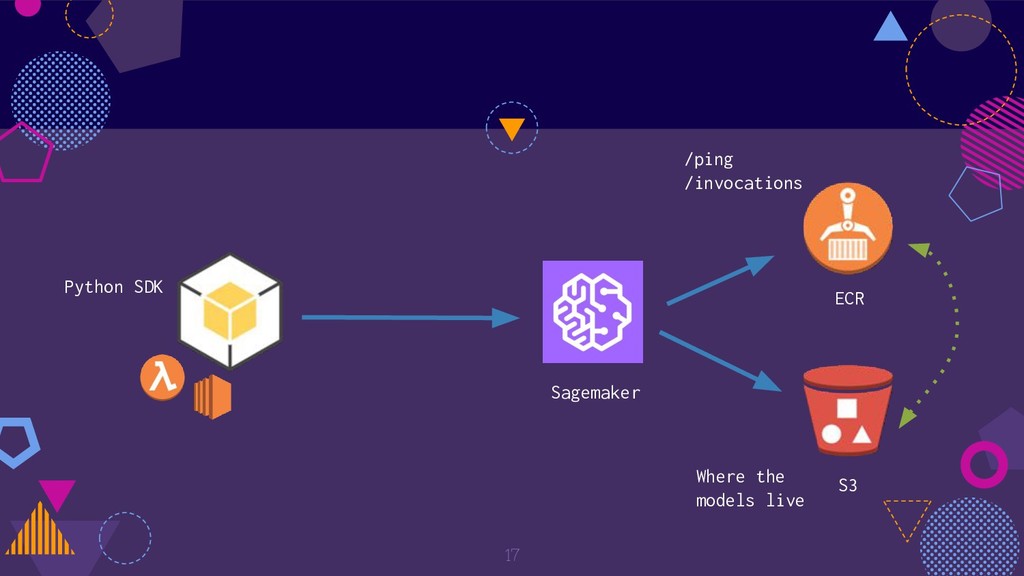
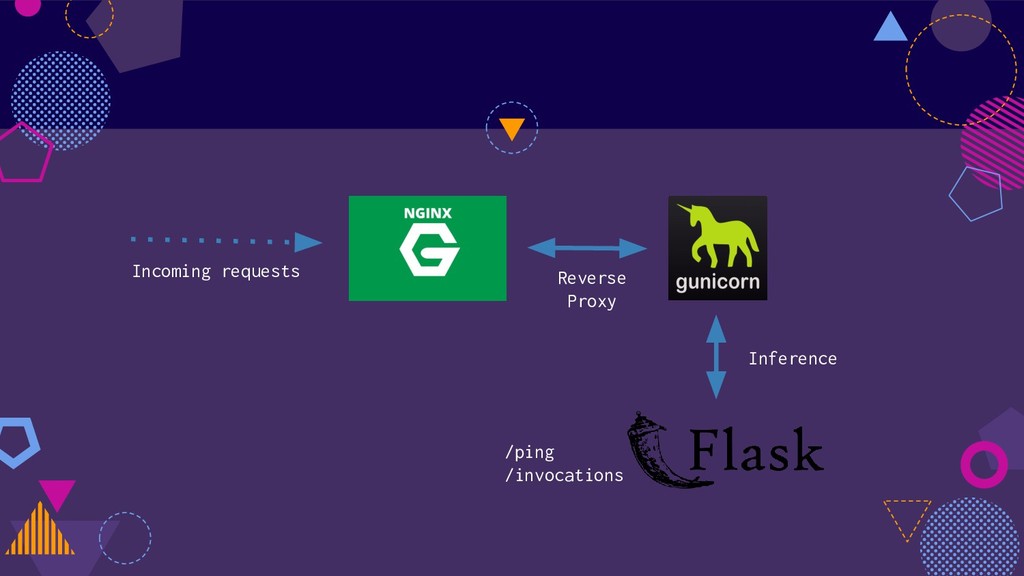
There are several ways to host a machine learning model on AWS. It can range from a dedicated EC2 instance to a fully managed lambda based solution. This presentation talks about several ways to host machine learning models embracing the serverless paradigm on AWS.
{kind=link}
{kind=link}
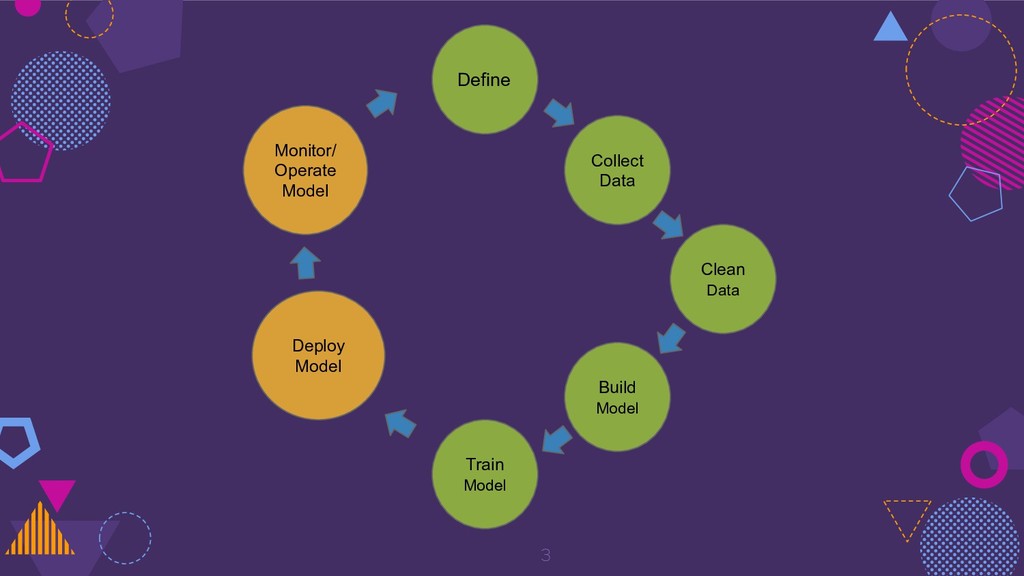{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
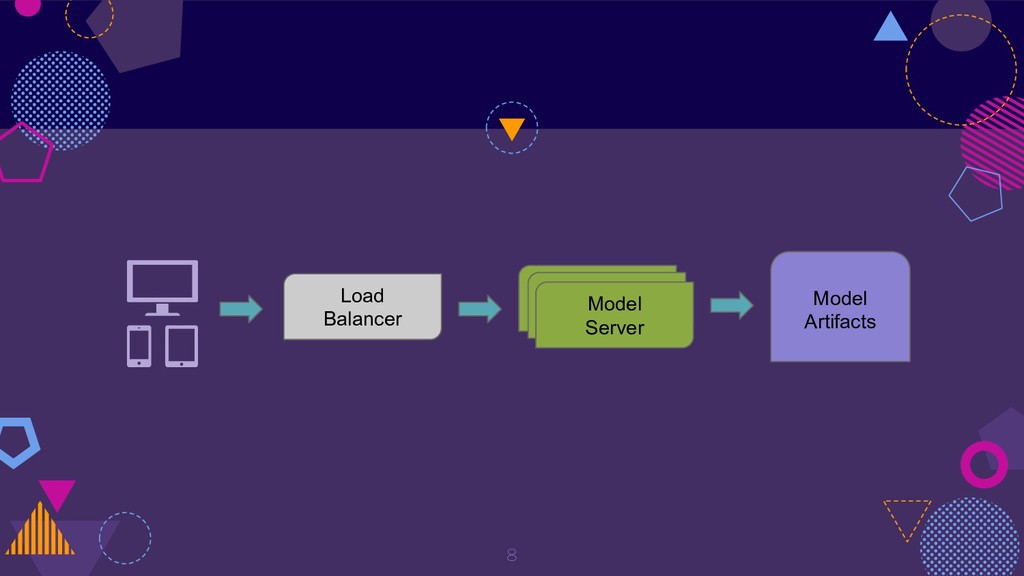{kind=link}
{kind=link}
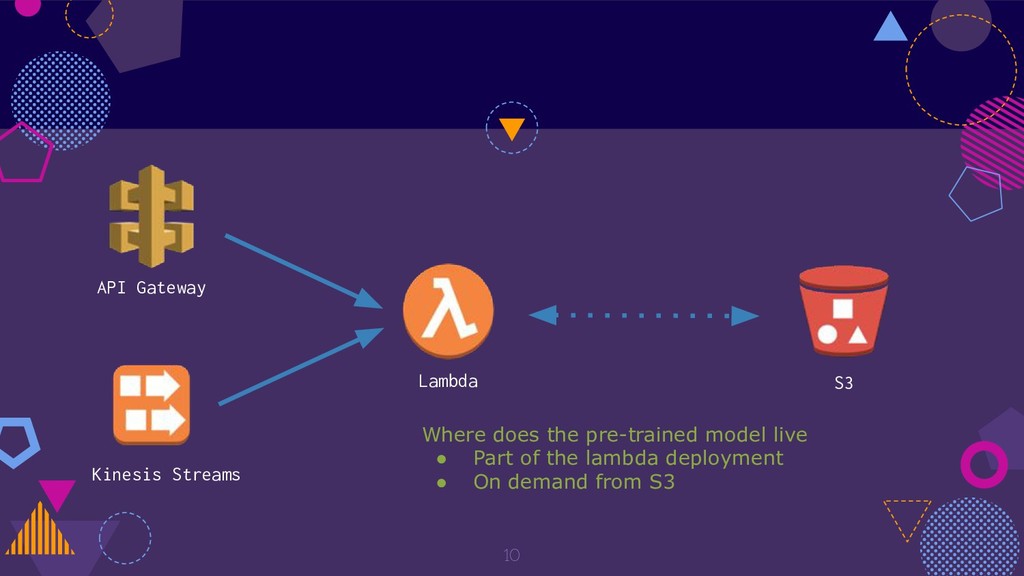{kind=link}
{kind=link}
{kind=link}
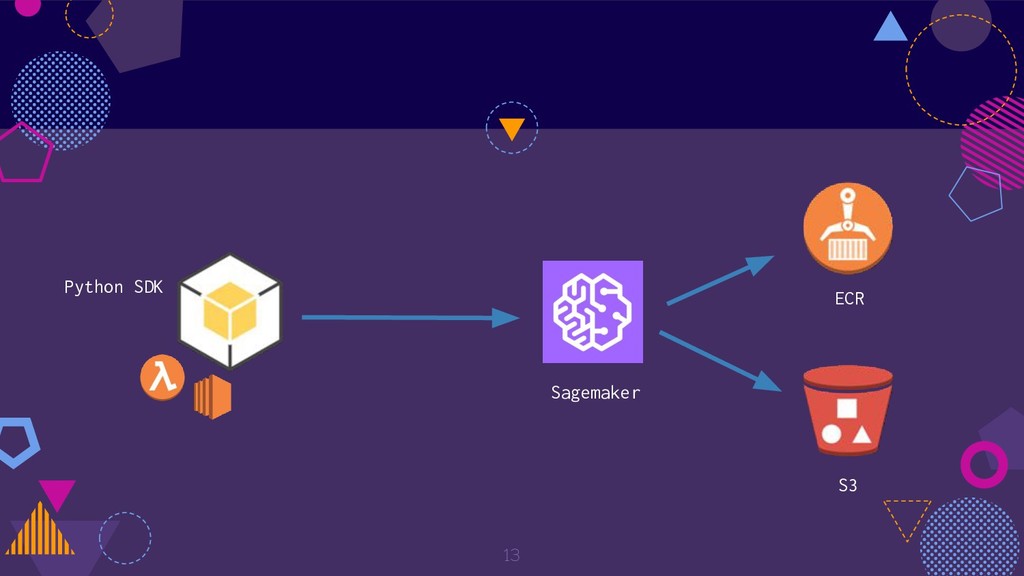{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}