Understand how we can use CompilerGym for RL in compiler optimization Run a basic script to use RL to optimize instruction code size. RL Tutorial https://compilergym.ai
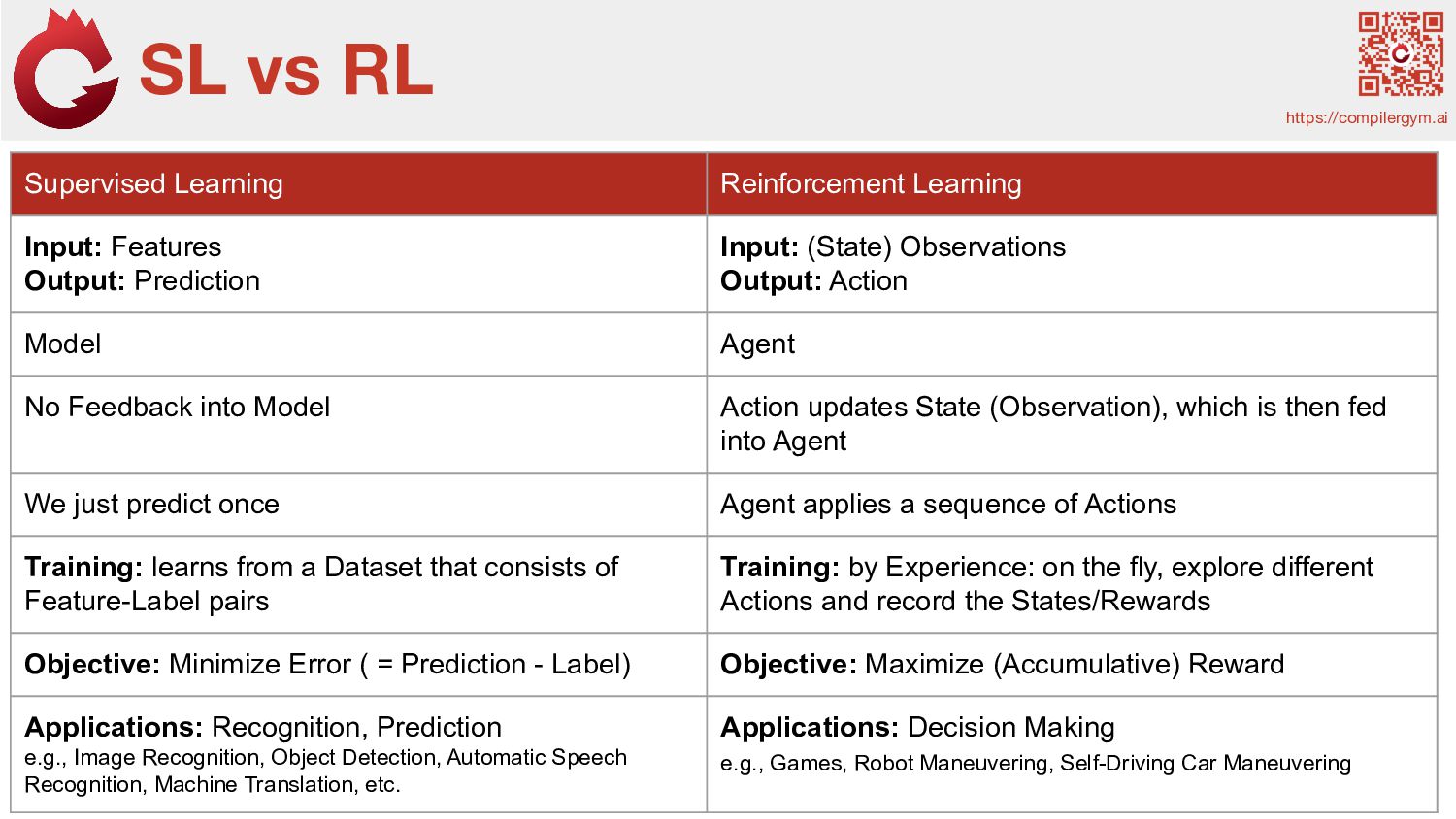
Output: Prediction Input: (State) Observations Output: Action Model Agent No Feedback into Model Action updates State (Observation), which is then fed into ِAgent We just predict once Agent applies a sequence of Actions Training: learns from a Dataset that consists of Feature-Label pairs Training: by Experience: on the fly, explore different Actions and record the States/Rewards Objective: Minimize Error ( = Prediction - Label) Objective: Maximize (Accumulative) Reward Applications: Recognition, Prediction e.g., Image Recognition, Object Detection, Automatic Speech Recognition, Machine Translation, etc. Applications: Decision Making e.g., Games, Robot Maneuvering, Self-Driving Car Maneuvering
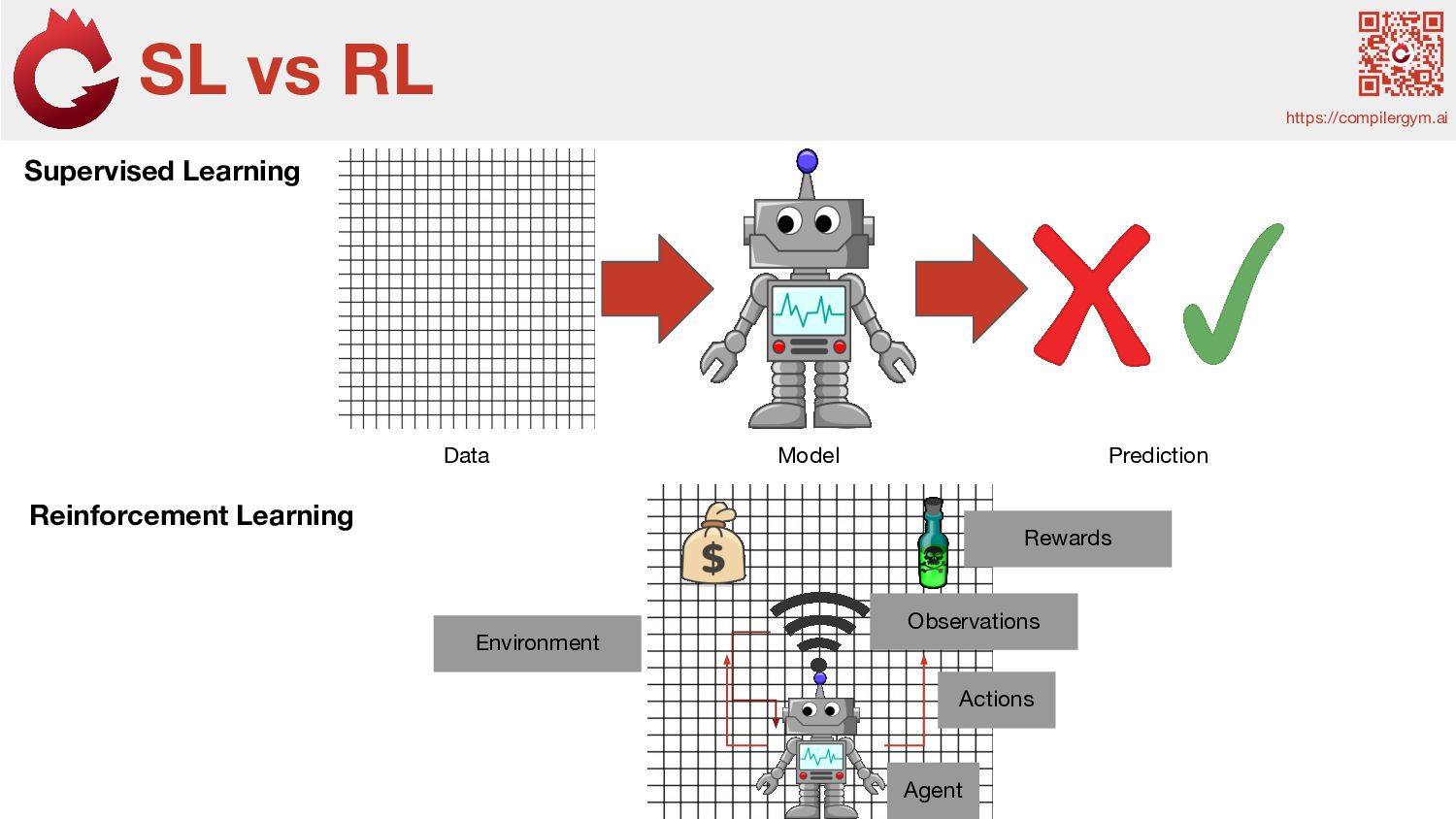
interacts with the Environment. - Environment: Everything which isn’t the Agent; everything the Agent can interact with, either directly or indirectly. - Action: the Agent’s method which allow it to interact and change its Environment - Reward: A numerical value received by the Agent from the Environment as a direct response to the Agent’s actions. - State: Every scenario the Agent encounters in the Environment is formally called a state. We identify the state by measuring Observations. RL Terminology https://compilergym.ai
and a terminal-state. - Policy: The decision of which action to choose given a State. - Value Function, (a.k.a. State-Value Function): the total reward over all steps in an episode - Action-Value Function, (a.k.a. Q-Value): same as Value Function, but starting from a specific step till the end of the episode. RL Terminology https://compilergym.ai
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}