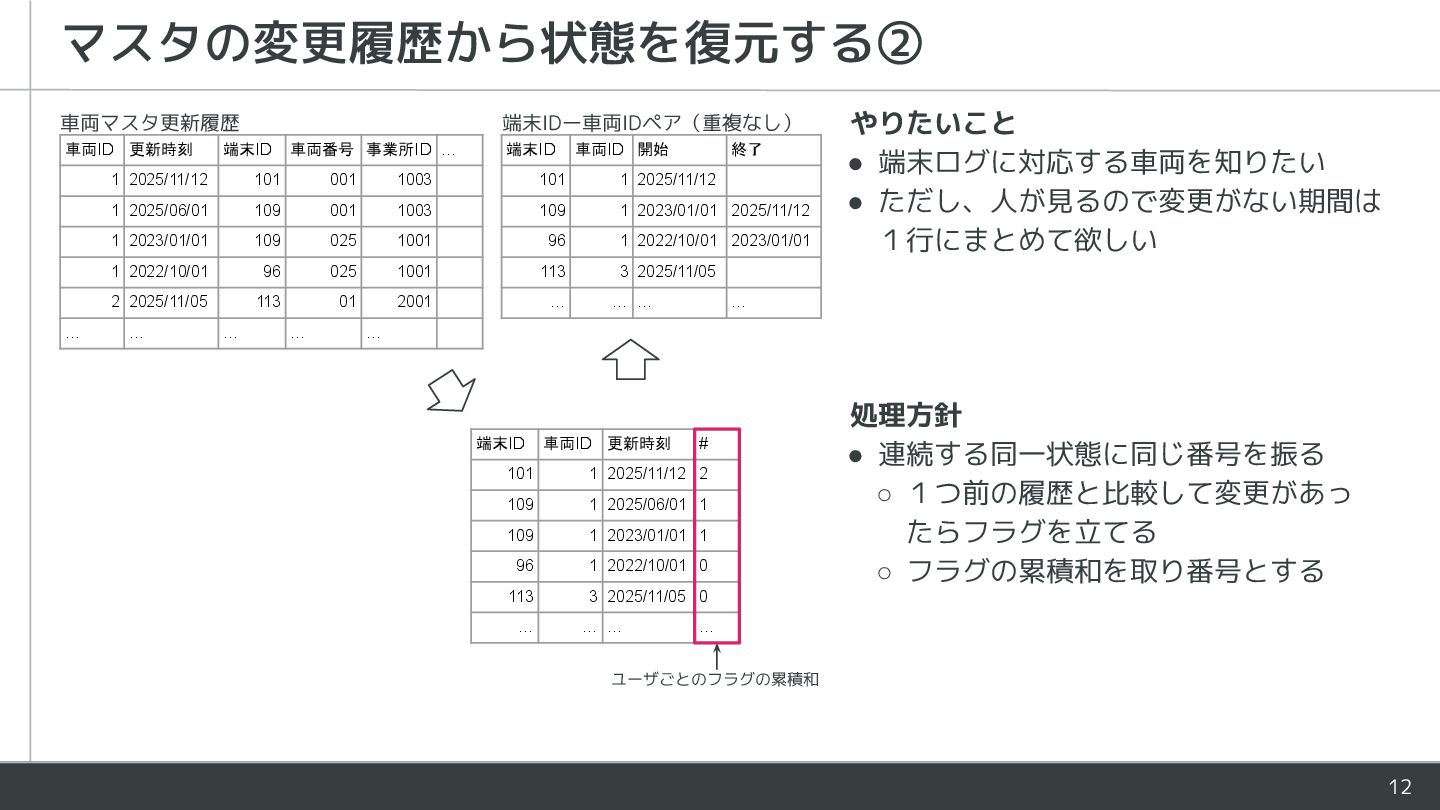
(partition by car_id order by updated_at rows between unbounded preceding and current row) as serial_no, from ( select car_id, device_id, if (lag(device_id) over w != device_id, 1, 0) as is_changed, updated_at, ifnull(lead(updated_at) over w, '3000-01-01') as lead_updated_at, from car_history window w as (partition by car_id order by updated_at) ) ) select car_id, device_id, min(updated_at) as start_ts, max(lead_updated_at) as end_ts, from car_device_pair group by car_id, device_id, serial_no order by car_id, start_ts -- debug 1つ前の履歴と比較†して変更があったらフラグを立てる フラグの累積和を取り番号を作る この番兵がないと直近の期間が作られないので注意 ※分析関数(ここだとlagとsum)は入れ子にできないので 1ステップずつ副問になってしまうのは残念な所 †複数項目あるならformat('%t %t %t', val1, val2, val3) のように1つの値にまとめると楽
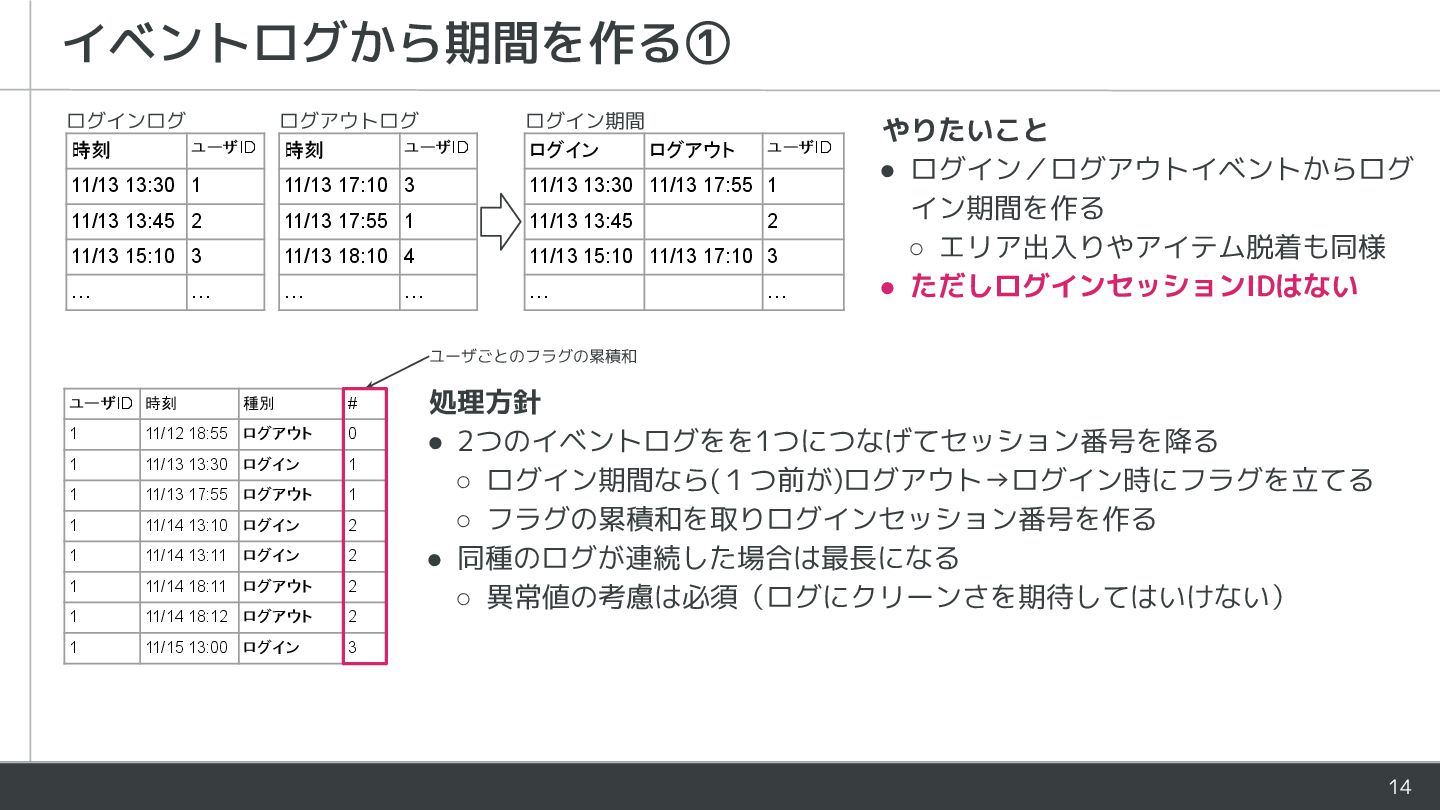
as tp, from login union all select user_id, ts, 'logout' as tp, from logout ) select user_id, min(if(tp='login', ts, NULL)) as login_ts, max(if(tp='logout', ts, NULL)) as logout_ts, from ( select *, sum(is_start) over ( partition by user_id order by ts rows between unbounded preceding and current row ) as session_no, from ( select *, if (lag(tp) over (partition by user_id order by ts) = 'logout' and tp = 'login', 1, 0) as is_start, from event_log ) ) group by user_id, session_no having login_ts is not NULL -- 最初のログがログアウトを除外 order by user_id, login_ts -- debug 2つのイベントログを1つにつなげる ログアウト→ログイン時にフラグ1を立てる フラグの累積和を取りログインセッション番号を作る 単にmin(ts)とmax(ts)だと集計期間の都合で ログインがないケースで問題となる
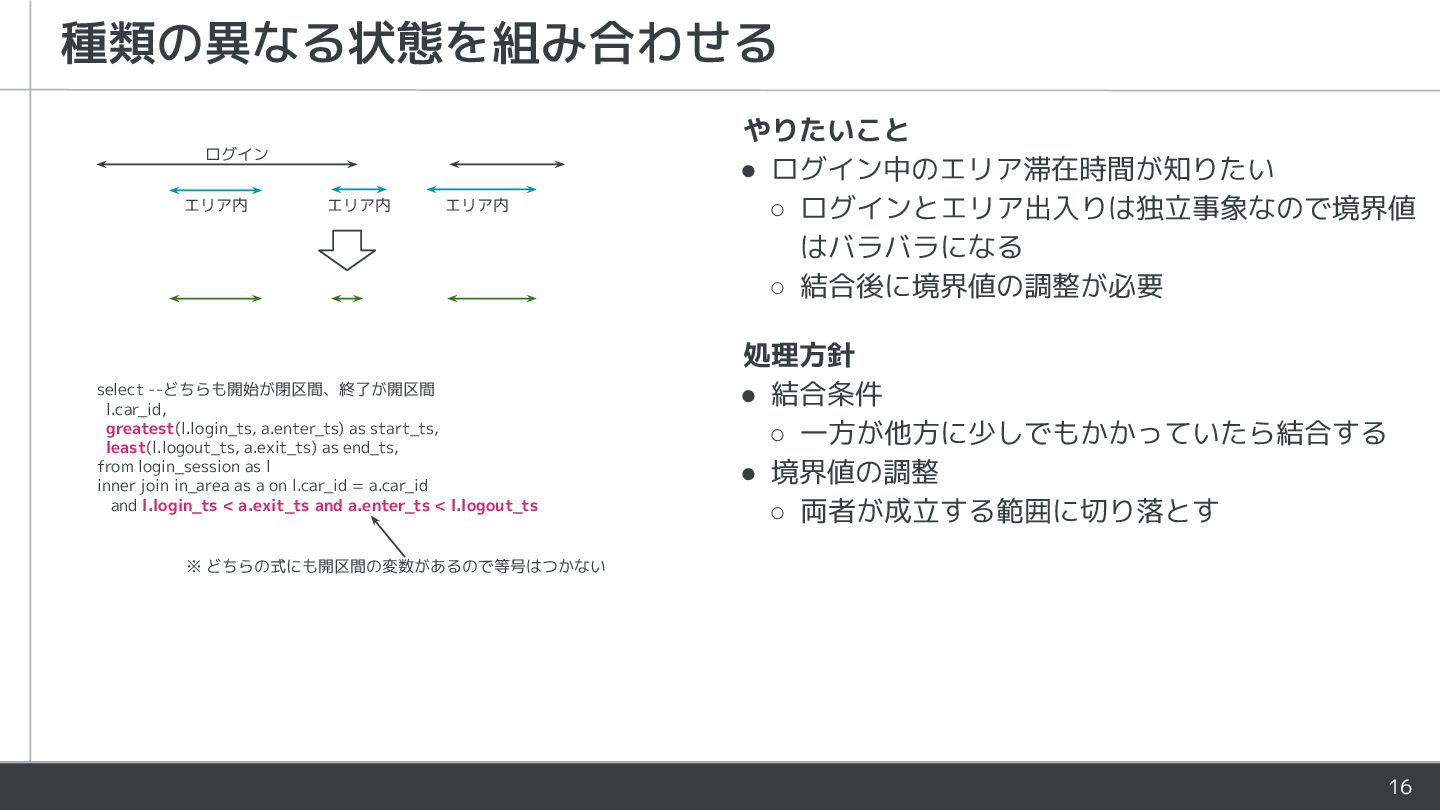
ログイン エリア内 エリア内 エリア内 select --どちらも開始が閉区間、終了が開区間 l.car_id, greatest(l.login_ts, a.enter_ts) as start_ts, least(l.logout_ts, a.exit_ts) as end_ts, from login_session as l inner join in_area as a on l.car_id = a.car_id and l.login_ts < a.exit_ts and a.enter_ts < l.logout_ts ※ どちらの式にも開区間の変数があるので等号はつかない 処理方針 • 結合条件 ◦ 一方が他方に少しでもかかっていたら結合する • 境界値の調整 ◦ 両者が成立する範囲に切り落とす
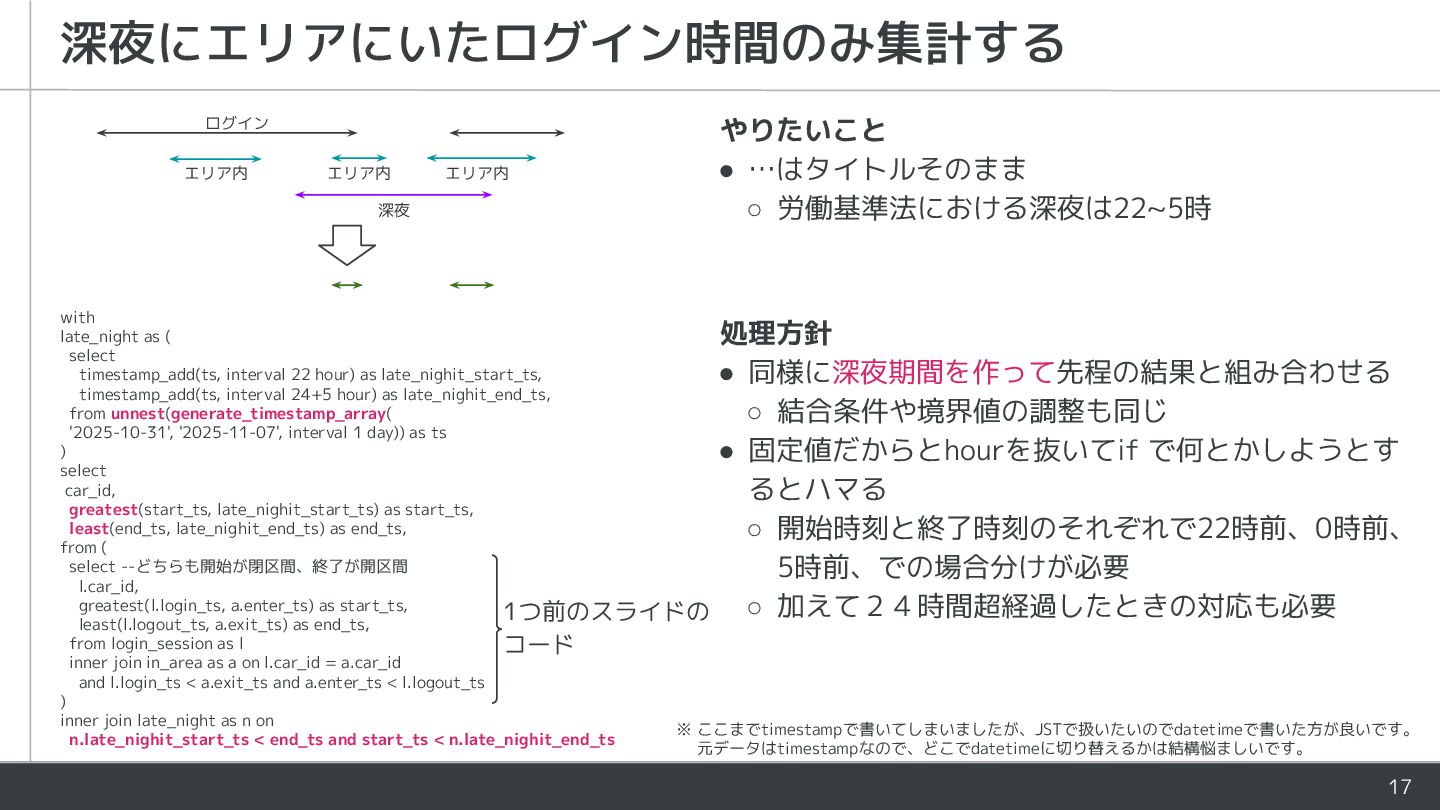
エリア内 深夜 処理方針 • 同様に深夜期間を作って先程の結果と組み合わせる ◦ 結合条件や境界値の調整も同じ • 固定値だからとhourを抜いてif で何とかしようとす るとハマる ◦ 開始時刻と終了時刻のそれぞれで22時前、0時前、 5時前、での場合分けが必要 ◦ 加えて24時間超経過したときの対応も必要 with late_night as ( select timestamp_add(ts, interval 22 hour) as late_nighit_start_ts, timestamp_add(ts, interval 24+5 hour) as late_nighit_end_ts, from unnest(generate_timestamp_array( '2025-10-31', '2025-11-07', interval 1 day)) as ts ) select car_id, greatest(start_ts, late_nighit_start_ts) as start_ts, least(end_ts, late_nighit_end_ts) as end_ts, from ( select --どちらも開始が閉区間、終了が開区間 l.car_id, greatest(l.login_ts, a.enter_ts) as start_ts, least(l.logout_ts, a.exit_ts) as end_ts, from login_session as l inner join in_area as a on l.car_id = a.car_id and l.login_ts < a.exit_ts and a.enter_ts < l.logout_ts ) inner join late_night as n on n.late_nighit_start_ts < end_ts and start_ts < n.late_nighit_end_ts ※ ここまでtimestampで書いてしまいましたが、JSTで扱いたいのでdatetimeで書いた方が良いです。 元データはtimestampなので、どこでdatetimeに切り替えるかは結構悩ましいです。 1つ前のスライドの コード
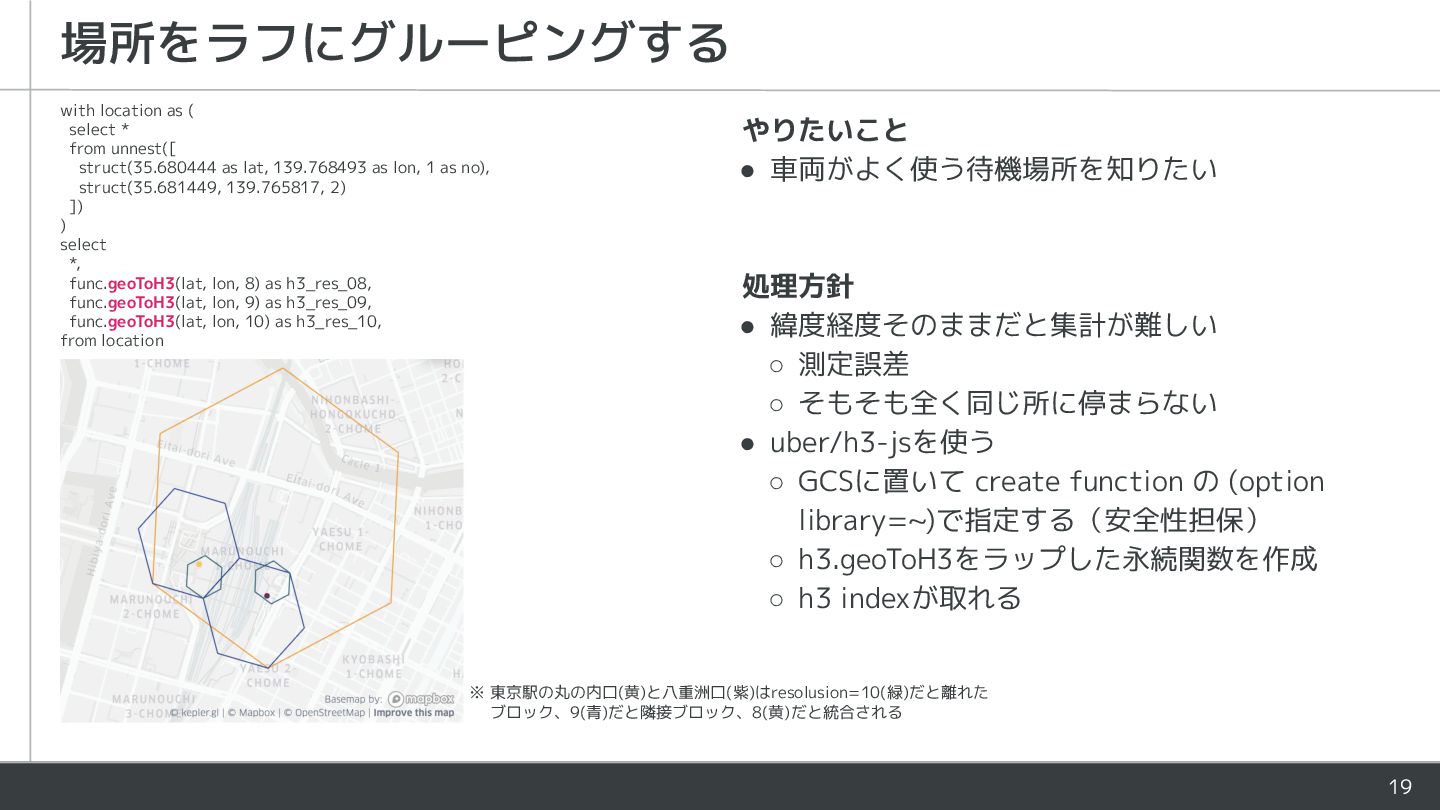
◦ そもそも全く同じ所に停まらない • uber/h3-jsを使う ◦ GCSに置いて create function の (option library=~)で指定する(安全性担保) ◦ h3.geoToH3をラップした永続関数を作成 ◦ h3 indexが取れる with location as ( select * from unnest([ struct(35.680444 as lat, 139.768493 as lon, 1 as no), struct(35.681449, 139.765817, 2) ]) ) select *, func.geoToH3(lat, lon, 8) as h3_res_08, func.geoToH3(lat, lon, 9) as h3_res_09, func.geoToH3(lat, lon, 10) as h3_res_10, from location ※ 東京駅の丸の内口(黄)と八重洲口(紫)はresolusion=10(緑)だと離れた ブロック、9(青)だと隣接ブロック、8(黄)だと統合される
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![21 ▪ 今回はBigQueryでややこしい処理を書くときの小ネタを紹介しました ▪ 未調査ですが他のDBでも使える所はありそうです、ご参考まで ▪ それでは皆様良いBigQueryライフを! おわりに ※ unnest([...])でモンテカルロ法をやろうとして怒られた所](https://files.speakerdeck.com/presentations/39718bc18aec41bf8522debf60de8943/slide_20.jpg){kind=link}