Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
多段解析法による形態素解析を用いた音声合成用読み韻律情報設定法とその単語辞書構成
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
nishi-k
July 08, 2016
0
220
多段解析法による形態素解析を用いた音声合成用読み韻律情報設定法とその単語辞書構成
nishi-k
July 08, 2016
Tweet
Share
More Decks by nishi-k
See All by nishi-k
自動抽出した換喩表現を用いた係り受け関係のずれの解消
nishiyama
0
370
日本語解析システム「雪だるま」における表記ゆれの拡張とまとめあげ
nishiyama
0
1.2k
画像検索を用いた語義別画像付き辞書の構築
nishiyama
0
180
質問応答に基づく対災害情報分析システム
nishiyama
0
260
対話システム
nishiyama
0
310
動詞名詞換言辞書の構築と敬語の常体への換言
nishiyama
0
550
情報検索2
nishiyama
0
130
2016/02/17 情報検索
nishiyama
0
160
文脈の解析
nishiyama
0
460
Featured
See All Featured
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
71
CoffeeScript is Beautiful & I Never Want to Write Plain JavaScript Again
sstephenson
162
16k
Highjacked: Video Game Concept Design
rkendrick25
PRO
1
320
Paper Plane (Part 1)
katiecoart
PRO
0
5.6k
ラッコキーワード サービス紹介資料
rakko
1
2.6M
JavaScript: Past, Present, and Future - NDC Porto 2020
reverentgeek
52
5.9k
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
1
320
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
680
Un-Boring Meetings
codingconduct
0
220
RailsConf 2023
tenderlove
30
1.4k
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillation
inesmontani
PRO
3
2.1k
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
Transcript
多段解析法による形態素解析を用いた音声合成用 読み韻律情報設定法とその単語辞書構成 長岡技術科学大学 自然言語処理研究室 学部4年 西山 浩気
参考文献 浅野 久子,松岡 浩司,高木 伸一郎,小原 永, 多段解析法による形態素解析を用いた 音声合成用読 み韻律情報設定法
と その単語辞書構成, 自然言語処理, Vol.6(1999), No.2, pp.59-81 2
概要 日本語テキスト音声合成 自然で聴きやすい音声を出力 アクセント , ポーズ等の読み韻律情報を正しく設定
多段解析法に基づく形態素解析を用いて、読み韻律情 報を設定する方法 読み韻律情報を設定するために用いる単語辞書情報 ニュース文章を対象にした評価で、読み韻律情報を正し く設定でき、有効性を確認 3
はじめに 日本語テキスト音声合成 入力: 漢字かな混じりのテキスト 入力文に音律情報を設定 読み
アクセント句,ポーズ アクセント型 出力:合成音声を出力 読み韻律情報からピッチや時間長データを設定し波形を生成する ⇒ 自然で聴きやすい合成音声を出力するためには、 読み韻律情報の正しい設定が必要 4
はじめに アクセント句境界・ポーズ 係り受け構造を利用した手法 係り受け等の既知の言語的情報があることが前提 ⇒ 前提となる言語情報の取得が困難 ⇒係り受け解析の精度が十分ではない
N文節の品詞情報を用いた局所的な係り受け情報の取得(鈴 木, 斉藤 1995) 文節内の処理については言及なし 品詞列を入力として確立文脈自由文法を用いて係り受けを学 習 (藤尾, 匂坂, 樋口 1997) 文節内構造の予測誤りによる精度の低下が問題 6
はじめに 本論文では AUDIOTEXにおける 形態素解析における読み韻律情報付与に対応した長単位認定 アクセント句境界設定における複数文節アクセント句の設定
ポーズ設定における多段階設定法の導入 以上の処理における単語辞書の構成 について説明 (宮崎, 大山 1986)の方式がベース 読み韻律情報設定の際に文節間の係り受け解析は行わない 7
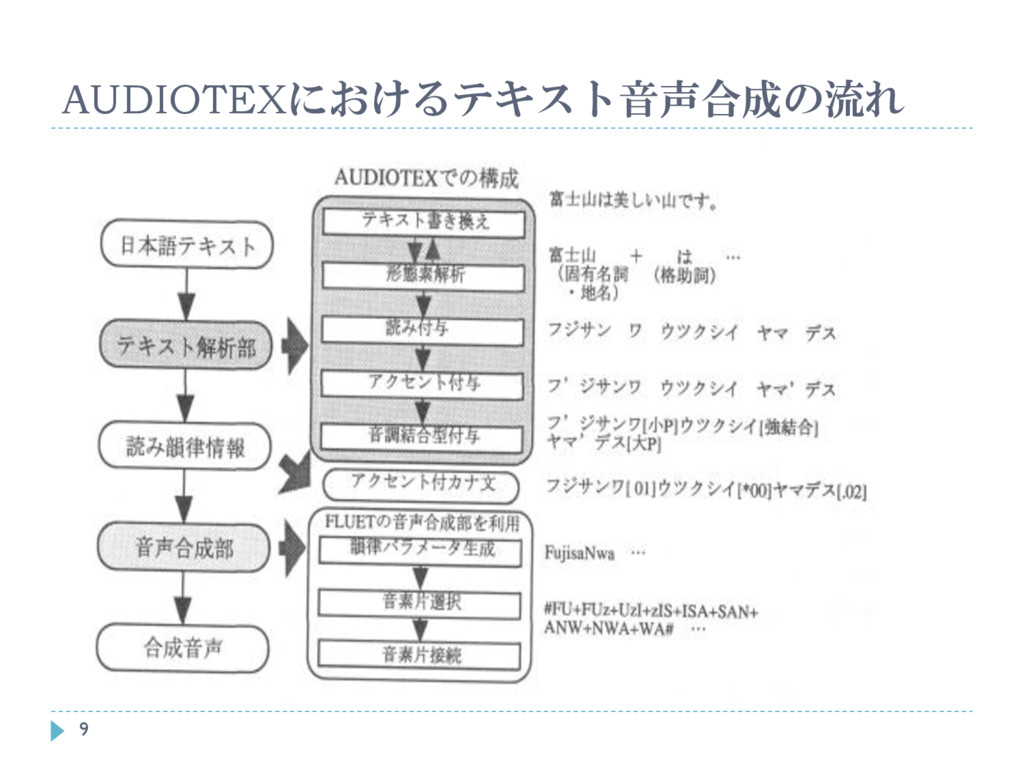
AUDIOTEX AUDIOTEX: 日本語音声合成システム 1.読み韻律情報を設定 多段解析法による形態素解析を用いて得られた単語情報から規則 を獲得
2.合成音声を出力 音声合成ソフトウェア FLUET (Hakoda et al. 1995) 特徴 単語辞書の登録数が多く、形態素解析で未知語認定が少ない. 他のシステムにない意味カテゴリ等の意味情報がある. 複合語の意味的係り受け解析の精度が高い. 8
AUDIOTEXにおけるテキスト音声合成の流れ 9
読み韻律情報設定のための単語辞書情報 10 長単位語(複合語など)への対応 基本的には単語辞書には短単位語が登録されている 短単位語を組み合わせて長単位語とする 一部例外として長単位で登録
連語:補助用言(~している) , 格助詞相当語 (~について) 一部の慣用表現、熟語、並列語 (一期一会, 日仏英) 短単位語の組み合わせでは正しくアクセントを設定できないため. 有名な人名・地名、一般語で構成される固有名詞 (羽生善治(ハブヨシハル), 清水寺(キヨミズデラ), 週刊住宅情報) 一般語のみで構成される固有名詞を認定させるため. 国語辞典に子見出し語や派生語として収録されている一般用語
読み韻律情報設定のための単語辞書情報 11 長単位語を1語として扱う場合の問題 一般的に形態素解析の性能は向上 アクセント等の設定において問題が発生 長単位の内部のアクセント句境界に対応できない
日仏英 ⇒ 日/ 仏/ 英 彼について ⇒ 彼に/ ついて 複合語を構成する単語数によりアクセント句境界を設定する場合に正 しくアクセントが設定できない 為替相場 (1語の場合) 形態素解析結果: “為替相場” + “速報” + “サービス” (3語 (実際は4語)) アクセント句 : “為替相場速報サービス” 正しくは : “為替相場/ 速報サービス ” ⇒ 長単位に対しても適切な読み韻律情報の設定をするための情報が必要
読み韻律情報設定のための単語辞書情報 12 アクセント句情報 長単位語を構成する短単位語のモーラ数(拍)などを保持 語数 登録単語を構成する単語数
例: 為替相場(2) 構成単語情報 各構成単語(最大10単語)の見出し長、品詞、読み長
読み音律情報の設定法 13 アクセント付与 先行研究:文節間でのアクセント結合は行っていない. 文節をアクセント句としていた. AUDIOTEX: 結びつきの強い文節間ではアクセント結合を行う
指示副詞 + 用言 例: そう + 思う(動詞) ⇒ そう思う 連体詞 + 名詞 ( ≠ 複合詞) 例: この + 会議 ⇒ この会議 複合語内の意味的な係り受け情報、複合語直後の単語の品 詞情報によって他の単語とアクセント結合するかを判断 例: 正月(時詞) + 番組 + で ⇒ 正月番組で : 今日(時詞) + 番組 + で ⇒ 今日/ 番組で
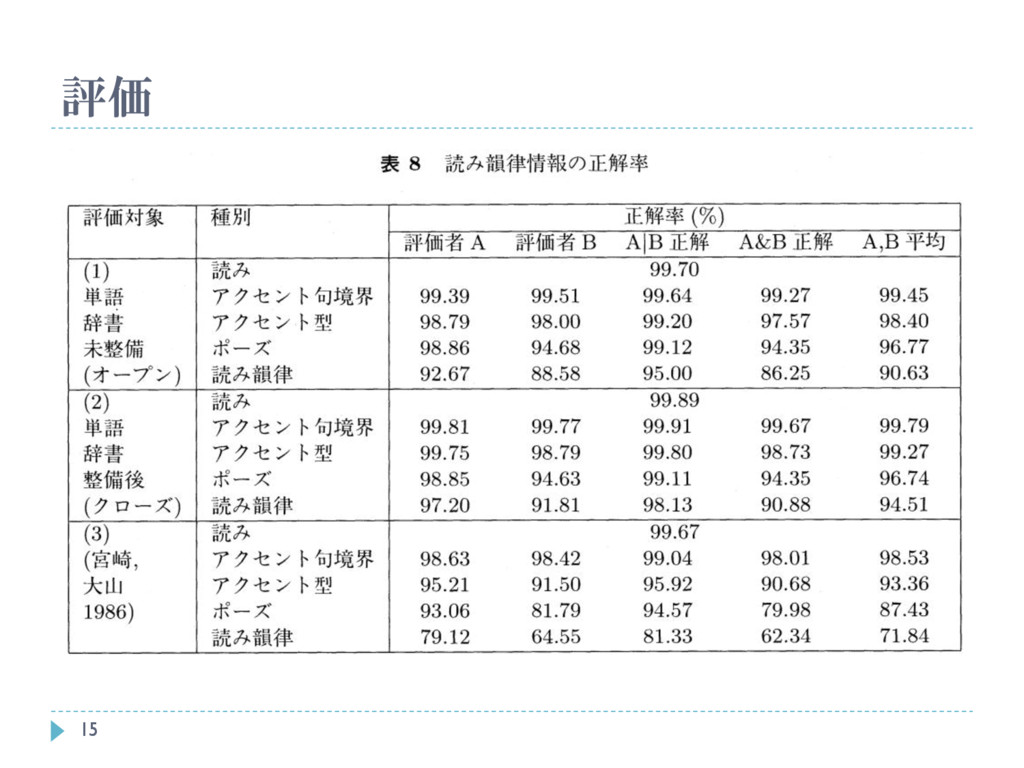
評価 14 評価対象 ニュース文章484文(29,829文) に対し、 1. 単語辞書を全く整備しない状態
(オープン評価) 2. 単語辞書の整備を行った後 (クローズ評価) 3. ベース手法 (宮崎, 大山 1986) により生成されたアクセント付きカナ文を2名の評価者で不自然に聞こえる 箇所を誤りとして評価
評価 15
誤り要因 16 読み誤り 同型語の読み分け誤り:75%(24件) 例: 香港ドルと元(×モト ⇒
◦ゲン) 例: 大勢 (×オオゼー ⇒ ◦タイセー) アクセント句境界誤り 形態素解析における品詞・単語境界の設定誤り:33%(9件) 例: 国会/ 会期末 ⇒ 国会/ 会期末 国会(固有名詞) + 会(接尾辞) + 期末(名詞) と解析される 数量表現において、通常は数詞が連続した場合:11%(3件) 例: 捜査/ 一課 ⇒ 捜査一課 捜査 と 一 の関連付けができない
まとめ 17 形態素解析から得られる単語情報を用いて、読み韻律 情報を規則により設定 読み韻律情報設定のための単語辞書の構成 2名の評価者による評価
単語辞書整備前の評価 95% 単語辞書整備後の評価 91% の精度で、読み韻律情報を正しく設定 単語辞書の精度に大きく依存しているため、単語辞書の 精度向上を容易に行う手法を考える必要がある
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}