BigData/Cloud/Machine Learning, c'est maintenant des mots passé dans le langage courant, mais souvent avant d'atteindre le niveau de la *Big*Data, il faut parfois se battre pour juste avoir la partie Data. Dans cette présentation, je vais vous apprendre à créer de la donnée !!
Ok, pas créer de la donnée... Disons plutôt sauvegarder le patrimoine mondial de l'humanité en utilisant une bonne dose de connaissance du web, un peu de NLP, de crawling et surtout un peu de Python. Si vous décidez de me suivre, vous allez pouvoir apprendre rapidement :
A organiser votre recherche d'information et la selection de vos cibles
Comment extraire l'information d'une page web
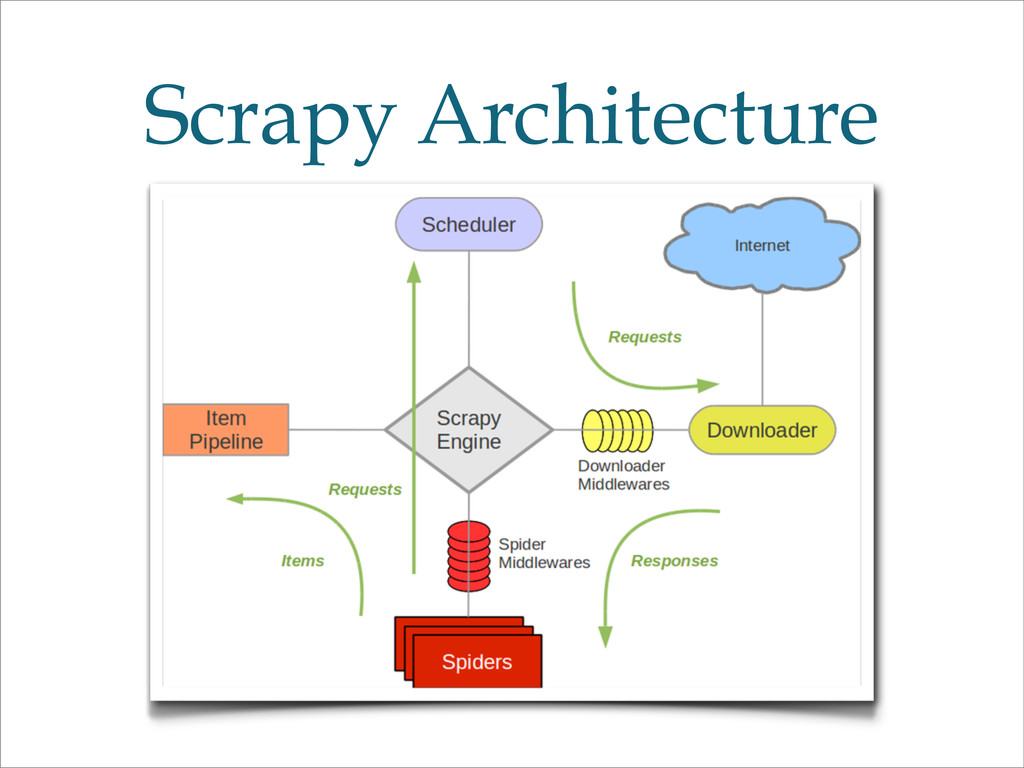
A construire et déployer un crawler pour le web
Comment bypasser, comme un vrai hacker, certaines techniques de protection des sites web
et quelques techniques pour arriver à extraire de l'information de textes bruts
A grands pouvoirs, correspond grandes responsabilités, ainsi le tout sera saupoudré d'une courte introduction au contexte légal pour que vous ne choisissiez d'utiliser vos nouvelles compétences en connaissance de cause et dans les limites de la loi.
Et puis comme j'aime bien les challenges, on fera une petite séance de LiveCoding, où je mettrais tout ça en pratique avec vous sur un sujet que vous allez choisir en live pendant la conférence.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}