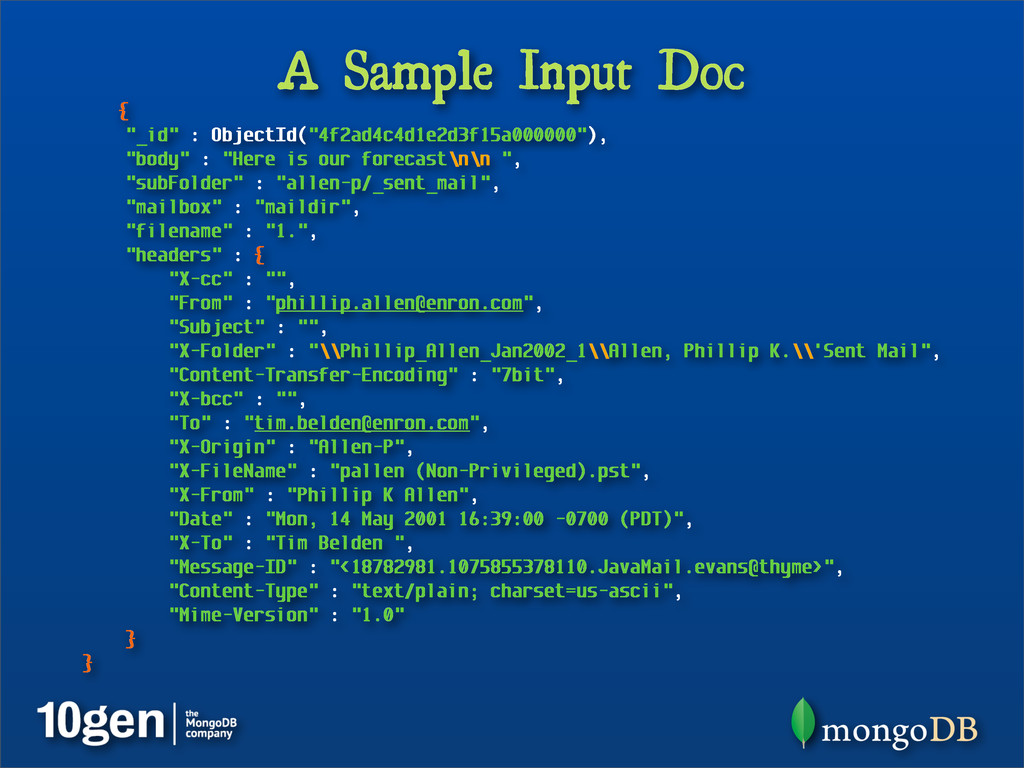
"
[email protected]", "f" : "
[email protected]" }, "count" : 1 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 1 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 2 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 2 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 4 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 1 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 1 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 2 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 1 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 2 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 1 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 3 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 1 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 3 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 4 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 1 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 6 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 3 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 2 } { "_id" : { "t" : "
[email protected]", "f" : "
[email protected]" }, "count" : 1 } has more
![Brendan McAdams 10gen, Inc. [email protected] @rit Taming The Elephant In](https://files.speakerdeck.com/presentations/4fc4e5370608eb0022013642/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
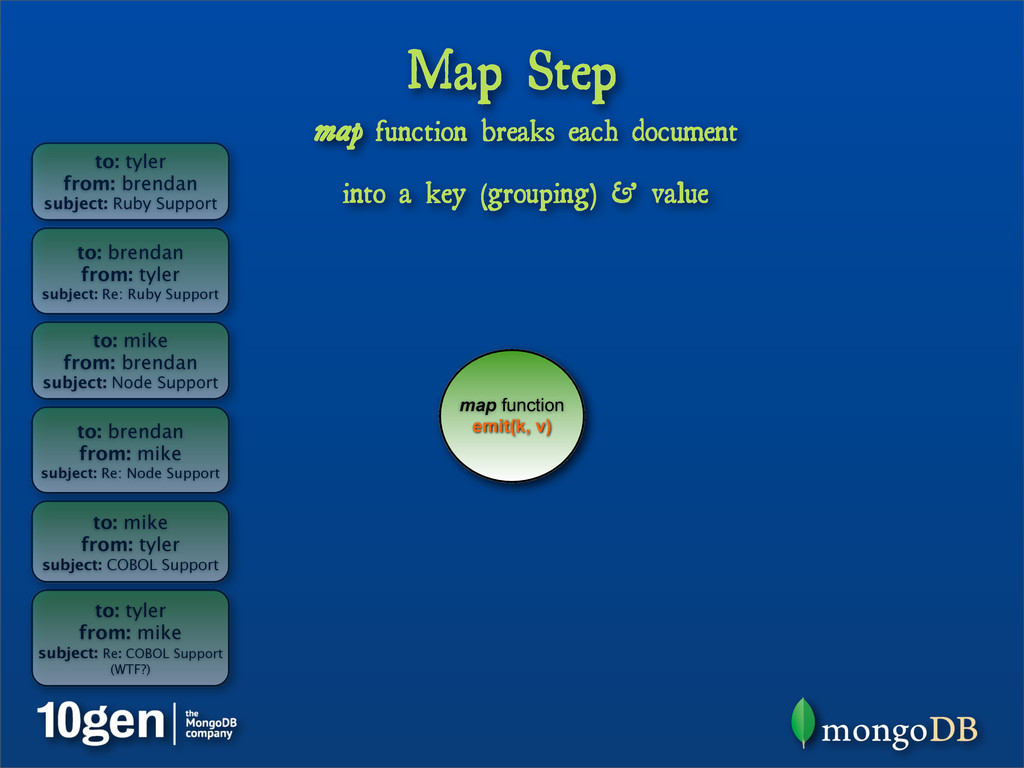{kind=link}
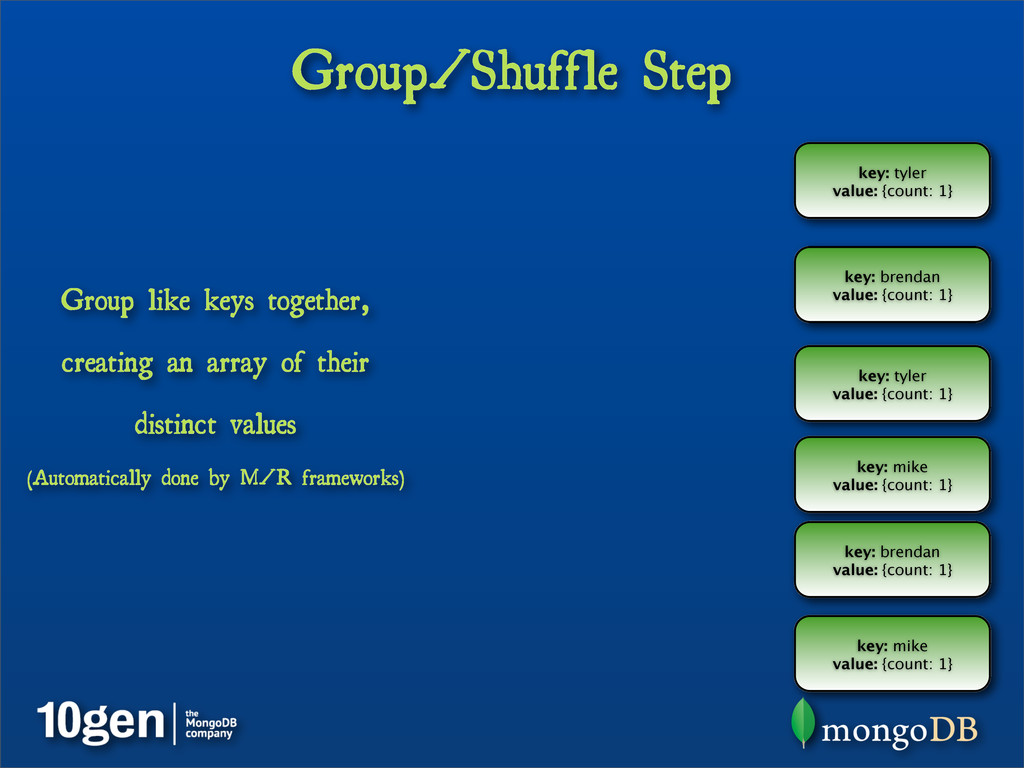{kind=link}
![Group/Shuffle Step key: brendan values: [{count: 1}, {count: 1}] key:](https://files.speakerdeck.com/presentations/4fc4e5370608eb0022013642/slide_31.jpg){kind=link}
![Reduce Step key: brendan values: [{count: 1}, {count: 1}] key:](https://files.speakerdeck.com/presentations/4fc4e5370608eb0022013642/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
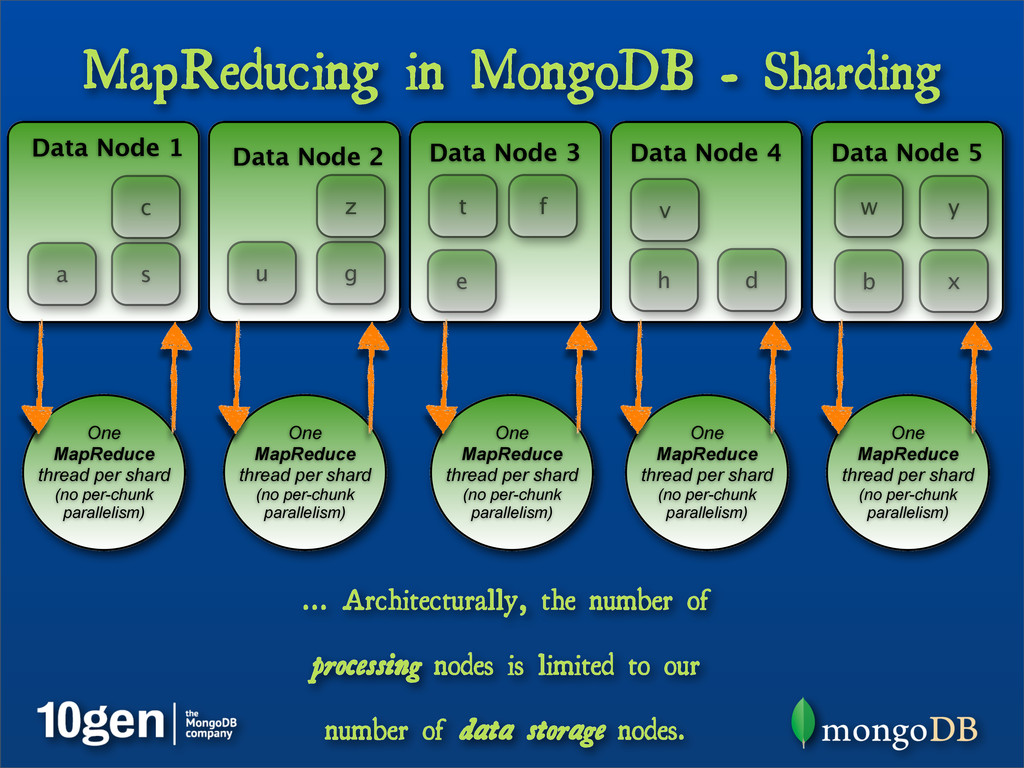{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
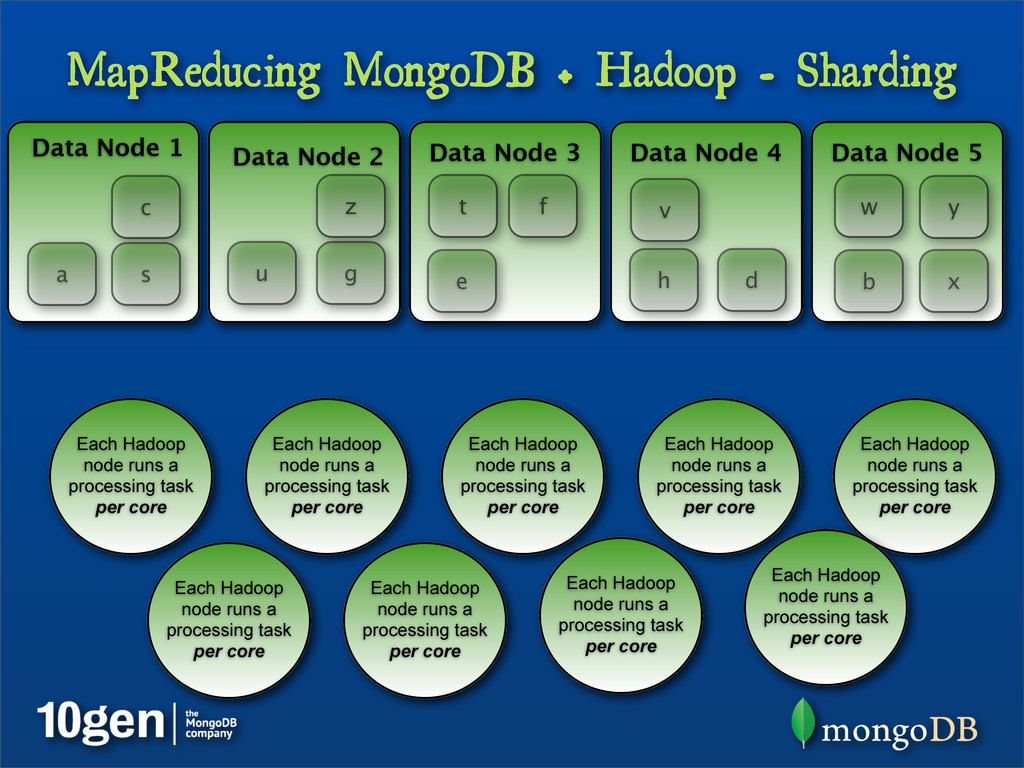{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}