MongoChicago 2011
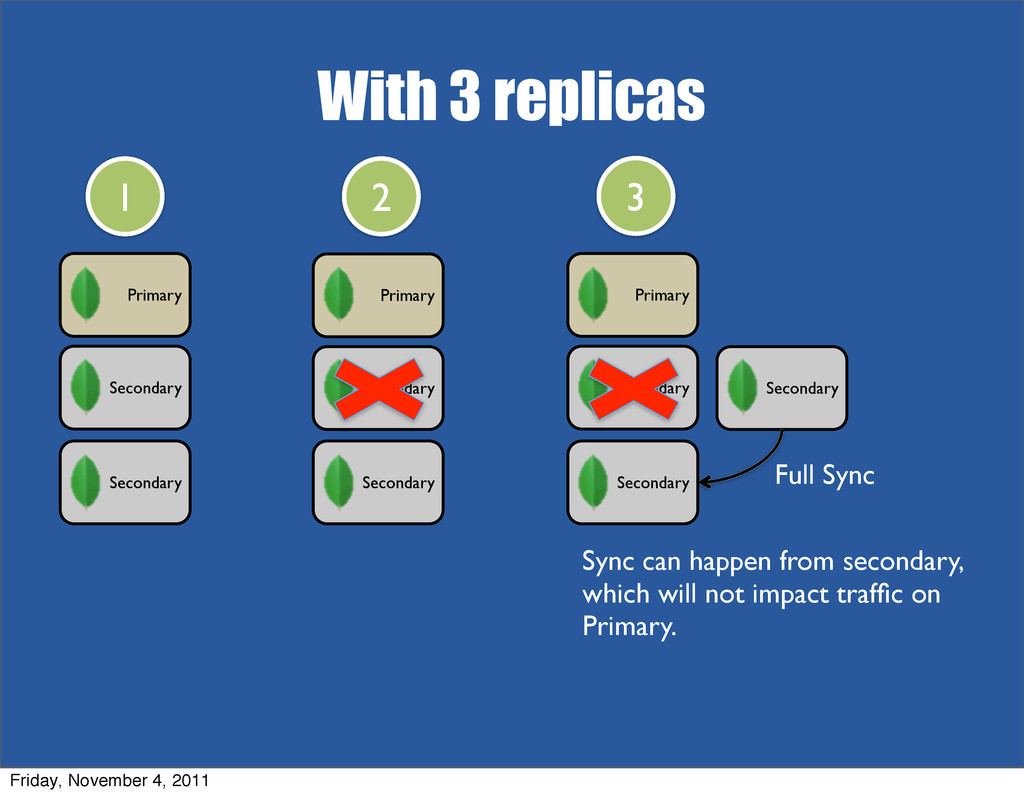
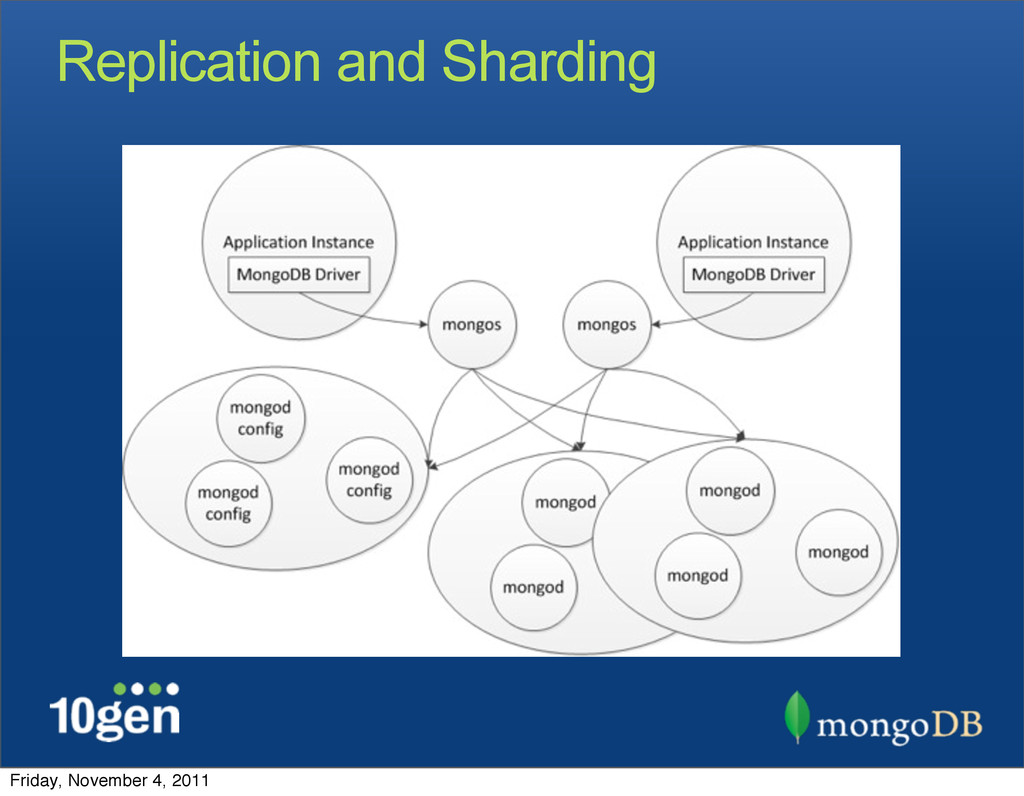
MongoDB supports replication for failover and redundancy. In this session we will introduce the basic concepts around replica sets which provide...... automated failover and recovery of nodes. We'll show you how to set up, configure, and initiate a replica set, and methods for using replication to scale reads. We'll also discuss proper architecture for durability.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
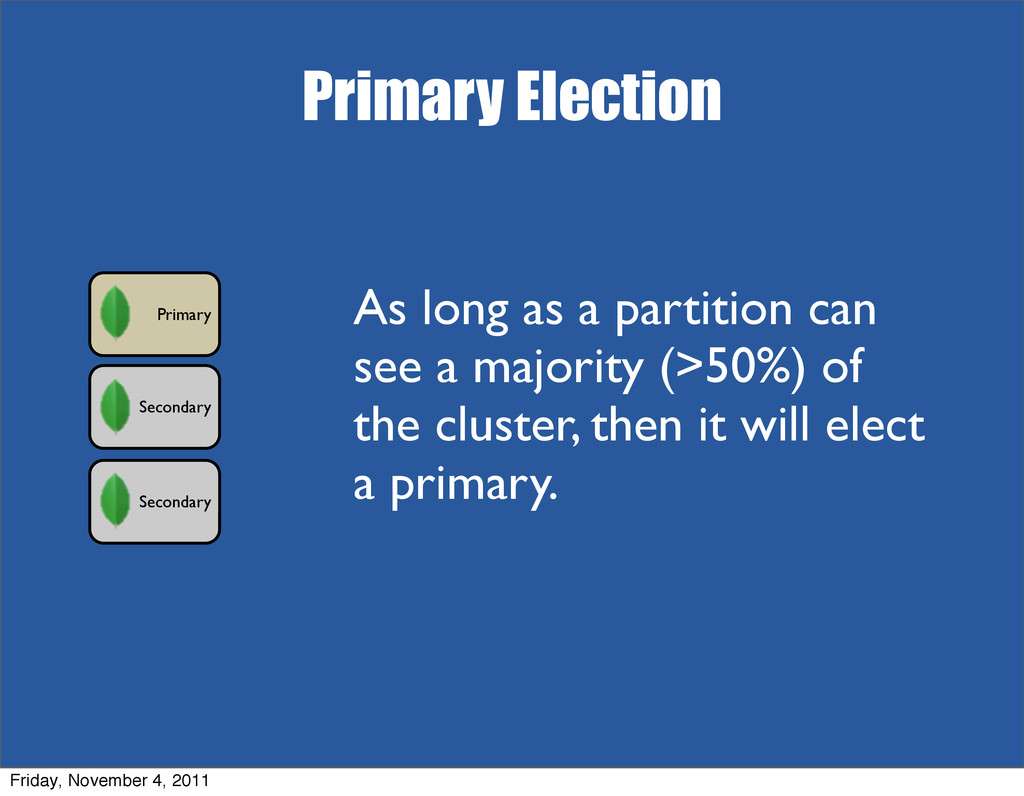{kind=link}
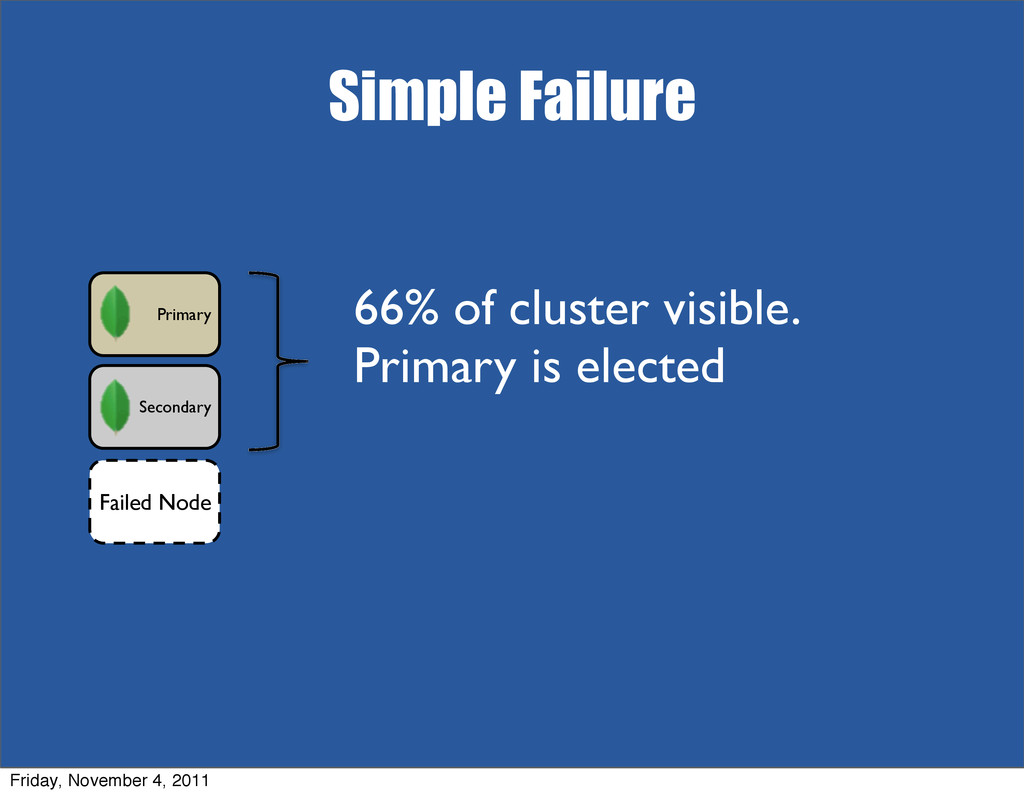{kind=link}
{kind=link}
{kind=link}
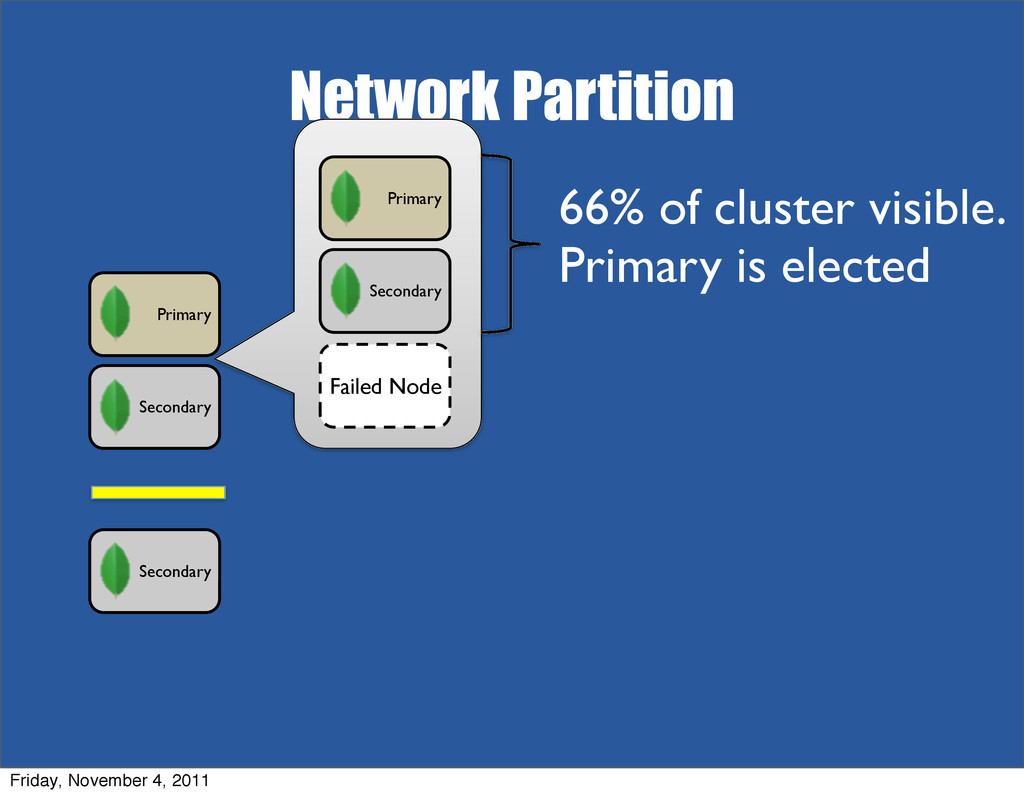{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
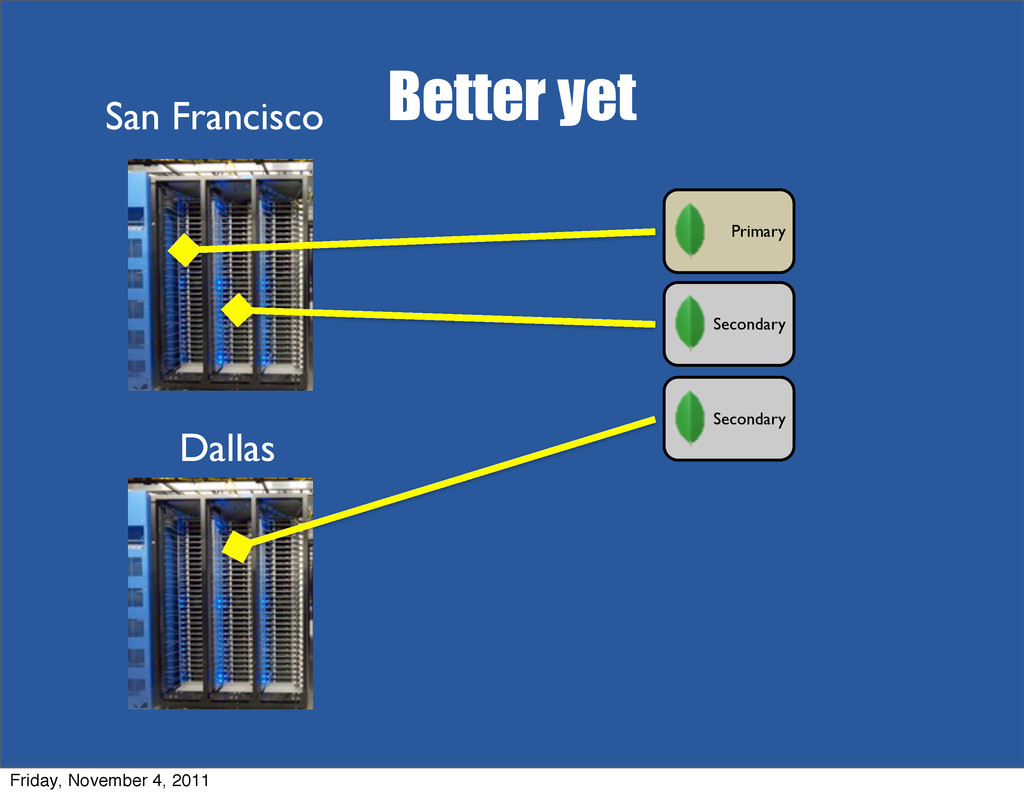{kind=link}
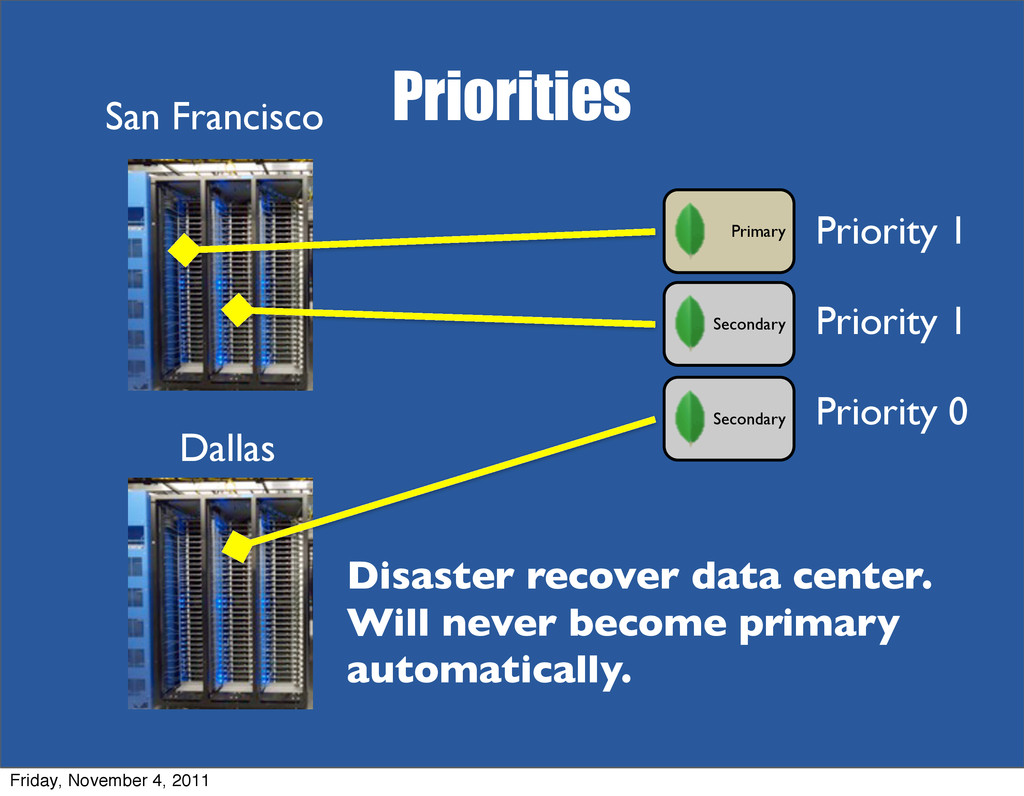{kind=link}
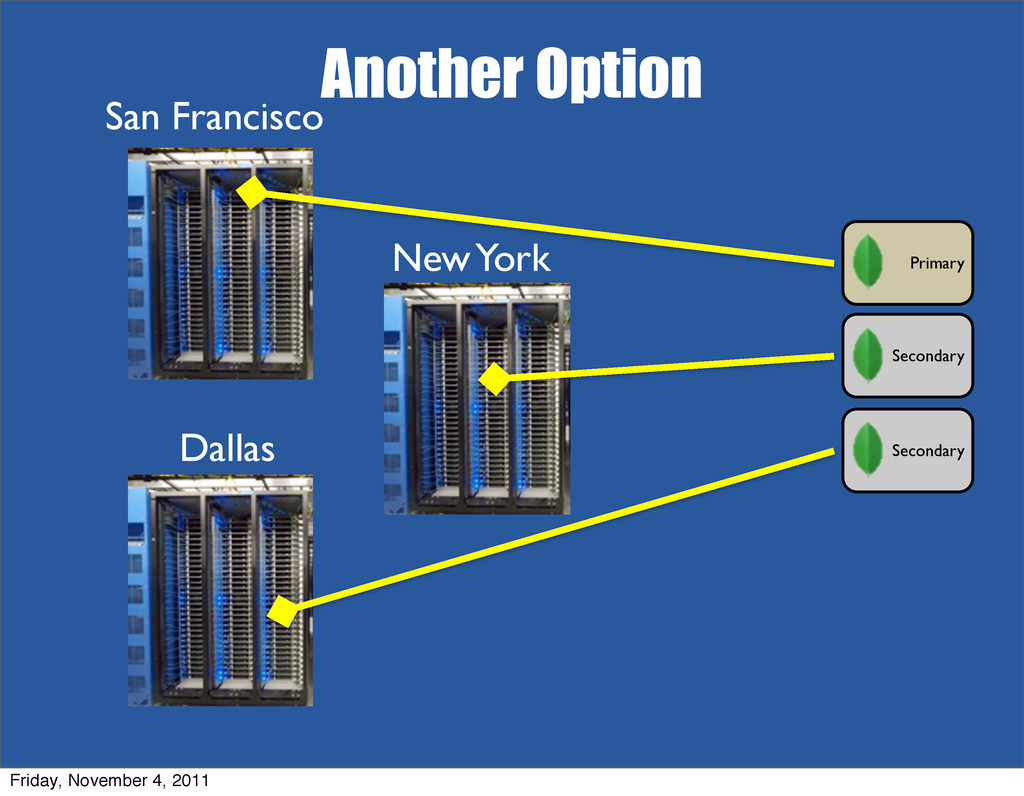{kind=link}
{kind=link}
{kind=link}
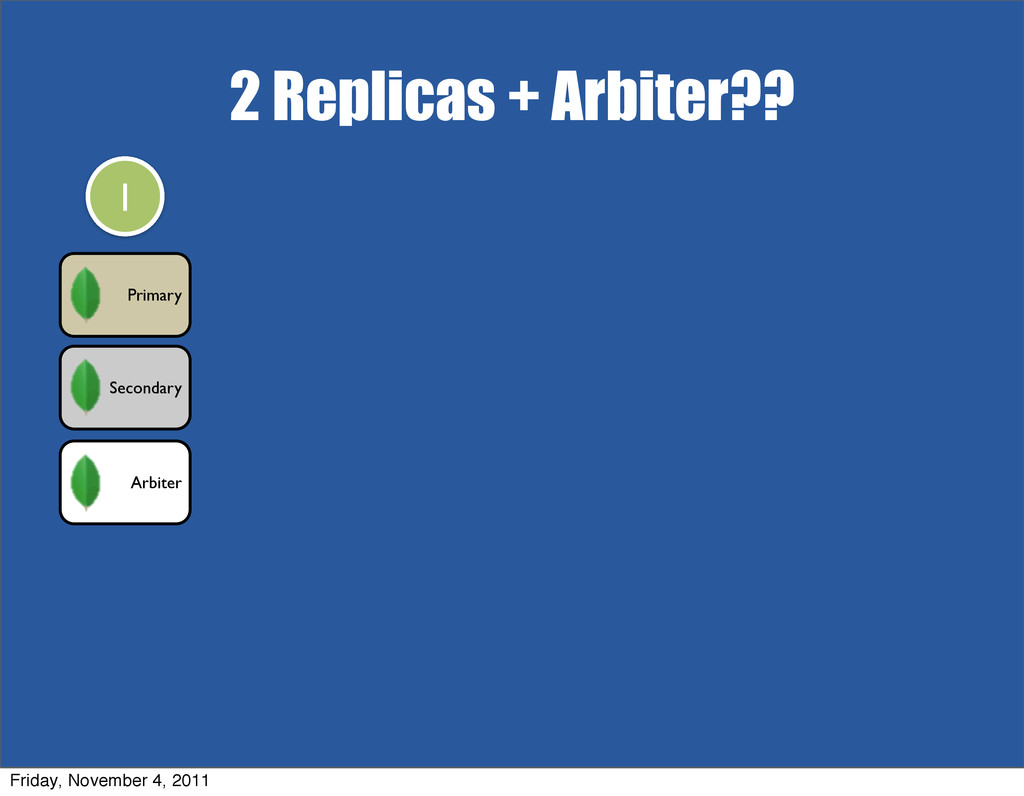{kind=link}
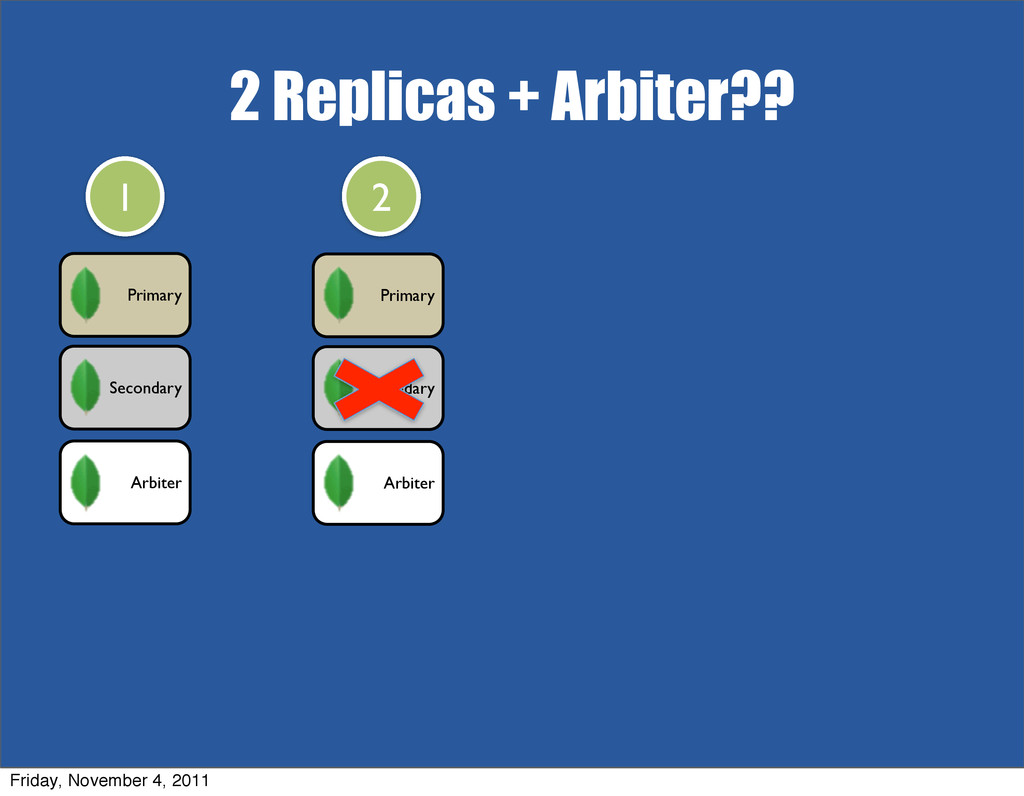{kind=link}
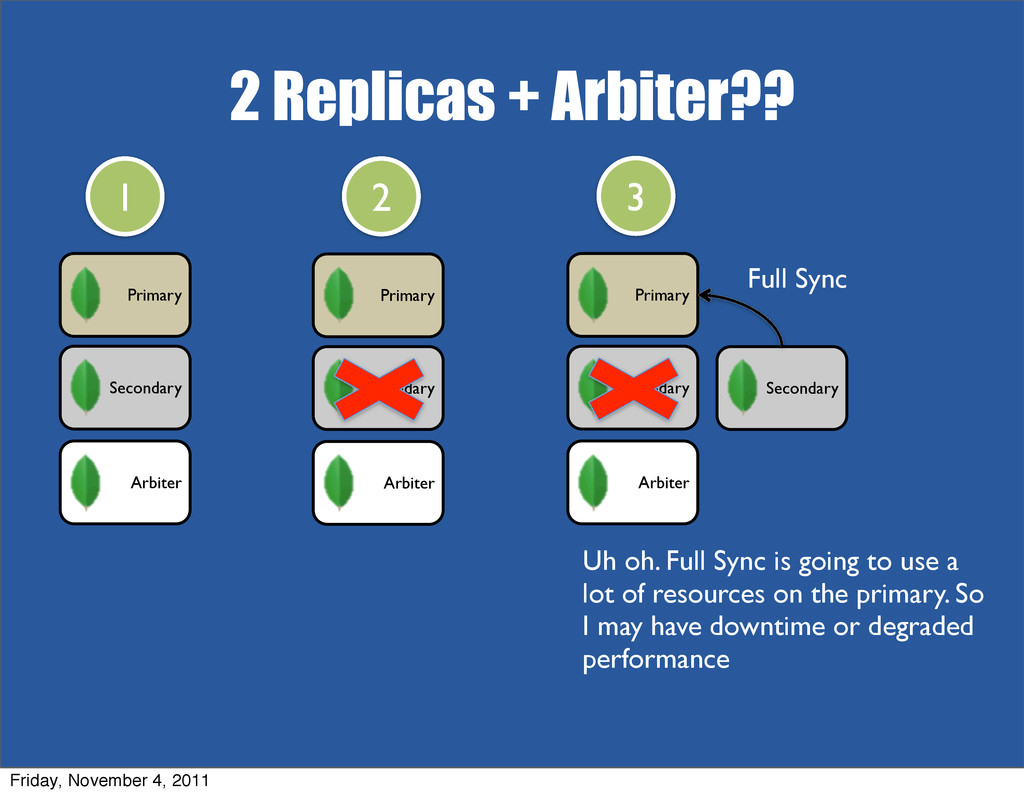{kind=link}
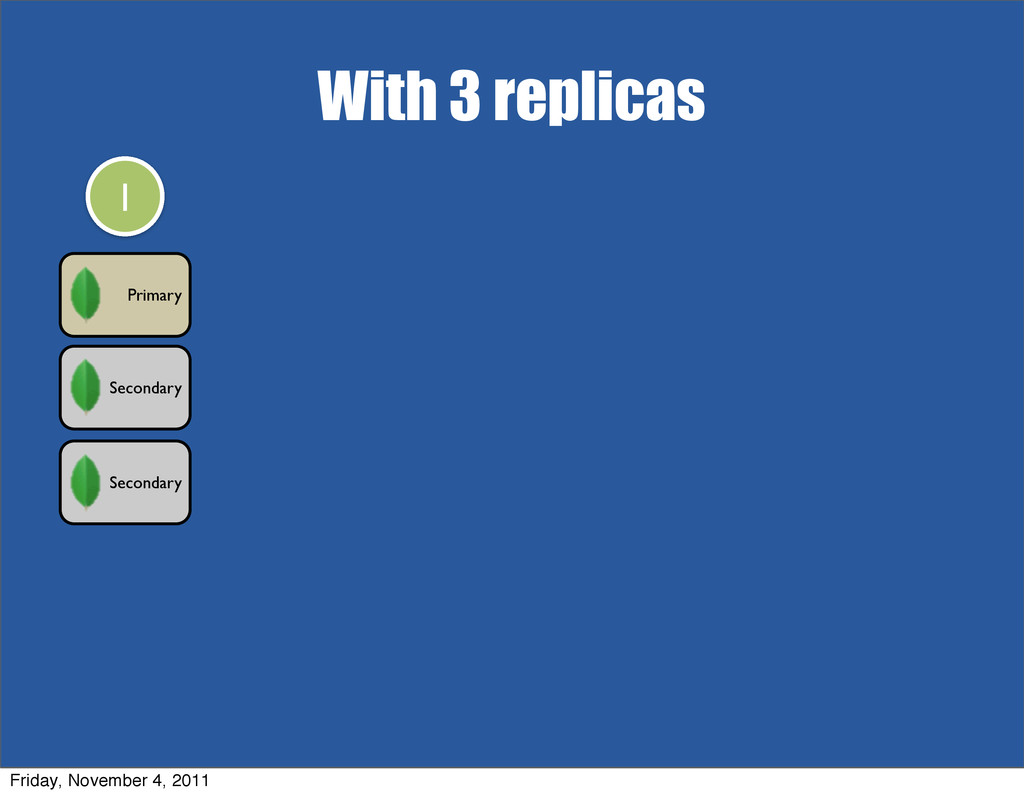{kind=link}
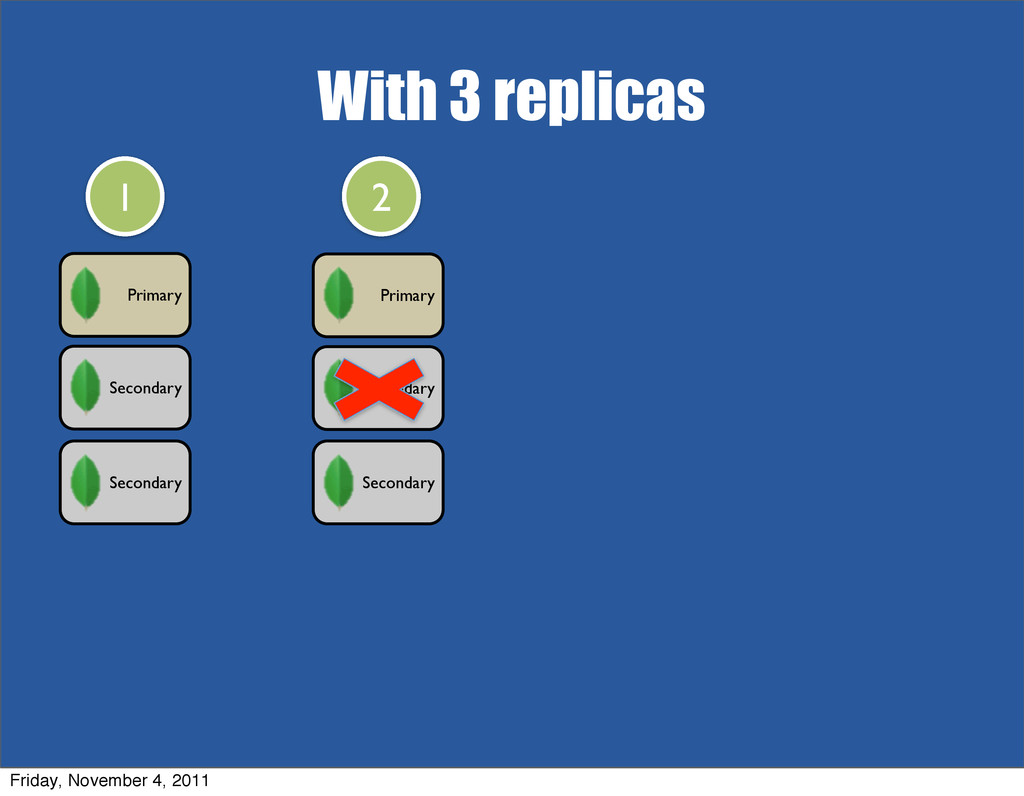{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}