Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ソースコードのEUC-JP、全部抜く大作戦 / BuriKaigi2026
Search
yukyan
January 10, 2026
2.6k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ソースコードのEUC-JP、全部抜く大作戦 / BuriKaigi2026
yukyan
January 10, 2026
More Decks by yukyan
See All by yukyan
Let's Vibe Coding Mini Apps
n3xem
0
69
Perplexity Slack Botを作ってAI活用を進めた話 / AI Engineering Summit プレイベント
n3xem
0
1k
Goで作るChrome Extensions / Fukuoka.go #21
n3xem
2
3.2k
短期間での新規プロダクト開発における「コスパの良い」Goのテスト戦略」 / kamakura.go
n3xem
2
500
Featured
See All Featured
It's Worth the Effort
3n
188
29k
Optimizing for Happiness
mojombo
378
71k
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
sira's awesome portfolio website redesign presentation
elsirapls
0
310
My Coaching Mixtape
mlcsv
0
170
Principles of Awesome APIs and How to Build Them.
keavy
128
18k
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
500
Making Projects Easy
brettharned
120
6.7k
How to Ace a Technical Interview
jacobian
281
24k
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
380
Claude Code どこまでも/ Claude Code Everywhere
nwiizo
65
57k
Transcript
1 ソースコードのEUC-JP、 全部抜く⼤作戦 ⼤浦 優太郎 EC事業部 事業開発チーム BuriKaigi 2026 2026.01.10
2 ⾃⼰紹介 EC事業部 事業開発チーム 2022年 新卒⼊社 ⼤浦 優太郎 Oura Yutaro EC事業部でECサイト構築サービス「カラーミー
ショップ byGMOペパボ」の開発‧運⽤に携わる。 1⽉から事業開発チームに参画。うなぎの浜松出 ⾝。 • X : @yukyan_p • Instagram: @yukyan_p
3 アジェンダ 1. はじめに 2. EUC-JP を倒すことの難しさ 3. 解決策 4.
実際の成果 5. まとめ
1. はじめに 4
はじめに 5 あけましておめでとうございます!
はじめに 6 2026年ですが プロダクト開発で EUC-JP と戦っている⼈いますか?
はじめに 7 私は戦っています!
はじめに 8
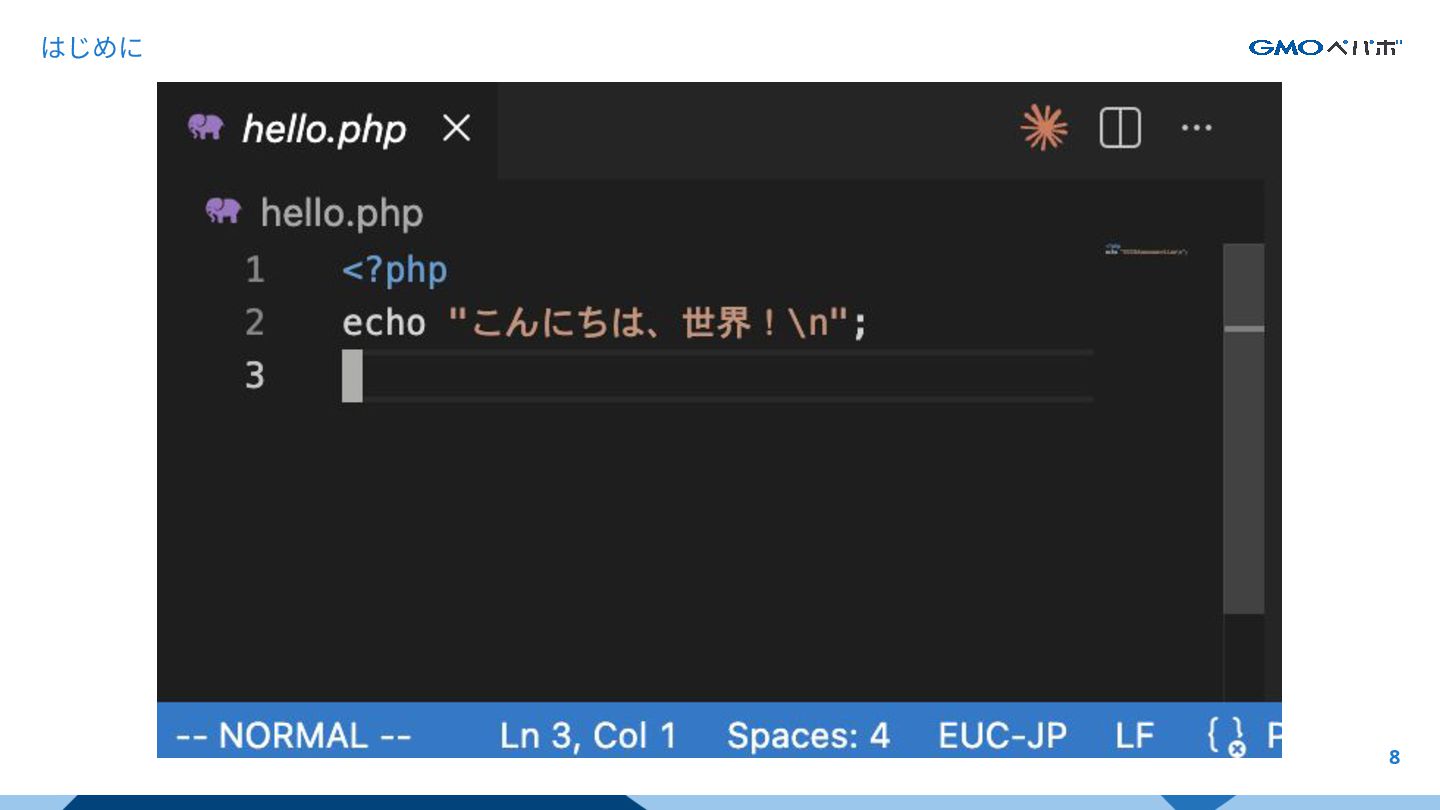
はじめに 9 Claude Code で編集していると
はじめに 10
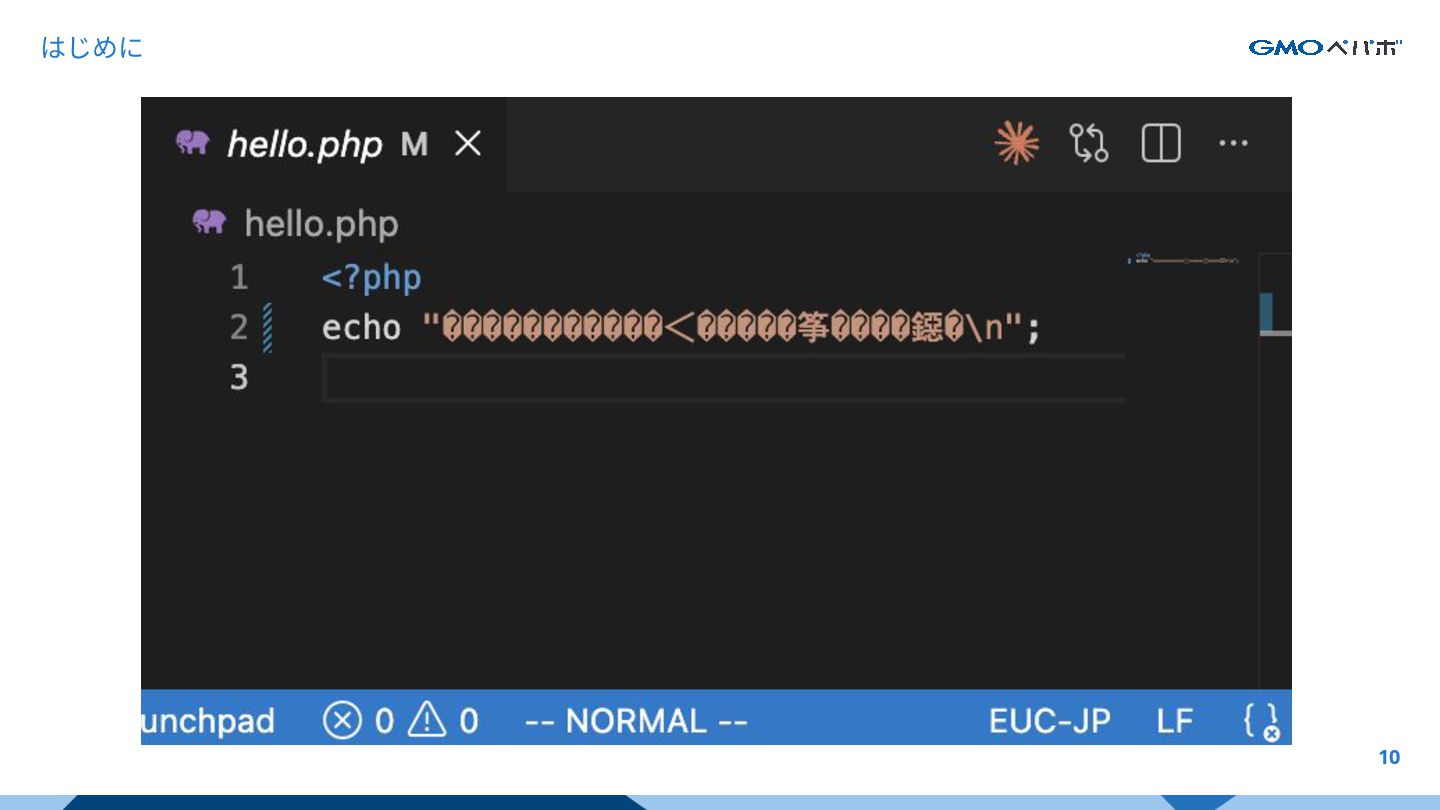
はじめに 11 ⽂字化けしてしまう!
はじめに 12 • Claude Code で編集した際に⽂字化け • エディタの設定による⽂字化け • GitHub
でレビューする際に⽂字化け ところどころで、UTF-8 でないことによる開発体験の痛みがある UTF-8 前提のツールによる⽂字化け
2. EUC-JP を倒すことの難しさ 13
EUC-JP を倒すことの難しさ 14 Q. nkf -w で終わりなのでは?
EUC-JP を倒すことの難しさ 15 • マルチバイト⽂字がコメントアウトだけであれば問題ないが... • ソースコードの中にマルチバイトの⽂字列リテラルがあり、ロ ジックが、それがEUC-JPであることに依存している場合、最 終的な結果が変わってしまうことがある nkf
-w で困ること
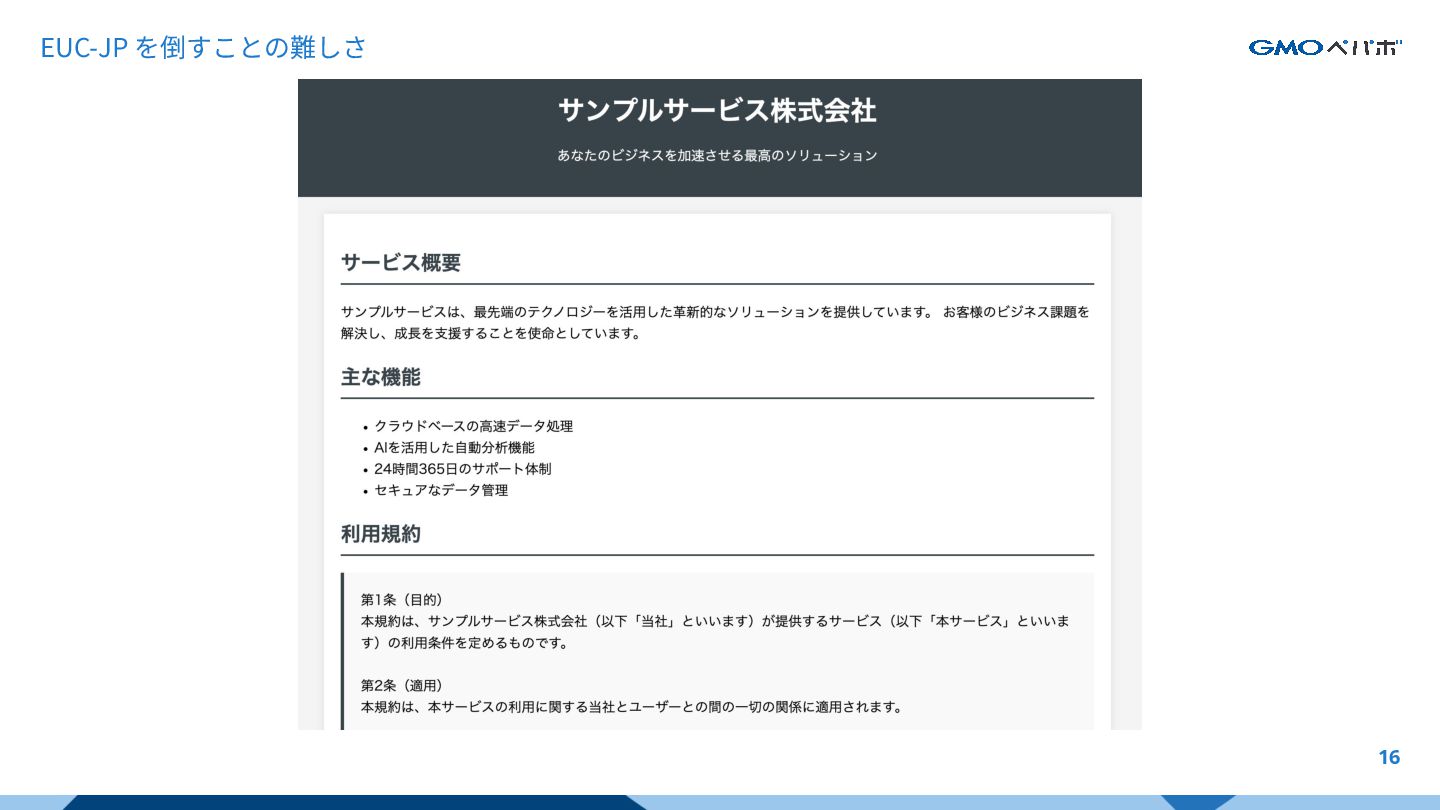
EUC-JP を倒すことの難しさ 16
EUC-JP を倒すことの難しさ 17
EUC-JP を倒すことの難しさ 18 Q. それならまずUTF-8で書いて mb_convert_encodingで UTF-8 から EUC-JP に
変換するようにしたら?
EUC-JP を倒すことの難しさ 19 • UTF-8 は Unicode を使えるので111万⽂字ぐらい • PHPがサポートしている
EUC-JP は下記の⽂字集合の合成 US-ASCII + JIS X0201:1997(半⾓カナ) + JIS X0208:1990 + JIS X0212:1990 ⼤体 1万2千⽂字 UTF-8 -> EUC-JP で失われる情報がある https://www.php.net/manual/ja/mbstring.encodings.php
EUC-JP を倒すことの難しさ 20 • UTF-8 でプログラム上で扱う⽂字列を記述すると、それを EUC-JP として扱おうとしたときに、失われる情報が出てくる (今後、⽂字を追加する場合などに) •
つまり、EUC-JP は EUC-JP のまま表現して取り扱いたい (EUC-JP に⼤きく依存した今回のケースにおいては) UTF-8 -> EUC-JP で失われる情報がある
3. 解決策 21
解決策 22 1. マルチバイト⽂字列リテラルを⼀つのファイルに追い出し、元々 直接⽂字列リテラルが書かれていた箇所はそれを参照するように する 2. 追い出し切ったら、コメントアウト以外は ASCII⽂字 ということ
になる。 3. ASCII⽂字は EUC-JP と UTF-8 でバイト値が変わらないので⼀気に UTF-8 に変換できる i18n を参考にした解決策
解決策 23 1. マルチバイト⽂字列リテラルを⼀つのファイルに追い出し、元々 直接⽂字列リテラルが書かれていた箇所はそれを参照するように する 2. 追い出し切ったら、コメントアウト以外は ASCII⽂字 ということ
になる。 3. ASCII⽂字は EUC-JP と UTF-8 でバイト値が変わらないので⼀気に UTF-8 に変換できる i18n を参考にした解決策
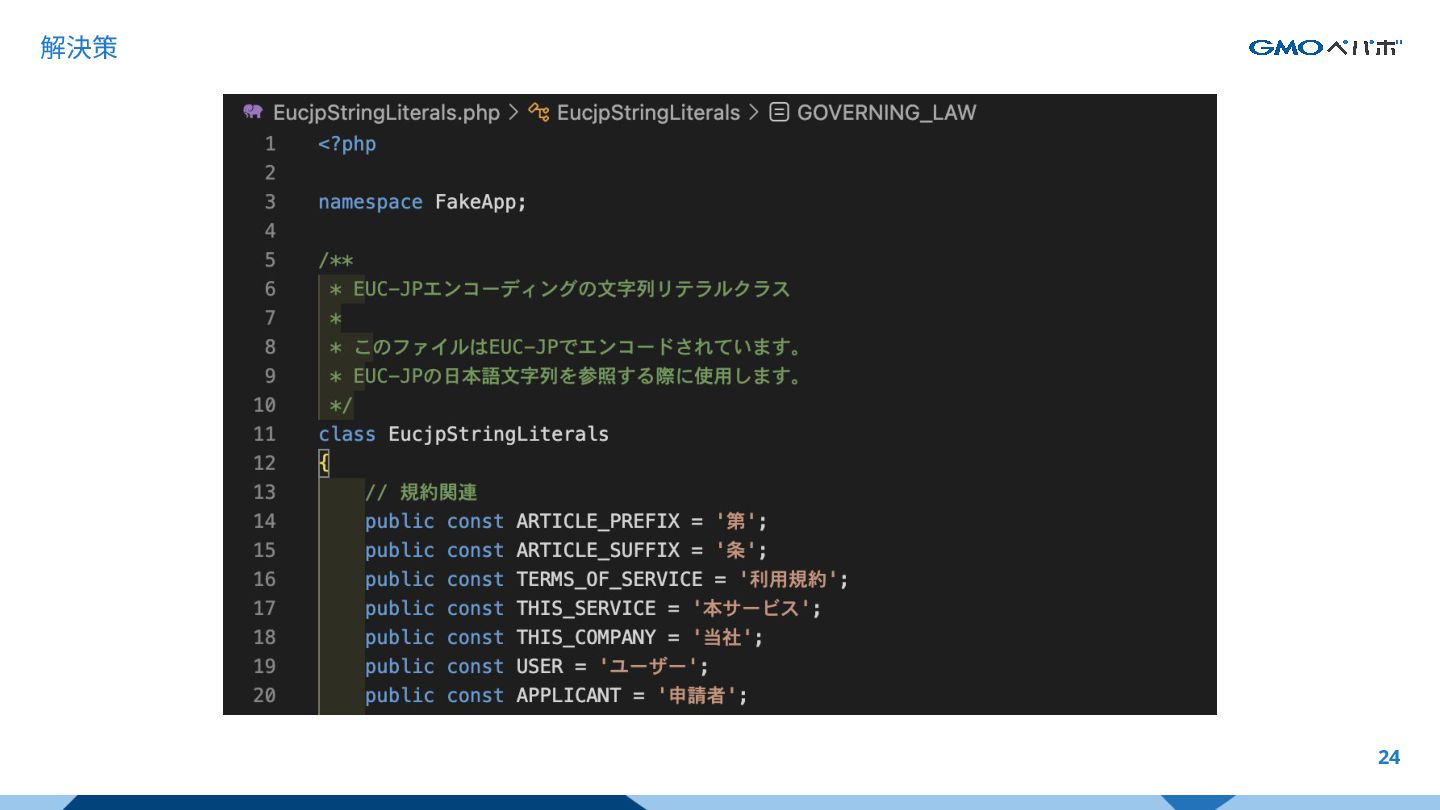
解決策 24
解決策 25 どうやって追い出すのか?
解決策 26 AIでスクリプトを書きます! Vibe Coding!
解決策 27 PHPトークナイザーを活用し、PHPソースコード内のコメ ントアウト以外のマルチバイト文字列をすべて EucjpStringLiterals.php に定数として定義し直すス クリプトを書いてください。 元々マルチバイト文字列箇所は、 EucjpStringLiterals.php に定義した定数を参照する
形に書き直してください。 プロンプト例
解決策 28 1. マルチバイト⽂字列リテラルを⼀つのファイルに追い出し、元々 直接⽂字列リテラルが書かれていた箇所はそれを参照するように する 2. 追い出し切ったら、コメントアウト以外は ASCII⽂字 ということ
になる。 3. ASCII⽂字は EUC-JP と UTF-8 でバイト値が変わらないので⼀気に UTF-8 に変換できる i18n を参考にした解決策
解決策 29 どうやって「追い出し切ったか」を 判定するのか
解決策 30 PHPCodeSnifferを活⽤!
解決策 31 • PHPコードの品質を管理するための静的解析ツール • コードが PSR-12 などの標準ルールやに沿っているかを できる •
ルールは⾃分で作ることもできる。このルールを「ス ニフ」と呼ぶ PHPCodeSniffer とは
解決策 32 • 「コメント以外にマルチバイト⽂字列がない」状態を 保証する仕組みが欲しい • リポジトリに導⼊されていた PHPCodeSniffer を⽤い て、コメントアウト以外のマルチバイト⽂字列を検知
するスニフを作成 PHPCodeSniffer の活⽤⽅法
解決策 33 use PHP_CodeSniffer\Sniffs\Sniff; use PHP_CodeSniffer\Files\File; use PHP_CodeSniffer\Util\Tokens; /** *
NonAsciiInCodeSniff * * コード内の非ASCII文字をチェックします(コメントは除外)。 */ class NonAsciiInCodeSniff implements Sniff {
解決策 34 … // PHPCSのTokens::$commentTokensを使用して、 // すべてのコメント関連トークンをスキップ if (isset($token['code']) &&
isset(Tokens::$commentTokens[$token['code']])) { continue; } … // 非ASCII文字が含まれていたら警告を出す if ($this->containsNonAscii($token['content'])) { $phpcsFile->addWarning( …
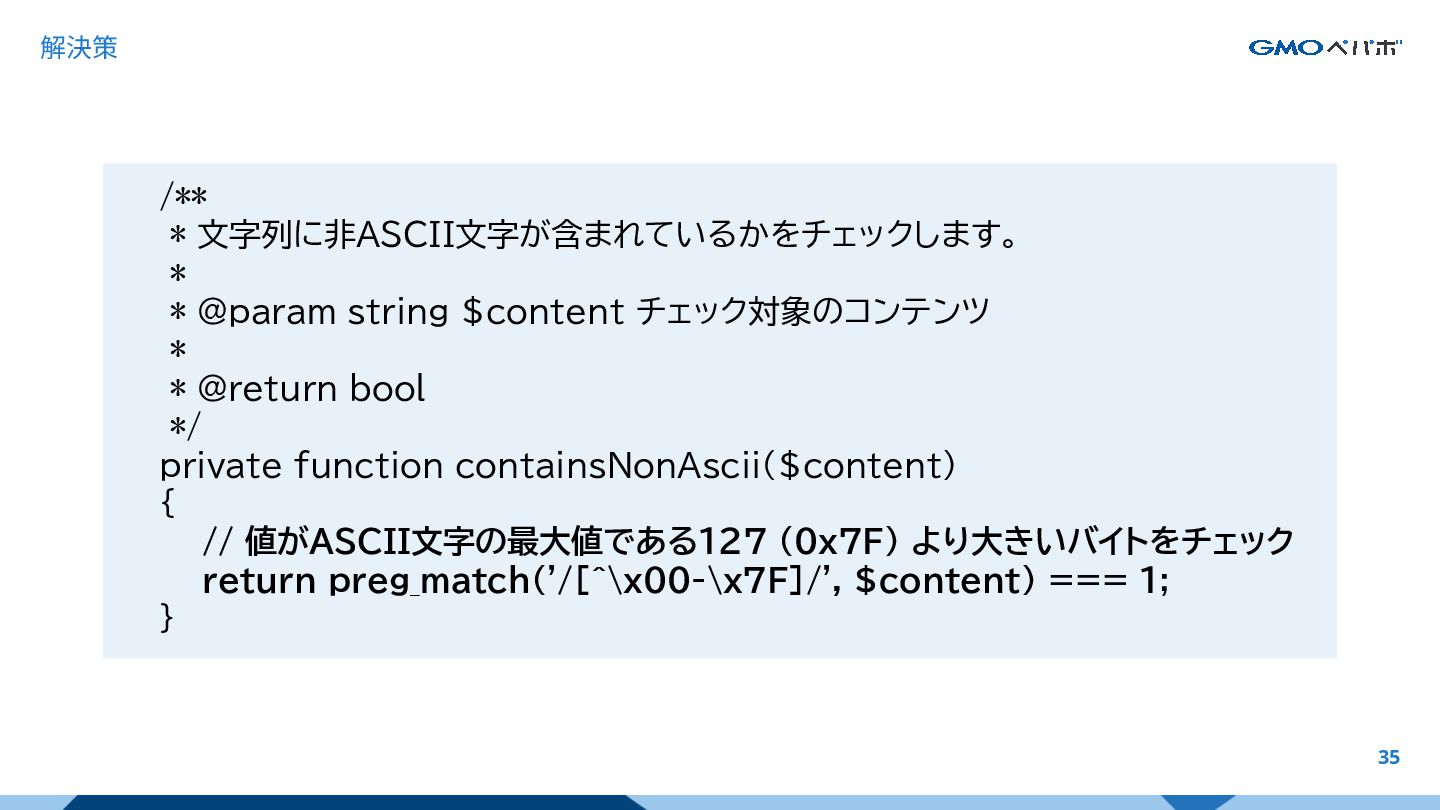
解決策 35 /** * 文字列に非ASCII文字が含まれているかをチェックします。 * * @param string $content
チェック対象のコンテンツ * * @return bool */ private function containsNonAscii($content) { // 値がASCII文字の最大値である127 (0x7F) より大きいバイトをチェック return preg_match('/[^\x00-\x7F]/', $content) === 1; }
解決策 36 1. マルチバイト⽂字列リテラルを⼀つのファイルに追い出し、元々 直接⽂字列リテラルが書かれていた箇所はそれを参照するように する 2. 追い出し切ったら、コメントアウト以外は ASCII⽂字 ということ
になる。 3. ASCII⽂字は EUC-JP と UTF-8 でバイト値が変わらないので⼀気 に UTF-8 に変換できる i18n を参考にした解決策
解決策 37 • 追い出し先のファイルのみ EUC-JP を許容することになってしまう • 追い出し先のファイルにすべてのマルチバイト⽂字列を置くので、メ ンテナンスコストが⾼そう •
⼀旦追い出して開発体験を改善したあと、今後の運⽤⽅法を検討する ことになるだろう この⼿法の課題
4. 実際やってみたところ 38
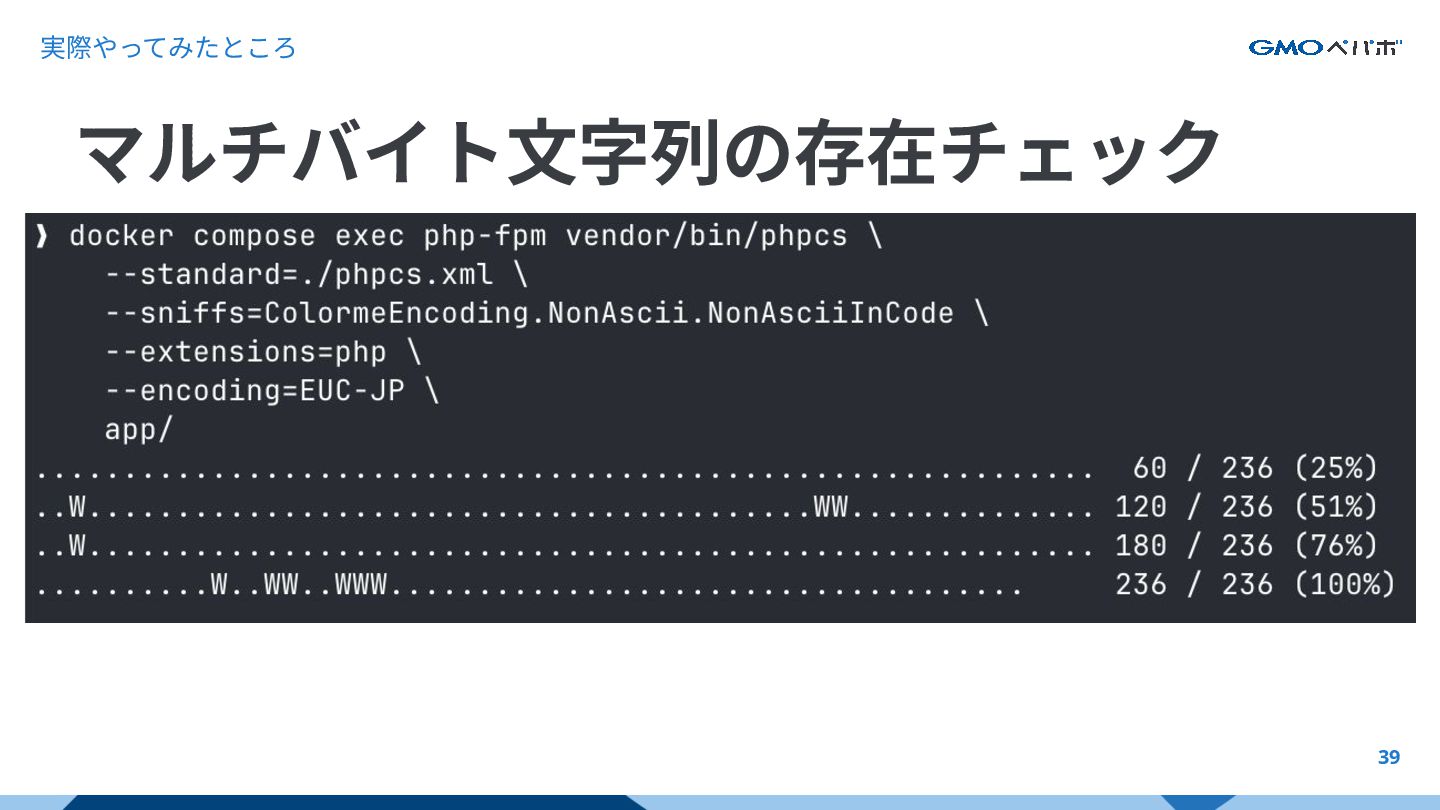
実際やってみたところ 39 マルチバイト⽂字列の存在チェック
実際やってみたところ 40 変換スクリプトを実⾏
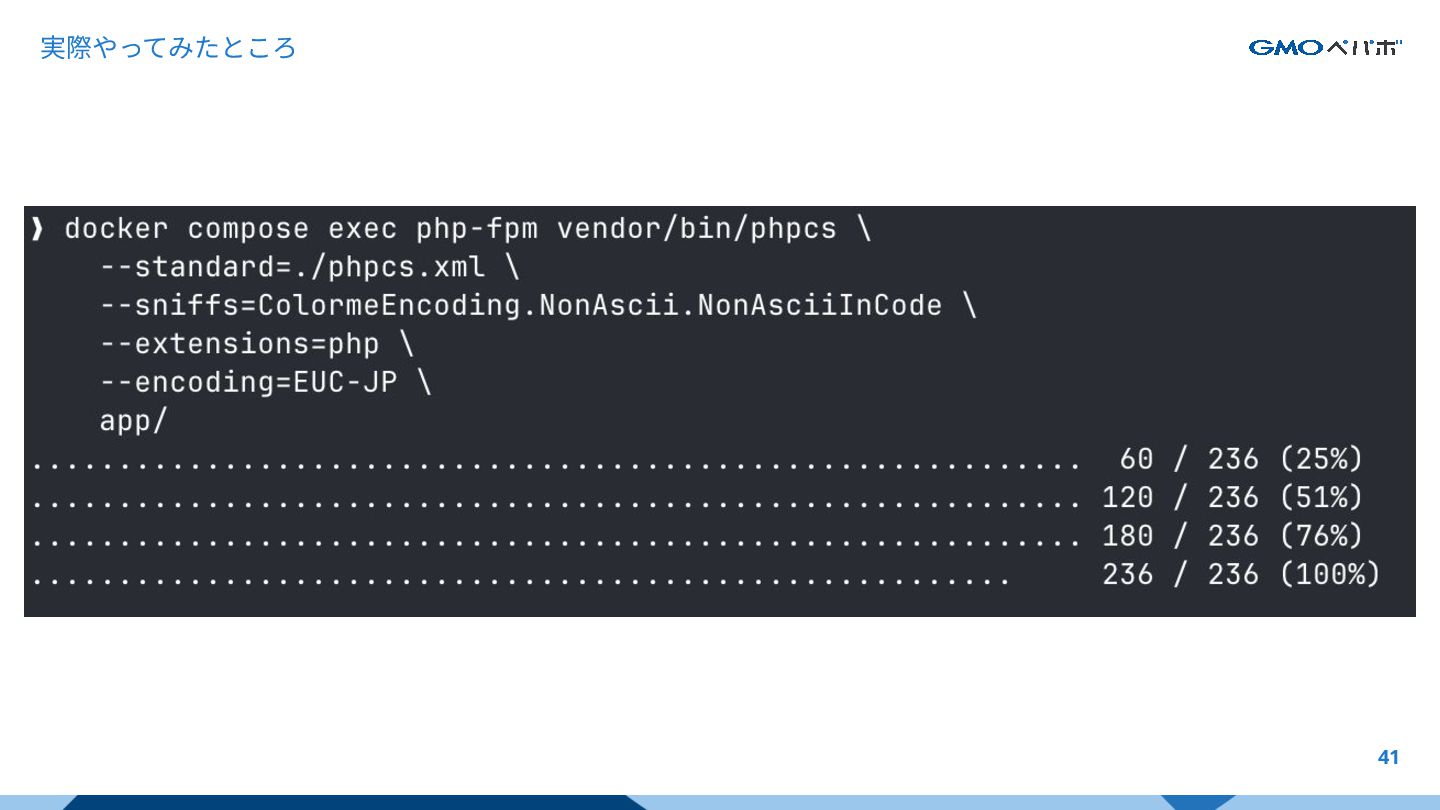
実際やってみたところ 41
はじめに 42 ソースコードからマルチバイト⽂字列を 追い出し切れた!! 🎉 あとは⼀気に変換するだけ!
6. まとめ 43
はじめに 44 • EUC-JP を安全にソースコードから抜く⼿法を提⽰した ◦ ⼀⽅で課題もある • この⼿法は「EUC-JPをEUC-JPのまま取り扱いたい」場合の解決策 の⼀つとなる
• PHPCodeSniffer を使うことで、マルチバイト⽂字列リテラルが ソースコードにないことを保証する仕組みを作れる • よりいい⽅法を模索していきたいので、情報お待ちしています! まとめ
45 Thank you!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![解決策 34 … // PHPCSのTokens::$commentTokensを使用して、 // すべてのコメント関連トークンをスキップ if (isset($token['code']) &&](https://files.speakerdeck.com/presentations/a7bd94b056ba4890a46e84279c26d09b/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}