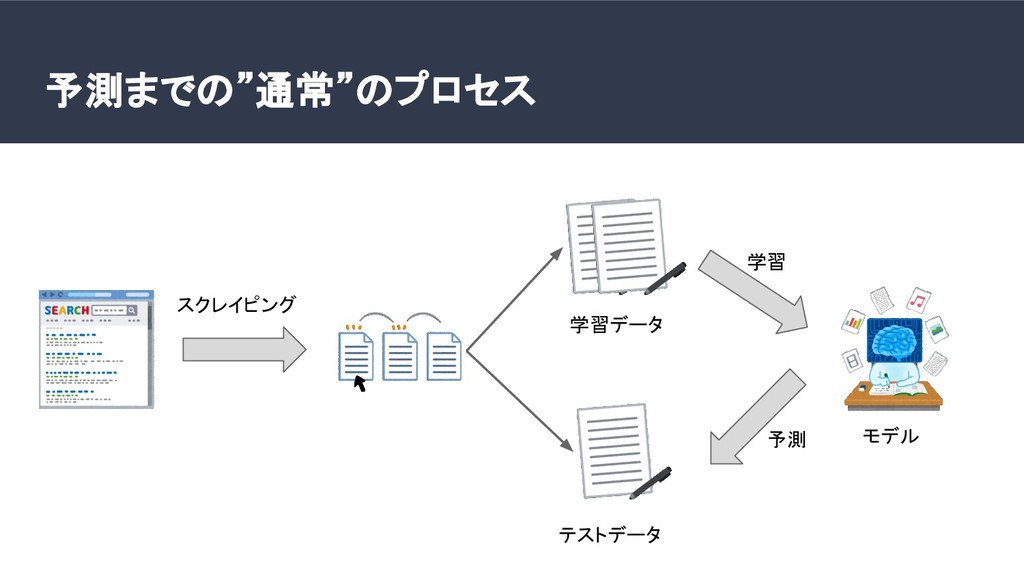
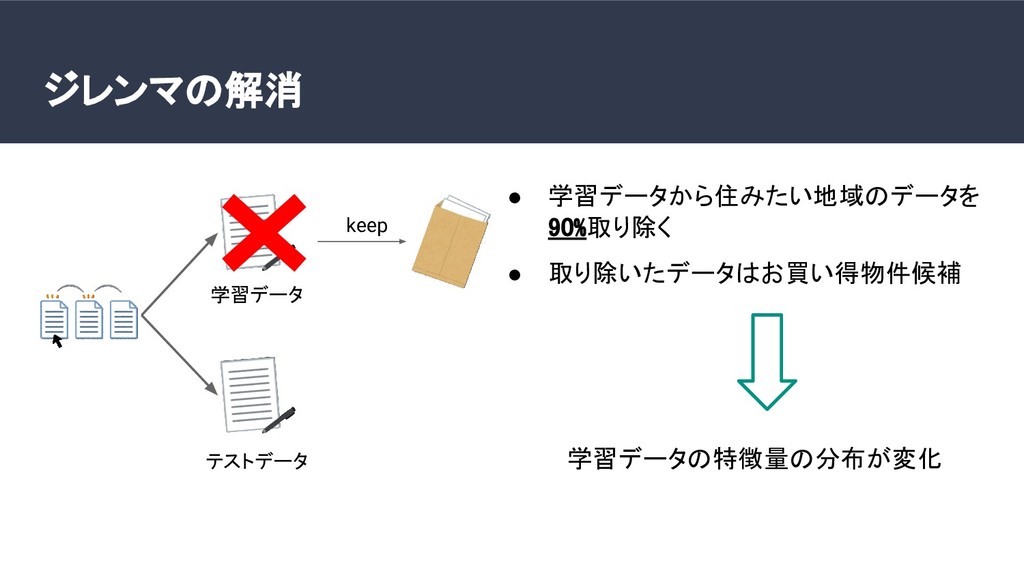
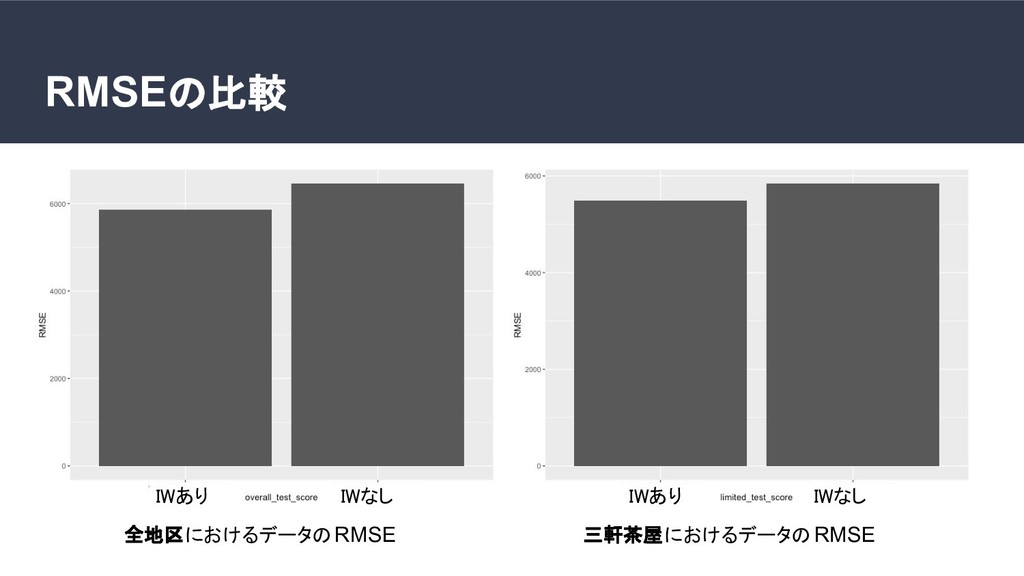
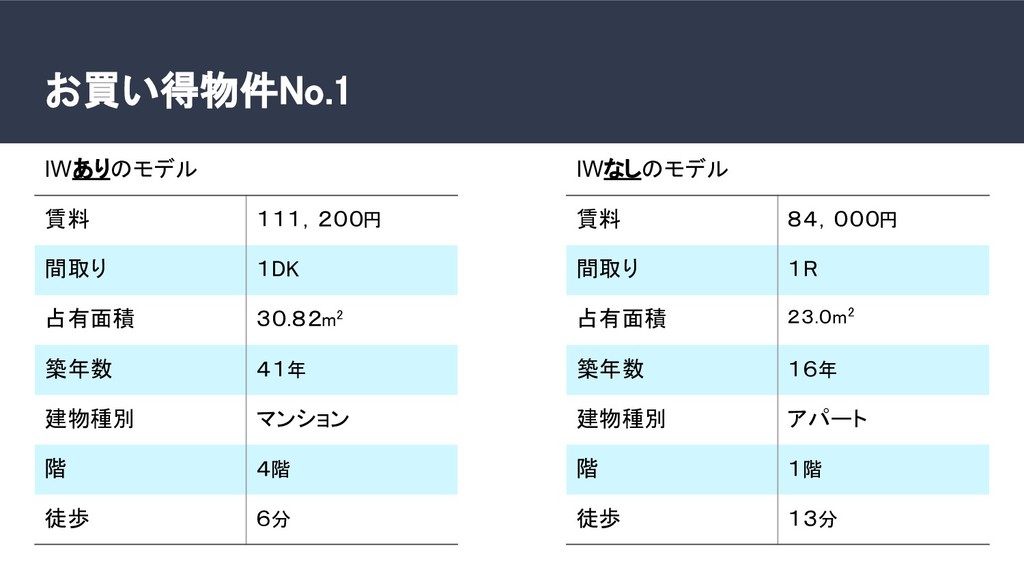
家賃予測を行う機械学習モデルを作り、予測家賃が実際の家賃より高い物件をお買い得と判断する。しかし、学習に使ったデータは学習に使わなかったデータよりもモデルにフィットしているので、予測賃金との誤差は小さい。よって、学習データはお買い得度合いを正確に測ることができない。そうすると、調べられる物件の数が減ってしまう。今回は、お買い得か調べたい地域のデータを学習に少ししか使わなくても、あたかも全てのデータを学習に使ったかのような状況を再現できるCovariate shift corretionを行って、行わなかった場合と制度を比較した。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}