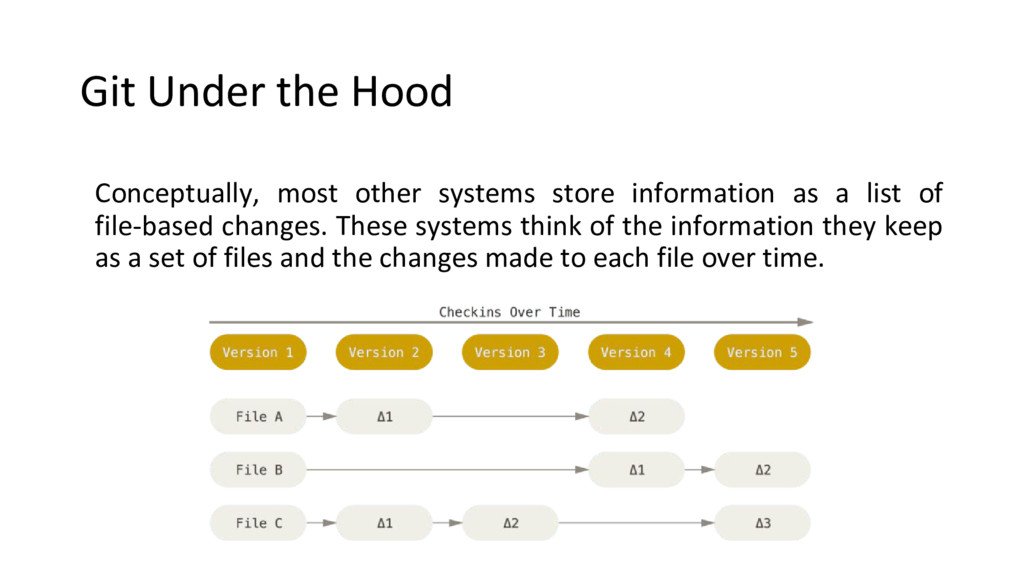
must use the same file system. •Client-server model (SVN, TFS) • Developers use a shared single repository. •Distributed model (Git, Mercurial) • Each developer works directly with his or her own local repository, and changes are shared between repositories as a separate step
control system •Open Source, GNU General Public License v2 •Written in a collection of Perl, C, and various shell scripts •Created by Linus Torvalds in 2005 for development of the Linux Kernel, he described the tool as "the stupid content tracker"
like a set of snapshots of a miniature filesystem. Every time you commit, or save the state of your project in Git, it basically takes a picture of what all your files look like at that moment and stores a reference to that snapshot.
is stored and is then referred to by that checksum. This means it’s impossible to change the contents of any file or directory without Git knowing about it. Git uses SHA-1 hash: 24b9da6552252987aa493b52f8696cd6d3b00373
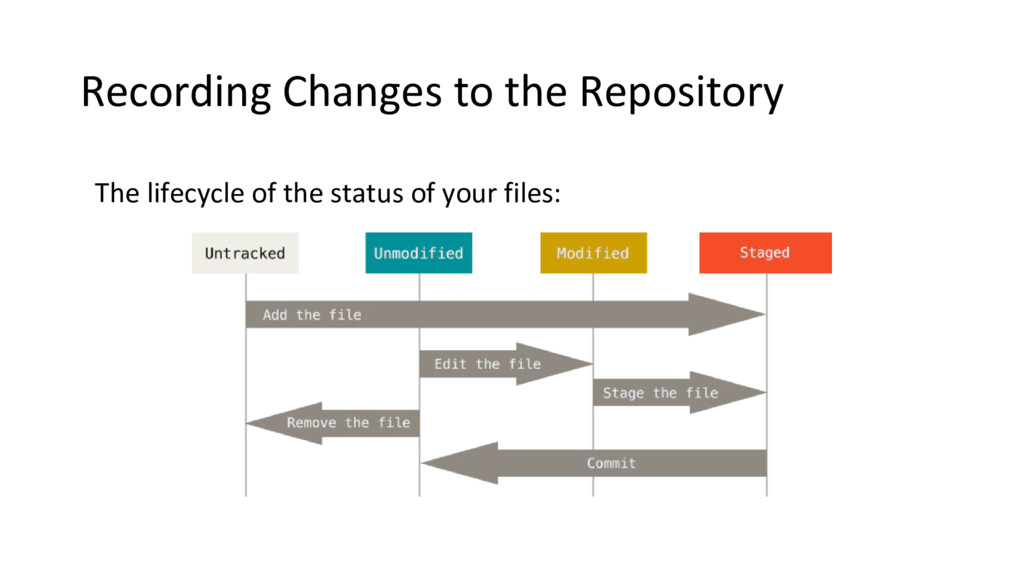
files can reside in: 1. Committed: data is safely stored in your local database 2. Modified: the file changed but have not committed it to your database yet 3. Staged: you have marked a modified file in its current version to go into your next commit snapshot
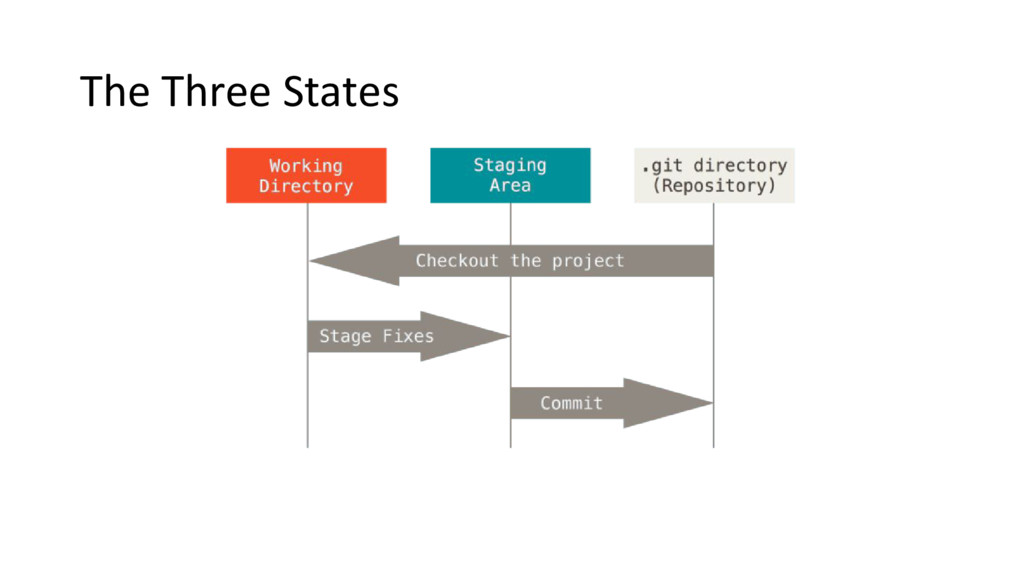
this: 1. You modify files in your working tree. 2. You stage the files, adding snapshots of them to your staging area 3. You do a commit, which takes the files as they are in the staging area and stores that snapshot permanently to your Git directory.
you don’t want Git to automatically add or even show you as being untracked. In such cases, you can create a file listing patterns to match them named .gitignore. • Blank lines or lines starting with # are ignored. • Standard glob patterns work • You can start patterns with a forward slash (/) to avoid recursivity • You can end patterns with a forward slash (/) to specify a directory • You can negate a pattern by starting it with an exclamation point (!)
.a files *.a # but do track lib.a, even though you're ignoring .a files above !lib.a # only ignore the TODO file in the current directory, not subdir/TODO /TODO # ignore all files in the build/ directory build/ # ignore doc/notes.txt, but not doc/server/arch.txt doc/*.txt # ignore all .pdf files in the doc/ directory doc/**/*.pdf
something. Be careful, because you can’t always undo some of these undos. This is one of the few areas in Git where you may lose some work if you do it wrong. $ git commit --amend
that remote project and pulls down all the data from that remote project that you don’t have yet. After you do this, you should have references to all the branches from that remote, which you can merge in or inspect at any time. $ git fetch [remote-name]
complete and ready to be merged into your master branch. $ git checkout master Switched to branch 'master' $ git merge iss53 Merge made by the 'recursive' strategy. index.html | 1 + 1 file changed, 1 insertion(+)
changed the same part of the same file differently in the two branches you’re merging together, Git won’t be able to merge them cleanly. $ git merge iss53 Auto-merging index.html CONFLICT (content): Merge conflict in index.html Automatic merge failed; fix conflicts and then commit the result.
resolved is listed as unmerged. Git adds standard conflict-resolution markers to the files that have conflicts, so you can open them manually and resolve those conflicts. <<<<<<< HEAD:index.html <div id="footer">contact : [email protected]</div> ======= <div id="footer"> please contact us at [email protected] </div> >>>>>>> iss53:index.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}