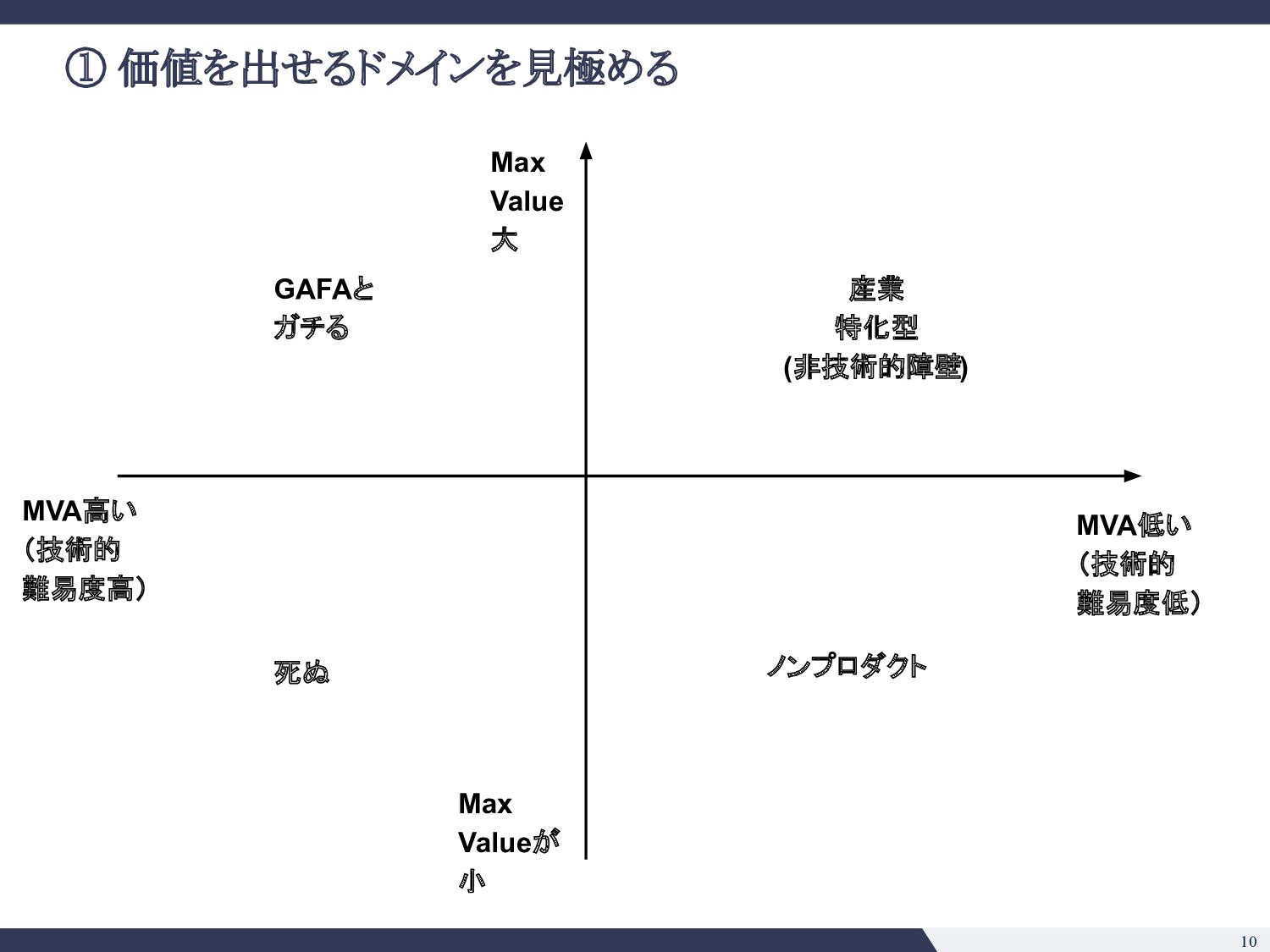
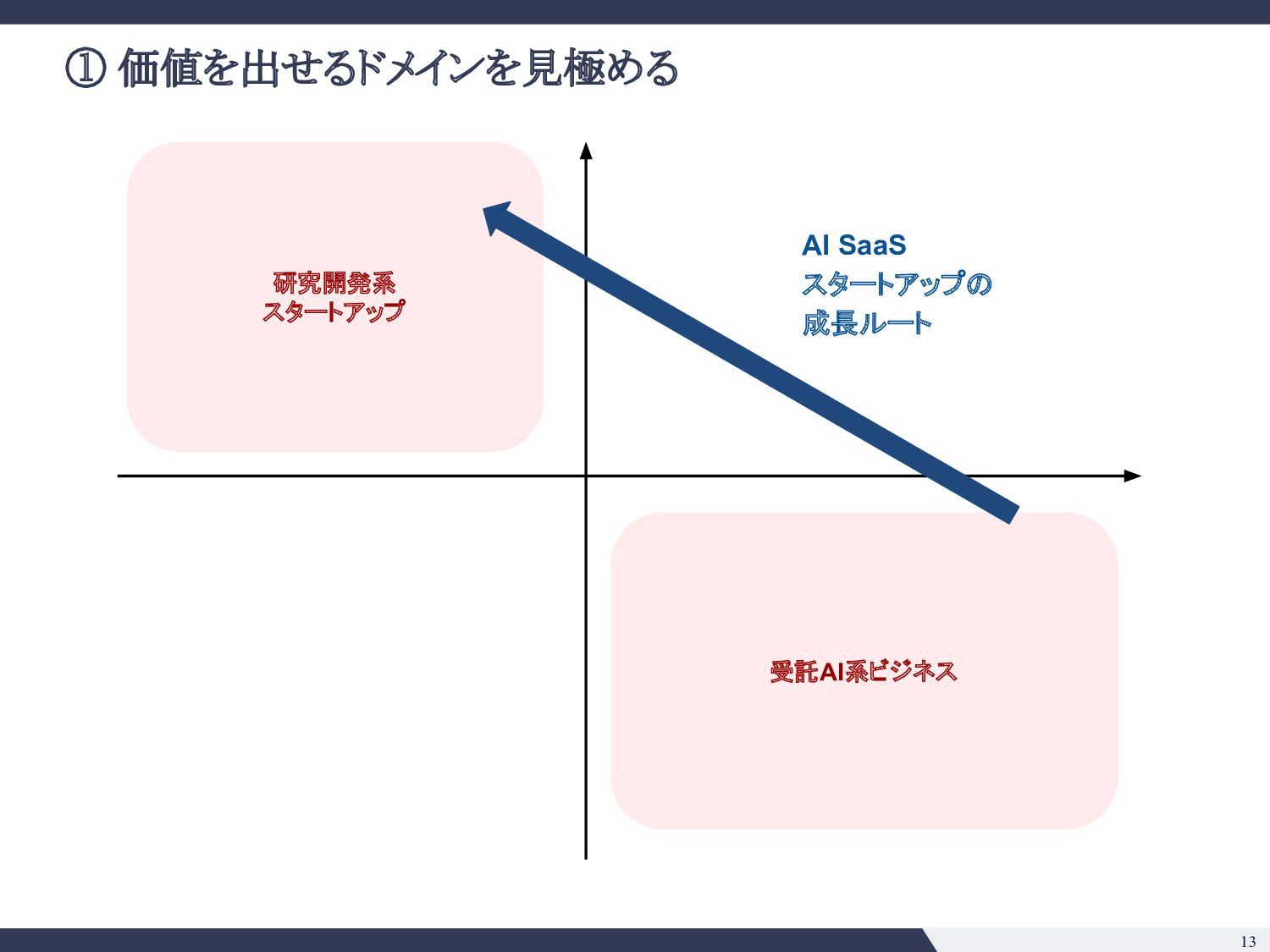
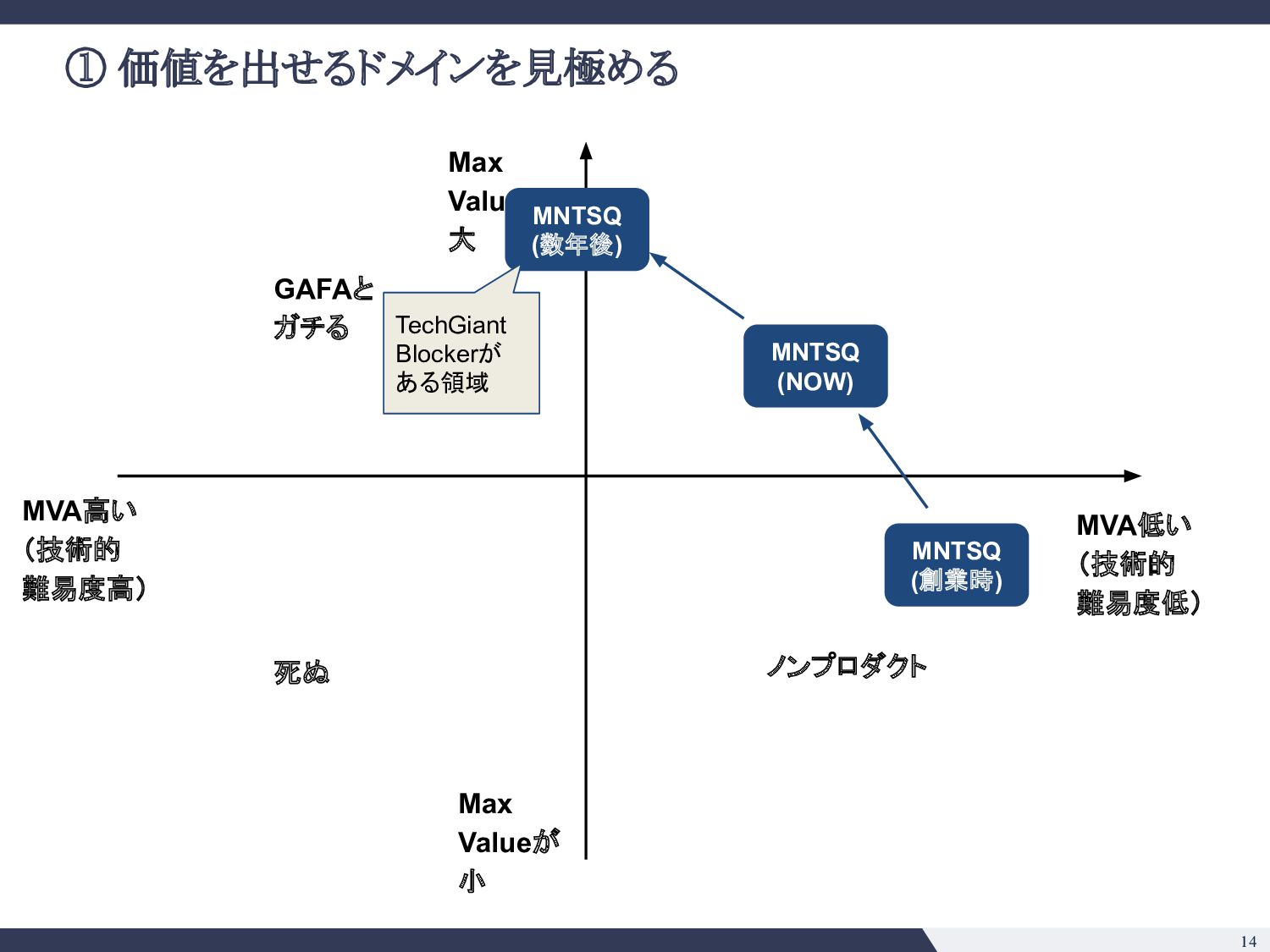
綺麗な日本語の解析 ▪ 条項号の構造 ▪ 強いドメイン知識の注入ができそう • e. そのタスクで既に達成できていることは? 今後できそうなことは? ◦ SQuADの事例 (2018) ◦ 大きい言語モデル(BERT, GPT-3等)の応用は色々出てきており 確実にできることの幅は広がりそう ◦ 一方で日本語で巨大なモデルの運用がどこまでいけるか未知数 • f. Modelは顧客ごとに使いまわせるか? ◦ 契約書の会社ごとに違わない => 単一モデル運用が可能 • g. データの入手可能性は? ◦ データは手に入れにくいが、壁を乗り越えれば moatになる ◦ 米国ではEdgar等開示されるのでそこまで日本ほどではない • h. アノテーションコストは? ◦ 弁護士、パラリーガルじゃないと判断がつかないところがありそう ◦ アノテーションコストが高い 技術的見極め 事業的見極め • a. 精度100%の時のマックスバリューはどの程度か? ◦ 法務DDならxxx億円市場 ◦ 「法務」という意味でざくっといえば 2兆円市場 • b. 精度付加価値曲線( Accuracy-Value Curve)はどんな形か? ◦ Minimum Viable Accuracyはそれなりに高そう ◦ ドメイン知識の注入と、タスク特性( Precision重視、Recall重視)を踏ま えた調整をすれば不可能ではなさそう • c. 海外のテックジャイアントへのブロッカーがあるか? ◦ 日本語、日本法の壁
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}