- Speakers: Christophe Moy and Lilian Besson
- Title of the talk: Reinforcement learning for on-line dynamic spectrum access: theory and experimental validation
- Abstract:
This tutorial covers both theoretical and implementation aspects of on-line machine learning for dynamic spectrum access in order to solve spectrum scarcity issue. We target in this work efficient and ready-to-use solutions in real radio operation conditions, at an affordable electronic price, even in embedded devices.
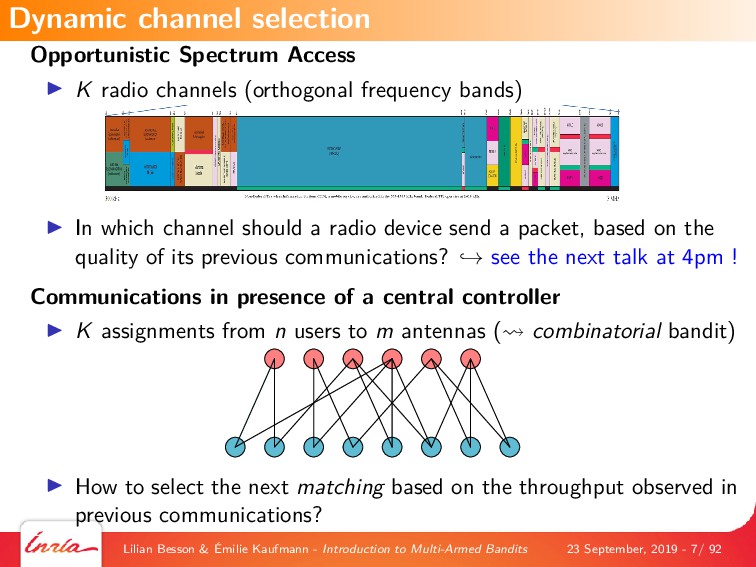
We focus on two wireless applications in this presentation: Opportunistic Spectrum Access (OSA) and Internet of Things (IoT) networks. OSA is the scenario that has been first targeted in the early 2010s, and is a futuristic scenario that has not been regulated yet. Internet of Things has known a more recent interest and revealed to be also a potential candidate for the application of learning solutions of the Reinforcement Learning family as soon as now.
First part (Lilian BESSON): Introduction to Multi-Armed Bandits and Reinforcement Learning
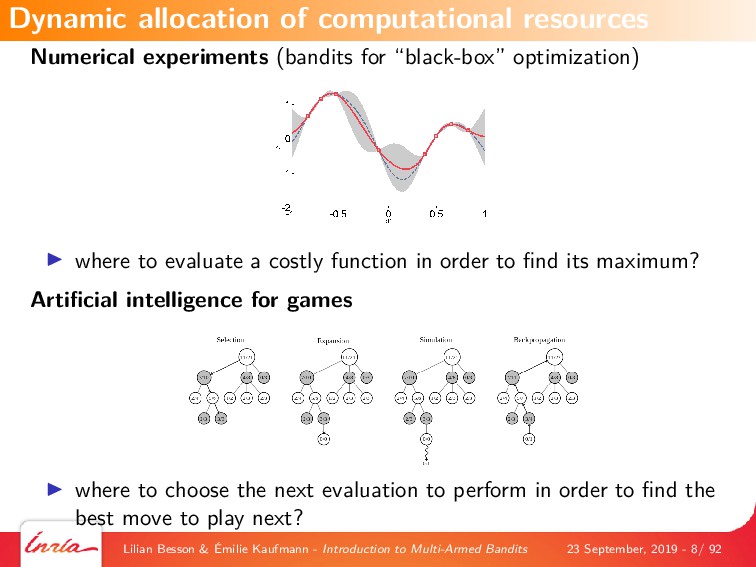
The first part of the tutorial introduces the general framework of machine learning, and focuses on reinforcement learning. We explain the model of multi-armed bandits (MAB), and we give an overview of different successful applications of MAB, since the 1950s.
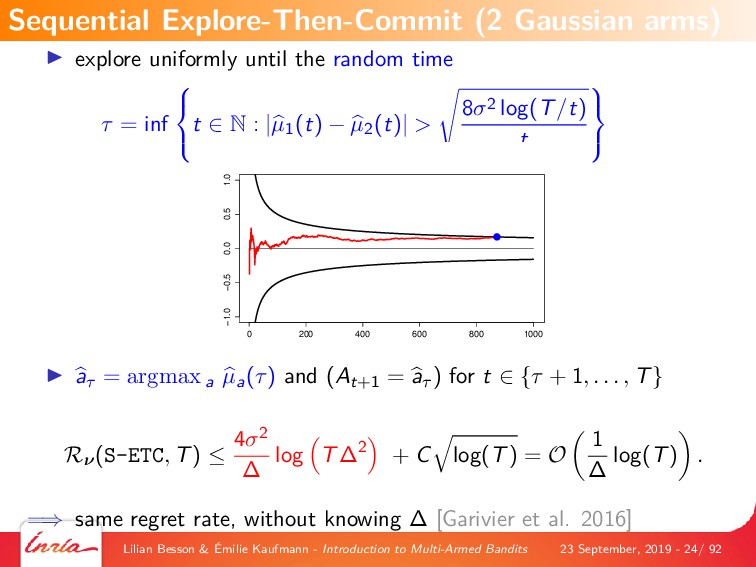
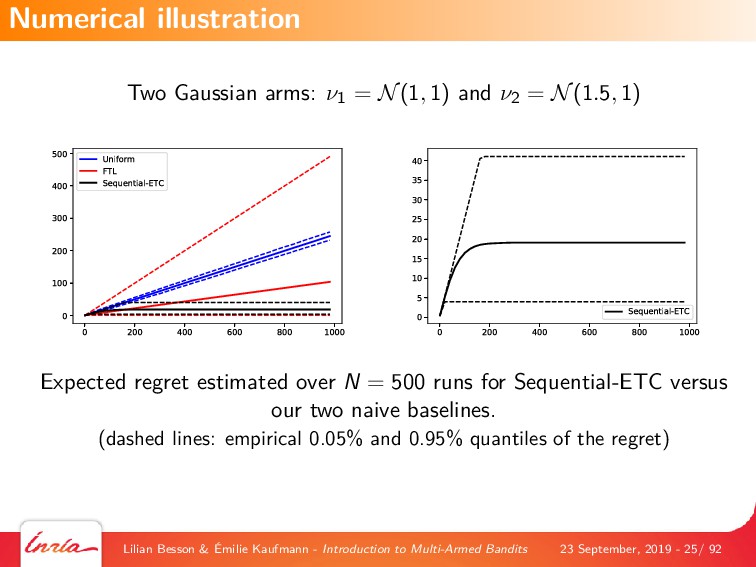
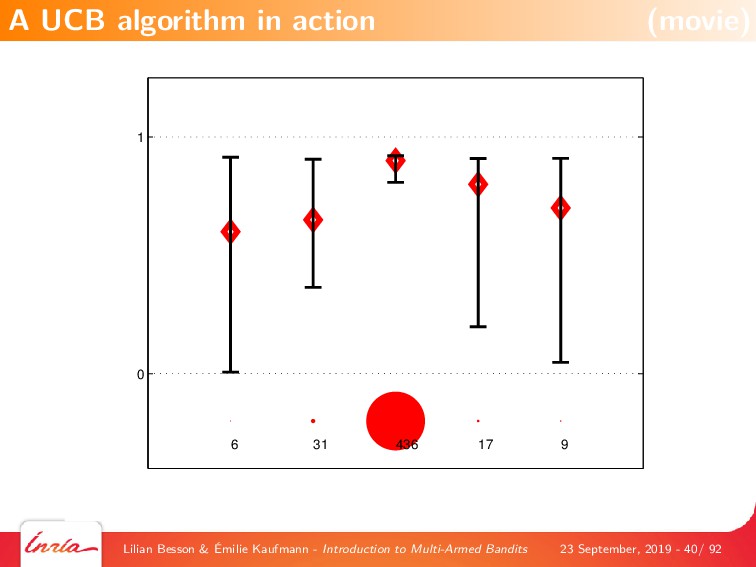
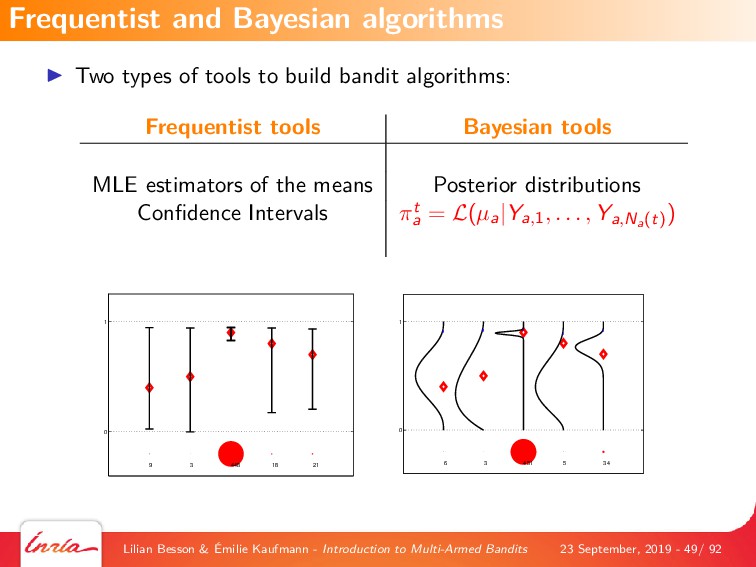
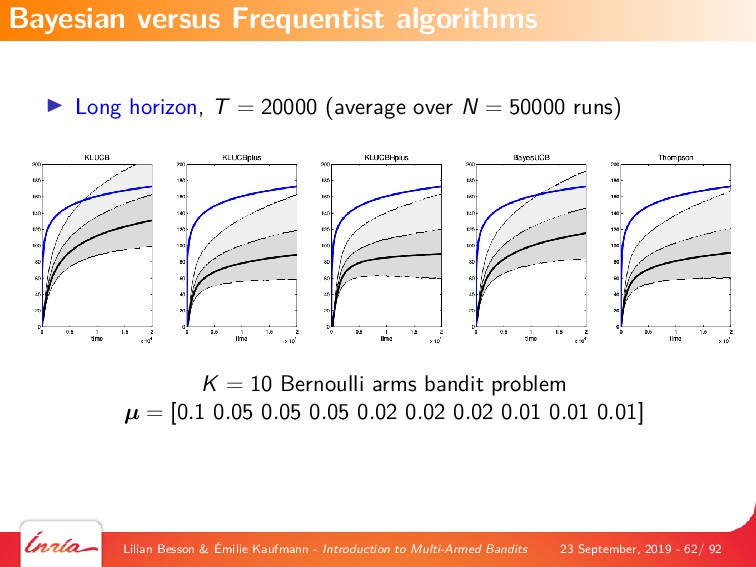
By first focusing on the simplest model, of a single player interacting with a stationary and stochastic (i.i.d) bandit game with a finite number of resources (or arms), we explain the most famous algorithms that are based on either a frequentist point-of-view, with Upper-Confidence Bounds (UCB) index policies (UCB1 and kl-UCB), or a Bayesian point-of-view, with Thompson Sampling. We also give details on the theoretical analyses of this model, by introducing the notion of regret which is a measure of performance of a MAB algorithm, and famous results from the literature on MAB algorithms, covering both what no algorithm can achieve (ie, lower-bounds on the performance on any algorithm), and what a good algorithm can indeed achieve (ie, upper-bounds on the performance of some efficient algorithms).
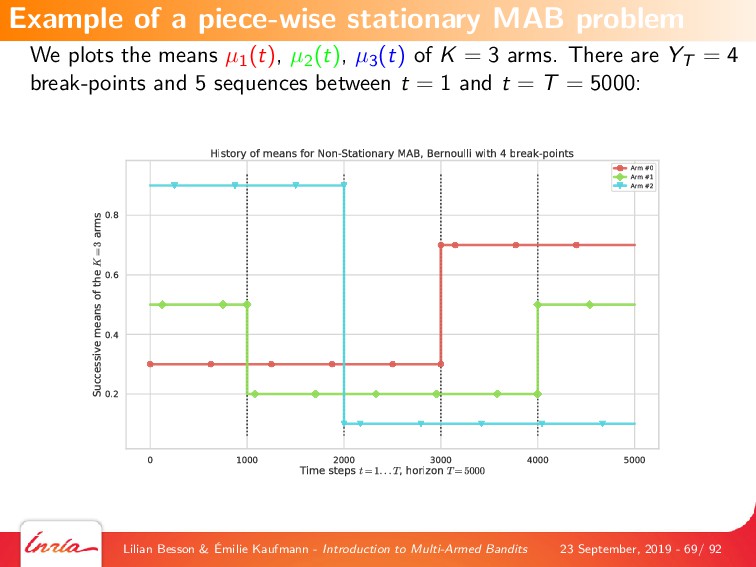
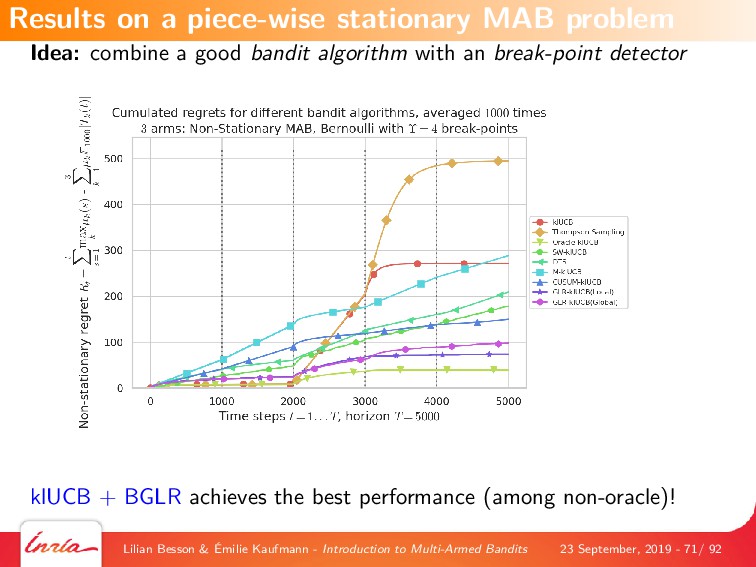
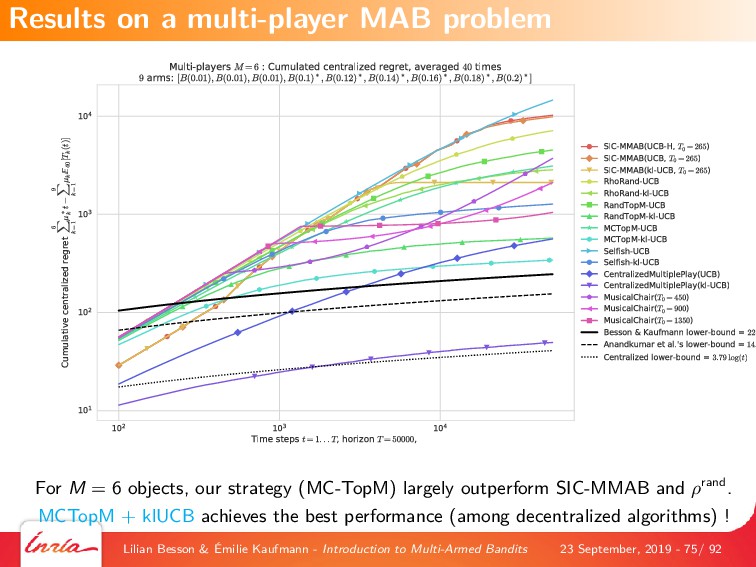
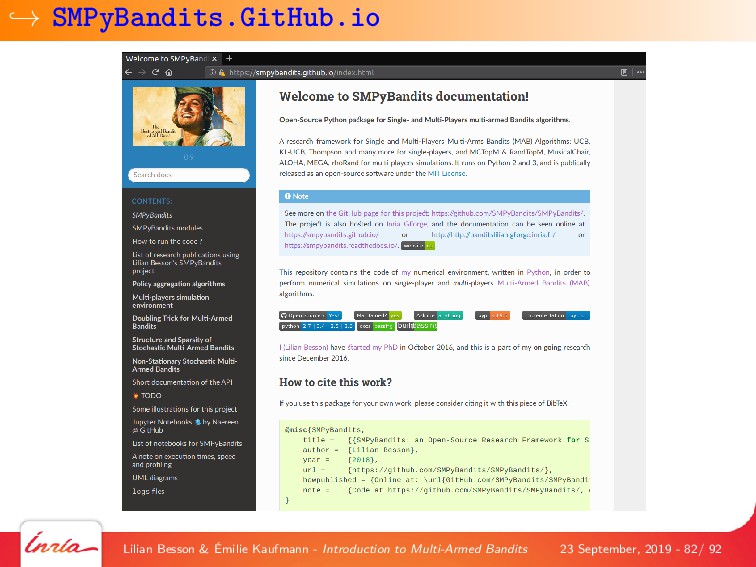
We also introduce some generalizations of this first MAB model, by considering non-stationary stochastic environments, Markov models (either rested or restless), and multi-player models. Each variant is illustrated with numerical experiments, showcasing the most well-known and most efficient algorithms, using our state-of-the-art open-source library for numerical simulations of MAB problems, SMPyBandits (see https://SMPyBandits.github.io/).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Historical motivation [Thompson 1933] B(µ1) B(µ2) B(µ3) B(µ4) B(µ5) For](https://files.speakerdeck.com/presentations/e021c0ba2512454fb2dbe4ba5c202d48/slide_18.jpg){kind=link}
![Modern motivation ($$$$) [Li et al, 2010] (recommender systems, online](https://files.speakerdeck.com/presentations/e021c0ba2512454fb2dbe4ba5c202d48/slide_19.jpg){kind=link}
![Opportunistic spectrum access [Zhao et al. 10] [Anandkumar et al.](https://files.speakerdeck.com/presentations/e021c0ba2512454fb2dbe4ba5c202d48/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![The ε-greedy rule [Sutton and Barton, 98] is the simplest](https://files.speakerdeck.com/presentations/e021c0ba2512454fb2dbe4ba5c202d48/slide_46.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Theorem [Auer et al, 02] UCB(α) with parameter α =](https://files.speakerdeck.com/presentations/e021c0ba2512454fb2dbe4ba5c202d48/slide_60.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
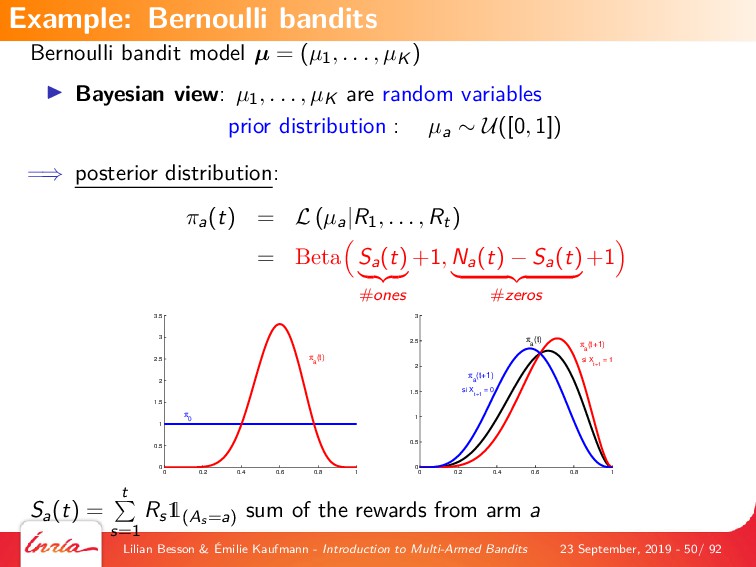{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
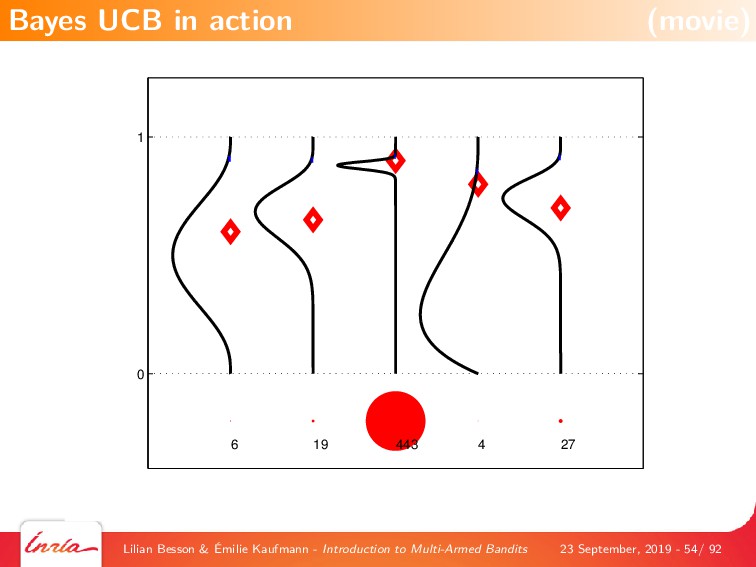{kind=link}
![Bayes-UCB is asymptotically optimal for Bernoulli rewards Theorem [K.,Cappé,Garivier 2012]](https://files.speakerdeck.com/presentations/e021c0ba2512454fb2dbe4ba5c202d48/slide_75.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Problem-dependent regret ∀ε > 0, Eµ[Na(T)] ≤ 1 + ε](https://files.speakerdeck.com/presentations/e021c0ba2512454fb2dbe4ba5c202d48/slide_79.jpg){kind=link}
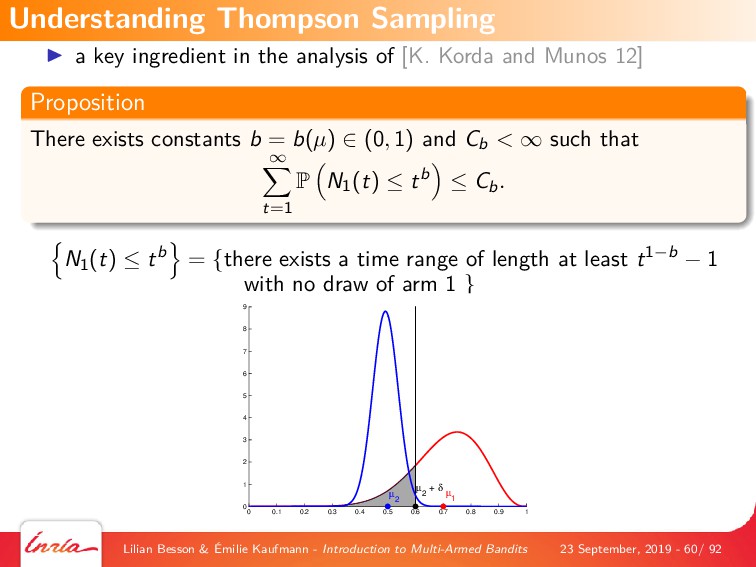{kind=link}
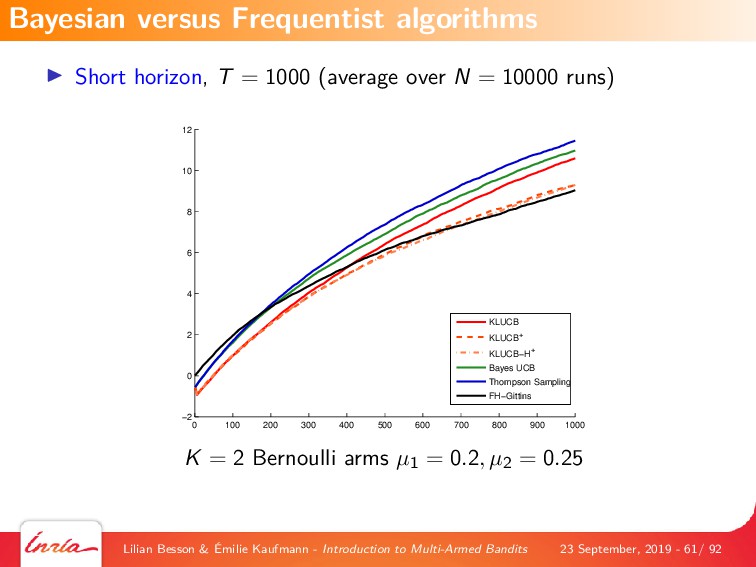{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}