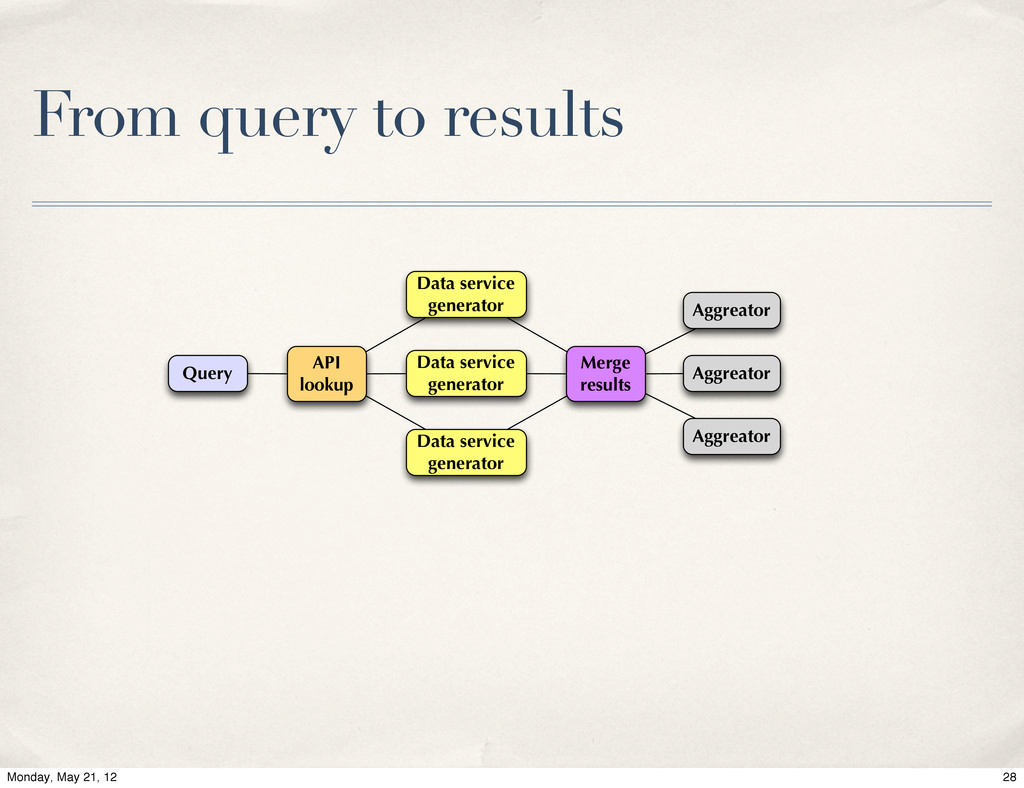
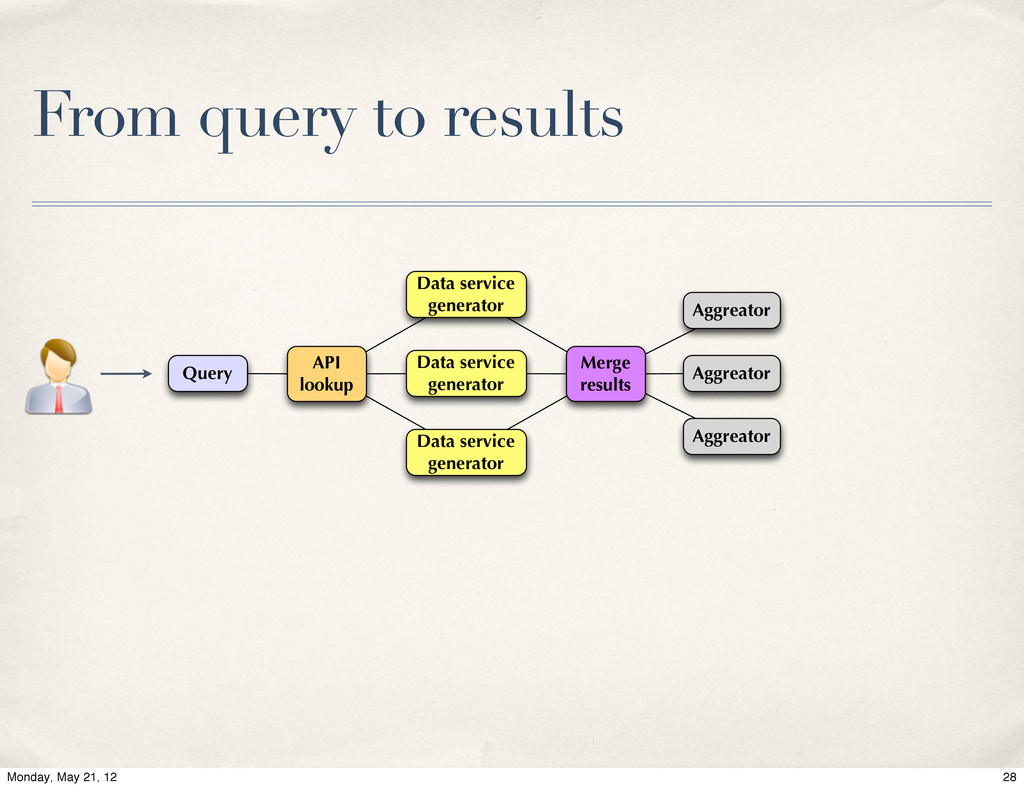
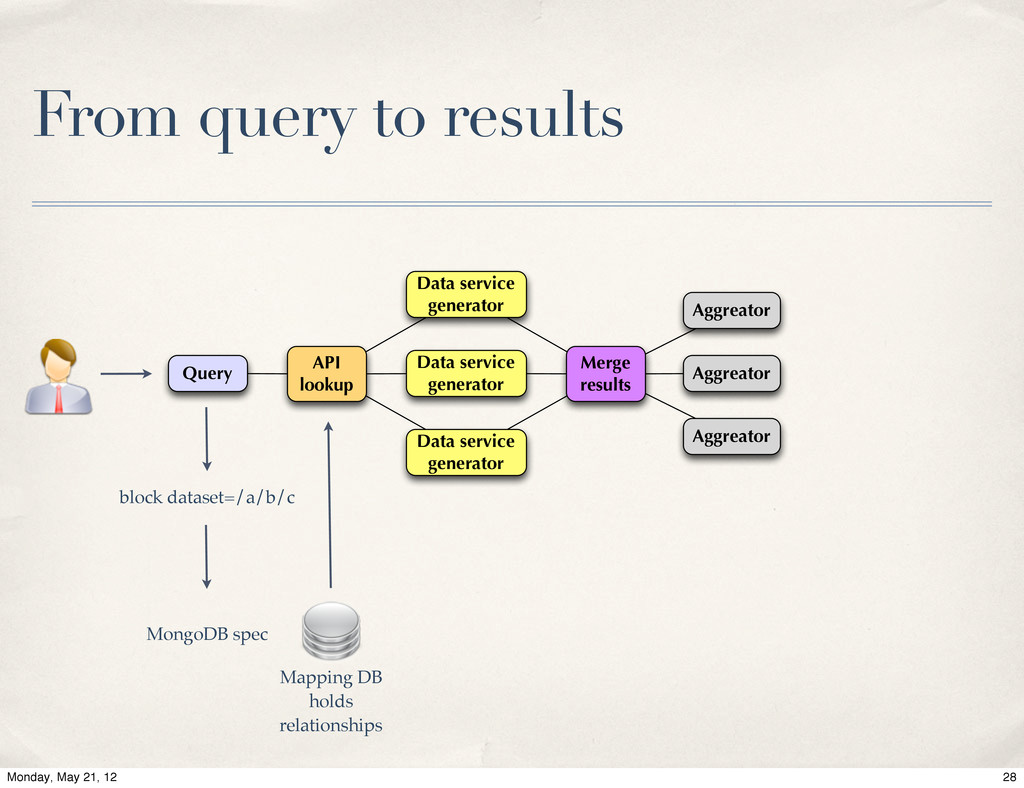
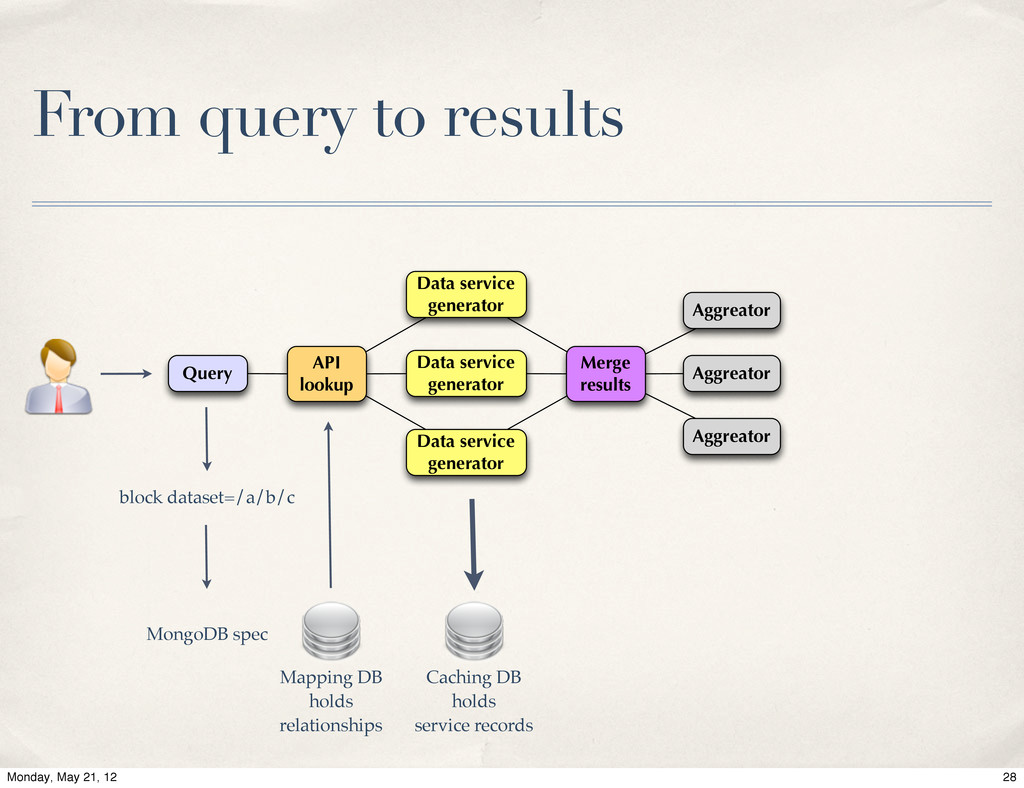
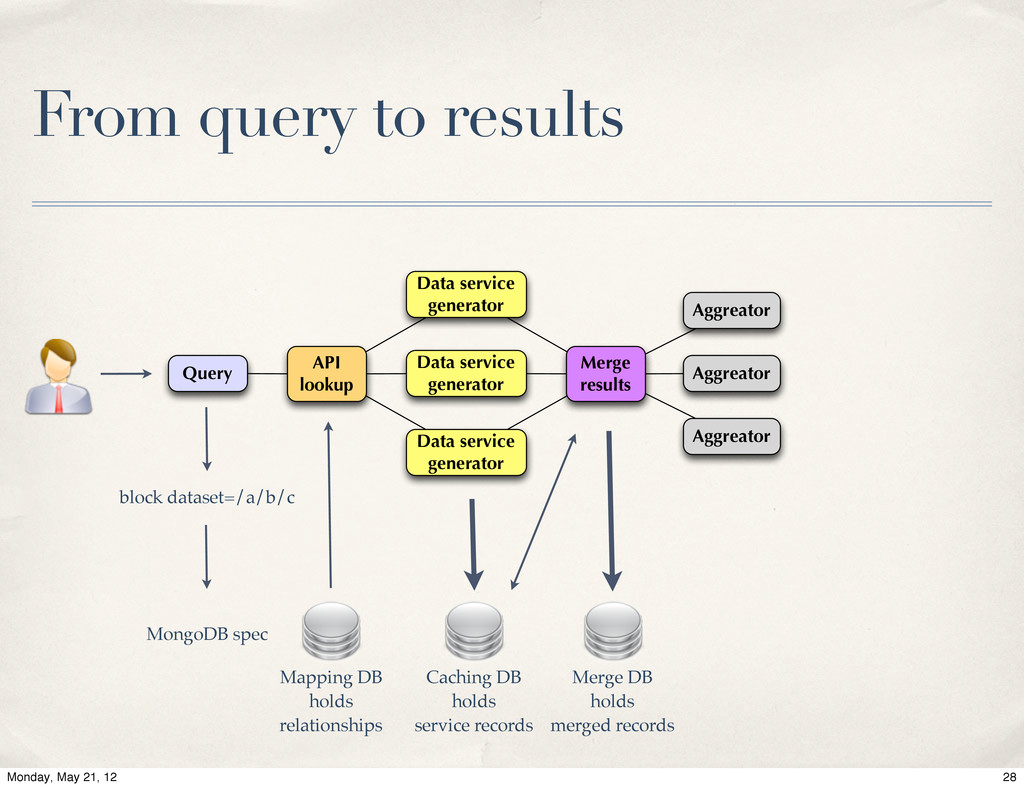
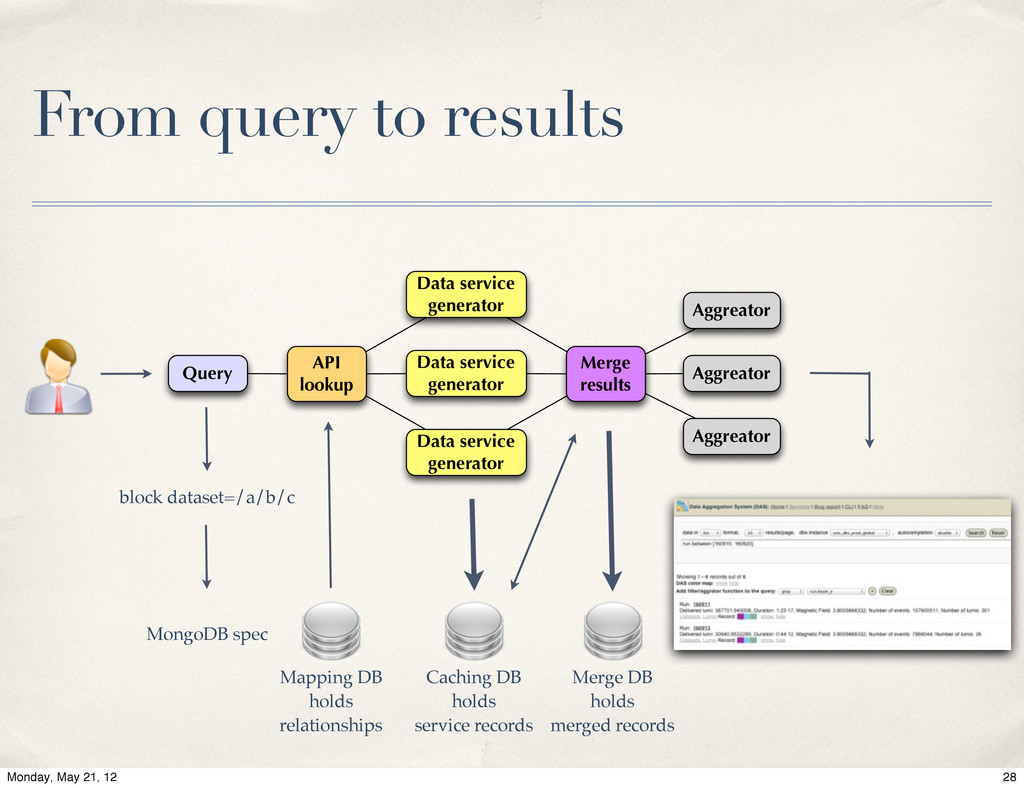
Live of MongoDB at Energy Frontier, Valentin Kuznetsov, Cornell / CERN. The Data Aggregation system is a next generation of data discovery service for CMS experiment at CERN LHC. Its primary goal is to help physicists to find desired information across distributed CMS data-services. The MongoDB was chosen as a primary back-end to carry this task. We will provide system overview and our experience with MognoDB in production environment.
{kind=link}
{kind=link}
{kind=link}
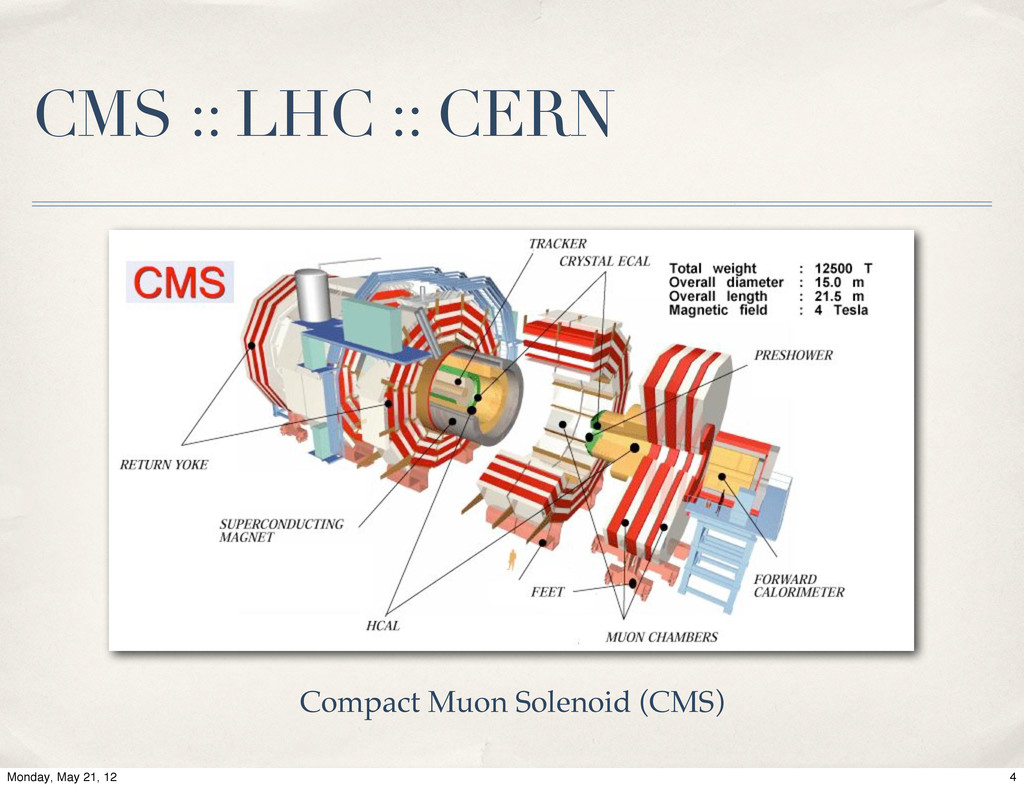{kind=link}
{kind=link}
{kind=link}
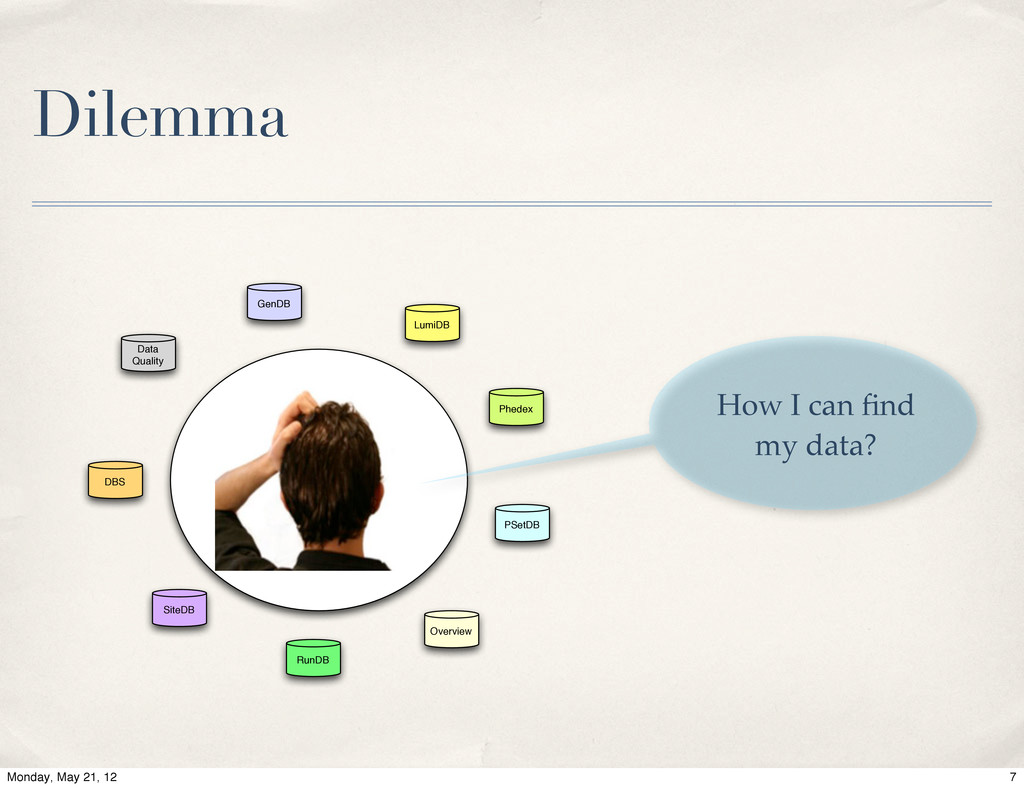{kind=link}
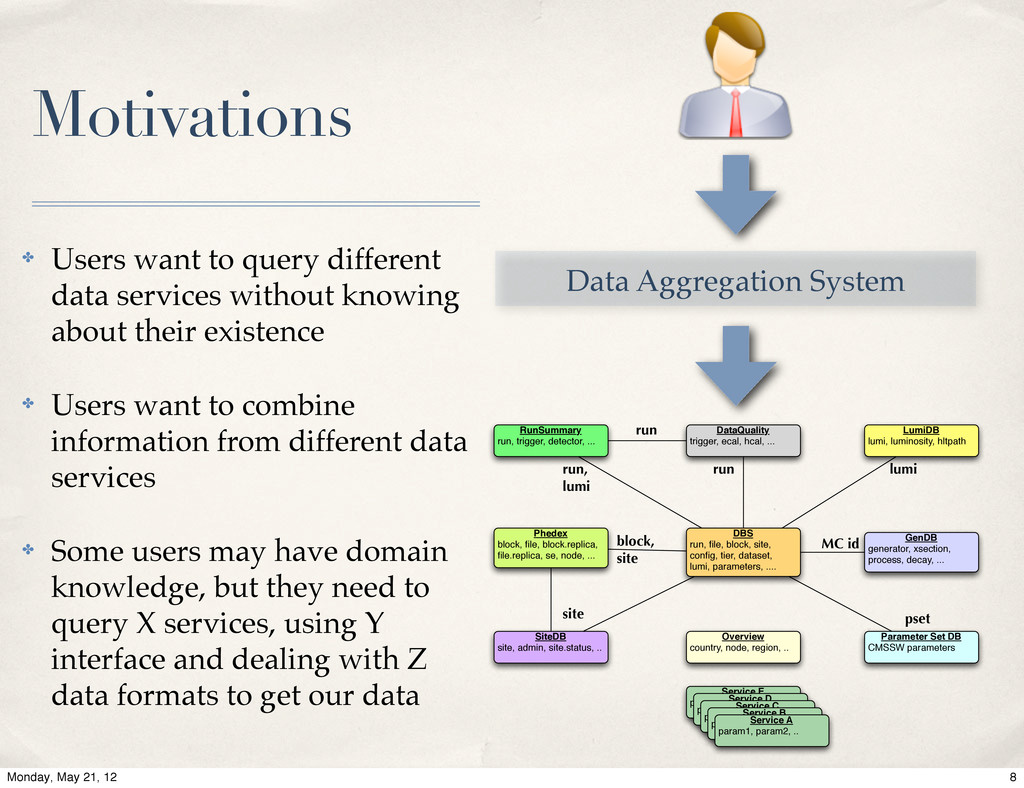{kind=link}
{kind=link}
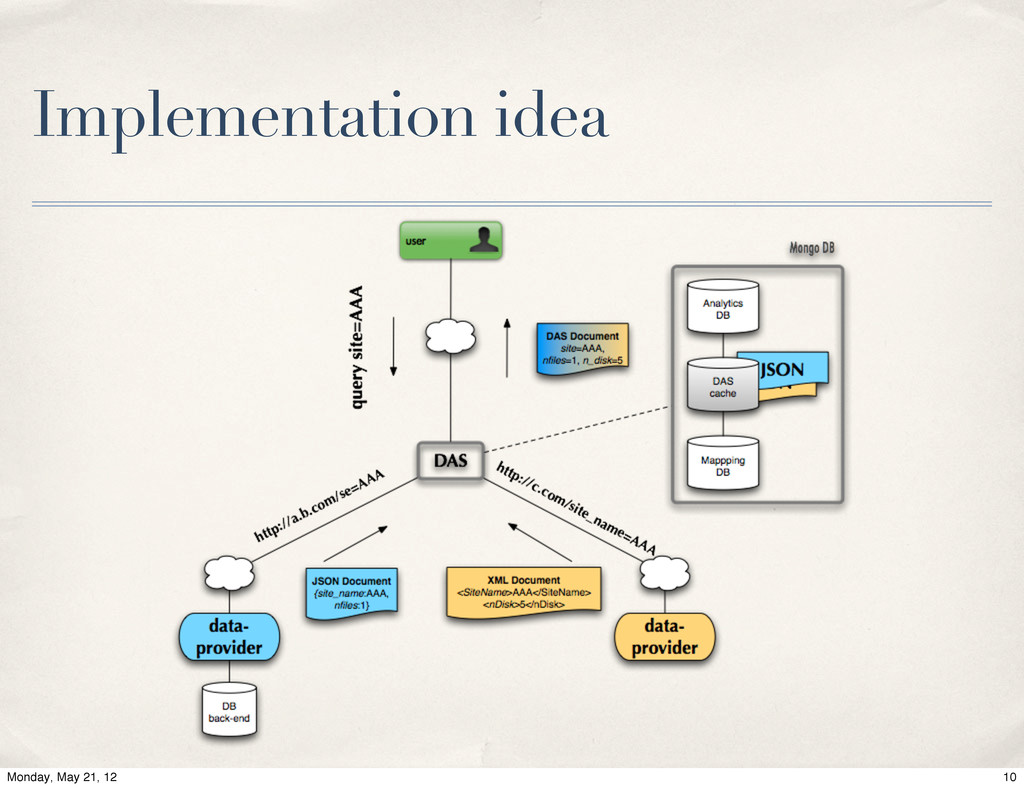{kind=link}
{kind=link}
{kind=link}
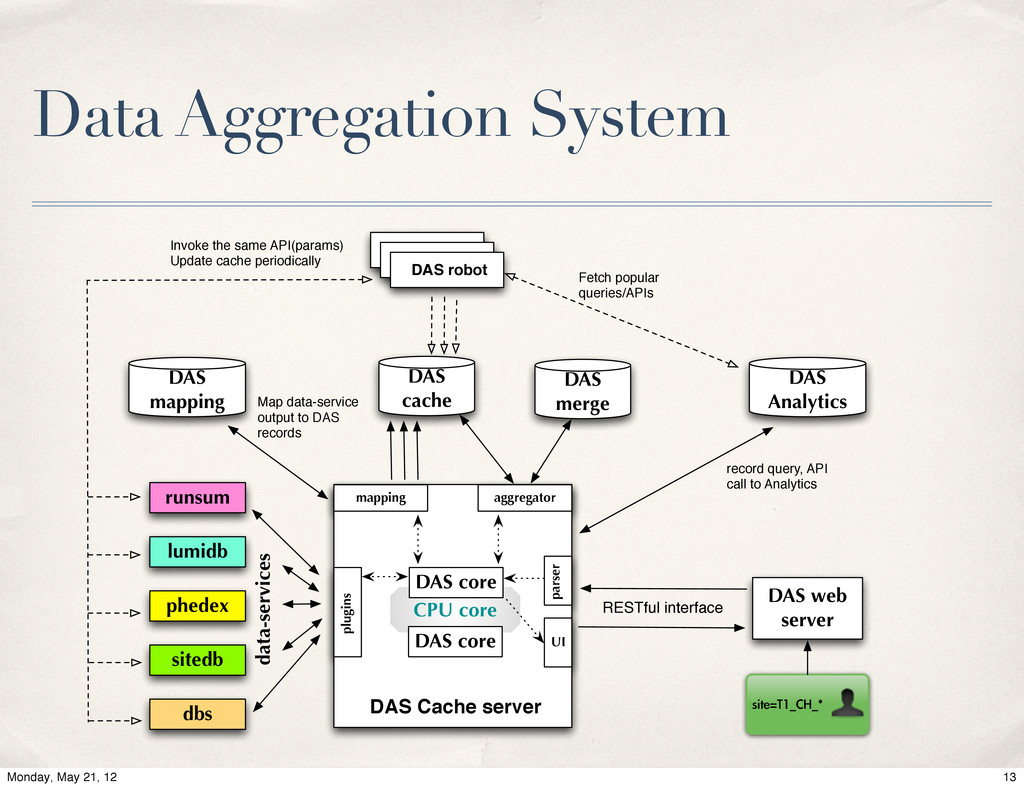{kind=link}
{kind=link}
{kind=link}
{kind=link}
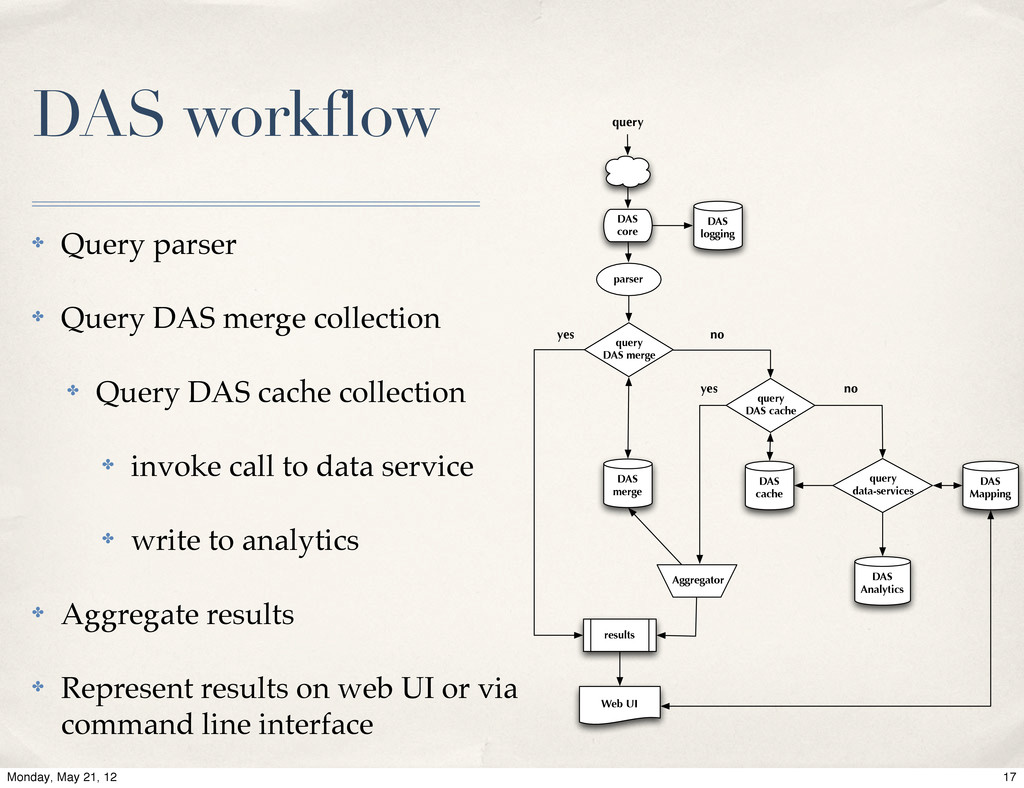{kind=link}
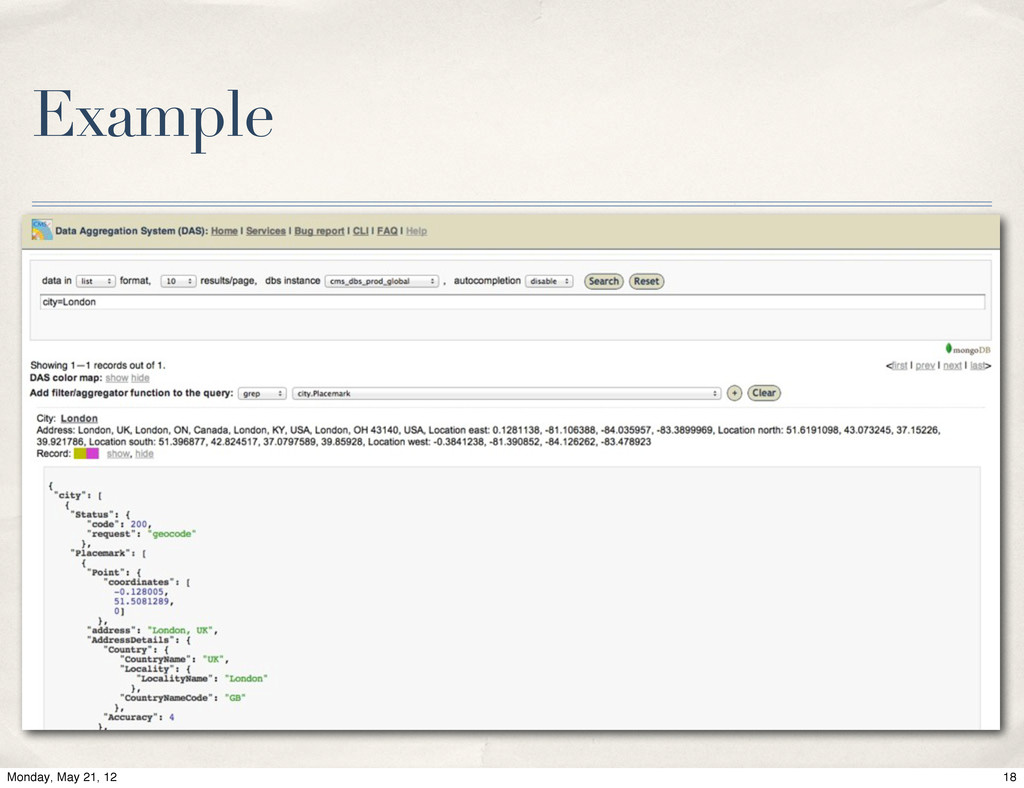{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}