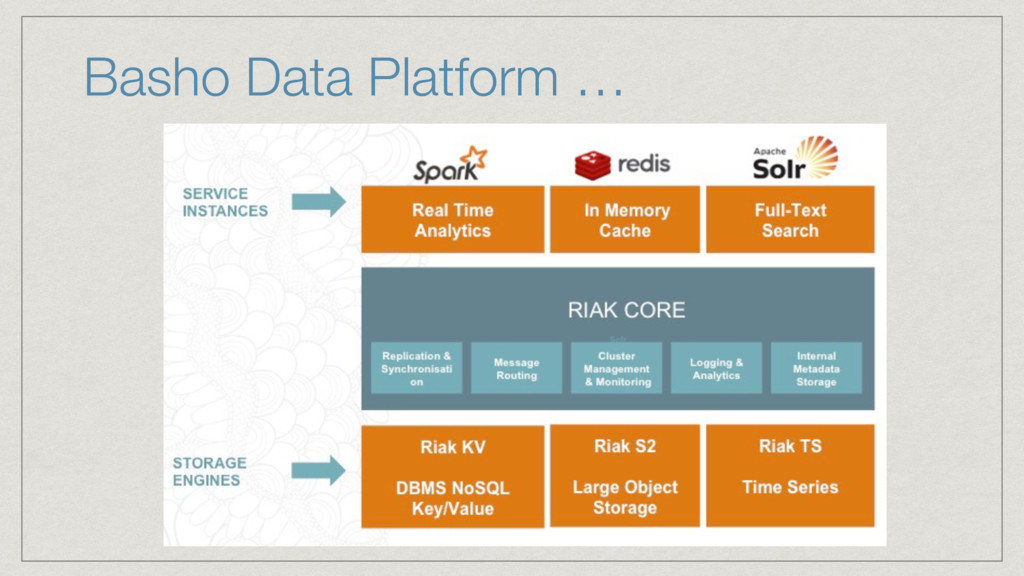
key value database Riak S2: Large Object Storage 2015 New Products Basho Data Platform: Integrated NoSQL databases, caching, in-memory analytics, and search Riak TS: NoSQL Time Series database 120+ employees Global Offices Seattle (HQ), Washington DC, London, Paris, Tokyo 300+ Enterprise customers, 1/3 of the Fortune 50
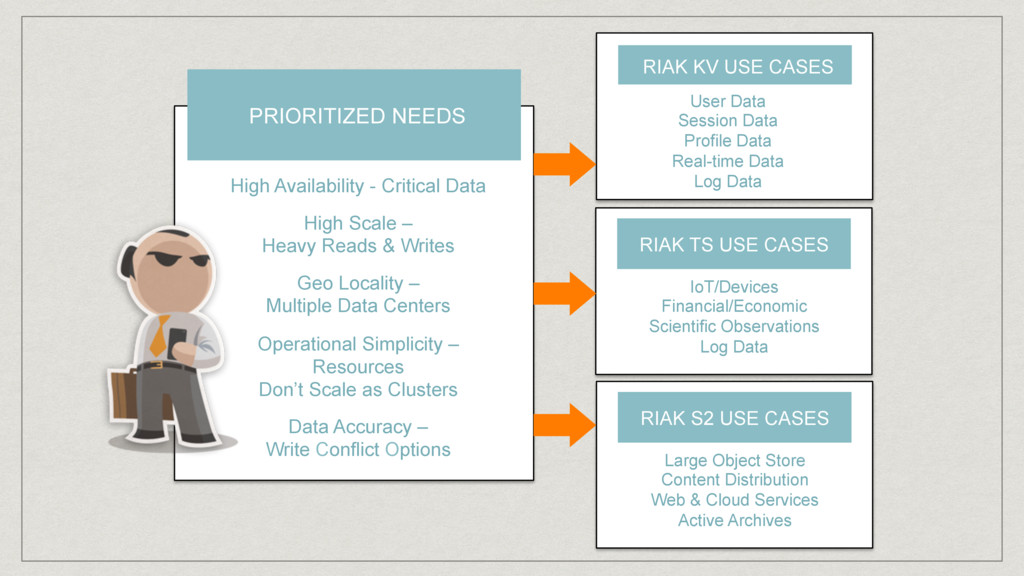
Heavy Reads & Writes Geo Locality – Multiple Data Centers Operational Simplicity – Resources Don’t Scale as Clusters Data Accuracy – Write Conflict Options ∂ RIAK S2 USE CASES Large Object Store Content Distribution Web & Cloud Services Active Archives ∂ RIAK KV USE CASES User Data Session Data Profile Data Real-time Data Log Data ∂ RIAK TS USE CASES IoT/Devices Financial/Economic Scientific Observations Log Data
Enhanced DataFrames - based on Riak TS Schema APIs Server-side aggregations and grouping - using TS SQL commands Speed Data Locality (partition RDDs according to replication in the cluster) - launch Spark executors on the same nodes where the data resides. Better mapping from vnodes to Spark workers using coverage plan Better support for Riak data types (CRDT) and Search queries Today requires using Java Riak client APIs Spark Streaming Provide example and sample integration with Apache Kafka Improve reliability using Riak for checkpoints and WAL Add examples and documentation for Python support DRAFT
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
: RiakRDD[V] riakBucket[V](bucketName: String, bucketType: String):](https://files.speakerdeck.com/presentations/2652772d346a4dcbac21091b327c9cf8/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you @ogirardot [email protected] https://github.com/ogirardot/spark-riak-example https://speakerdeck.com/ogirardot/spark-and-riak-introduction-to- the-spark-riak-connector @mcarney23 [email protected] fr.basho.com](https://files.speakerdeck.com/presentations/2652772d346a4dcbac21091b327c9cf8/slide_24.jpg){kind=link}