Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
0309-nlpaperchallenge-nlp5
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
nizhny
March 09, 2019
Technology
720
1
Share
0309-nlpaperchallenge-nlp5
nizhny
March 09, 2019
More Decks by nizhny
See All by nizhny
Disentangled Representation Learning for Non-Parallel Text Style Transfer
nizhny
0
1.1k
Other Decks in Technology
See All in Technology
海外カンファレンス「JavaOne」参加レポート ユーザー系IT企業における目的・成果/JavaOne Report Purpose and Results in the User IT Company
muit
0
110
組織の中で自分を経営する技術
shoota
0
230
最低限これだけ押さえれ大丈夫_Claude Enterprise/Team企業展開ガバナンス入門
tkikuchi
1
550
AI時代から振り返るTerraform drift運用の歴史 / AI Age Reflections on the History of Terraform Drift Operations
aeonpeople
0
600
脅威をエンジニアリングの糧にして:恐怖を乗り越えた先にあったもの / Turn threats into fuel for engineering: what lay beyond overcoming fear
nrslib
1
350
AI フレンドリーなエラー監視を TypeScript で実現する
shinyaigeek
2
190
Generative UI × A2UI で AI エージェントを作った話 AI-DLC も使ってみた!
kmiya84377
1
280
Kiro CLI v2.0.0がやってきた!
kentapapa
0
220
イベントストーミングとKiroの仕様駆動開発で実現する要件の認識合わせプロセス
syobochim
7
970
Claude Codeですべての日常業務を爆速化しよう!
minorun365
PRO
16
16k
Oracle AI Database@Google Cloud:サービス概要のご紹介
oracle4engineer
PRO
6
1.5k
OpenID Connectによるサービス間連携
takesection
0
140
Featured
See All Featured
Product Roadmaps are Hard
iamctodd
PRO
55
12k
Chasing Engaging Ingredients in Design
codingconduct
0
200
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.8k
Sharpening the Axe: The Primacy of Toolmaking
bcantrill
46
2.8k
jQuery: Nuts, Bolts and Bling
dougneiner
66
8.5k
Distributed Sagas: A Protocol for Coordinating Microservices
caitiem20
333
22k
Docker and Python
trallard
47
3.9k
Winning Ecommerce Organic Search in an AI Era - #searchnstuff2025
aleyda
1
2k
Why Mistakes Are the Best Teachers: Turning Failure into a Pathway for Growth
auna
0
150
SERP Conf. Vienna - Web Accessibility: Optimizing for Inclusivity and SEO
sarafernandez
2
1.5k
The Language of Interfaces
destraynor
162
26k
Transcript
深層学習による自然言語処理 第5章 応用 筑波大学 情報学群 B3 石原慧人
自己紹介 • 群馬高専→筑波大情報科学類 • 自然言語処理グループ (http://www.nlp.mibel.cs.tsukuba.ac.jp) • twitter: @nizhny_
概要 本章では、これまで取り上げられてきた深層学習モデルの自然言 語処理における応用、特に「機械翻訳」「文書要約」「対話」「質問 応答」の4つの分野について解説していく
目次 • 機械翻訳 • 文書要約 • 対話 • 質問応答
機械翻訳とは コンピューターを用いて人手を介さず自動的にある言語 の文章を別の言語の文章に翻訳する方法を総称して、機 械翻訳という → とくにニューラルネットによる機械翻訳をニューラル翻 訳(Neural Machine Translation;NMT)という
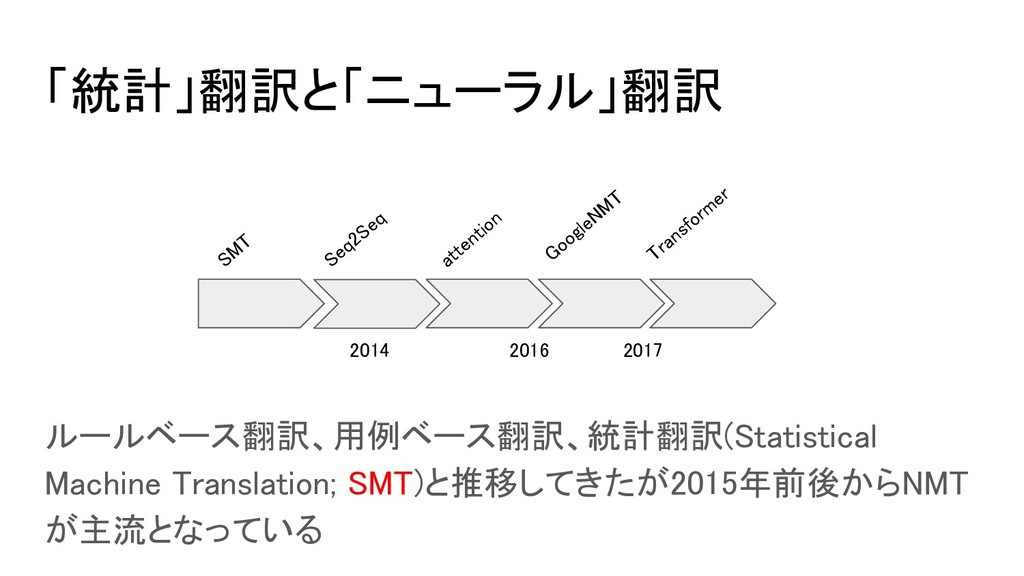
「統計」翻訳と「ニューラル」翻訳 ルールベース翻訳、用例ベース翻訳、統計翻訳(Statistical Machine Translation; SMT)と推移してきたが2015年前後からNMT が主流となっている SMT Seq2Seq attention Transformer
2017 2014 GoogleNMT 2016
WMT16 独英ニュース翻訳ランキング http://www.statmt.org/wmt16/pdf/W16-2301.pdf https://ec.europa.eu/info/sites/info/files/tef2016_haddow_en.pdf
典型的なモデル構成 (2017年1月時点での)論文中のベースラインとしてよく使わ れているツール • GroundHog(RNNSearch)→モントリオール大学からリ リース、メンテナンス終了済み • OpenNMT→ハーバード大学からリリース、本書ではこ ちらについて取り上げている
OpenNMT http://opennmt.net • 学習データを用意するだけでニューラルネットのモデリングが 可能なツール • 最近では類似ツールとしてGoogleが tensor2tensor(https://github.com/tensorflow/tensor2tensor) を公開している
NMTのタスク構成 翻訳前の文書を入力として、翻訳後の文書を解答としてモデ ルの学習を行うだけ 二層の双方向LSTMでの事例が紹介されているが、3,4章の 内容とあまり変わらないので割愛
入出力の処理単位に対する改良 • 扱える語彙数と計算量はトレードオフ • 選択肢が増えるため必ずしも語彙数と性能は比例し ない • そもそも未知語を完全になくすことは不可能 →未知語と判定したものを後処理で「UnkRep」などのトー クンに置き換えることが一般的
未知語に対する改良 そもそも文章の区切り方を単語単位から変えることによる解決も 試みられている • 文字単位→ほぼ未知語をなくすことが可能 • バイト対符号化(Byte Pair Encoding; BPE)→出現頻度の大き
い文字をペアにしていく、単語と文字の中間
文字単位 メリット • (特に英語は)文字種が限定されるため未知語が発生しにくい • 分かち書きに特殊な処理が必要ない • 誤字脱字に頑健 デメリット •
粒度が小さいので学習に時間がかかる https://www.slideshare.net/tdualdir/devsumi-107931922
BPE 出現頻度に応じてペアを作っていくことで、高頻度語は単 語単位で利用し、低頻度語は文字単位で利用する手法 文字単位と単語単位の中間的手法、ライブラリとしては Sentencepieceが登場している →これら三種類のうち実際どれが優れているかはまだ決 着がついていない
被覆に対する改良 • 同じ単語を繰り返し生成してしまう過剰生成問題 • 元の分の必要な語を無視してしまう不足生成問題 多个机场都被迫关闭了 → many airports were
close to close これらを解決するため「被覆(coverage)」という概念を導入 http://www.aclweb.org/anthology/P16-1008
被覆とは これらの問題はモデルが翻訳済みの情報を持たないために引き 起こされる →入力単語長と同じサイズのゼロベクトルを用意する。そして最 終的に全て1になるまで翻訳済みの単語に対応する要素を1にし ていくことで原文全体を過不足なく翻訳できる
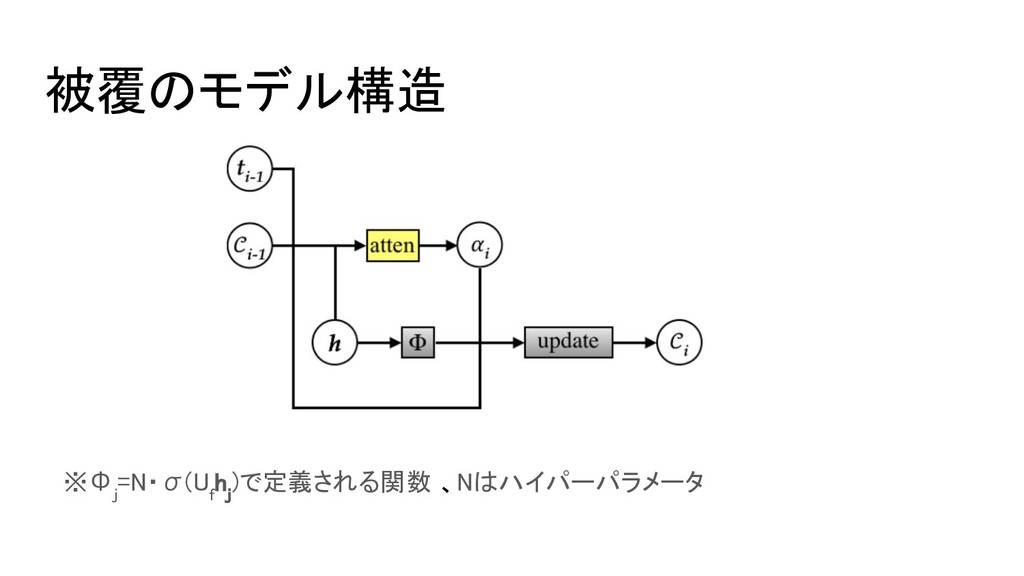
ニューラルネットにおける被覆 NMTにおいて被覆を直接モデリングするのは困難であるため、 被覆ベクトルを注意機構に組み込むパラメータとして定義する 被覆導入前: e i,j =v a Ttanh(W a
t i-1 +U a h j ) 被覆導入後: e i,j =v a Ttanh(W a t i-1 +U a h j +V a C i-1,j ) ※V a は重み、C i-1,j が被覆ベクトル,
被覆のモデル構造 ※Φ j =N・σ(U f h j )で定義される関数 、Nはハイパーパラメータ
現在のSOTA(WMT16独英翻訳) https://paperswithcode.com/task/machine-translation
目次 • 機械翻訳 • 文書要約 • 対話 • 質問応答
文章要約とは 与えられた文章から、要点を抽出したより短い文書を生成する 方法を文書要約という 同一言語内で完結するため機械翻訳より難易度が低そうに感 じるかもしれないが、NMTはモデルが言語依存の要因をほぼ 吸収してしまう為必ずしもそうではない
訓練データ獲得に対する課題 機械翻訳では基本的に入出力はどちらも一文だが、要約の場合 はほとんどの場合複数文である。 そのため文書要約においては機械翻訳よりもかなり多くのデータ 量が必要となる。
タスク定義の曖昧さの課題 (例) • 見出しの生成→1文程度の短い文書 • 概要の生成→複数文である程度の長さの文書 このように用途に応じて同じ文書要約でも正解が変化して しまう
短文生成タスク/見出し生成タスク ニュース記事の一文目を与えて見出しを生成するタスクは「見 出し生成タスク」と呼ばれ、文書要約の中でも以下のような理由 から比較的簡単でありよく取り組まれている • 新聞記事から容易に大規模なデータが得られる • 一文から一文を生成するタスクであるため機械翻訳と構造 があまり変わらない
典型的なモデル構成 順伝搬型ニューラル言語モデルと注意機構を組み合わせたモデルがベンチマークと してよく利用されている 論文中ではAttention Based Summarization(ABS)と名付けられ、入力文をX,出力文を Yとして以下の式に従ってモデル化している P abs (Y|X)=∏j+1P
abs (y j |X,Y [j-C, j-1] )…(5.1) P abs (y j |X,Y [j-C, j-1] )=softmax(o j )・y j …(5.2) o j =nnlm(Y [j-C, j-1] )+enc(X,Y [j-C, j-1] )…(5.3) https://aclweb.org/anthology/D/D15/D15-1044.pdf
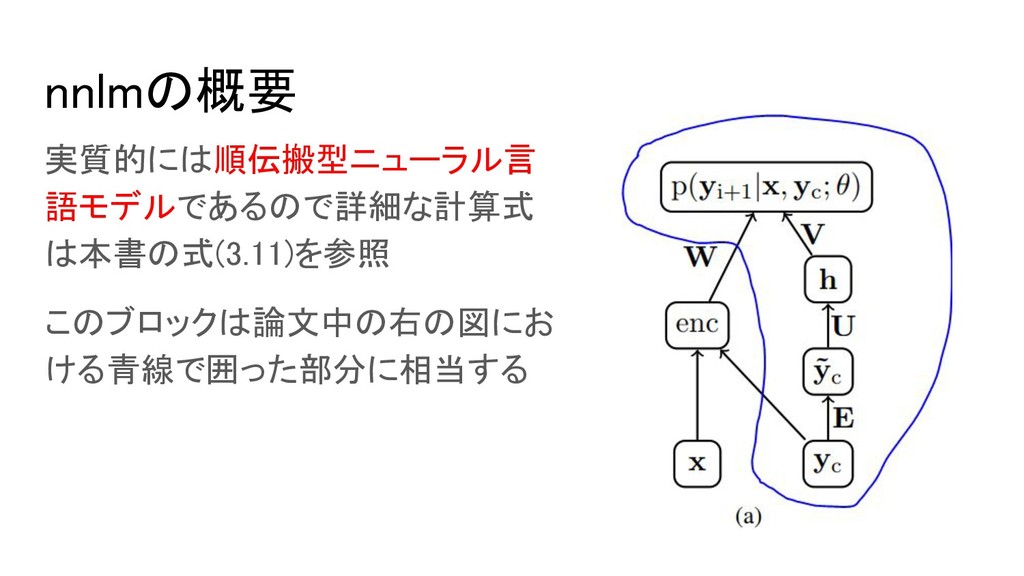
nnlmの概要 実質的には順伝搬型ニューラル言 語モデルであるので詳細な計算式 は本書の式(3.11)を参照 このブロックは論文中の右の図にお ける青線で囲った部分に相当する
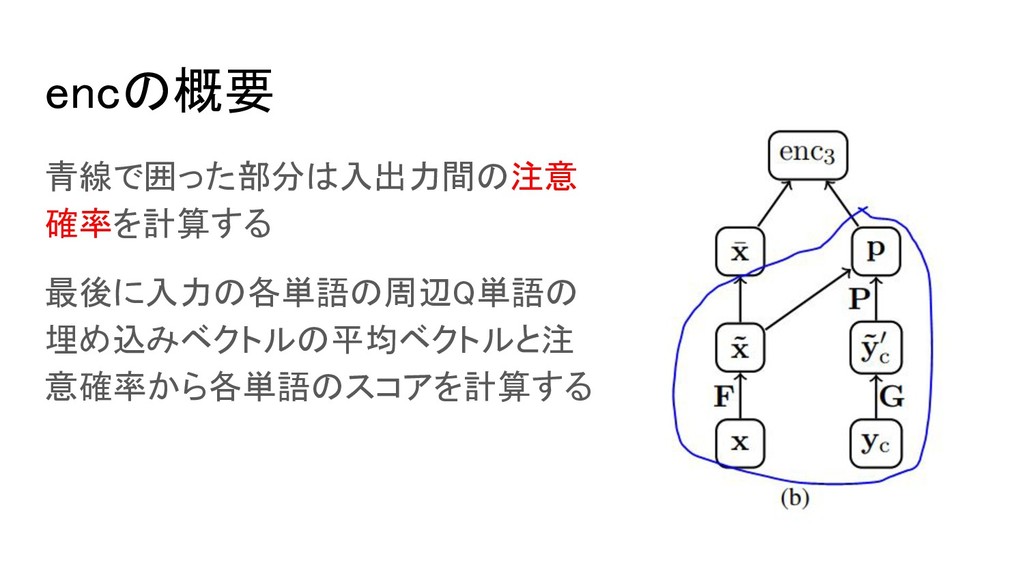
encの概要 青線で囲った部分は入出力間の注意 確率を計算する 最後に入力の各単語の周辺Q単語の 埋め込みベクトルの平均ベクトルと注 意確率から各単語のスコアを計算する
拡張 ABSではRNNが採用されていないがこれはABS登場時(2015年)に はまだRNNの効力がはっきりわかっていなかったことが原因 ABSの半年後にはRNNを用いた拡張が提案され効果が出ている
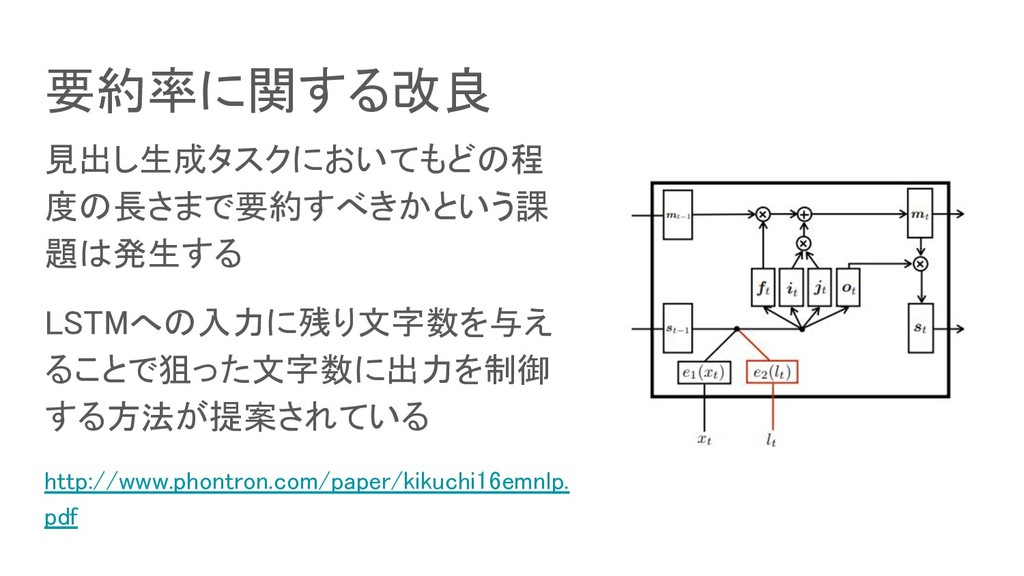
要約率に関する改良 見出し生成タスクにおいてもどの程 度の長さまで要約すべきかという課 題は発生する LSTMへの入力に残り文字数を与え ることで狙った文字数に出力を制御 する方法が提案されている http://www.phontron.com/paper/kikuchi16emnlp. pdf
意味表現の利用による改良 式(5.3)を以下のように拡張することで文書の主語や目的語といった意味情報を利用す ることで性能の向上が確認されている o j =nnlm(Y [j-C, j-1] )+enc(X,Y [j-C,
j-1] )+encAMR(A,Y [j-C, j-1] )…(5.5) encAMR(A,Y [j-C, j-1] )=O”As j …(5.6) s j =softmax(ATSy’ c )…(5.7) Aは論文中で提案されている意味表現に対する符号化器から得られる
コピー機構による改良 文書要約以外にも応用可能な技術として、入力側の単語をその まま出力に利用するコピー機構がある 入力文の単語をそのまま利用することで未知語についても性能 の向上が期待できる https://arxiv.org/pdf/1603.06393.pdf
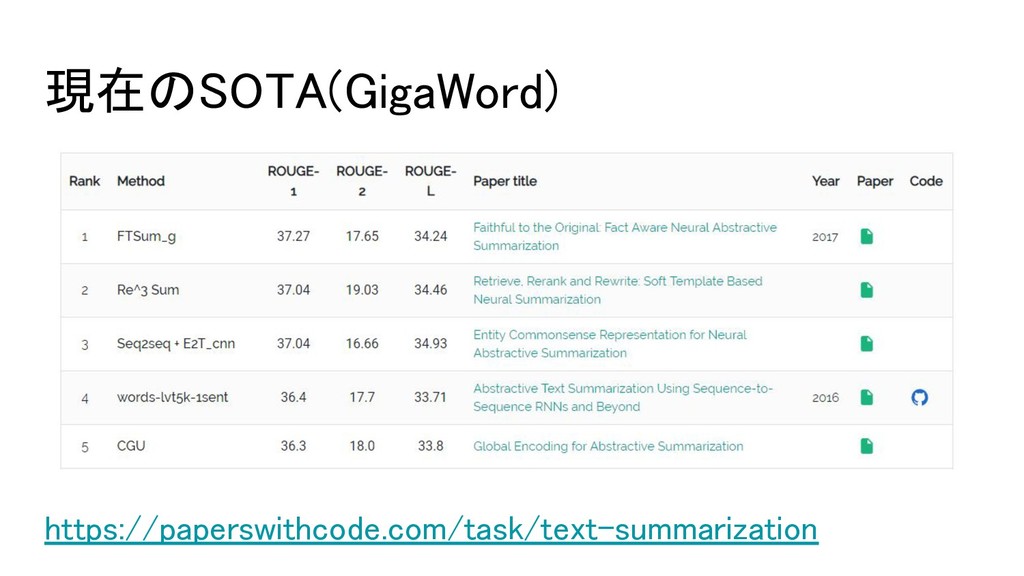
現在のSOTA(GigaWord) https://paperswithcode.com/task/text-summarization
目次 • 機械翻訳 • 文書要約 • 対話 • 質問応答
対話システムとは 人とコンピュータが会話することを目的としたシステムを対話 システムという ニューラルネットの登場で「言語の認識」「対話の状態管理」な どのサブシステムを介さずシステム全体を直接学習可能に
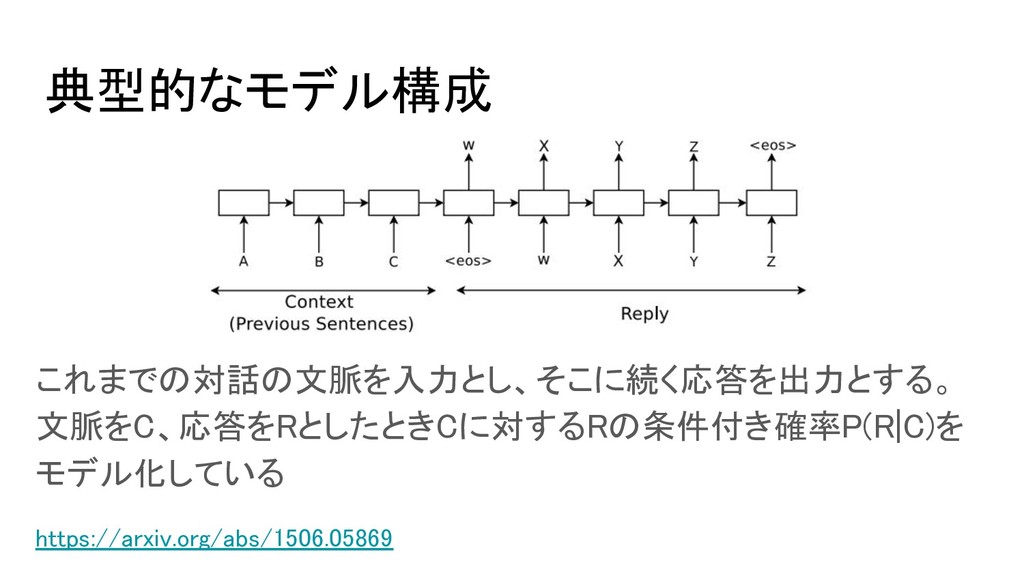
典型的なモデル構成 これまでの対話の文脈を入力とし、そこに続く応答を出力とする。 文脈をC、応答をRとしたときCに対するRの条件付き確率P(R|C)を モデル化している https://arxiv.org/abs/1506.05869
改良 以下のような要素をモデルに組み込むことで性能の向上が確認さ れている • 話者交代 • 話者ID • 話者別状態ベクトル
応答の長さに関する課題 「はい」「ありがとう」などの短い応答は多くの文脈で許容される短 い応答ばかりが出力されるのはあまり望ましくない →単純にスコアだけで単語を選択するのではなく、サンプリングや 相互情報量などを用いたほうが多様性のある応答が期待できる
実際の運用における課題 • 一度見当違いの応答を生成してしまうと、その後の応答でそ れを文脈として読み取ってしまう • 複数人会話では話相手の明示が必要で難易度が上がる
自動評価に関する課題 (例)「旅行に行きませんか?」 • 「はい、行きたい場所があります」 • 「いいえ、天気が悪いので映画を見に行きましょう」 →意味は真逆だがどちらも解答としては適切 このように対話システムは機械翻訳のような自動評価が困難であ り、評価方法そのものも研究対象としうる
応答選択タスク 応答生成を直接行わず、与えられた応答候補から正しい応答を 選択する「応答選択タスク」による評価も提案されている 与えられた文脈に対する応答候補それぞれをモデルによりスコ ア付けすることで、再現率などにより自動評価が容易に可能で ある https://arxiv.org/abs/1506.08909
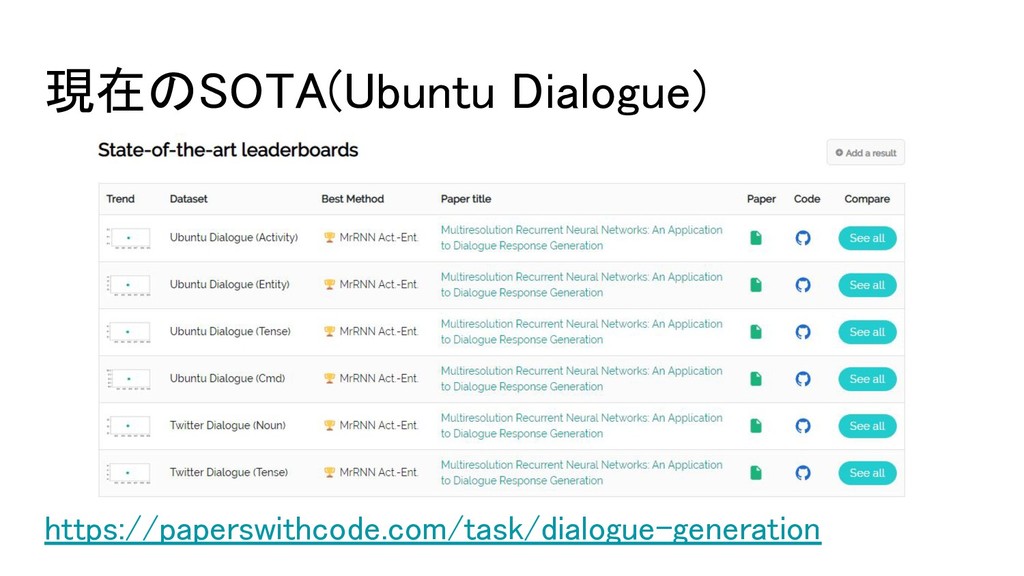
現在のSOTA(Ubuntu Dialogue) https://paperswithcode.com/task/dialogue-generation
目次 • 機械翻訳 • 文書要約 • 対話 • 質問応答
質問応答とは 自然言語で与えられた質問に対して、自然言語で回答を行うタス クを質問応答(Question Answering; QA)という 質問の種類に応じて「事実型質問応答」「非事実型質問応答」「ク ローズドメイン質問応答」「オープンドメイン質問応答」「画像質問 応答」と様々に分類される
質問応答の流れ 質問解析→文書検索→回答抽出→回答選択の順に処理を分解 して実行される 検索部分は情報検索技術を応用することが多く、深層学習が利 用されるのは主に回答選択部分である
回答選択タスク 質問文qが与えられ、N個の回答候補{a1,...,aN}それぞれについて 回答としてのスコアを算出するタスクを回答選択タスクという、対 話システムにおける応答選択タスクとほぼ等価である 質問文と回答候補それぞれについてCNNなどでベクトル化し、そ れらの類似度関数を最適化することでモデルを作成する
損失関数 質問文ベクトルをv(q)、正例回答文ベクトルをv(a+)、負例をv(a-)、 マージンをmとする f(v(q), v(a+))<m+f(v(q), v(a-))を満たす負例を用いてモデルの学習にお ける損失関数を max(0, m-f(v(q), v(a+))+f(v(q),
v(a-)))・・・(5.10) と定義する
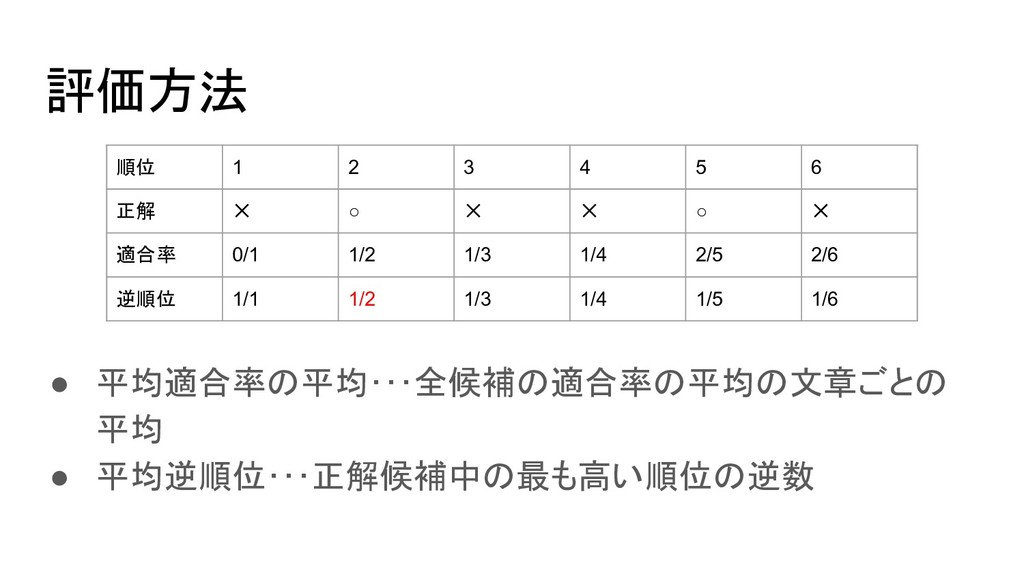
評価方法 • 平均適合率の平均・・・全候補の適合率の平均の文章ごとの 平均 • 平均逆順位・・・正解候補中の最も高い順位の逆数 順位 1 2 3
4 5 6 正解 ✕ ◦ ✕ ✕ ◦ ✕ 適合率 0/1 1/2 1/3 1/4 2/5 2/6 逆順位 1/1 1/2 1/3 1/4 1/5 1/6
end-to-end 他の分野と同じように部分問題のみならずend-to-endで質問応 答全体を単一のモデルで解決しようとする研究もある。 この場合質問に応答するために必要な知識源の獲得もニューラ ルネットが行うため記憶ネットワークなどが利用される bAbIタスクなどではend-to-endの質問応答のためにテキスト、質 問文、応答がデータセットとして提供される
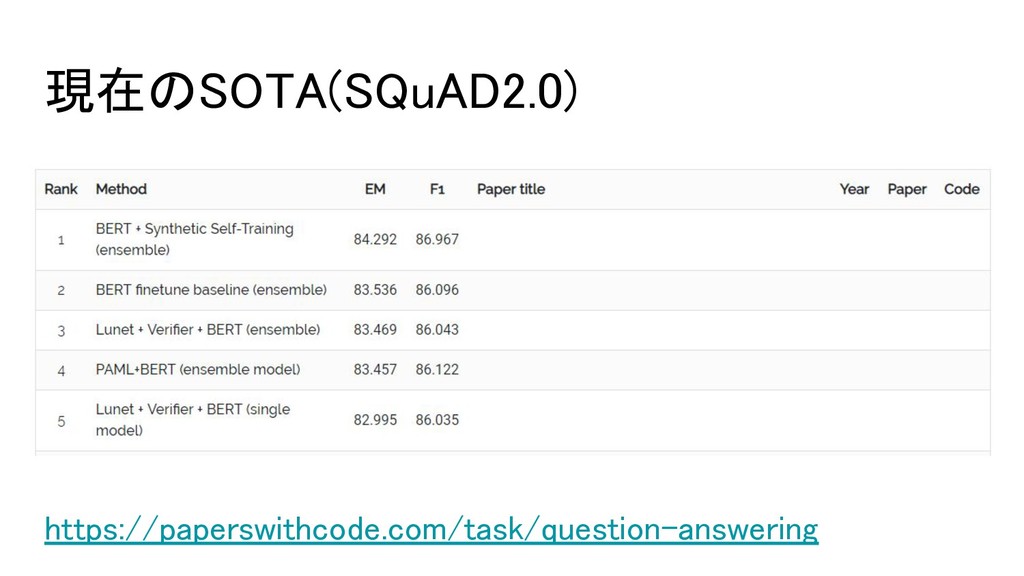
現在のSOTA(SQuAD2.0) https://paperswithcode.com/task/question-answering
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![意味表現の利用による改良 式(5.3)を以下のように拡張することで文書の主語や目的語といった意味情報を利用す ることで性能の向上が確認されている o j =nnlm(Y [j-C, j-1] )+enc(X,Y [j-C,](https://files.speakerdeck.com/presentations/4008a1445c764741ab7ab208fb3e143a/slide_29.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}