"number" : "2.3.1", "build_hash" : "bd980929010aef404e7 "build_timestamp" : "2016-04-04T12: "build_snapshot" : false, "lucene_version" : "5.5.0" }, "tagline" : "You Know, for Search" } You Know, for Search Download it Extract it Run Elasticsearch Enjoy it
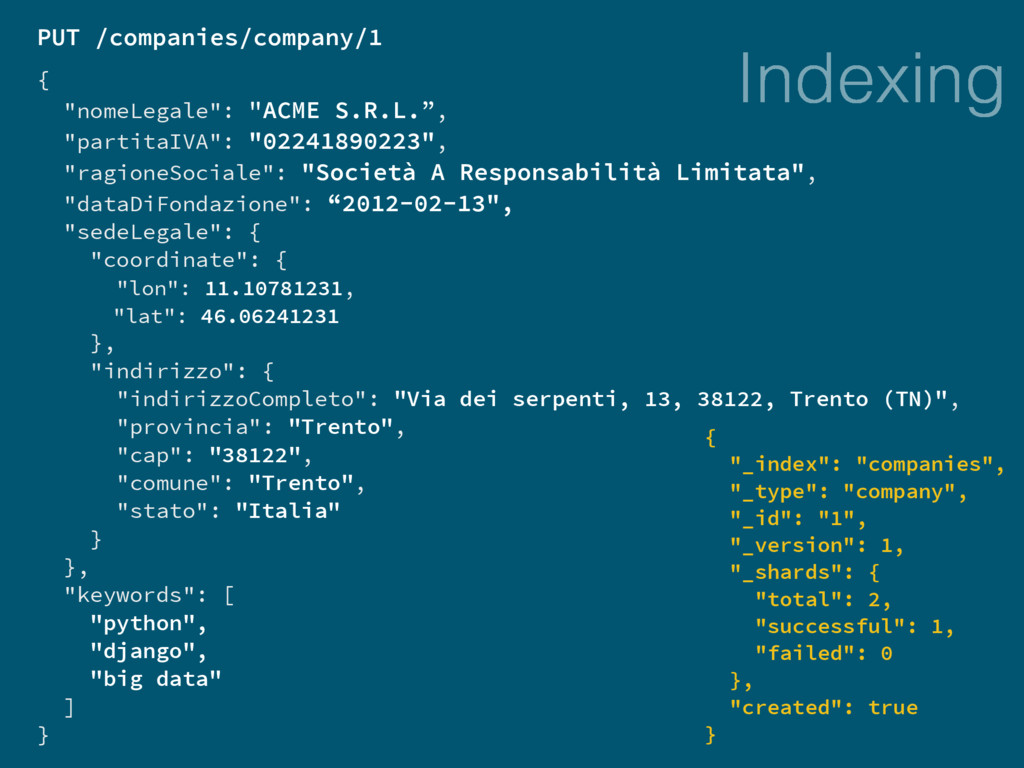
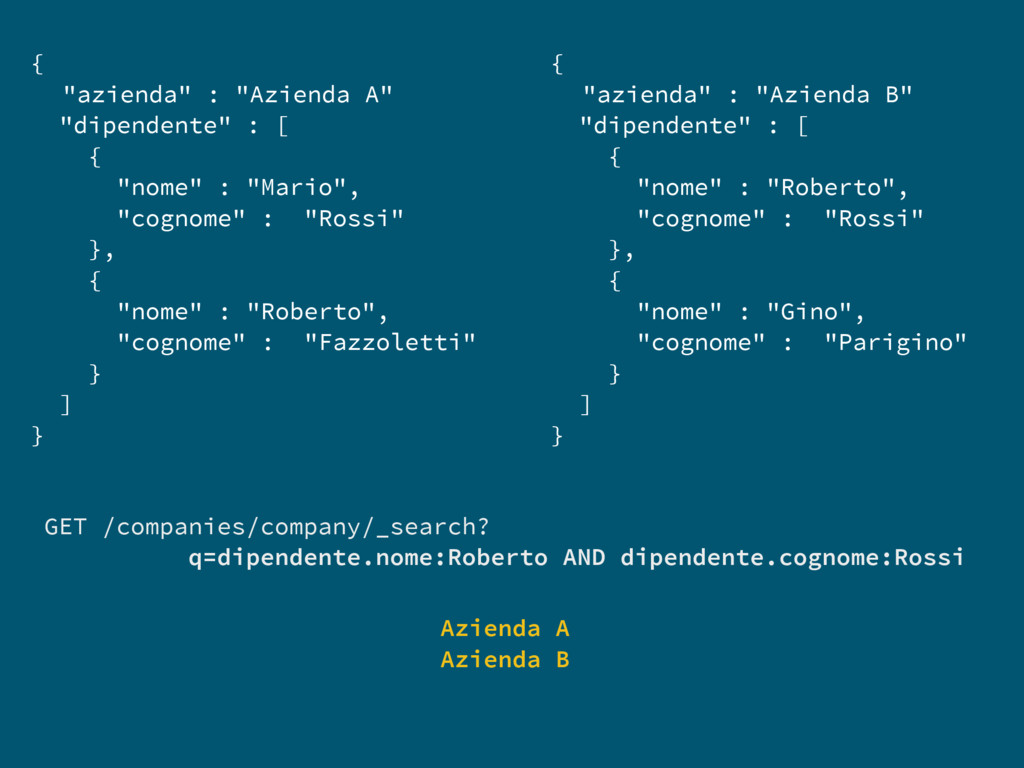
Query GET /companies/company/_search { "query": { "multi_match": { "query": "Super azienda", "fields": ["nomeLegale^3", "insegne"] } } } GET /companies/company/_search?q=descrizione:bar* bar | baretto | barbaforte GET /companies/company/_search?q=descrizione:bur~ bar | bur GET /companies/company/_search?q=descrizione:"bar rossi"~1 bar dei rossi | bar mario rossi | bar gino rossi
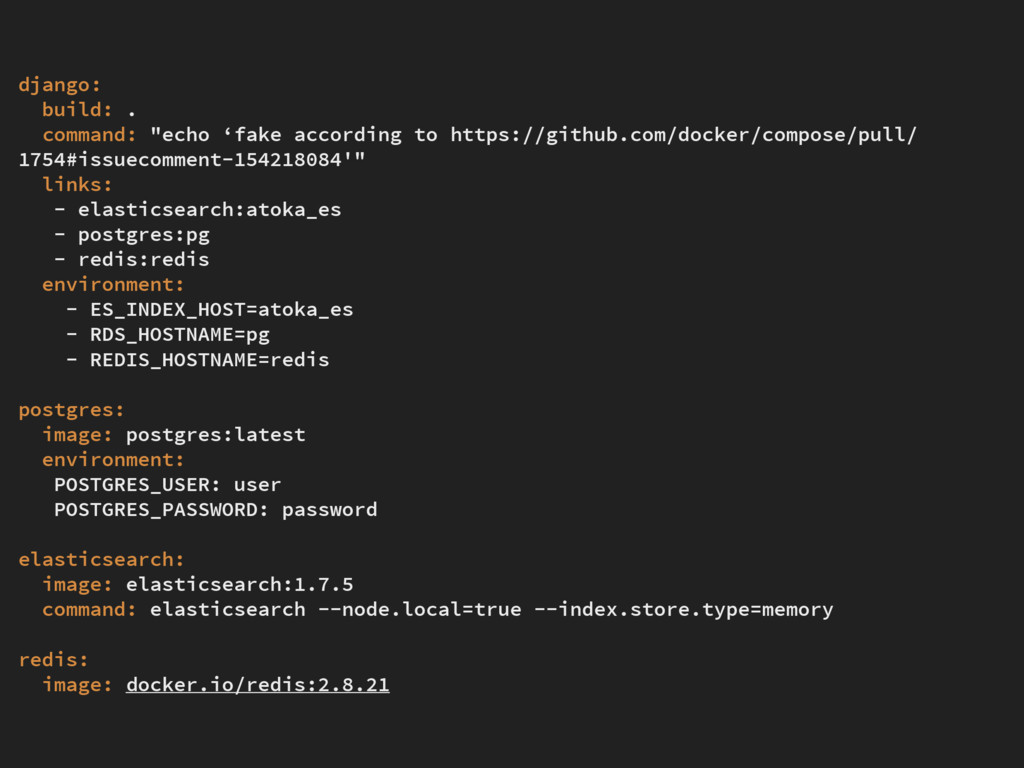
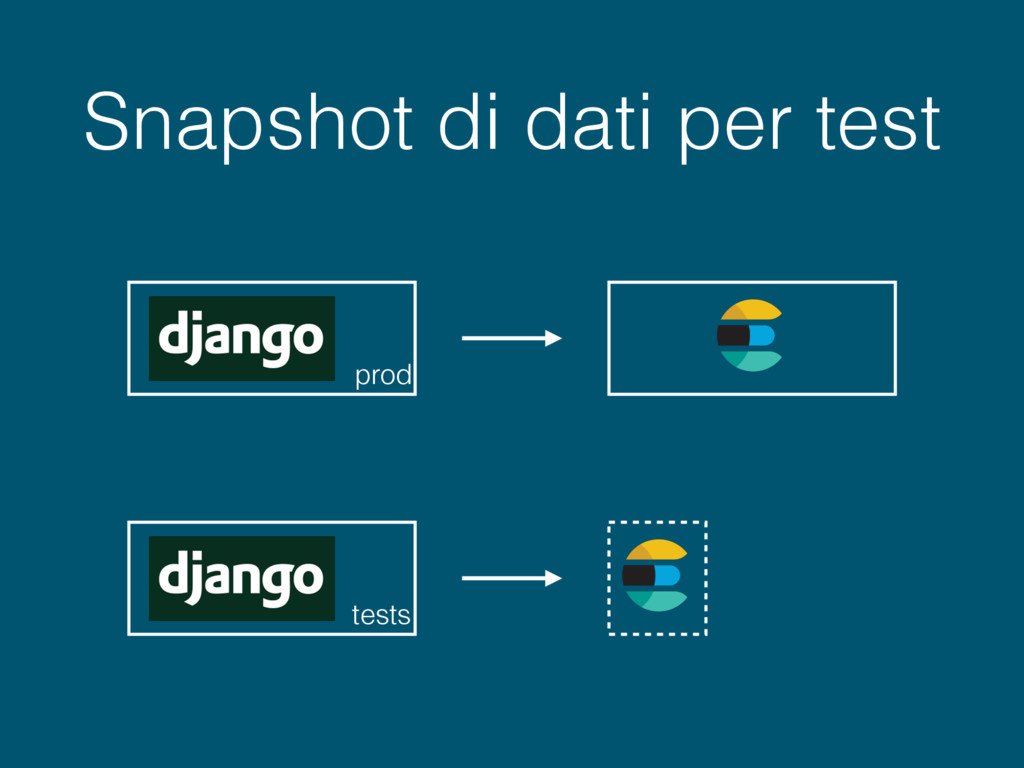
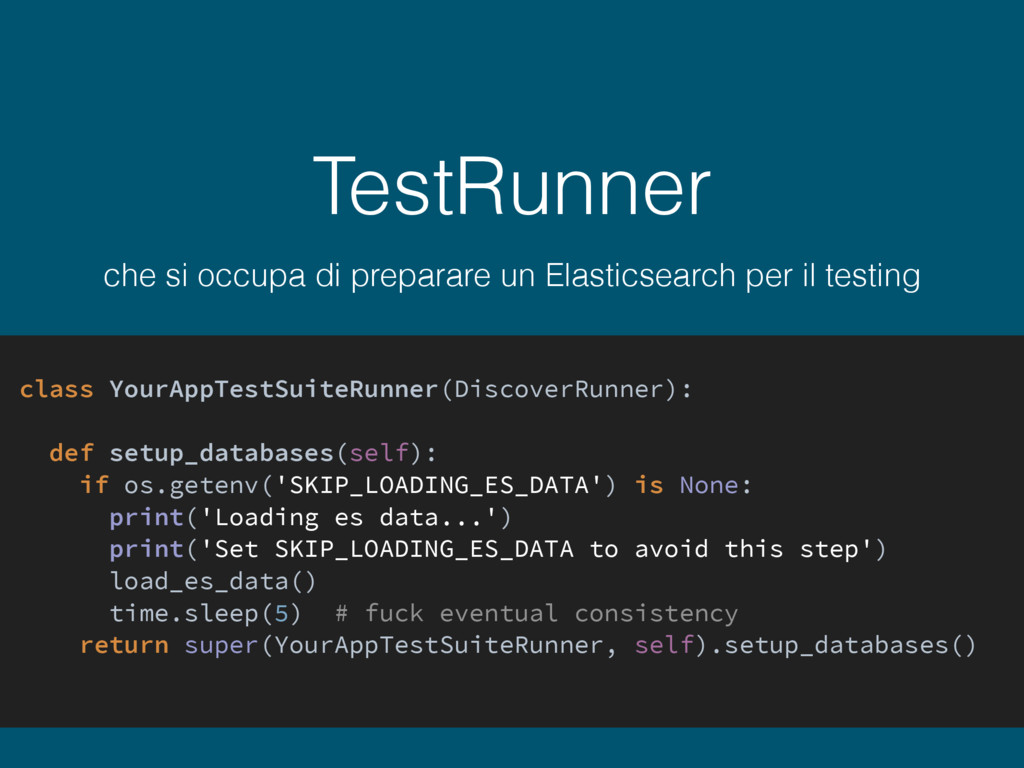
testing class YourAppTestSuiteRunner(DiscoverRunner): def setup_databases(self): if os.getenv('SKIP_LOADING_ES_DATA') is None: print('Loading es data...') print('Set SKIP_LOADING_ES_DATA to avoid this step') load_es_data() time.sleep(5) # fuck eventual consistency return super(YourAppTestSuiteRunner, self).setup_databases()
sarà il vostro peggior incubo https://es:9200/_cat/fielddata?v --ES_HEAP_SIZE ~ RAM/2 (max 32GB) evitare un numero eccessivo di shard https://www.elastic.co/blog/a-heap-of-trouble
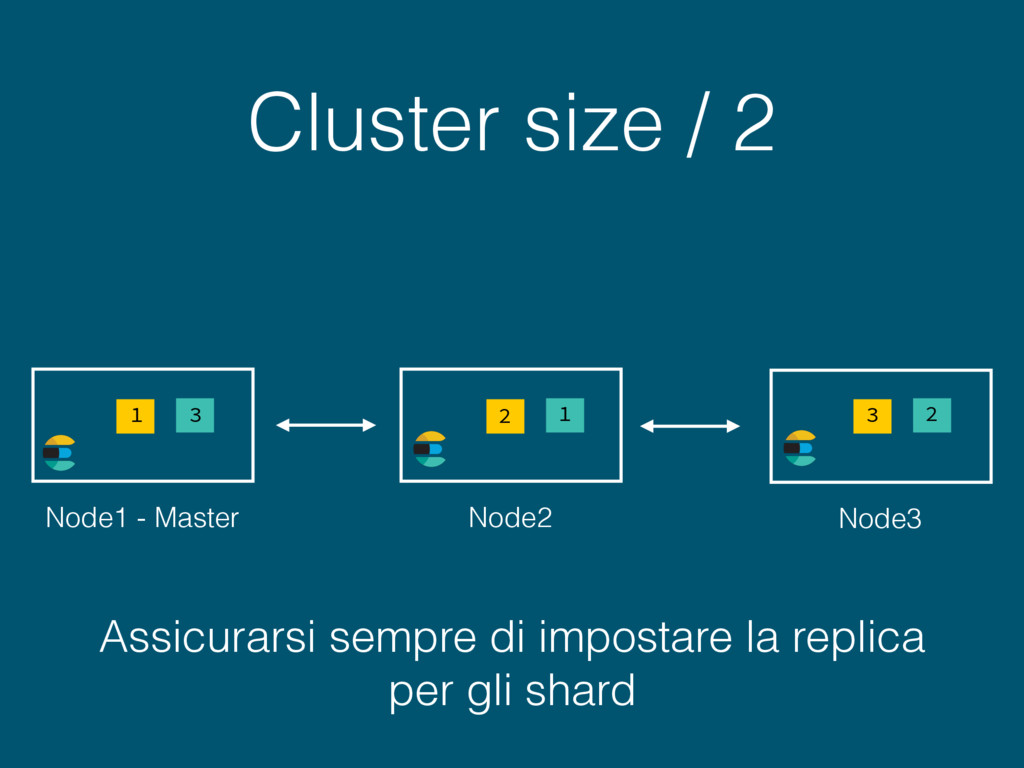
ottimale ottimizzare il throttling indexing ricordarsi di disabilitare le repliche https://www.elastic.co/guide/en/elasticsearch/guide/current/indexing- performance.html
shard allocation 3. Spegnere un nodo 4. Fare le operazioni di maintenance etc etc 5. Riavviare il nodo e verificare che sia nel cluster 6. Abilitare la shard allocation 7. Ripetere per ogni nodo PUT /_cluster/settings { "transient" : { "cluster.routing.allocation.enable":"none" } } PUT /_cluster/settings { "transient" : { "cluster.routing.allocation.enable":"all" } }
{kind=link}
{kind=link}
![2012 2013 2015 pss: we’re hiring [email protected]](https://files.speakerdeck.com/presentations/f995dc0d65274238bafbb2205ca96d2e/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
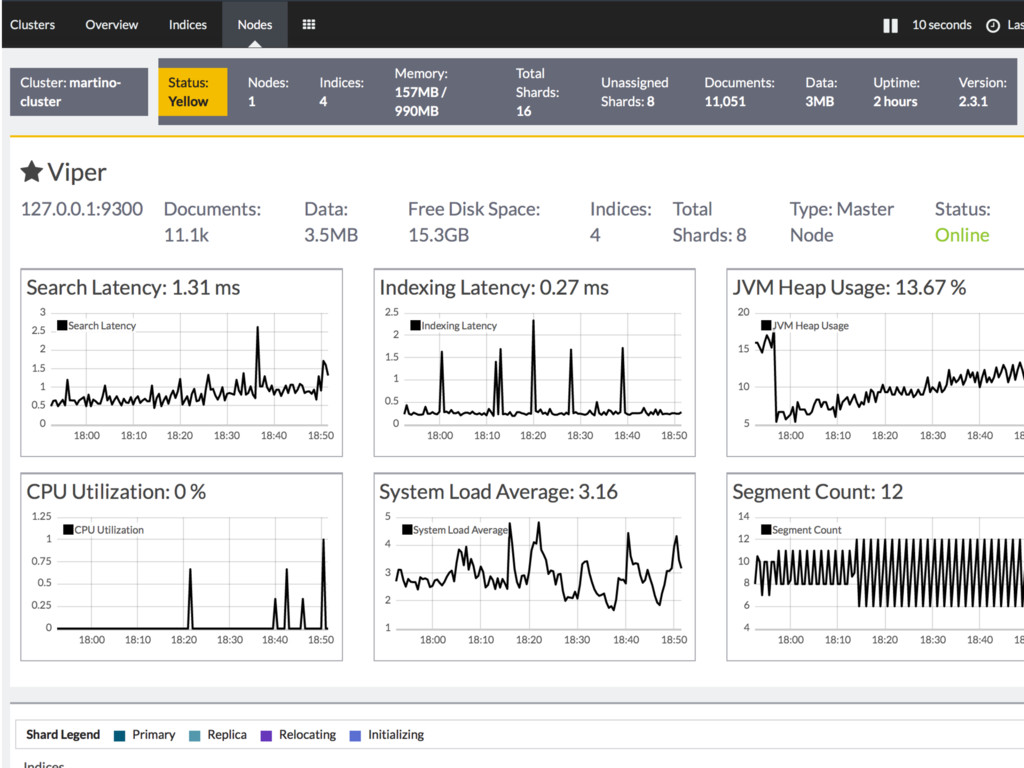{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}