Артем Безукладичный
В докладе рассматриваются основные типы рекомендательных систем, шаги при обработке данных и способы проверки качества получаемых рекомендаций. Более подробно будут представлены алгоритмы коллаборативной фильтрации и результаты их сравнения.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
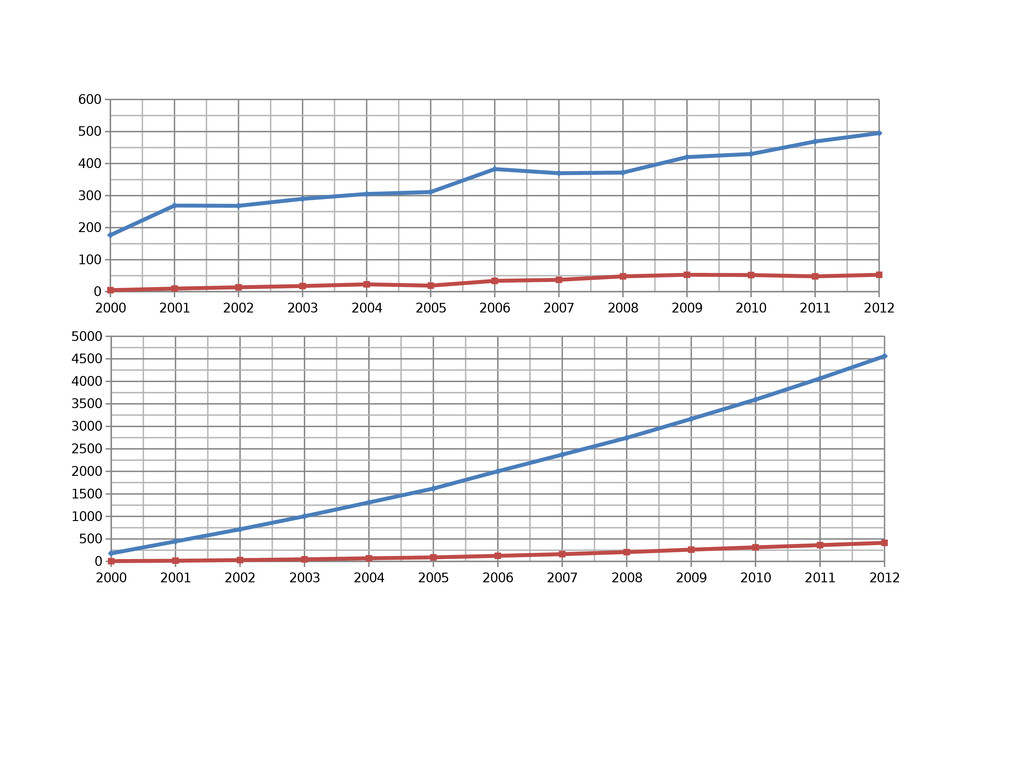{kind=link}
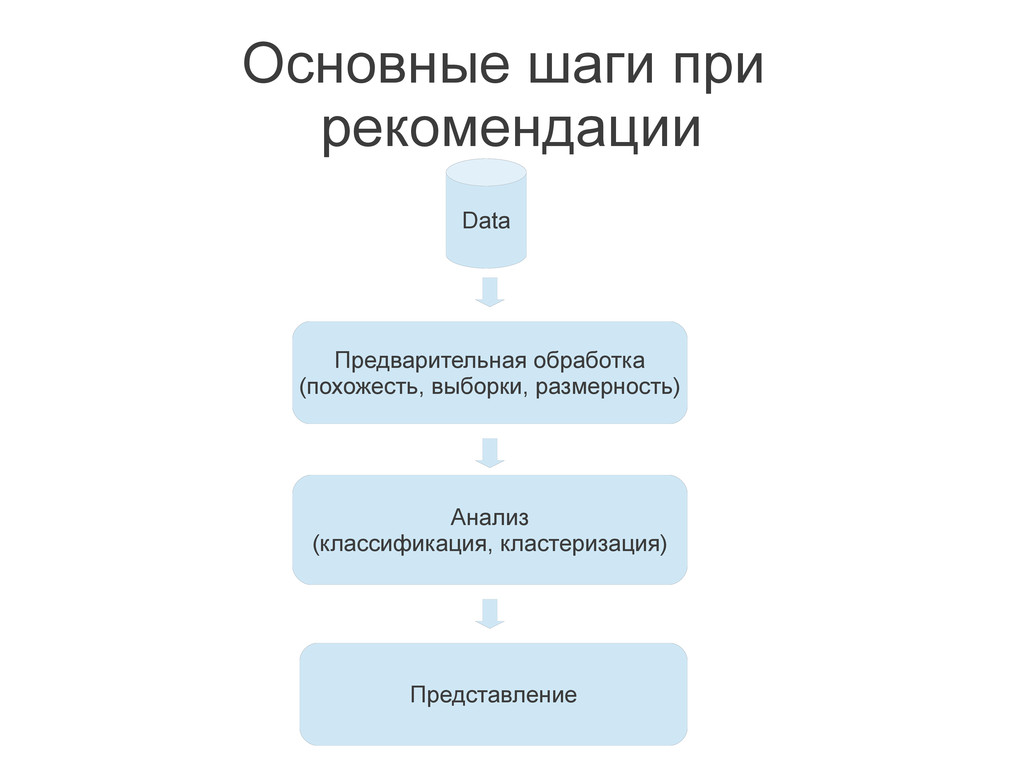{kind=link}
{kind=link}
{kind=link}
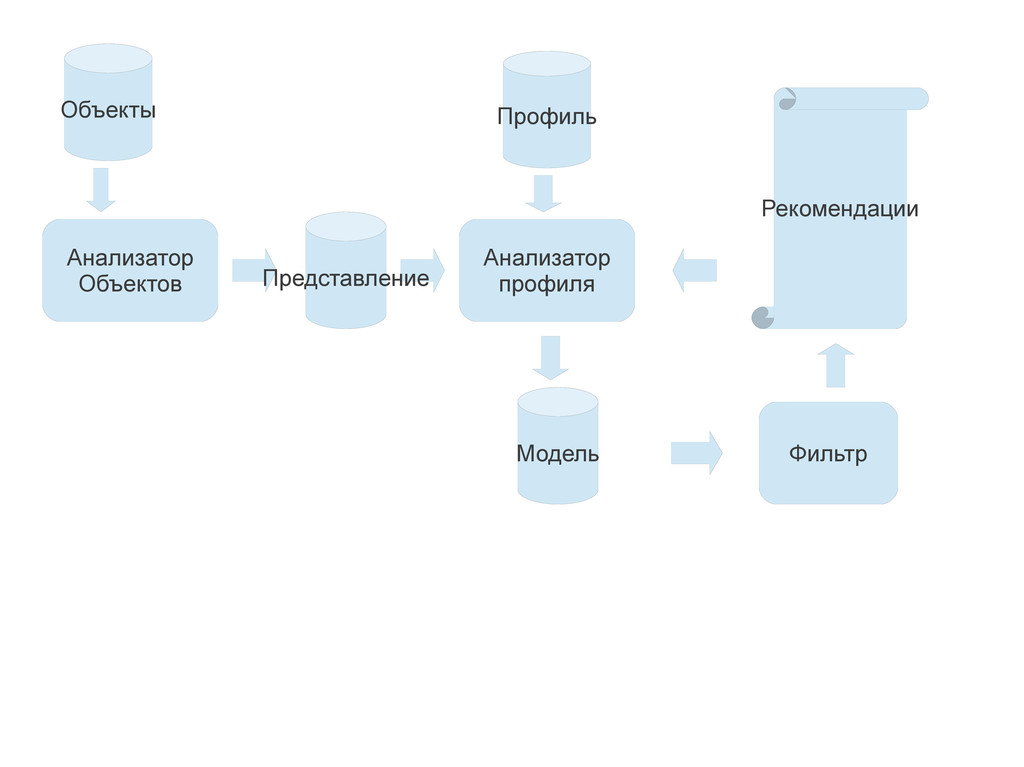{kind=link}
{kind=link}
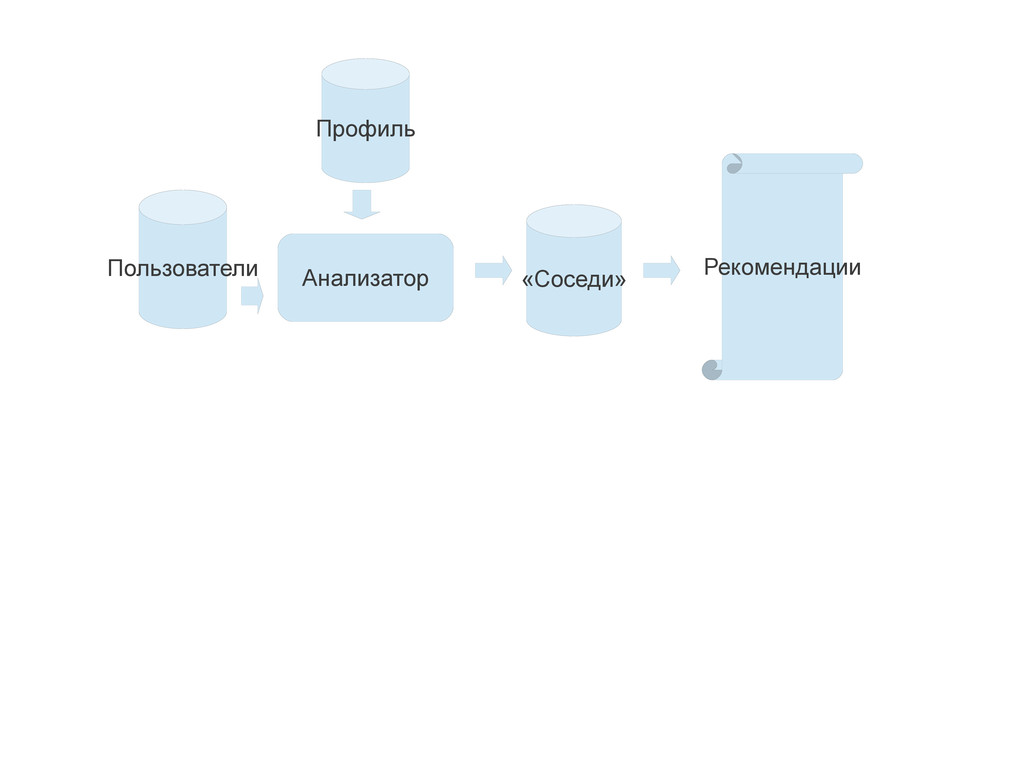{kind=link}
{kind=link}
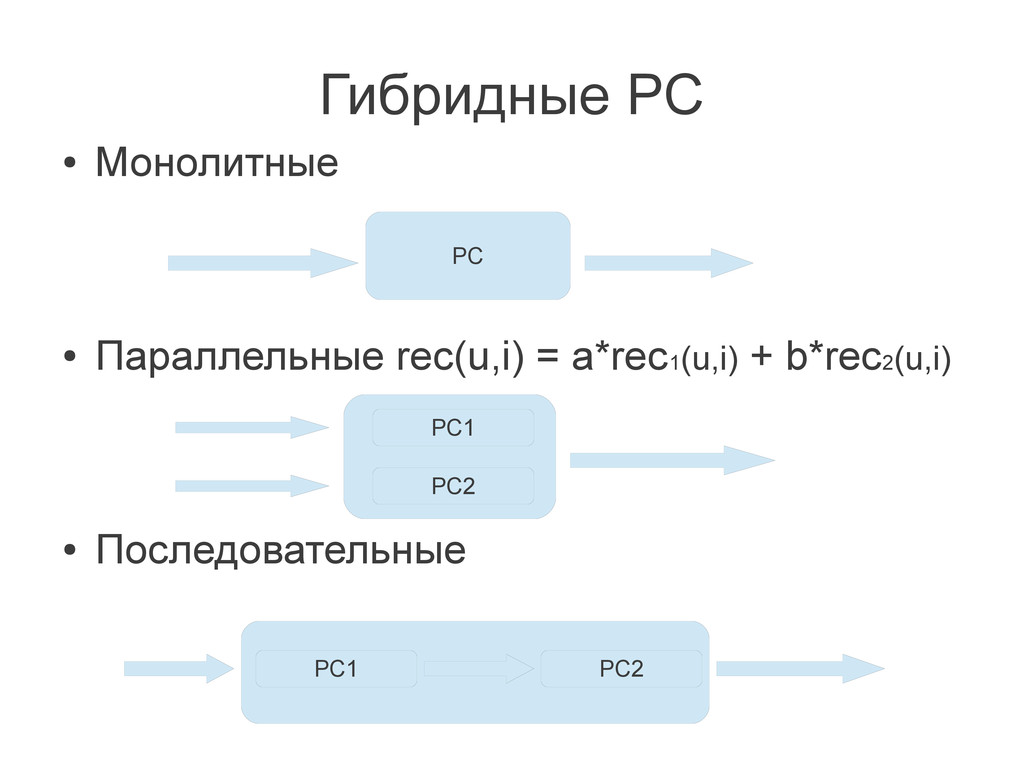{kind=link}
{kind=link}
{kind=link}
{kind=link}
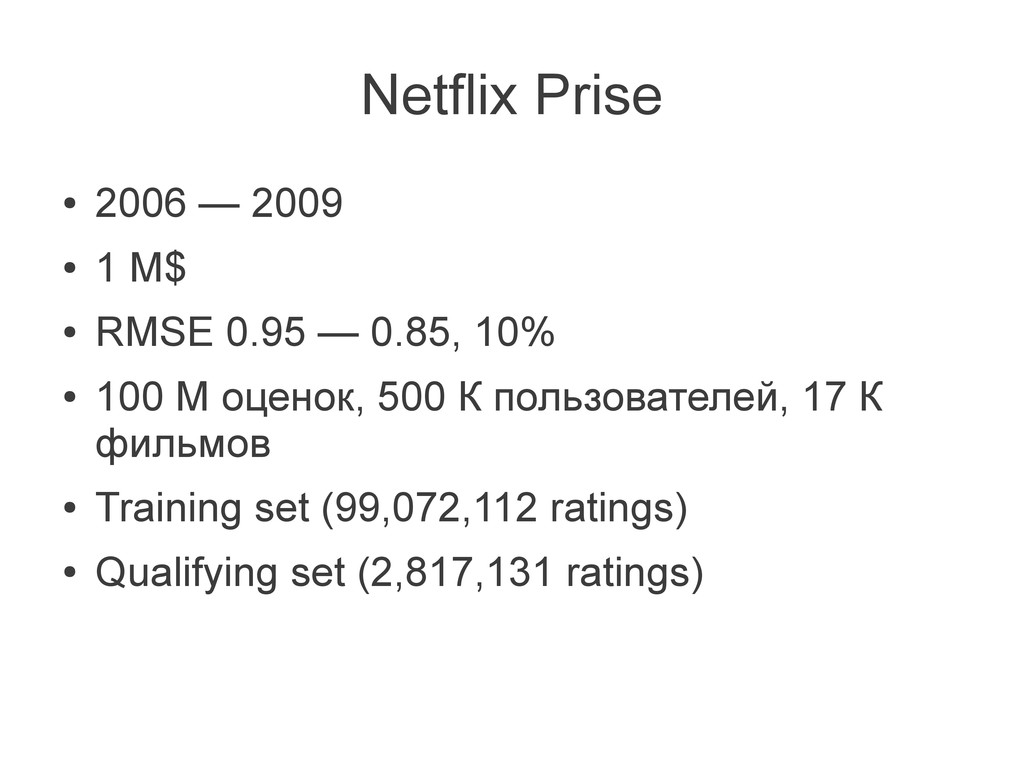{kind=link}
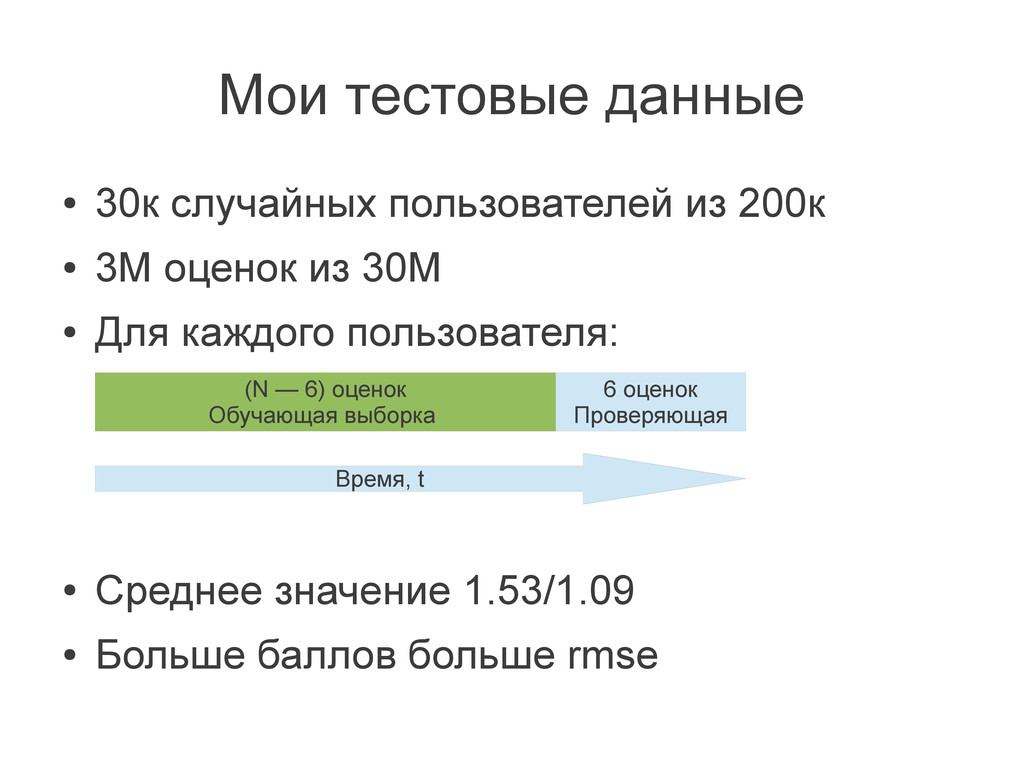{kind=link}
{kind=link}
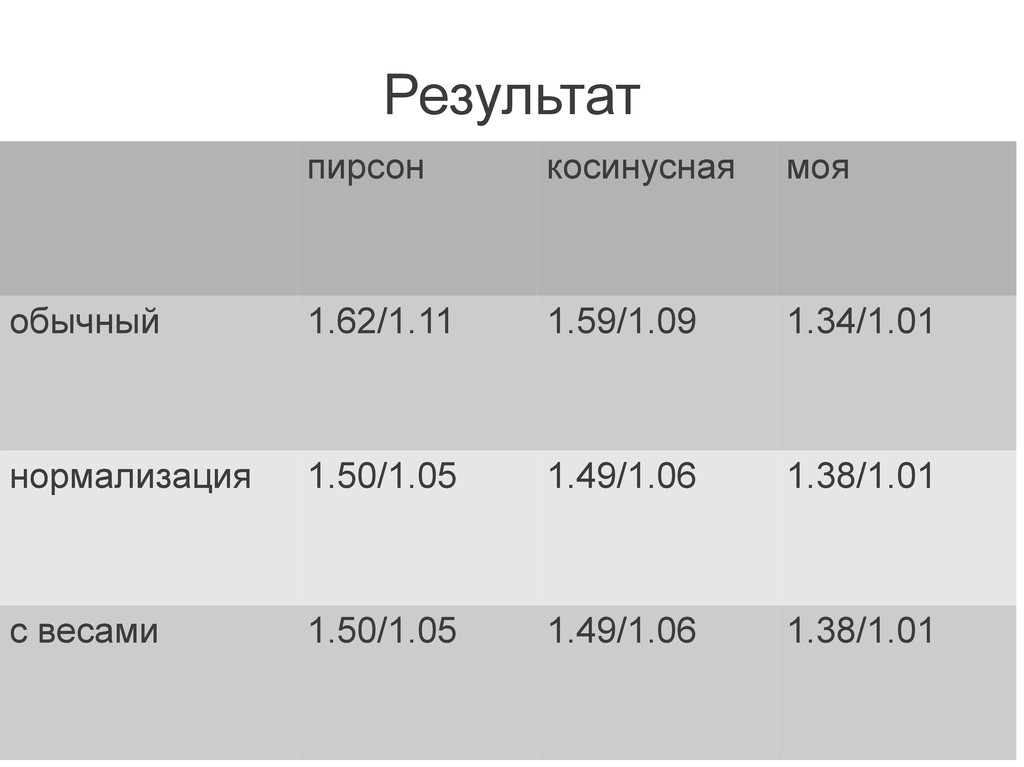{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}