MongoBoston 2011
Receiving data from a source that produces 5-10 GBytes per hour, sustained for 24 hrs, and presenting analysis results as the data streams in has... some interesting challenges. We used MongoDB running on Amazon EC2 to house the data, map reduce to analyze it and Django-non-rel to present the results in near-real-time.
{kind=link}
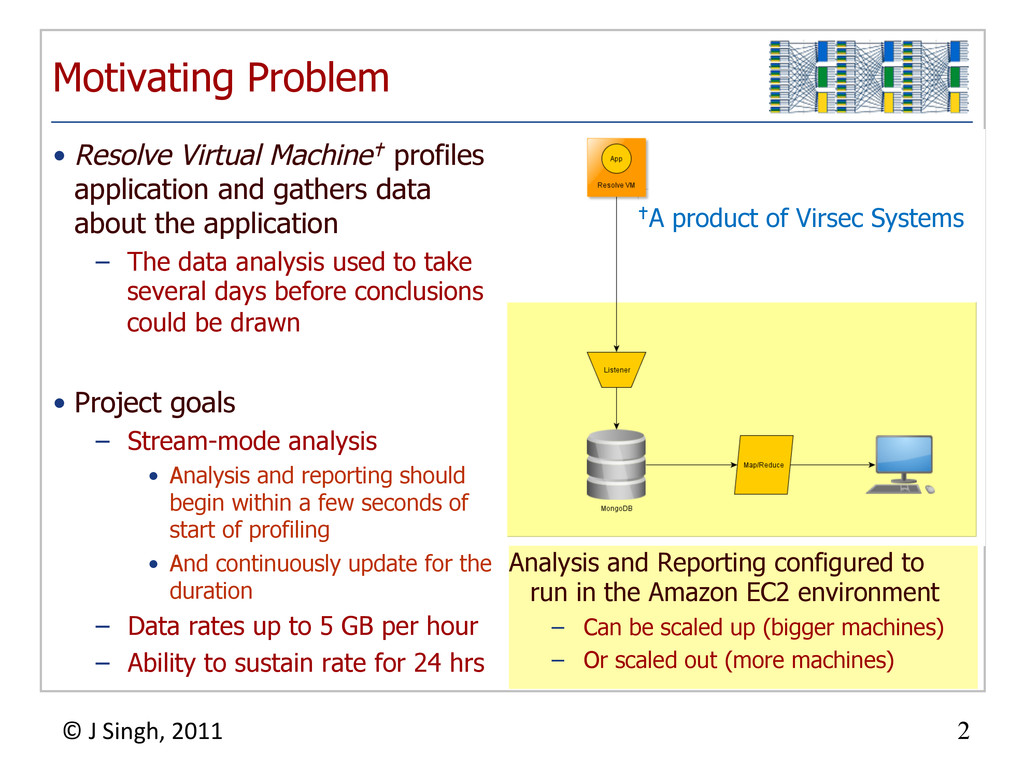{kind=link}
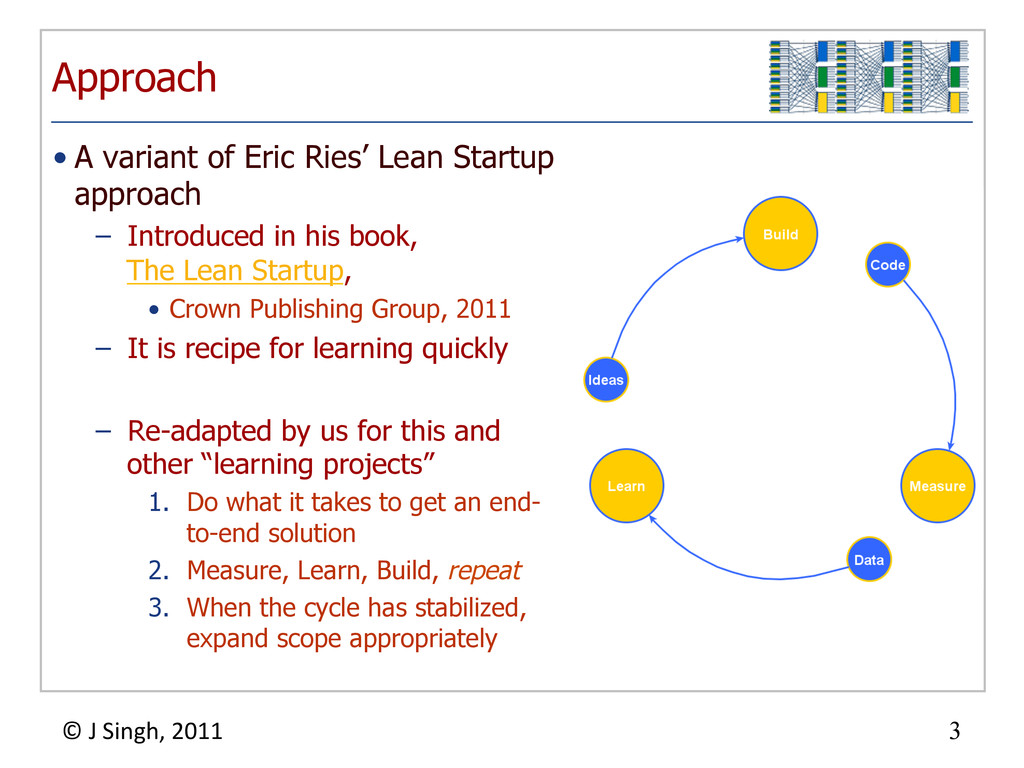{kind=link}
{kind=link}
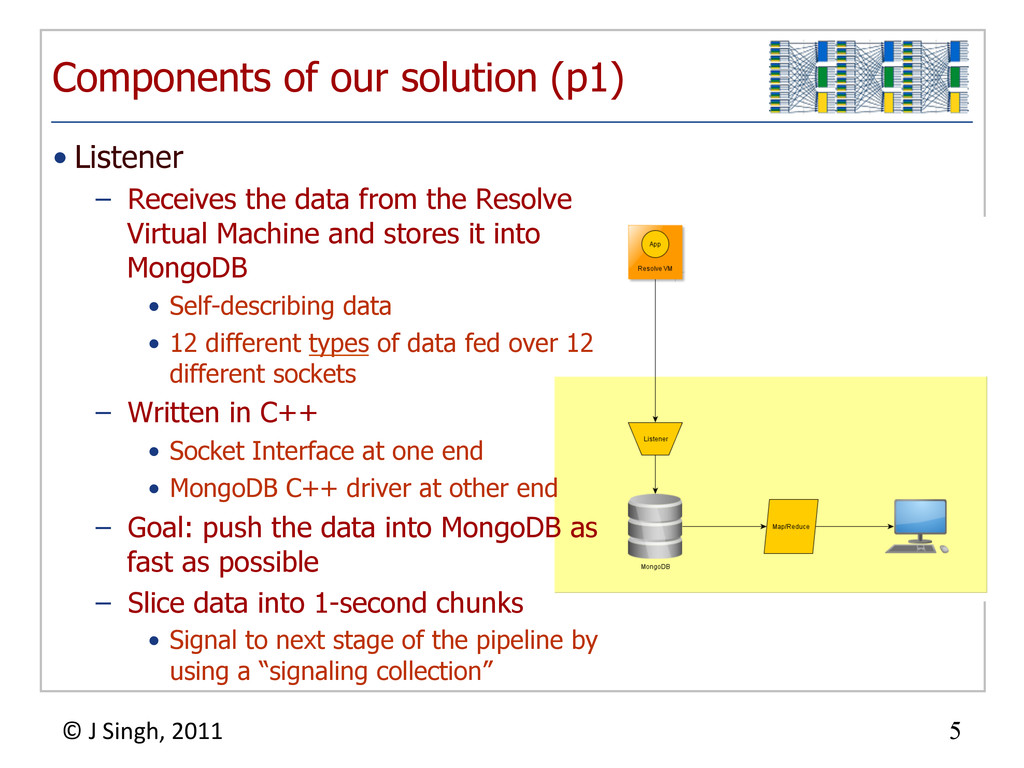{kind=link}
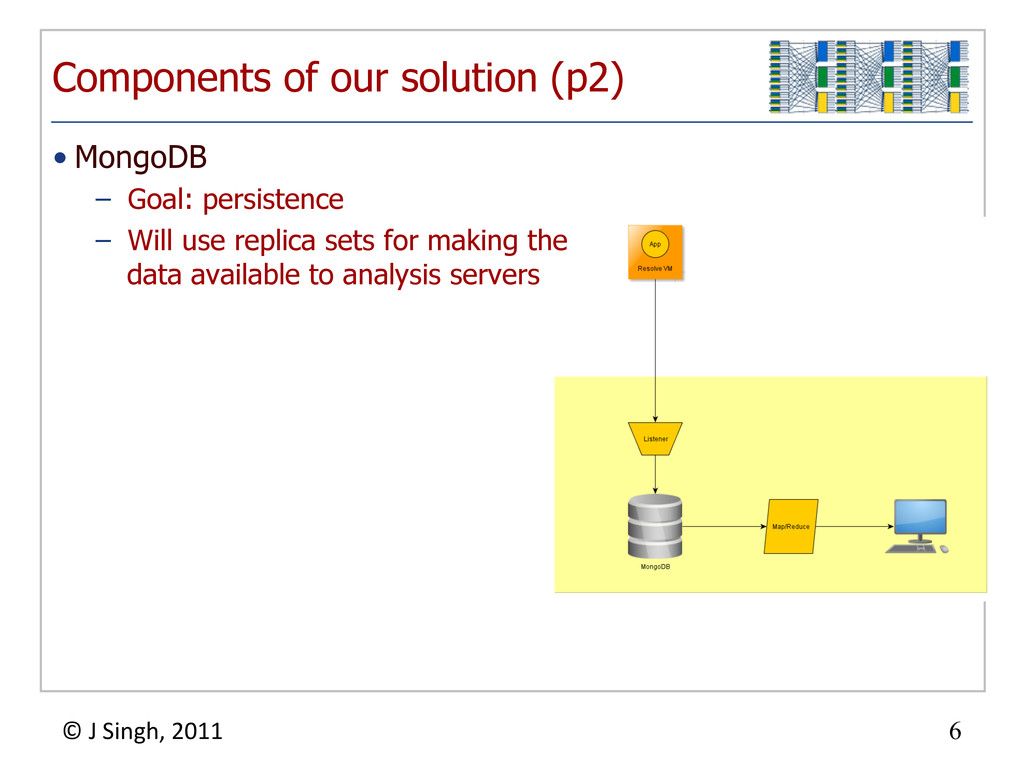{kind=link}
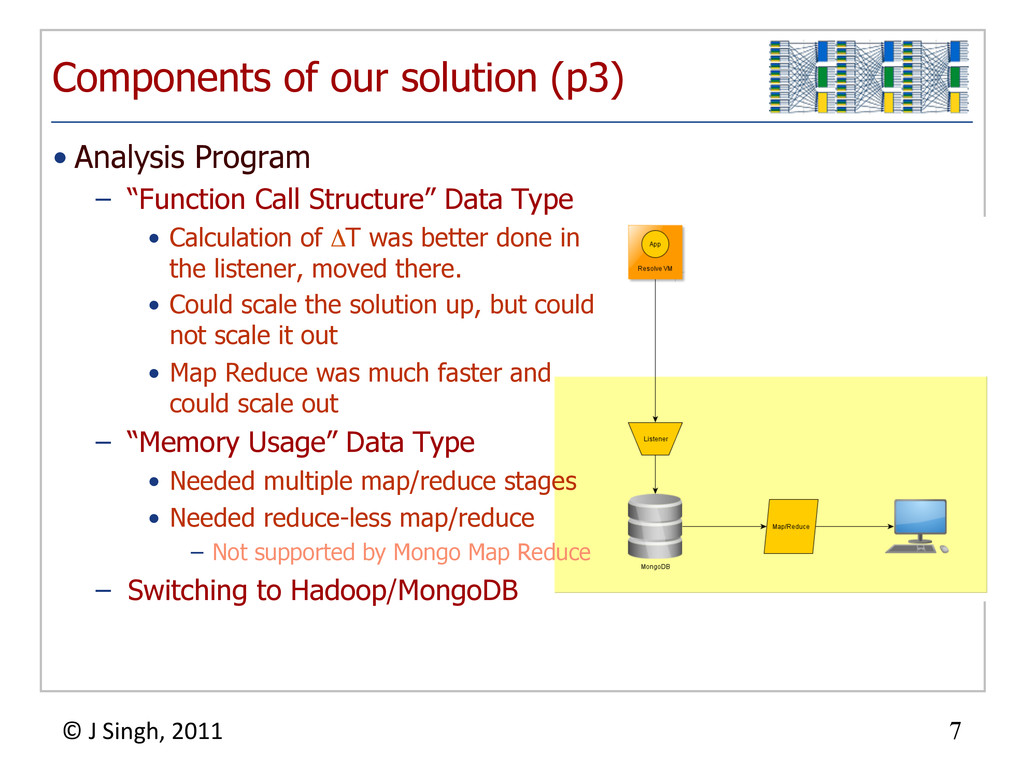{kind=link}
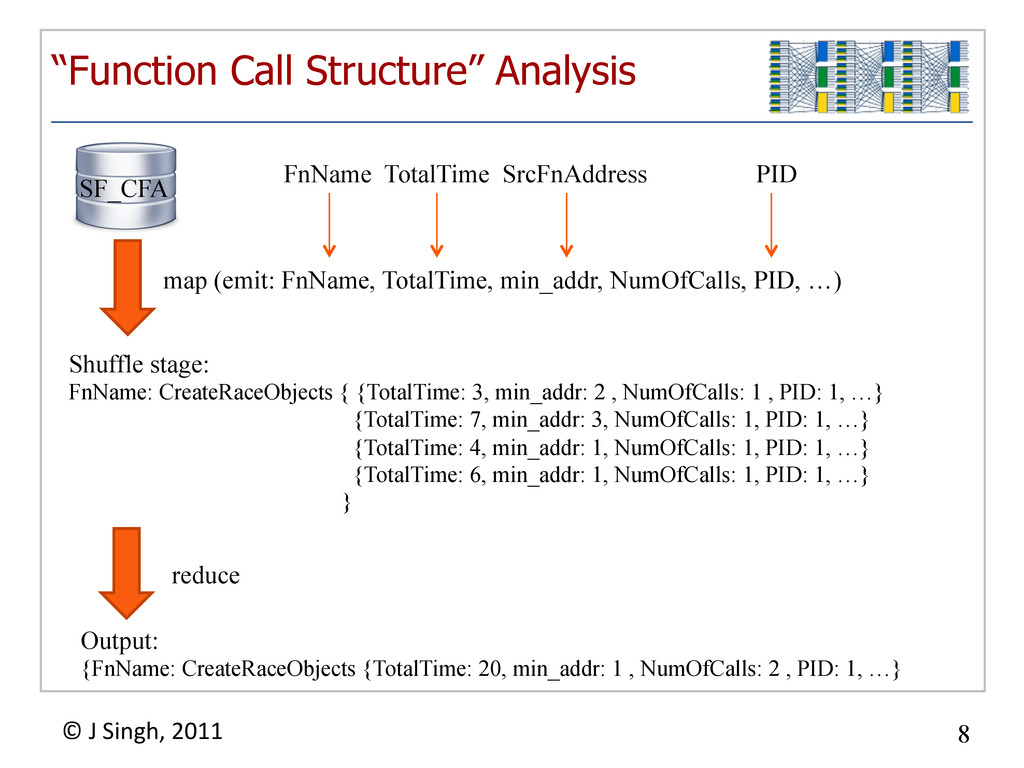{kind=link}
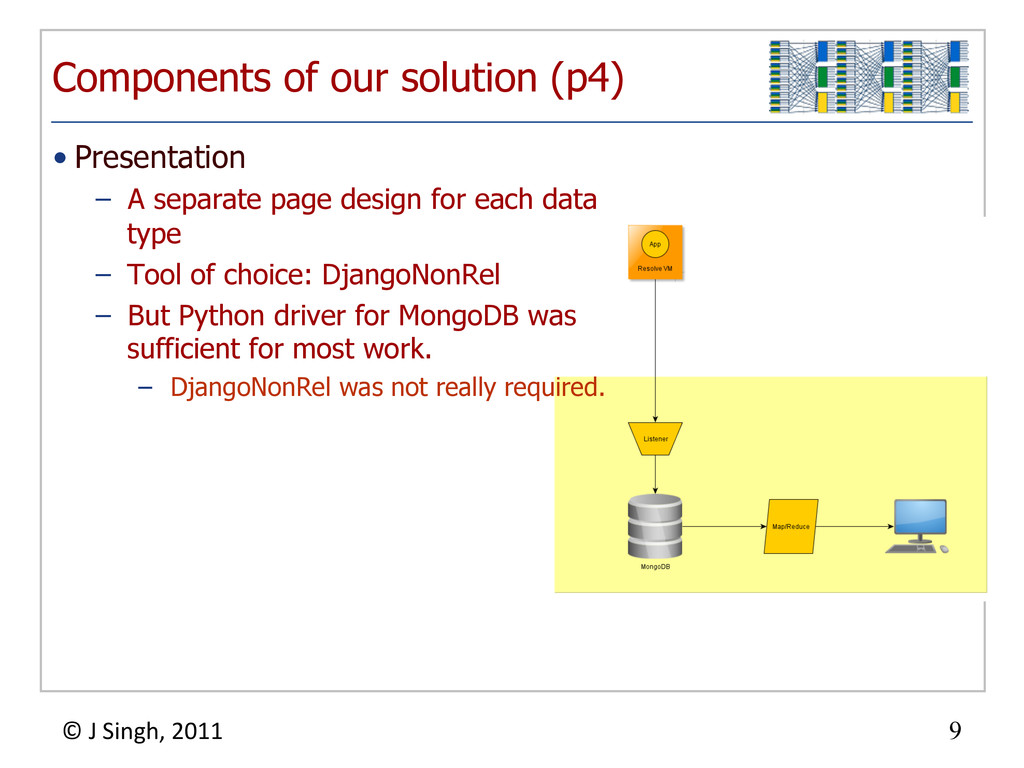{kind=link}
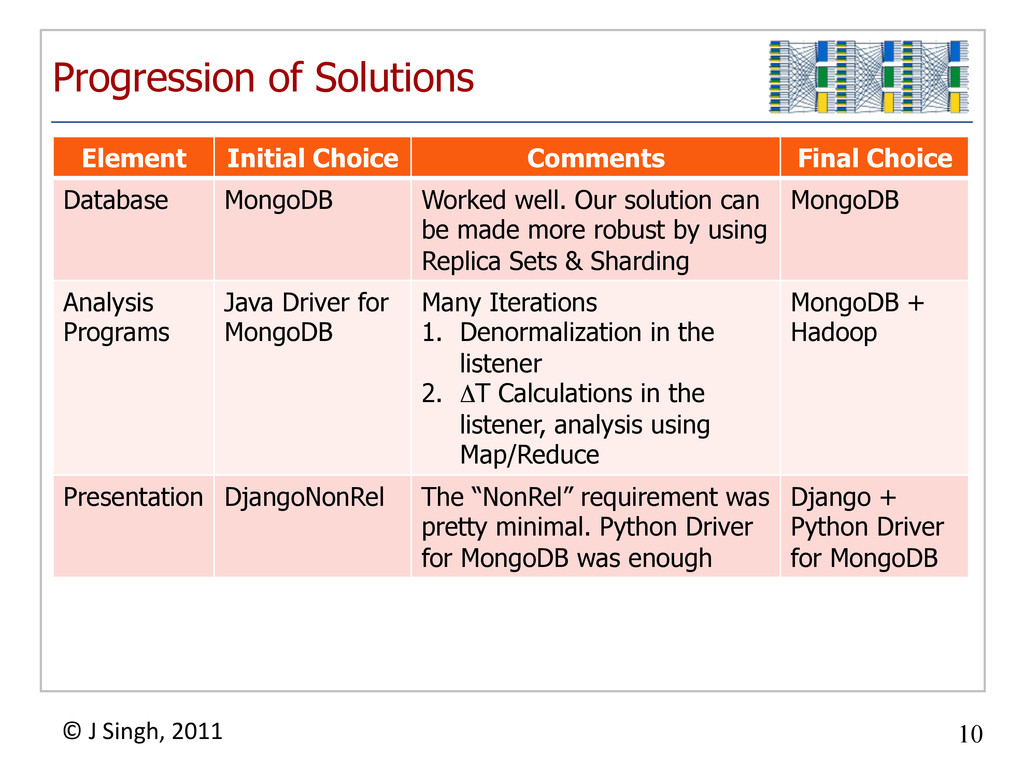{kind=link}
{kind=link}
{kind=link}