Ruby, Java, mongodb, elastic search automatyczne przygotowanie tekstu do tłumaczeń DDD, software that matters, agile dzielenie się wiedzą: Rzeszów Ruby User Group ( ) Politechnika Rzeszowska rrug.pl
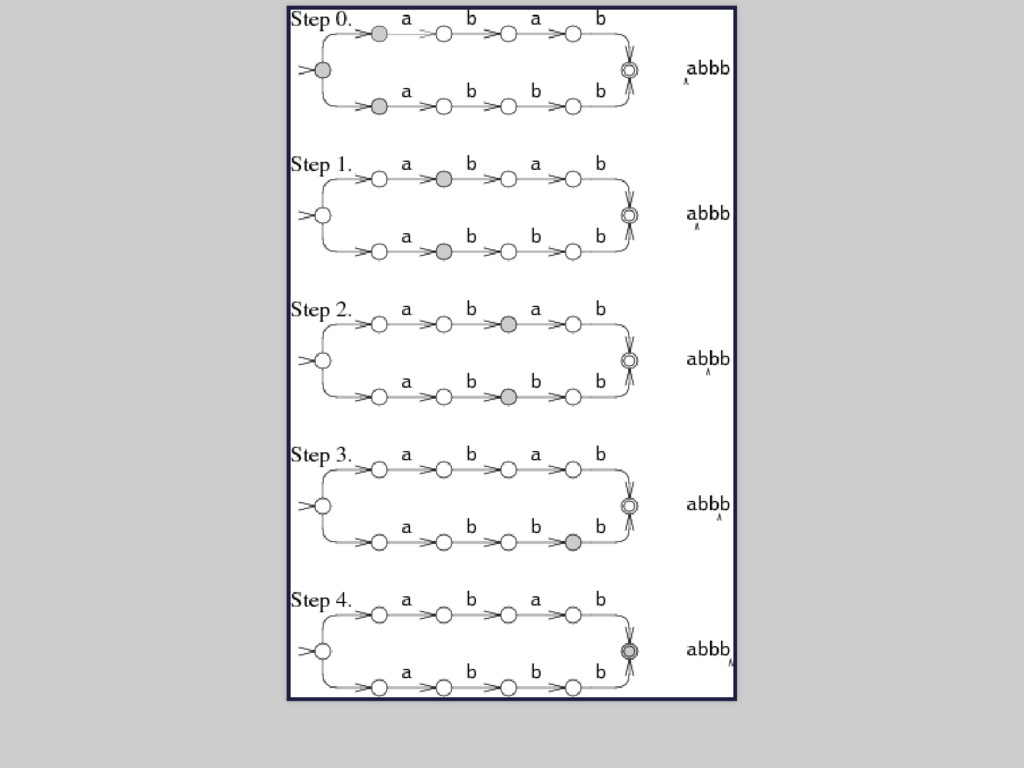
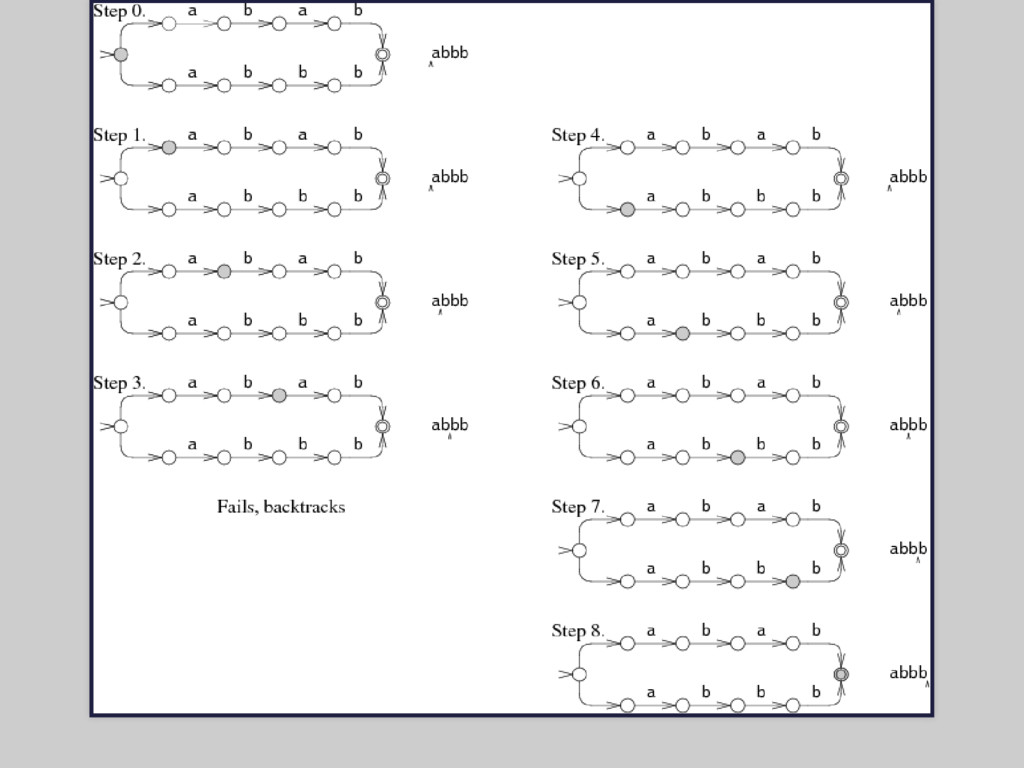
directed Thompson 1968 grep, awk, sed 400 linii w C 2. Regex-directed Larry Wall, perl, 1987 Perl-Compatible Regular Expressions (java, ruby, .Net,...)
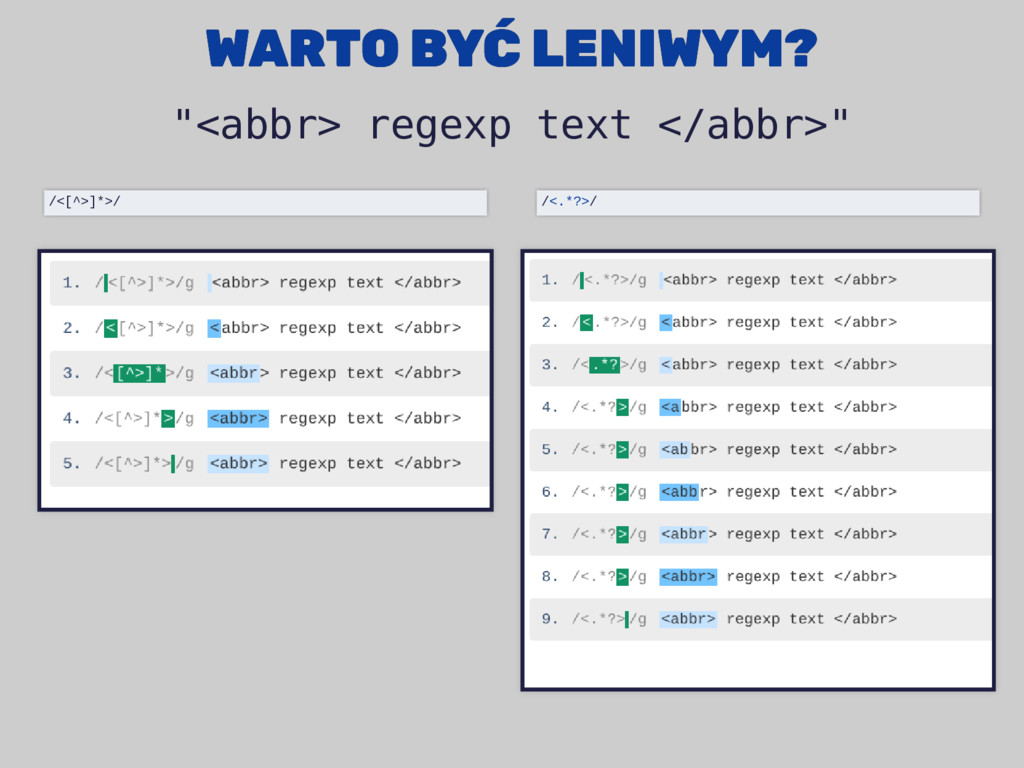
regexp text " => "<br/>" # so far so good /<.*>/=~"<abbr> regexp text </abbr>" => "<abbr> regexp text </abbr>" #hmmm... /<[^>]*>/=~"<abbr> regexp text </abbr>" => "<abbr>" # great! /<.*?>/=~"<abbr> regexp text </abbr>" => "<abbr>" # great!
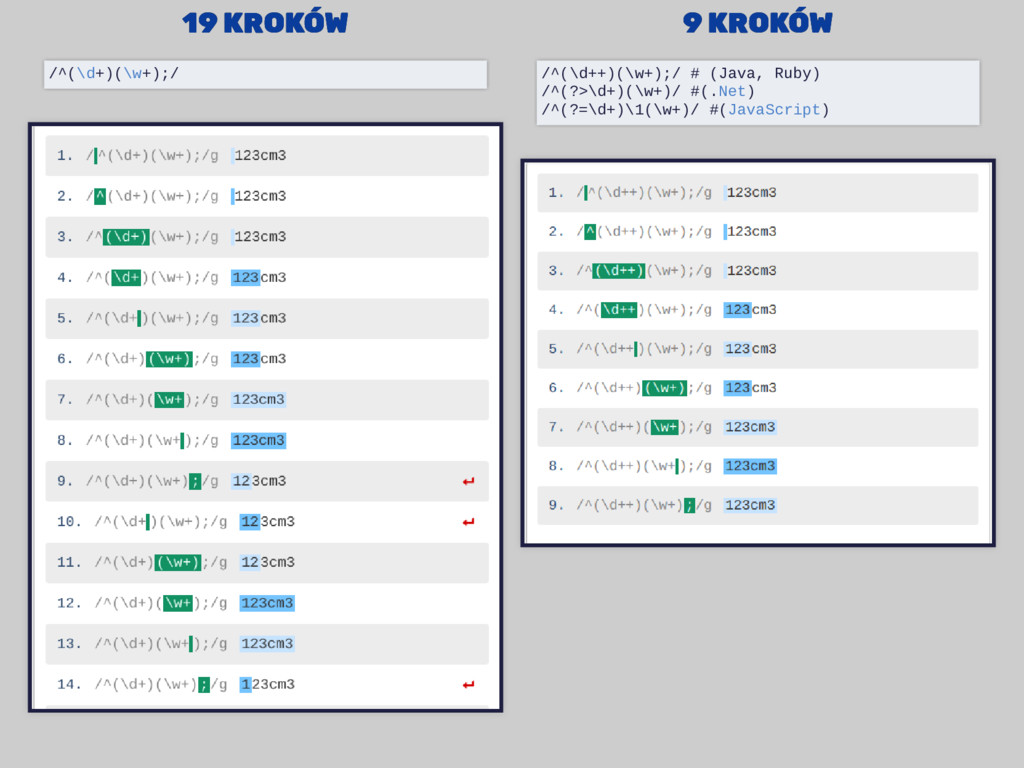
być prostszego? # liczba # 1, 3243, 4323 /\d+\s/ # liczba z częścią dziesiętną i minusem # -1, 1, 32.32, -2.2324 /-?(\d+\(\.\d+)?\s/ # liczba z częścią dziesiętną (kropka albo przecinek) # -23,23 4323.23 /-?(\d+\([.,]\d+)?\s)/
z częścią dziesiętną i separatorami tysięcy # -21,321,321.1111 433.233,12 /(-?(\d+[,.]?)+)\s/ # j.w., lazy /(-?((\d+?[,.])+?)\s/ # j.w., possesive /(-?((\d++[,.])++)\s/
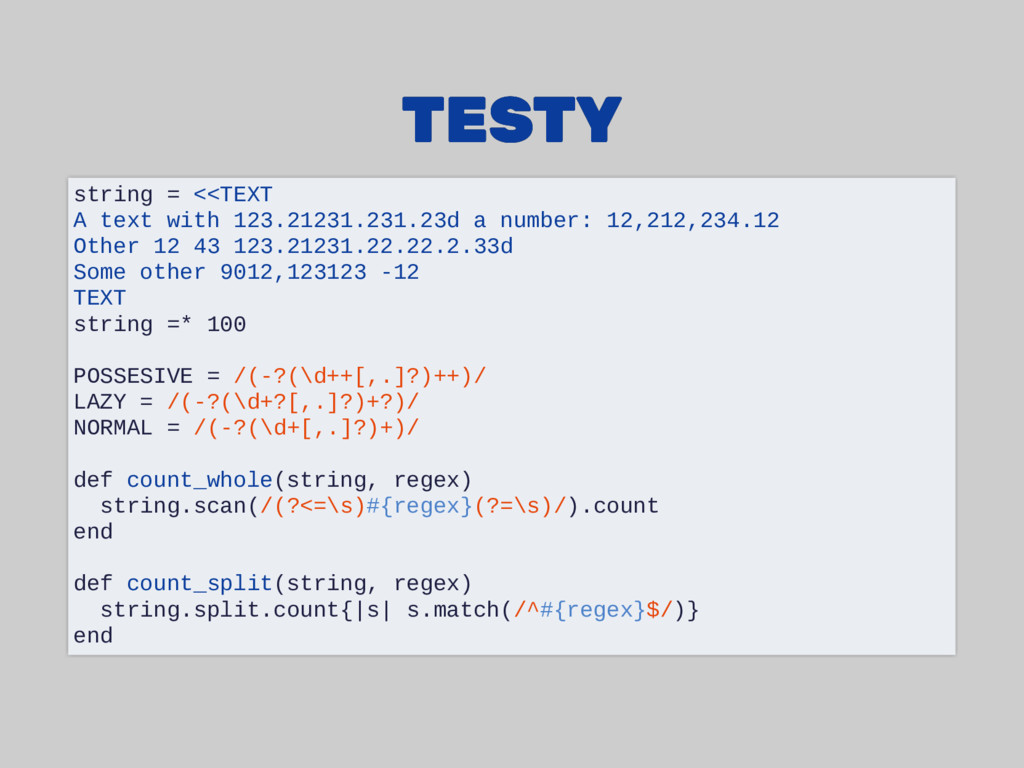
number: 12,212,234.12 Other 12 43 123.21231.22.22.2.33d Some other 9012,123123 -12 TEXT string =* 100 POSSESIVE = /(-?(\d++[,.]?)++)/ LAZY = /(-?(\d+?[,.]?)+?)/ NORMAL = /(-?(\d+[,.]?)+)/ def count_whole(string, regex) string.scan(/(?<=\s)#{regex}(?=\s)/).count end def count_split(string, regex) string.split.count{|s| s.match(/^#{regex}$/)} end
¡Hola! → Salut ! # Źródła funkcji ::Typography.to_html_french # Wstaw cienką spację przed znaki interpunkcyjne text.gsub(/(\s|)+([!?;]+(\s|\z))/, ' \2\3') # <-58 spacji -> GET /wp-login.php HTTP/1.1 69 GET /show.aspx HTTP/1.1 15 klient Discourse, opisane przez Sama Saffrona
problemy: nachodzące się zakresy lub alternatywy, zagnieżdżone powtórzenia testy: poprawny, niepoprawny, prawie poprawny napis, różne konfiguracje każdy silnik jest inny - testuj wydajność na swoim
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![DZIAŁANIA ARYTMETYCZNE DZIAŁANIA ARYTMETYCZNE 320-12= 430- 32+1= /(\d+[-+])+=/ /(\d+[-+]?)+=/ /(\d+|\.?)+=/](https://files.speakerdeck.com/presentations/2aa2781cbece4d3bb4a1dcc21e6abbeb/slide_35.jpg){kind=link}
![COPY-PASTING COPY-PASTING (email validation) , Java Classname RegExLib, id=1757 ^([a-zA-Z0-9])(([\-.]|[_]+)?](https://files.speakerdeck.com/presentations/2aa2781cbece4d3bb4a1dcc21e6abbeb/slide_36.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![DŁUGIE REGEXPY DŁUGIE REGEXPY /.* - - \[(.*)\] "((.+) ?)*"](https://files.speakerdeck.com/presentations/2aa2781cbece4d3bb4a1dcc21e6abbeb/slide_46.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![DOBRE PRAKTYKI DOBRE PRAKTYKI .* => [^X]* .*? => [^X]*](https://files.speakerdeck.com/presentations/2aa2781cbece4d3bb4a1dcc21e6abbeb/slide_53.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}