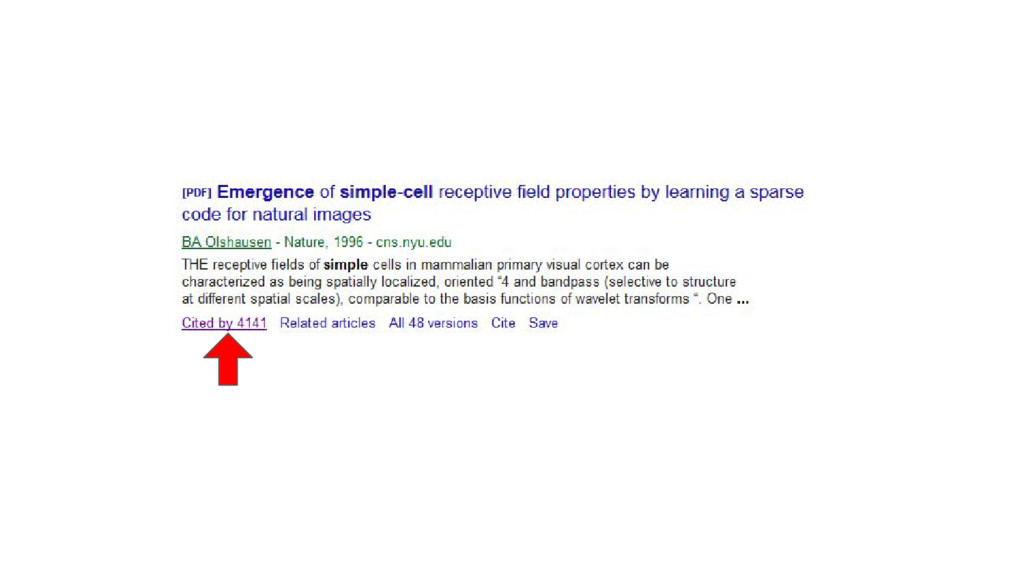
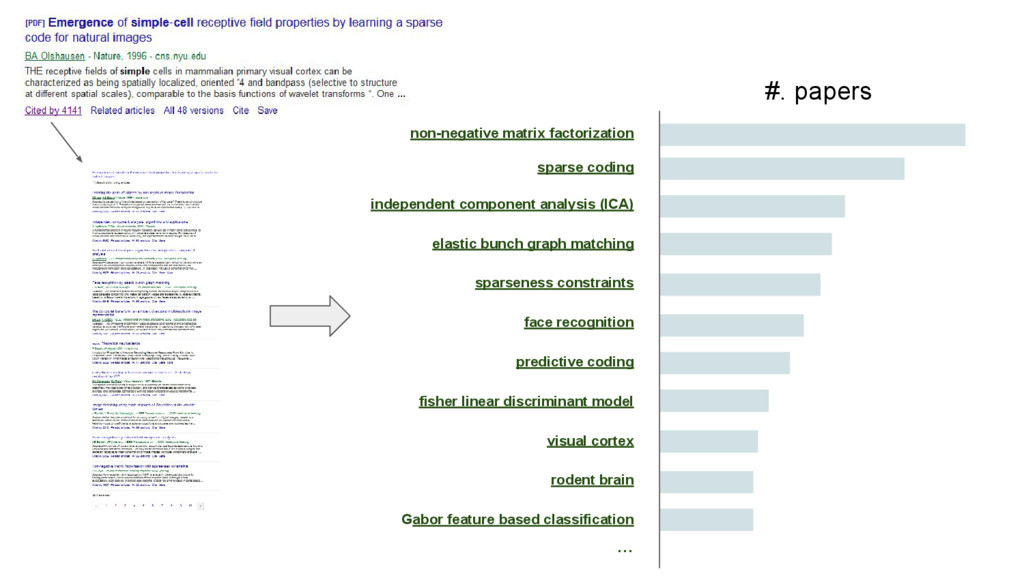
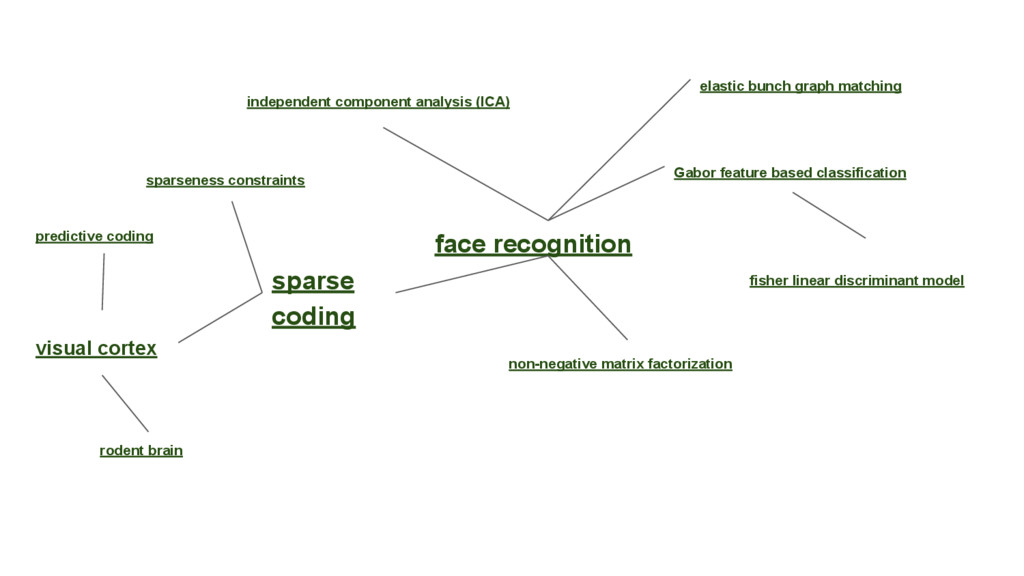
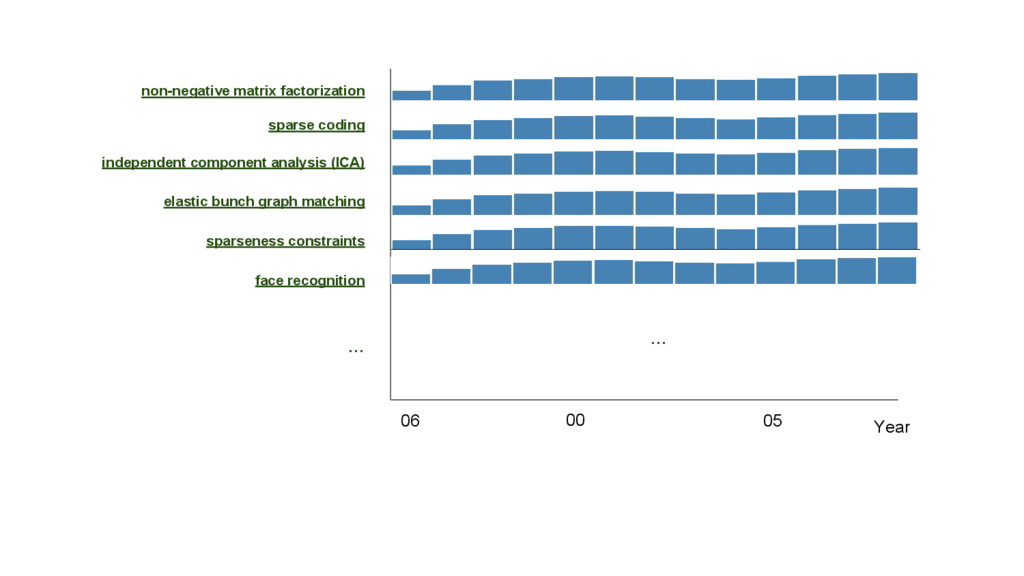
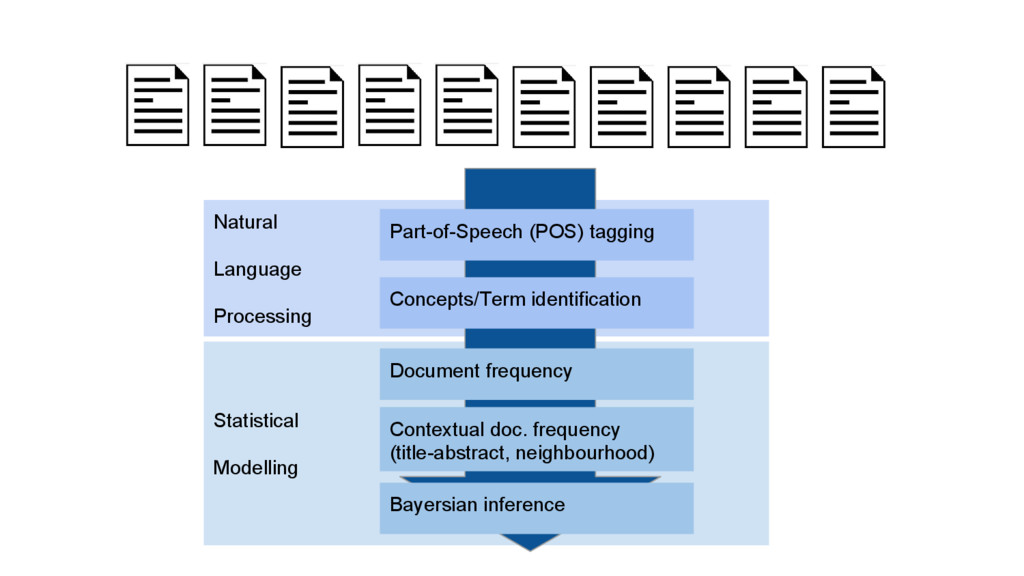
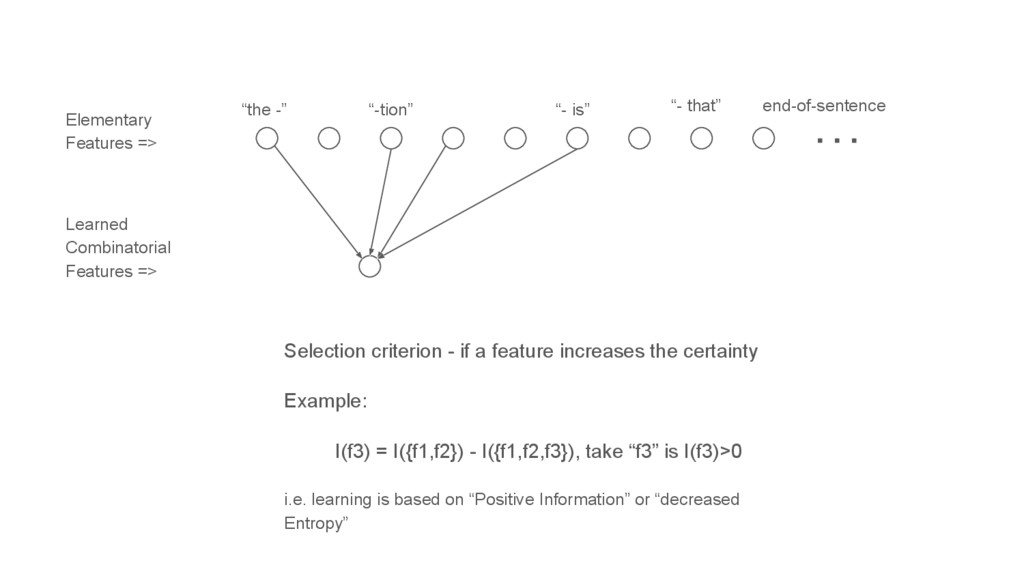
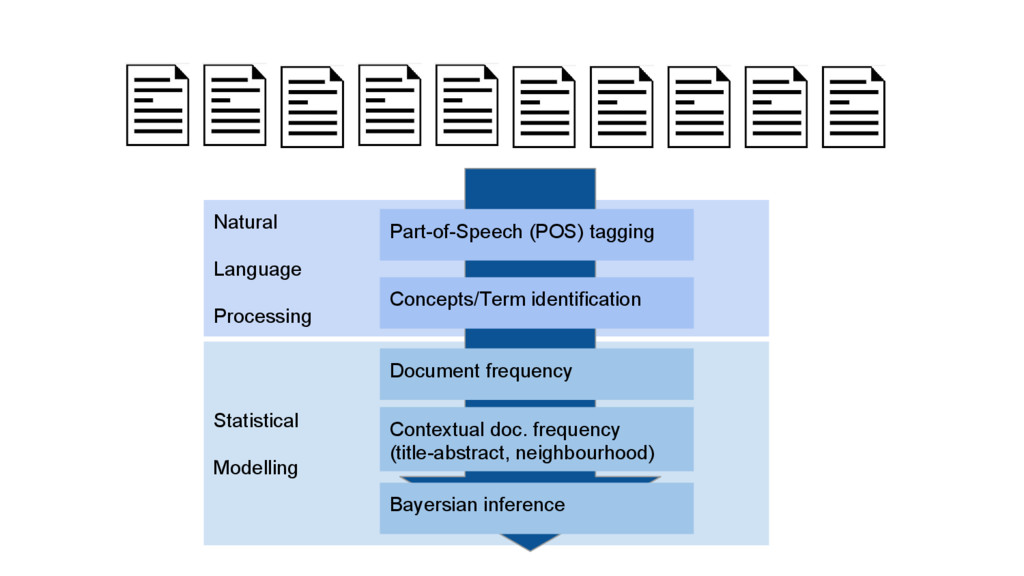
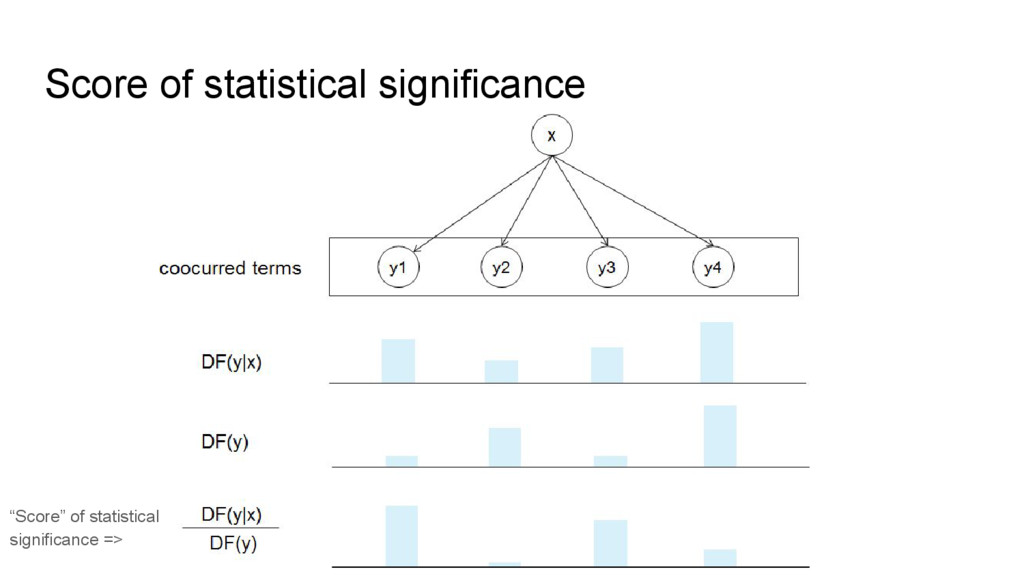
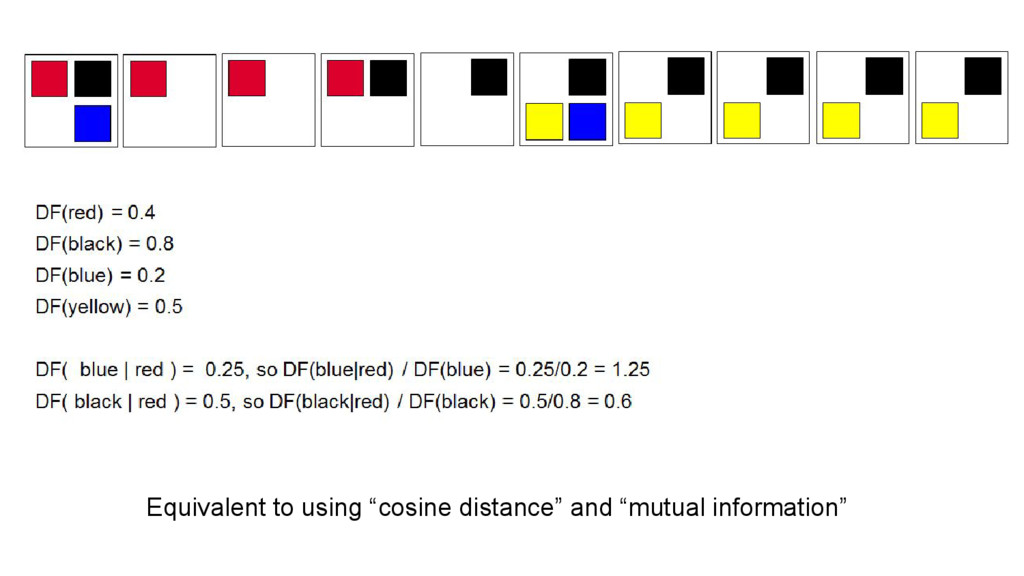
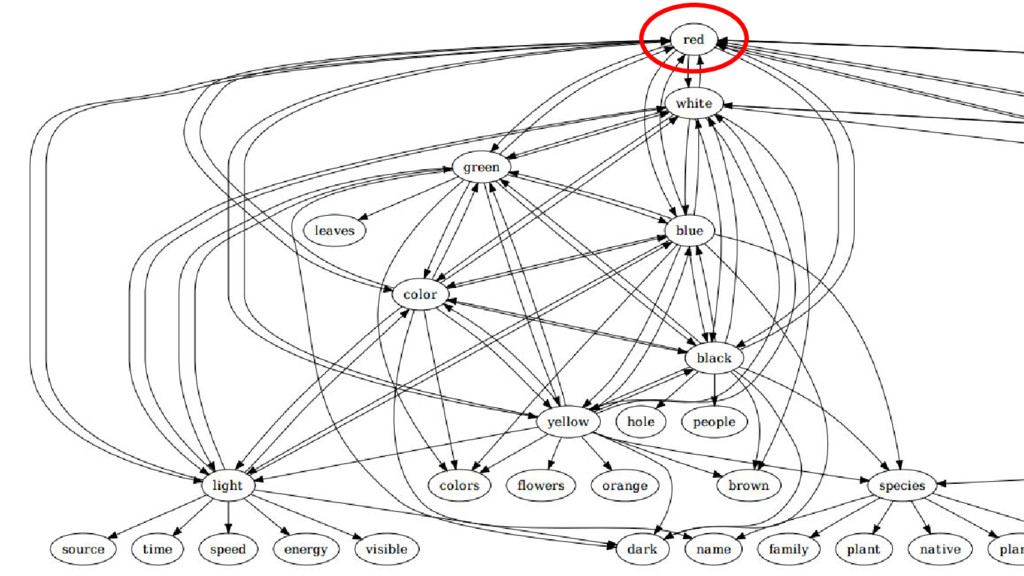
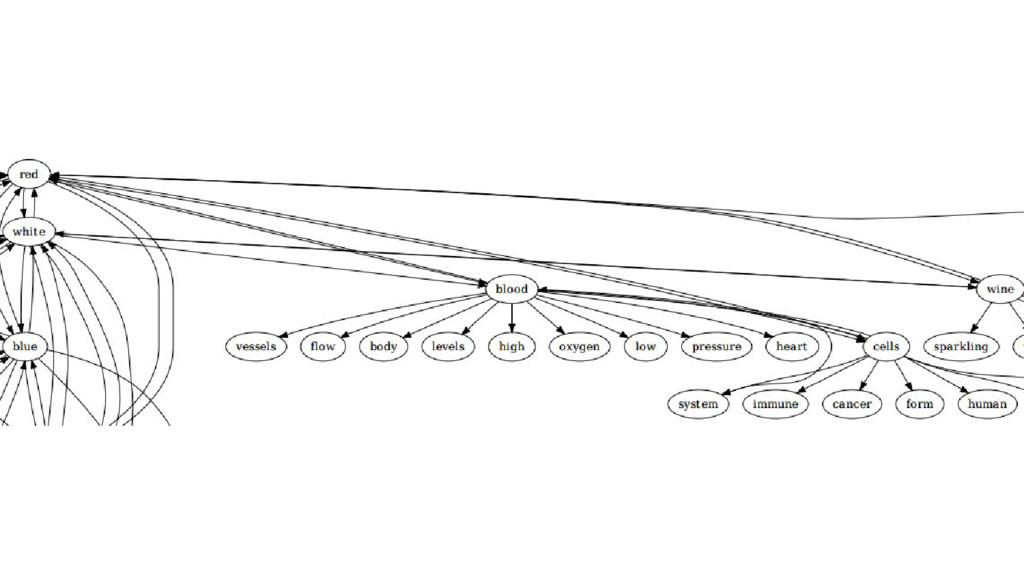
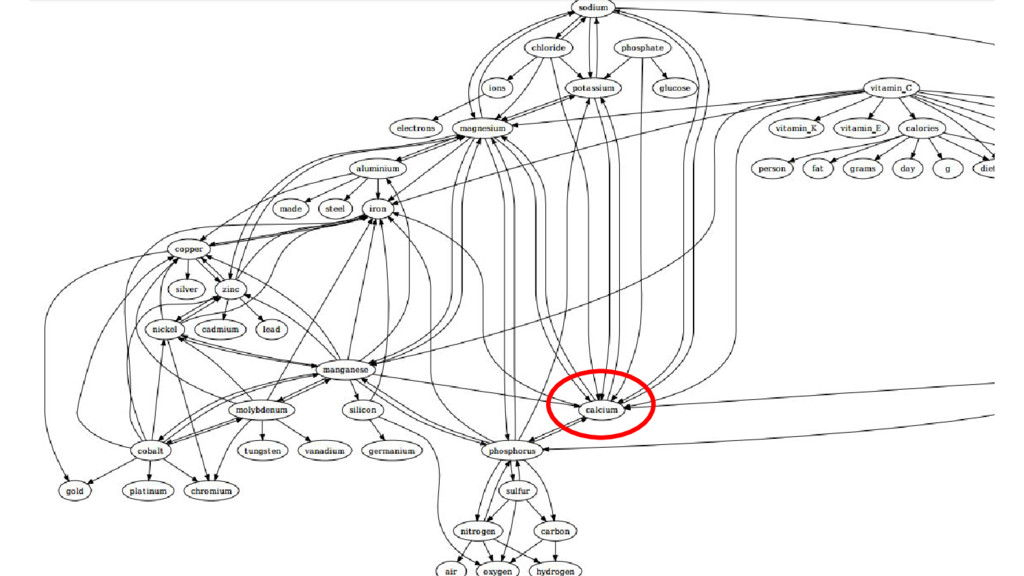
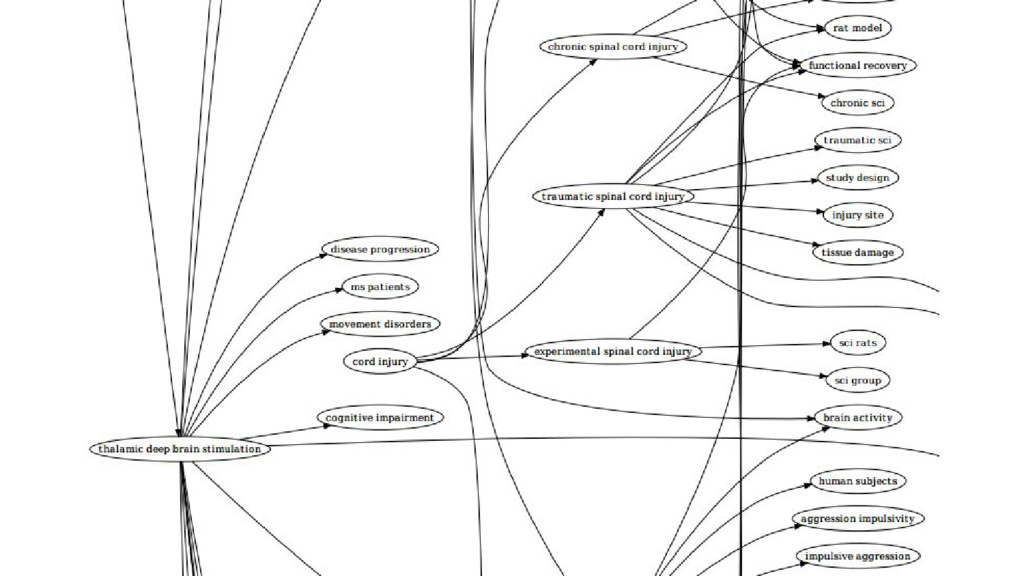
This talk is about applying text-mining on academic publications to extract information such as knowledge graphs of related concepts. The overall goal is to help researchers to better and faster explore a large amount of text documents which in this case are academic publications. Given the text of thousands or millions of publications, I will show 1) how to use natural language processing techniques to extract concepts 2) how to use statistics and bayersian theory to identify related concepts 3) how to use a short-long-term memory mechanism to learn related concepts in a sequential manner. In the end, we will be able to obtain a "knowledge graph" among the concepts through this text-mining process. Part of the results could be found at: www.neuronbit.io. The result of this work can also be useful for semantic search, document classification, information retrieval, etc.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}