Глеб Ивашкевич (Независимый разработчик) @ Moscow Python Conf 2017
"Tensorflow быстро стал одним из самых популярных фреймворков для глубокого обучения. Но несмотря на свою гибкость и мощь, в нем есть немало плохо документированных, да и просто сложных элементов. Мы разберемся с некоторыми из них: работой на нескольких графических процессорах и распределенным использованием Tensorflow.
Системы с несколькими GPU - распространенная данность и мы рассмотрим несколько вариантов использования таких систем из Tensorflow. Распределенные системы более экзотичны, поэтому мы попробуем понять, когда они действительно нужны и насколько сложно с ними работать. Во всем этом нам поможет Amazon Web Services.
Без сравнения Tensorflow с конкурентами рассказ был бы неполным, поэтому мы немного покритикуем TF (и, возможно, сделаем несколько комплиментов MXNet) и разберемся, почему несмотря на некоторые недостатки Tensorflow остается лидером".
Видео: https://conf.python.ru/raspredelennyj-tensorflow-i-oblaka/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
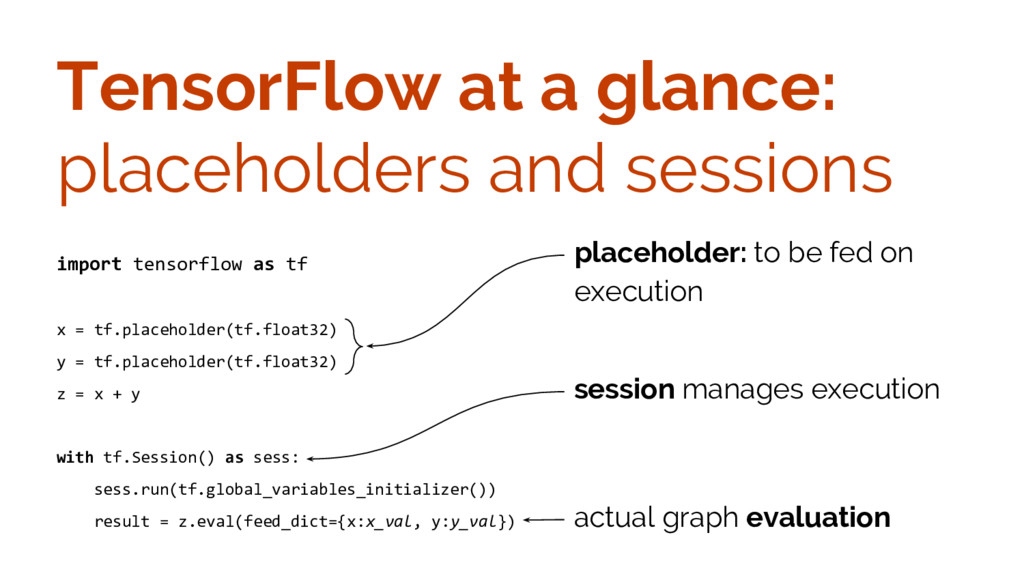{kind=link}
{kind=link}
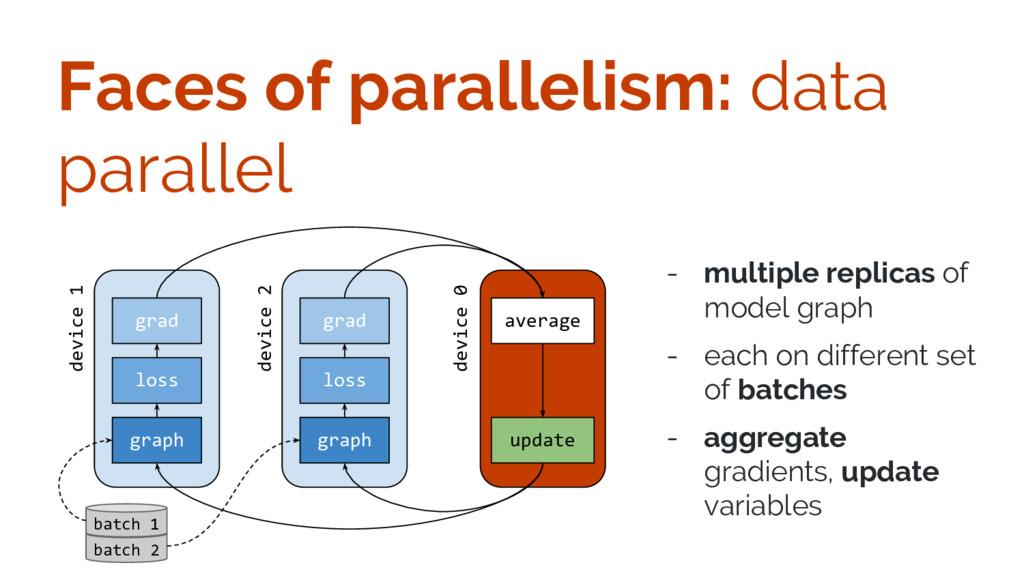{kind=link}
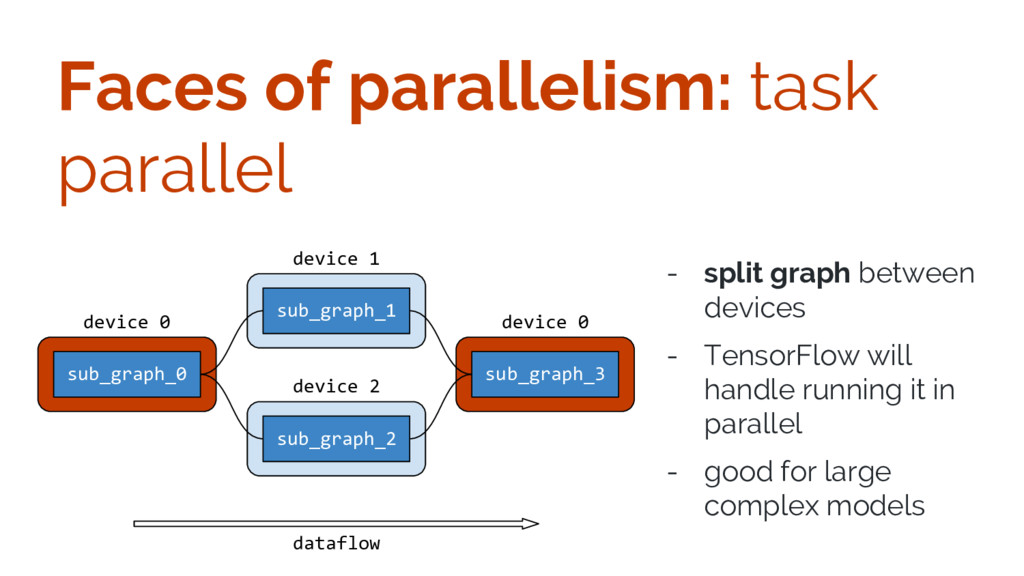{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}