Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
情報検索2
Search
nishi-k
March 01, 2016
Education
140
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
情報検索2
nishi-k
March 01, 2016
More Decks by nishi-k
See All by nishi-k
自動抽出した換喩表現を用いた係り受け関係のずれの解消
nishiyama
0
380
日本語解析システム「雪だるま」における表記ゆれの拡張とまとめあげ
nishiyama
0
1.2k
多段解析法による形態素解析を用いた音声合成用読み韻律情報設定法とその単語辞書構成
nishiyama
0
230
画像検索を用いた語義別画像付き辞書の構築
nishiyama
0
190
質問応答に基づく対災害情報分析システム
nishiyama
0
270
対話システム
nishiyama
0
320
動詞名詞換言辞書の構築と敬語の常体への換言
nishiyama
0
560
2016/02/17 情報検索
nishiyama
0
170
文脈の解析
nishiyama
0
500
Other Decks in Education
See All in Education
2026年度春学期 統計学 第1回 イントロダクション ー 統計的なものの見方・考え方について (2026. 4. 9)
akiraasano
PRO
0
180
生成AI時代の情報発信
molmolken
0
140
プログラミング言語において文字列を複数行にわたって だらだらと記載するアレ
sapi_kawahara
0
170
「機械学習と因果推論」入門 ② 回帰分析から因果分析へ
masakat0
0
720
自己紹介 / who-am-i
yasulab
6
7k
焦燥を平穏に変えるエンジニアのための哲学
ichimichi
5
4.5k
2026年度春学期 統計学 第2回 統計資料の収集と読み方 (2026. 4. 16)
akiraasano
PRO
0
200
From Days to Minutes: How We Taught an AI to Onboard 50+ Tenants on our AI Features
mfcabrera
0
190
Case Studies and Future Research - Lecture 12 - Next Generation User Interfaces (4018166FNR)
signer
PRO
0
180
AI時代に、 なぜ英語を勉強するのか
empelt
0
120
コミュニティを通じた_キャリア設計のススメ_20260424.pdf
masakiokuda
0
340
Visionary Initiative: Materials-Positive Society 「モノの進化をポジティブな社会の原動力に」|Science Tokyo(東京科学大学)
sciencetokyo
PRO
0
520
Featured
See All Featured
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
290
A Modern Web Designer's Workflow
chriscoyier
698
190k
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.7k
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.1k
Agile Leadership in an Agile Organization
kimpetersen
PRO
0
170
SEO Brein meetup: CTRL+C is not how to scale international SEO
lindahogenes
1
2.7k
Building AI with AI
inesmontani
PRO
1
1.1k
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.3k
Mind Mapping
helmedeiros
PRO
1
270
How to optimise 3,500 product descriptions for ecommerce in one day using ChatGPT
katarinadahlin
PRO
1
3.6k
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
570
Transcript
-情報検索(2)- 第9回 B3勉強会 2016年2月3日 自然言語処理研究室 学部3年 西山 浩気
はじめに 参考文献 黒橋 貞夫, 自然言語処理, 放送大学教 育振興会,(2015.3.20),pp.146-153 発表内容
◦ 1. 情報検索の評価 ◦ 2. ウェブ検索の仕組み ◦ 3. ページランク
前回の復習 クエリ ◦ 検索したい内容を表現する語集合 例: 「言語 コンピュータ」で検索
1万件以上がマッチする ⇒ 関連度の高い文章でランキングする必要がある! ベクトル空間モデル ◦ ベクトル間の類似度を用いてクエリに対する 文書のランキングを行う cos (d 文書1 , q) = 0.83 cos (d 文書2 , q) = 0.38 cos (d 文書3 , q) = 0.74 cos (d 文書4 , q) = 0.30 cos (d 文書5 , q) = 0.00
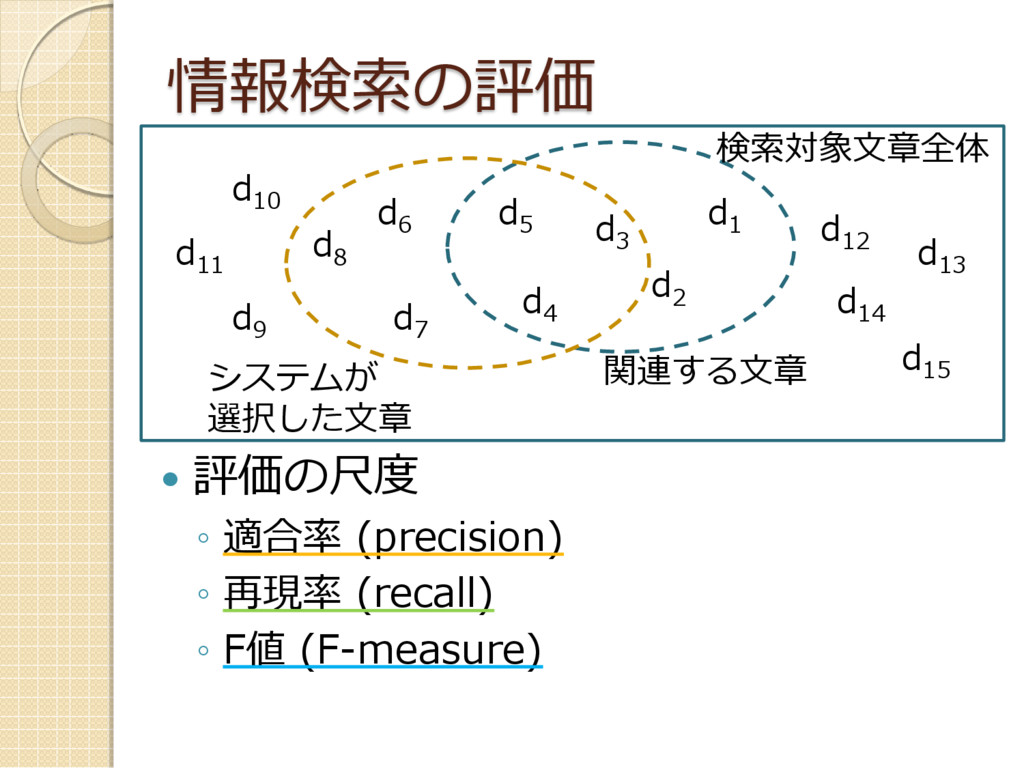
情報検索の評価 評価の尺度 ◦ 適合率 (precision) ◦ 再現率 (recall) ◦
F値 (F-measure) d 4 d 5 d 2 d 1 d 3 d 6 d 7 d 8 d 9 d 11 d 10 d 12 d 13 d 14 d 15 関連する文章 システムが 選択した文章 検索対象文章全体
適合率、再現率、F値 適合率 = |システムの選択文書 ∩ 関連文書| |システムの選択文書| = 3
/ 6 = 0.5 再現率 = |システムの選択文書 ∩ 関連文書| |関連文書| = 3 / 5 = 0.6 F値 = 2 × 適合率 × 再現率 適合率 + 再現率 = 2 × 0.5 × 0.6 = 0.6 0.5 + 0.6
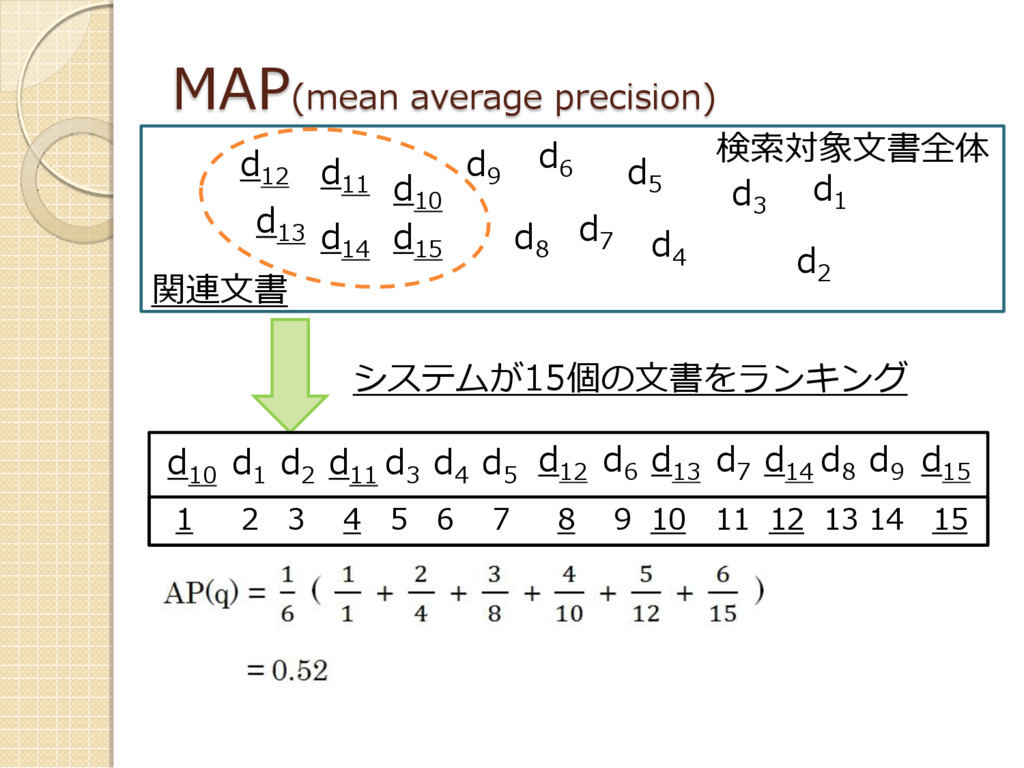
適合率・再現率・F値 ◦ 各文書が関連するか否か 多くの文書から必要な文書を抽出するためにはラン ク付きで返すことが重要 平均適合率(average precision)
: AP(q) ◦ AP(q) = n : qに関連のある文書数 r k : システムのランキングの中でk 番目の関連文書 のランキング MAP(mean average precision)
MAP(mean average precision) d 4 d 5 d 2 d
1 d 3 d 6 d 7 d 8 d 9 d 11 d 10 d 12 d 13 d 14 d 15 検索対象文書全体 システムが15個の文書をランキング 関連文書 d 10 d 1 d 2 d 11 d 3 d 4 d 5 d 12 d 6 d 13 d 7 d 14 d 8 d 9 d 15 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
MAP(mean average precision) m個の評価クエリの集合 Q ◦ Q = {
q 1 ,q 2 ,...q m }
ウェブ検索の仕組み 誘導型(navigational) ◦ 存在することが予想されるページを見つ けることが目的(企業や行政) クエリは企業名など クエリとは独立に、ページの重要度を考える
調査型(informational) ◦ 何を調べたいかが明確でない クエリとページの関連度が重要 ページの重要度も重要
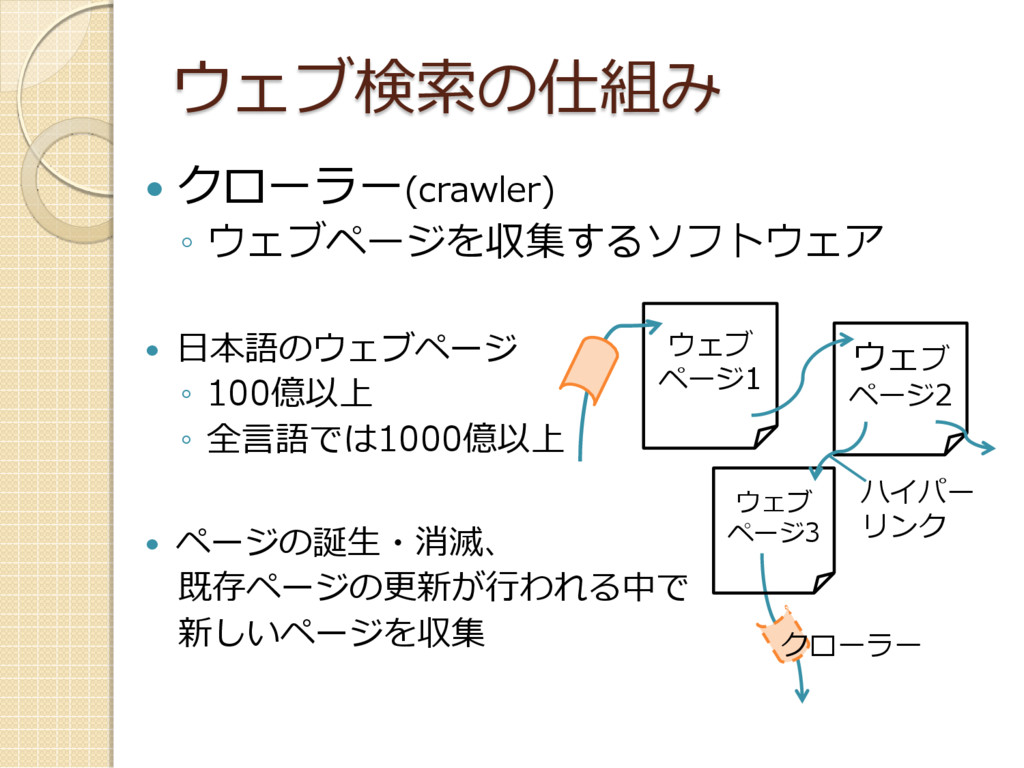
クローラー(crawler) ◦ ウェブページを収集するソフトウェア 日本語のウェブページ ◦ 100億以上 ◦ 全言語では1000億以上
ページの誕生・消滅、 既存ページの更新が行われる中で 新しいページを収集 ウェブ検索の仕組み ハイパー リンク ウェブ ページ1 ウェブ ページ2 ウェブ ページ3 クローラー
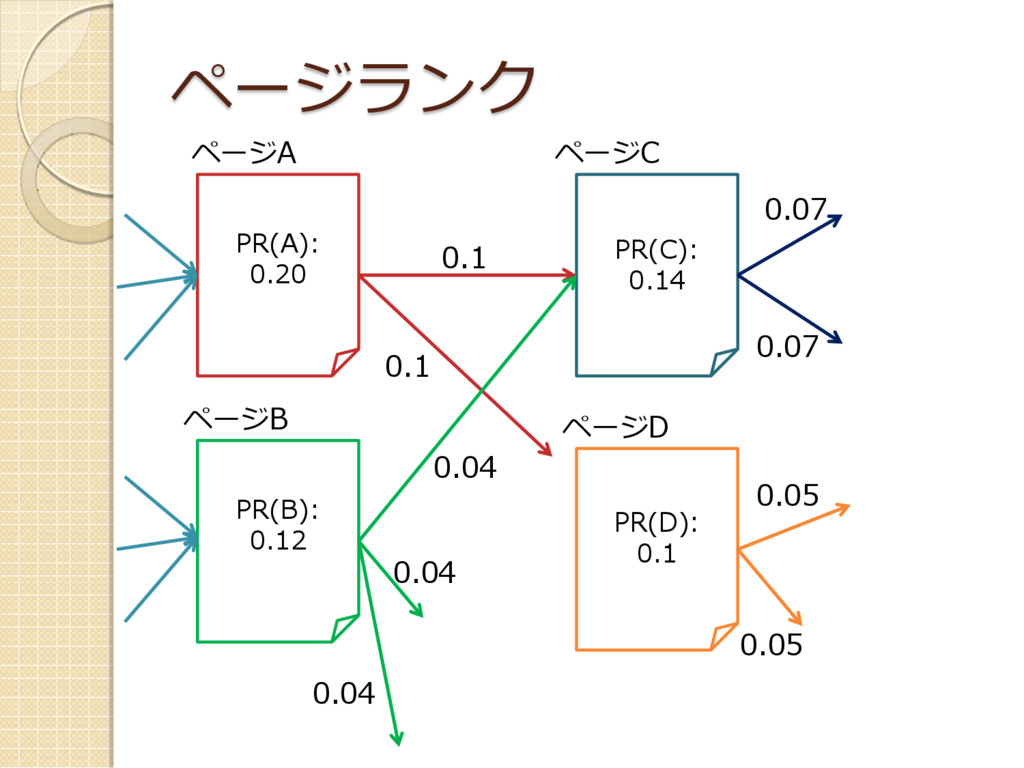
ページランク ページランク(PageRank) ◦ ハイパーリンクによるウェブの構造のみを利用 してページの重要度を計算するアルゴリズム 考え方:「重要なページは重要なページからリンク されている」
ページu の重要度PR(u) ◦ B u : ページuをリンクしてるページの集合 ◦ L v : ページvからのリンク数 ◦ N : 検索対象とするウェブページの総数 ◦ D: ダンピング・ファクター (0.85程度)
ページランク PR(A): 0.20 PR(B): 0.12 ページA ページB ページC 0.1 0.1
0.04 0.04 0.04 ページD 0.05 0.05 0.07 0.07 PR(C): 0.14 PR(D): 0.1
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}