Share
株式会社ニューロジカのテックブログを公開しました。
採用ポジション:https://speakerdeck.com/neurogica/recruitment-position HP:https://neurogica.com お問い合わせ:[email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
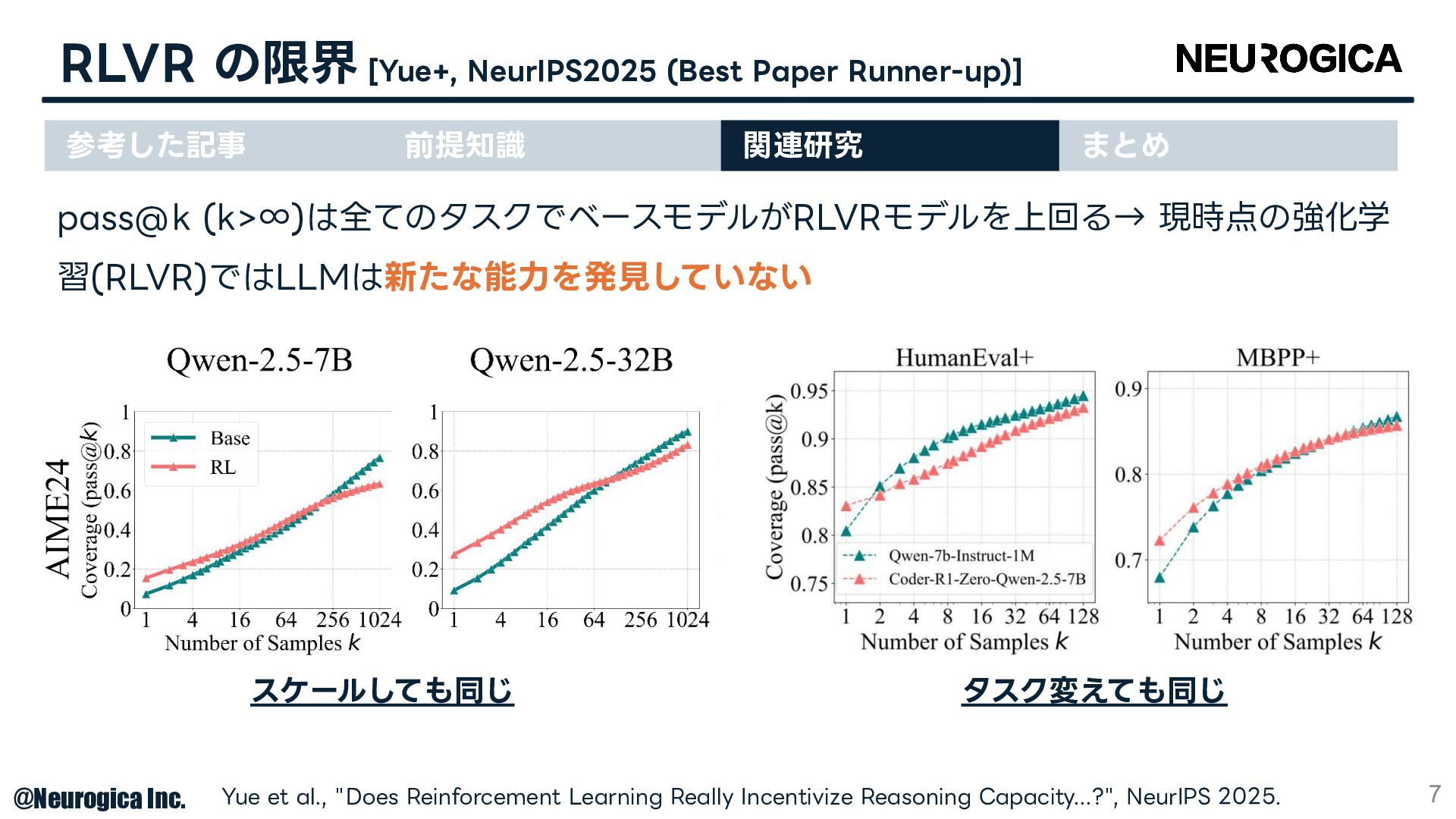
![RLVR の限界 [Yue+, NeurIPS2025 (Best Paper Runner-up)] 6 Yue et](https://files.speakerdeck.com/presentations/fd241b16dcf64cb79bab93dee71d5d7f/slide_5.jpg){kind=link}
{kind=link}
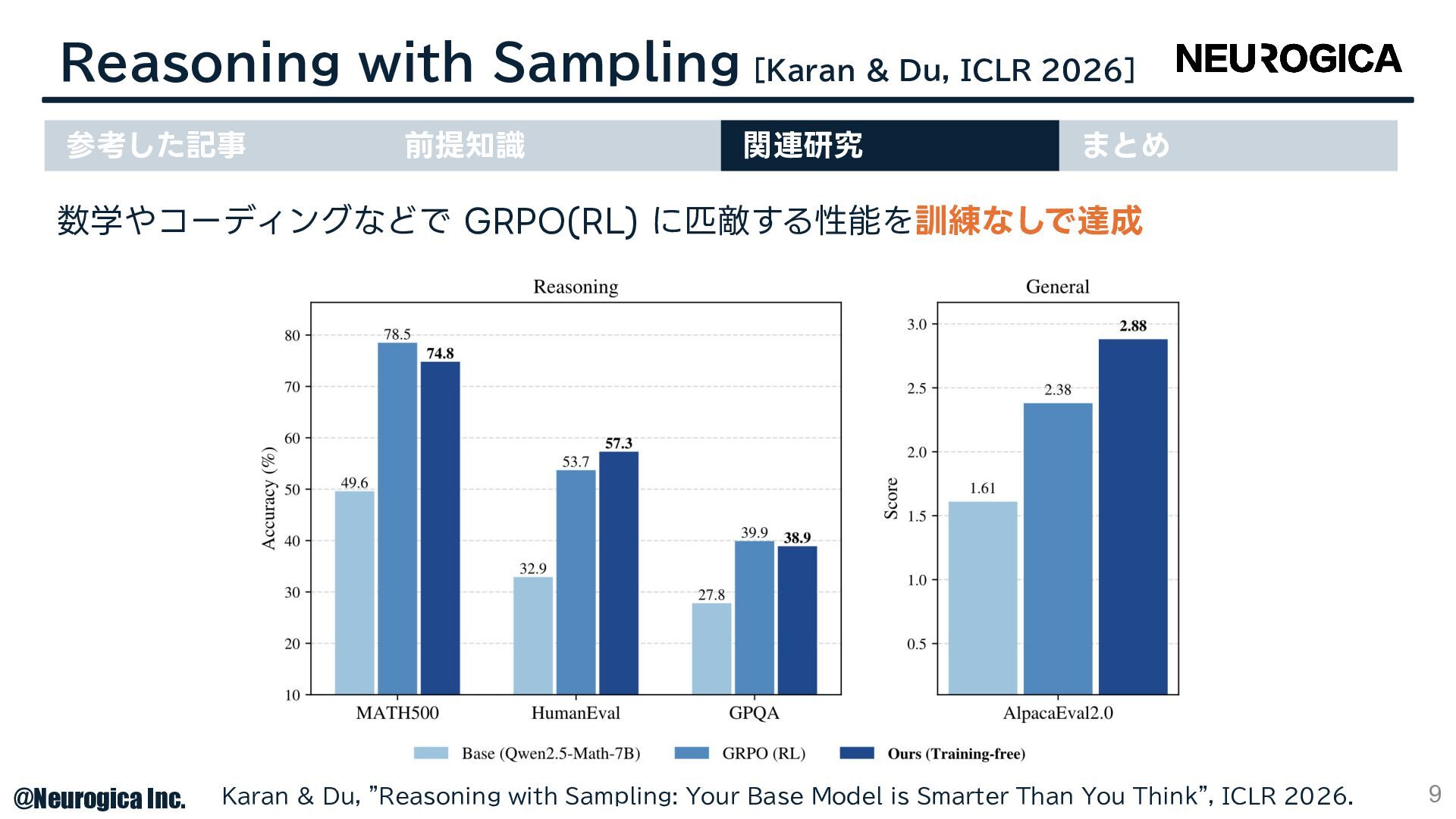
![Reasoning with Sampling [Karan & Du, ICLR 2026] 8 Karan](https://files.speakerdeck.com/presentations/fd241b16dcf64cb79bab93dee71d5d7f/slide_7.jpg){kind=link}
{kind=link}
![Prolonged RL [Liu+, NeurIPS2025] 10 Liu et al., "ProRL: Prolonged](https://files.speakerdeck.com/presentations/fd241b16dcf64cb79bab93dee71d5d7f/slide_9.jpg){kind=link}
{kind=link}