I A B I L I T Y E N G I N E E R I N G W I T H T O O L S Agenda SECTION CONTENT E X P E D I A G R O U P 01 | Intro 02 | Chaos Engineering 03 | Failover-as-a-Service Reliability Engineering On-road Platforms Concepts Chaos Engineering Framework Concepts Failover-as-a-Service Framework 04 | Key Takeaways Lessons Learned Key Takeaways 2
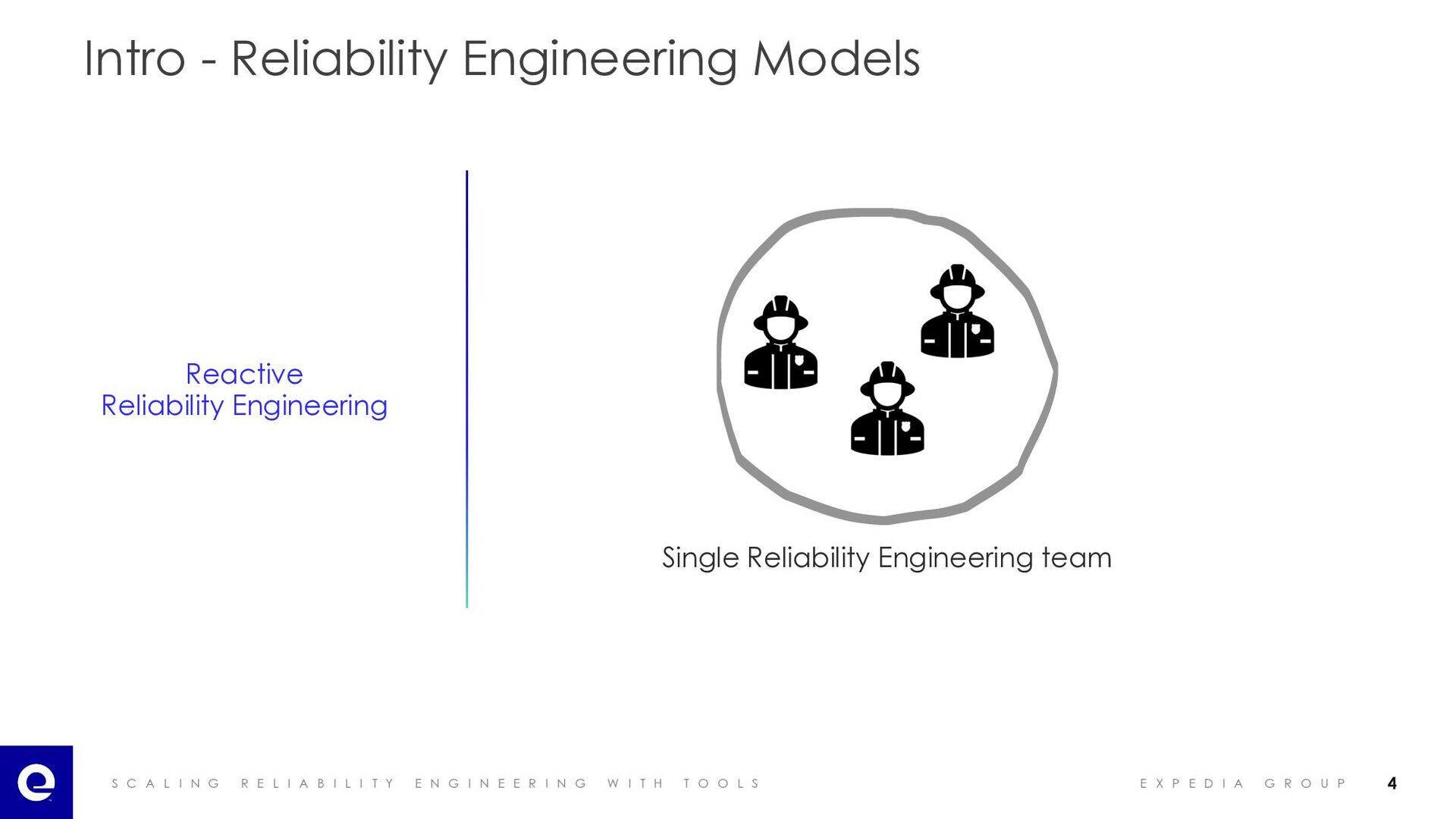
I A B I L I T Y E N G I N E E R I N G W I T H T O O L S E X P E D I A G R O U P Intro - Reliability Engineering Models Single Reliability Engineering team Reactive Reliability Engineering 4
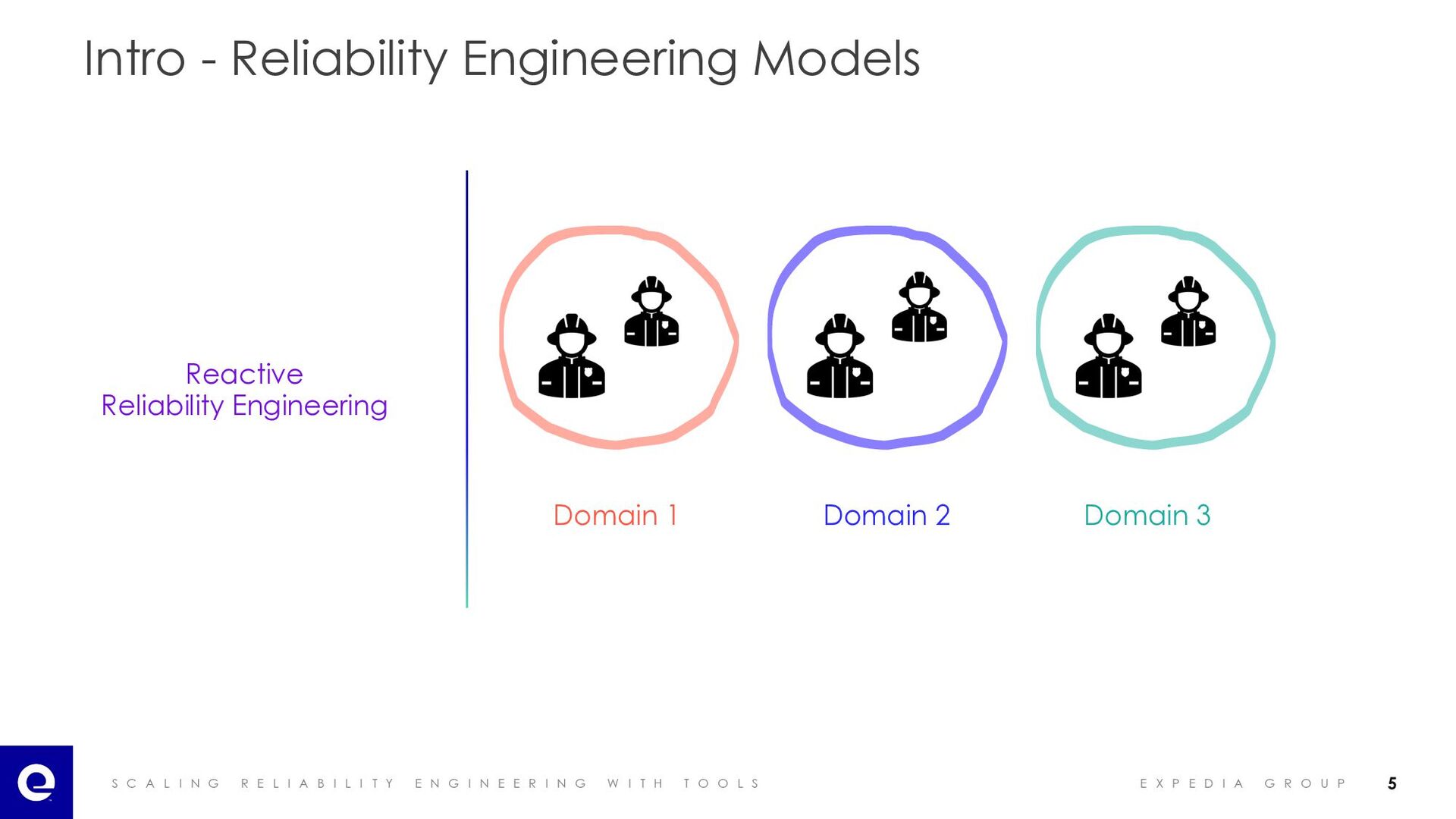
I A B I L I T Y E N G I N E E R I N G W I T H T O O L S E X P E D I A G R O U P Intro - Reliability Engineering Models Reactive Reliability Engineering Domain 1 Domain 2 Domain 3 5
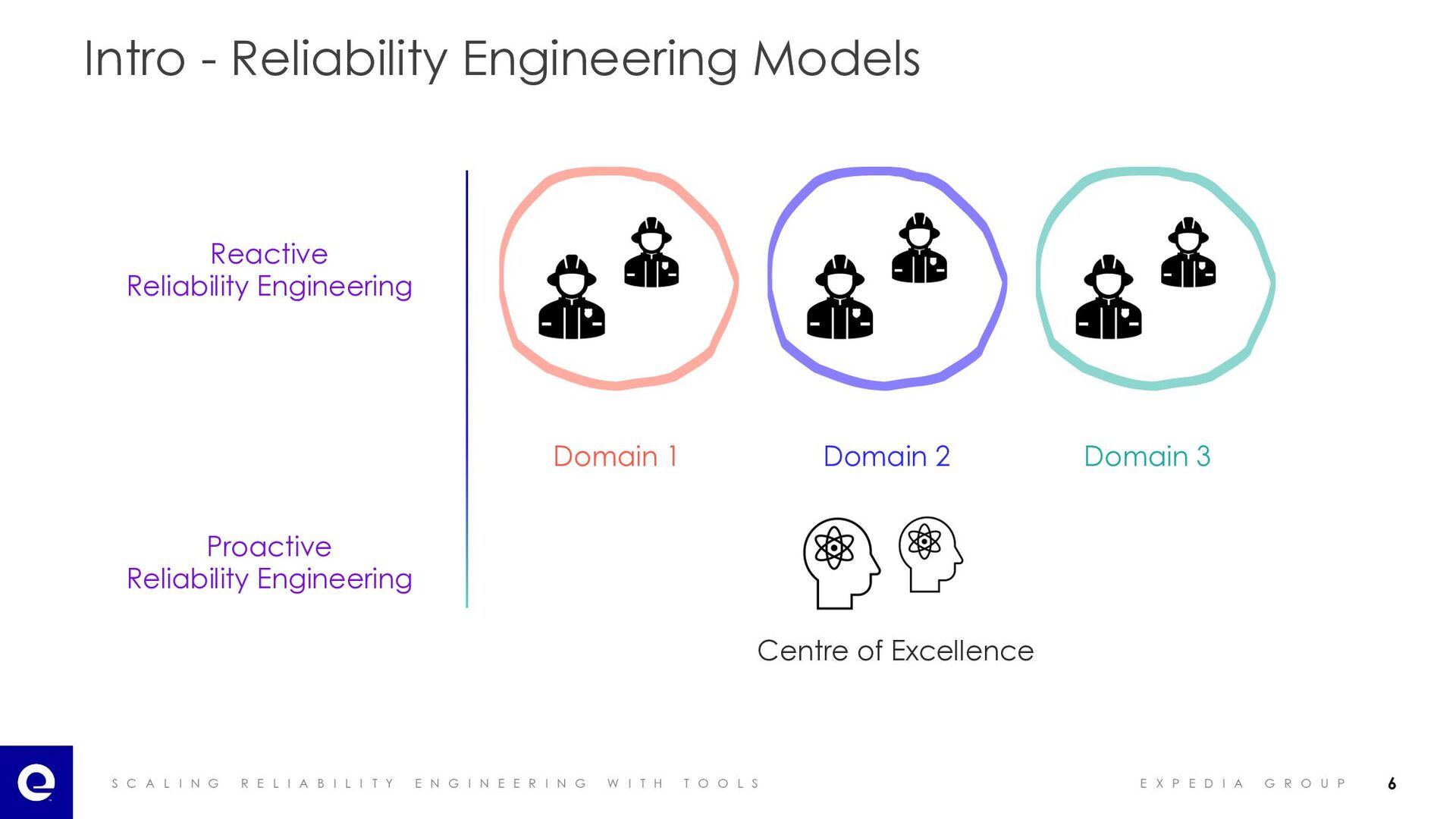
I A B I L I T Y E N G I N E E R I N G W I T H T O O L S E X P E D I A G R O U P Intro - Reliability Engineering Models Reactive Reliability Engineering Centre of Excellence Domain 1 Domain 2 Domain 3 Proactive Reliability Engineering 6
I A B I L I T Y E N G I N E E R I N G W I T H T O O L S E X P E D I A G R O U P Intro - Reliability Engineering Models Reactive Reliability Engineering Proactive Reliability Engineering Reliability Tooling Centre of Excellence Domain 1 Domain 2 Domain 3 7
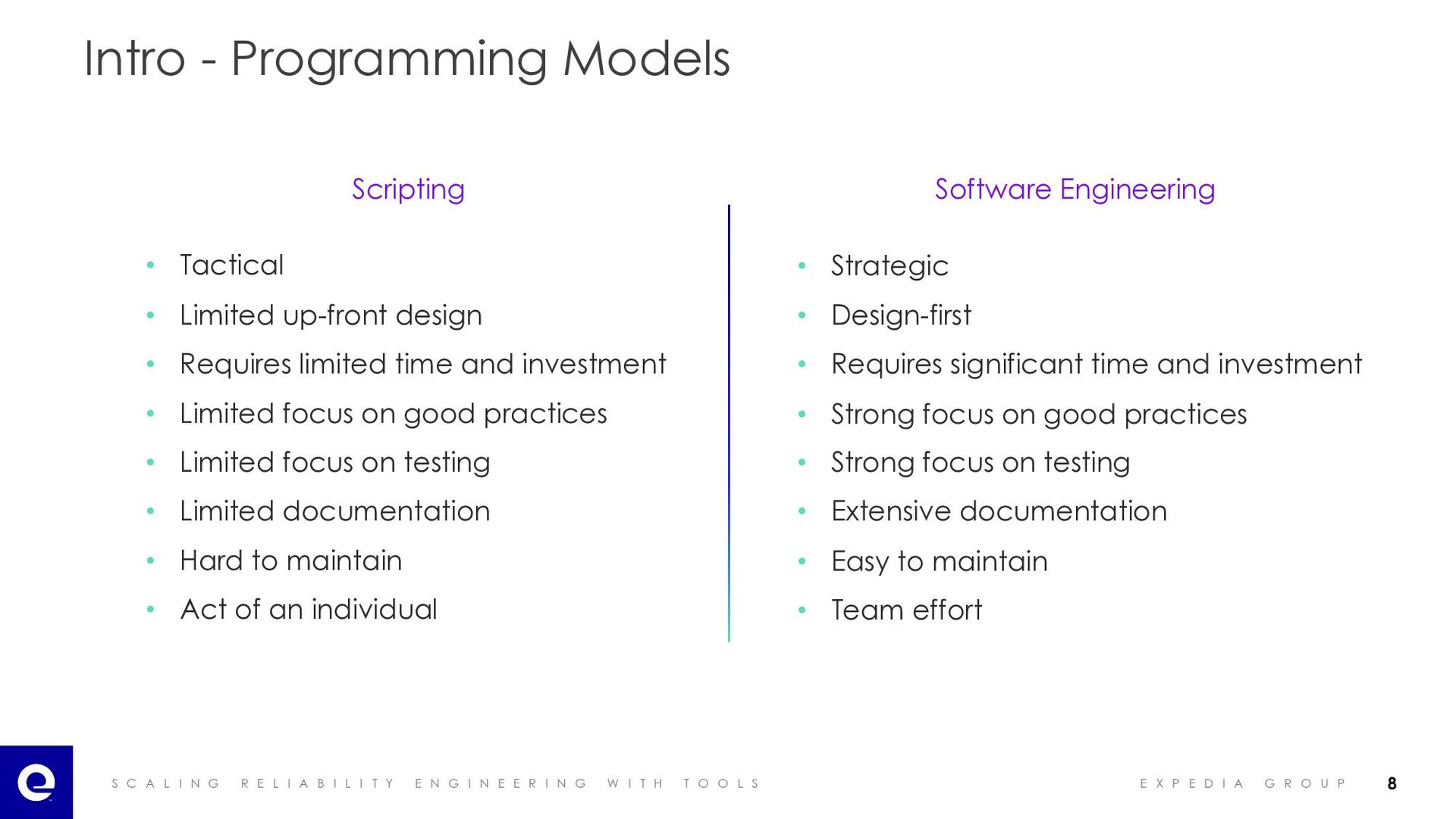
I A B I L I T Y E N G I N E E R I N G W I T H T O O L S E X P E D I A G R O U P Intro - Programming Models Scripting • Tactical • Limited up-front design • Requires limited time and investment • Limited focus on good practices • Limited focus on testing • Limited documentation • Hard to maintain • Act of an individual • Strategic • Design-first • Requires significant time and investment • Strong focus on good practices • Strong focus on testing • Extensive documentation • Easy to maintain • Team effort Software Engineering 8
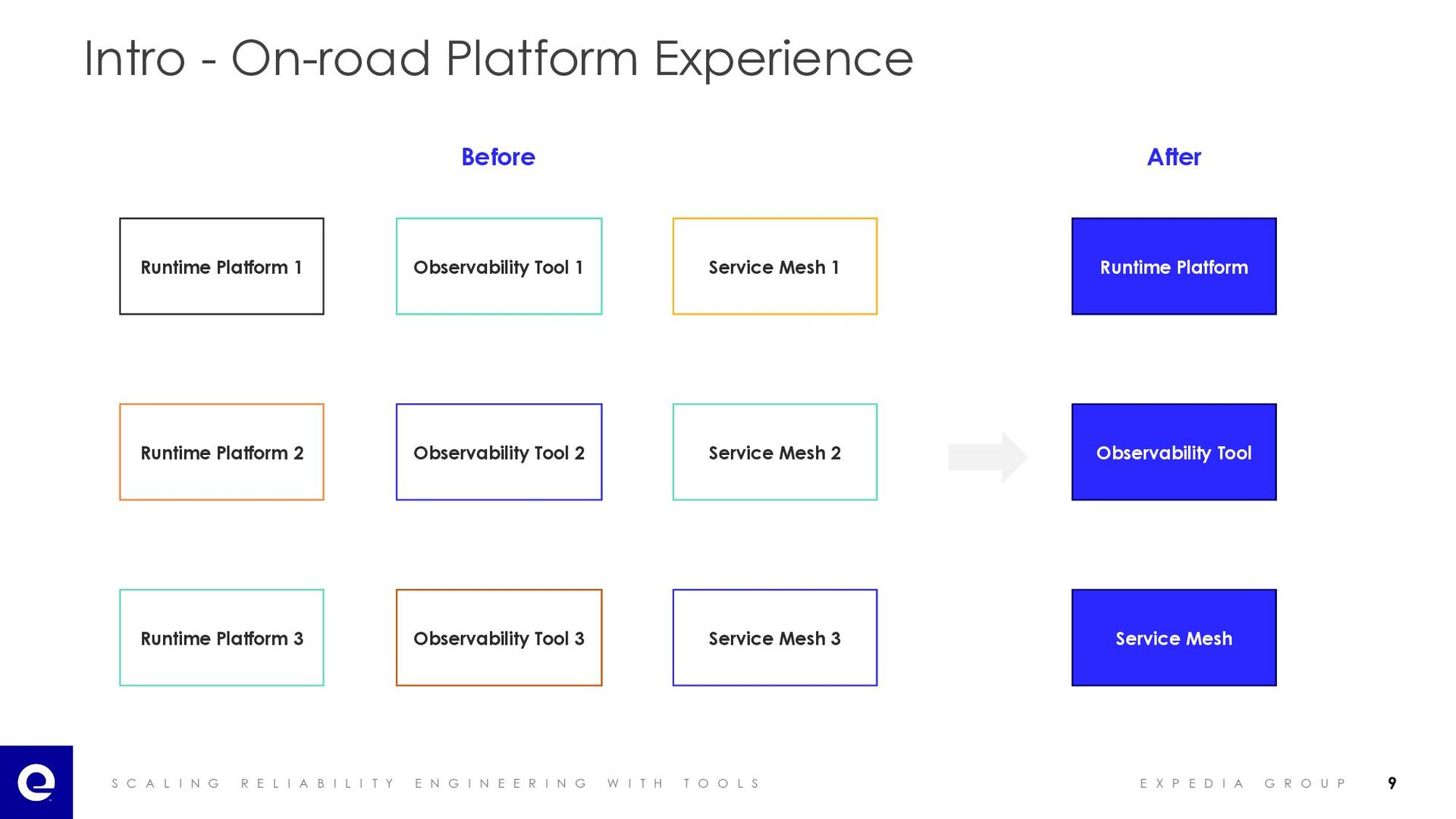
I A B I L I T Y E N G I N E E R I N G W I T H T O O L S E X P E D I A G R O U P Intro - On-road Platform Experience Runtime Platform 1 Runtime Platform 2 Runtime Platform 3 Observability Tool 1 Service Mesh 1 Observability Tool 2 Service Mesh 2 Observability Tool 3 Service Mesh 3 Runtime Platform Observability Tool Service Mesh Before After 9
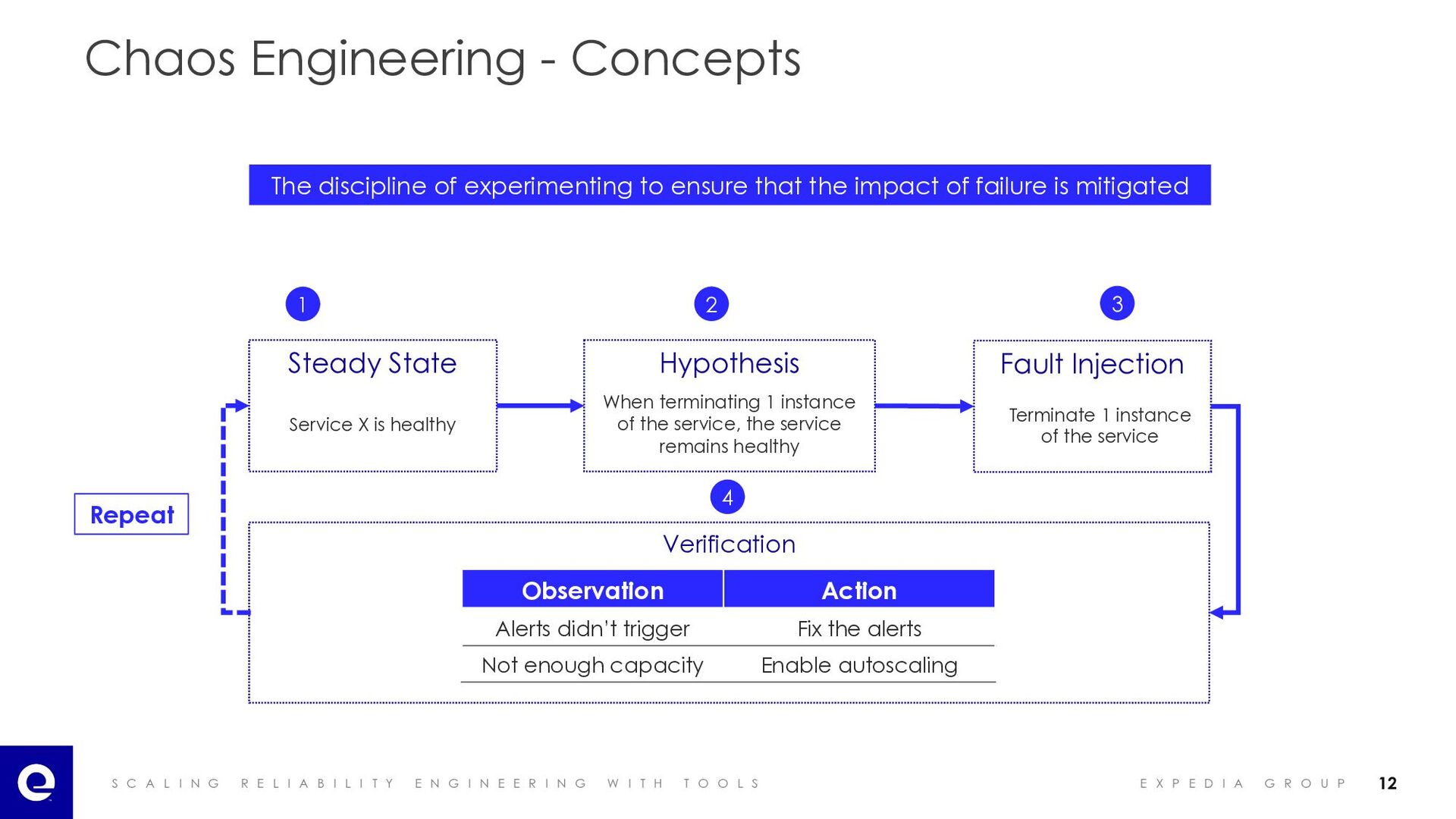
I A B I L I T Y E N G I N E E R I N G W I T H T O O L S E X P E D I A G R O U P Chaos Engineering - Concepts The discipline of experimenting to ensure that the impact of failure is mitigated Steady State Service X is healthy When terminating 1 instance of the service, the service remains healthy Hypothesis Fault Injection Terminate 1 instance of the service Verification Repeat Observation Action Alerts didn’t trigger Fix the alerts Not enough capacity Enable autoscaling 4 2 1 3 12
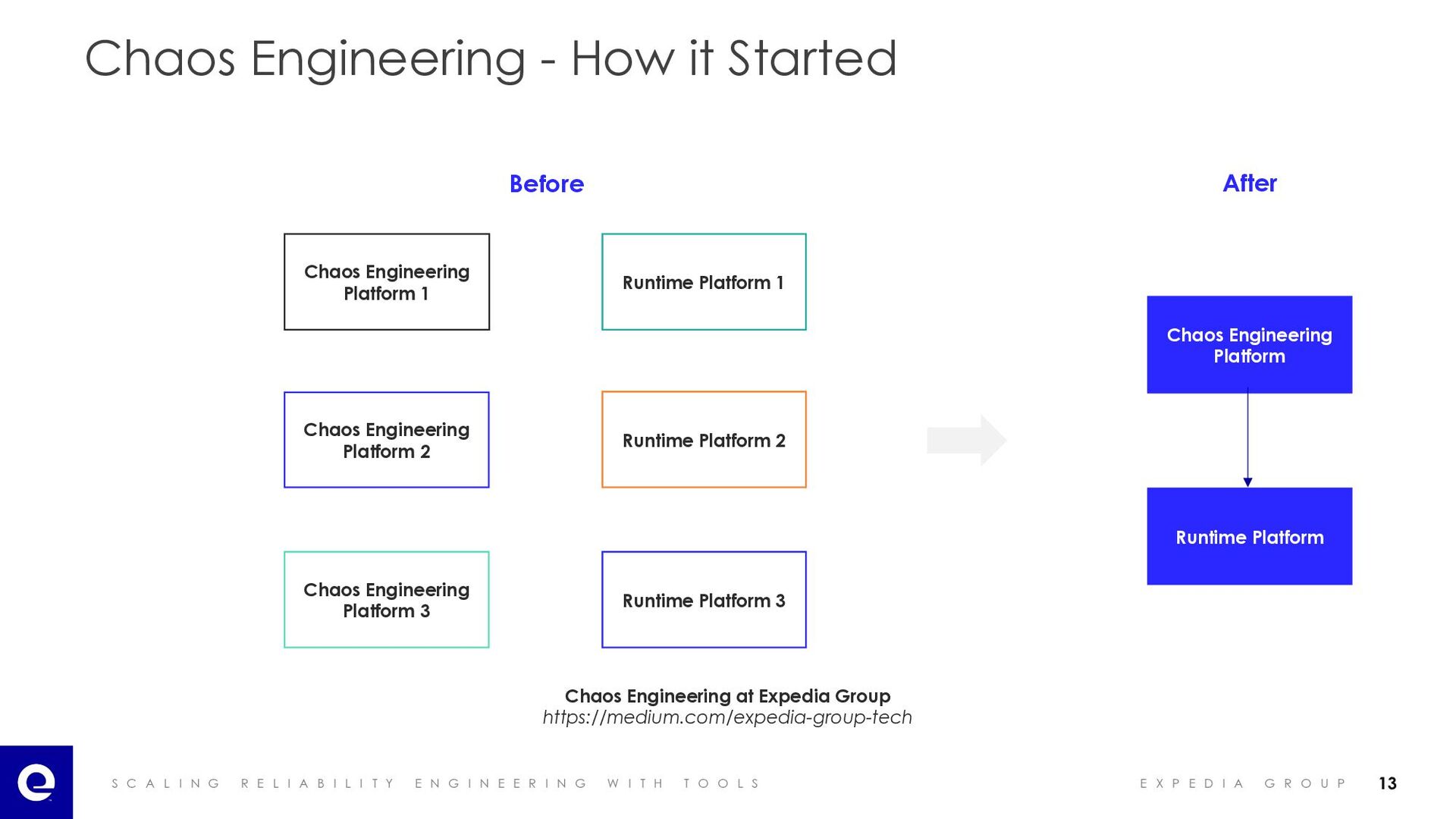
I A B I L I T Y E N G I N E E R I N G W I T H T O O L S E X P E D I A G R O U P Chaos Engineering - How it Started Runtime Platform Chaos Engineering Platform Before After Chaos Engineering Platform 1 Chaos Engineering Platform 2 Chaos Engineering Platform 3 Runtime Platform 1 Runtime Platform 2 Runtime Platform 3 13 Chaos Engineering at Expedia Group https://medium.com/expedia-group-tech
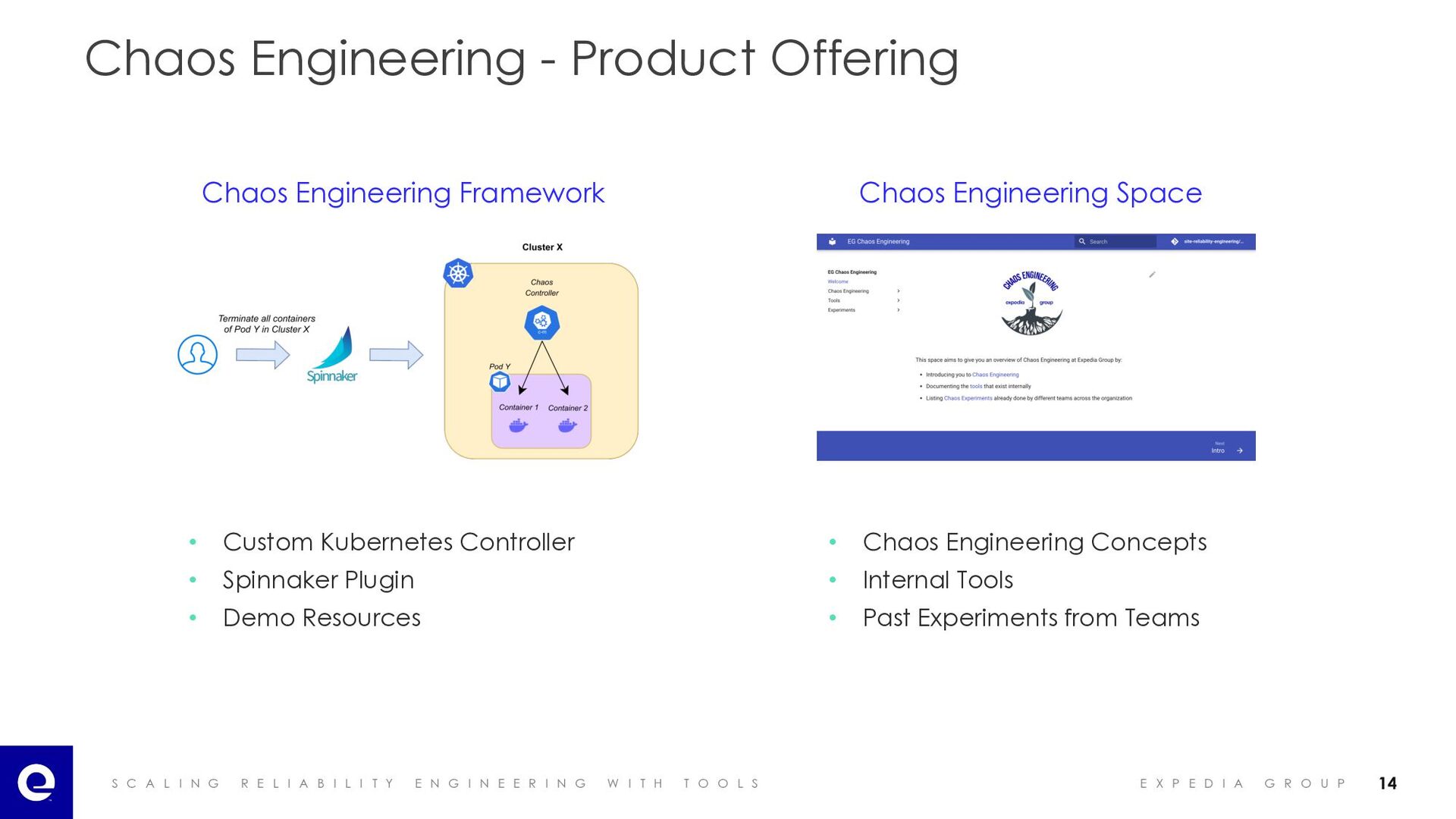
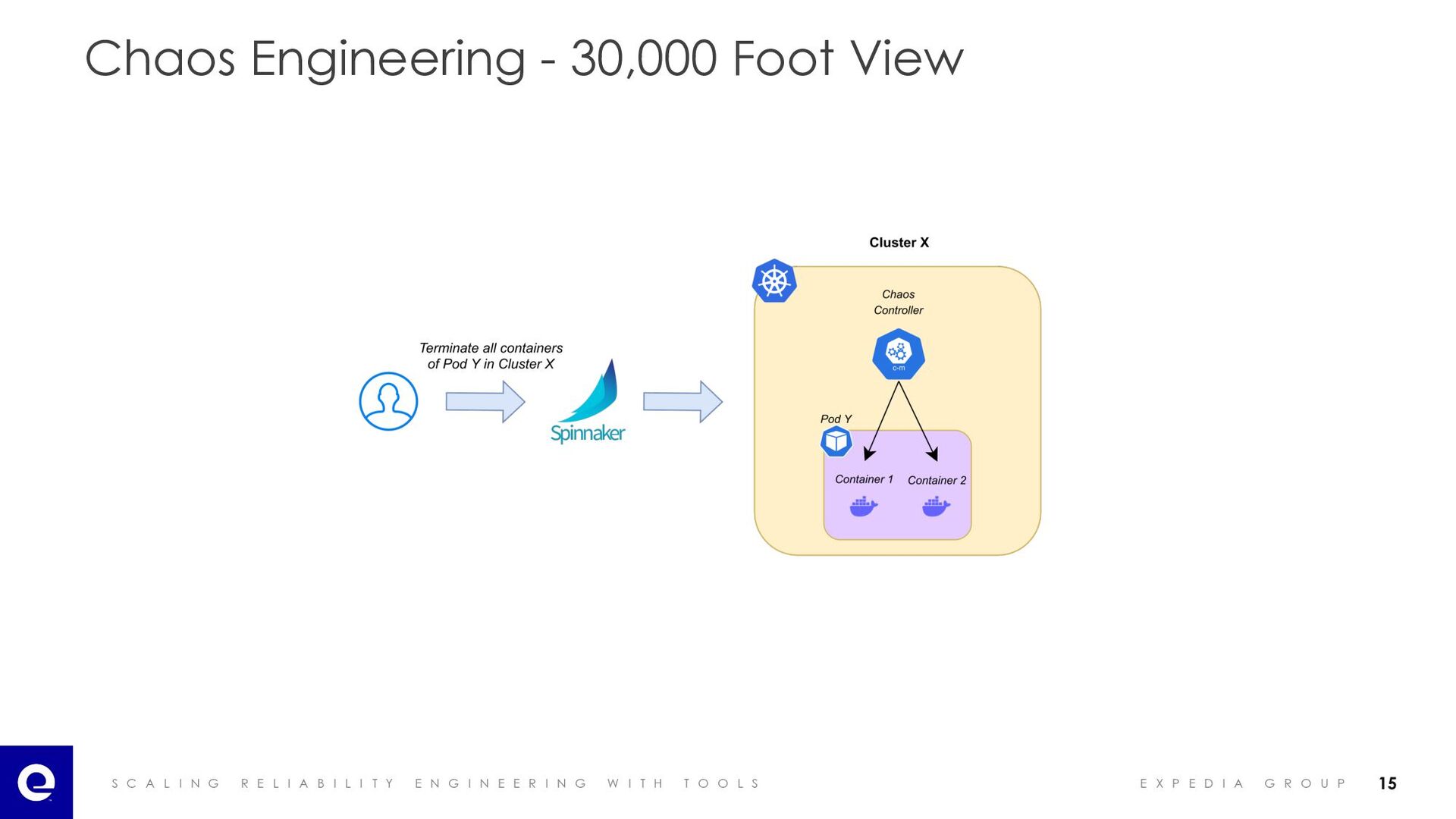
I A B I L I T Y E N G I N E E R I N G W I T H T O O L S E X P E D I A G R O U P Chaos Engineering - Product Offering Chaos Engineering Framework Chaos Engineering Space • Custom Kubernetes Controller • Spinnaker Plugin • Demo Resources • Chaos Engineering Concepts • Internal Tools • Past Experiments from Teams 14
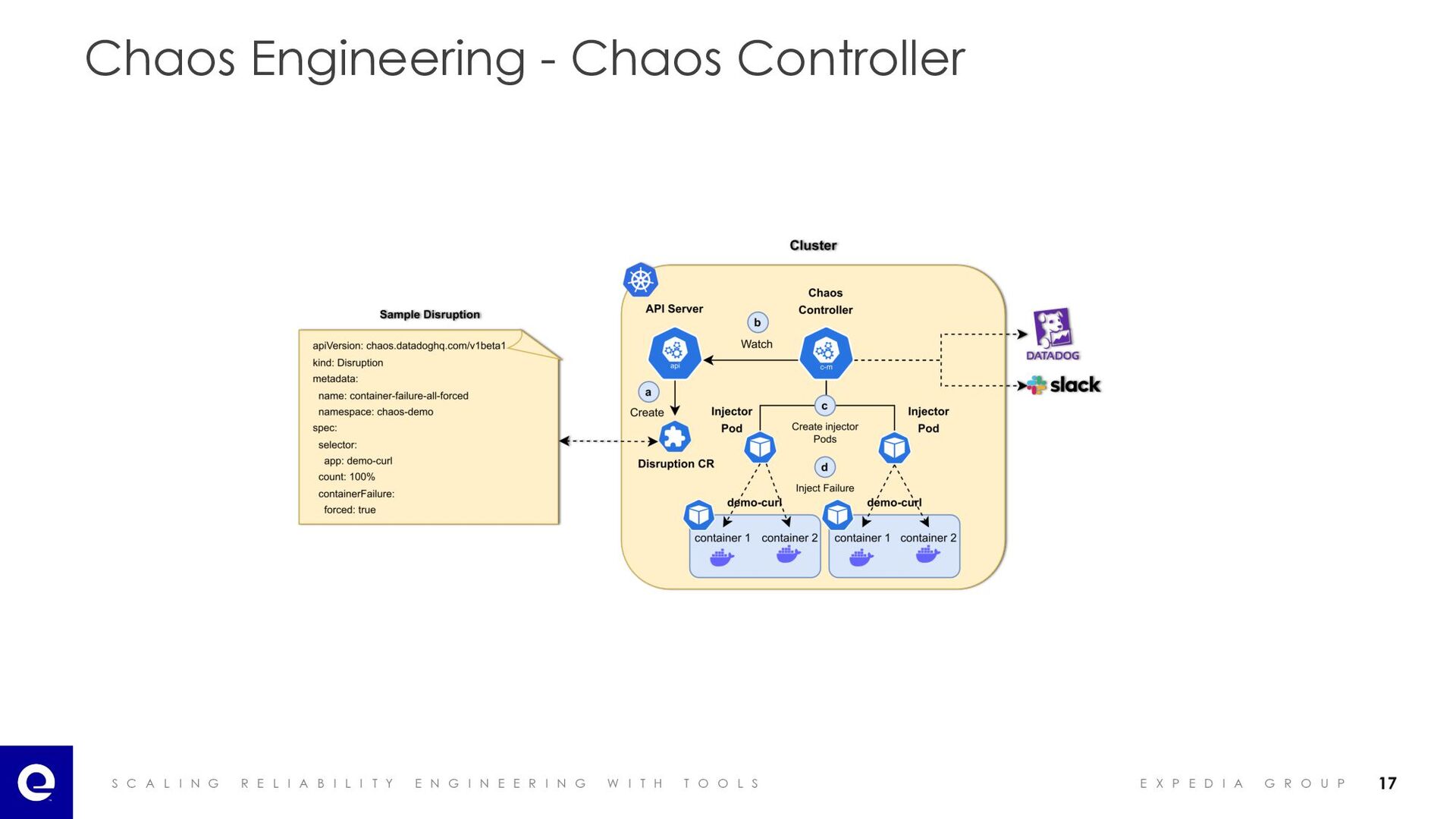
I A B I L I T Y E N G I N E E R I N G W I T H T O O L S E X P E D I A G R O U P Chaos Engineering - Chaos Controller • Chaos Engineering Framework for Kubernetes • Execution of Chaos Experiments using labels to reduce the blast radius • Support for a wide range of fault injection types at Container, Pod, and Node level • Observability through metrics, logs, and Kubernetes events • Safety nets https://github.com/DataDog/chaos-controller 16
I A B I L I T Y E N G I N E E R I N G W I T H T O O L S E X P E D I A G R O U P Chaos Engineering - Demo Resources A simple REST/gRPC application A curl Pod calling a Web Server https://github.com/DataDog/chaos-controller 18
I A B I L I T Y E N G I N E E R I N G W I T H T O O L S E X P E D I A G R O U P Type State Node shutdown Container termination Resource CPU pressure Disk pressure Network Packet drop Packet corruption Delay with jitter Bandwidth struggle Host-level Availability Zone failure DNS spoofing Request gRPC status code manipulation Chaos Engineering - Fault Injection Types https://github.com/DataDog/chaos-controller 📋 19
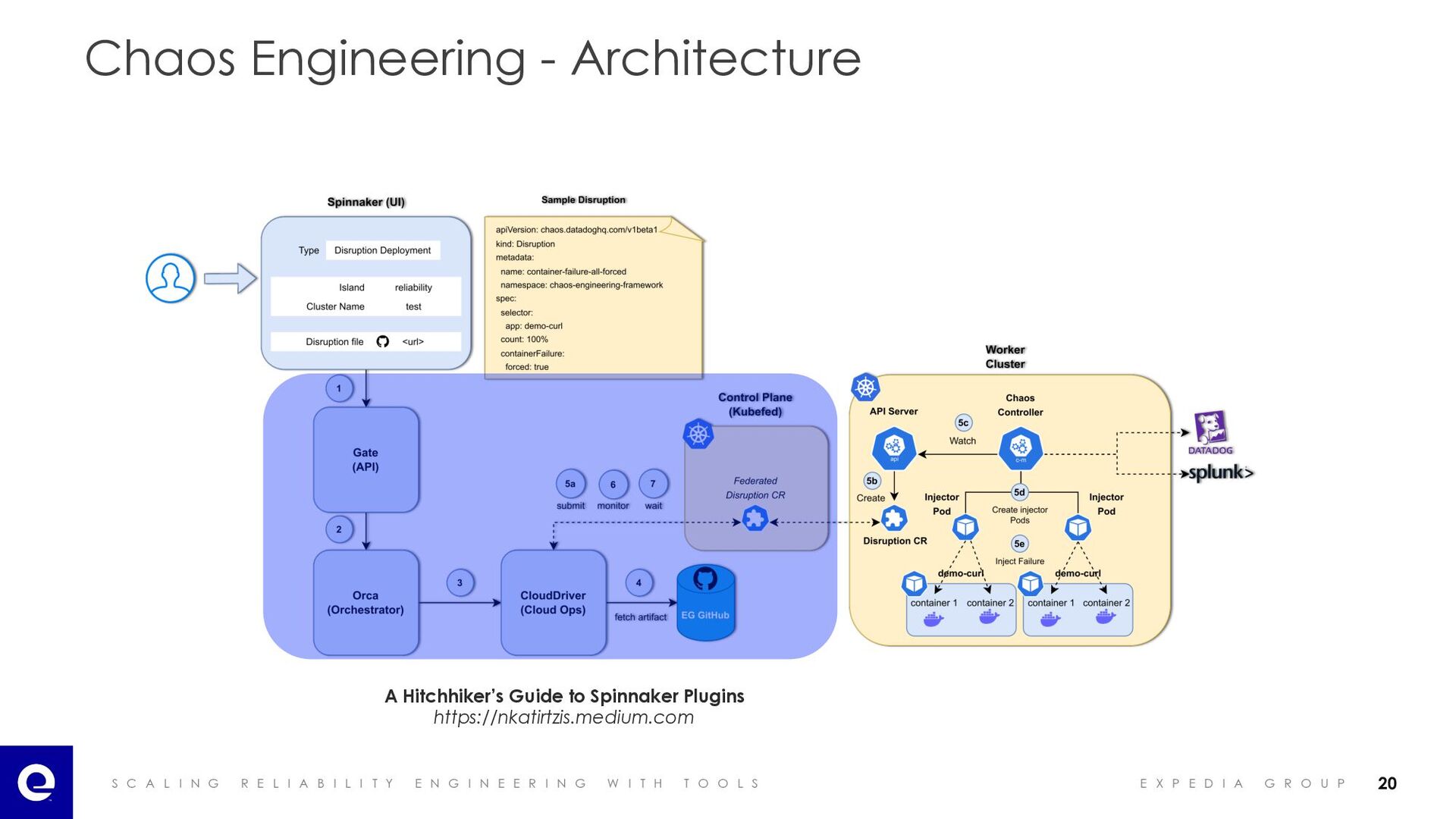
I A B I L I T Y E N G I N E E R I N G W I T H T O O L S E X P E D I A G R O U P Chaos Engineering - Architecture A Hitchhiker’s Guide to Spinnaker Plugins https://nkatirtzis.medium.com 20
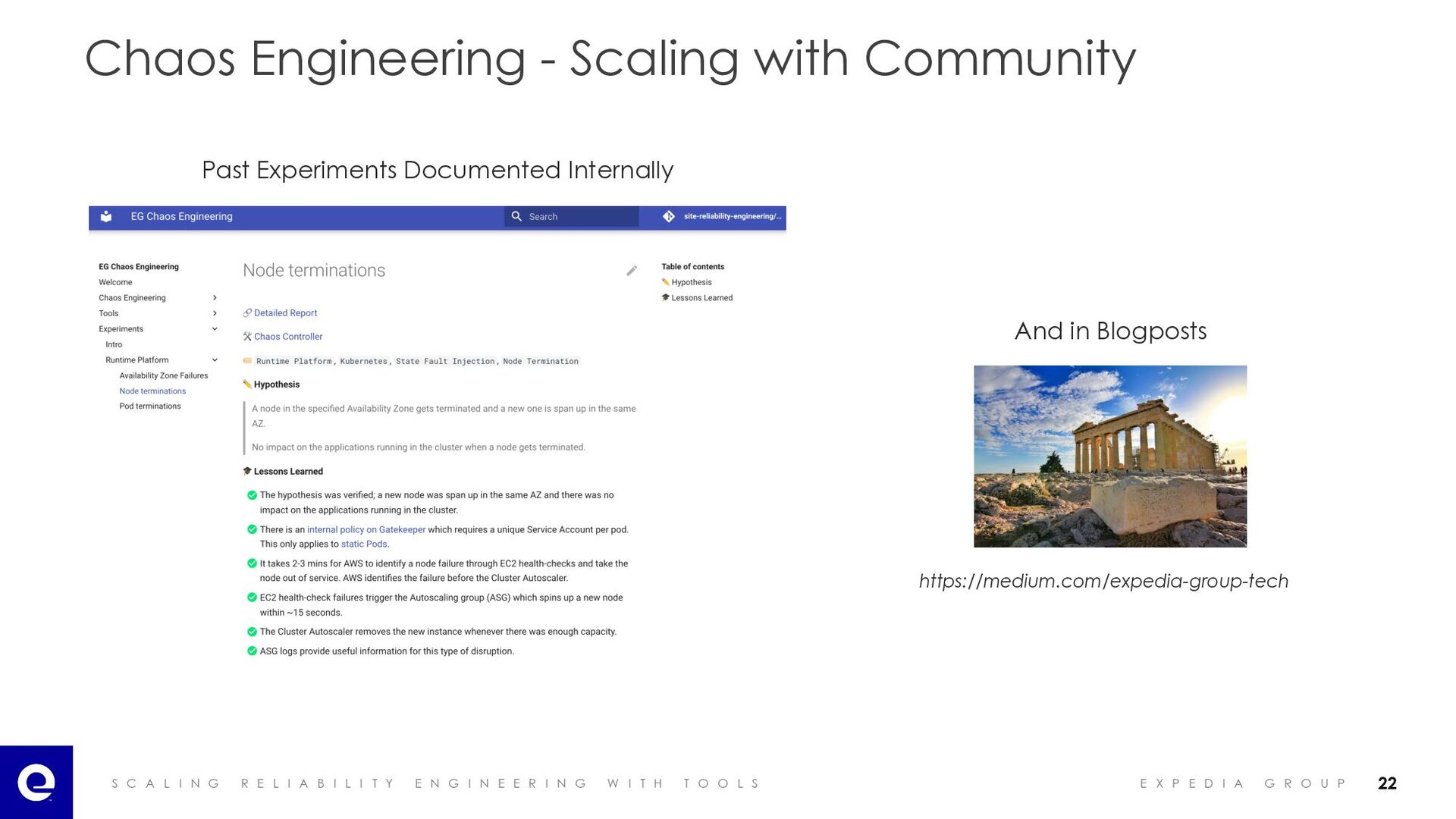
I A B I L I T Y E N G I N E E R I N G W I T H T O O L S E X P E D I A G R O U P Chaos Engineering - Scaling with Community https://medium.com/expedia-group-tech Past Experiments Documented Internally And in Blogposts 22
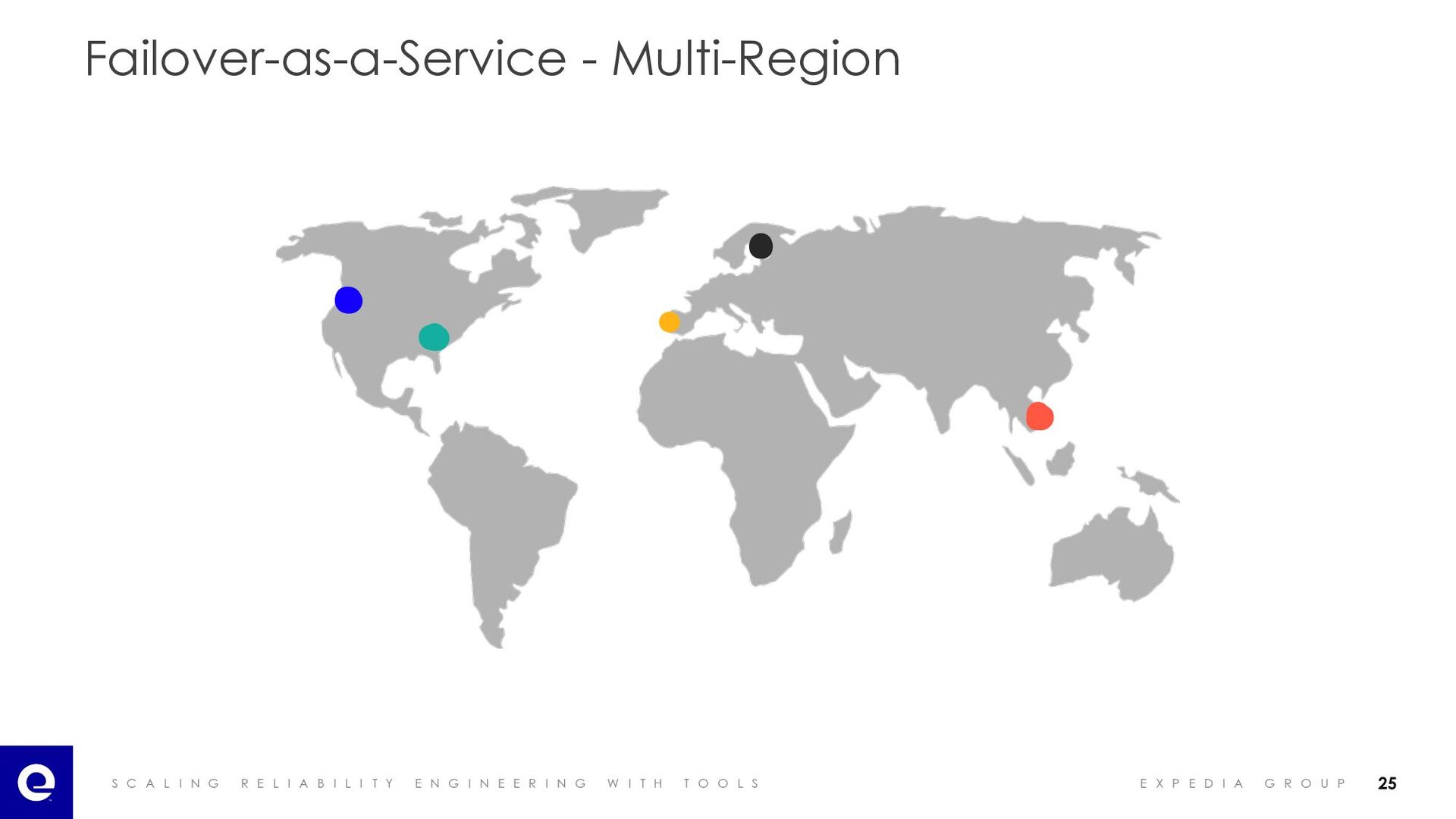
I A B I L I T Y E N G I N E E R I N G W I T H T O O L S E X P E D I A G R O U P 23 • Concepts • Failover-as-a-Service Framework 03 Failover-as-a-Service
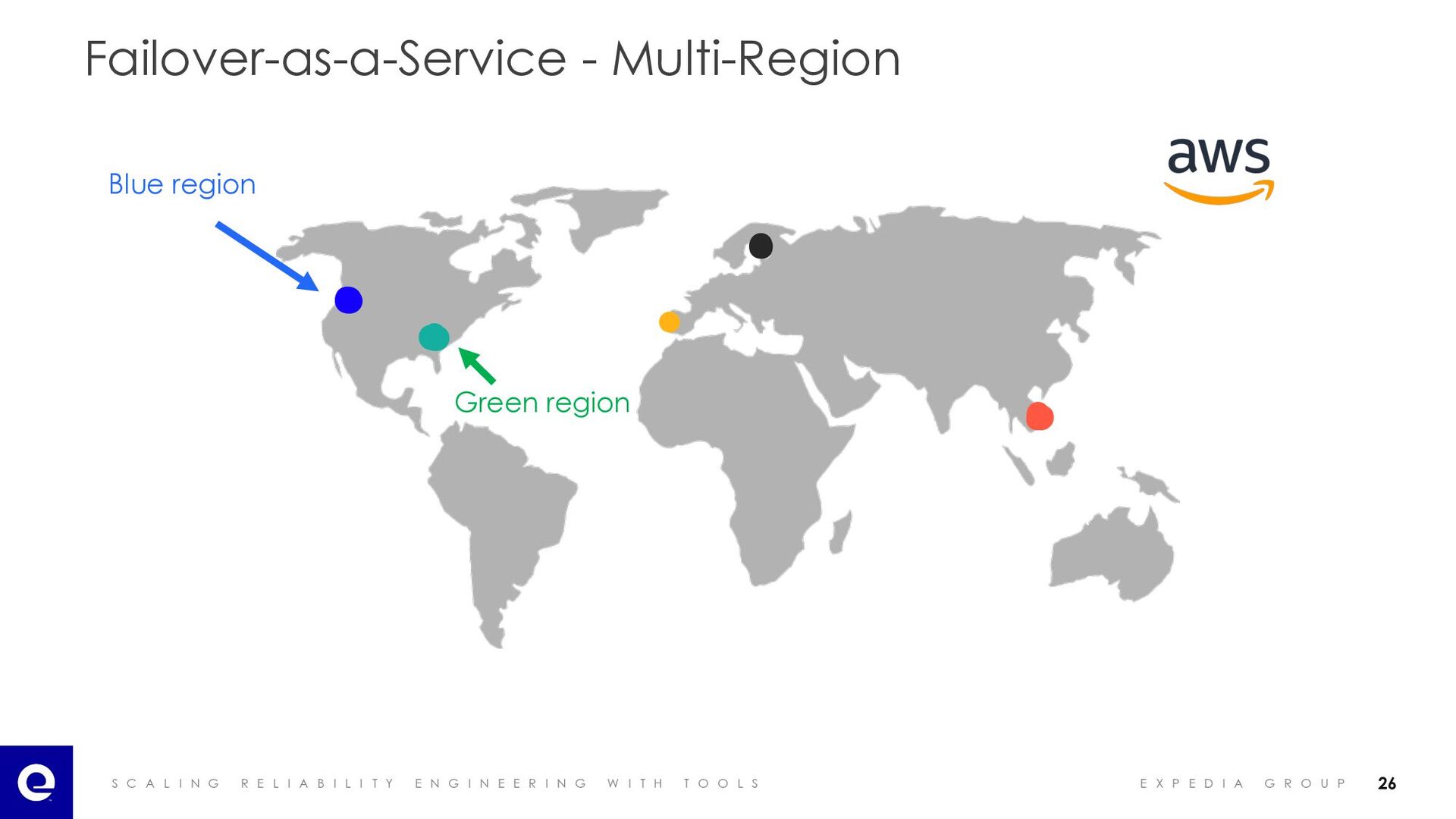
I A B I L I T Y E N G I N E E R I N G W I T H T O O L S E X P E D I A G R O U P Failover-as-a-Service - Recovering from Failures 24 Source: https://commons.wikimedia.org
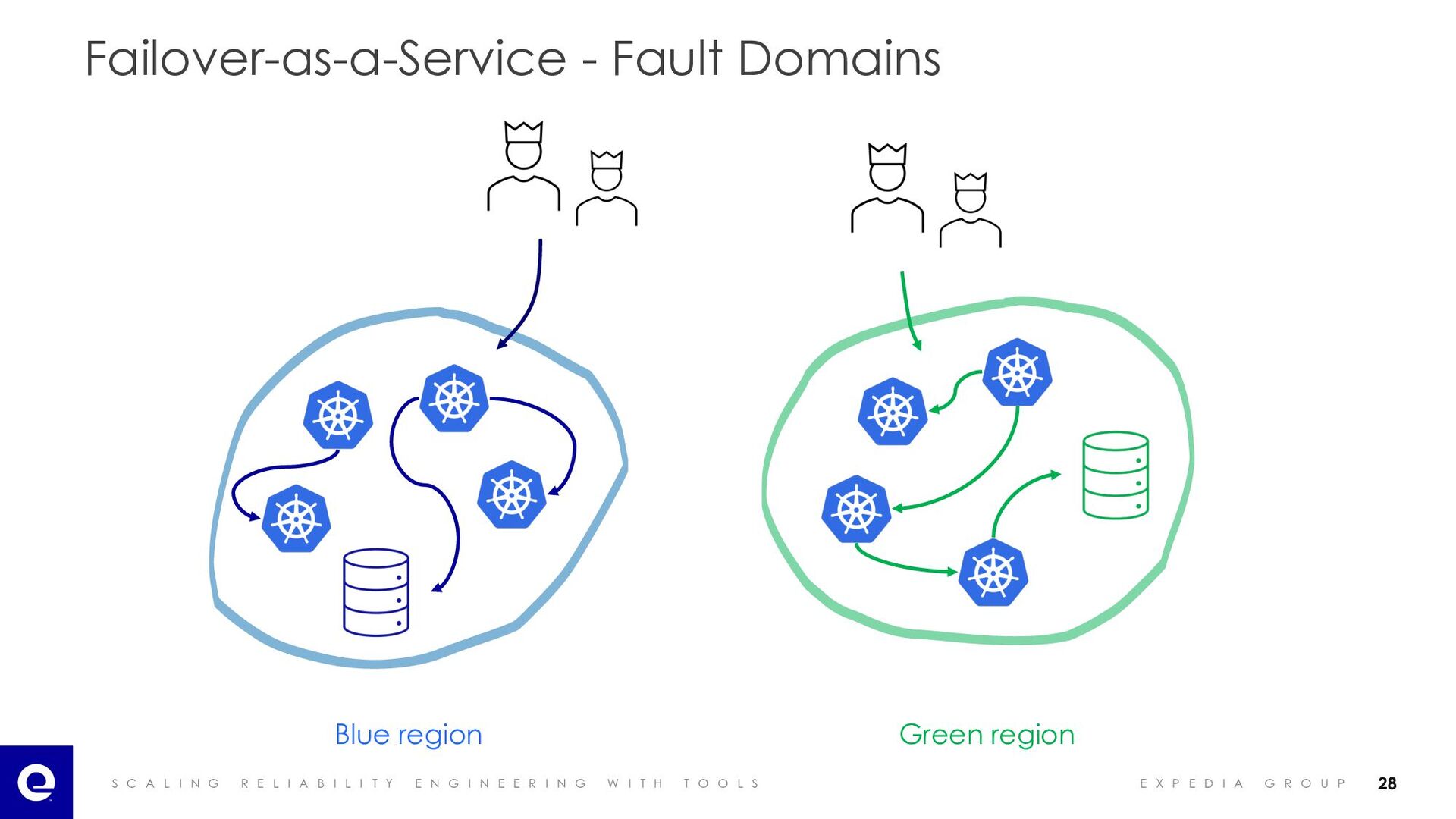
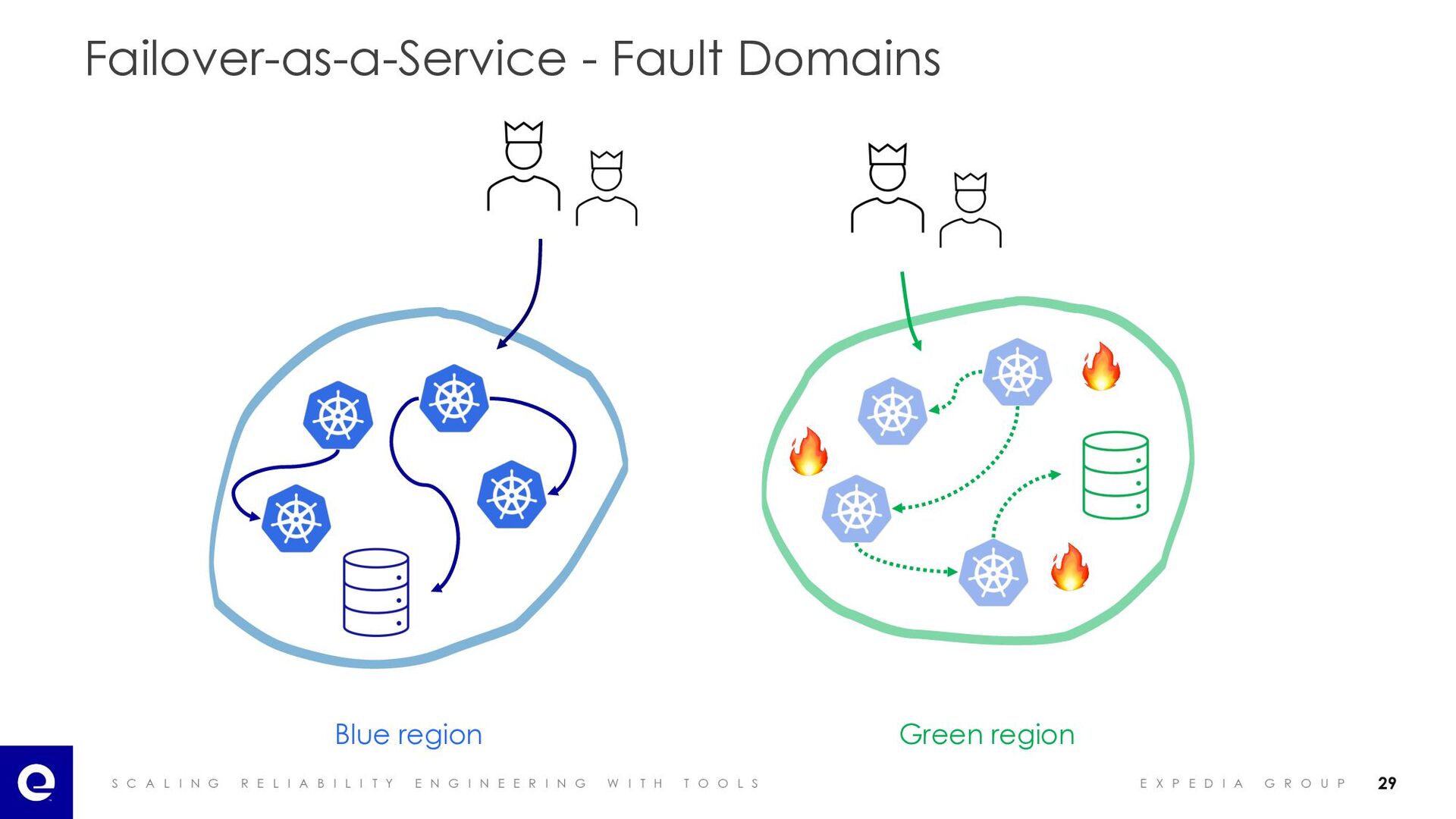
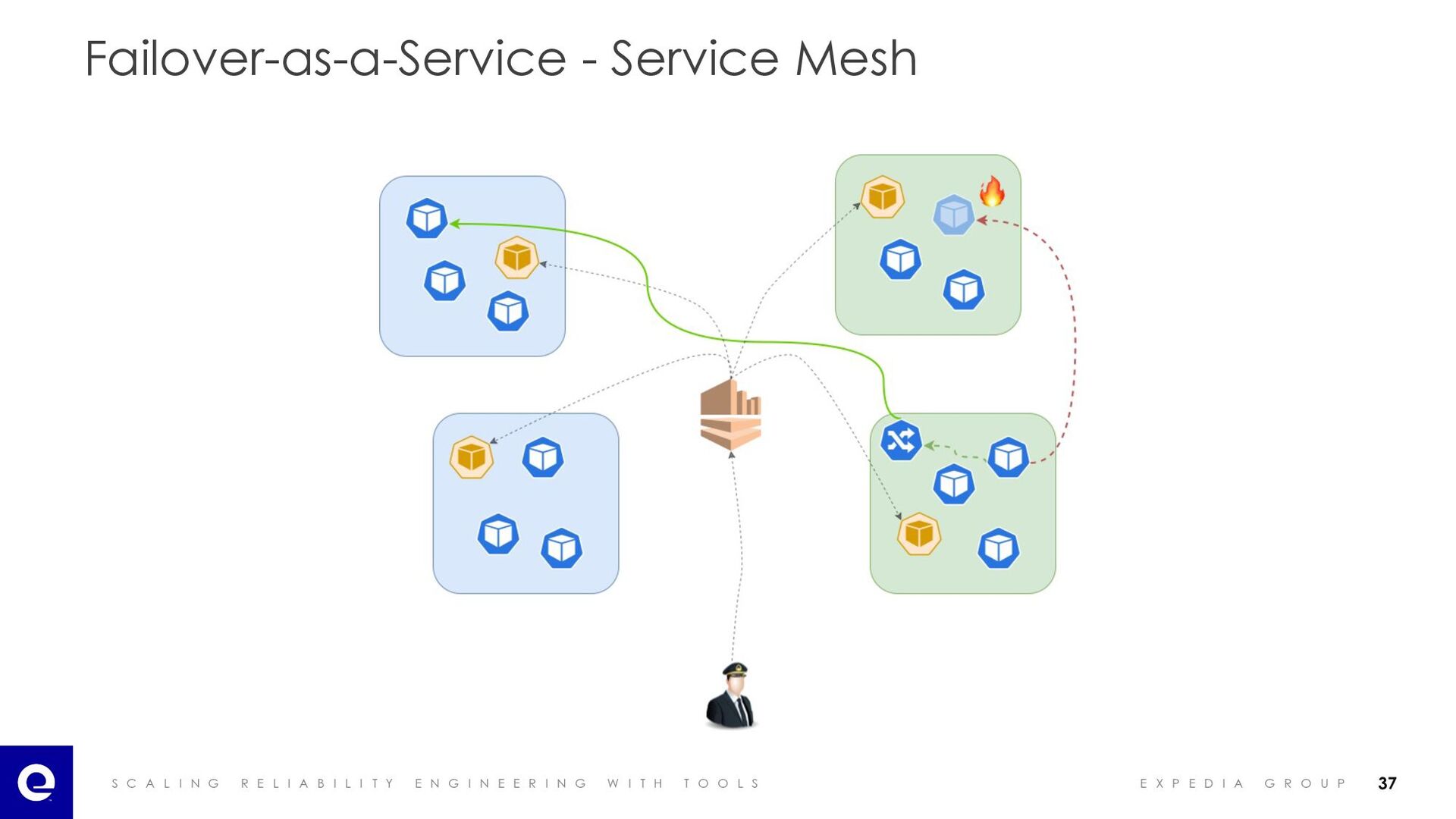
I A B I L I T Y E N G I N E E R I N G W I T H T O O L S E X P E D I A G R O U P Failover-as-a-Service - Fault Domains 🔥 🔥 🔥 Blue region Green region 29
I A B I L I T Y E N G I N E E R I N G W I T H T O O L S E X P E D I A G R O U P Failover-as-a-Service - Regional Evacuation 30 Source: https://www.theintelligencer.net
I A B I L I T Y E N G I N E E R I N G W I T H T O O L S E X P E D I A G R O U P Failover-as-a-Service - Small Isolated Failures 31 Source: https://www.geograph.ie
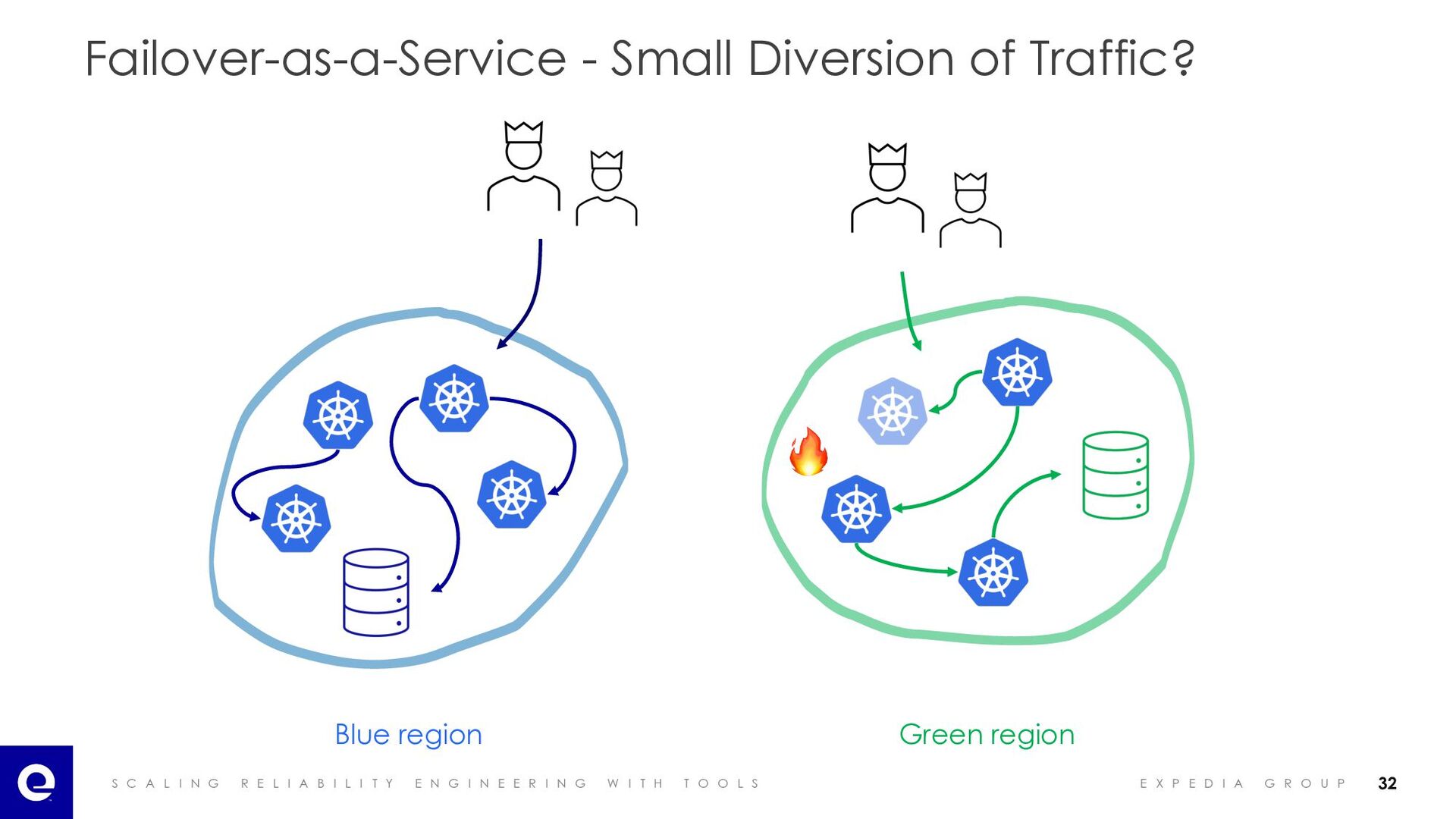
I A B I L I T Y E N G I N E E R I N G W I T H T O O L S E X P E D I A G R O U P Failover-as-a-Service - Small Diversion of Traffic? Blue region Green region 🔥 32
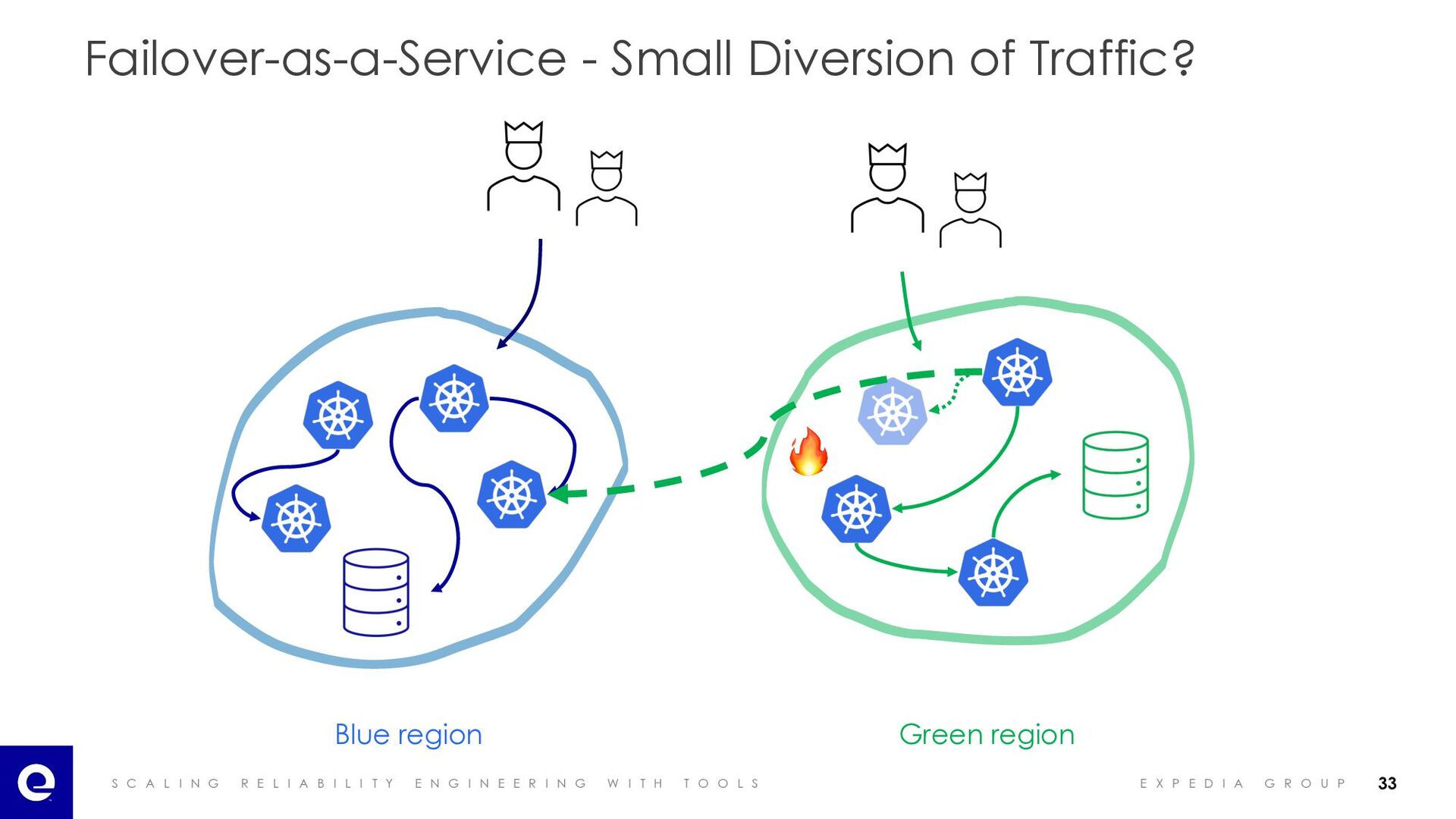
I A B I L I T Y E N G I N E E R I N G W I T H T O O L S E X P E D I A G R O U P Failover-as-a-Service - Small Diversion of Traffic? Blue region Green region 🔥 33
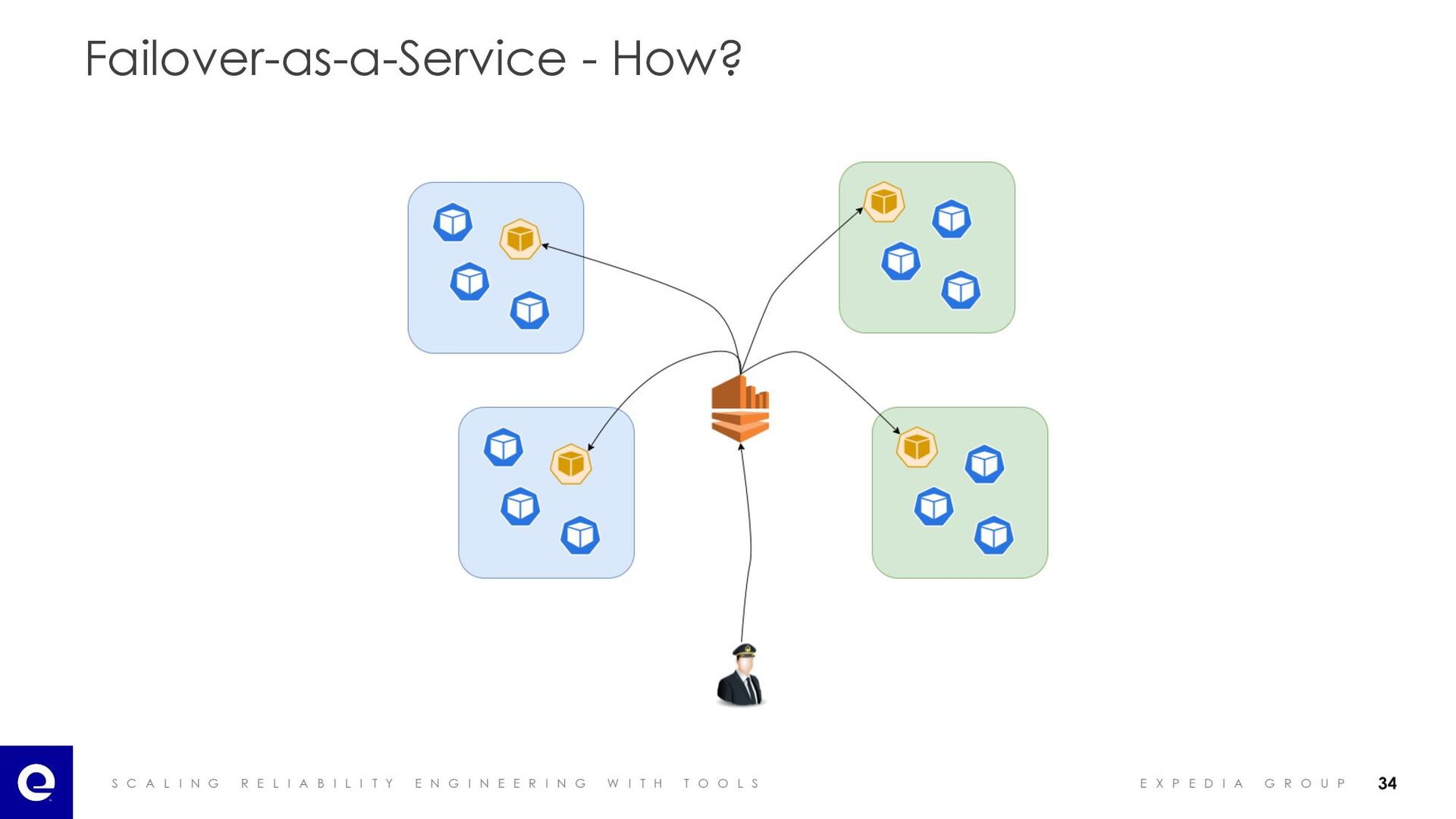
I A B I L I T Y E N G I N E E R I N G W I T H T O O L S E X P E D I A G R O U P Failover-as-a-Service - Capabilities Scaling up infra Scaling up workloads Custom actions Gradual traffic shifting 38
I A B I L I T Y E N G I N E E R I N G W I T H T O O L S E X P E D I A G R O U P Key Takeaways • Reactive reliability should not be your only strategy • Use tools to facilitate prevention of and recovery from incidents • Identify and verify failure modes of your systems • Practice incidents • Automate recovery Invest in Proactive Reliability • Know your customers • Get early and constant feedback • Automate as much as you can • Provide great developer experience • Have ways to measure adoption • Users will not come to you, you should go to them Focus on Customer • Reduce fragmentation • Create an on-road platform experience • Integrate with existing platforms and tools • De-prioritise legacy systems • Focus on adoption Consolidate tooling 40
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}