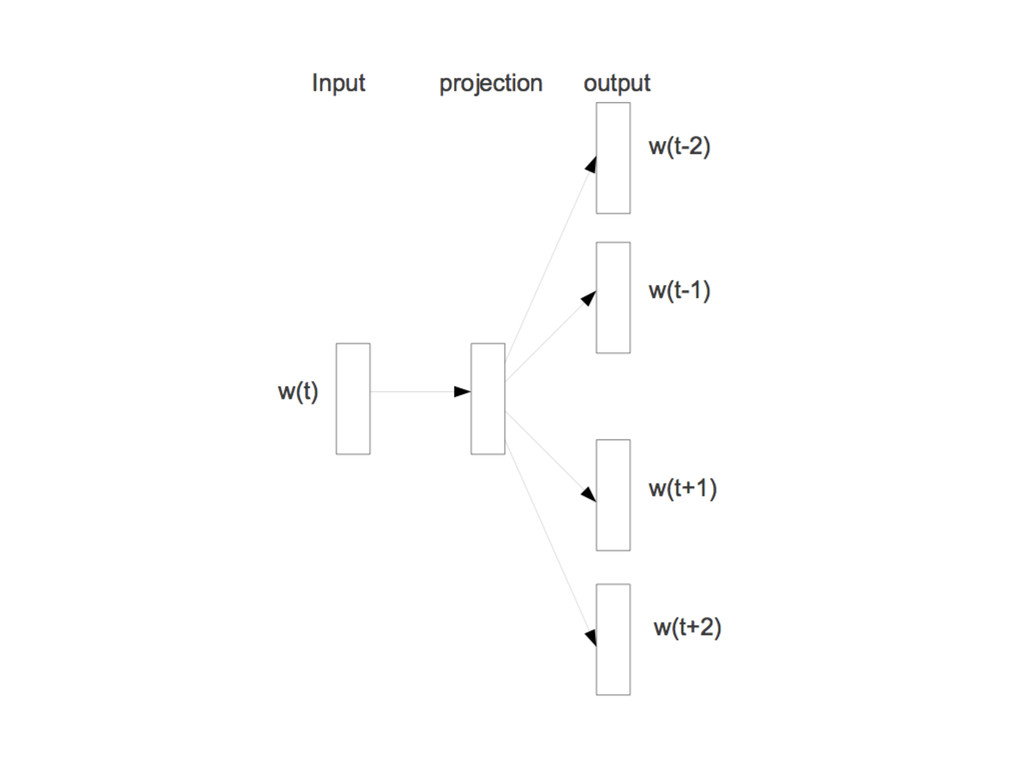
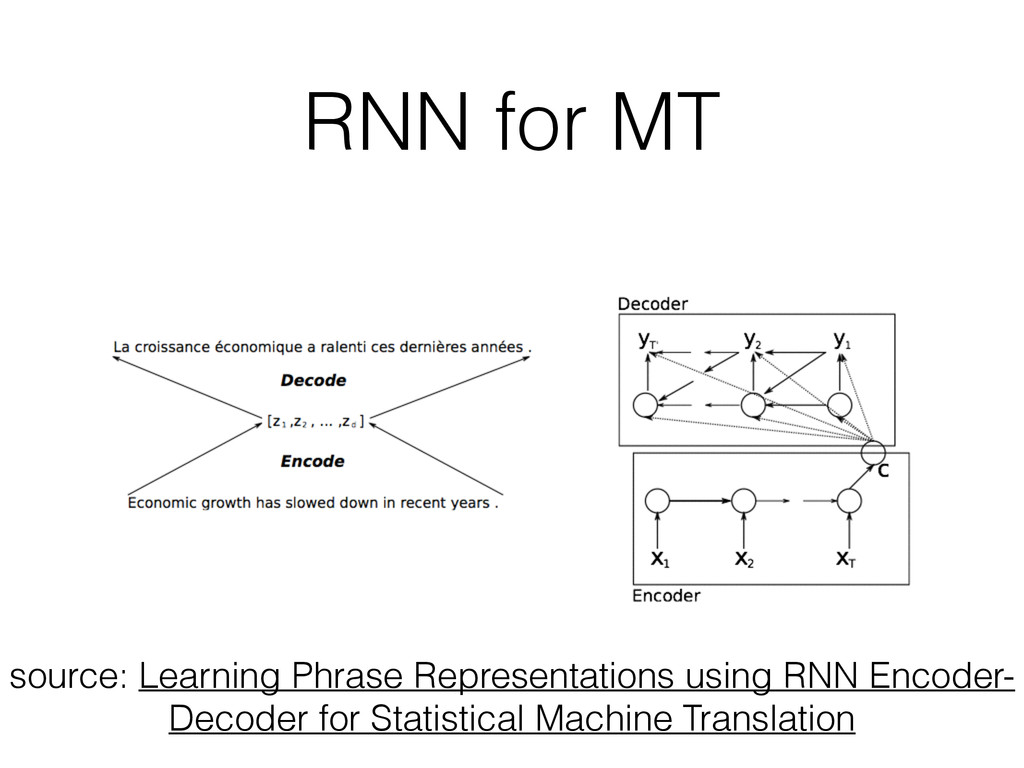
fixed dimensional vector • Goal is to predict target word given ~5-10 words context from a random sentence in Wikipedia • Use NN-style training to optimize the vector coefficients typically with log-likelihood objective (bi-linear, deep or recurrent architectures)
benefit from larger training data (1B+ words) and dimensions (typically 50-300) • Some models (GloVe) closer to matrix factorization than neural networks • Can successfully uncover semantic and syntactic word relationships from unlabeled corpora (wikipedia, Google News, Common Crawl).
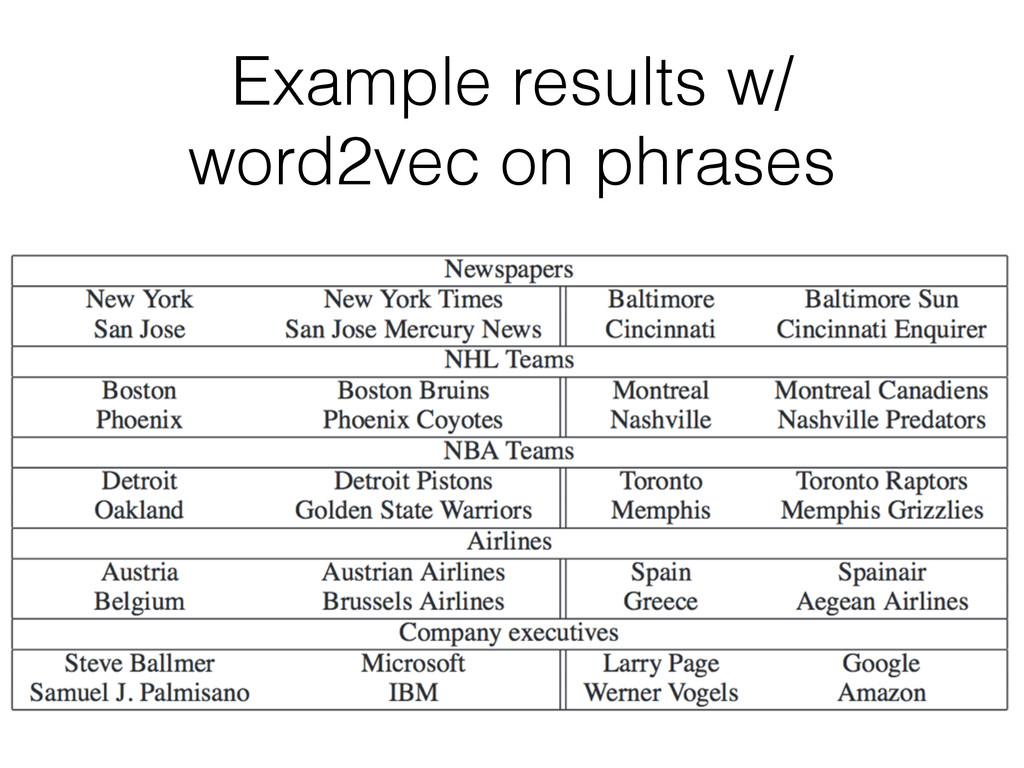
to extract 3-gram and 4-gram phrases. Then treat phrases in as new “words” to embed along with the unigrams. Score interesting bi-grams from counts and threshold:
GloVe is planned) • gensim also has: • Wikipedia corpus loader (markup cleaning) • similarity queries and evaluation tools • glove-python (work in progress, very active) • Both use Cython and multi-threading
each project page) First gen: http://metaoptimize.com/projects/wordreprs/ Word2Vec: https://code.google.com/p/word2vec/ GloVe: http://nlp.stanford.edu/projects/glove/ Word2Vec & GloVe both provide pre-trained embeddings on English datasets. • Relation to sparse and explicit representations Linguistic Regularities in Sparse and Explicit Word Representations by Omer Levy and Yoav Goldberg
{kind=link}
{kind=link}
{kind=link}
{kind=link}
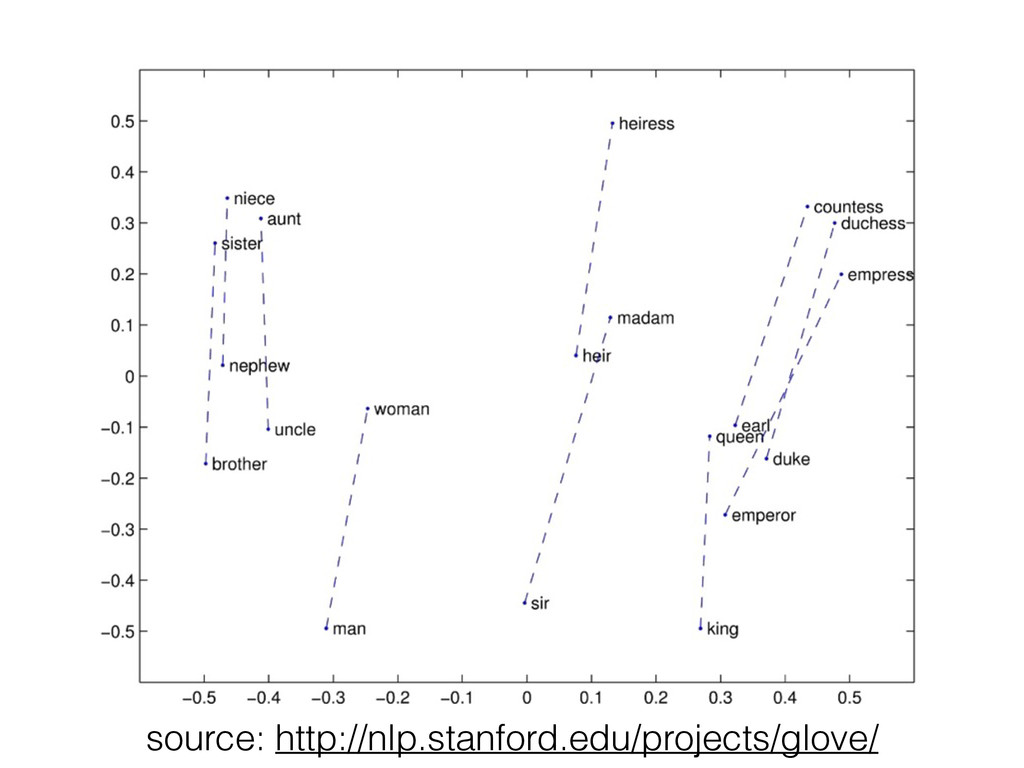
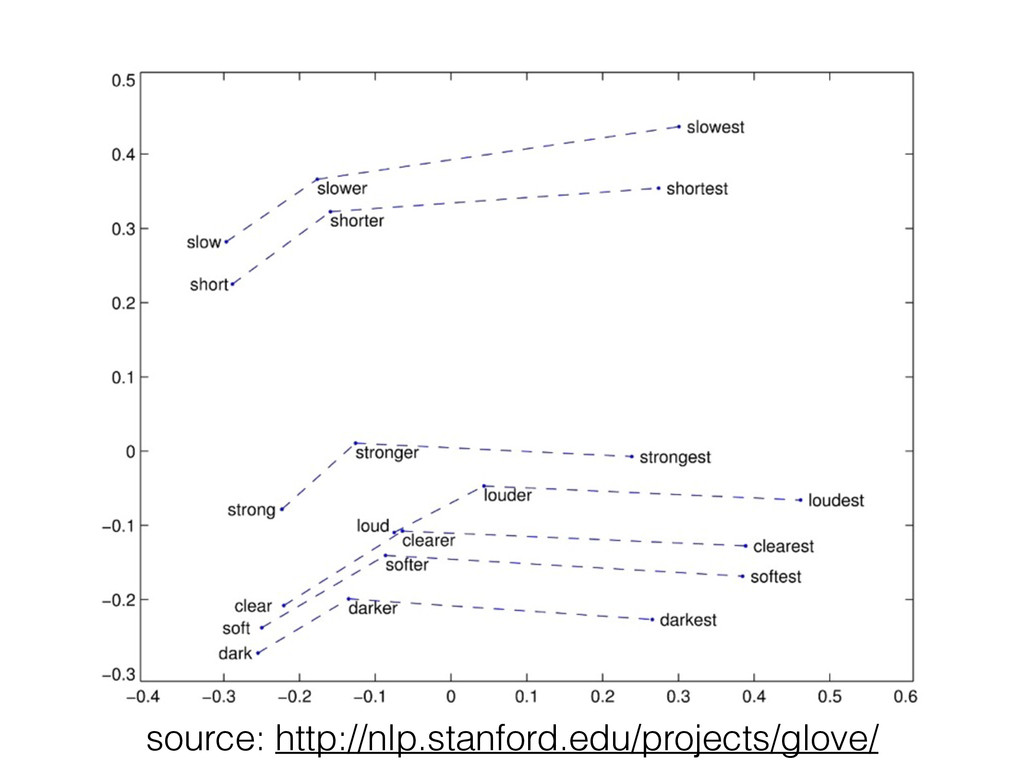
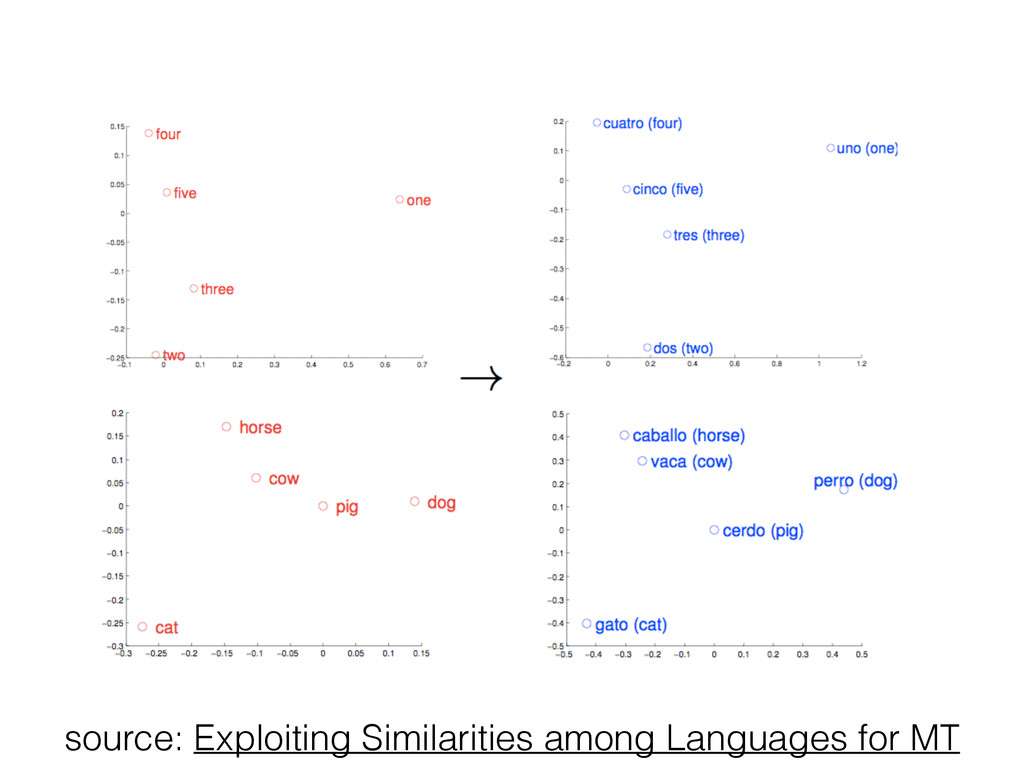
![Analogies • [king] - [male] + [female] ~= [queen] •](https://files.speakerdeck.com/presentations/31f18ad0522c0132b9b662e7bb117668/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}