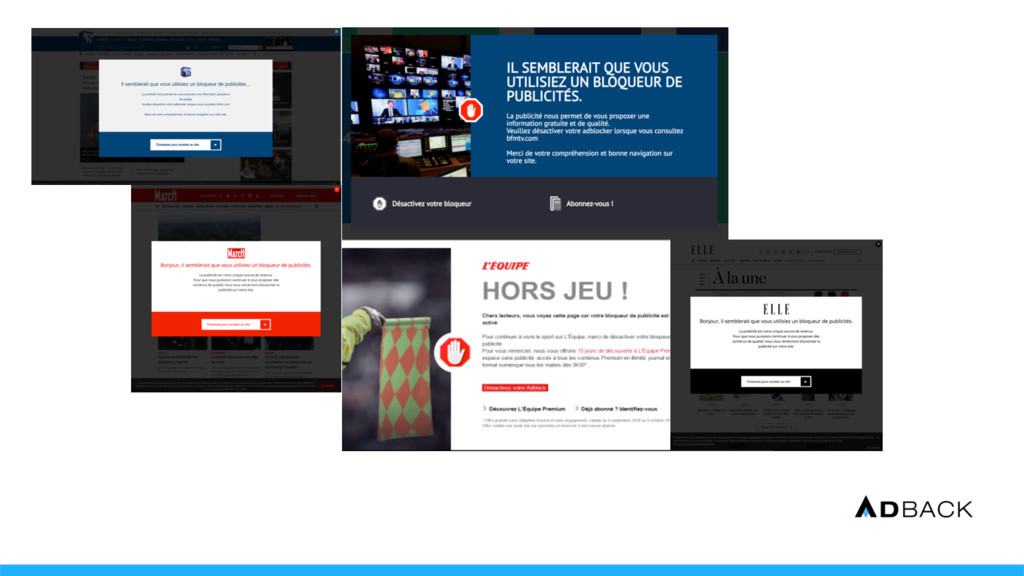
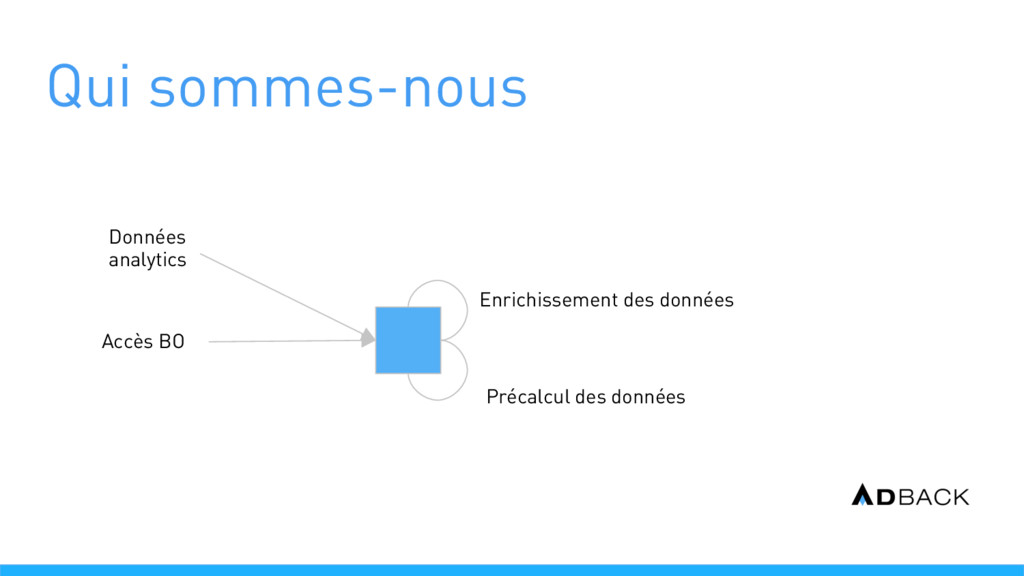
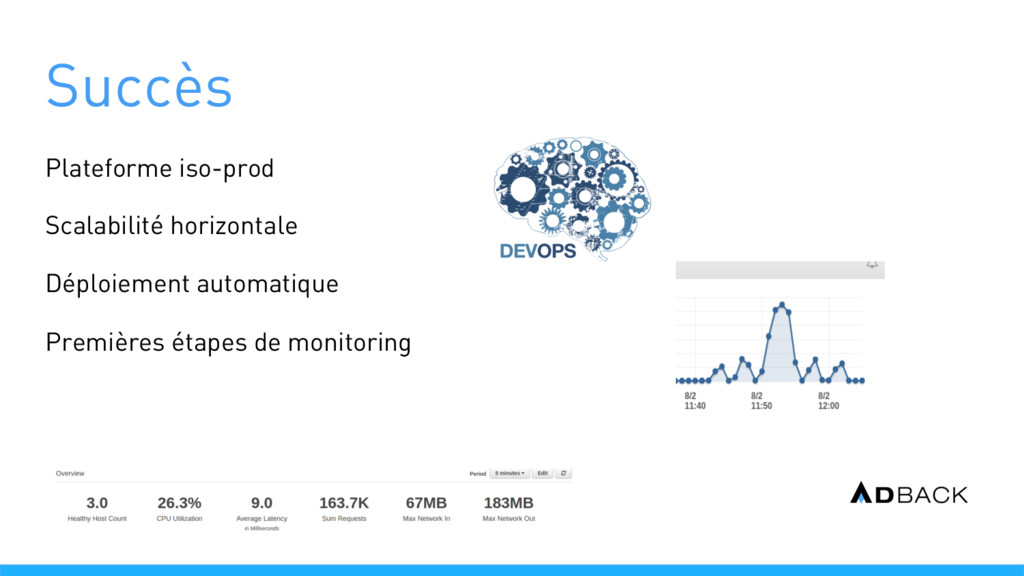
et récupérer les données Workers : réaliser l’enrichissement des données Worker-cache : réaliser le pré-calcul des données la nuit Back-office : présenter le résultat aux clients
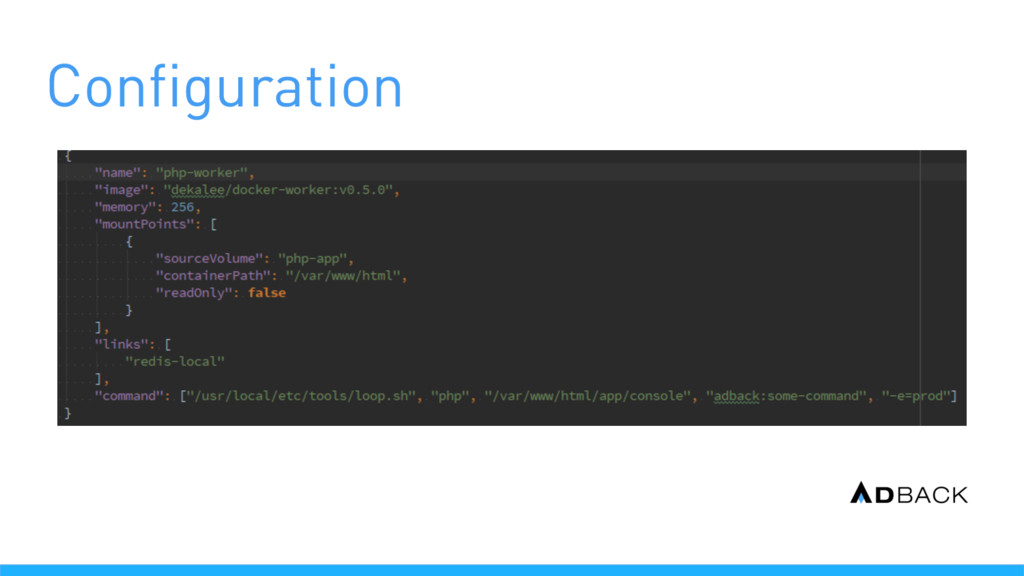
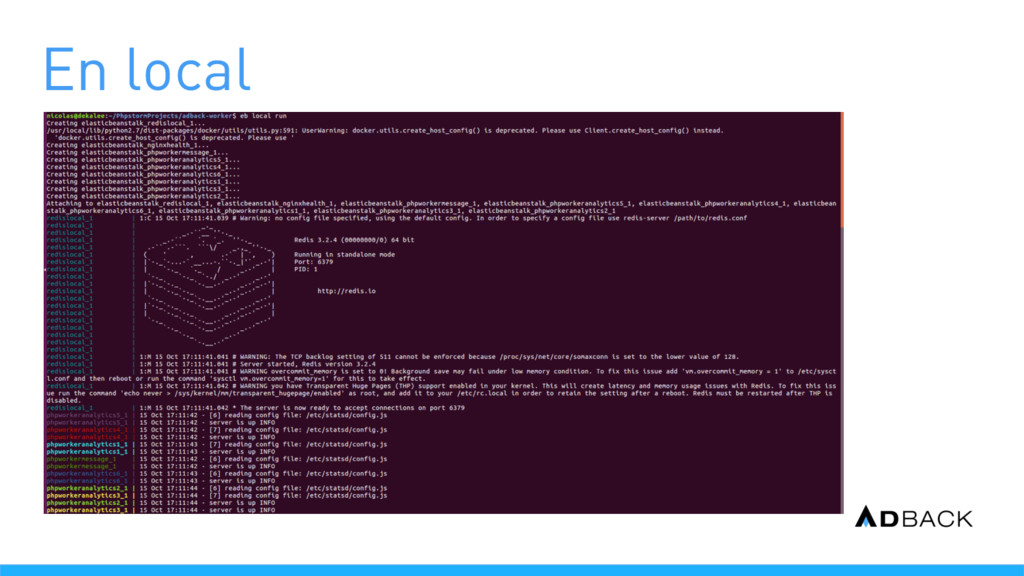
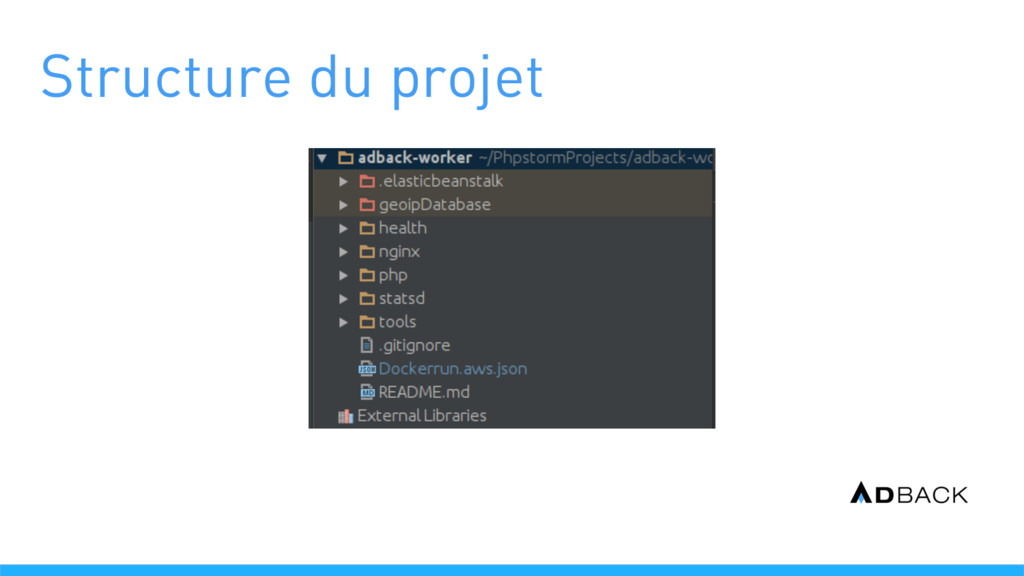
une instance EC2 Le scaling est réalisé en ajoutant des instances EC2 La configuration se fait par un fichier Dockerrun.aws.json Mise à disposition d’un executable local (eb) Le déploiement peut aussi mettre à jour les containers
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
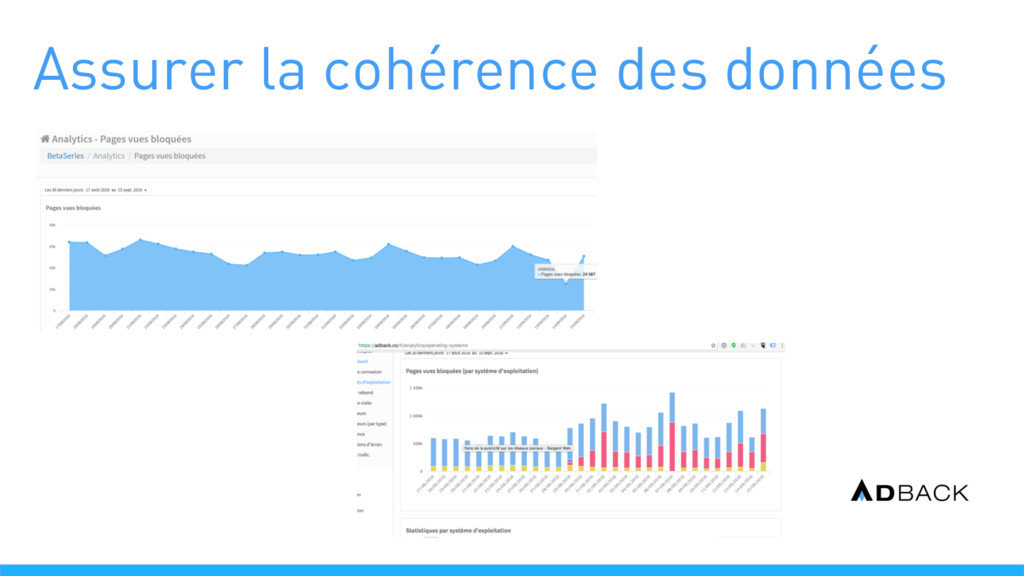{kind=link}
{kind=link}
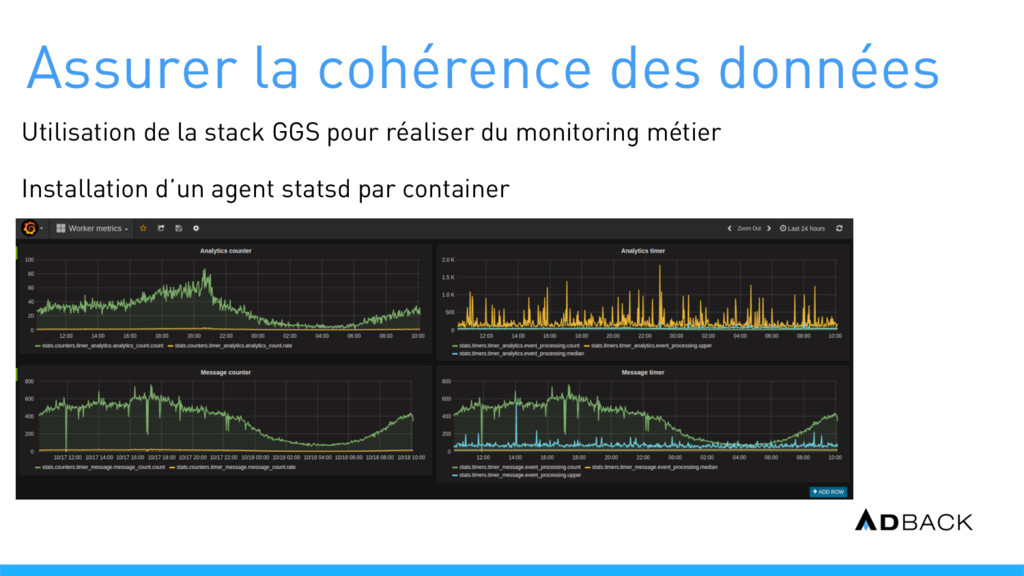{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}