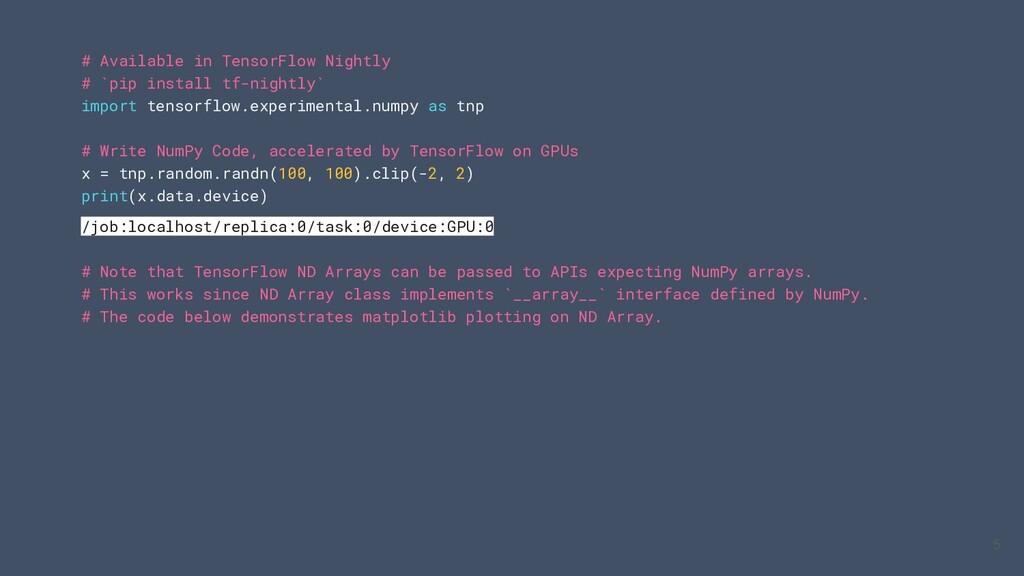
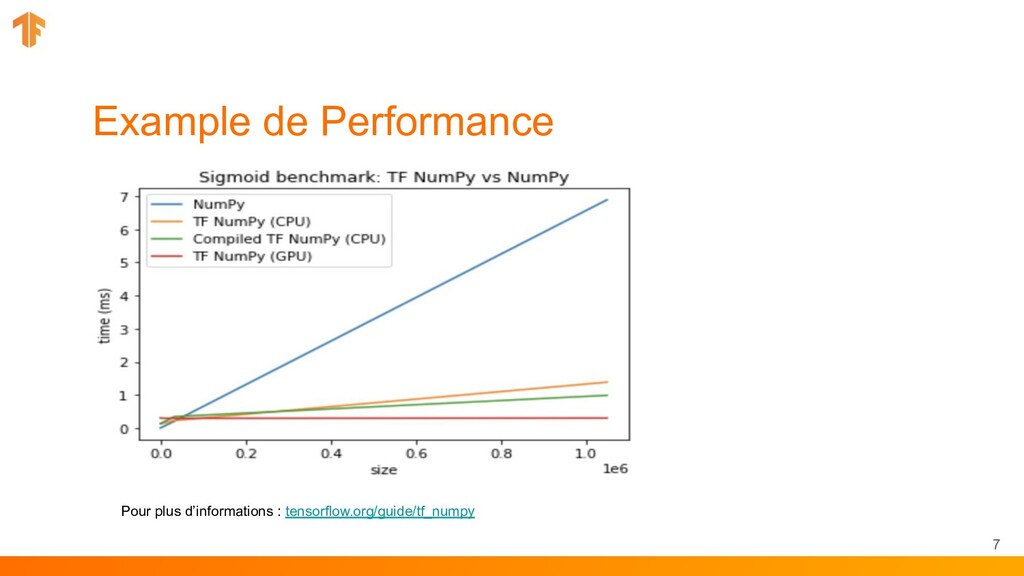
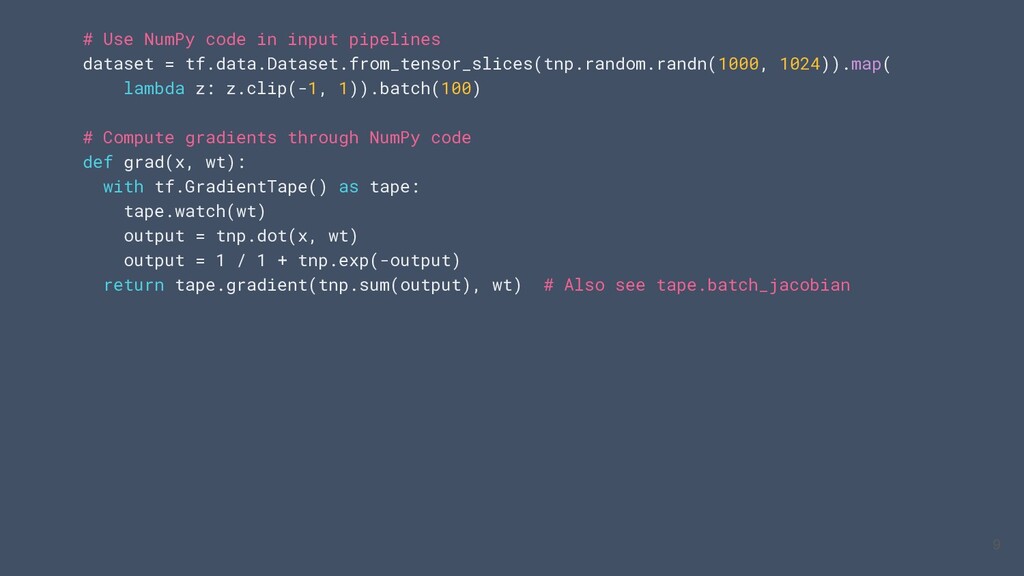
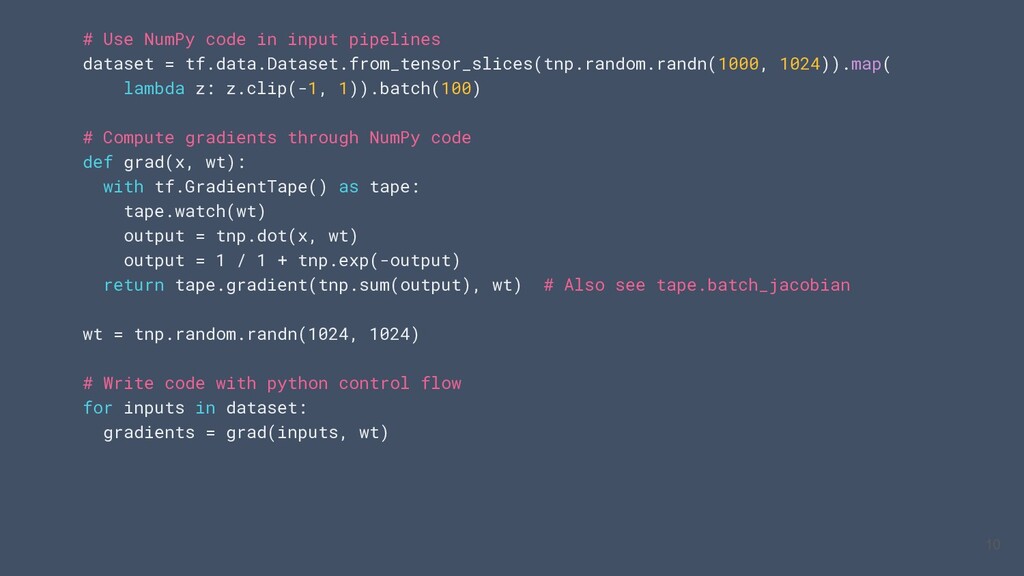
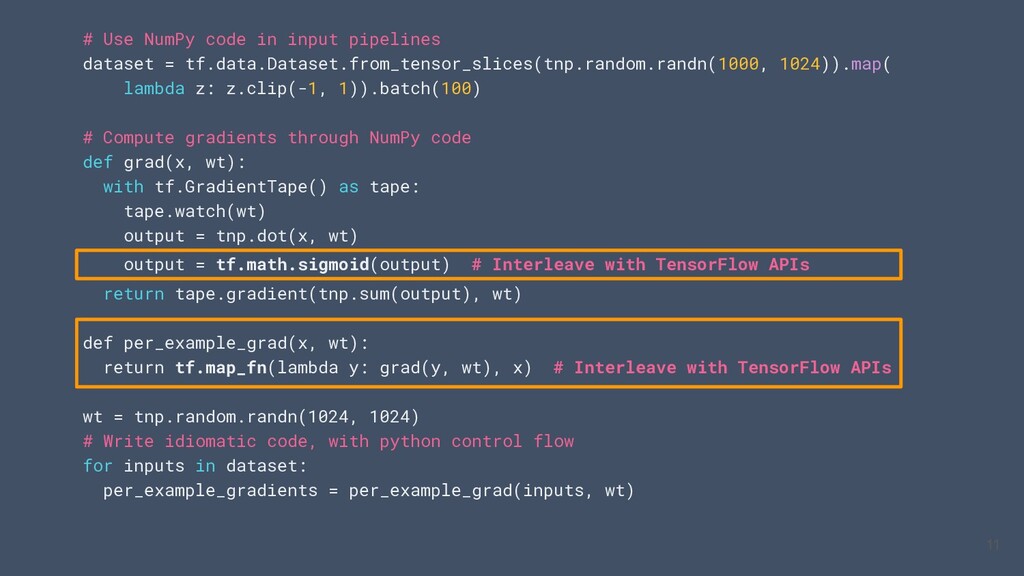
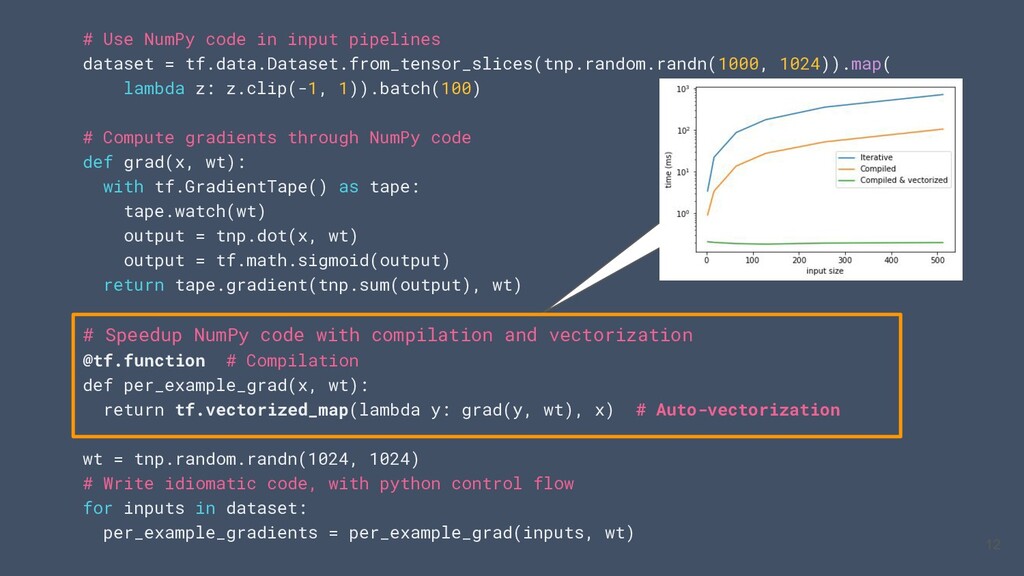
un sous ensemble Nump sur CPU / GPU / TPU • Utiliser le code numpy avec les APIs TensorFlow (tf.linalg, tf.signal, tf.data, tf.keras, tf.distribute) • Compiler le code NumPy à l’aide de `tf.function` et le vectoriser grace à `tf.vectorized_map` Visitez tensorflow.org/guide/tf_numpy pour plus informations 4
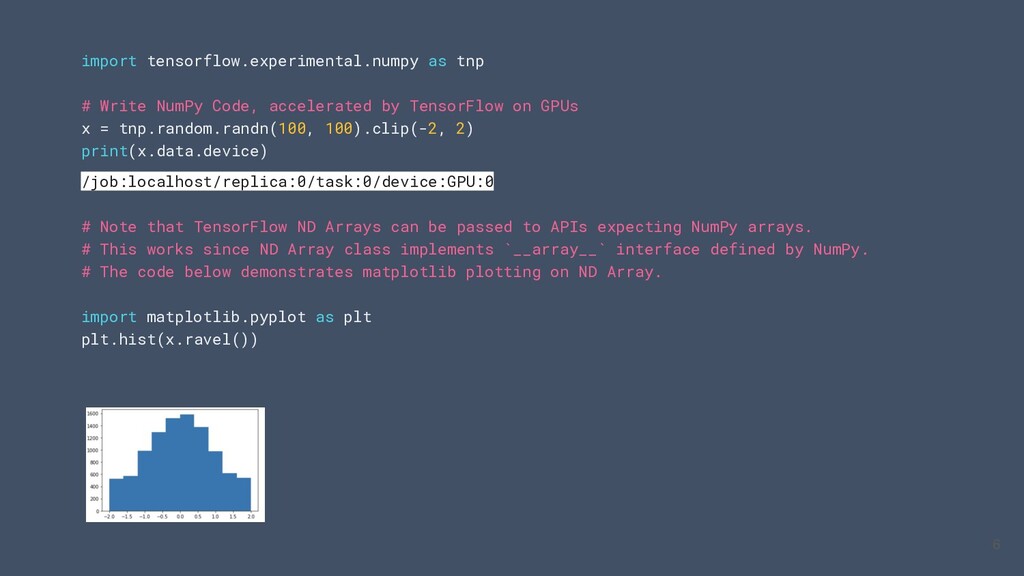
tensorflow.experimental.numpy as tnp # Write NumPy Code, accelerated by TensorFlow on GPUs x = tnp.random.randn(100, 100).clip(-2, 2) print(x.data.device) /job:localhost/replica:0/task:0/device:GPU:0 # Note that TensorFlow ND Arrays can be passed to APIs expecting NumPy arrays. # This works since ND Array class implements `__array__` interface defined by NumPy. # The code below demonstrates matplotlib plotting on ND Array. 5
TensorFlow on GPUs x = tnp.random.randn(100, 100).clip(-2, 2) print(x.data.device) /job:localhost/replica:0/task:0/device:GPU:0 # Note that TensorFlow ND Arrays can be passed to APIs expecting NumPy arrays. # This works since ND Array class implements `__array__` interface defined by NumPy. # The code below demonstrates matplotlib plotting on ND Array. import matplotlib.pyplot as plt plt.hist(x.ravel()) 6
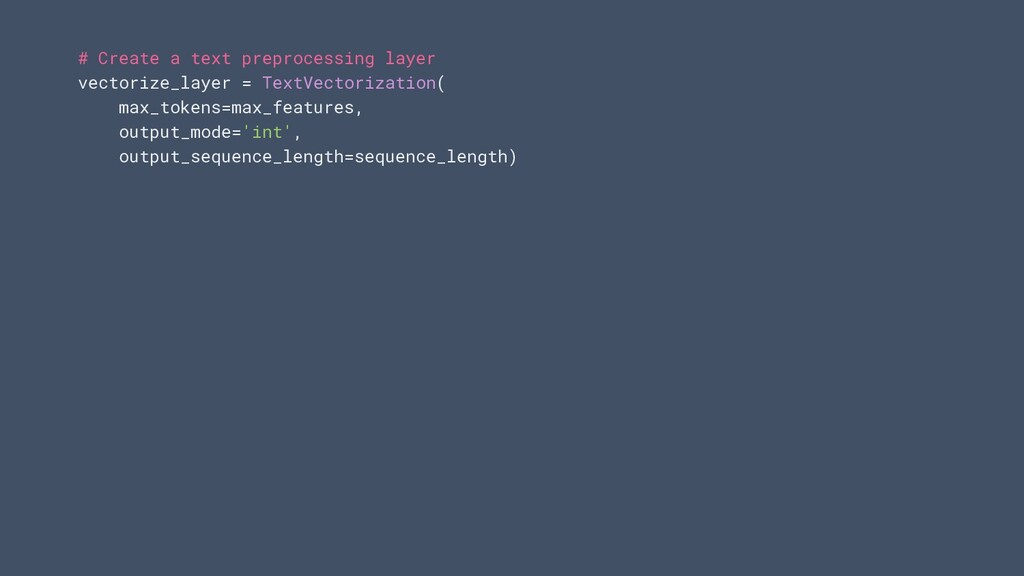
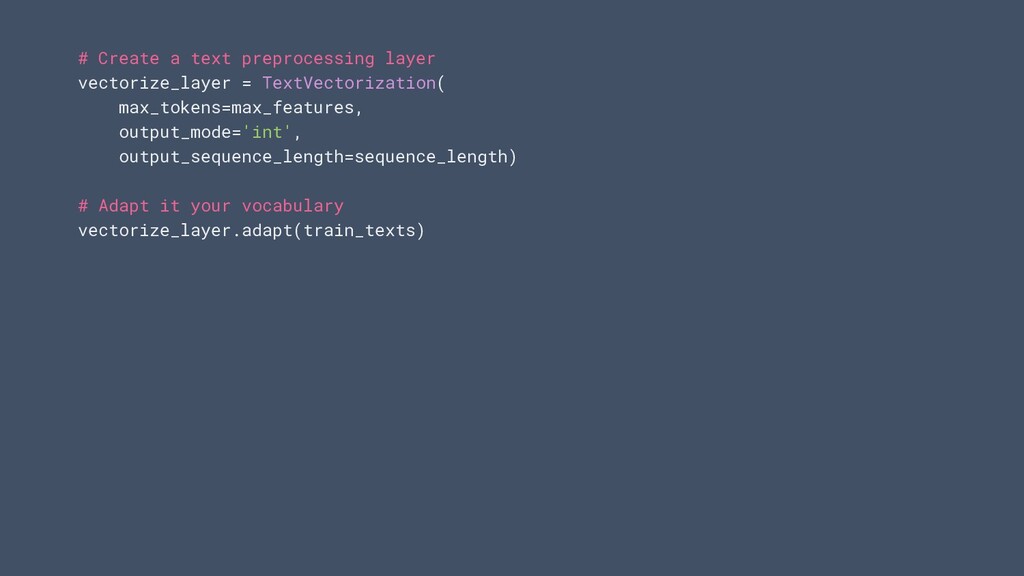
texte, vous devez écrire une logique de prétraitement pour la standardisation, la tokenisation et la vectorisation. • Pour déployer ce modèle, vous devez vous assurer que le texte est prétraité exactement de la même manière. • Cela peut entraîner une duplication de code pour une logique complexe, qui est difficile à maintenir. Background La logique de prétraitement prend du temps
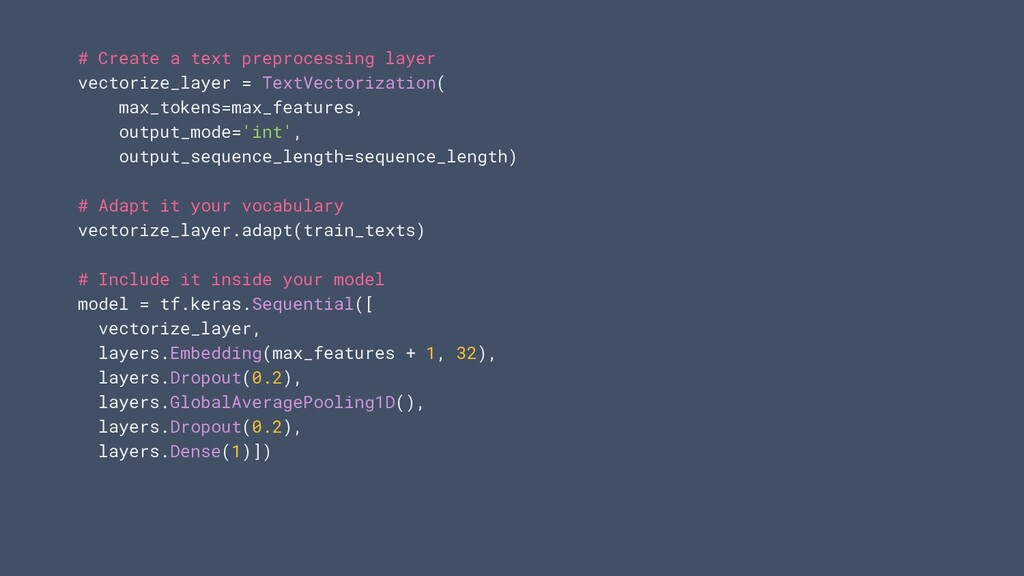
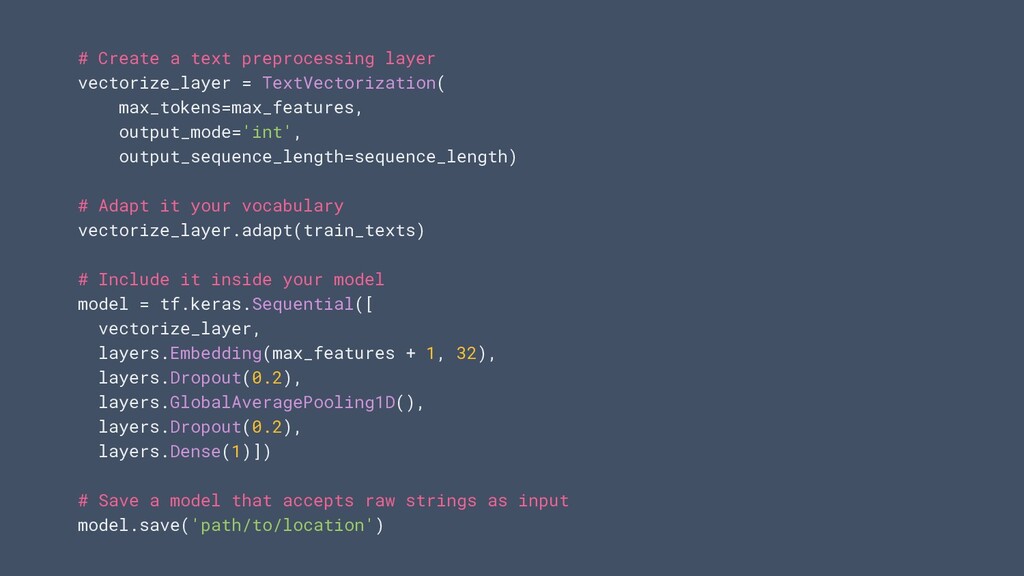
tant que couches dans votre modèle. Vous permet de: • Enregistrez des modèles qui prennent des images brutes, du texte ou des données structurées en entrée • Déployez des modèles sans avoir à réimplémenter la logique de prétraitement côté serveur • Exécutez facilement l'augmentation des données sur le GPU
output_mode='int', output_sequence_length=sequence_length) # Adapt it your vocabulary vectorize_layer.adapt(train_texts) # Include it inside your model model = tf.keras.Sequential([ vectorize_layer, layers.Embedding(max_features + 1, 32), layers.Dropout(0.2), layers.GlobalAveragePooling1D(), layers.Dropout(0.2), layers.Dense(1)])
output_mode='int', output_sequence_length=sequence_length) # Adapt it your vocabulary vectorize_layer.adapt(train_texts) # Include it inside your model model = tf.keras.Sequential([ vectorize_layer, layers.Embedding(max_features + 1, 32), layers.Dropout(0.2), layers.GlobalAveragePooling1D(), layers.Dropout(0.2), layers.Dense(1)]) # Save a model that accepts raw strings as input model.save('path/to/location')
normaliser et exécuter l'augmentation des données sur GPU Structured data • Prise en charge des variables numériques et catégoriels. One hot encoding, hachage..;. Prise en charge immédiate des types de données courants API doc: tensorflow.org/api_docs/python/tf/keras/layers/experimental/preprocessing
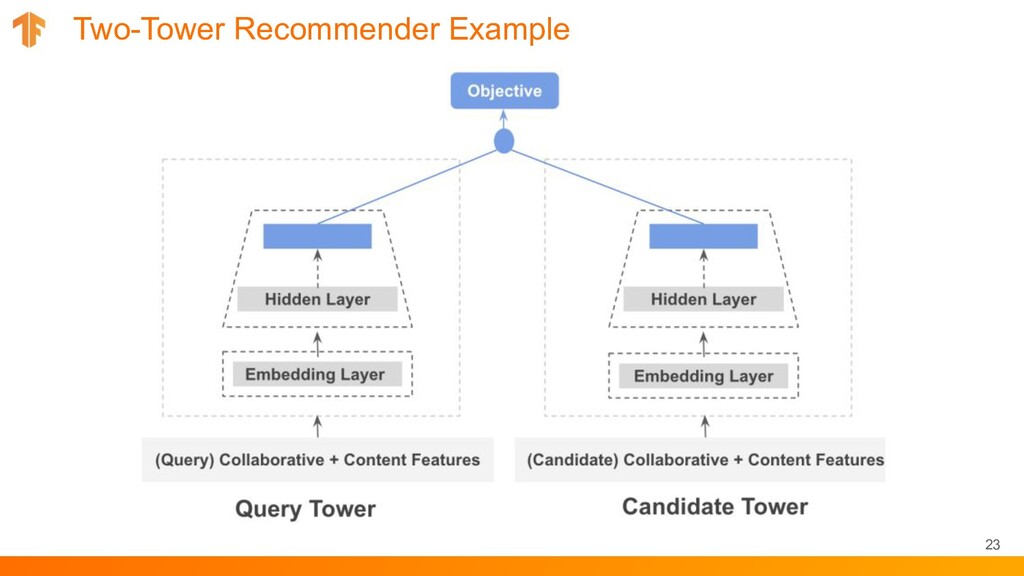
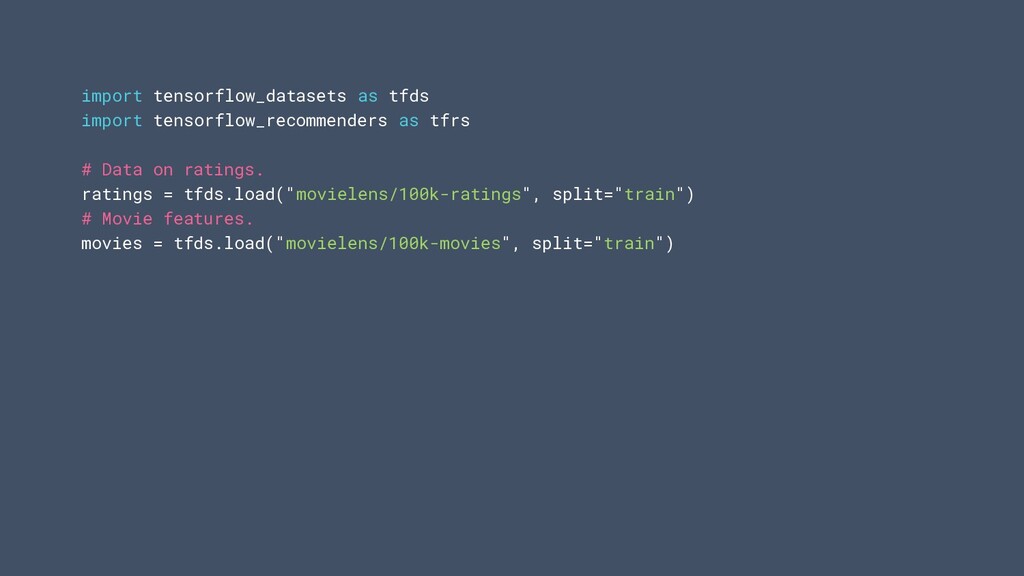
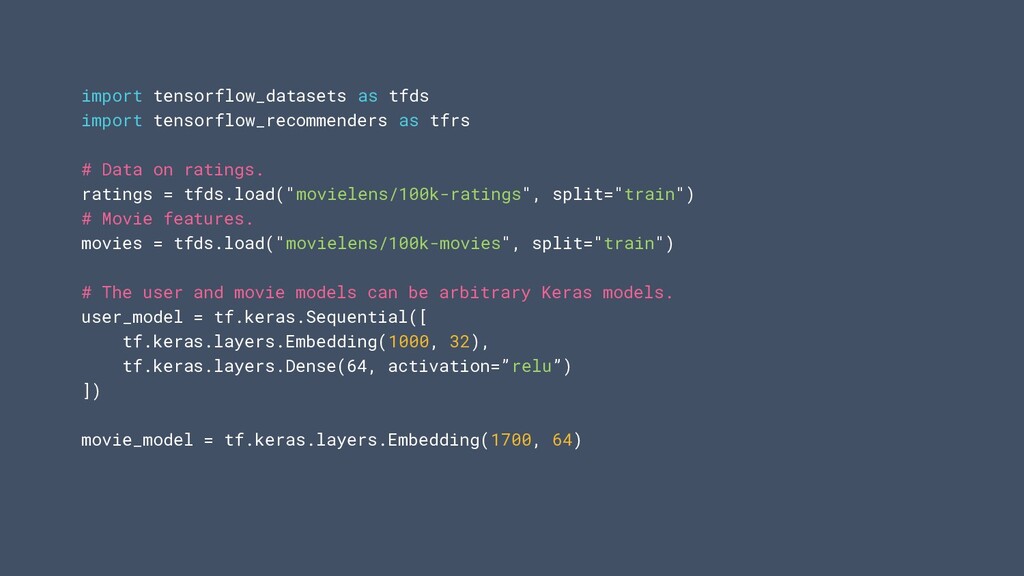
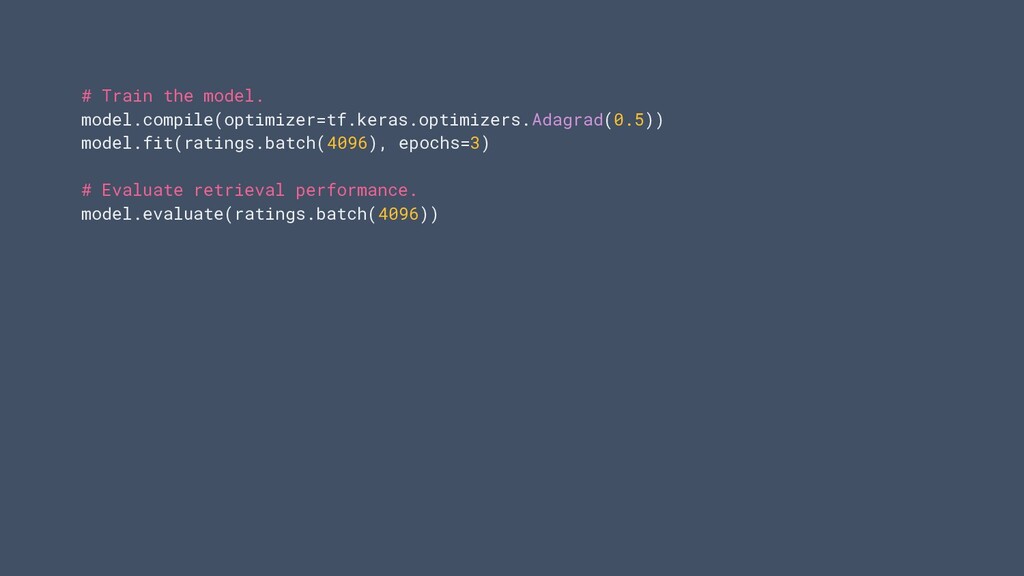
on ratings. ratings = tfds.load("movielens/100k-ratings", split="train") # Movie features. movies = tfds.load("movielens/100k-movies", split="train") # The user and movie models can be arbitrary Keras models. user_model = tf.keras.Sequential([ tf.keras.layers.Embedding(1000, 32), tf.keras.layers.Dense(64, activation=”relu”) ]) movie_model = tf.keras.layers.Embedding(1700, 64)
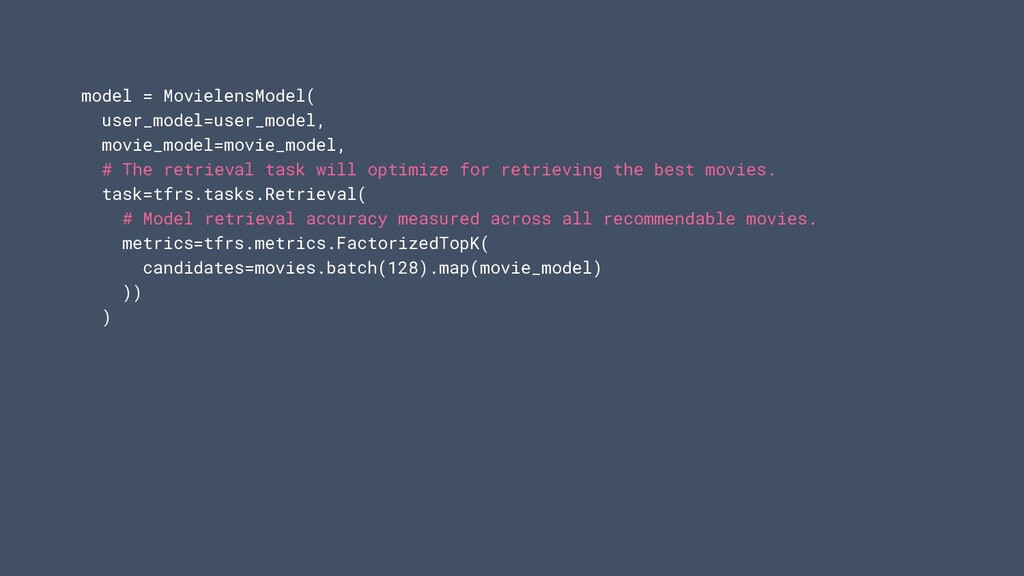
will optimize for retrieving the best movies. task=tfrs.tasks.Retrieval( # Model retrieval accuracy measured across all recommendable movies. metrics=tfrs.metrics.FactorizedTopK( candidates=movies.batch(128).map(movie_model) )) )
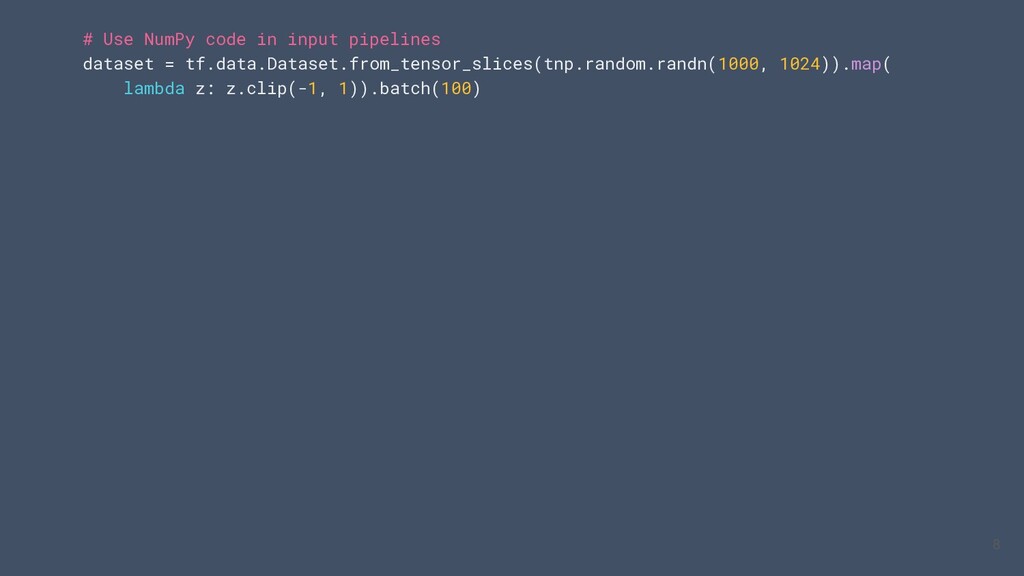
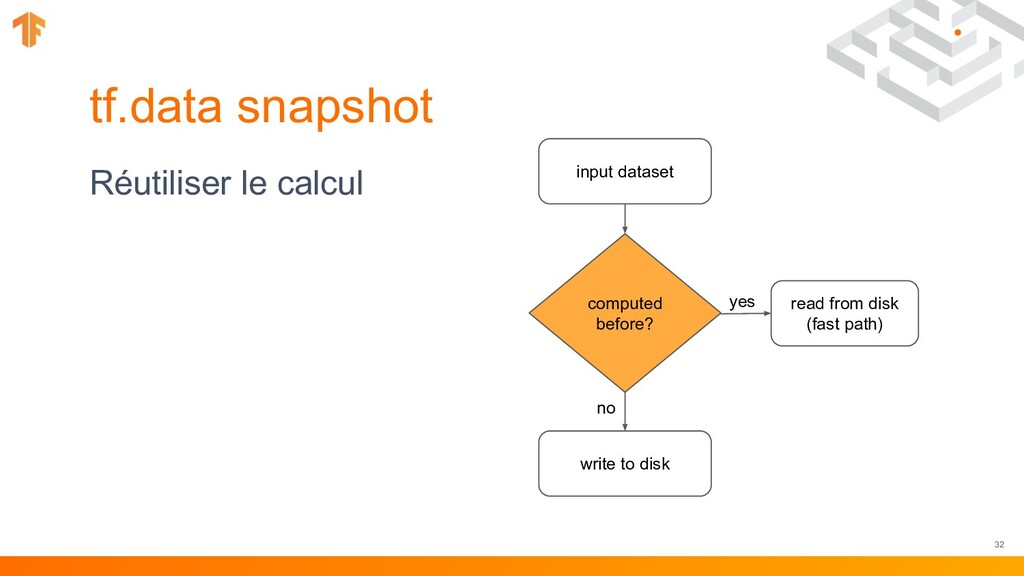
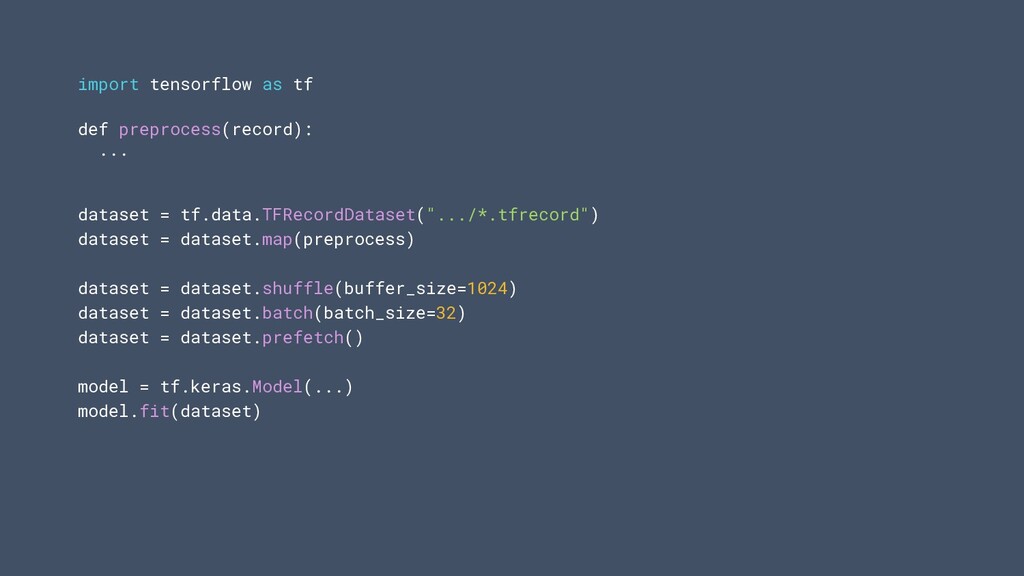
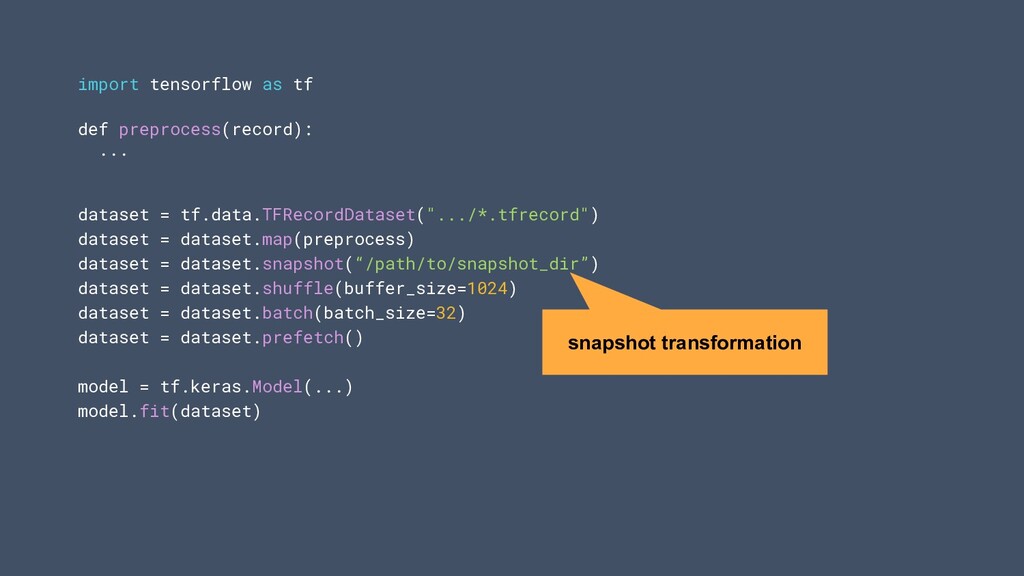
traitement répétitif des données • tf.data.service peut vous aider à mettre à l'échelle horizontalement le traitement des données • Nouvelle API pour une sauvegarde et un chargement efficaces des ensembles de données arbitraires tf.data 31
pipeline avec une seule ligne de code • Snapshot permet la réutilisation du prétraitement des données • service facilite le prétraitement des données distribuées
créer de nouveaux modèles et à obtenir les performances dont vous avez besoin. • tf.experimental.numpy • Keras preprocessing layers • librairie TF Recommenders l • Les ameliorations de TensorFlow Profiler En résumé 41
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}