Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Sparkが社内で流行ってきた話
Search
Okada Haruki
October 08, 2016
Technology
970
4
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Sparkが社内で流行ってきた話
Scala関西 Summit 2016での発表資料
Okada Haruki
October 08, 2016
More Decks by Okada Haruki
See All by Okada Haruki
HyperLogLog feature of ClickHouse
ocadaruma
0
1.5k
HyperLogLog is interesting
ocadaruma
3
900
A Redis compatible HLL implementation in Java
ocadaruma
0
360
sbt-uglifier
ocadaruma
0
1.3k
Other Decks in Technology
See All in Technology
SRENEXT_2026_Chairs__Talks_in_Tamachi.sre.pdf
srenext
1
160
現場で使える AWS DevOps Agent 活用ノウハウ - Release Management 機能の検証結果を添えて / AWS DevOps Agent Release Management and Know-How
kinunori
3
420
2026年のソフトウェア開発を考える(2026/07版) / Agentic Software Engineering 2026-07 Findy Edition
twada
PRO
30
17k
【5分でわかる】セーフィー エンジニア向け会社紹介
safie_recruit
0
53k
AI時代におけるエンジニアの新たな役割──FDEとクオリアの探求/登壇資料(戸井田 裕貴)
hacobu
PRO
0
600
システム監視を 「システムを監視するだけ」で 終わらせないために
seiud
0
140
Claude Mythos、Fable...フロンティアAIの最新動向と企業のセキュリティ対策
flatt_security
0
160
AIエージェントがあれば技術書なんてすぐ書けるでしょ→無理でした
watany
6
1k
ダッシュボード"開発"について 〜使われるダッシュボードのつくりかた〜
kimichan
0
230
コンポーネント名には何を含めるべきなのか? / what-should-be-included-in-component-names
airrnot1106
0
140
Power Automateアップデート情報
miyakemito
0
270
なぜ、あなたのエージェントは言うことを聞かないのか
segavvy
1
560
Featured
See All Featured
How to Build an AI Search Optimization Roadmap - Criteria and Steps to Take #SEOIRL
aleyda
1
2.1k
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
What does AI have to do with Human Rights?
axbom
PRO
1
2.3k
Site-Speed That Sticks
csswizardry
13
1.4k
Agile that works and the tools we love
rasmusluckow
331
22k
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
2
430
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
670
Information Architects: The Missing Link in Design Systems
soysaucechin
0
1k
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
280
Are puppies a ranking factor?
jonoalderson
1
3.7k
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
350
Transcript
Sparkが社内で 流行ってきた話 株式会社オプト 岡田遥来
目次 • Sparkとは • オプトでのSpark採用の経緯 • Spark採用プロダクトが増えてきた話
自己紹介 • 岡田 遥来 (@ocadaruma) • 株式会社 Demand Side Science
(2015-03~2015-12) • 株式会社 オプト (2016-01~) • おもにログ計測/集計等バックエンド • Spark (on EMR) • DynamoDB • Redshift • Github: sbt-youtube, chronoscala
Sparkとは • オープンソースの大規模データ処理フレームワーク • Scalaで実装されている • オンメモリ主体の高速な処理 • Scala, Java,
Python, R用のインターフェースがある
Sparkでの処理の書き方 • collection操作の要領でロジックを書く • ローカルでも動かせるし、そのまま大規模クラスタ上でも動く import org.apache.spark.{SparkConf, SparkContext} object Main
{ def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("word_count") val sc = new SparkContext(conf) sc.textFile("/path/to/input") .flatMap(_.split(' ')) .map((_, 1)) .reduceByKey(_ + _) .map { case (word, count) => s"$word:$count" } .saveAsTextFile("/path/to/output/word_count.txt") } }
Sparkで扱える入力 • ローカルファイル • Scalaのコレクション • HDFS • S3 •
etc,…
オプトでのSpark採用の経緯 • 広告効果計測システムの新バージョン開発 • 開発言語: Scala • インフラ: AWS •
データ規模: 6,000,000 req / h • Sparkが候補に -> 採用
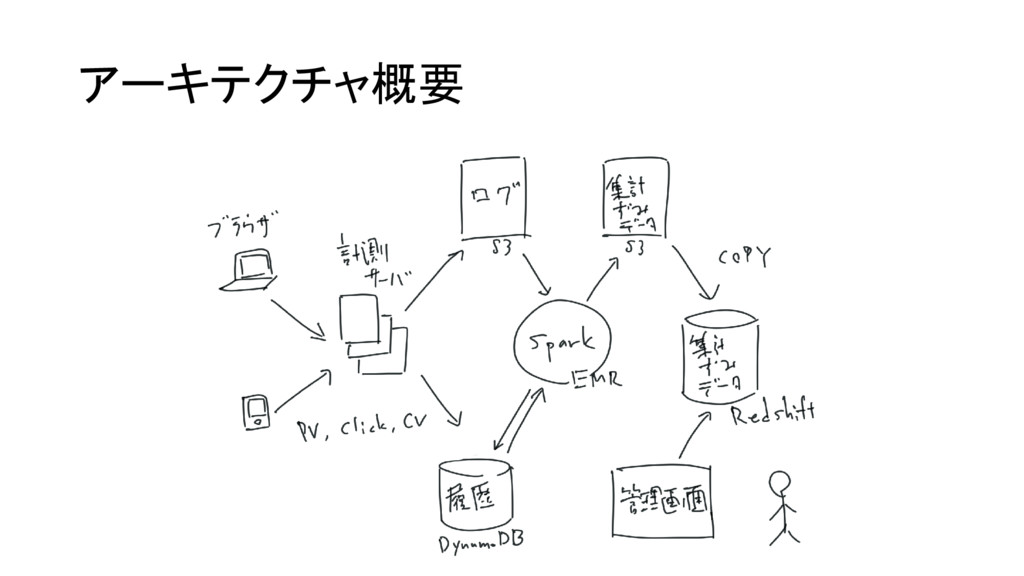
アーキテクチャ概要
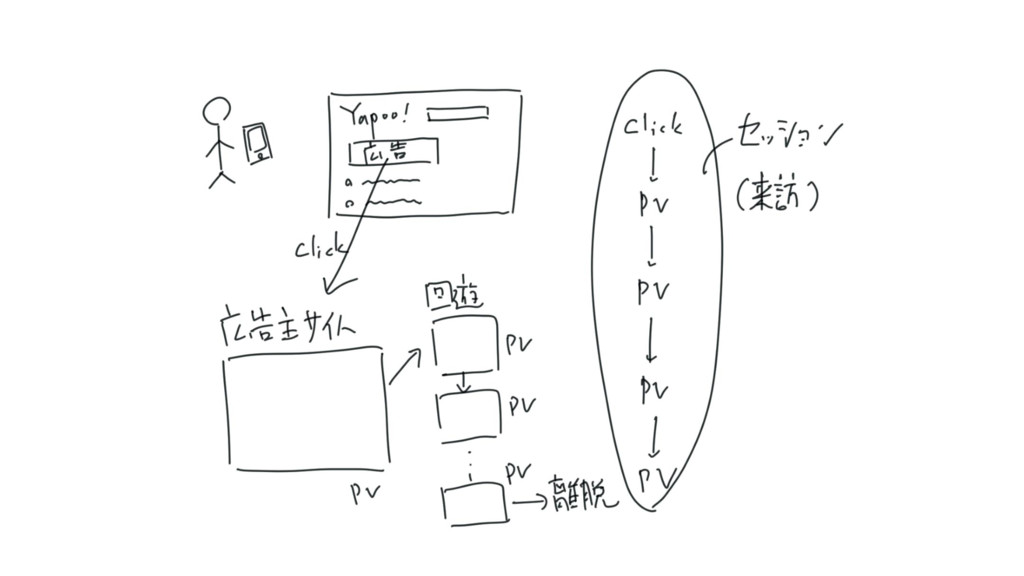
広告効果計測で行う処理の例 • セッション化 • アクセス解析 / 広告効果解析では、サイトへの来訪を表す「セッション」単位 での分析を行う • 一定間隔空かないPVの集合を「セッション」にまとめる
None
Sparkでのセッション化 sealed trait Event { def epochMillis: Long def cookieId:
String } case class PageView(epochMillis: Long, cookieId: String, url: String) extends Event case class Click(epochMillis: Long, cookieId: String, referrer: String) extends Event case class Session(epochMillis: Long, cookieId: String, numPageViews: Int) val pageViews = sc.textFile("/path/to/page_views") .map(decodePageView(_): Event) val clicks = sc.textFile("/path/to/clicks") .map(decodeClick(_): Event) val sessions = (pageViews ++ clicks) .map(e => (e.cookieId, e)) .groupByKey() .flatMap { case (_, events) => sessionize(events.toSeq) }
広告効果計測で行う処理の例 • ラストクリックの突合せ • 広告効果解析では、コンバージョン(購入等)に至るまでにクリックされた広 告のうち、最後のもの(ラストクリック)を重視する • (最近は、ラストクリック以外を評価する様々な考え方も出てきているが) • CVログに対して、過去のクリック履歴を参照し、ラストクリックを突き合わせる
処理
None
Sparkでのラストクリック突合せ case class Conversion(epochMillis: Long, cookieId: String) case class ConversionWithLastClick(conversion:
Conversion, lastClick: Option[Click]) def fetchClickHistory(epochMillis: Long, numDays: Int): Option[Click] = ??? val conversions = sc.textFile("/path/to/conversions") .map(decodeConversion) val conversionsWithLastClick = conversions.map { cv => ConversionWithLastClick(cv, fetchClickHistory(cv.epochMillis, 30)) }
TIPS1: broadcastの利用 • 集計で必要な設定/マスタデータ等は、ドライバで読んでbroadcast • 各executorに都度Serializeして送信、が発生しないように case class Config(lastClickTrackingDays: Int)
def fetchConfig(): Config = ??? val config = fetchConfig() val configBroadcast = sc.broadcast(config) val conversions = sc.textFile("/path/to/conversions") .map(decodeConversion) val conversionsWithLastClick = conversions.map { cv => ConversionWithLastClick(cv, fetchClickHistory(cv.epochMillis, configBroadcast.value.lastClickTrackingDays)) }
TIPS2: Spark起動して自動テスト 1/2 • Sparkの依存をprovidedとtestで加える • assemblyに含めないように • test時にローカルモードで動かせるように val
sparkCore = "org.apache.spark" %% "spark-core" % "1.6.1" libraryDependencies ++= Seq( sparkCore % Provided, sparkCore % Test )
TIPS2: Spark起動して自動テスト 2/2 class SparkTest extends FlatSpec { it should
"calculate sum" in { val conf = new SparkConf().setAppName("testApp").setMaster("local[*]") val sc = new SparkContext(conf) val numbers = sc.parallelize(1 to 10) assert(numbers.sum() == 55) } }
Sparkを導入して分かったこと • RDDの枠組みの上でロジックを書けば、ちゃんとスケールする • localモードを使って、Sparkを起動するユニットテストも書ける • EMRのSparkバイナリがScala 2.10ビルドだった • Scala
2.11アプリを動かすには、ひと工夫必要 • 自前でビルドしたものをS3に配置、実行時にspark-yarn-jarを指定 • EMR 5.0.0ではSpark 2.0.0になり、Scala 2.11ビルドになった • DynamoDBがボトルネックに • せっかくのSparkの高速性を活かせない • できるだけI/Oは減らし、Sparkで完結する作りにするべき
Spark採用プロダクトが増えてきた話 • Sparkの知見が得られ、社内に詳しい人がいる状態になった • 他プロダクトでも採用 • 商品リスト広告(PLA)のレコメンドエンジン開発 • データフィード管理システム開発
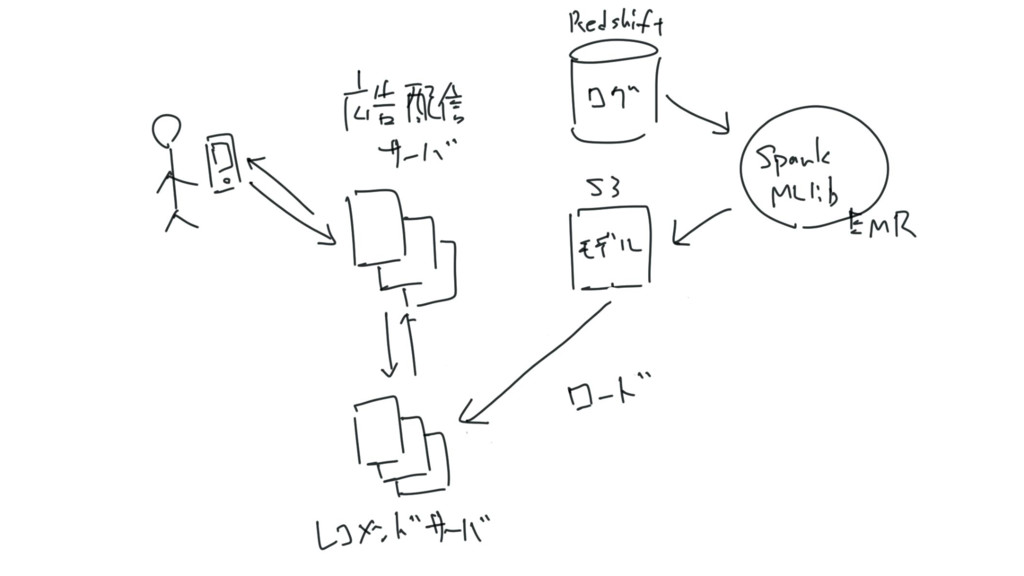
レコメンドエンジン • 協調フィルタリング(ALS)により、配信する広告のレコメンドを行う • 以下の処理をSpark MLlib on EMRで実行 • ハイパーパラメータの計算
• ユーザの閲覧履歴をもとにした、モデルの構築
None
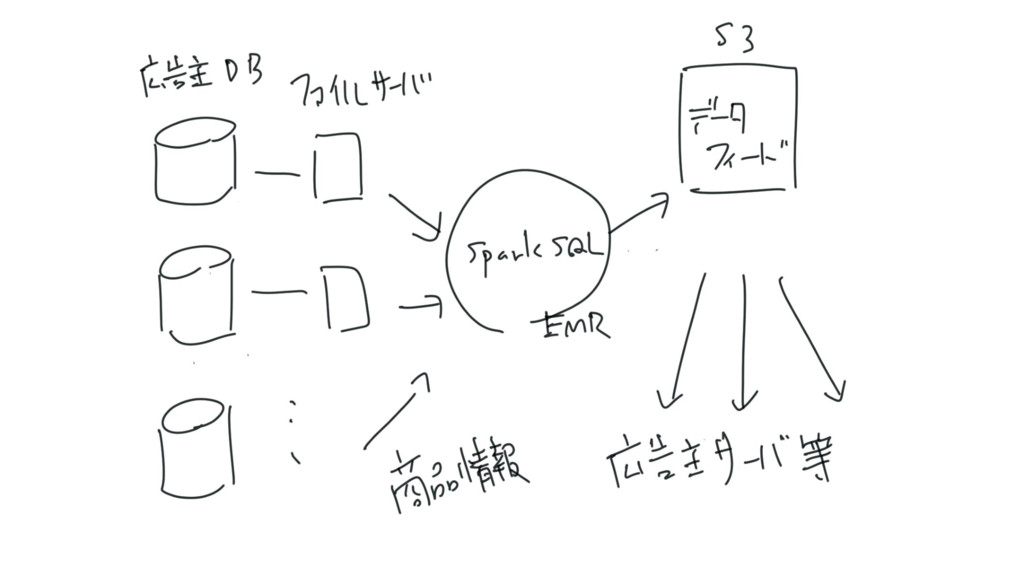
データフィード管理システム • 広告主のもつ様々な商品情報を結合・加工し、データフィード広告の ためのフィードを生成する • 商品情報のフィルタ / 結合 / 加工に、Spark
SQL on EMRを利用
None
まとめ • 社内で、分散並列処理を行う際の有力候補として定着してきた • マネージドクラスタが用意されていて楽 • AWS -> EMR •
GCP -> Cloud Dataproc(試してない) • Scalaで書けるのがよい
株式会社オプトでは Scalaエンジニアを募集しています! • https://www.opt.ne.jp/opttechnologies/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}