2005, doubling every year ~125 million messages per second in 2015 • Finance & telco: fraud detection • Online advertising: personalized ads • Computer networks: monitor security attacks e.g. DOS • Manufacturing: process control and automation • Sensor networks: monitoring applications e.g. congestion-based tolling on highways, real-time traffic routing
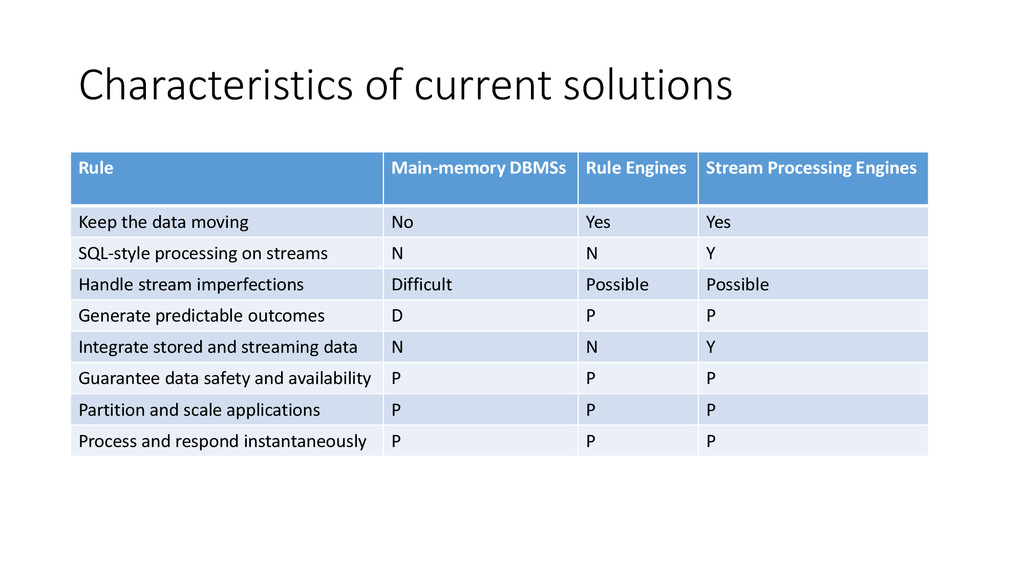
data 6. Guarantee data safety and availability 7. Partition and scale automatically 8. Process and response instantaneously Paper: The 8 requirements of real-time stream processing by Stonebraker, Cetintemel, Zdonik, ACM SIGMOD 2005
Processing Engines Keep the data moving No Yes Yes SQL-style processing on streams N N Y Handle stream imperfections Difficult Possible Possible Generate predictable outcomes D P P Integrate stored and streaming data N N Y Guarantee data safety and availability P P P Partition and scale applications P P P Process and respond instantaneously P P P
Keep the data moving: yes, no storage involved, push not poll 2. Query on streams: not really 3. Handle stream imperfections: yes, guarantee reliability with tuple acknowledgment 4. Generate predictable outcomes: yes
Integrate stored and streaming data: not really 6. Guarantee data safety and availability: yes 7. Partition and scale automatically: yes 8. Process and response instantaneously: yes
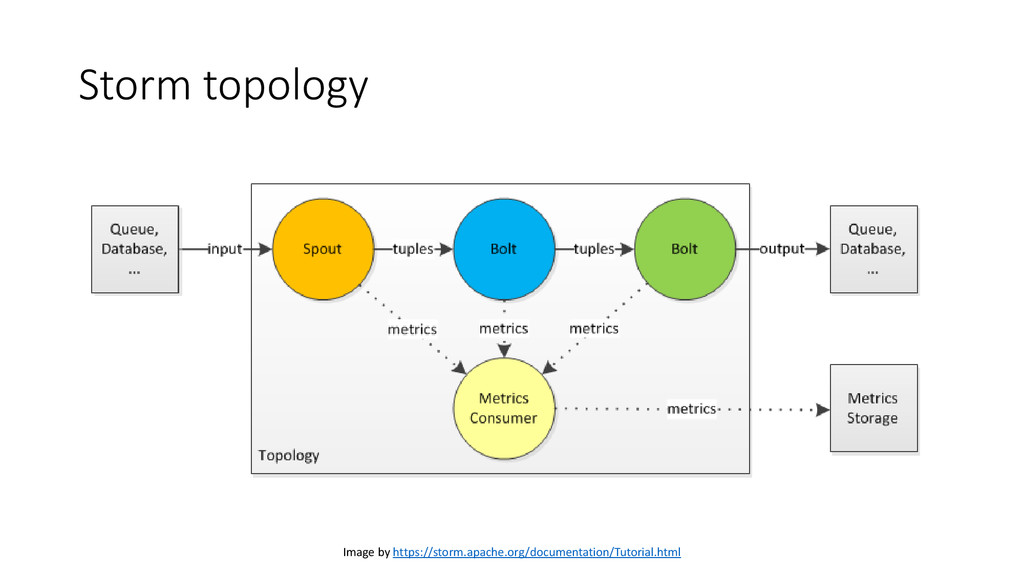
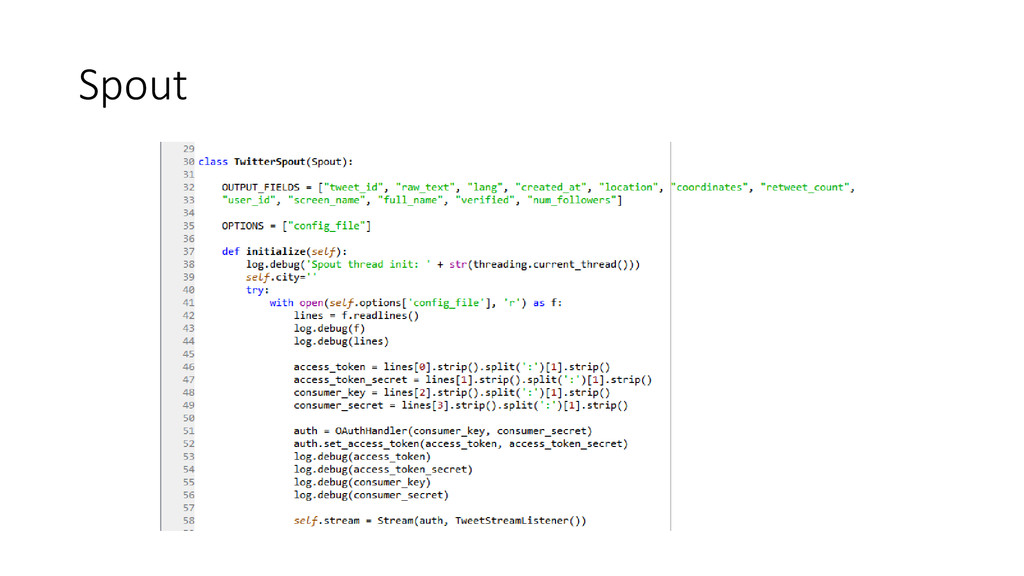
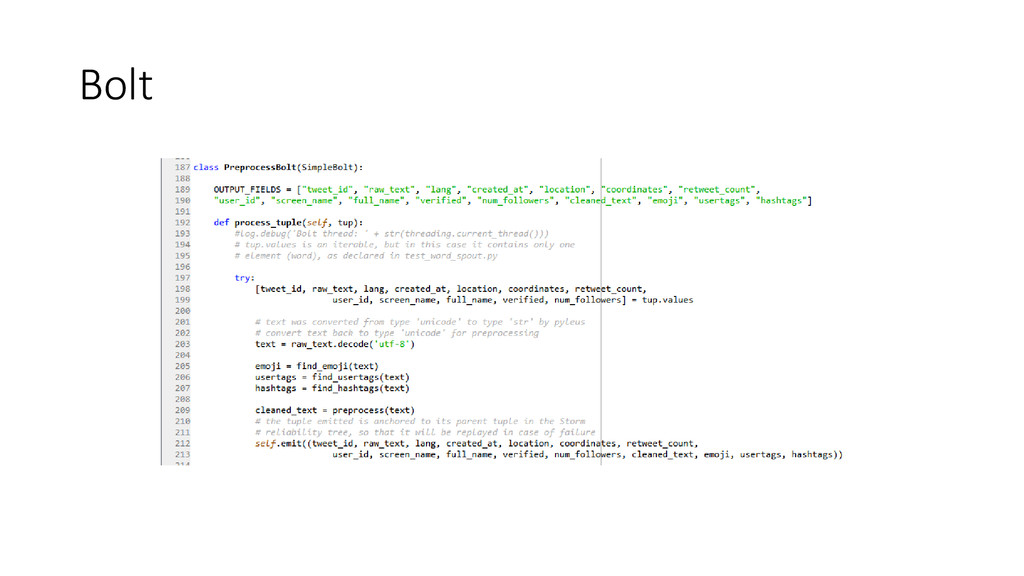
• Stream: unbounded sequence of tuples • Spout: source of the stream • Bolt: processing unit – process tuples & produce new output stream • Topology: a network of spouts and bolts • Task: a running instance of a spout or a bolt • Stream grouping: how tuples are sent between tasks e.g. shuffle, fields
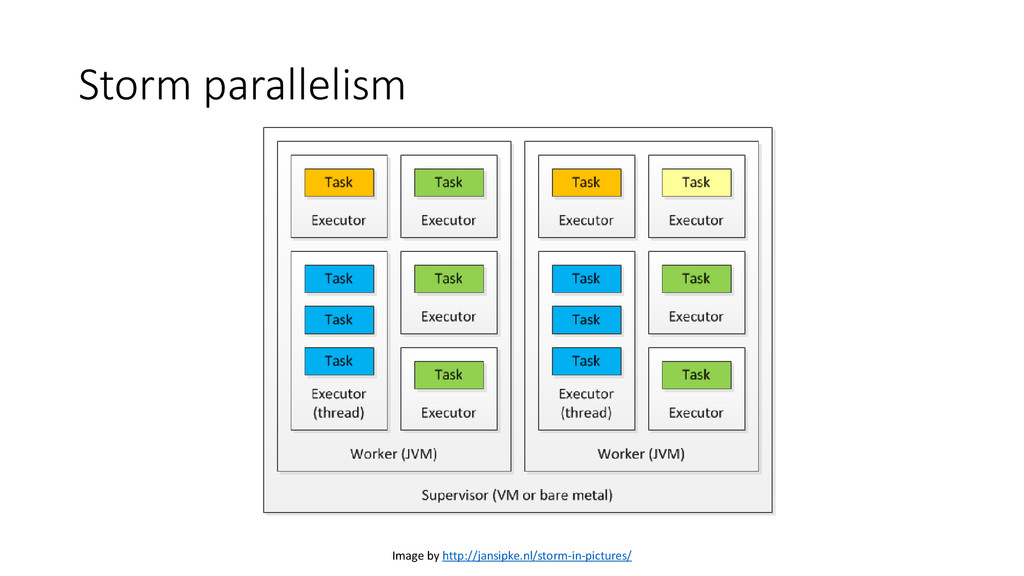
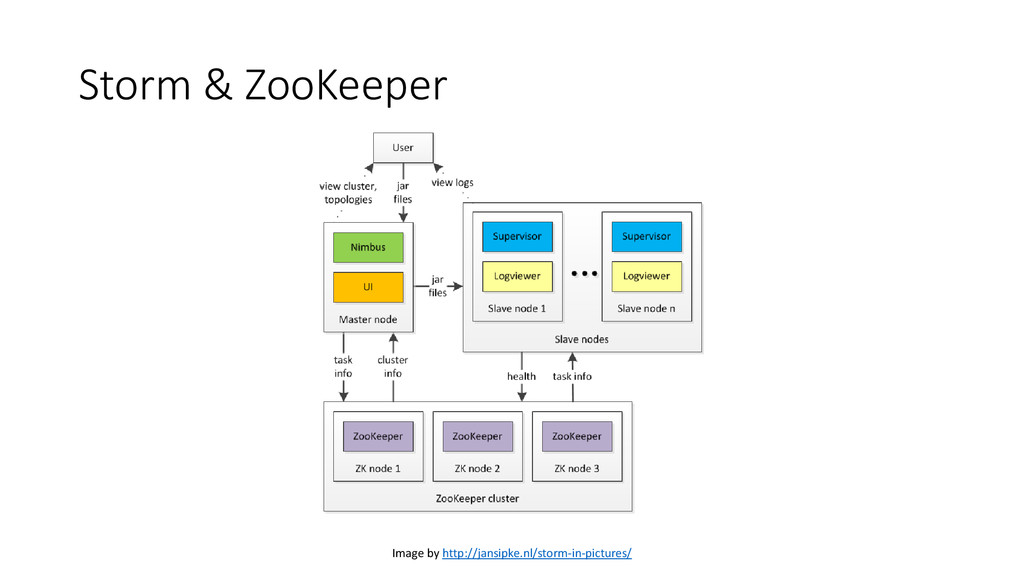
Storm from scratch? • Storm + Zookeeper + Supervisord • How to develop and test a Storm topology locally? • Spout: initialize(), next_tuple() • Bolt: initialize(), process_tuple() • Topology: define connections among spouts and bolts in a .yaml config file • Compile: pyleus build • Run in local mode: pyleus local • How to deploy and monitor a Storm topology? • Run pyleus submit (pyleus list, pyleus kill, storm activate, storm deactivate, storm rebalance) • Monitor with Storm UI
day 5800 thousand per sec • Twitter streaming API: 1% - 58 per sec • Preprocess: remove unwanted content • Compute sentiment score • Write the result to Elasticsearch
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}