MongoDB New York User Group
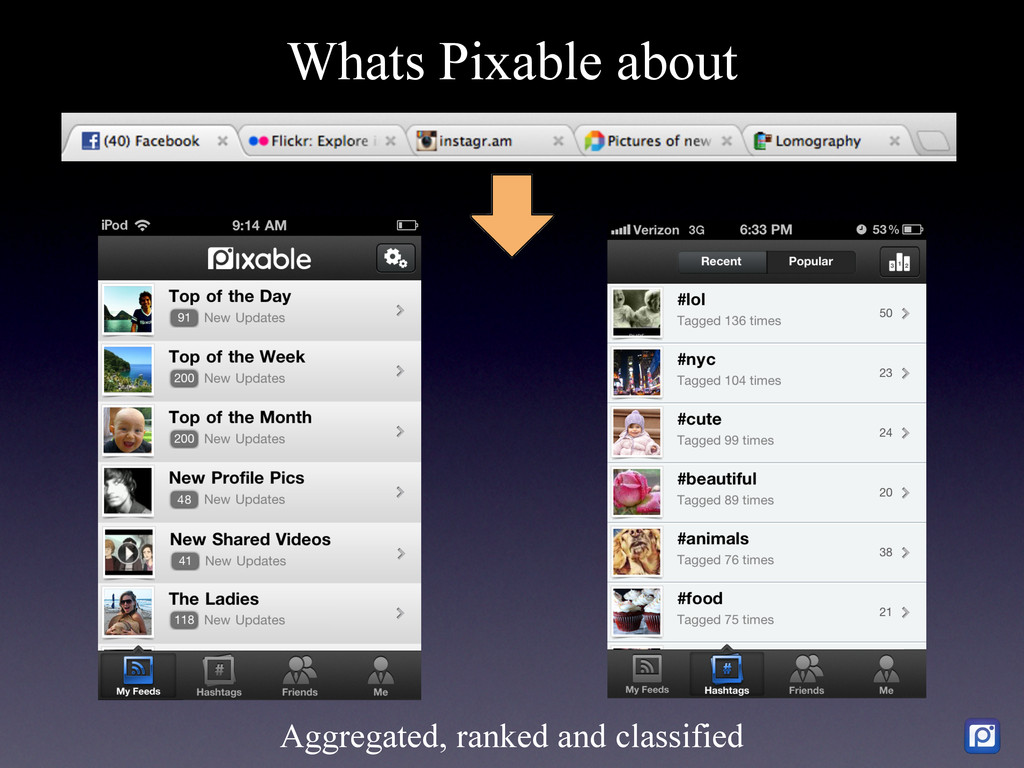
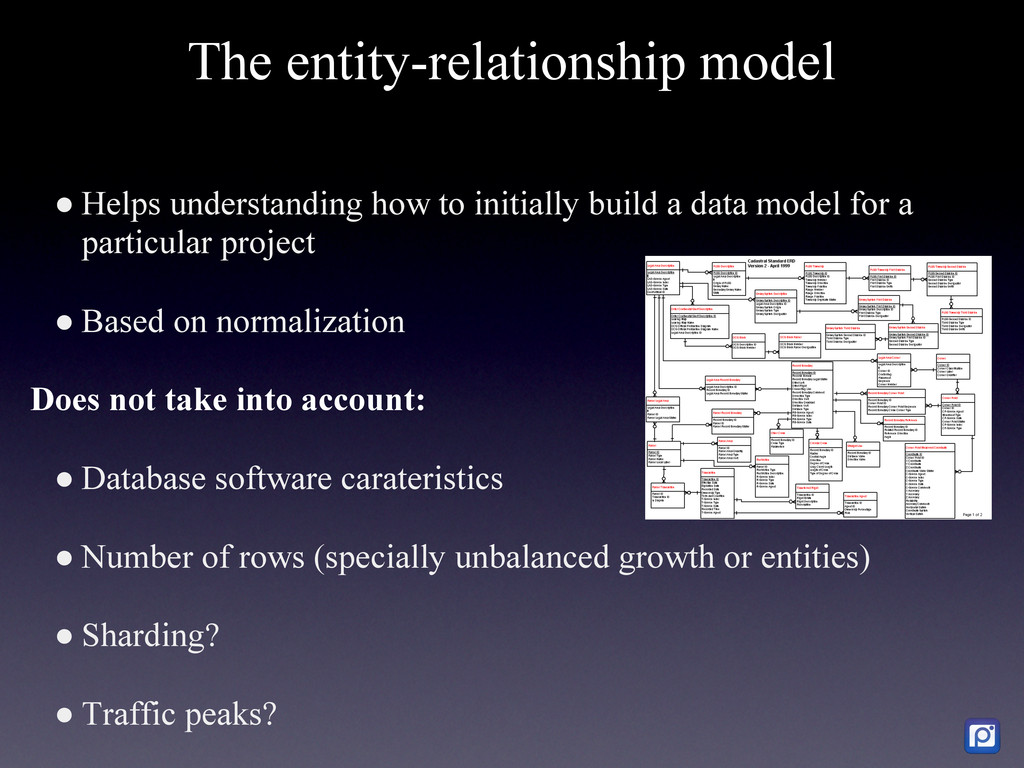
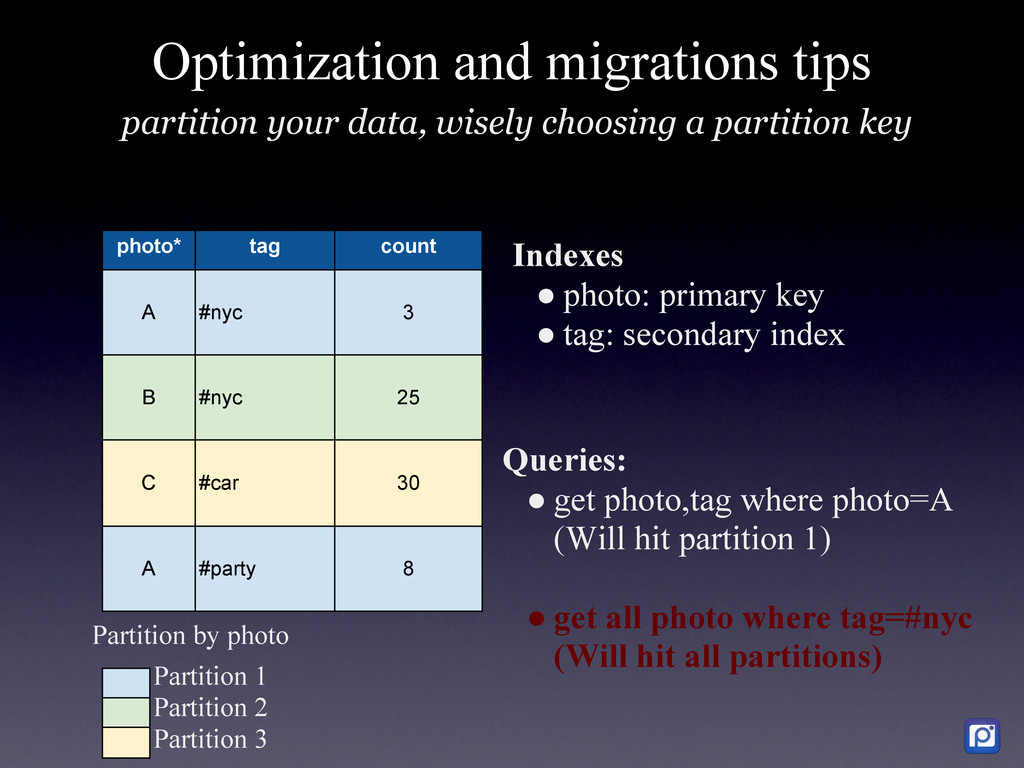
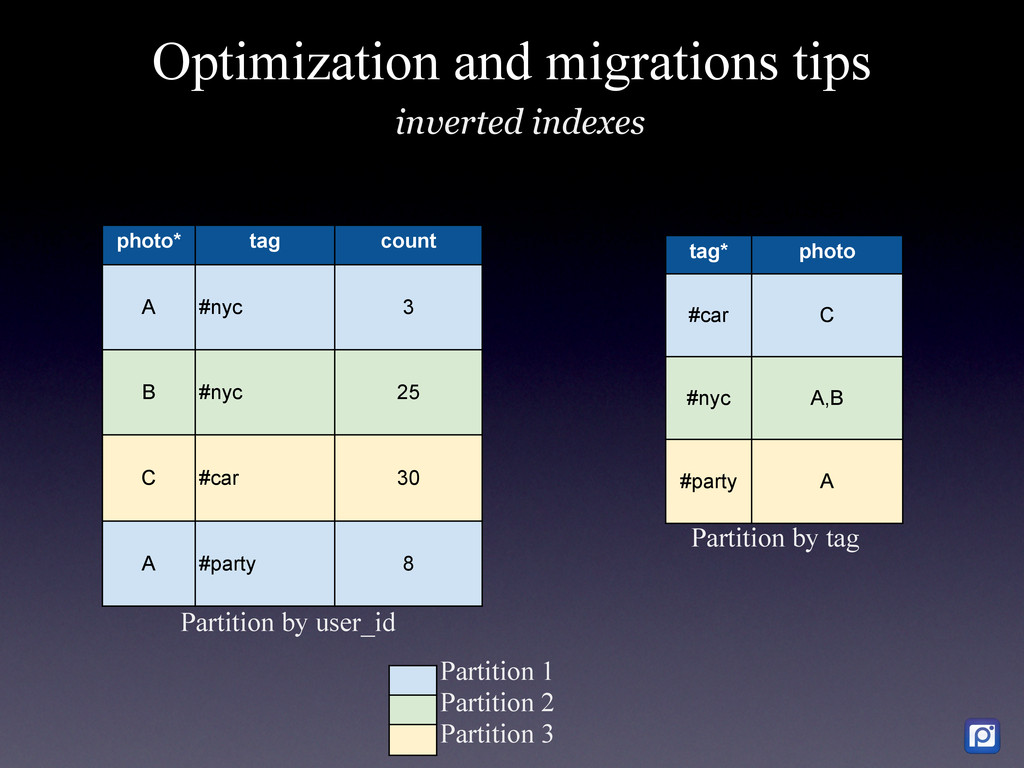
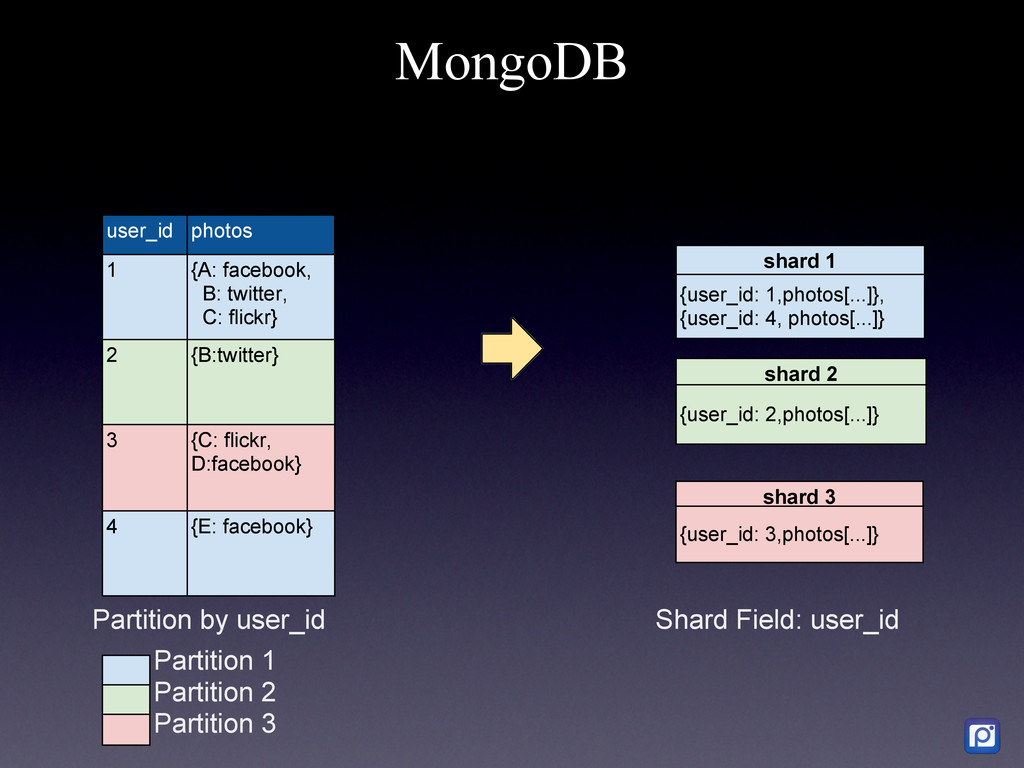
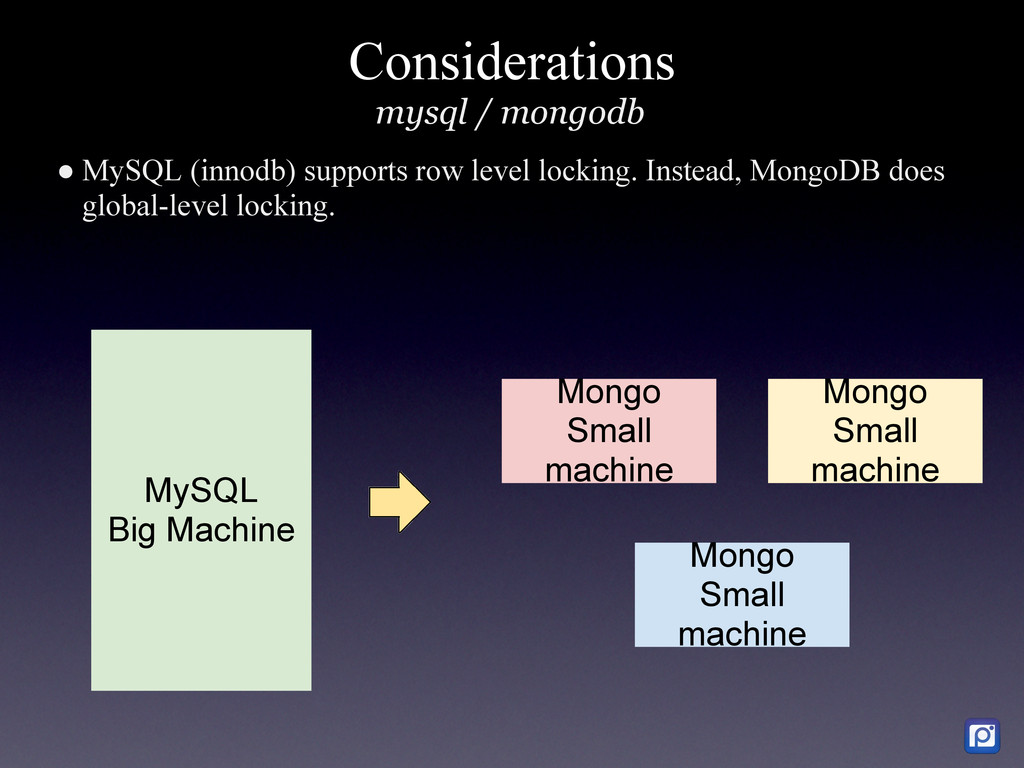
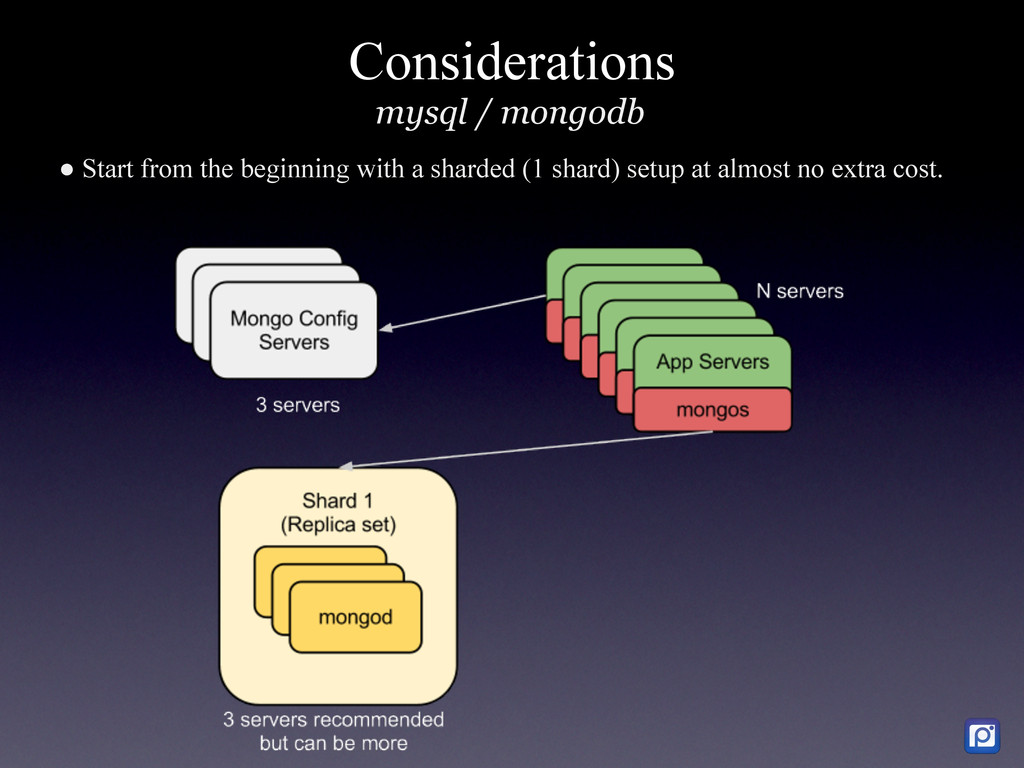
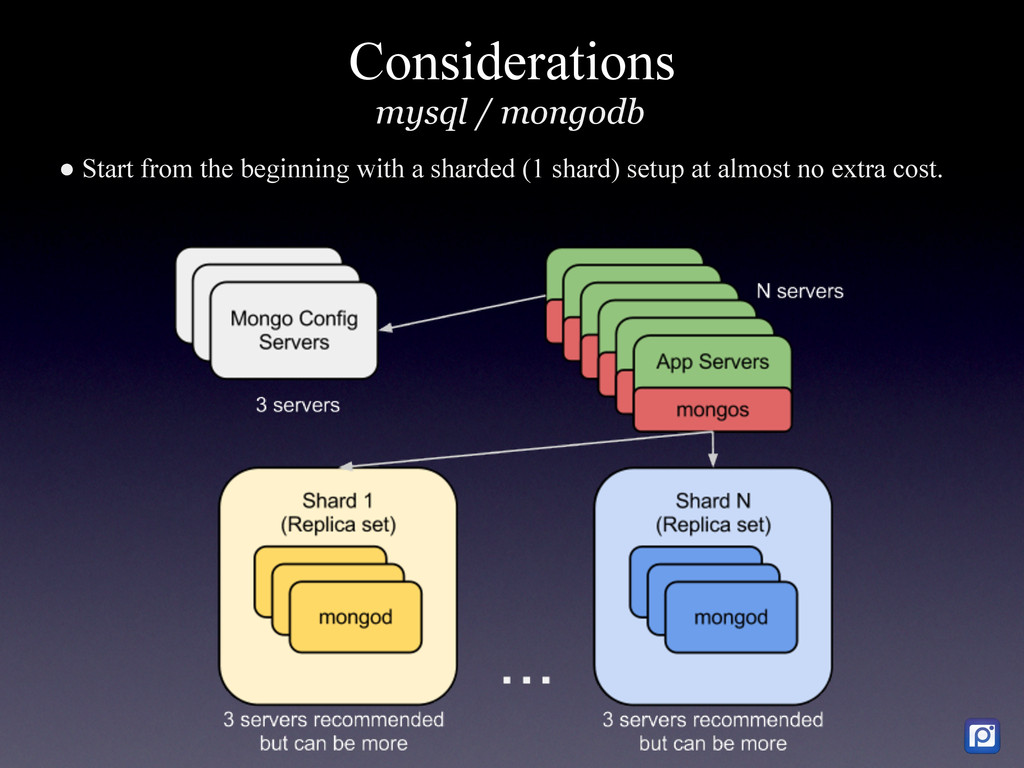
How we did it in MySQL and why we are migrating to MongoDB We have two main challenges at Pixable. The first one is how to access millions of photos per day from Facebook, Twitter, Instagram, and other services in the most efficient manner. The second one, is how to process, organize, index, and store all the meta-data related to those photos. In order to accomplish this, we heavily rely on Amazon Web Services, where we have 100+ servers running. As of today, we are processing the metadata of an average 20 million new photos per day, which we need to compare, rank and sort with over 5 billion that are already stored in our database. On top of this we have a API backend that serves thousands of request per second, and a logging and analytics system that performs over 10K updates per second in our database. To support all ever-growing database needs, we have built a highly customized MySQL cluster with semi-automatic shards and partitions, optimized every single request and de-normalized most of our data. For large write rates we use our own publish/subscriber frameworks with various database levels and memory buffers (almost everything in Pixable is asynchronous). But in our quest of building a system that could allow us to scale in a more easy, flexible and solid way, we chose MongoDB as our next generation data storage solution. Resuming, this is the story of how we got to this point in MySQL, what are our current challenges and how are we progressively migrating our millions of users and billion of photos to MongoDB.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}