Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AIは公平な評価, 決断を行えるか? 〜 LLM-as-a-Judgeの限界と意思決定バイア...
Search
Neurogica
May 04, 2026
Technology
50
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
AIは公平な評価, 決断を行えるか? 〜 LLM-as-a-Judgeの限界と意思決定バイアス 〜 Can AI Make Fair Evaluations and Decisions?
Neurogica
May 04, 2026
More Decks by Neurogica
See All by Neurogica
DBコネクションプール Database Connection Pooling
neurogica
0
21
時系列基盤モデルは作れるのか? Can We Build a Foundation Model for Time Series?
neurogica
0
80
双曲空間と機械学習 〜 階層性を活かした学習〜 Hyperbolic Space and Machine Learning ~ Learning that Leverages Hierarchical Structure ~
neurogica
0
30
PENGUIN: General Vital Sign Reconstruction from PPG with Flow Matching State Space Models | ICASSP 2026
neurogica
0
43
DecompSSM: A Decomposition-based State Space Model for Multivariate Time-Series Forecasting | ICASSP 2026
neurogica
0
62
最新の物体検出モデルに関するサーベイ A Survey of the Latest Object Detection Models
neurogica
0
75
強化学習はLLMの能力に何をもたらしたのか What has reinforcement learning added to LLM capabilities?
neurogica
0
41
生成モデルを用いた意味論的に自然な画像編集 Semantically coherent image editing with generative models
neurogica
0
27
複雑系科学を知ろう Introduction to Complex Systems
neurogica
0
41
Other Decks in Technology
See All in Technology
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
SRE歴2ヶ月でも開発6年の知見を活かして、チームで止まっていた環境改善を前に進めた話
a_ono
1
220
FinOps X 2026 Recap from Engineer Side #JapanFinOps
chacco38
0
270
『AIに負けない』より『AIと遊ぶ』」〜ワクワクが最強のテスト・QA学習戦略_公開用
odan611
2
540
AWS Blocks を触ってみた/first-tach-aws-blocks
fossamagna
2
150
脱金融のフューチャー・デザイン / Future Design Beyond Finance
ks91
PRO
0
140
ZOZOTOWNの進化と信頼性を両立する負荷試験
zozotech
PRO
0
150
スタートアップにおけるアジャイルの実践について #shibuyagile
murabayashi
3
2.1k
プロダクトだけじゃない、社内プロセスにおける自動化・省力化ノススメ
kakehashi
PRO
1
3.1k
CIで使うClaude
iwatatomoya
0
190
Terraform共通モジュールをチーム横断で“変えられる”運用へ ― リリースと適用の分離
kekke_n
1
2.1k
Road to SRE NEXTの今までとこれから
hiroyaonoe
0
240
Featured
See All Featured
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
Design in an AI World
tapps
1
260
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
240
How to Talk to Developers About Accessibility
jct
2
290
Distributed Sagas: A Protocol for Coordinating Microservices
caitiem20
333
23k
Java REST API Framework Comparison - PWX 2021
mraible
34
9.4k
Designing for Timeless Needs
cassininazir
1
280
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.3k
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
260
The Psychology of Web Performance [Beyond Tellerrand 2023]
tammyeverts
49
3.5k
Code Review Best Practice
trishagee
74
20k
Transcript
AIは公平な評価, 決断を⾏えるか? 〜 LLM-as-a-Judgeの限界と意思決定バイアス 〜 株式会社ニューロジカ 開発部 三ツ井 智哉 AIは公平な評価,
決断を⾏えるか? 〜 LLM-as-a-Judgeの限界と意思決定バイアス 〜
⾃然⾔語⽣成(NLG)の評価 • ⼈間による評価:コストが⾼く時間がかかる • Large Language Models (LLMs) による評価:低コスト、時短 G-Eval
(EMNLP 2023) [1] • GPT-4などのLLMをNLGの評価者として利⽤ • Chain-of-Thought(CoT)などを活⽤し, ⼈間の評価との⾼い相関を実現 1,000件のモデル応答 LLM as a Judge とは © Neurogica Inc. はじめに [1] Liu, Yang, et al. "G-eval: NLG evaluation using gpt-4 with better human alignment." Proceedings of the 2023 conference on empirical methods in natural language processing. 2023. 問題点 解決案 エージェント まとめ 数⽇〜数週間 数⼗万円 ⼈によりばらつき 数分 数万円 同⼀の基準 ⼈間 LLM
Large Language Models are not Fair Evaluators (ACL 2024) [2]
• LLMの位置バイアスの実証 • “AとB, どちらの出⼒が良いか?” という⽐較において, 選択肢の提⽰順(AとB)を⼊れ替えるだけで勝敗判定が変化 • 順番を⼊れ替えた結果を平均化する⼯夫が必要 LLM as a Judge の問題点 ① はじめに [2] Wang, Peiyi, et al. "Large language models are not fair evaluators." Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. 問題点 解決案 エージェント まとめ Which response is better? Response 1: … Response 2: … Which response is better? Response 1: … Response 2: … Response 1: … Response 2: … LLM Judge © Neurogica Inc.
Self-Preference Bias in LLM-as-a-Judge (NeurIPS 2024 Workshop) [3] • LLMは⾃⾝の⽣成物を不当に⾼く評価してしまう傾向
• モデルにとって馴染みやすい, 予測しやすい⽂章を⾼く評価 • ⽣成側と評価側のスタイルの相性が混⼊ LLM as a Judge の問題点 ② はじめに [3] Wataoka, Koki, Tsubasa Takahashi, and Ryokan Ri. "Self-Preference Bias in LLM-as-a-Judge." Neurips Safe Generative AI Workshop 2024. 問題点 解決案 エージェント まとめ © Neurogica Inc.
Pairwise or Pointwise? (COLM 2025) [4] • 評価プロトコル⾃体の違いによるバイアスの受けやすさを⽐較 • Pairwise(A/B⽐較):順番の⼊れ替えなどで評価が逆転する割合が約35%
と⾼い • Pointwise(絶対評価・スコアリング):評価のブレが約9%に留まり, より ノイズに対して頑健 問題の解決案 はじめに [4] Tripathi, Tuhina, et al. "Pairwise or Pointwise? Evaluating Feedback Protocols for Bias in LLM-Based Evaluation." Second Conference on Language Modeling., 2025 問題点 解決案 エージェント まとめ Which response is better? Response 1: … Response 2: … Scoring this response Response 1: … Pairwise Pointwise © Neurogica Inc..
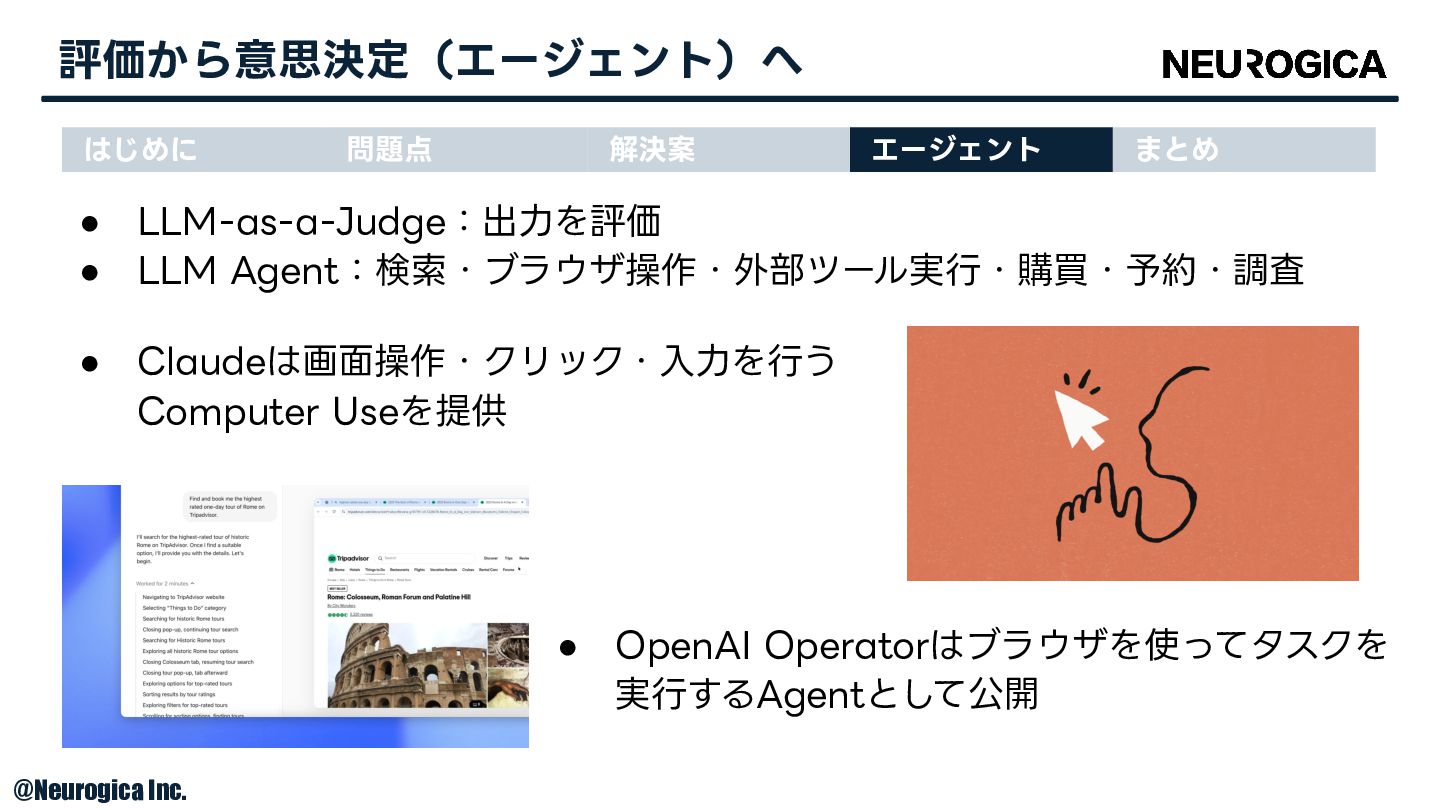
• LLM-as-a-Judge:出⼒を評価 • LLM Agent:検索・ブラウザ操作・外部ツール実⾏・購買・予約・調査 評価から意思決定(エージェント)へ はじめに 問題点 解決案 エージェント
まとめ • Claudeは画⾯操作・クリック・⼊⼒を⾏う Computer Useを提供 • OpenAI Operatorはブラウザを使ってタスクを 実⾏するAgentとして公開 © Neurogica Inc.
Actions Speak Louder than Words [5] • 差別的な回答をしないよう調整されたLLMでも, エージェントとしての意思決 定には潜在的な社会的バイアス
エージェントにおけるバイアス ① はじめに [5] Li, Yuxuan, Hirokazu Shirado, and Sauvik Das. "Actions speak louder than words: Agent decisions reveal implicit biases in language models." Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency. 2025. 問題点 解決案 エージェント まとめ • LLMにペルソナを与え, 避難・融資・採⽤などの 意思決定シナリオで⽐較 • ほぼすべてのシミュレー ションで有意な意思決定 格差が観測 © Neurogica Inc.
What Is Your AI Agent Buying? [6] • LLM購買エージェントについて, モデルごとの選好バ
イアスを実証 • 商品の位置, 価格, レビュー数, 広告タグの有無などに 対する感応度がモデルごと, 世代ごとに異なる. エージェントにおけるバイアス ② はじめに [6] Allouah, Amine, et al. "What Is Your AI Agent Buying? Evaluation, Biases, Model Dependence, & Emerging Implications of Agentic E-Commerce." Proceedings of the ACM Web Conference 2026. 問題点 解決案 エージェント まとめ ←位置バイアスを⽰す タグや評価による→ 影響を⽰す © Neurogica Inc.
まとめ はじめに 問題点 解決案 エージェント まとめ LLM評価の問題 • 選択肢の順番にバイア スが存在
• 評価するモデルと同じ モデルの⽣成物を⾼く 評価 エージェントへの進化 • テキスト評価だけでな く操作, 意思決定も • LLMの意思決定にもバ イアスが存在 © Neurogica Inc.. LLM as a Judge ⼈間と近い評価を⼈間よりは るかに短時間低コストで実⾏ 可能
{kind=link}
{kind=link}
![Large Language Models are not Fair Evaluators (ACL 2024) [2]](https://files.speakerdeck.com/presentations/81febfed64f44f97988e5c2469a90545/slide_2.jpg){kind=link}
![Self-Preference Bias in LLM-as-a-Judge (NeurIPS 2024 Workshop) [3] • LLMは⾃⾝の⽣成物を不当に⾼く評価してしまう傾向](https://files.speakerdeck.com/presentations/81febfed64f44f97988e5c2469a90545/slide_3.jpg){kind=link}
![Pairwise or Pointwise? (COLM 2025) [4] • 評価プロトコル⾃体の違いによるバイアスの受けやすさを⽐較 • Pairwise(A/B⽐較):順番の⼊れ替えなどで評価が逆転する割合が約35%](https://files.speakerdeck.com/presentations/81febfed64f44f97988e5c2469a90545/slide_4.jpg){kind=link}
{kind=link}
![Actions Speak Louder than Words [5] • 差別的な回答をしないよう調整されたLLMでも, エージェントとしての意思決 定には潜在的な社会的バイアス](https://files.speakerdeck.com/presentations/81febfed64f44f97988e5c2469a90545/slide_6.jpg){kind=link}
![What Is Your AI Agent Buying? [6] • LLM購買エージェントについて, モデルごとの選好バ](https://files.speakerdeck.com/presentations/81febfed64f44f97988e5c2469a90545/slide_7.jpg){kind=link}
{kind=link}