Teams building data-oriented applications against sensitive or large-scale information often face the problem of how to conduct discovery and work iteratively during development. Often, developers are cut-off from production data sets for security and operational reasons. But this doesn't have to be the case. You can build your system in such a way that analysts can work securely with production data, separate from customers, sharing their work, and performing quality control with real, live, production data. Save on operational overhead and complexity while maintaining security by moving your development environment to production instead of your production environment to your laptop.
This version includes speaker's notes.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
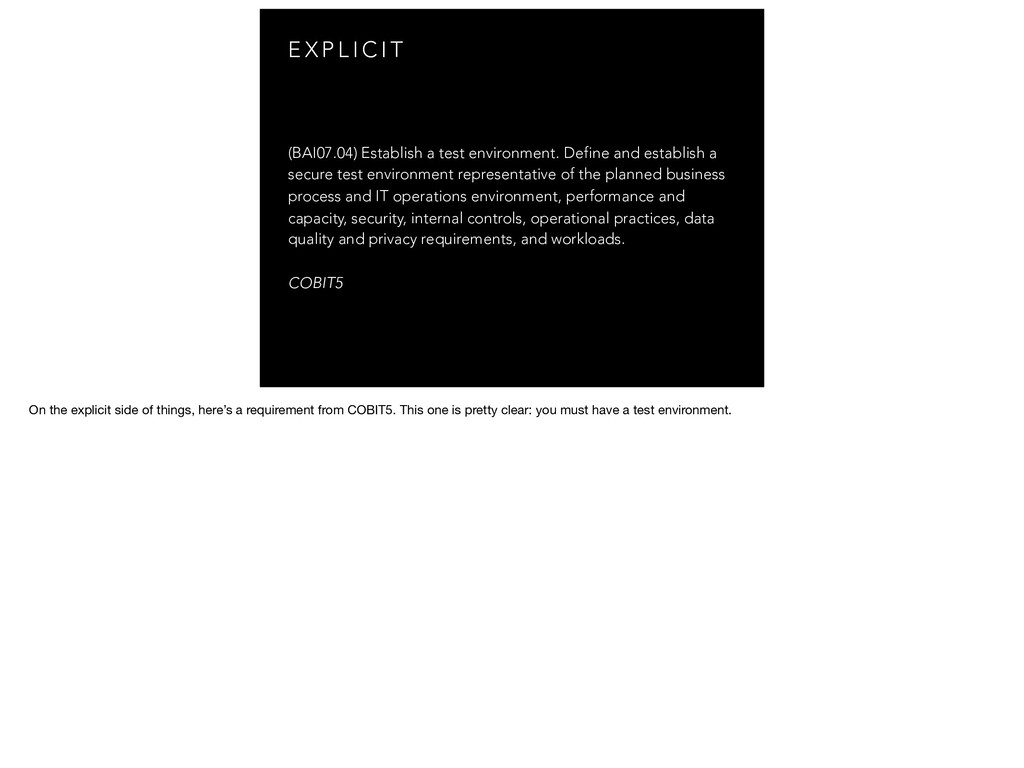{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
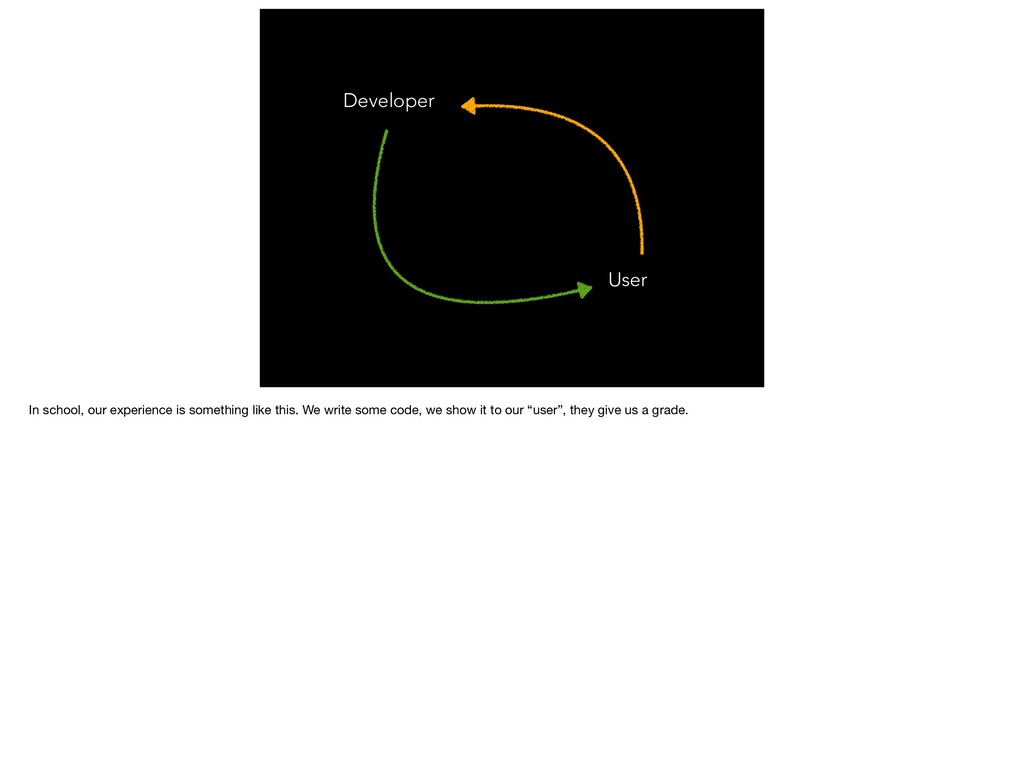{kind=link}
{kind=link}
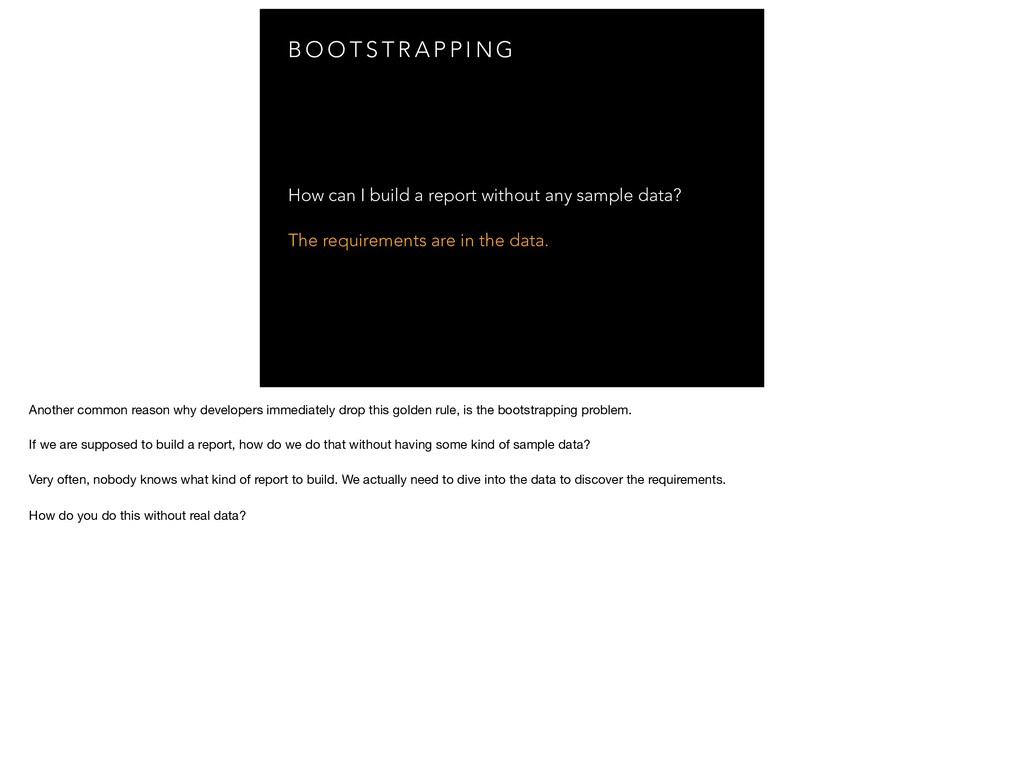{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
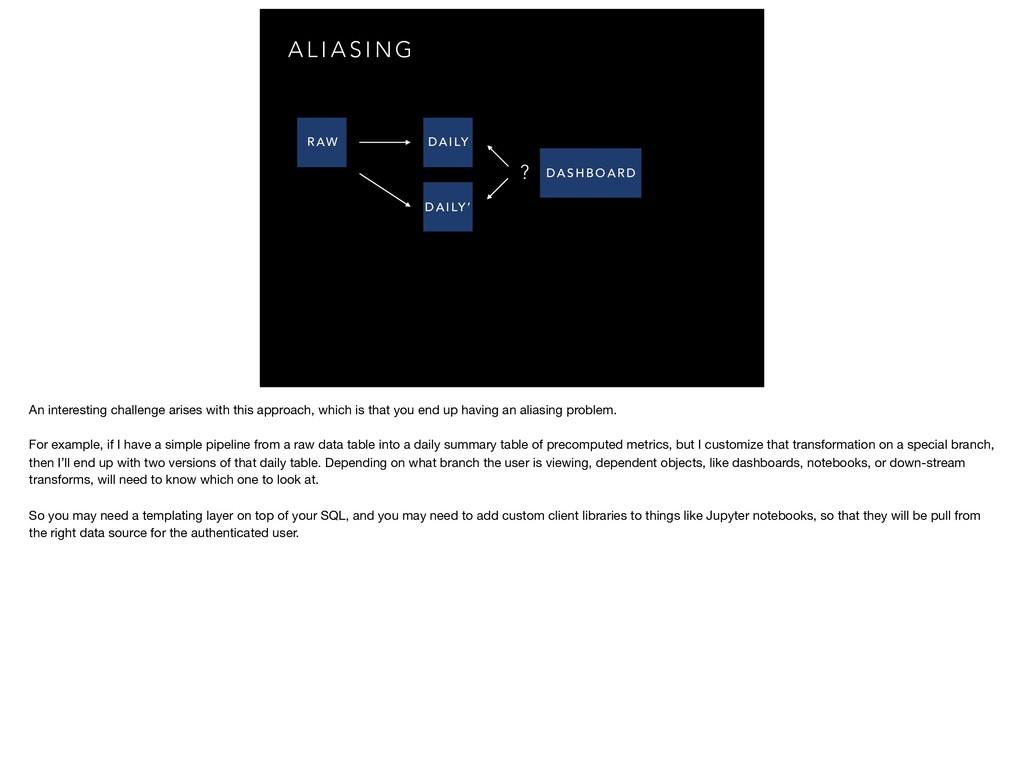{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}