can : - represent any object - handle for any object’s field (no matter how nested) an encryption function (ex: mask, hash, cypher…) - while being general purpose & expressive
what it is “semantically” ex: This is a Person’s first name 2. Define Privacy Strategies, i.e. what to do with “a Person’s first name” ex: Hash, Mask, Delete…
object Zero extends Number case class Succ(prev: Number) extends Number def numberToInt(n: Number): Int = n match { case Succ(x) => 1 + numberToInt(x) case Zero => 0 }
Number case class Succ(prev: Number) extends Number Succ(Succ(Succ(Zero))) = 3 def numberToInt(n: Number): Int = n match { case Succ(x) => 1 + numberToInt(x) case Zero => 0 } Zero
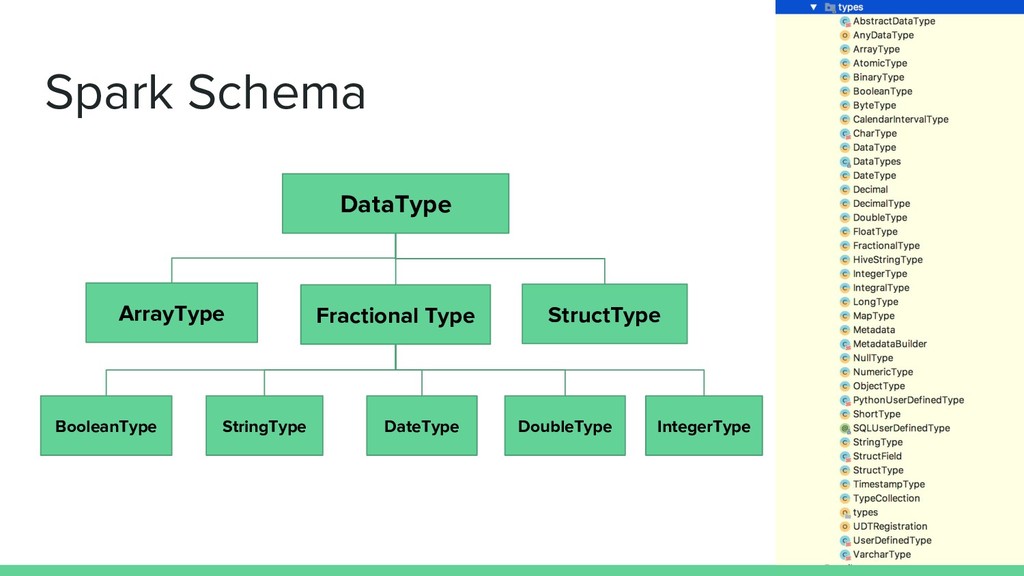
metadata: ColumnMetadata) extends TSchema case class TArray(elementType: TSchema, metadata: ColumnMetadata) extends TSchema sealed trait TValue extends TSchema case class TBoolean(metadata: ColumnMetadata) extends TValue case class TDate(metadata: ColumnMetadata) extends TValue case class TDouble(metadata: ColumnMetadata) extends TValue case class TFloat(metadata: ColumnMetadata) extends TValue case class TInteger(metadata: ColumnMetadata) extends TValue case class TLong(metadata: ColumnMetadata) extends TValue case class TString(metadata: ColumnMetadata) extends TValue
metadata: ColumnMetadata) extends TSchema case class TArray(fields: TSchema, metadata: ColumnMetadata) extends TSchema sealed trait TValue extends TSchema case class TBoolean(metadata: ColumnMetadata) extends TValue case class TDate(metadata: ColumnMetadata) extends TValue case class TDouble(metadata: ColumnMetadata) extends TValue case class TFloat(metadata: ColumnMetadata) extends TValue case class TInteger(metadata: ColumnMetadata) extends TValue case class TLong(metadata: ColumnMetadata) extends TValue case class TString(metadata: ColumnMetadata) extends TValue
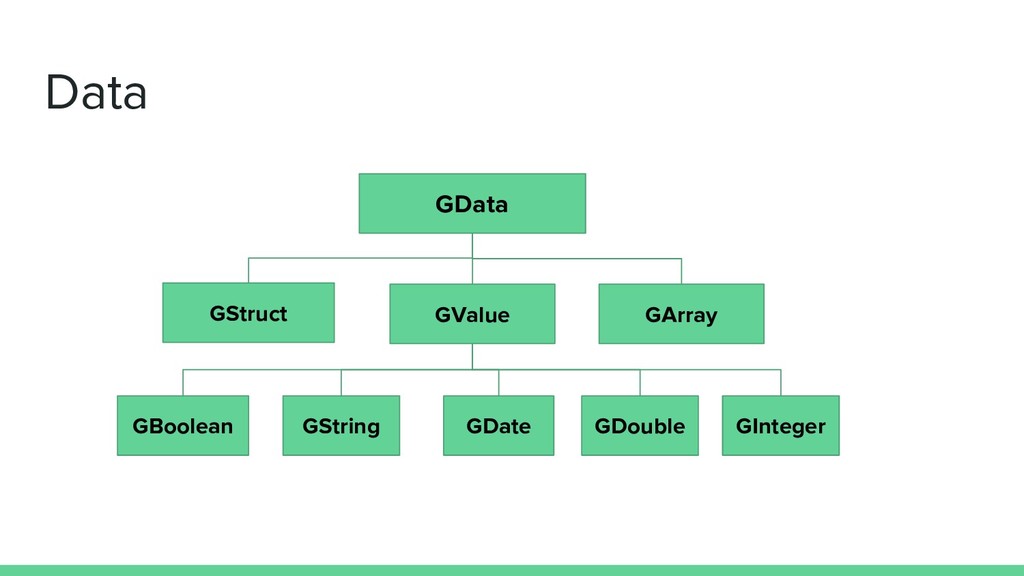
GData)]) extends GData case class GArray(elements: Seq[GData]) extends GData sealed trait GValue extends GData case class GBoolean(value: Boolean) extends GValue case class GString(value: String) extends GValue ...
(fields: List[(String, A)], metadata: ColumnMetadata) extends SchemaF[A] case class ArrayF[A](elementType: A, metadata: ColumnMetadata) extends SchemaF[A] sealed trait ValueF[A] extends SchemaF[A] case class BooleanF[A](metadata: ColumnMetadata) extends ValueF[A] case class StringF[A](metadata: ColumnMetadata) extends ValueF[A] … sealed trait TSchema case class TStruct(fields: List[(String, TSchema)], metadata: ColumnMetadata) extends TSchema case class TArray(elementType: TSchema, metadata: ColumnMetadata) extends TSchema sealed trait TValue extends TSchema case class TBoolean(metadata: ColumnMetadata) extends TSchema case class TString(metadata: ColumnMetadata) extends TSchema ...
Functor[SchemaF] { def map[A, B](fa: SchemaF[A])(f: A => B): SchemaF[B] = fa match { case StructF(fields, m) => StructF(fields.map{ case (name, value) => name -> f(value) }), m) case ArrayF(elem, m) => ArrayF(f(elem), m) case BooleanF(m) => BooleanF(m) case StringF(m) => StringF(m) case IntegerF(m) => IntegerF(m) ... } }
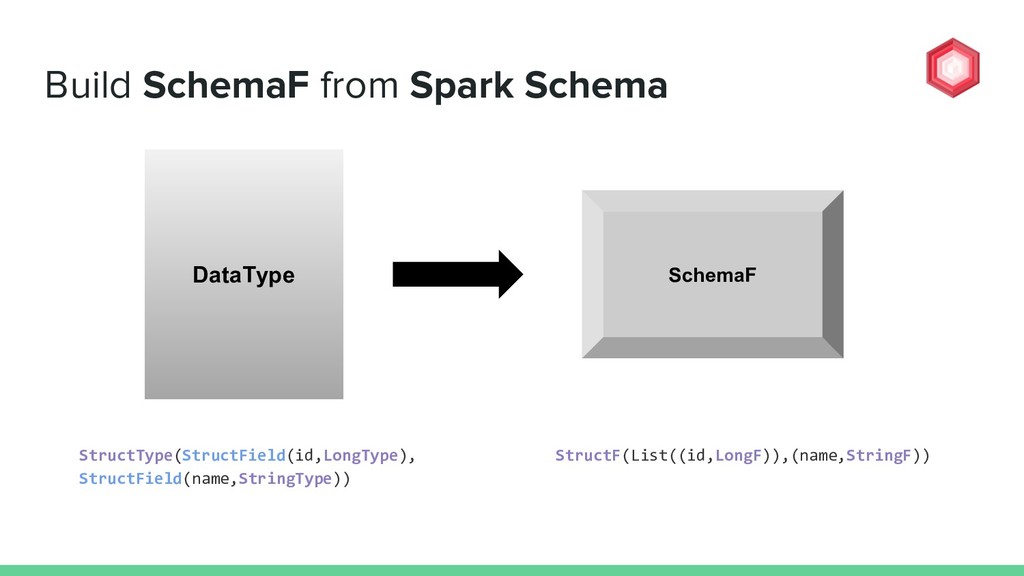
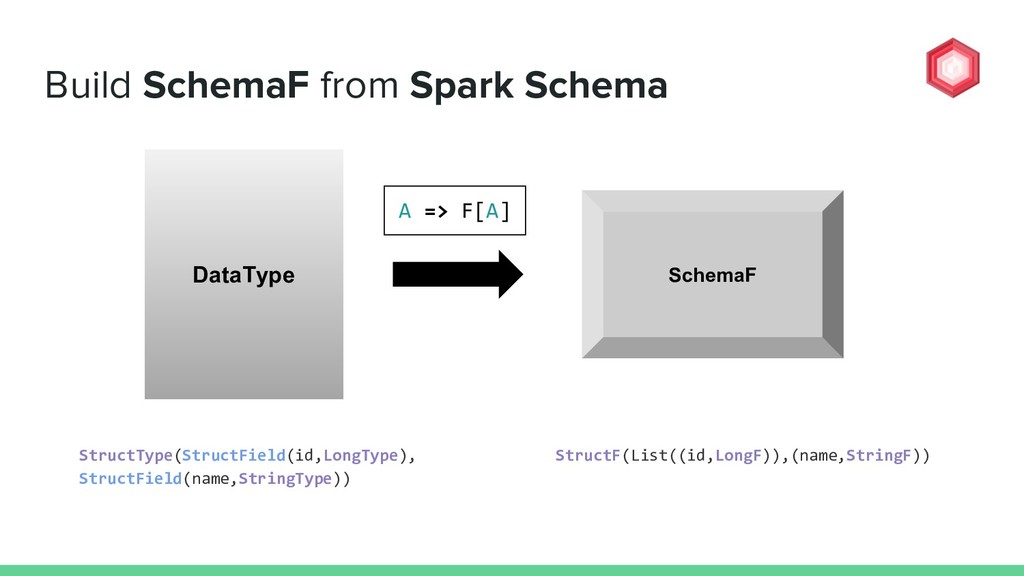
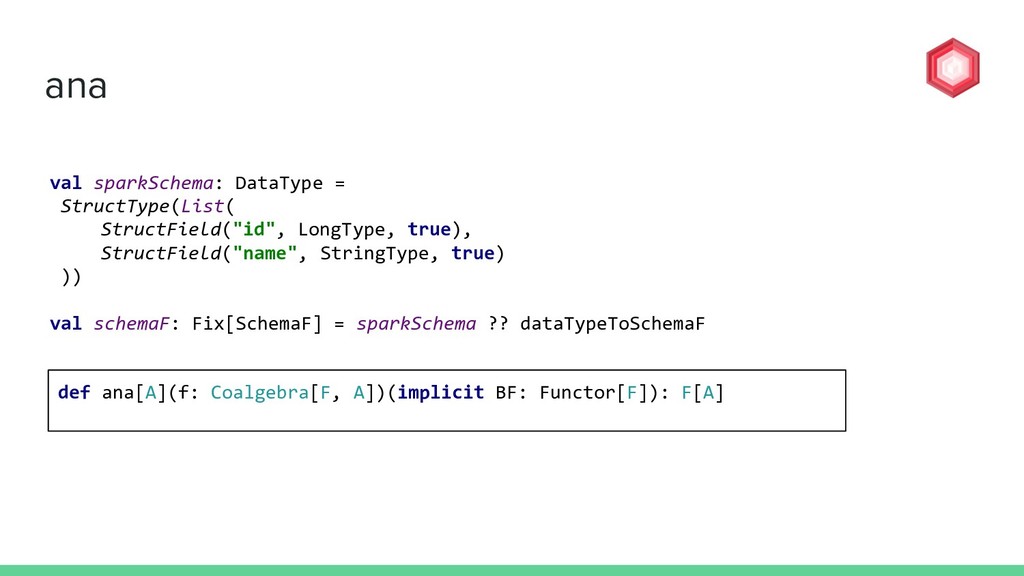
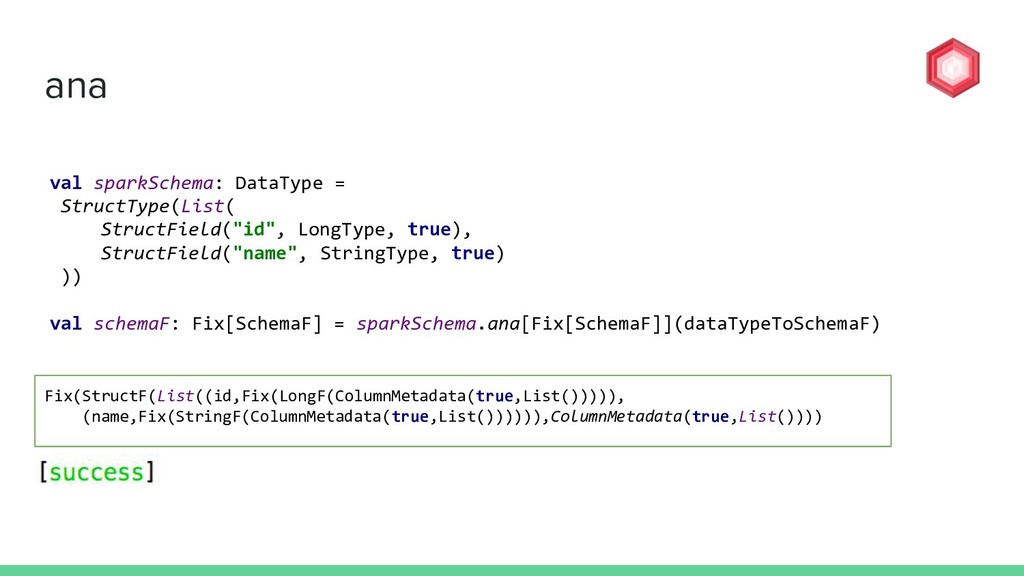
DataType? val dataTypeToSchemaF: Coalgebra[SchemaF, DataType] = { case StructType(fields) => StructF(fields.map(f => f.name -> f.dataType)), ColumnMetadata.empty) case ArrayType(elem, _) => ArrayF(elem, ColumnMetadata.empty) case BooleanType => BooleanF(ColumnMetadata.empty) case DateType => DateF(ColumnMetadata.empty) case DoubleType => DoubleF(ColumnMetadata.empty) case FloatType => FloatF(ColumnMetadata.empty) case IntegerType => IntegerF(ColumnMetadata.empty) case LongType => LongF(ColumnMetadata.empty) case StringType => StringF(ColumnMetadata.empty) } DataType TOP DOWN
=> f.name -> f.dataType)), ColumnMetadata.empty) case ArrayType(elem, _) => ArrayF(elem, ColumnMetadata.empty) case BooleanType => BooleanF(ColumnMetadata.empty) case DateType => DateF(ColumnMetadata.empty) case DoubleType => DoubleF(ColumnMetadata.empty) case FloatType => FloatF(ColumnMetadata.empty) case IntegerType => IntegerF(ColumnMetadata.empty) case LongType => LongF(ColumnMetadata.empty) case StringType => StringF(ColumnMetadata.empty) } StructType(StructField(id,LongType), StructField(name,StringType)) StructType TOP DOWN How to build up a single layer of SchemaF from DataType?
=> f.name -> f.dataType)), ColumnMetadata.empty) case ArrayType(elem, _) => ArrayF(elem, ColumnMetadata.empty) case BooleanType => BooleanF(ColumnMetadata.empty) case DateType => DateF(ColumnMetadata.empty) case DoubleType => DoubleF(ColumnMetadata.empty) case FloatType => FloatF(ColumnMetadata.empty) case IntegerType => IntegerF(ColumnMetadata.empty) case LongType => LongF(ColumnMetadata.empty) case StringType => StringF(ColumnMetadata.empty) } StructType(StructField(id,LongType), StructField(name,StringType)) StructType StructF(List(id,LongType),(name,StringType)) TOP DOWN How to build up a single layer of SchemaF from DataType?
=> f.name -> f.dataType)), ColumnMetadata.empty) case ArrayType(elem, _) => ArrayF(elem, ColumnMetadata.empty) case BooleanType => BooleanF(ColumnMetadata.empty) case DateType => DateF(ColumnMetadata.empty) case DoubleType => DoubleF(ColumnMetadata.empty) case FloatType => FloatF(ColumnMetadata.empty) case IntegerType => IntegerF(ColumnMetadata.empty) case LongType => LongF(ColumnMetadata.empty) case StringType => StringF(ColumnMetadata.empty) } StructType(StructField(id,LongType), StructField(name,StringType)) StructF(List(id,LongType, (name,StringType)) LongType TOP DOWN How to build up a single layer of SchemaF from DataType?
=> f.name -> f.dataType)), ColumnMetadata.empty) case ArrayType(elem, _) => ArrayF(elem, ColumnMetadata.empty) case BooleanType => BooleanF(ColumnMetadata.empty) case DateType => DateF(ColumnMetadata.empty) case DoubleType => DoubleF(ColumnMetadata.empty) case FloatType => FloatF(ColumnMetadata.empty) case IntegerType => IntegerF(ColumnMetadata.empty) case LongType => LongF(ColumnMetadata.empty) case StringType => StringF(ColumnMetadata.empty) } StructType(StructField(id,LongType), StructField(name,StringType)) StructF(List(id,LongF(ColumnMetadata.empty), (name,StringType)) LongType TOP DOWN How to build up a single layer of SchemaF from DataType?
=> f.name -> f.dataType)), ColumnMetadata.empty) case ArrayType(elem, _) => ArrayF(elem, ColumnMetadata.empty) case BooleanType => BooleanF(ColumnMetadata.empty) case DateType => DateF(ColumnMetadata.empty) case DoubleType => DoubleF(ColumnMetadata.empty) case FloatType => FloatF(ColumnMetadata.empty) case IntegerType => IntegerF(ColumnMetadata.empty) case LongType => LongF(ColumnMetadata.empty) case StringType => StringF(ColumnMetadata.empty) } StructType(StructField(id,LongType), StructField(name,StringType)) StructF(List(id,LongF(ColumnMetadata.empty), (name,StringType)) StringType TOP DOWN How to build up a single layer of SchemaF from DataType?
=> f.name -> f.dataType)), ColumnMetadata.empty) case ArrayType(elem, _) => ArrayF(elem, ColumnMetadata.empty) case BooleanType => BooleanF(ColumnMetadata.empty) case DateType => DateF(ColumnMetadata.empty) case DoubleType => DoubleF(ColumnMetadata.empty) case FloatType => FloatF(ColumnMetadata.empty) case IntegerType => IntegerF(ColumnMetadata.empty) case LongType => LongF(ColumnMetadata.empty) case StringType => StringF(ColumnMetadata.empty) } StructType(StructField(id,LongType), StructField(name,StringType)) StructF(List(id,LongF(ColumnMetadata.empty), (name,StringF(ColumnMetadata.empty))) StringType TOP DOWN How to build up a single layer of SchemaF from DataType?
=> StructType(fields.map { case (name, value) => StructField(name, value) }.toArray) case ArrayF(elem, m) => ArrayType(elem, containsNull = false) case BooleanF(_) => BooleanType case DateF(_) => DateType case DoubleF(_) => DoubleType case FloatF(_) => FloatType case IntegerF(_) => IntegerType case LongF(_) => LongType case StringF(_) => StringType } SchemaF UP BOTTOM
=> StructType(fields.map { case (name, value) => StructField(name, value) }.toArray) case ArrayF(elem, m) => ArrayType(elem, containsNull = false) case BooleanF(_) => BooleanType case DateF(_) => DateType case DoubleF(_) => DoubleType case FloatF(_) => FloatType case IntegerF(_) => IntegerType case LongF(_) => LongType case StringF(_) => StringType } LongF StructF(List((id,LongF)),(name,StringF)) StructF(List((id,LongF)),(name,StringF)) UP BOTTOM
=> StructType(fields.map { case (name, value) => StructField(name, value) }.toArray) case ArrayF(elem, m) => ArrayType(elem, containsNull = false) case BooleanF(_) => BooleanType case DateF(_) => DateType case DoubleF(_) => DoubleType case FloatF(_) => FloatType case IntegerF(_) => IntegerType case LongF(_) => LongType case StringF(_) => StringType } LongF StructF(List((id,LongType)),(name,StringF)) StructF(List((id,LongF)),(name,StringF)) UP BOTTOM
=> StructType(fields.map { case (name, value) => StructField(name, value) }.toArray) case ArrayF(elem, m) => ArrayType(elem, containsNull = false) case BooleanF(_) => BooleanType case DateF(_) => DateType case DoubleF(_) => DoubleType case FloatF(_) => FloatType case IntegerF(_) => IntegerType case LongF(_) => LongType case StringF(_) => StringType } StringF StructF(List((id,LongType)),(name,StringF)) StructF(List((id,LongF)),(name,StringF)) UP BOTTOM
=> StructType(fields.map { case (name, value) => StructField(name, value) }.toArray) case ArrayF(elem, m) => ArrayType(elem, containsNull = false) case BooleanF(_) => BooleanType case DateF(_) => DateType case DoubleF(_) => DoubleType case FloatF(_) => FloatType case IntegerF(_) => IntegerType case LongF(_) => LongType case StringF(_) => StringType } StringF StructF(List((id,LongType)),(name,StringType)) StructF(List((id,LongF)),(name,StringF)) UP BOTTOM
=> StructType(fields.map { case (name, value) => StructField(name, value) }.toArray) case ArrayF(elem, m) => ArrayType(elem, containsNull = false) case BooleanF(_) => BooleanType case DateF(_) => DateType case DoubleF(_) => DoubleType case FloatF(_) => FloatType case IntegerF(_) => IntegerType case LongF(_) => LongType case StringF(_) => StringType } StructF(List((id,LongType)),(name,StringType)) StructF(List((id,LongF)),(name,StringF)) StructF UP BOTTOM
=> StructType(fields.map { case (name, value) => StructField(name, value) }.toArray) case ArrayF(elem, m) => ArrayType(elem, containsNull = false) case BooleanF(_) => BooleanType case DateF(_) => DateType case DoubleF(_) => DoubleType case FloatF(_) => FloatType case IntegerF(_) => IntegerType case LongF(_) => LongType case StringF(_) => StringType } StructType(StructField(id,LongType), StructField(name,StringType)) StructF(List((id,LongF)),(name,StringF)) StructF UP BOTTOM
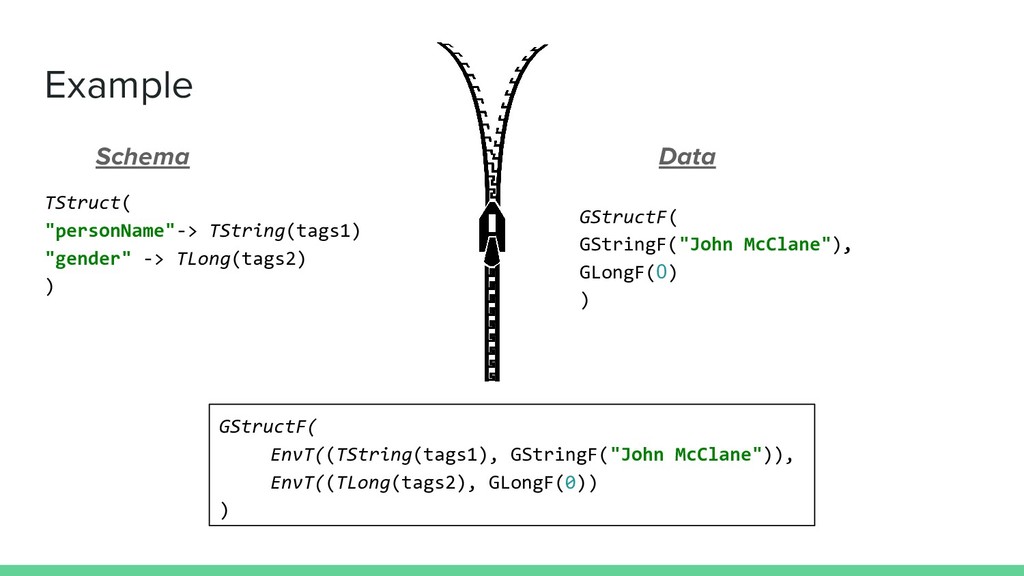
matched, for example with a type Data & Schema : type DataWithSchema[A] = EnvT[Fix[SchemaF], DataF, A] … match { case EnvT((TStruct(f, m)), data @ GStructF(fields))) => } Or you can access the inner values with ask & lower final case class EnvT[E, W[_], A](run: (E, W[A])) { self => def ask: E = run._1 def lower: W[A] = run._2 }
match Schema ⇔ Data if it doesn’t match then your data is not compatible with your Schema : def zipWithSchema: CoalgebraM[\/[Incompatibility, ?], DataWithSchema, (Fix[SchemaF], Fix[DataF])] = { case (structf @ Fix(StructF(fields, metadata)), Fix(GStructF(values))) => … // everything is fine ! build the EnvT case (arrayf @ Fix(ArrayF(elementType, metadata)), Fix(GArrayF(values))) => … // everything is fine ! build the EnvT (you get the idea !) case values … case (wutSchema, wutData) => … // everything is not fine ! Incompatibility ! }
match { case -\/(incompatibilities) => log.error(s"Found incompatibilities between the observed data and its expected schema : $incompatibilities") case \/-(result) => result }
every piece of data we need to zip it with its schema - So for 1,000 rows of the same table - we will duplicate the same schema Is it possible to just “prepare” the mutation ?
// Transform the data def andThen(f: Fix[DataF] => Fix[DataF]): MutationOp // Chain transformations } // NoOp - nothing comes out of this - there's nothing to do ! case object NoMutationOp extends MutationOp with Serializable { override def apply(gdata: Fix[DataF]): Fix[DataF] = gdata override def andThen(f: Fix[DataF] => Fix[DataF]): MutationOp = GoDown(f) } // A specific [[MutationOp]] that goes "down" and apply a function to the data private case class GoDownOp(apply0: Fix[DataF] => Fix[DataF]) extends MutationOp { override def apply(gdata: Fix[DataF]): Fix[DataF] = apply0(gdata) override def andThen(f: Fix[DataF] => Fix[DataF]): MutationOp = { GoDownOp(apply0.andThen(f)) }} What would be the form of our lambda ?
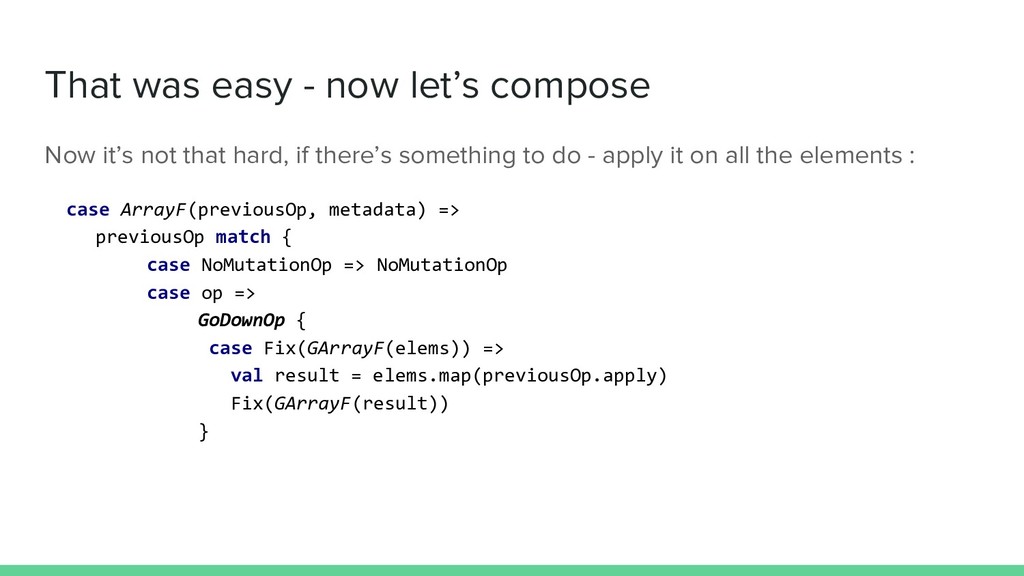
that hard, if there’s something to do - apply it on all the elements : case ArrayF(previousOp, metadata) => previousOp match { case NoMutationOp => NoMutationOp case op => GoDownOp { case Fix(GArrayF(elems)) => val result = elems.map(previousOp.apply) Fix(GArrayF(result)) }
do apply it on the fields : case StructF(fields, metadata) => if (fields.map(_._2).forall(_ == NoMutationOp)) { // all fields are not to be touched NoMutationOp } else { // at least one field need work done GoDownOp { case Fix(GStructF(dataFields)) => Fix(GStructF(fields.zip(dataFields).map { case ((fieldName, innerOp), (_, data)) => if (innerOp == NoMutationOp || data == Fix[DataF](GNullF())) { (fieldName, data) } else { (fieldName, innerOp(data)) } } )) }
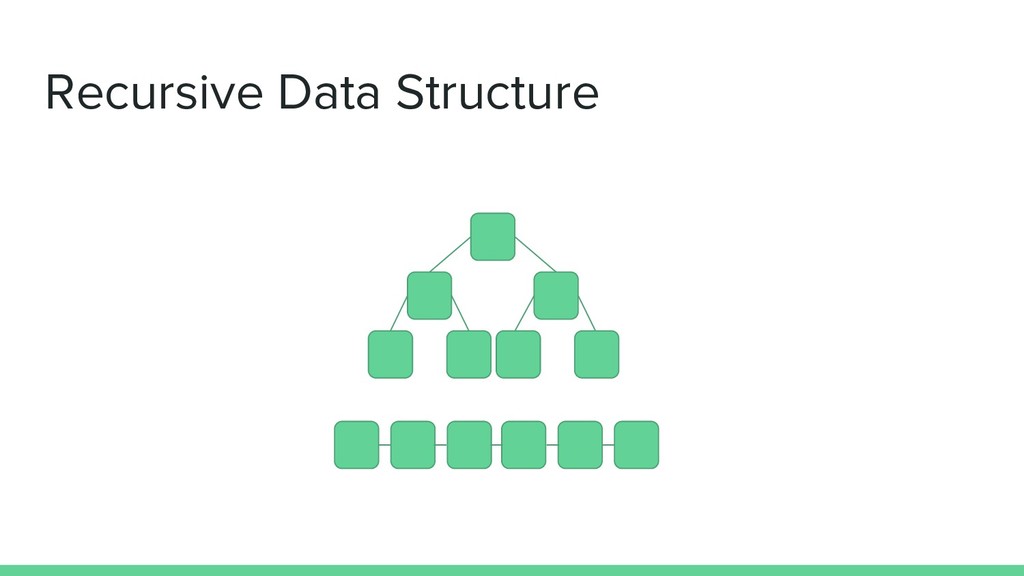
only once a lambda that : - will zoom into our recursive data - But only go into what it needs to > data.get(0).get(1).get(0) <=== There it is ! - And can be Serialized & applied many times
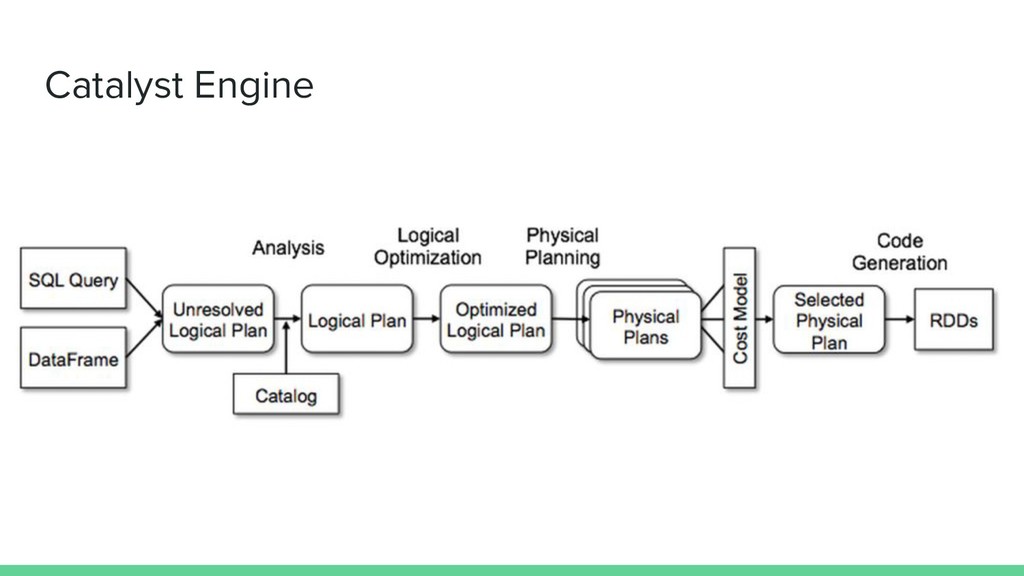
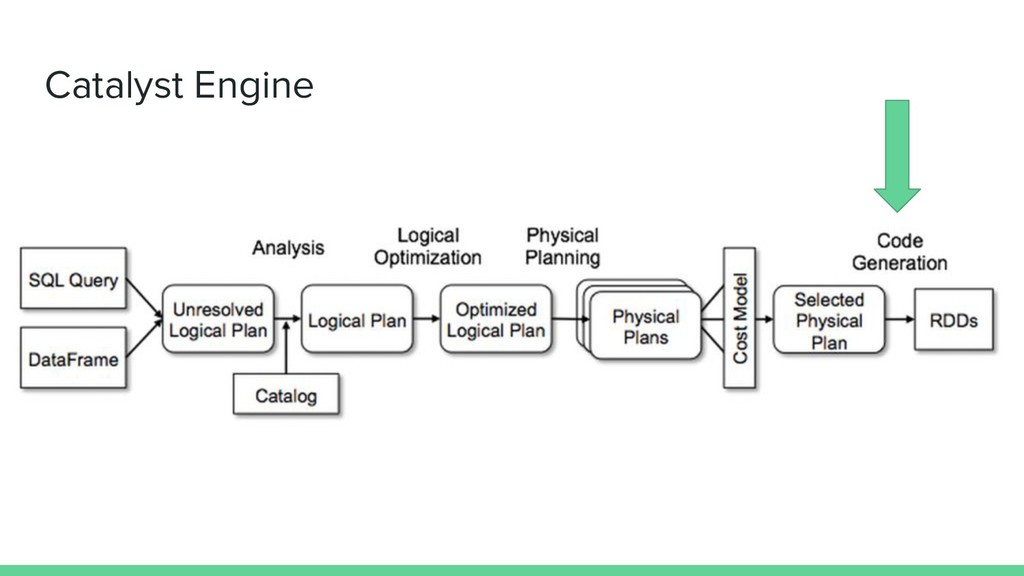
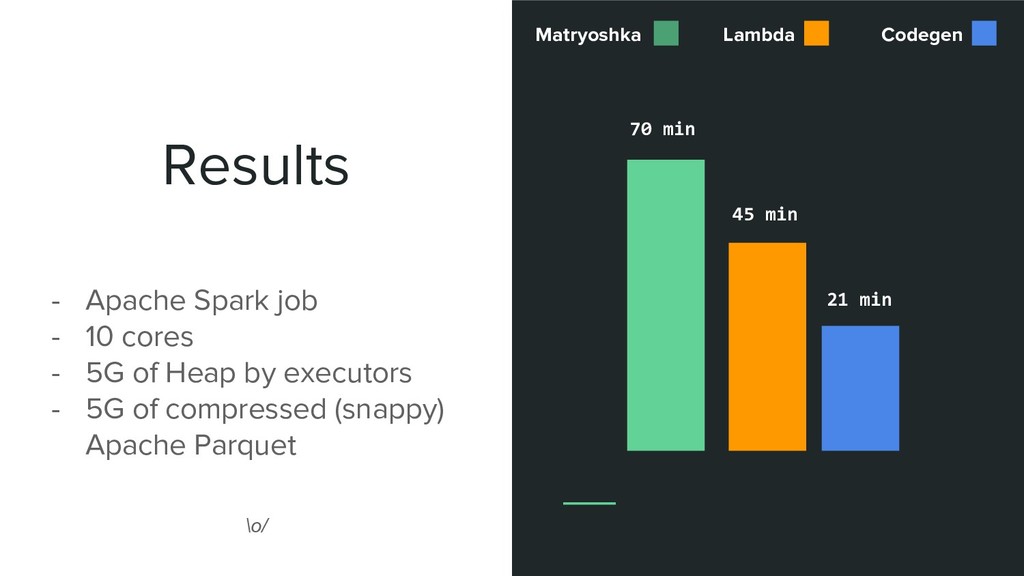
Apache Spark Job (ex Millions of records) is : - GC Intensive (lots of conversions back & forth) - ex. for the matryoshka engine : (Spark Row) => (DataF) => (DataWithSchema) => (DataF) => (Row) - Not really integrated with Spark (No DataFrame function, so we need a UDF ? or go back to RDD ?)
It generate too much objects => GC Overflow • It becomes tedious to use : > val r = df.rdd.map(row => ApplyPrivacyEngine.transform(schema, row, strategies)) spark.createDataFrame(r, newSchema)... :(
“Java Code” to - go down into the data according to a schema - mutate it according to privacy - stay “off-heap” using sun.misc.unsafe as much as possible i.e. : Algebra[SchemaF, CatalystOp] where CatalystOp = NoOp + CatalystCode(InputVariable => String, outputVariable)
= No need to do anything • CatalystCode = we’ll generate some code ◦ The “caller” provides the name of the input variable ◦ The case class provides the name of the output variable case class InputVariable(name: String) extends AnyVal sealed trait CatalystOp case class CatalystCode(code: InputVariable => String, outputVariable: String) extends CatalystOp case object NoOp extends CatalystOp
Our schema privacyStrategies: PrivacyStrategies, // The strategies to apply children: Seq[Expression] // The top columns of our dataframe ) extends Expression { // can your expression output a null ? override def nullable: Boolean = ??? // How does your expression transform the original schema of your data override def dataType: DataType = ??? // What spark will call to evaluate your expression without codegen override def eval(input: InternalRow) = ??? // here’s the code generation part ! override protected def doGenCode(ctx: CodegenContext, ev: ExprCode): ExprCode = ??? }
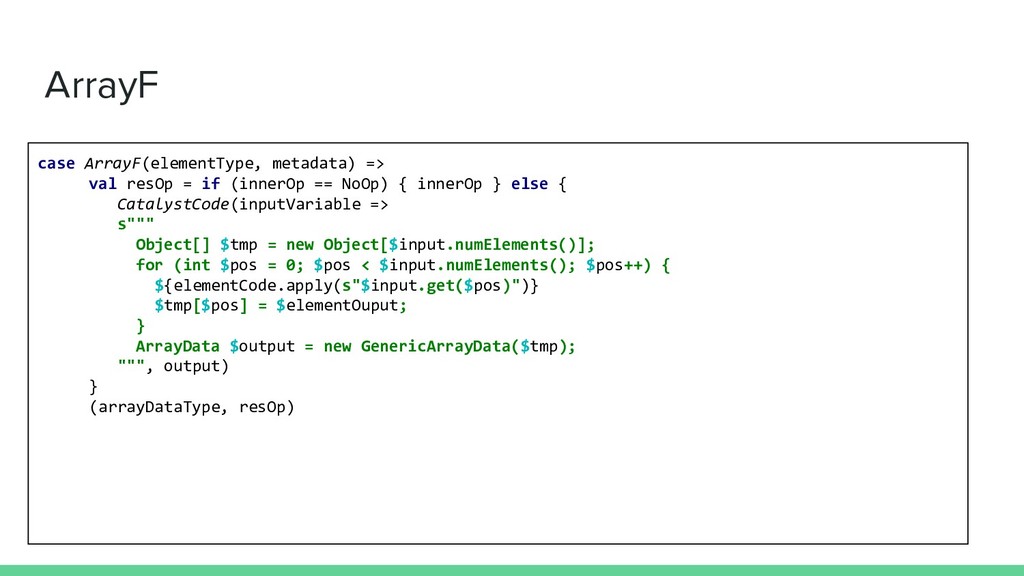
case StructF(fieldsWithDataTypes, metadata) => // create the code to destroy / re-create the struct // & call the code previously computed for each field case ArrayF(elementType, metadata) => // create the code to destroy / re-create the array // & call the code previously computed for the “elementType” case v: ValueF[FieldWithInfos] if valueColumnSchema.metadata.tags.nonEmpty => // create the code to mutate the field (or NoOp) case v: ValueF[FieldWithInfos] if value.metadata.tags.isEmpty => // \o/ NoOp FTW ! }
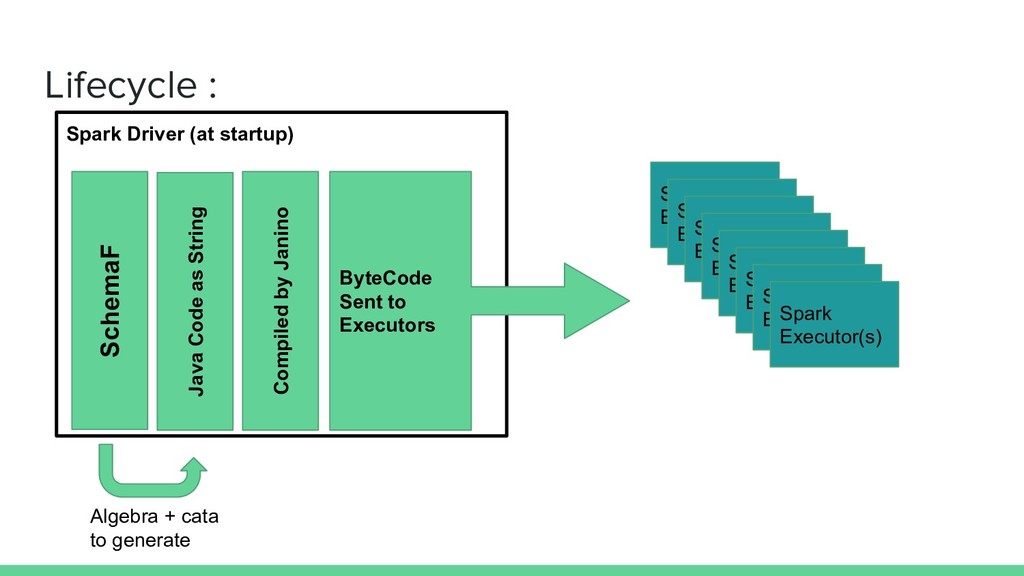
now : - the data stays “off”-heap if it’s not needed - it can even stays in the Tungsten format for Long,Int,etc… while being mutated - & it is deeply integrated with Spark in a non-hacky way !
generic privacy framework • create 3 engines with different point of views : ◦ Matryoshka Engine for the most complicated cases ◦ Lambda Engine well suited for streaming app ◦ Codegen Engine well suited for simple low-overhead Batch processing • All of that in a testable, (type-)safe, efficient and maintainable way !
here - https://github.com/ogirardot/high-perf-privacy-scalaIO2018 Check out the ongoing effort around scalaz-schema - https://github.com/scalaz/scalaz-schema Contact us on twitter : @ogirardot @WiemZin
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Privacy Framework type PrivacyStrategies = Map[Seq[String], PrivacyStrategy]](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_10.jpg){kind=link}
![Privacy Framework type PrivacyStrategies = Map[Seq[String], PrivacyStrategy] “address” “name” “email”](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_11.jpg){kind=link}
![Privacy Framework type PrivacyStrategies = Map[Seq[String], PrivacyStrategy] “address” “name” “email”](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_12.jpg){kind=link}
![Privacy Framework type PrivacyStrategies = Map[Seq[String], PrivacyStrategy] “address” “name” “email”](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_13.jpg){kind=link}
![Privacy Framework type PrivacyStrategies = Map[Seq[String], PrivacyStrategy] String String String](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_14.jpg){kind=link}
![Privacy Framework type PrivacyStrategies = Map[Seq[String], PrivacyStrategy] String String String](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
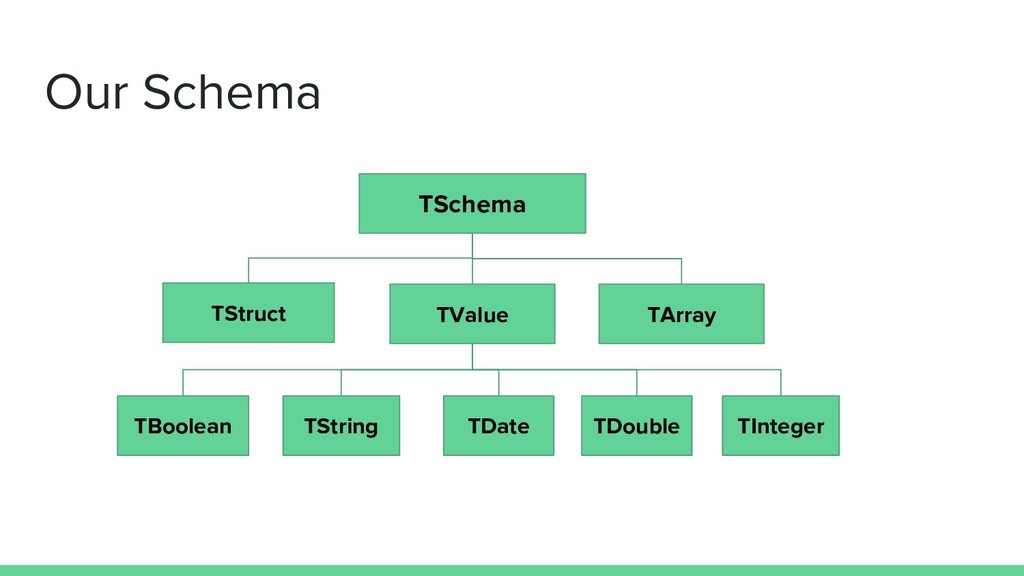
![Our Schema sealed trait TSchema case class TStruct(fields: List[(String, TSchema)],](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_25.jpg){kind=link}
![Our Schema sealed trait TSchema case class TStruct(fields: List[(String, TSchema)],](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_26.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Step 1: Remove Recursion sealed trait SchemaF[A] case class StructF[A]](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_35.jpg){kind=link}
![But.. case class StructF[A] (fields: List[(String, A)], metadata: ColumnMetadata) extends](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_36.jpg){kind=link}
![But.. val schema: SchemaF[SchemaF[ ]] = StructF(List("adresses" -> ArrayF(StringF[Nothing](m1), m2),](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_37.jpg){kind=link}
![Solution We need something like this: val schema:SchemaF[SchemaF[ ]] →](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_38.jpg){kind=link}
![Step 2: Recapture Recursion case class Fix[F[_]](unFix: F[Fix[F]])](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_39.jpg){kind=link}
![Step 2: Recapture Recursion case class Fix[F[_]](unFix: F[Fix[F]]) Fix[F] ==](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_40.jpg){kind=link}
![Step 2: Recapture Recursion case class Fix[F[_]](unFix: F[Fix[F]]) Fix[F] ==](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_41.jpg){kind=link}
![Step 2: Recapture Recursion case class Fix[F[_]](unFix: F[Fix[F]]) val schema:](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_42.jpg){kind=link}
![Step 3: Define Functor implicit val schemaFunctor: Functor[SchemaF] = new](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_43.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Coalgebra Coalgebra[F[_], A] = A => F[A] Coalgebra[SchemaF, DataType] =](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_49.jpg){kind=link}
{kind=link}
![val dataTypeToSchemaF: Coalgebra[SchemaF, DataType] = { case StructType(fields) => StructF(fields.map(f](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_51.jpg){kind=link}
![val dataTypeToSchemaF: Coalgebra[SchemaF, DataType] = { case StructType(fields) => StructF(fields.map(f](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_52.jpg){kind=link}
![val dataTypeToSchemaF: Coalgebra[SchemaF, DataType] = { case StructType(fields) => StructF(fields.map(f](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_53.jpg){kind=link}
![val dataTypeToSchemaF: Coalgebra[SchemaF, DataType] = { case StructType(fields) => StructF(fields.map(f](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_54.jpg){kind=link}
![val dataTypeToSchemaF: Coalgebra[SchemaF, DataType] = { case StructType(fields) => StructF(fields.map(f](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_55.jpg){kind=link}
![val dataTypeToSchemaF: Coalgebra[SchemaF, DataType] = { case StructType(fields) => StructF(fields.map(f](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_56.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Algebra Algebra[F[_], A] = F[A] => A Algebra[SchemaF, DataType] =](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_63.jpg){kind=link}
![Algebra def schemaFToDataType: Algebra[SchemaF, DataType] = { case StructF(fields, _)](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_64.jpg){kind=link}
![Algebra def schemaFToDataType: Algebra[SchemaF, DataType] = { case StructF(fields, _)](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_65.jpg){kind=link}
![Algebra def schemaFToDataType: Algebra[SchemaF, DataType] = { case StructF(fields, _)](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_66.jpg){kind=link}
![Algebra def schemaFToDataType: Algebra[SchemaF, DataType] = { case StructF(fields, _)](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_67.jpg){kind=link}
![Algebra def schemaFToDataType: Algebra[SchemaF, DataType] = { case StructF(fields, _)](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_68.jpg){kind=link}
![Algebra def schemaFToDataType: Algebra[SchemaF, DataType] = { case StructF(fields, _)](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_69.jpg){kind=link}
![Algebra def schemaFToDataType: Algebra[SchemaF, DataType] = { case StructF(fields, _)](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_70.jpg){kind=link}
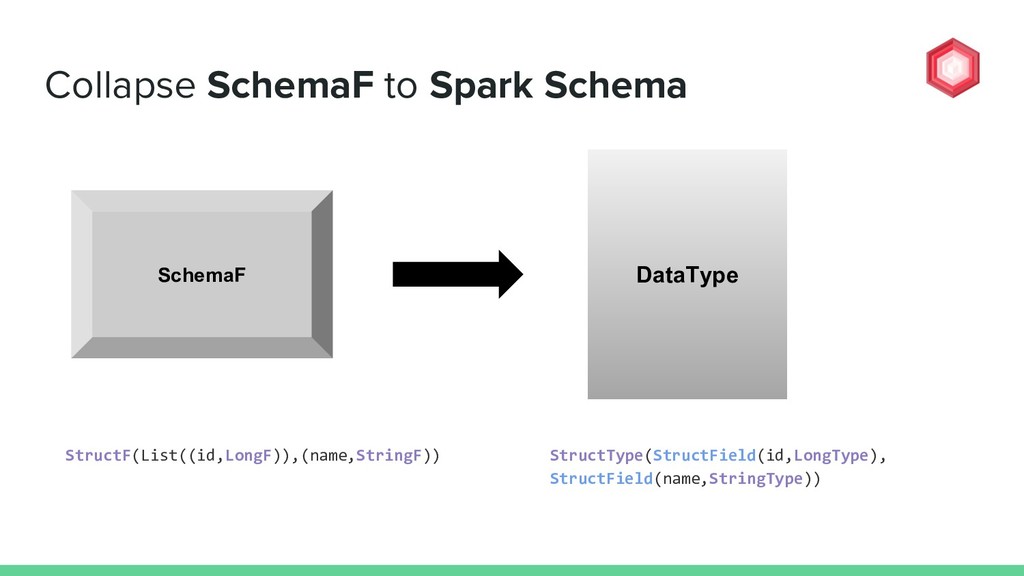
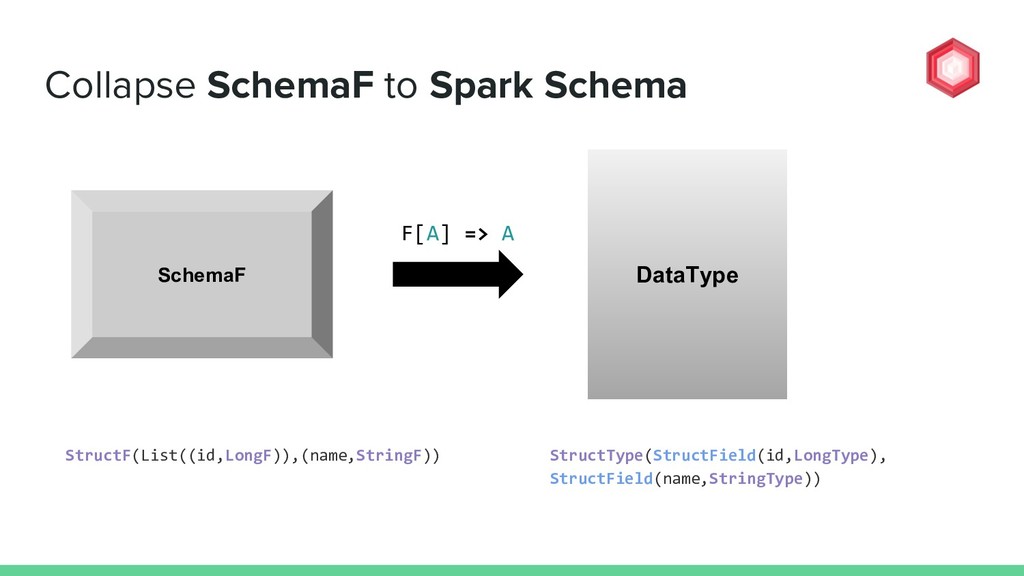
![How to collapse a SchemaF into DataType? val schemaF: Fix[SchemaF]](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_71.jpg){kind=link}
![cata val schemaF: Fix[SchemaF] = Fix(StructF(List(id,Fix(LongF(ColumnMetadata.empty)), (name, Fix(StringF(ColumnMetadata.empty))))) val dataType:](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_72.jpg){kind=link}
![cata val schemaF: Fix[SchemaF] = Fix(StructF(List(id,Fix(LongF(ColumnMetadata.empty)), (name, Fix(StringF(ColumnMetadata.empty))))) val dataType:](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_73.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![hylo DataType1 DataType2 DataType1 DataType2 hylo def hylo[F[_]: Functor, A,](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_78.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Zip Data & Schema recursively ? case class EnvT[E, W[_],](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_83.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Putting it all together (schema, data).hyloM[\/[Incompatibility, ?], DataWithSchema, Fix[DataF]](privacyAlg, zipWithSchema)](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_88.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![sealed trait MutationOp extends Serializable { def apply(gdata: Fix[DataF]): Fix[DataF]](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_93.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Creating a new expression : case class ApplyPrivacyExpression(schema: Fix[SchemaF], //](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_108.jpg){kind=link}
{kind=link}
![Let’s create the CatalystCode val privacyAlg: Algebra[SchemaF, FieldWithInfos] = {](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_110.jpg){kind=link}
![ValueF case valueColumnSchema: ValueF[FieldWithInfos] if valueColumnSchema.metadata.tags.nonEmpty => val valueCode =](https://files.speakerdeck.com/presentations/1be29aa636f94e27817face298cdff01/slide_111.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}