Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
最新の物体検出モデルに関するサーベイ A Survey of the Latest Objec...
Search
Neurogica
April 21, 2026
Technology
75
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
最新の物体検出モデルに関するサーベイ A Survey of the Latest Object Detection Models
Neurogica
April 21, 2026
More Decks by Neurogica
See All by Neurogica
DBコネクションプール Database Connection Pooling
neurogica
0
21
時系列基盤モデルは作れるのか? Can We Build a Foundation Model for Time Series?
neurogica
0
80
双曲空間と機械学習 〜 階層性を活かした学習〜 Hyperbolic Space and Machine Learning ~ Learning that Leverages Hierarchical Structure ~
neurogica
0
30
PENGUIN: General Vital Sign Reconstruction from PPG with Flow Matching State Space Models | ICASSP 2026
neurogica
0
43
DecompSSM: A Decomposition-based State Space Model for Multivariate Time-Series Forecasting | ICASSP 2026
neurogica
0
62
AIは公平な評価, 決断を行えるか? 〜 LLM-as-a-Judgeの限界と意思決定バイアス 〜 Can AI Make Fair Evaluations and Decisions?
neurogica
0
50
強化学習はLLMの能力に何をもたらしたのか What has reinforcement learning added to LLM capabilities?
neurogica
0
41
生成モデルを用いた意味論的に自然な画像編集 Semantically coherent image editing with generative models
neurogica
0
27
複雑系科学を知ろう Introduction to Complex Systems
neurogica
0
41
Other Decks in Technology
See All in Technology
ヘルスケア領域における AI 活用と その安全性担保のための取り組み (Leveraging AI in Healthcare and Our Efforts to Ensure Its Safety) - Google I/O Extended Tokyo 2026, July 11, 2026
zettaittenani
0
230
依頼文化をやめる日 EM視点で語るPlatform EngineeringとInclusive SRE / Discussing Platform Engineering and Inclusive SRE from an EM's Perspective
shin1988
4
4.6k
なぜ人は自分のプロジェクトを 「なんちゃってアジャイル」と 自嘲するのか
kozotaira
0
270
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.4k
Amazon EVS で VCF 9.0 / 9.1 のサポート開始まとめ
mtoyoda
0
280
小さいから、全部わかる。— 常駐AI "xangi" のすすめ
sugupoko
0
280
Compose 新機能総まとめ / What's New in Jetpack Compose
yanzm
0
150
Terraform共通モジュールをチーム横断で“変えられる”運用へ ― リリースと適用の分離
kekke_n
1
2.2k
Keeping applications secure by evolving OAuth 2.0 and OpenID Connect
ahus1
PRO
1
150
AIDLC_ヤフーショッピングの取り組み
lycorptech_jp
PRO
0
580
初めてのDatabricks勉強会
taka_aki
2
250
Baseline対応のDOMの型定義を作った
uhyo
3
720
Featured
See All Featured
Chasing Engaging Ingredients in Design
codingconduct
0
230
Ethics towards AI in product and experience design
skipperchong
2
320
The Spectacular Lies of Maps
axbom
PRO
1
850
The Success of Rails: Ensuring Growth for the Next 100 Years
eileencodes
47
8.2k
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
Between Models and Reality
mayunak
4
370
Designing Experiences People Love
moore
143
24k
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
Paper Plane
katiecoart
PRO
1
52k
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
170
A Soul's Torment
seathinner
6
3k
Art, The Web, and Tiny UX
lynnandtonic
304
22k
Transcript
最新の物体検出モデルに関するサーベイ 株式会社ニューロジカ 開発部 佐藤太陽 最新の物体検出モデルに関するサーベイ
1. はじめに:物体検出とは 2. YOLO ・YOLO26(2026) ・YOLO-World(2024) 3. DETR ・RT-DETRv4(2025) 4.
SAM ・SAM3(2025) 5. まとめ アジェンダ アジェンダ はじめに YOLO DETR SAM まとめ © Neurogica Inc.
物体検出とは? アジェンダ はじめに YOLO DETR SAM まとめ Microsoft coco: Common
objects in context (ECCV 2014) https://arxiv.org/abs/1405.0312 person sheep dog person sheep background dog 1. 画像分類 (Image Classification) 画像全体を分析し、 「何が写っているか」を特定。 出⼒:クラス名(⼈、⽺など) 2. 物体検出 (Object Detection) 画像内の特定の物体の 「位置」と「種類」を特定。 出⼒:四⾓い枠とクラス名 3. セグメンテーション (Segmentation) 画像をピクセル単位で分類し、 物体の「形状」を特定。 出⼒:マスク画像 物体検出の活⽤例:⾃動運転、製造業での異常検知、医⽤画像診断など © Neurogica Inc.
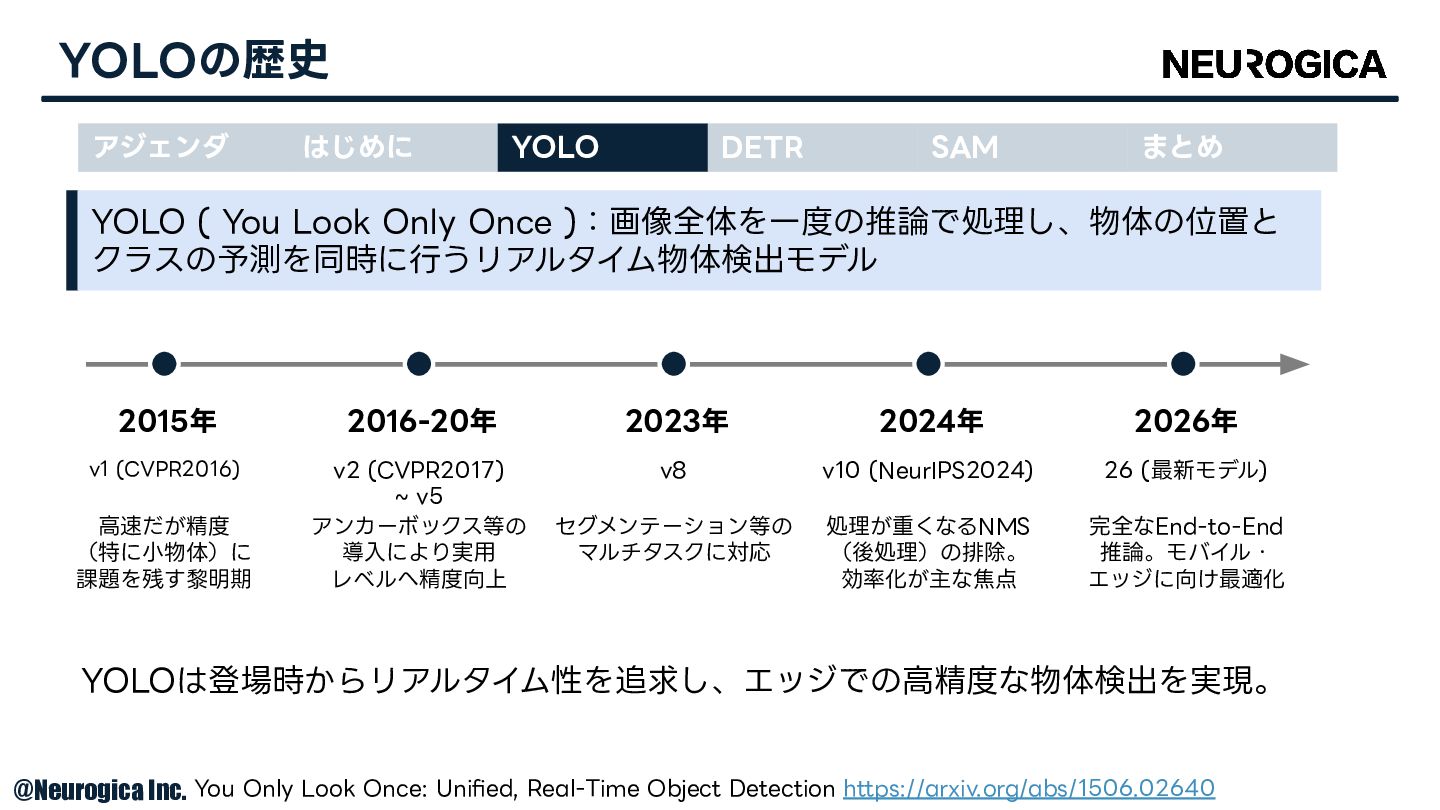
v1 (CVPR2016) YOLOの歴史 YOLO ( You Look Only Once ):画像全体を⼀度の推論で処理し、物体の位置と
クラスの予測を同時に⾏うリアルタイム物体検出モデル 2015年 2016-20年 2023年 2024年 2026年 v2 (CVPR2017) ~ v5 v8 v10 (NeurIPS2024) 26 (最新モデル) ⾼速だが精度 (特に⼩物体)に 課題を残す黎明期 アンカーボックス等の 導⼊により実⽤ レベルへ精度向上 セグメンテーション等の マルチタスクに対応 処理が重くなるNMS (後処理)の排除。 効率化が主な焦点 完全なEnd-to-End 推論。モバイル・ エッジに向け最適化 YOLOは登場時からリアルタイム性を追求し、エッジでの⾼精度な物体検出を実現。 You Only Look Once: Unified, Real-Time Object Detection https://arxiv.org/abs/1506.02640 アジェンダ はじめに YOLO DETR SAM まとめ © Neurogica Inc.
YOLO26 対応タスク 物体検出、セグメンテーション、姿勢推定、OBB、 画像分類 学習・必要データ 教師あり学習。実⽤には1クラスあたり100〜1,000 枚の画像データ(アノテーション済み)が必要。 エッジデバイスでの運⽤可能性 パラメータ数は2.4Mから55.7Mなので搭載可能。 CPUでの処理速度も⼗分速い。
YOLO26: Key Architectural Enhancements and Performance Benchmarking for Real-Time Object Detection https://arxiv.org/abs/2509.25164 アジェンダ はじめに YOLO DETR SAM まとめ https://www.youtube.com/watch?v=pJLXmhyuHzA © Neurogica Inc.
YOLO-World (CVPR2024) 対応タスク テキスト条件付きOpen-Vocabulary物体検出 アジェンダ はじめに YOLO DETR SAM まとめ
学習・必要データ 膨⼤な視覚・⾔語ペアデータで事前学習済み。 追加学習データなし(ゼロショット)で利⽤可能。 エッジデバイスでの運⽤可能性 パラメータ数は13Mから48Mなので搭載可能。 YOLO-World: Real-Time Open-Vocabulary Object Detection https://arxiv.org/abs/2401.17270 プロンプト条件なし検出とプロンプト条件あり検出 https://www.youtube.com/watch?v=sWEm3dIGKU8 © Neurogica Inc.
DETRの歴史 アジェンダ はじめに YOLO DETR SAM まとめ DETR (ECCV2020) DETR
( Detection TRansformer):TransformerのAttention機構を利⽤して、画 像全体の⽂脈を⼀度に把握する物体検出モデル 2020年 2021年 2023年 2024-26年 Deformable DETR (ICLR2021) DINO (ICLR2023) RT-DETR (CVPR2024) シリーズ パラダイムシフトを起こすが 学習(収束)に膨⼤な時間が かかった 画像の⼀部のみに注⽬すること で収束を速め、計算量・メモリ 削減 ノイズを活⽤した学習 により検出精度向上。 ⾃⼰教師あり学習の DINOとは別物 DINOをベースに更に効率化。 YOLOに匹敵する速度を獲得 DETRは⾼精度だが速度が遅かった。その後の改良によりYOLOに匹敵する速度を獲得。 End-to-End Object Detection with Transformers https://arxiv.org/abs/2005.12872 © Neurogica Inc.
RT-DETRv4 アジェンダ はじめに YOLO DETR SAM まとめ 対応タスク 物体検出(※内部で物体候補の分類は⾏うが、画像 分類モデルとしては⽤いない。)
学習・必要データ 教師あり学習。基盤モデルからの蒸留を活⽤するた め、必要数は⽐較的少ない(具体的な枚数不明)。 エッジデバイスでの運⽤可能性 パラメータ数は10Mから62Mなので搭載可能。 CPUでの処理速度も⼗分速い。 RT-DETRv4: Painlessly Furthering Real-Time Object Detection with Vision Foundation Models https://arxiv.org/abs/2510.25257 https://github.com/RT-DETRs/RT-DETRv4 © Neurogica Inc.
SAMの歴史 アジェンダ はじめに YOLO DETR SAM まとめ SAM1 (ICCV2023) SAM
( Segment Anything Model ):セグメンテーションに特化した、膨⼤な量の データセットで学習された視覚基盤モデル 2023年 2024年 2025年 SAM2 SAM3 (ICLR2026) 1,100万枚以上の画像と11億以上の マスクのデータセットで学習。 点や枠を与えるとその物体だけを 切り抜く 対象を動画へ拡張。⼀度プロンプト で指定した物体を⾼速に トラッキング可能 テキストプロンプトで⾃由に全てを 切り抜き可能 SAMはセグメンテーション分野に対して、プロンプト指⽰というパラダイムを導⼊。 End-to-End Object Detection with Transformers https://arxiv.org/abs/2005.12872 © Neurogica Inc.
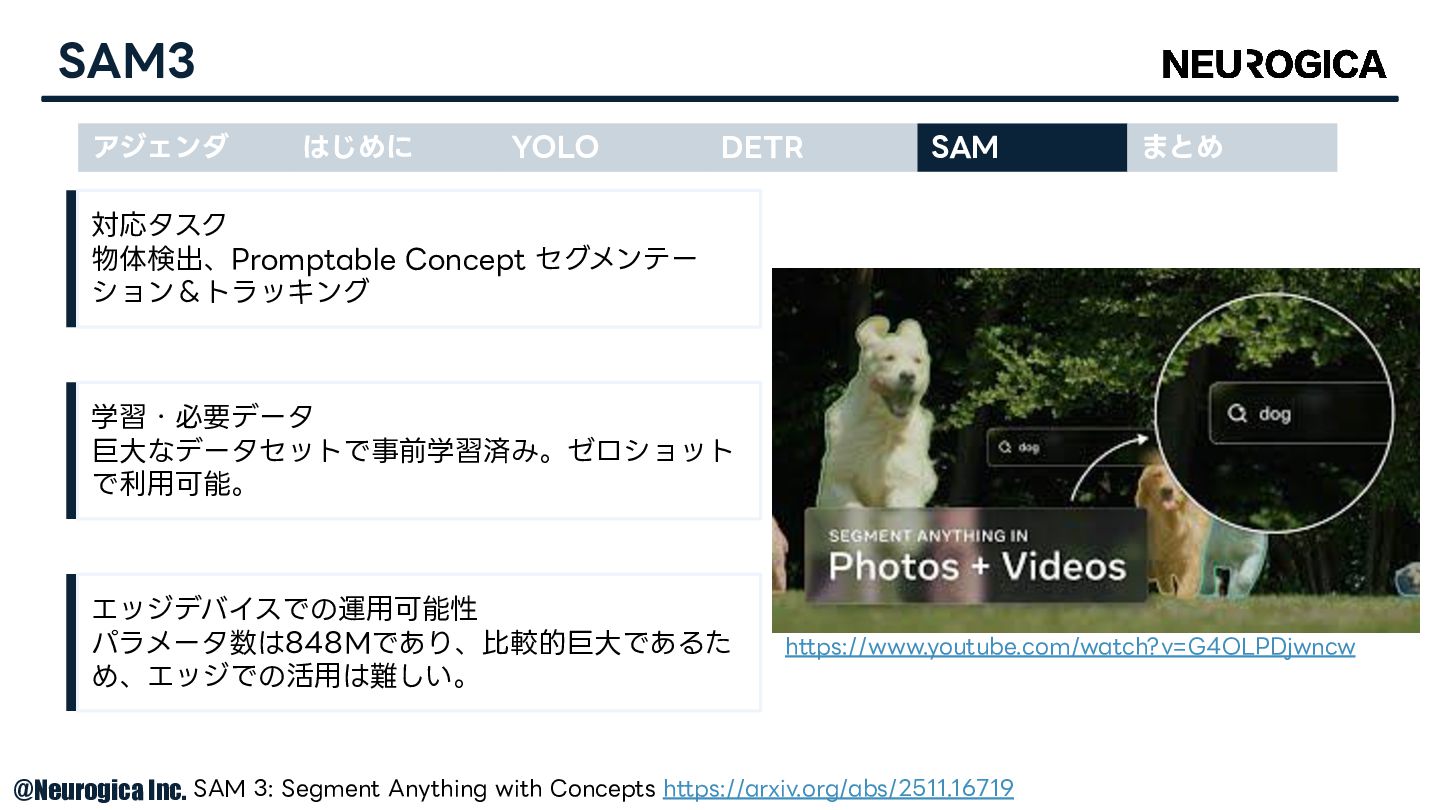
SAM3 アジェンダ はじめに YOLO DETR SAM まとめ 対応タスク 物体検出、Promptable Concept
セグメンテー ション&トラッキング 学習・必要データ 巨⼤なデータセットで事前学習済み。ゼロショット で利⽤可能。 エッジデバイスでの運⽤可能性 パラメータ数は848Mであり、⽐較的巨⼤であるた め、エッジでの活⽤は難しい。 SAM 3: Segment Anything with Concepts https://arxiv.org/abs/2511.16719 https://www.youtube.com/watch?v=G4OLPDjwncw © Neurogica Inc.
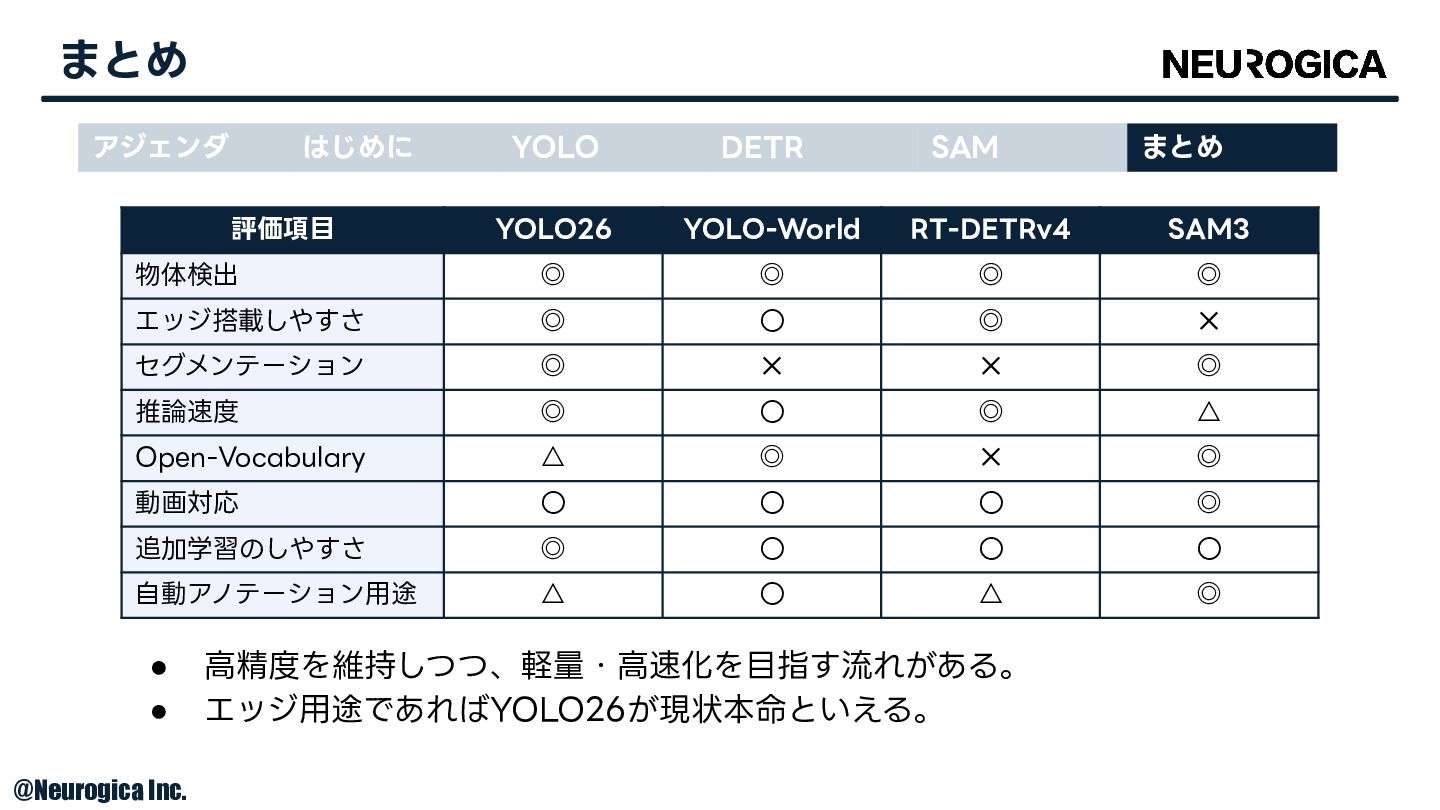
まとめ アジェンダ はじめに YOLO DETR SAM まとめ 評価項⽬ YOLO26 YOLO-World
RT-DETRv4 SAM3 物体検出 ◎ ◎ ◎ ◎ エッジ搭載しやすさ ◎ 〇 ◎ ✕ セグメンテーション ◎ ✕ ✕ ◎ 推論速度 ◎ 〇 ◎ △ Open-Vocabulary △ ◎ ✕ ◎ 動画対応 〇 〇 〇 ◎ 追加学習のしやすさ ◎ 〇 〇 〇 ⾃動アノテーション⽤途 △ 〇 △ ◎ • ⾼精度を維持しつつ、軽量・⾼速化を⽬指す流れがある。 • エッジ⽤途であればYOLO26が現状本命といえる。 © Neurogica Inc.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}