Computing, – Green Computing, and – Cloud Computing • We want to investigate power consumption tradeoffs against execution time for a workload of discrete tasks submitted to a multicore server • Multicore (WLOG manycore) provides a very different landscape from conventional, serial processors – We aim to optimise scheduling for different workloads 2
– large-scale: cloud computing, small-scale: multicore CPUs • Cloud-based server consolidation can clearly save energy – plus economies of scale regarding all types of infrastructure • Multicore has reversed previous decades’ trend – Parallelism, and increasingly distribution, are a part of almost all computer CPU architectures – This community knows that, of course! – Still challenges regarding support for multicore CPUs in the designs of common programming languages and operating systems. 4
power – Instead, our research focuses on maximising the total energy savings recouped over the completion of a set of computing jobs – Developing CPUs that require less power does not necessarily guarantee improved energy efficiency for a given set of tasks – (but it’s still a good idea!) – Our work makes heavy use of Dynamic Voltage and Frequency Scaling (DVFS) in order to optimise overall energy usage • Common green computing metric: Performance per Watt – We introduce other metrics: Speedup per Watt (SPW), Power per Speedup (PPS) and Energy per Target (EPT) 5
Cloud Computing workloads: – Novel scheduling policies that may employ periods of higher power usage in order to produce lower overall energy consumption – Take advantage of the particular processing consolidation options that multicore CPUs can provide • Take-away from Zhiyi’s presentation yesterday: want workload knowledge for job scheduling – Can change the total execution time of those jobs, and thus facilitate overall energy savings – Cloud Computing environments likely to provide heterogeneity of jobs, scale of server numbers and appropriate limits of job queue sizes to make effective use of energy-aware scheduling schemes 6
fable of race between Tortoise and Hare – Hare is high power, tortoise low power, similar overall energy – Both Hare and Tortoise provide useful scheduling approaches that are optimal for different types of workload • However, race-to-sleep approaches have requirements: – Rate of job arrival cannot depend on the service rate – Must be a mechanism to recoup short-term energy cost • Must be time available, and energy savings to be gained from switching CPU into aggressive power-saving mode – Need to consider delays between power-saving states 7
intra-job parallelism • Power-aware scheduler can consider combinations of inter-application or intra-application parallelism applied to the jobs—also referred to as ‘exclusive’ and ‘sharing’ policies respectively in our research – cores can be used to run different jobs in parallel – ... or cores can be used to run a job’s many threads in parallel – (or some intermediate combination of these two extremes) – Scheduler can apply DVFS alter the instantaneous power properties of the overall CPU, and in most cases of the individual cores too. 8
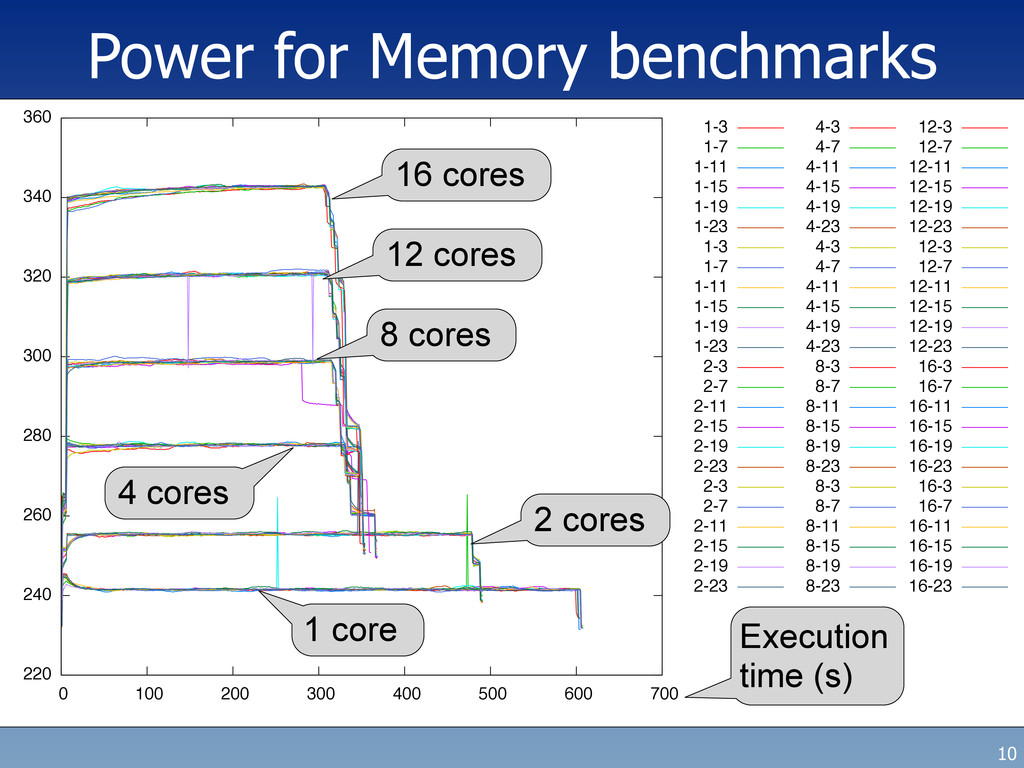
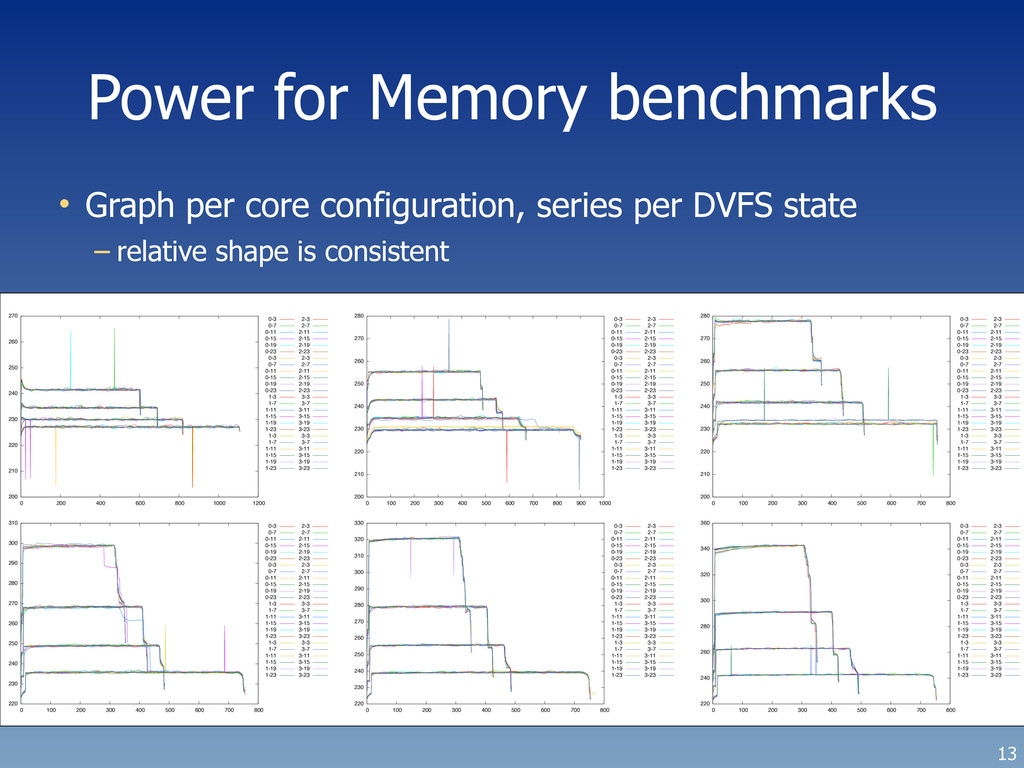
• Plot power consumption on Y-axis (in Watts) • Plot time on the X-axis (in seconds) – Data comes from a USB-connected meter watching the line power • Different series are different numbers of cores used • Multiple iterations of each run are shown (consistent) – including some glitches from the power meter... 9
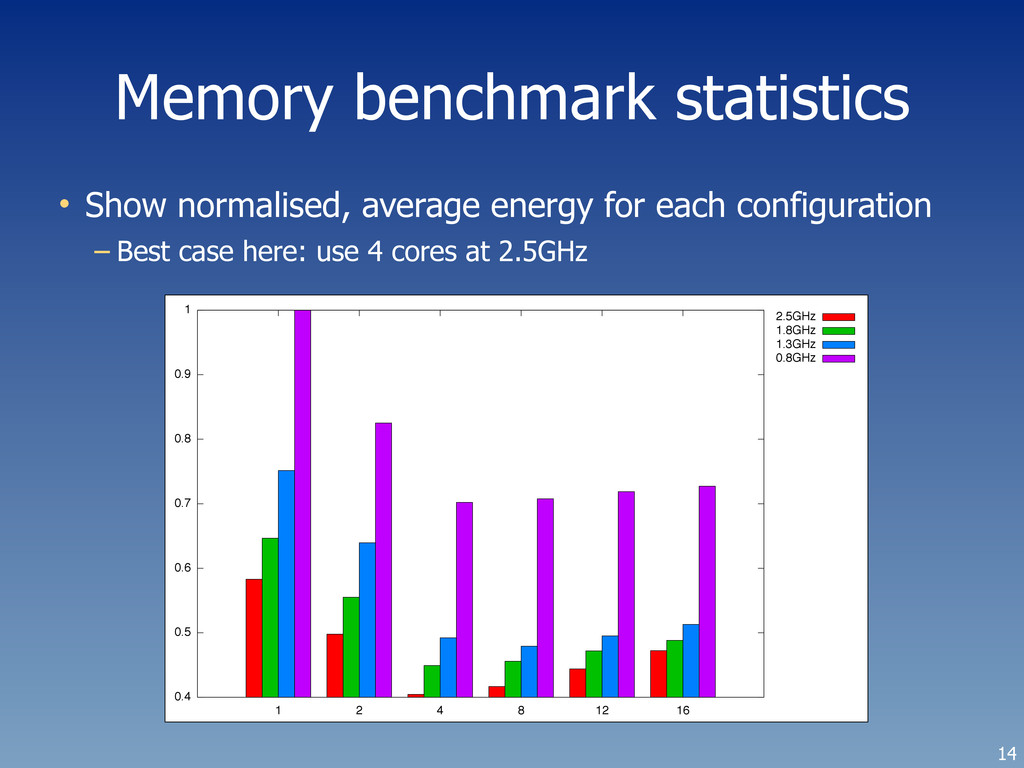
• Best in this case to run on only four cores – Leaves 12 cores to do other work (or go to low power) – Time is about 60% of the time taken by one core – Takes about 62% of the energy compared to one core – However, what do I mean by this case? • Memory micro-benchmark stresses whole RAM hierarchy – Note that we are seeing AMD NUMA effect here: • Optimal to use all cores on one die – While not unsurprising (considering NUMA) we still need to know what the actual difference is! 12
entirely predictable – ... but it is easy to measure the results of scheduling decisions • Just looked at the memory micro-benchmark in this talk – Also have a CPU-heavy micro-benchmark – ... and a set of less extreme benchmarks • Our methodology for optimising against a given workload can be applied easily – ongoing work to filter the data to collect, and simplify the analysis 15
about dynamic task characterisation for asymmetric multicore – Similar approaches work for energy-efficient multicore scheduling – e.g. memory versus CPU-bound implies different scheduling • More kit! Results are dependent on the machine at hand – ... although the methodology generalises – Buying 64-core machine later this year (4x 16-core) – Anyone have any spare 256-core machines they want to lend us? 16
a per-node level and a serial CPU speed – Complexities from fundamental machine architecture (e.g. NUMA) • Experimental results: saving power does not necessarily reduce energy use for discrete jobs with deadlines. • Our energy-aware scheduling benefits are greatly amplified by multicore CPUs, and apply to cloud workloads • Questions? 17
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}