Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
2016/02/17 情報検索
Search
nishi-k
February 16, 2016
Education
170
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
2016/02/17 情報検索
nishi-k
February 16, 2016
More Decks by nishi-k
See All by nishi-k
自動抽出した換喩表現を用いた係り受け関係のずれの解消
nishiyama
0
380
日本語解析システム「雪だるま」における表記ゆれの拡張とまとめあげ
nishiyama
0
1.2k
多段解析法による形態素解析を用いた音声合成用読み韻律情報設定法とその単語辞書構成
nishiyama
0
230
画像検索を用いた語義別画像付き辞書の構築
nishiyama
0
190
質問応答に基づく対災害情報分析システム
nishiyama
0
270
対話システム
nishiyama
0
330
動詞名詞換言辞書の構築と敬語の常体への換言
nishiyama
0
560
情報検索2
nishiyama
0
140
文脈の解析
nishiyama
0
500
Other Decks in Education
See All in Education
2026年度春学期 統計学 第13回 不確かな測定の不確かさを測る ― 不偏分散とt分布 (2026. 6. 25)
akiraasano
PRO
1
110
Implicit and Cross-Device Interaction - Lecture 10 - Next Generation User Interfaces (4018166FNR)
signer
PRO
2
2.3k
Course Review - Lecture 13 - Information Visualisation (4019538FNR)
signer
PRO
1
2.7k
Laura Wilson - The Quarterly PR Pivot
laurawilsonbseo1
1
370
Visionary Initiative: Materials-Positive Society — Evolving “Things,” empowering a positive society | Science Tokyo
sciencetokyo
PRO
0
130
モブ社員がモブエンジニアを名乗って得られたこと_20260413
masakiokuda
4
550
Lectura 1 (PIT : Python Basico)
robintux
0
380
生成AI時代のエンジニア育成について考えてみた
akasan
0
170
0415
cbtlibrary
0
230
[2026前期火5] 論理学(京都大学文学部 前期 第2回)「論理的な正しさはどこにあるのか」
yatabe
0
1k
BITCOIN : Les fondamentaux !
rlifchitz
0
200
LinkedIn
matleenalaakso
0
4.4k
Featured
See All Featured
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
260
Navigating Weather and Climate Data
rabernat
0
310
Faster Mobile Websites
deanohume
310
32k
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
56k
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.7k
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
3
920
The browser strikes back
jonoalderson
0
1.4k
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
460
Sam Torres - BigQuery for SEOs
techseoconnect
PRO
0
300
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
750
How GitHub (no longer) Works
holman
316
150k
How to Build an AI Search Optimization Roadmap - Criteria and Steps to Take #SEOIRL
aleyda
1
2.1k
Transcript
- 情報検索- 第7回 B3勉強会 2016年2月17日 自然言語処理研究室 学部3年 西山 浩気
情報検索の歴史 参考文献 黒橋 貞夫, 自然言語処理, 放送大学教 育振興会,(2015.3.20),pp.141-147 発表内容
1. 情報検索の歴史 2. 情報検索のしくみ 3. 語の重要度 4. TF-IDF法 5. ベクトル空間モデル
情報検索の歴史 初期 ◦ 論文・ビジネス書の内容にマッチするキー ワードを付与 現在 ◦ 文書から重要なキーワードを自動抽出
◦ 全文検索 語の重要度を考慮しつつ文書全体を検索する ◦ 1990年代から ウェブの全文検索(サーチエンジン)の開発が進展
情報検索の仕組み 転置インデックス ◦ あらゆる語がどの文書に出現するかを表 す索引 文書1 言語、コンピュータ、問題 文書2 コンピュータ、問題
文書3 言語、問題、情報 文書4 問題、情報 文書5 情報、コンピュータ 言語 文書1、文書3 コンピュータ 文書1、文書2、文書5 問題 文書1、文書2、文書3、文書4 情報 文書3、文書4、文書5
語の重要度 クエリ ◦ 検索したい内容を表現する語集合や自然文 ◦ 例: 「言語 コンピュータ」で検索
1千万件以上がマッチ → 関連度の高い文章でランキングすることが必要! TF(term frequency) ◦ 文書d における語 t の頻度 t f t,d 例: 文書1における語「自然」の頻度 tf 文書1, 自然
語の重要度 例: クエリが「言語 問題」であるとき ◦ 言語 : 検索の意図をより限定的に表現 ◦
問題:一般的な語 → クエリ中のどの語が検索においてより重要か を知る必要がある! IDF(逆文書頻度) idf t ◦ クエリ中のどの語がより重要かを表現する尺度
語の重要度 文書頻度 ◦ ある語t を含む文書数 df t (各文書に t
が何回出現したかは問わない) ◦ 限定的な語 (例「言語」) → 小さい値 ◦ 一般的な語(例「問題」) → 大きい値 IDF(idf t )の計算式 idf t = log ◦ N : 検索対象の文書の総数 N df t
TF-IDF法 TF-IDF法 ◦ ある語tの文書dにおける重要度をTFと IDFの積とする方法 TF(tf t,d ):文書dにおけるある語tの頻度
IDF(idf t ):クエリ中のどの語がより重要かを表 現する尺度 文書頻度DF(df t ) :ある語tを含む文書数
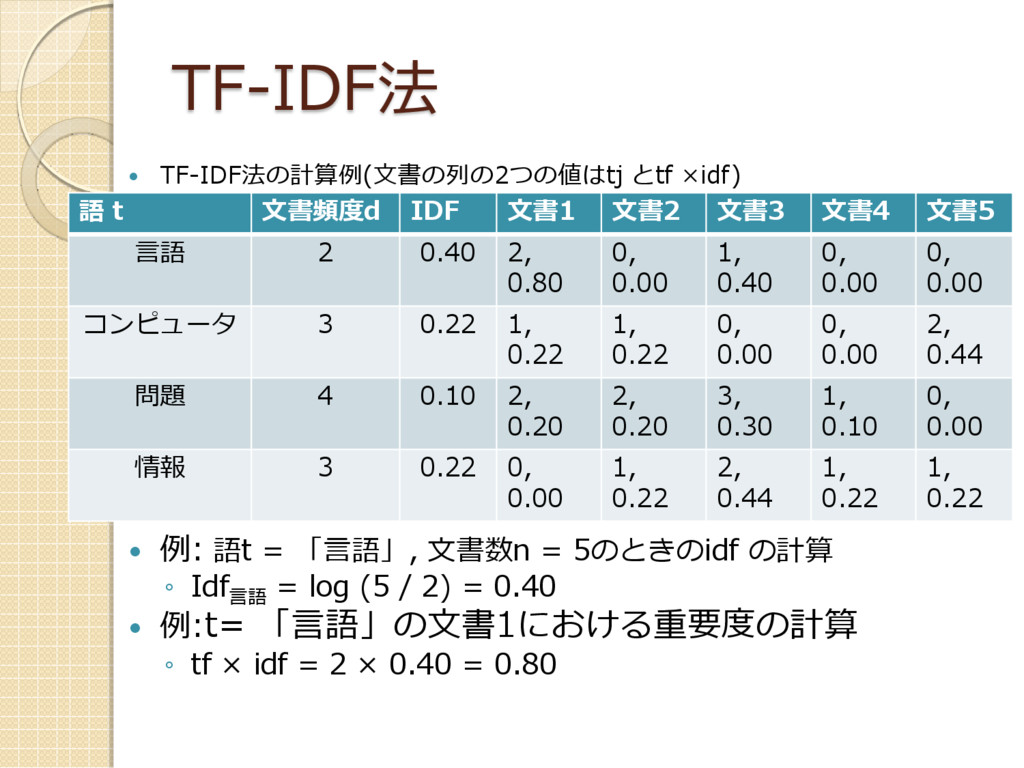
TF-IDF法 TF-IDF法の計算例(文書の列の2つの値はtj とtf ×idf) 例: 語t = 「言語」,
文書数n = 5のときのidf の計算 ◦ Idf 言語 = log (5 / 2) = 0.40 例:t= 「言語」の文書1における重要度の計算 ◦ tf × idf = 2 × 0.40 = 0.80 語 t 文書頻度d IDF 文書1 文書2 文書3 文書4 文書5 言語 2 0.40 2, 0.80 0, 0.00 1, 0.40 0, 0.00 0, 0.00 コンピュータ 3 0.22 1, 0.22 1, 0.22 0, 0.00 0, 0.00 2, 0.44 問題 4 0.10 2, 0.20 2, 0.20 3, 0.30 1, 0.10 0, 0.00 情報 3 0.22 0, 0.00 1, 0.22 2, 0.44 1, 0.22 1, 0.22
ベクトル空間モデル ベクトル検索モデル ◦ ベクトル間の類似度を使ってクエリに対するランキングを行う検 索モデル 例: 「言語 問題」のランキング計算
◦ 各文書のベクトル ◦ 類似度を求めるためにベクトル間の余弦を用いる cos (d 文書1 , q) = 0.83 cos (d 文書2 , q) = 0.38 cos (d 文書3 , q) = 0.74 cos (d 文書4 , q) = 0.30 cos (d 文書5 , q) = 0.00 ◦ 類似度の高い順番に並べ替える → ウェブ検索の結果も関連度の高い順番でランキングできる d 文書1 = 0.80 0.22 0.20 0.00 ,d 文書2 = 0.00 0.22 0.20 0.22 ,d 文書3 = 0.40 0.00 0.30 0.44 , ... ,q= 1 0 1 0
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}