et al., 2007. HyperLogLog: the analysis of a near-optimal cardinality estimation algorithm 集合のcardinality( 要素数) をO(1) space で⾼精度に 推定できる このスライドでは以下HLL と省略
public byte[] merge(byte[] sketch1, byte[] sketch2) { int m = sketch1.length; byte[] merged = new byte[m]; for (int i = 0; i < m; i++) { merged[i] = Math.max(sketch1[i], sketch2[i]); } return merged; }
A New Algorithm for Cardinality Estimation Based on LogLog Counting オリジナルのHLL はcardinality が⼩さいときに誤差 が⼤きくなる LogLog-Beta はすべてのcardinality range でよい精度 を⽰す
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
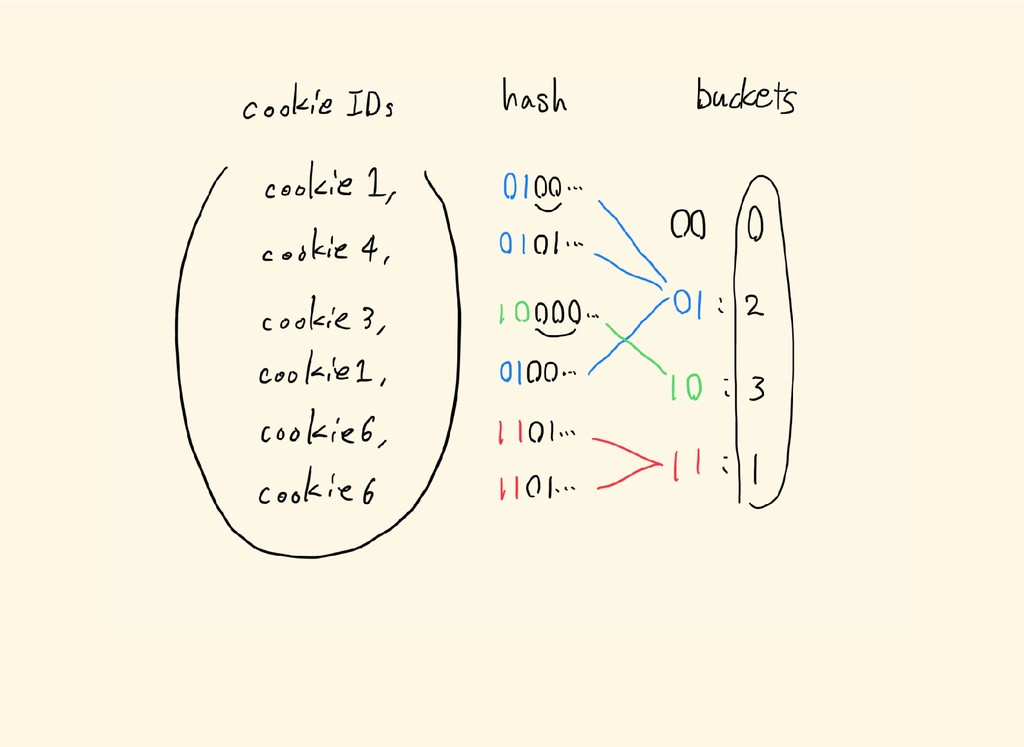{kind=link}
{kind=link}
{kind=link}
![Estimation Estimation sketch をM としてM[i] でi 番⽬のbucket を表すと、 HLL では以下の式で最終的なcardinality](https://files.speakerdeck.com/presentations/d24b499337dd427fb6c990127176c168/slide_22.jpg){kind=link}
{kind=link}
![Pseudo code Pseudo code Sketch construction byte[] sketch = new](https://files.speakerdeck.com/presentations/d24b499337dd427fb6c990127176c168/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
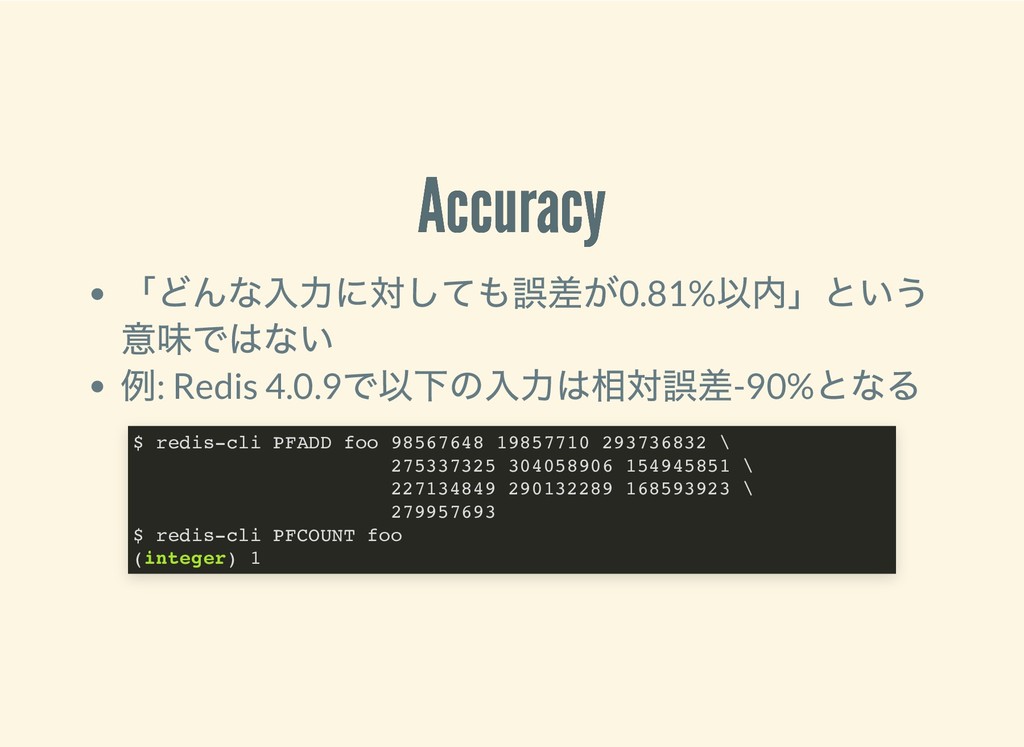{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
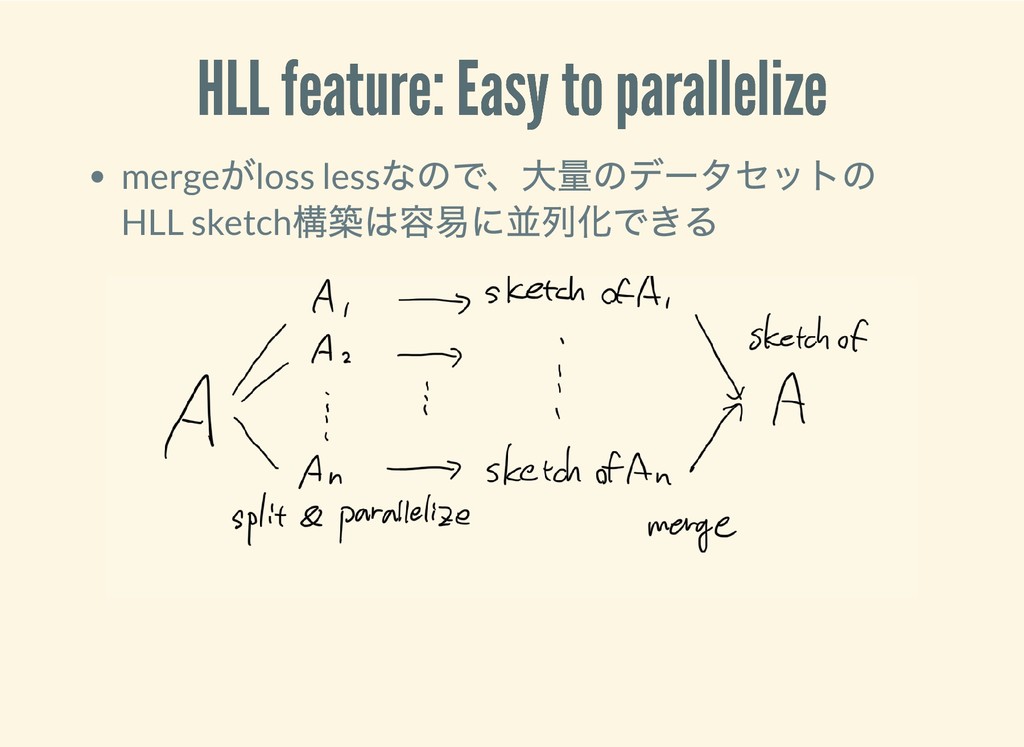{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
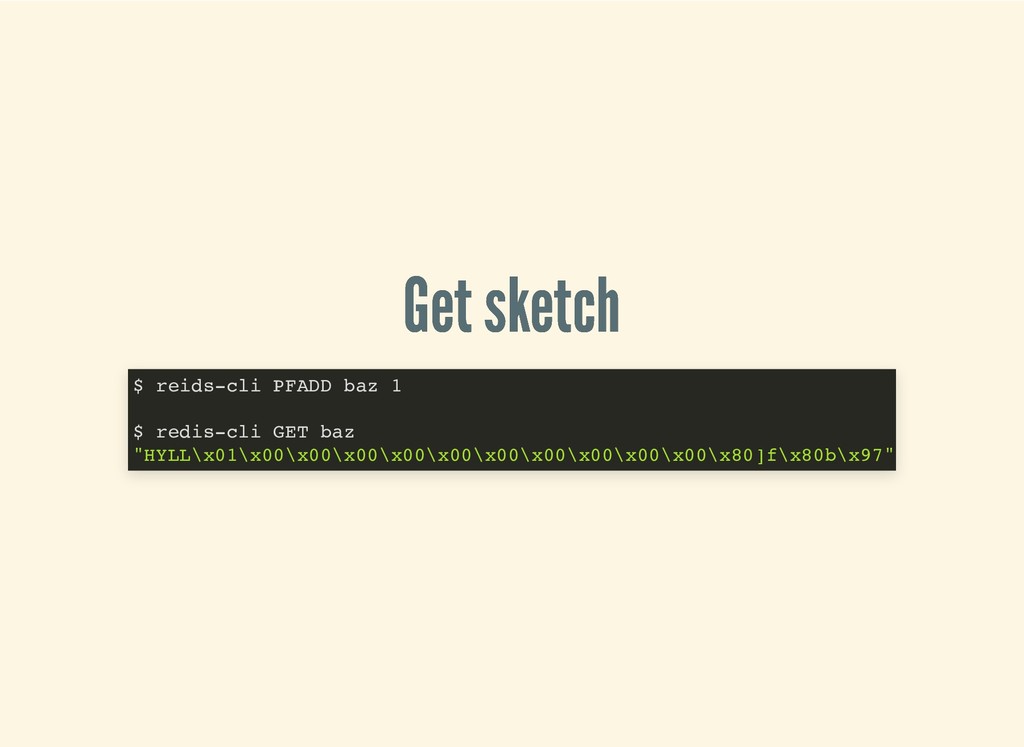{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}