implementation of neural networks For example, if you use (u)int8 instead of float32, you can improve both area and performance Personally, I strongly feel using floating-point operations is pretty bad since I actually implemented fadd last semester
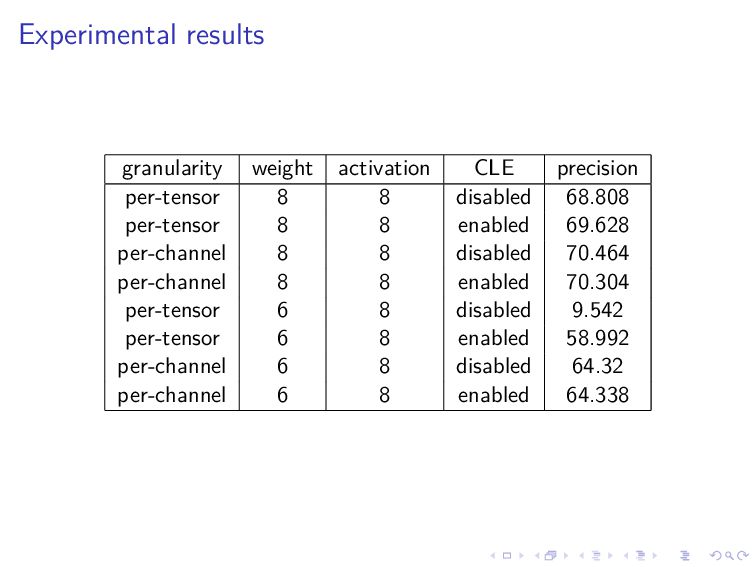
quantization is easy and 4-bit quantization is difficult However, it was known that 8-bit quantization with per-tensor quantization significantly degrades accuracy for some models, notably MobileNetV2 Nagel et al. solved this by proposing cross-layer equalization (CLE) I implemented this and conducted experiments on the quantization of MobileNetV2 using ImageNet dataset
quantization The above coincides with the results in the literature However, 8-bit quantization without CLE performs much worse in the literature This difference is beyond my understanding I wish I could have implemented the quantized network in FPGA (MobilenetV2 was too big to implement by hand)
one fully-connected layer is trained, tested, and quantized using MNIST dataset (implemented quantization by myself) A simple CNN with four convolution layers and one fully-connected layer is trained, tested, and quantized using CIFAR-10 dataset (implemented quantization by myself) As to MNIST, a separate computation unit is used for each layer As to CIFAR-10, a common computation unit is used for all layers
memory to PL BRAM at once All feature maps are placed on PL BRAM Two computation units are created for two convolution layers respectively This scheme scales poorly but is simple to implement and optimize By parallelizing each computation unit along the output channel direction, 40x speedup was achieved on the whole (measured by the latency estimated by Vitis HLS Cosimulation)
PS main memory to PL BRAM at once Feature maps for two layers are placed on PL BRAM (double buffering) Only one computation unit is created for four convolution layers and it is used to compute all of them I’m afraid I didn’t have enough time to optimize the design for CIFAR-10
implementation of neural networks: training, test, quantization, and implementation on FPGA I got perspectives of both software (including machine learning and quantization) and hardware (including SoC FPGA and HLS) In the future, I want to further explore the possibility of optimizing the architecture and implementation for neural networks In the future, I want to explore more optimization of the architecture for neural networks and scale the size of neural network models
Welling, ”Data-Free Quantization Through Weight Equalization and Bias Correction,” 2019 IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 1325-1334, doi: 10.1109/ICCV.2019.00141.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}