Slides for a seminar given at the PANAMA (https://team.inria.fr/panama/) team at IRISA lab (https://www.irisa.fr/) in Rennes.
Abstract : We propose a new algorithm for the piece-wise i.i.d. non-stationary bandit problem with bounded rewards. Our proposal, GLR-klUCB, combines an efficient bandit algorithm, klUCB, with an efficient, parameter-free, change-point detector, the Bernoulli Generalized Likelihood Ratio Test, for which we provide new theoretical guarantees of independent interest. We analyze two variants of our strategy, based on local restarts and global restarts, and show that their regret is upper-bounded by O(Υ_T √(T log(T))) if the number of change-points Υ_T is unknown, and by O(√(Υ_T T log(T))) if Υ_T is known. This matches the current state-of-the-art bounds, as our algorithm needs no tuning based on knowledge of the problem complexity other than Υ_T. We present numerical experiments showing that GLR-klUCB outperforms passively and actively adaptive algorithms from the literature, and highlight the benefit of using local restarts.
See : https://hal.inria.fr/hal-02006471/
Format : 4:3
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
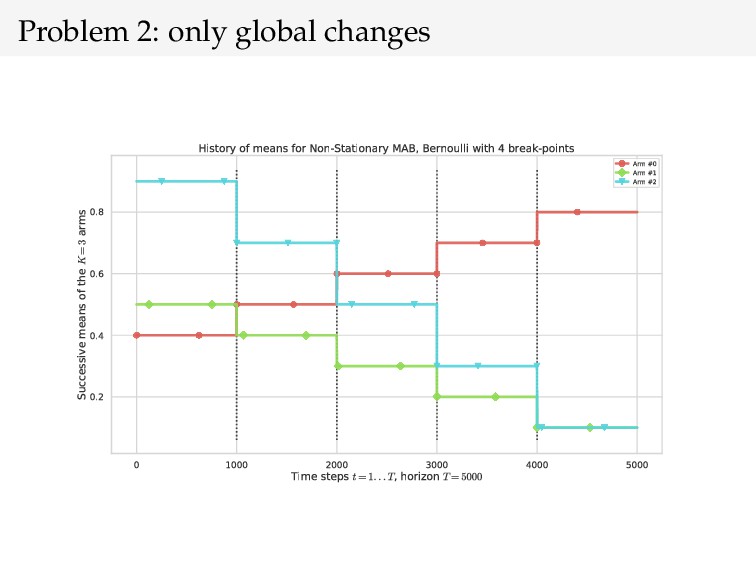{kind=link}
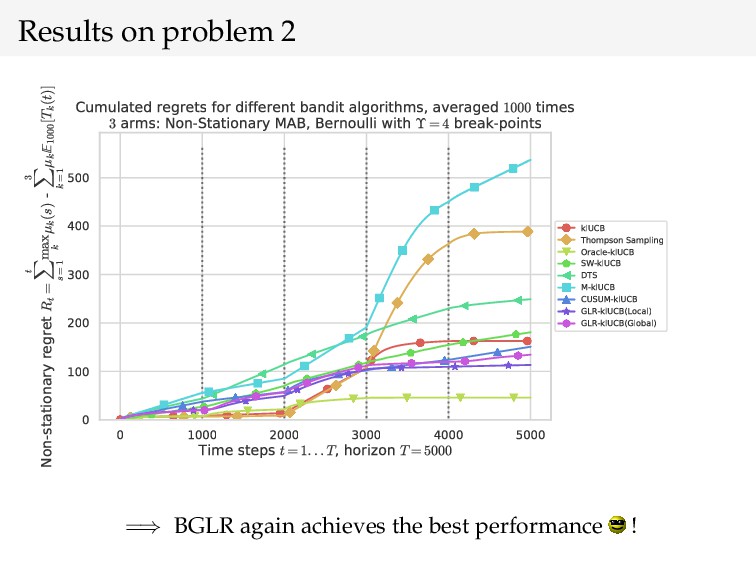{kind=link}
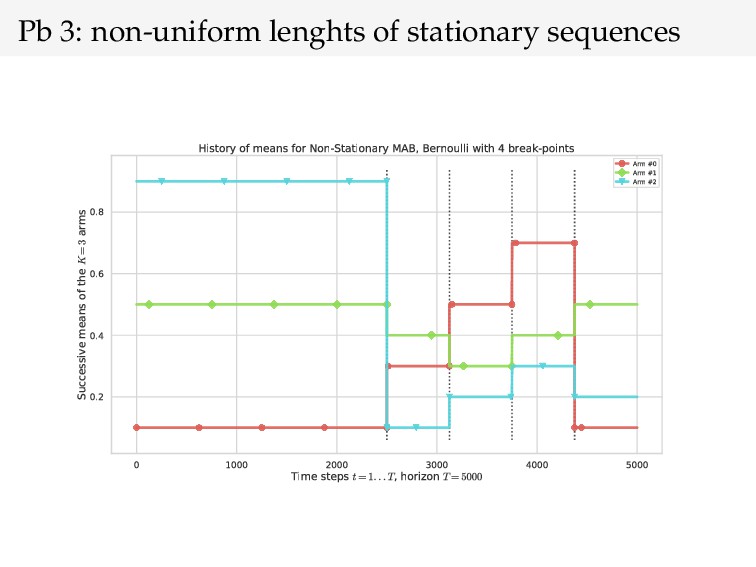{kind=link}
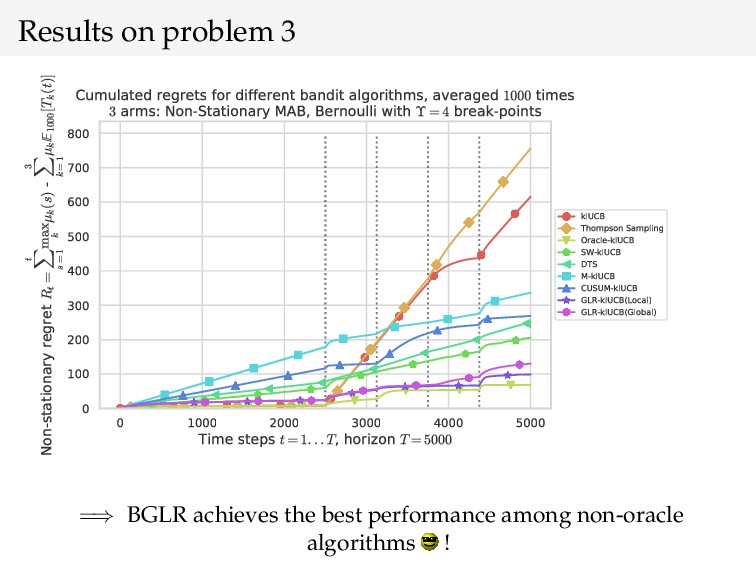{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}